##Node中的Stream(流)
流(stream)在 Node.js 中是处理流数据的抽象接口(abstract interface)。
stream模块提供了基础的 API 。使用这些 API 可以很容易地来构建实现流接口的对象。Node.js 提供了多种流对象。 例如, HTTP 请求 和
process.stdout就都是流的实例。流可以是可读的、可写的,或是可读写的。所有的流都是EventEmitter*(Node事件机制将在后续讲解,可以先自行了解)*的实例。
尽管所有的 Node.js 用户都应该理解流的工作方式,这点很重要, 但是 stream 模块本身只对于那些需要创建新的流的实例的开发者最有用处。 对于主要是消费流的开发者来说,他们很少(如果有的话)需要直接使用 stream 模块。
####1.Node Stream(流)
数据流(stream)是处理系统缓存的一种方式。操作系统采用数据块(chunk)的方式读取数据,每收到一次数据,就存入缓存。Node应用程序有两种缓存的处理方式,第一种是等到所有数据接收完毕,一次性从缓存读取,这就是传统的读取文件的方式*(遇上大文件很容易使内存爆仓);第二种是采用“数据流”的方式,收到一块数据,就读取一块,即在数据还没有接收完成时,就开始处理它(像流水一样)*
####Node.js 中有四种基本的流类型:
- Readable - 可读的流 (例如
fs.createReadStream()). - Writable - 可写的流 (例如
fs.createWriteStream()). - Duplex - 可读写的流 (例如
net.Socket). - Transform - 在读写过程中可以修改和变换数据的 Duplex 流 (例如
zlib.createDeflate()).
####所有的 Stream 对象都是 EventEmitter 的实例 常用的事件有:
data- 当有数据可读时触发。end- 没有更多的数据可读时触发。error- 在接收和写入过程中发生错误时触发。finish- 所有数据已被写入到底层系统时触发。
可读流(Readable streams)是对提供数据的 源头 (source)的抽象
可读数据流有两种状态:流动状态和暂停状态。处于流动状态时,数据会尽快地从数据源导向用户的程序(就像流水一样);处于暂停态时,必须显式调用stream.read()等指令,“可读数据流”才会释放数据,(就像流水的闸门,打开它水才继续流下去)
可读流在创建时都是暂停模式,暂停模式和流动模式可以互相转换。
要从暂停模式切换到流动模式,有下面三种办法:
-
给“data”事件关联了一个处理器
-
显式调用
resume() -
调用
pipe()方法将数据送往一个可写数据流
要从流动模式切换到暂停模式,有两种途径:
- 如果这个可读的流没有桥接可写流组成管道,直接调用
pause() - 如果这个可读的流与若干可写流组成了管道,需要移除与“data”事件关联的所有处理器,并且调用
unpipe()方法断开所有管道
readable:在数据块可以从流中读取的时候发出。它对应的处理器没有参数,可以在处理器里调用read([size])方法读取数据。data:有数据可读时发出。它对应的处理器有一个参数,代表数据。如果你只想快快地读取一个流的数据,给data关联一个处理器是最方便的办法。处理器的参数是Buffer对象,如果你调用了Readable的setEncoding(encoding)方法,处理器的参数就是String对象。end:当数据被读完时发出。对应的处理器没有参数。close:当底层的资源,如文件,已关闭时发出。不是所有的Readable流都会发出这个事件。对应的处理器没有参数。error:当在接收数据中出现错误时发出。对应的处理器参数是Error的实例,它的message属性描述了错误原因,stack属性保存了发生错误时的堆栈信息。
read([size]):该方法可以接受一个整数作为参数,表示所要读取数据的数量,然后会返回该数量的数据。如果读不到足够数量的数据,返回null。如果不提供这个参数,默认返回系统缓存之中的所有数据。setEncoding(encoding):给流设置一个编码格式,用于解码读到的数据。调用此方法后,read([size])方法返回String对象。pause():暂停可读流,不再发出data事件resume():恢复可读流,继续发出data事件pipe(destination,[options]):绑定一个 Writable 到readable上, 将可写流自动切换到 flowing 模式并将所有数据传给绑定的 Writable。数据流将被自动管理。这样,即使是可读流较快,目标可写流也不会超负荷(overwhelmed)unpipe([destination]):该方法移除pipe方法指定的数据流目的地。如果没有参数,则移除所有的pipe方法目的地。如果有参数,则移除该参数指定的目的地。如果没有匹配参数的目的地,则不会产生任何效果
Writable streams 是 destination 的一种抽象,这种 destination 允许数据写入
write方法用于向“可写数据流”写入数据。它接受两个参数,一个是写入的内容,可以是字符串,也可以是一个stream对象(比如可读数据流)或buffer对象(表示二进制数据),另一个是写入完成后的回调函数,它是可选的,write方法返回一个布尔值,表示本次数据是否处理完成
drainwritable.write(chunk)返回false以后,当缓存数据全部写入完成,可以继续写入时,会触发drain事件finish调用end方法时,所有缓存的数据释放,触发finish事件。该事件的回调函数没有参数pipe可写数据流调用pipe方法,将数据流导向写入目的地时,触发该事件unpipe可读数据流调用unpipe方法,将可写数据流移出写入目的地时,触发该事件error如果写入数据或pipe数据时发生错误,就会触发该事件
-
write()用于向“可写数据流”写入数据。它接受两个参数,一个是写入的内容,可以是字符串,也可以是一个stream对象(比如可读数据流)或buffer对象(表示二进制数据),另一个是写入完成后的回调函数,它是可选的。 -
cork(),uncork()cork方法可以强制等待写入的数据进入缓存。当调用uncork方法或end方法时,缓存的数据就会吐出。 -
setDefaultEncoding()用于将写入的数据编码成新的格式。它返回一个布尔值,表示编码是否成功,如果返回false就表示编码失败。 -
end()用于终止“可写数据流”。该方法可以接受三个参数,全部都是可选参数。第一个参数是最后所要写入的数据,可以是字符串,也可以是stream对象或buffer对象;第二个参数是写入编码;第三个参数是一个回调函数,finish事件发生时,会触发这个回调函数。
管道提供了一个输出流到输入流的机制。通常我们用于从一个流中获取数据并将数据传递到另外一个流中>(我们把文件比作装水的桶,而水就是文件里的内容,我们用一根管子(pipe)连接两个桶使得水从一个桶流入另一个桶,这样就慢慢的实现了大文件的复制过程)
千言万语抵不过这图:
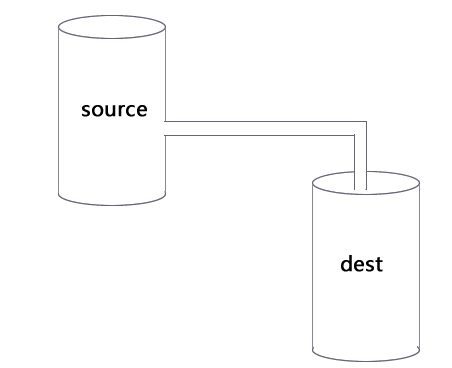
链式是通过连接输出流到另一个流并创建多个流操作链的机制,链式流一般用于管道操作
接下来我们就是用管道和链式来压缩文件 创建compress.js文件
const fs =require('fs');
const zlib = require('zlib');
// 将README.md文件压缩为README.md.gz
fs.createReadStream('/README.md')
.pipe(zlib.createGizp())
.pipe(fs.createWriteStream('README.md.gz'))
console.log('GZIP DONE')const fs = require('fs');
// 可读取数据流
let data = ''
// 创建数据流
let readStream = fs.creaateReadStream('./README.md')
console.log(readStream)
// 设置编码格式
readStream.setEncoding('UTF-8')
//处理事件流 end,data,error
readStream.on('data',function(chunk){
data+=chunk
})
readStream.on('end',function(){
console.log(data)
})
readerStream.on('error', function(err){
console.log(err.stack)
})
console.log("程序执行完毕")Node的Stream(流)很少需要直接使用 stream 模块,更多信息参考Node中文网
下面我们就进入今天的实例小项目:实现文件的复制功能
const fs = require('fs');
const file = fs.readFileSync('./README.md',{encoding:'utf8'})
fs.writeFileSync('./TEST.md',file)将文件内容存在内存中,小文件可以这样处理,大文件容易内存溢出
用Stream来实现这个简单的功能:
const fs =require('fs');
let pathname = {
src:'./copy.js',
dist:'./test.js',
}
let ReadStream = fs.createReadStream(pathname.src);
let WriteStream = fs.createWriteStream(pathname.dist);
ReadStream.pipe(WriteStream)
WriteStream.on('finish',()=>{
console.log('复制完成')
})
fs.readFileSync()const fs = require('fs');
const out = process.stdout;
let path = {
src: '../test/test.mp4',
dist:'../test1.mp4'
}
function copy(paths){
let {src,dist} = paths
let readStream = fs.createReadStreams(src)
let writeStream = fs.createWriteStream(dist)
let stat = fs.statSync(src),
totalSize = stat.size,
lastSize = 0,
process = 0,
startTime = Date.now();
readStream.on('data',funciton(chunk){
process += chunk.length;
})
//添加递归的setTimeout 作为旁观者
setTimeout(function show(){
let percent = Math.ceil(process/totalSize)*100;
let size = Math.ceil(process/1000000)
let diff = size - lastSize
lastSize = size
out.clearLine();
out.cursorTo(0)
out.write(`已经完成${size}MB,${percent}%,速度${diff*2}MB/s`)
if(process<totalSize){
setTimeout(show,500)
}else{
let endTime = Date.now()
console.log(`共用时:${(endTime - startTime) / 1000}秒。`)
}
},500)
}
copy(paths)对流来说,通常使用pipe方法更为简便直接