赵岳 14231027 备注:Thinking 3.7为选做。Exercise3.1代码已经给出,不再赘述。
void
env_init(void)
{
int i;
LIST_INIT(&env_free_list);
for(i=NENV-1;i>=0;i--){ //NENV=1024, with backward sequence
envs[i].env_status=ENV_FREE;
LIST_INSERT_HEAD(&env_free_list,envs+i,env_Link);
}
}
与page_init类似,甚至比其简单。因为在page_init函数中,我们还需要考虑哪些物理页已经使用了,哪些还未使用。而在env_init函数中所有进程都是ENV_FREE的。唯一需要注意的只是需要逆序插入。
注释中说:Insert in reverse order, so that the first call to env_alloc() returns envs[0]. 我们使用的是LIST_INSERT_HEAD宏,即每次都插入到链表的头部,我们从freelist中取出一项时,使用LIST_FIRST宏,那么既然要让取出的是env[0],那我们必须要让env[0]最后插入,也就是倒序插入的方式构造链表。除此原因以外,我们在后面的时间片轮转算法中,是从envs数组的envs[0]开始的,因此我们需要逆序插入,这样才能保证最先来到的进程最先被分配,最先被轮转。
1.第三点注释中的问题: 为什么我们要执行pgdir[i] = boot_pgdir[i]这个 赋值操作?换种说法,我们为什么要使用boot_pgdir作为一部分模板?(提 示:mips 虚拟空间布局)
1.每一个进程都有 4G 的逻辑地址可以访问,而多个进程的UTOP~4G是内核态,是在不切换进程的情况下(由于我们是2G/2G的模式,切换到内核态并不用切换进程,也就自然不用改变CR3寄存器了),切换到内核态的。那既然每个进程都可以切换到内核态,自然就需要给每个进程都拷贝一份boot_pgdir的内容到envs_pgdir中。因此需要该赋值操作。
2.UTOP和ULIM差距是3*4Mb的大小。这12Mb的虚拟地址实际上存储的是记录页面使用情况的4M大小的PAGES数组,4M进程控制块ENVS数组和用户页表域的那4M虚拟空间。由于这些变量应该是全局的,它们也应属于“内核态”。因此,我们在赋值的时候,是从第PDX(UTOP)项开始把boot_pgdir赋给envs_pgdir的,而不是ULIM。而ULIM以上的地址只是可以直接去掉高位进行物理-虚拟地址转换。
3.env_cr3存储的是用户进程页目录的物理地址, e->env_pgdir[PDX(UVPT)] = e->env_cr3 | PTE_V | PTE_R;的赋值就是让用户进程页目录中的第PDX(UVPT)项存储的物理地址等于用户进程页目录的物理地址,这样就完成了自映射。当我们给出一个属于UVPT域(UVPT ~ UVPT+4M)的虚拟地址时,进行虚拟到物理地址转换时,就会找到用户进程页目录的物理地址。
int
env_alloc(struct Env **new, u_int parent_id)
{
int setup_return_value;
struct Env *temp;
/*precondtion: env_init has been called before this function*/
/*1. get a new Env from env_free_list*/
temp=LIST_FIRST(&env_free_list);
/*2. call some function(has been implemented) to intial kernel memory layout for this new Env.
*hint:please read this c file carefully, this function mainly map the kernel address to this new Env address*/
if((setup_return_value=env_setup_vm(temp))<0)
return setup_return_value;
/*3. initial every field of new Env to appropriate value*/
temp->env_id = mkenvid(temp);
temp->env_parent_id=parent_id;
temp->env_status=ENV_NOT_RUNNABLE;
/*4. focus on initializing env_tf structure, located at this new Env. especially the sp register,
* CPU status and PC register(the value of PC can refer the comment of load_icode function)*/
temp->env_tf.regs[29]=USTACKTOP;
temp->env_tf.pc=UTEXT+0xb0;
temp->env_tf.cp0_status=0x10001004; //MIPS R3000
/*5. remove the new Env from Env free list*/
LIST_REMOVE(temp,env_link);
*new=temp;
return 0;
}
这个参数很关键。在我写load_icode_mapper、load_icode、load_elf这三个函数时,由于这三个函数是同一个进程的操作,那我们需要将记录该进程信息的数据结构一脉相承地作为参数传递下去,user_data这个参数位可以为我们很好的服务。比如,我们需要在load_icode_mapper中申请物理页面,把物理页面使用page_insert函数映射到该进程的页目录、页表中,那么我们当然就需要一个记录该进程的数据结构的指针,这样我们才能顺利找到该进程的页目录。否则,没有这个参数的穿线,这三个函数怎么算是为一个进程服务的呢?或者,一些关于I\O的进程,也需要这个参数传递与用户交互的数据。
static int load_icode_mapper(u_long va, u_int32_t sgsize,
u_char *bin, u_int32_t bin_size, void *user_data)
{
struct Env *env = (struct Env *)user_data;
struct Page *p = NULL;
u_long i;
int r; //return value
u_long offset = va - ROUNDDOWN(va, BY2PG);
/*Step 1: load all content of bin into memory. */
for (i = 0; i < bin_size; i += BY2PG) {
if((r= page_alloc(&p))<0)
return r;
if((r=page_insert(env->env_pgdir,p,va,PTE_V)) < 0)
return r;
bzero((void *)page2kva(p),BY2PG);
bcopy((void *)bin,(void *)(page2kva(p)+offset),BY2PG);
bin+=BY2PG;
va+=BY2PG;
/* Hint: You should alloc a page and increase the reference count of it. */
}
/*Step 2: alloc pages to reach `sgsize` when `bin_size` < `sgsize`.
* i has the value of `bin_size` now. */
while (i < sgsize) {
if((r= page_alloc(&p))<0)
return r;
if((r=page_insert(env->env_pgdir,p,va,PTE_V)) < 0)
return r;
bzero((void *)page2kva(p),BY2PG);
i+=BY2PG;
va+=BY2PG;
}
return 0;
}
该函数总体分为两大部分,第一部分是将进程的某一段段拷入用户空间里对应的地址上,第二部分是将剩下的未被代码填充的区域 填0。自然地想到了在init.c中的两个函数:bzero和bcopy。在这里,我猜想传入的va可能不是按页对齐的,因此我在使用bcopy函数时,起始地地址并不是一页的开始,而是加上页内偏移量。即page2kva(p)+offset。
static void
load_icode(struct Env *e, u_char *binary, u_int size)
{
struct Page *p = NULL;
u_long entry_point; //set this value in load_elf function
u_long r; //return value
u_long perm;
/*Step 1: alloc a page. */
if((r= page_alloc(&p))<0)
return;
/*Step 2: Use appropriate perm to set initial stack for new Env. */
/*Hint: The user-stack should be writable? */
perm=PTE_V|PTE_R;
page_insert(e->env_pgdir,p,(USTACKTOP-BY2PG),perm);
/*Step 3:load the binary by using elf loader. */
load_elf(binary,size,&entry_point,e, load_icode_mapper);
/***Your Question Here***/
/*Step 4:Set CPU's PC register as appropriate value. */
e->env_tf.pc = entry_point;
e->env_status=ENV_RUNNABLE;
}
这个函数是拷贝进程镜像的最后一关。通过调用load_elf找到了代码的各个区段,然后在load_elf中又调用mapper将各个区段(segment)映射好。最后,在该函数内,申请一页,添加映射关系(page_insert),将该进程的栈空间放在该物理页上,虚拟地址设置为USTACKTOP-BY2PG的位置上,保证栈顶位于USTACKTOP处。最后,由于我们没有在env_alloc函数内为进程设置PC,因此我们在该函数内还需要给进程设置PC值。这里,需要感谢学长将本年的操作系统实验难度降低,去除了给PC赋值的部分。使PC的赋值还有个各个segment的定位都放到了elf_loader函数内实现。
1.虚拟空间。
2.是一样的。由于每个进程都有属于自己的地址空间,我们在切换进程的时候,切换了cr3寄存器,也就是对于每个进程有不同的页目录、页表,那么就有不同的虚拟、物理地址映射关系。因此,虽然entry_point的值对于每个进程都一样,但是其对应的物理内存是不一样的,自然也对应了不同的指令。虚拟地址相同,具体内容不同。
3.UTEXT+0xb0。也就是0x004000b0。首先,UTEXT顾名思义,就像我们将操作系统的text放在0x80010000一样,这里应该存放的就是某个进程的代码段,也就是PC的起始位置。查阅了网上资料,发现ELF文件并不是一开始就是代码,而是有一些叫做magic的字节用于标识这是一个可执行文件,还有一些header。我们可以利用mips_4KC-readelf工具来直接观察这个地址。 Entry point address: 0x4000b0就是PC值设置为0x4000b0的证据。
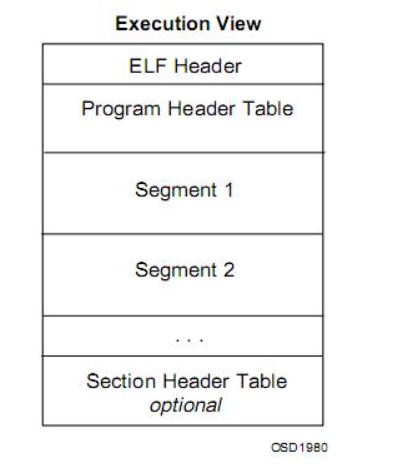 参考博客:(可执行文件(ELF)格式的理解 )
参考博客:(可执行文件(ELF)格式的理解 )
struct Env *e;
/*Step 1: Use env_alloc to alloc a new env. */
if((env_alloc(&e,0))< 0)
return;
/*Step 2: Use load_icode() to load the named elf binary. */
load_icode(e,binary,size);
这里没什么难度,只需依次调用alloc函数和进程加载镜像函数,来创建一个进程即可。值得一提的是,由于我们是新创建的进程,所以不算进程创建进程,因此没有父进程,新的env的父env结构体id是0,作为alloc的第二个参数。还有一点,就是我实现进程的创建时,在env_alloc后,并未将进程的status直接设置为ENV_RUNNABLE,而是在load_icode函数的最后才将其设置为ENV_RUNNABLE。这也是符合逻辑的,因为在alloc的时候,进程的栈还未设置好,PC值也未设置好。这或许就是"合适的值"的意义所在吧。
查看这两个文件我们可以看到,每个文件实际上都定义了两个全局变量。 我们以 code_a.c 为例, unsigned char binary_user_A_start[] 代表的是二进制代码, unsigned int binary_user_A_size 代表的是二进制代码的大小。通过阅读宏
#define ENV_CREATE(x) \
{ \
extern u_char binary_##x##_start[];\
extern u_int binary_##x##_size; \
env_create(binary_##x##_start, \
(u_int)binary_##x##_size); \
}
就明白了,原来我们需要拼接形成变量名binary_user_A_start[],那么实际上x=user_A,user_B同理。然后我们将两行代码插入到init.c的注释处即可。
需要把env_tf.pc的地址设置为cp0_epc的位置。进程切换是由于各种中断触发的,所以,这个进程在再次被恢复执行的时候, 应该执行导致(或遭受)异常的那条指令,相当于异常处理程序处理结束,返回到原来的程序中, 所需要执行的那条指令。而异常返回地址记录在EPC中。也就是说,应该执行EPC(异常返回地址)寄存器中储存的那条指令。 这个知识实际在上学期计算机组成原理P7中已经学习过,这里没有什么难度。
答:TIMESTACK是一个保存上一个现场的栈结构。每个新的进程在run的时候,都需要将其拷贝一份到自己的trap frame里,以便记录该进程中断返回时回到的状态。这也符合栈的直观印象,是一个时间栈,越新的进程将在顶部的位置,每次只需要取顶部的拷贝进新进程的相关结构中即可。
void
env_run(struct Env *e)
{
/*Step 1: save register state of curenv. */
/* Hint: if there is a environment running,you should do
* context switch.You can imitate env_destroy() 's behaviors.*/
struct Trapframe *old;
if(curenv)
{
old=(struct Trapframe*)(TIMESTACK-sizeof(struct Trapframe));
bcopy(old,&curenv->env_tf,sizeof(struct Trapframe));
curenv->env_tf.pc=old->cp0_epc;
}
/*Step 2: Set 'curenv' to the new environment. */
curenv = e ;
/*Step 3: Use lcontext() to switch to its address space. */
lcontext(curenv->env_pgdir);
/*Step 4: Use env_pop_tf() to restore the environment's
* environment registers and drop into user mode in the
* the environment.
*/
/* Hint: You should use GET_ENV_ASID there.Think why? */
env_pop_tf(&(curenv->env_tf),GET_ENV_ASID(curenv->env_id));
}
这里有一点值得注意, lcontext(curenv->env_pgdir)最初我写成了lcontext(curenv->env_cr3),导致会出现LOW REFRENCE的警告。仔细查找,在pmap.c中发现了证据:
pgdir = alloc(BY2PG, BY2PG, 1); //0x0400000 to 0x80401000 4096 bytes
printf("to memory %x for struct page directory.\n", freemem);
mCONTEXT = (int)pgdir;
也就是说,mCONTEXT中记录的是当前地址空间的页目录的虚拟地址,而查看lCONTEXT汇编函数发现,其作用非常简单,就是将参数传递给mCONTEXT。因此,我们在进行进程切换时,需要把当前进程的页目录的虚拟地址(这里一定是虚拟地址!)作为lCONTEXT汇编函数的参数。而我们在初始化一个进程时,将页目录的虚拟地址存在了env->env_pgdir中。所以将当前的curenv->env_pgdir传入调用函数即可。
.section .text.exc_vec3
NESTED(except_vec3, 0, sp)
.set noat
.set noreorder
1:
mfc0 k1,CP0_CAUSE
la k0,exception_handlers
andi k1,0x7c
addu k0,k1
lw k0,(k0)
NOP
jr k0
nop
END(except_vec3)
.set at
代码指导书已经给出,非常简单,我们只需要将其插入到start.S中合适的位置。至于合适的位置,我的理解是这样:首先阅读代码,大意是处理中断的过程。那么处理中断肯定应当是在_start之后了。其次,其中有一句.set noat我没有看懂,查阅网上资料发现它的意思是屏蔽以后对at的使用,配合后面的.set at打开屏蔽。那么我猜想如果没有.set at,并且把这段代码放到start.S的头部,可能会使后面的代码报错。当然,现在有了.set at应该就可以解决该问题了。
. = 0x80000080;
.except_vec3 : {
*(.text.exc_vec3)
}
插入到.end以前即可。
void sched_yield(void)
{
static int i = 0;
while(1){
i = (i+1)%NENV;
if (envs[i].env_status == ENV_RUNNABLE)
env_run(&envs[i]);
}
}
根据注释/*Implement simple round-robin scheduling.*/,我们需要实现一个轮转调度算法。所以,我们需要定义一个局部静态变量(注释中说关于计数的变量应当为静态变量), 用于记录我们当前轮转到了哪里。同时,寻找下一个可以被调度的进程(if (envs[i].env_status == ENV_RUNNABLE)),调用 env_run 来执行这个进程。至于在切换进程时发生了什么,并不是该函数所关心的,应该交给env_run函数来做。