Some of the subject matter reasoning attached to the academic aims of this course are outlined and discussed here. Here is the Spring 2024 Schedule mapped to the contents of this README.
| Schedule | Topic | Readme Section Heading |
|---|---|---|
| 00: 01/16 – 01/20 | Design Orientation | Design Foundations - Orientation to the Subject |
| 01: 01/21 – 01/27 | Design Orientation | Design Foundations - Orientation to the Subject |
| 02: 01/28 – 02/03 | Empirical Software Testing | Empirical Validation and Testing |
| 03: 01/28 – 02/03 | Design Principles, Paradigms, and Patterns | Design Principles, Paradigms, and Patterns |
| 04: 02/04 – 02/10 | Design Principles, Paradigms, and Patterns | Design Principles, Paradigms, and Patterns |
| 05: 02/11 – 02/17 | Design Principles, Paradigms, and Patterns | Design Principles, Paradigms, and Patterns |
| 06: 02/18 – 02/24 | Architectures Part 1 | Software Architecture Patterns 1 |
| 07: 02/25 – 03/02 | Architectures Part 1 | Software Architecture Patterns 1 |
| 08: 03/03 – 03/09 | Implementations Details Part 1 | Implementation Details 1 |
| 09: 03/17 – 03/23 | Architectures Part 2 | Software Architecture Patterns 2 |
| 10: 03/24 – 03/30 | Architectures Part 2 | Software Architecture Patterns 2 |
| 11: 03/31 – 04/06 | Implementations Details Part 2 | Forthcoming |
| 12: 04/07 - 04/13 | The Software Architect | The Software Architect |
| 13: 04/14 - 04/19 | Continuous Improvement and the Mastery Path |
- Design Foundations - Orientation to the Subject
- Design Principles, Paradigms, and Patterns
- Empirical Validation and Testing - Empirical Software Testing
- Software Architecture and Patterns
- The Empirics of Implementation
- Components, Modularity
- Abstractions, Details, and Implementation
- The Software Architect
- Continuous Improvement and the Mastery Path
We are here to learn more about Software Engineering, Software Architecture, and Systems Design and Development. These are not necessarily overlapping concepts, but they do share familial aims and purposes.
However, to wit, let us see what the oracle of our age, Wikipedia, has to say about thes things.
Software Engineering
Software engineering is an engineering-based approach to software development. A software engineer applies the engineering design process to design, develop, test, maintain, and evaluate computer software. The term programmer is sometimes used as a synonym, but may emphasize software implementation over design and can also lack connotations of engineering education or skills.
Engineering techniques are used to inform the software development process, which involves the definition, implementation, assessment, measurement, management, change, and improvement of the software life cycle process itself. It heavily uses software configuration management, which is about systematically controlling changes to the configuration, and maintaining the integrity and traceability of the configuration and code throughout the system life cycle. Modern processes use software versioning.
Software Architecture
Software architecture is the set of structures needed to reason about a software system and the discipline of creating such structures and systems. Each structure comprises software elements, relations among them, and properties of both elements and relations.
The architecture of a software system is a metaphor, analogous to the architecture of a building. It functions as the blueprints for the system and the development project, which project management can later use to extrapolate the tasks necessary to be executed by the teams and people involved.
Software architecture design is commonly juxtaposed with software application design. Whilst application design focuses on the design of the processes and data supporting the required functionality (the services offered by the system), software architecture design focuses on designing the infrastructure within which application functionality can be realized and executed such that the functionality is provided in a way which meets the system's non-functional requirements.
Software architecture is about making fundamental structural choices that are costly to change once implemented. Software architecture choices include specific structural options from possibilities in the design of the software.
For example, the systems that controlled the Space Shuttle launch vehicle had the requirement of being very fast and very reliable. Therefore, an appropriate real-time computing language would need to be chosen. Additionally, to satisfy the need for reliability the choice could be made to have multiple redundant and independently produced copies of the program, and to run these copies on independent hardware while cross-checking results.
Documenting software architecture facilitates communication between stakeholders, captures early decisions about the high-level design, and allows reuse of design components between projects.
Systems Development
In software engineering, a software development process is a process of planning and managing software development. It typically involves dividing software development work into smaller, parallel, or sequential steps or sub-processes to improve design and/or product management. It is also known as a software development life cycle (SDLC). The methodology may include the pre-definition of specific deliverables and artifacts that are created and completed by a project team to develop or maintain an application.
Most modern development processes can be vaguely described as agile. Other methodologies include waterfall, prototyping, iterative and incremental development, spiral development, rapid application development, and extreme programming.
A life-cycle "model" is sometimes considered a more general term for a category of methodologies and a software development "process" is a more specific term to refer to a specific process chosen by a specific organization.[citation needed] For example, there are many specific software development processes that fit the spiral life-cycle model. The field is often considered a subset of the systems development life cycle.
-
What is engineering?
-
What is design?
-
What is architecture
-
What is a system?
-
What is an information system?
-
What is software?
Let's explore these by unpacking some principal concepts that would surround these phenomena in support of answering these questions:
- What is the role of design in software and systems development?
- What structures exist to support engineering and design processes for systems development?
- How can we validate, verify, and implement our architectures?
- How can we engage in continuous improvement of our designed artifact
- When should we re-design and adjust?
- What are competencies and capabilities of the architect?
We will answer these, not necessarily in order, in the remaining sections here.
Design is the first stage of any successful system, and encompasses everything that you work on before you begin implementation - Jaime Buetla
We are really here to reconcile three things:
- Designs for Interfaces
- Designs for Business Logic
- Designs for Data

All systems will have these things and it is these systems that still drive the contemporary information and computing environment.
It will be common to encounter the concept of an Application Programming Interface as being the gateway into and out of a system. This is not to be confused with User Interfaces, Human Computer Interfaces, or OOP Interfaces. We will focus on APIs as they express the what of a system in terms of input, outcomes, and retreival.
There are a variety of approaches to this in the Python Language, including not relying on any frameworks beyond what comes with Python and its own Library.
We still write programs that govern the execution of systems and the direciton of the data and logic flows that reside within them. This is the case despite advances in AI and assistive tools meant to curate and accelerate the development of computer code artifacts. At this time, while many of these concepts could easily be learned without getting our "hands dirty" with code, that would be a mistake. We must make ourselves available to conversations and realizations with the materials of our design and these materials are code and data.
At its heart, writing an API allows other systems to utilize the outputs of a system without understanding how these results are obtined. While available actions outcomes are necessarily exposed to others (like a menu of options) without revealing the complexities of the operation; this is a simplification and simplification is a key aspect of using abstractions for modeling.
An answer regarding a fact or expression of system state are common responses provided by an API:
- expressions of fact (functional): output is commonly related to, and a function of inputs (e.g. conversion formulae).
- expressions of state (emphatic or emphemeral): State can vary with time and may not be purely deterministic (e.g. time-based lookups).
APIs should provide clearn intentions and expections for both inputs and outputs so that the API provides a clear and understandable contract.
Abstractions present scope and scale from which a system's outputs and benefits can be understood. In order to develop a good abstraction, a good understanding of what the system represents is also necessary - this understanding is often emergent.
When the process happens organically, the abstractions are decided mostly on the go. There is an initial idea, acknowledged as an understanding of the problem, that then gets tweaked.
Since all models are abstractions, our instincts and inclinations that pervade our understanding of the underlying phemena to which the system attends to will change (and perhaps mature).
In designing an API you explicitly describe the abstractions that the API will use clarify what the system will provide. The objective when modeling is to keep the viewpoint of a user of the system in mind; the purpose of the system is to meet the needs of users.
An abstraction can said to be "leaky" when it ceases to be an opaque "black box" and "leaks" implementation details.
'All non-trivial abstractions, to some degree, are leaky" – Joel Spolsky's Law of Leaky Abstractions
When designing an API, it is important to account for leakiness:
- Generate clear errors and hints: A good design will always include cases for things going wrong and try to present them clearly with proper error codes or error handling.
- Expose and alarm on depedency errors: When dependencies fail an API should abstract these details with some options for a graceful recovery. If a graceful landing is not possible, then some terminating signal would be appropriate.
A dictionary or key-value-pairing concept is useful for API design as communication can be described as API accessing resources that can perform actions.
- Resources are referenced entities or values.
- Actions are performed on resources.
If your systems are doing anything useful over time then that data describes the state of a system such that its transactive operations provide some utility and value. Data is the lifeblood of any system and nearly all other parts share that common interest.
A datum or data will always indicate whether a system is alive and can present and consume records of its lifetime. When we think of data in a computing systems context, what we commonly think of is a database. To this end, we will consider the following:
- Types of Databases
- Database transactions
- Distributed databases
- The relational model
- Schema Design
- Data Indexing
The short version, which is presented here, says that there are relational databases, and then the rest:
- Relational databases: Leverages the relational model and the Structured Query Language to define and manipulate data and schemas.
- Non-relational databases: Functionally, this means other data management paradigms beyond the relational model - document, key-value, object, graph, and wide column data stores.
- Small or flat databases: Single file datastores meant to emphasize portability or simplicity. File-based such as XML, JSON, CSV, or even SQLite.
Note: Python has rich support for any of these database approaches.
Note: 12-Factor App
Data stores become valuable when they facilitate and broker access across many requests and demands. Most interactions with a database can be expressed in terms of a transaction. Care is needed in managing transactions to ensure enduring intergrity of the underlying system. For this reason we can speak to the ability for a database system to handle transactions using the ACID acronym:
- Atomicity Requirement that transactions are applied as a unit such that they are either wholly successful, or not.
- Consistency Requirement that transactions are subject to constraints.
- Isolation Requirement that transactions are free from "dirty reads" and "lost updates" such that parallel transactions do not negatively impact each other.
- Durability Requirement that completed transactions are preserved, permanent, and free from transient interferance.
These are not magic, but rather what any decent database management system will provide. In the Relational World, we have popular Relational Database Management Systems (RDBMS) such as:
- Oracle
- MySQL
- MS SQL Server
- PostgreSQL
- SQLite
- Snowflake
When designing data, a schema is created/designed to express the topology of the semantic and physical aspects of data storage and management. More specifically, we are interested in identifying and grouping:
- fields - the name and type of a datum to be stored in a collection of data that describes a record.
- keys - values within the data that can be used to uniquely retrieve a record in the data store.
- relationships - mappings between keys that allow for the selection of sets of related records.
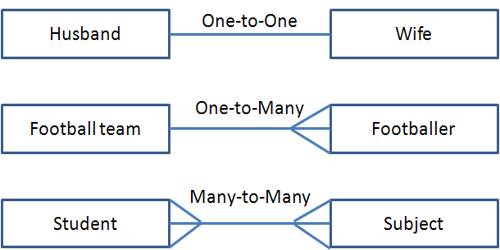
Once relationships are established, we can then speak of a number of types of relationships:
- one-to-one
- one-to-many
- many-to-many
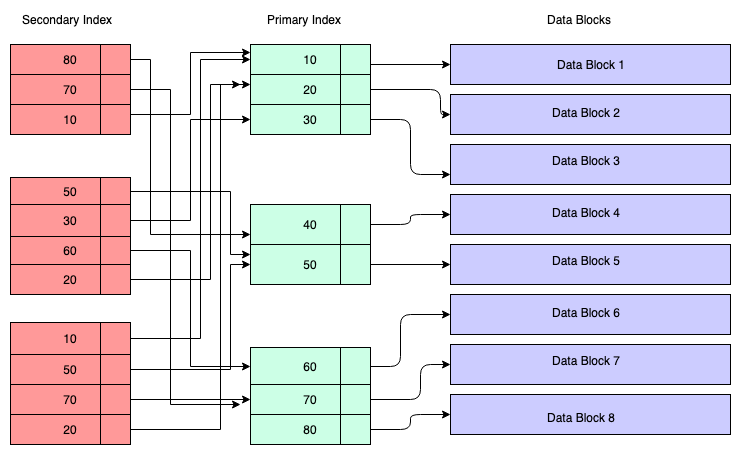
Schema design can be refined through processes of data normalization.

Once normalized, data can often be indexed to reduce search time.
Whereas we must attend to the implementation of data, for archictectural purposes, we often abstract data as mong the layers or tiers of our design. Therefore, we can conceive of an n-tiered, or multitiered architecture for the purposes of reasoning about a system's overall design:

The idea here isn't to get too hung up on tiers and layers beyond keeping in mind that abstractions are useful for the processes of designing and reasoning about a system.
We can look to Domain-Driven Design for useful vocabulary from which we can understand how to develop and use abstractions for architectural design.
A DDD approach suggests the importance of the abstractions of models and context. A Data Model abstracts data management to include state changes and the related business logic that governs state changes for the model. Of significant utility is to devel abstractions that separate applications and implementations. A DDD encourages that we name these abstractions as methods and attributes that are consistent with the underlying langauge of the domain - as we name it in reality, we should name it in the model.
DDD and Object-Oriented Programming (OOP) provide concepts that encourage designs that reflect the concepts intrinsic to a specific domain of practice. DDD encourages that we explore and define business-oriented interfaces to be included in our Model layer so we can abstract and present a consistent interface that represent the flow of business logic.
DDD serves as a reminder that intimate knowledge of the specific domain, and subject-matter expertise (SME) are required to specify meaningful interfaces. At its simplest expression, a Data Model simply replicates the database schema - a class or object is designed that replicates the fields and structure of the database. However, models can be more complex and provide an interface to multiple tables or fields to best reflect actual patterns of use within the domain.
Object-Relational Mapping (ORM) is the development of a system that transforms and translates from raw database access to in-memory/runtime objects that abstract raw access to the database. An ORM will provide mappings between the collections or tables in a database via the provision of related objects in an OOP environment.
While ORM desribes a technique, ORMs are usually tool/libraries (SQLAlchemy and the DjangoORM are good examples)convert from SQL to Python objects. From a codig standpoint, we replace SQL statements with methods called on the classes and objects that represent the underlying database schema.
Eventually, we rely on migrations to describe object model changes as schema changes, and vice versa.
Data modeling leads to our exploration of a few architectural patterns we will explore later:
- Unit of Work
- Command Query Responsibility Segregation
Representational State Transfer (REST) uses the HTTP protocol standards as a basis for a API communication protocol for applications. For a system to be considered RESTful, it must:
- Facilitate a Client-server architecture through remote calls made through HTTP.
- Be Stateless - such that information salient to a request should be self-contained within the request and independent.
- Be Cacheable - the availability of query or result caching should be clear.
- Be seamlessly layered - It is unimportant which layer of the system that requesting client is connected to as the results will always be the same.
- Provide Uniform interface - subject to a few key constraints:
- Resources are identified as a part of the requests.
- Resource manipulation is effected through representations that provide all of thee required information necessary to make changes to the state of the system.
- Self-documenting and internally-complete messages
- Hypermedia as the Engine of Application State (HATEOAS) - system navigation is complete via hyperlinks
With a RESTful API, we are typiclly creating a dictionary or look-up between HTTP methods (Verbs) and operations you are interested in on an entity within your application/project/system. Often, this facilitates the most basic of Create Read Update and Delete (aka CRUD) operations on entities within the system.
This is also a way to think of accessing the resources available within a system.
| Resource | Partial URI | HTTP Method | Description |
|---|---|---|---|
| Collection | /reports | GET | A list operation that returns all elements in the collection |
| POST | A list creation operation | ||
| Single Object | /report/1 | GET | Get a single element from the collection based on its unique id |
| PUT | Create a single object to be inserted into the collection | ||
| PATCH | An update operation that modifies some data in a record | ||
| DELETE | Delete an object from the collection using its unique id |
The entire point of a REST API is for the HTTP method to clarify the type of transaction you want from the system and for the URI to clarify which resource you are interested and/or to specify how you'd like to query for that resource.
In most cases, REST APIs will return JSON which gained prominence over earlier standards like XML. Either are fine and some of the earliest tools for REST interfaces were assumed to be working with XML.
Like many early networking and web protocols, HTTP is straightforward, simple, and pretty easy to grasp as it is not too large. Here are some excerpts of what would be actual HTTP payload information as clients and servers transact using the HTTP protocol.
The following examples presume we are working with an aviation weather API that provides coded and decoded aviation-related weather information.
NOTE: The list of possible media and content types that can be returned in an HTTP request can be found here through the Internet Assigned Numbers Authority.
GET
GET /reports/1
HTTP/1.1 200 OK
Content-Type: application/json
{"icao": "KAMA", "raw": "KAMA 221753Z 18011KT 10SM CLR 09/M01 A2990 RMK AO2 SLP119 T00941011 10100 21006 50004", "updated": "1826 UTC 22 Mon Jan 2024"}
GET with parameter
GET /reports/KAMA/raw
HTTP/1.1 200 OK
Content-Type: text/plain
KAMA 221753Z 18011KT 10SM CLR 09/M01 A2990 RMK AO2 SLP119 T00941011 10100 21006 50004
We can also use HTTP headers and Status Codes to assist in maintaining application state with respect to the provision and use of a RESTful API.
A resource-based view of your system is useful as it is prudent to consider that both state change and derived value come from viewing your system via the transactions it facilitates. As the a RESTful API, by virtue of leveraging HTTp is limited to CRUD operations, a resource-based view encourages a design where resources are the "lego bricks" for the API your system provides. Seeing everything as a resource helps to create very explicit APIs and helps with the stateless requirement for RESTful interfaces.
HTTP forces a stateless approach which ensures that all the information required to fulfill a request is initiated by the particulars of the call. What a RESTful API facilitates is the ability of two networked machines to coordinate by makings requests and providing responses. This has also been referred to in the past as Remote Procedure Calls. Being remote, there is both latency and a degree of resource marshalling that must occur to keep these available. Selecting something stateless, like HTTP, forces useful restrictions on API development which can be beneficial.
Here are some notes for RESTful design from Jaime Buelta:
The best way to start designing a RESTful API is to clearly state the resources and then describe them:
- Description: Description of the action
- Resource URI: Note that this may be shared for several actions, differentiated by the method (for example, GET to retrieve and DELETE to delete)
- Methods applicable: The HTTP method to use for the action defined in this endpoint
- (Only if relevant) Input body: The input body of the request
- Expected result in the body: Result
- Possible expected errors: Returning status codes depending on specific errors
- Description: Description of the action
- (Only if relevant) Input query parameters: Query parameters to add to the URI for extra functionality
- (Only if relevant) Relevant headers: Any supported header
- (Only if relevant) Returning status codes out of the ordinary (200 and 201): Different from errors, in case there's a status code that's considered a success but it's not the usual case; for example, a success returns a redirection
There are other items for consideration when developing RESTful APIs:
- Documentation: Tools such as OpenAPI and Swagger help to expose both your API and its documentation to facilitate use.
- Authentication: One of the drivers of big data is profit where access to API-driven information is ascribed a fee. Among many approaches to this is JSON Web Tokens.
- Versioning: You will also want to version your API so that you can distinguish fixes and features over time. Semantic Versioning is a common (and familiar) approach to this.
Keep in mind that our architecture and design, although commonly associated with the "backend" of an applicaiton ecosystem, can also apply to more client-facing "frontend" components of a system.
Perhaps this picture illustrates these concepts:

Understanding these broad aspects lends itself to our ability to our architectures in terms of layers and segments. The general structures that underlies our architectural reasoning lies in the ability to array concerns or focal points into patterns. We can sometimes understand brokering traffic between frontend and backend using the Model-View-Controller architecture pattern:
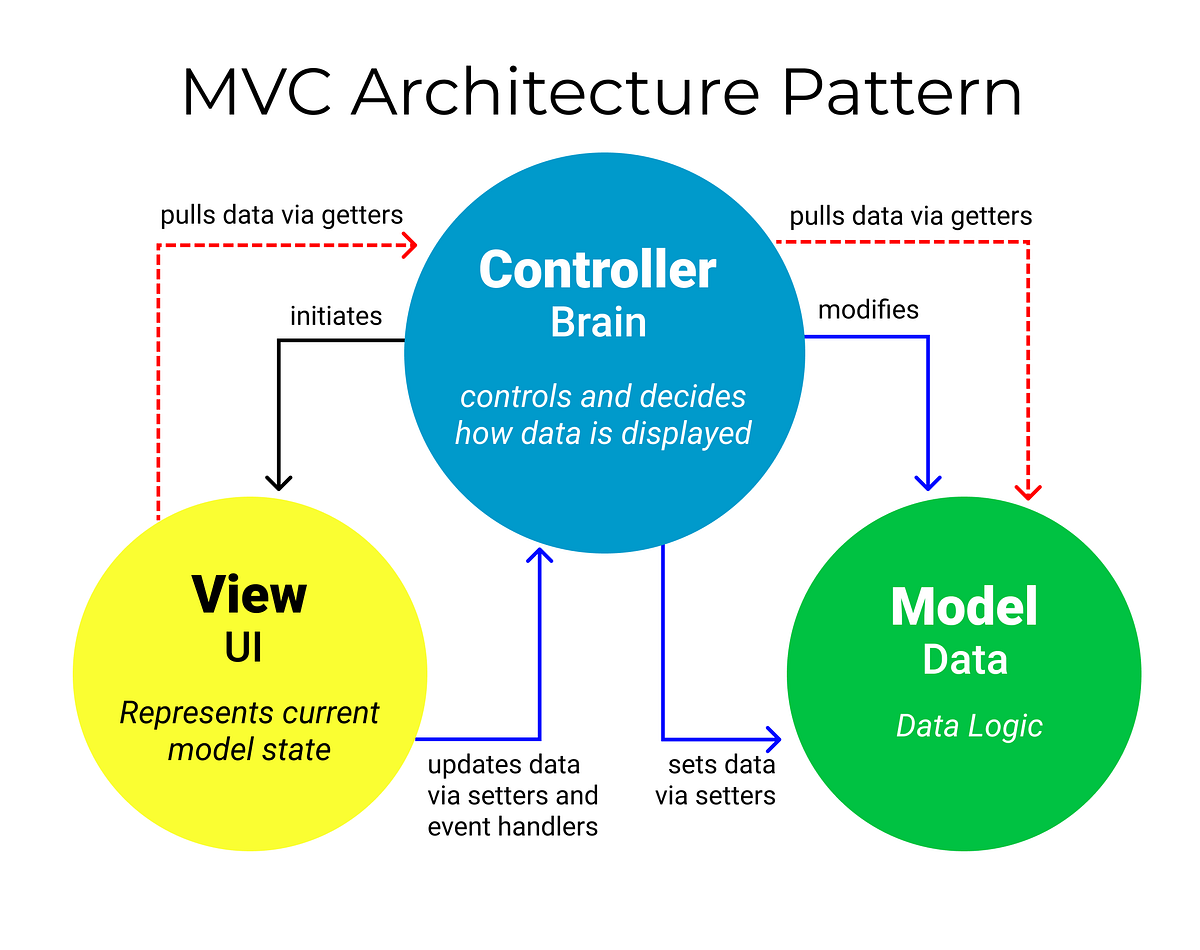
There are a number of visual models we'll want to become familiar with as a tool for expressing various aspects of a system. The diagrams should ultimately contribute to the code artifacts we produce to facilitate the system's effectiveness. With that said, these models are themselves artifacts of design; their purpose is to facilitate understanding that leads to an information systems artifact.
Credit to Scott Ambler.
| Diagram | Description | Link |
|---|---|---|
| Activity Diagram | Depicts high-level business processes, including data flow, or to model the logic of complex logic within a system. | Activity Diagram Guidelines |
| Class Diagram | Shows a collection of static model elements such as classes and types, their contents, and their relationships. | Class Diagram Guidelines |
| Sequence Diagram | Models the sequential logic, in effect the time ordering of messages between classifiers. | Sequence Diagram Guidelines |
| Component Diagram | Depicts the components that compose an application, system, or enterprise. The components, their interrelationships, interactions, and their public interfaces are depicted. | Component Diagram Guidelines |
| Deployment Diagram | Shows the execution architecture of systems. This includes nodes, either hardware or software execution environments, as well as the middleware connecting them. | Deployment Diagram Guidelines |
| State Machine Diagram | Describes the states an object or interaction may be in, as well as the transitions between states. Formerly referred to as a state diagram, state chart diagram, or a state-transition diagram. | State Machine Diagram Guidelines |
| Use Case Diagram | Shows use cases, actors, and their interrelationships. | Use Case Diagram Guidelines |
Here are some additional notes about using the UML.
What's is the difference between include and extend in use case diagram?
Here’s an approach checked against Jacobson, Fowler, Larmen and 10 other references.
Relationships are dependencies The key to Include and extend use case relationships is to realize that, common with the rest of UML, the dotted arrow between use cases is a dependency relationship. I’ll use the terms ‘base’, ‘included’ and ‘extending’ to refer to the use case roles.
include A base use case is dependent on the included use case(s); without it/them the base use case is incomplete as the included use case(s) represent sub-sequences of the interaction that may happen always OR sometimes. (This is contrary to a popular misconception about this, what your use case suggests always happens in the main scenario and sometimes happens in alternate flows simply depends on what you choose as your main scenario; use cases can easily be restructured to represent a different flow as the main scenario and this should not matter).
In the best practice of one way dependency the base use case knows about (and refers to) the included use case, but the included use case shouldn’t ‘know’ about the base use case. This is why included use cases can be: a) base use cases in their own right and b) shared by a number of base use cases.
extend The extending use case is dependent on the base use case; it literally extends the behavior described by the base use case. The base use case should be a fully functional use case in its own right (‘include’s included of course) without the extending use case’s additional functionality.
Extending use cases can be used in several situations:
The base use case represents the “must have” functionality of a project while the extending use case represents optional (should/could/want) behavior. This is where the term optional is relevant – optional whether to build/deliver rather than optional whether it sometimes runs as part of the base use case sequence. In phase 1 you can deliver the base use case which meets the requirements at that point, and phase 2 will add additional functionality described by the extending use case. This can contain sequences that are always or sometimes performed after phase 2 is delivered (again contrary to popular misconception). It can be used to extract out subsequences of the base use case, especially when they represent ‘exceptional’ complex behavior with its own alternative flows. One important aspect to consider is that the extending use case can ‘insert’ behavior in several places in the base use case’s flow, not just in a single place as an included use case does. For this reason, it is highly unlikely that an extending use case will be suitable to extend more than one base use case.
As to dependency, the extending use case is dependent on the base use case and is again a one-way dependency, i.e. the base use case doesn’t need any reference to the extending use case in the sequence. That doesn’t mean you can’t demonstrate the extension points or add a x-ref to the extending use case elsewhere in the template, but the base use case must be able to work without the extending use case.
SUMMARY I hope I’ve shown that the common misconception of “includes are always, extends are sometimes” is either wrong or at best simplistic. This version actually makes more sense if you consider all the issues about the directionality of the arrows the misconception presents – in the correct model it’s just dependency and doesn’t potentially change if you refactor the use case contents.
Software architecture will have a fleeting definitive expression as it bridges organizational, aesthetic, and technical realms. As such, software achitecture focuses and intersects a number of abilities within those who will design. Thus, we can characterize software architecture in what it will "attend to." I like Richards and Ford's model:
software architecture consists of the structure of a system, the design intensions the system must support, architecture-influenced design decisions, and design principles.

Like "Engineering", claiming to be an architect, or to develop architecture, is subjective despite the degree to which both the engineering and architecture disciplines and professionals have tried to protect these.
Therefore, it would be most useful to understand these:
- What is the difference between achitecture and design?
- How to maintain technical depth and breadth.
- How to recognize and evaluate design tradeoffs inherent in solution technologies and patterns.
- Understand how the business and problem domains drive architectural decisions.
I like Richards and Ford's Technical depth and breadth model here:

While a foundational grasp of both Object-Oriented Programming and the Unified Modeling Language are ideal pre-requisites, there are pragmatic ways of understanding Modularity in software and systems development.
- A module:
a set of standardized parts from which a more complex structure can be crafted - Modularity:
A logical grouping of related code - often classes - designed for effective reuse - package, module, or namespace
Aspects of measuring and identifyin modularity follow:
- Cohesion:
To what extent part of a module are naturally bound (thematically, funtionally) and thus belong together.We can reconcile with cohesion by considering whether that cohesion is functional, sequential, communicative, procedural, temporal, or logical. - Coupling:
Degree to which items are connected such that both are commonly involved at the same time, within the same sequence, or within the same logical dependence.We can reconcile with coupling by considering whether modules are related through abstractions, call distance, or instability of implementation. - Connascense: This is a more acute coupling where
items within a module are coupled when changes in one module require changes in another - they are codependent.
Modularity is a necessary part of architectural design.
Since all software systems solutions will involve both domain requirements and architectural characteristics, an understanding of architectual charactistics will be useful here.
An architectural characteristics can be understood as classified in more or more of the following:
- Specifies a nondomain design consideration/need.
- Incluences or supports necessary design structures.
- Is critical to application success.
Richards and Ford have a nice model of this:

Again Richards and Ford provide some nice examples:
Operational Architecture Characteristics
| Characteristic | Definition |
|---|---|
| Availability | "Uptime" |
| Continuity | "Risk management and disaster recovery" |
| Performance | "Resilience, horsepower, abundance " |
| Recoverability | "Restoration after disaster" |
| Reliability | "Connected to availability" |
| Robustness | "Continuity during error and boundary conditions" |
| Scalability | "Factors of 10" |
Sturctural Architecture Characteristics
| Characteristic | Definition |
|---|---|
| Configurability | "Built to accommodate options and customization" |
| Extensibility | "Add to function by plugging in new capabilities" |
| Deployability | "Where can this be operated from?" |
| Reusability | "Can this solution be used in other contexts?" |
| Localizable | "Can this solution support location and context?" |
| Maintainability | "Cost in time and skill" |
| Portability | "Can we migrate to new operating environments?" |
| Supportability | "What is the extend of support needs" |
| Upgradeability | "Backwards compatibility" |
Other Architecture Characteristics
| Characteristic | Definition |
|---|---|
| Accessibility | "Compliant with provisions to broadly support a variety of users." |
| Archivability | "What data needs to be retained and for how long" |
| Authentication | "You are who you say you are" |
| Authorization | "You can use this, but now that" |
| Legal | "Stay within the lines of what is permitted" |
| Privacy | "Visibility and control over that visibility" |
| Security | "CIA" |
| Exertise/Skill | "Expected user skill level required." |
See also: the ISO25010 standards on Software Product Quality
A design pattern is a shortcut that builds on prior knowledge gained from trial and error that culminates in common approaches to common needs and issues that arise in the design of a system. I am borrowing from a few inputs here to develop an amalgam of patterns and approaches:
- The Twelve-Factor App
- Web Application Architectures
- Event-Driven Architectures
- Command-Query Responsibility Separation
- Scope and Structures in Microservices and Monoliths
The Twelve-Factor App is an methodology to facilitate that software is commonly delivered as a service. The 12-factor approach emphasizes:
- Delarative configurations that encourage the use of automation.
- Configuration that ensures a clean contract with the underlying operating system for portability between execution environments.
- Oriented towards deployment on cloud platforms to minimize servers and systems administration.
- Minimize divergence between development and production environments continuous deployment.
- Facilitataes scaling without significant changes to tooling, architecture, or development practices
The twelve-factor methodology is a design patterns as it stems from solutions to common and systemic in application development. The twelve-factor methodology provides a vocabulary and lexicon that conceptualizes common problems and solutions. The ideas in the twelve-factor methodology are inspired by Martin Fowler’s books:


| Factor | Concept |
|---|---|
| 1. Code base: One codebase tracked in revision control, many deploys. | 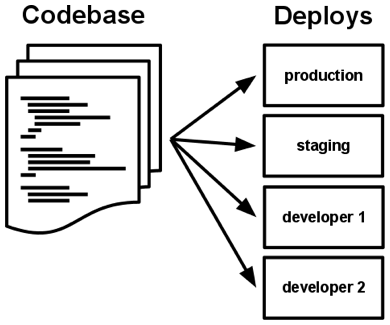 |
| 2. Dependencies: Explicitly declare and isolate dependencies. | |
| 3. Config: Store config in the environment. | |
| 4. Backing services: Treat backing services as attached resources. | 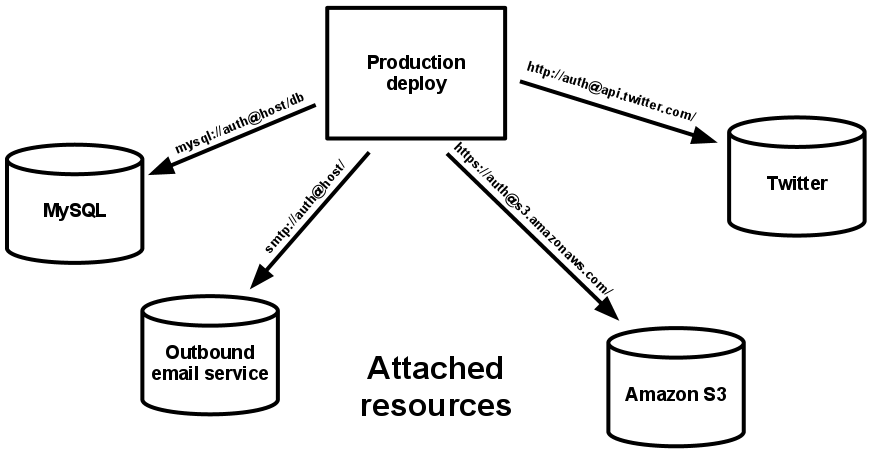 |
| 5. Build, release, run: Differentiate between build and run states. | 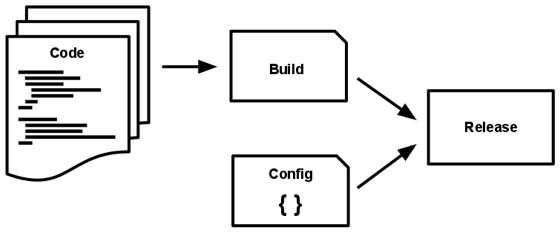 |
| 6. Processes: Execute the app as one or more stateless processes. | |
| 7. Port binding: Export services via port binding. | |
| 8. Concurrency: Scale out via the process model. | 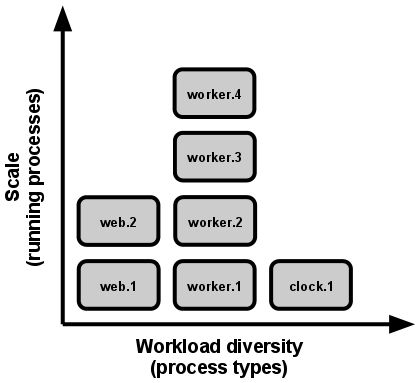 |
| 9. Disposability: Maximize robustness with fast startup and graceful shutdown. | |
| 10. Dev/prod parity: Keep development, staging, and production as similar as possible. | |
| 11. Logs: Treat logs as event streams. | |
| 12. Admin processes: Run admin/management tasks as one-off processes. |
Continuous Integration (CI) features compulsory automated testing when code is committed to a central repository. The objective CI is to ensure that only working code makes it to production. This is an empirical approach that favors feedback to minimize errors and increase the speed of delivery. Automated testing is designed to produce quality code by relying on quality tests which emphasizes the need for test quality.
CI systems will run tests automatically upon either detecting changes or by being triggered by other workflow automation. Test area comprehensive and may be time consuming depending on the size and scope of a project. Commonly, tests are run when new changes in the code base are detected. Git, and GitHub or GitLab, provide "hooks" to assist in controlling test automation. We learn how to use GitHub Actions for to create conditional or event-driven CI actions. It is common to refer to the process of CI in terms of a "pipeline," or a series of treatments and tests run in the interest of implementing CI.
A pipeline may look like this:
- A project workspace is configured to work with CI automation - usually 3rd party libraries and configuration files.
- Explicit build commands are executed to prepare the code for further use.
- Static Code Analysis (linters) tools like flake8 or black are used for linting and code style conformity.
- Unit tests run and the pipeline stops on errors.
- If unit tests pass, downstream integration tests can be run as well.
All CI pipelines presume some, or total, automation: all stetps in the pipeline are designed to be run without monitoring or assistance. Thus, dependencies must also be a part of the CI configuration. It is also common to include virtual machines as a part of the automation to ensure testing environment that mirrors the expected operating environment.

Application systems ideally behave consistently under a range of demand loads. This is a system behavior that is designed automatically increase resources to accommodate more demand. This can be achieved using two main approaches:
- Vertical scalability: Increase resources at each system node.
- Horizontal scalability: Increase the number of system nodes at the same resource level.

The Twelve-Factor App encourages the view that both code and configuration are vital assets to be managed equally. This is manifest in the concept of Configuration as Code.
The concept of configuration and code being equal assets is readily visible in the widespread use of virtual machines and app containers, where both exists to ensure a stable and known execution environment. Configurations are the set of parameters used to indicate the settings and behaviors required for the system to support the application's execution:
Here is a way to think of these configuration parameters:
- Operational configuration: These parameters connect different parts of the system or that are related to monitoring:
- credentials for the database
- service URLs
- Log and system settings
- Feature configuration: These parameters change external behavior, enable features or change the behaviors of the system:
- UI settings
- Enabled app behaviors
- Defining constants or macros
Operational configurations are typically concerned with deploying and running your app/system and often help distinguish between a local development environment and a production environment.
Like code, operational configurations usually stored in files and organized by the referenced target environment. This also means that configuration changes are code changes. There are issues with this approach in the case of horizontal scaling where threats related to duplication and misalignment may occur between resources nodes.
In general, the Twelve-Factor App suggests using Environment Variables as a result.
We can group the 12-factor practices to better understand their practical implementations:
- Portability: Code base, Build, release, run, and Dev/prod parity.
- Git and GitHub/GitHub Actions
- VMs, VPSs, Containers
- PaaS, IaaS, SaaS
- Service configuration and connectivity: Config, Dependencies, Port binding, and Backing services
- Favor the use of Environment Variables and similar strategies (dot env)
- Map services to TCP/IP ports
- scalability: Processes, Disposability, and Concurrency
- Processes represent conceptual/semantic areas of responsibility
- Work with operating system-level features to manage processes (Windows/Linux)
- monitoring: Logs and Admin processes
- Metrics and loggin as key health, security, and performance tools
- major state changes
- Reporting
The 12-factor can be restarted, within the groups above, as supporting the following principles:
- Build once, run multiple times - Generating a single application package that runs in many environments.
- Dependencies and configuration - Manage configuration, software and service dependencies of the application as an equal resource.
- Scalability - Strategies to facilitate scalability.
- Monitoring and admin - Manage the operation of the software and system.
It is almost redundant to speak of application architecures and then speak of the architecture of Web/HTTP server architectures as the Web is the primary application/protocol delivery "stack." As any distributed system architecture will require remote access, Web services based on HTTP are ubiquitous and will be our sole focus.
Our principle points of study will be:
- The structure of HTTP servers
- The HTTP request-response paradigm
- three-layer application design:
- web server - HTTP
- worker processes - Work that you design, independent of HTTP
- service layers that direct worker processes and interact with the web server - and Application server to coordinate between HTTP and your worker processes.
Example with Django:
- HTTP Server: nginx
- Application Service Layer: uWSGI
- Worker Specification and Web Application Framework: Django
- Data-only API Web Application Framework: Django REST framework
In general, request–response or request–reply is a basic method that computers use to communicate with each other over a network: machine A sends a request for some data and machine B responds to the request. This is duplex messaging pattern which allows two applications to have a two-way conversation with one another over a channel and is especially common in client–server architectures.

The request-response pattern is often implemented synchronously such as in our use case of interest where a web service calls over HTTP, which holds a connection open and waits until the response is delivered or the timeout period expires. Request–response may also be implemented asynchronously where a response can be received later. Even with synchronous communication, there is communications latency within the request and response cycle endemic to the nature of sending and processing electro-magnetic energy. When communications occur within the machine, latency can be measured in a few milliseconds. However over internetworked communications, latency can be measured in hundreds of milliseconds, or worse. These variations in time are a key component of how the HTTP, TCP, and IP protocols work together.
In implementation, most requests are made synchronously such that process execution halts and waits for a response. The latency involved in waiting requires error handling that needs to consider different failure cases and provisions to reattempt the communication.
The request-response is a call and response pattern where the responder does not contact the caller proactively. This simplification suggests that such communications are not truley Duplex, but effectively so. In the request-response pattern, the client is required to initiate the request where the server's role is to listen to and respond to these requests. Again, a basic request-response communication is not fully bidirectional communication. The server polls to check whether there are new messages. Despite its drawbacks, the request-response architecture forms the basis of web services.
This is easier to comprehend if we borrow from the Mozilla Developer Network's documentation on HTTP messages.
In the image below, we see the major components of how the Hypertext Transfer Protocol works:

Using packet sniffers such as wireshark, the payload of these messages can be examined as the protocol works with very simple plaintext messages:


- The client sends the HTTP a message containing a
request line:- An HTTP Method is stated
- A
request targetis specified: a URL, or the absolute path of the protocol, port, and domain - Specification of the HTTP Version
- The Client clarifies the request using HTTP Headers. Generally, the types of specifications communicated in the header are:
- Body - only some requests have bodies, depending on the nature of the HTTP request. There are typically two categories of bodies:
- Single-resource -
Content-TypeorContent-Length - Multi-resources - HTML Forms are a good example.
- Single-resource -

- The server responds to an HTTP message starting with a
status lineProtocol version- HTTP Response Status Code - these can be key in denoting state when HTTP is coopted to develop an API.
Status textwhich is an informational and informal addendum to the status code.
- The response also uses headers, which nearly identical in form and purpose to request headers.
- The
response bodyforms the essence of the request-response chain as the answer contains the "value" of the transaction. Again we have a few categories for the response body:- Single-resource bodies:
Content-TypeandContent-Length - Single-resource bodies with follow-on data: consists of a single file of unknown length, encoded by chunks with
Transfer-Encodingset tochunked. - Multiple-resource bodies: a multipart body with each part containing a different section of information.
- Single-resource bodies:
A common free and open source software-driven web application architecture will conceptually look like this:

We can see the following elements:
- Web Server
- Web Application Server
- Application Server (Workers)
- Database

We'll focus on nginx, uWSGI, and Django as working examples.

Using a separate example, we'll see Django and the Django Rest Framework used to illustrate a full web application architecture. In general, we'll leverage Django, the DRF, and any WSGI app container to perform key communication and data handling aspects of our archictures. This will leave the matter of work and workers to our own design.

We could then use containers and other load balancing strategies to scale our application.
Our journey through patterns becomes a bit more abstract here as we examine ways to structure our modeling of data, our work and workers, and our methods for communicating within and without our software system. We will proceed with the following subjects:
- Event-Driven Architectures
- Streams, Pipelines, and Busses
- Command-Query Responsibility Separation
- Scope and Structures of Microservices and Monoliths
Whereas Request-Response implies synchronous communication, some communications are notifications where responses may not be immediate. We refer to these sorts of messages as events: which are commonly asynchronous background tasks where the resulting work, and notification of its completion, is not blocking.
Asynchronous tasks are typically handled in a messaging or queueing system. A variation of such a system is a scheduled task system that executes on an interval.
In the Django and Python contextss, Celery serves as a distributed task queue and manager. There are other event and messaging patterns to explore, including the following topics and concepts:
An event-driven architecture facilitates an unsupervised or managed communication approach where data is sent without the expectation of an immediate response. This is in contract to Request-Response which waits and blocks for a response. In an event-driven pattern, an event is a signal for a request where the sender does not wait for a response. An event-driven system will often return a unique ID which provides a means of querying for event results at a later time for any follow-up tasks.
Events act as a notification signal which will commonly travel within elements of the system in a transmission towards a final destination. The underlying concept is that of the message bus and works to forward messages that flow through the system. A message bus architecture acts as a central exchange to manage messages across a system - internally and externally. It is common to rely on a single bus for communicatition within all subsystems of your own applicaiton architecture and as a means of contacting external systems. The message bus that carries events through the system can be thought of as a event queue. A queue is a FIFO data structure that is used to seqeuence the events.

Clients subscribing to the message bus listen to the event queue and extract relevant events. Any client on the message bus doesn't communicate directly with the sender of the event but can react and respond back into the message bus. Processes that put and pull into and from the event bus are called the publisher and the subscriber. Systems that provides a message bus RabbitMQ, Redis, and Apache Kafka.
Events are important empirical evidence and are often the basis of logged information that is typical for instrumentation and monitoring. Such events contain metadata and information about error conditions. In these cases, such error events are typically non-blocking where the system or application continues after the error. It is also possible to capture more than just error conditions where other aspects of performance and instrumentation are needed and can be captured in an event for later querying, aggregation, and reporting. Commonly called logs and metrics these events often simply textual representations generated according to some business logic.
These logging and metric events provide a picture of the health of running systems and provides inputs to instrumentation for control or alerting according to set criteria. For instance, we may be interested in receiving an alert if number of logged exceeds a threshold.

It is also possible to use event monitoring to throttle or achieve throughput quotas or limits.

An event pipeline introduces the concepts of an event/messaging bus extending communication with other systems. Events that cascade forward to multiple systems can be part of a larger process design (an architecture). These are often triggered and can be seen in CI/CD pipelines.

We can consider how a video service like Youtube provides this sort of triggered processing when a video is rescaled as it is uploaded. Youtube will commonly (and automatically) converted the video into different versions - commonly to accommodate different resolutions. The same process could be called upon to generate the thumbnail for the uploaded video.
The steps could included:
- A queue that receives an upload triggered event to start the processing.
- A queues to process rescaling
- A queue to generate the thumbnail
- Coordination with external storage such as AWS S3.

A message queueing system can also be referred to as a bus (or message bus). Commonly associated with electrical systems, a bus describes communication channels that transmit data between different hardware components components. Semantically, we describe a centralization of multisource and multidestination communications. As such, in software, a bus is a generalization that allows for the interconnect of several logical components.
We entrust a bus architecture to order communication within the system where a message sender doesn't need to know much other than what to transmit and which queue to send the message to. The bus handles intermediary routing. This is similar to postal and parcel post systems.
The bus can also act as a message broker which can both customize, decouple, and generalize inter- and intra-systems communication and services. Most packages that provide message bus services are commonly called message brokers - a prime example being redis (However, a system like redis will do more than message brokering). Apache kafka can work this way as well and many of these systems also create additional facilities to develop a publication/subscription approach.
Commonly a message broker/bus serve as a central communication hub where all the event-related communication is sent directed to. While this creates a single poit of failure, it is also convenient. Most Django examples that show using celery for task scheduling also commonly show the use of redis.

A publisher/subscriber model can be thought of a being a bit more tailored in terms of routing and notification over a simple message broker/queueing system:
Message Queue (AWS)

PubSub (AWS)

A message bussing/brokering approach allows for the architecting of higher complexity where events will filter through multiple intermediary stages in much the same manner that plugin or middleware systems can work fromo the same queue. Django's middleware system works in this manner.

Complex systems can utilize the message bus to feed alerting messages back into the system based on how those messages are comprehended by other subsystems.

An event-driven messaging system distributes work between several functional components or modules within the system. The components can independently respond to, and send, messages into the queue can are modularly interchangeable without impacting customer-facing front end systems. Such systems assume that some degree of consistent formatting and structure will be developed for internal messages.
Such a message structure could be expressed as XML, YAML, JSON, or other similar data structuring approaches. Here is an example in JSON:
{
"type": "FUEL",
"data": {
"from": "KLAX",
"to": "KIAD",
"req_date": 2024-03-01,
"buffer_date": null
}
}
In the given example, the type field identifies the event type such that a system scanning this event could determine if it was relevant. In an airline context, a FUEL event may be ignored by a crew scheduling module, whereas a CREW event might garner notice.
Whereas this discussion has promoted the flexibility of event-driven systems, this flexibility makes software testing more challenging.
We have learned that unit tests are simple and directly connected to where the system directly creates value. However, a distributed event-driven system makes it hard to use unit tests alone to test the the event detection and handling. It is not the case that these are difficult to fake, but rahter whether, in the "wild," whether we ensure that an event has been generated.
This is where the use of both Integration and End-to-End System tests help.
There is a variety of nomenclature and perspective on automated testing types (unit tests, integration tests, system tests, acceptance tests, etc.). It may be useful to distinguish that, while we can fake/mock data in unit tests, we want to test actual behaviors when using integration tests. Because they are isolated from dependencies, unit tests "affordable" and can be deployed to fully cover all functions within a module.
Often, what an integration test seeks to achieve is to check for an optimum, or a happy path scenario. In the case of integration testing, real loads must be present so that that business logic trigger generate real alerts encountered under system stress. For these reasons it is common to aim for a high ratio of unit to integration tests.
In a distributed event-driven system, it might be the case that data stores may distributed. Often each module data stores and external calls. In these cases an architectural pattern such as the Command and Query Responsibility Segregation (CQRS) may become necessary to create additional order to the messaging queue as relate to system state. This approach holds that read and write messages are handled independently as writing new data requires the generation of events which are then considered independently of the requests. This suggest that a common data model that spans modules may become a part of the message brokering system; multiple modules may contribute to the shaping of information stored in the model. Using an airline example, a query in the crewing system may require some informtion from the fleet system such that a valid response can only be developed by querying both the crew scheduling module and fleet scheduling modules. However, the response may be related to an original query/command relevant to a model in the crew scheduling module.
In such cases, frequently accessed information may become duplicated to facilitate quicker query response. However, these data redundancies will still consume additional processing to keep their facts reconciled. We will soon covered the SOLID principles and undersanding how this degree of "denormalization" breaks the [Single Responsibility Principle]. In this case, systems architecture is about making design choices where the choice in this case is to optimized on query complexity over data reconciliation complexity. The processing of designing and dividing responsibility within the system is the essence of Software Architecture.
A dichotomy has arisen in softwre engineering and architecture where questions related to cohesion, coupling, distribution, and modularization are manifest in the "Microservices" vs. "Monolith" continuum.

Amazon has this to say:
A monolithic architecture is a traditional software development model that uses one code base to perform multiple business functions. All the software components in a monolithic system are interdependent due to the data exchange mechanisms within the system. It’s restrictive and time-consuming to modify monolithic architecture as small changes impact large areas of the code base. In contrast, microservices are an architectural approach that composes software into small independent components or services. Each service performs a single function and communicates with other services through a well-defined interface. Because they run independently, you can update, modify, deploy, or scale each service as required.
A system is often thought as an integral whole such that most designs capture and express the whole of the system. This is a logical and natural way to "see" the software system as its design is often incrementally realized in small and simple design explorations. Over time, both through use, reflection, and refactoring, the design (and understanding) of a system grows. This growth includes additional features, evolved/modified features, and deprecate features. As original design concepts are often unitary, it is common to keep adding to the same code and design structure. Modulary, when it is introduced, and with some exceptionsl, is frequently a post hoc rationalization of how code maintenance could be improved. Even with modularization, these modules are often designed to remain within the system's boundaries. Aspects of the design of Django are akin to a monolith, but that is not entirely the case either (which will create the argument in favor of balance)

Conceptually, the "monolith" assumes both code and functionality are tied together in a single "monolithic" architecture. The "monolith" is a common where each has a good degree of internal modularity and structure. In this sense, the "monolith" is a slight misnomer as such systems are commonly divided logically into different logical component parts and modules with distributed responsibilities.
As we have examined earlier, Django is built on a variant of the MVC architecture, which is often expressed as a monolithic architecture. In the MVC pattern, Models, Views, and Controllers are designed to run within the same process, where it is the structures within that process that specify and differentiate responsibilities and functions within the pattern.

In this regard, it is important to be fair and keep in mind that a monolithic architecture does not construe the absence of structures and patterns. Rather, the key characteristic of a monolith module intercommunicaiton happens via internal APIs using the same overall execution process. There is significant flexibility in this approach where deployment is easier given the expectation of a common execution process. As a result, most web application frameworks - Ruby on Rails (Ruby), Django (Python), ASP.NET Core (C#), Spring (Java), Laravel (PHP) - have design cues and assumptions that are closer to a monolithic design. This is not to say that these frameworks are not vastly extensible and configurable, often containing impressive capabilities to leverage extensive internal and third party frameworks. In each case, the application framework can be updated simply by restarting the main host (often HTTP-driven) services. Nearly all of these systems do not co-locate the data access layer as an internal dependency.
In the case of a web application framework, a monolithic application can run across multiple and cooperative instances of the same sytem. A monolithic web application would commonly run multiple instances of the same software running in parallel to achieve load balancing to better distribute higher reqeuest loads. Even in the case of a restart, each instance can return to a known state in a relatively straightforward manner.
These monolithic architectures are simpler to manage as all code resides within the same structure and in the same code management repository. In nearly all cases, web application monoliths provide a means for the developers and designers to extend the framework as a part of the application effort.
A microservices architecture is an alternative the single block and extends patterns of reuse and modularity within the monolith such that modules and components do not commonly share the same execution context. The major attraction of microservices architecture is its foundation on the use of very loosely coupled and distributed services that work in together as a comprehensive service.
There are some key concepts in this definition that may not be immediately distint from the monolith and require further elaboration.
- The collection of services are well-defined modules that are commonly deployed in separate execution contexts - what is particularly common is to use PaaS/IaaS services such as Amazon and Azure to run these.
- The services are loosely coupled so each microservice can be independently deployed and developed.
- The services in a microservice architecture are expected to be later orchestrated so that they work in unison.
- A collective and comprehensive service then exists such that the whole system is created from these distributed parts.
As opposed to the monolith microservices do not suppose running under the same process, and rather use uses multiple and separate modules (microservices) that cooperate well-defined APIs. The interoperabilty achieved relies on standardization and an ability to swap component implementation and deployment with ease to allow system scaling.

In a microservice architecture calls between different services are brokered through external APIs. These APIs serve as identifiable boundaries between functionalities. A microservices architecture heavily assumes the use of cloud services and advanced planning, advanced knowledge of how to configure and operate these cloud services, and requires careful planning to coordinate components. This mandates upfront design to ensure that the modules will align and connect. The microservices architecture is the tool commonly utilized when high and distributed loads are expected where the "brittle" nature of the monolith is infeasible. This makes for careful upfront planning as opposed to the more organic nature of the growth and evolution behind most monoliths. The microservices architecture a common end state for that migrate from from extant and mature monolithic architecture.
Regardless of being an advanced system architecture the microservices architecture is not necessarily better than the monolithic approach as each has merits and demerits:
- Most applications will start as monolithic.
- Microservices require careful planning and prior experience.
- There are no silver bullets and no design is future-proof.
- The proper balance is a constant challenge and art.
- Mature monoliths often suffer from unpaid technical and design debt
- Refactoring to manage complexity and technical debt is its own art \
- The redevelopent of clear and strict boundaries can often be accomplished by extracting out of the monolith
- Microservices encourages flavor-the-month and look-squirrel technical innovation tail chasing (although all innovations typically have their own merit)
A reasonable justification for microservices lies within the fact that their modularization may accommodate different domain-specific knowledge such that expertise can concentrate on a component in isolation. The modules themselves can now evolve organically where they only have to respect clear communication expectaions into and out of the module. However, code standards, programming languages choice, technology stack selection, and deployment can be tailored for the nature of the task.
Monoliths can also be a bit heavy on resources as the execution context is combined. The system resources to run the monoligth will often assume worst-case and high-load scenarios, which is only compounded as more instances are run in parallel.
Microservices are, by contrast, able to require a minimally feasible footprint where high-demand and worst-case scenarios can evolved and their own pace.
Deployment works differently between monoliths and microservices. Monolithic applications may need more resources, but are somewhat easier to managed in a CI/CD pipeline that includes extensive testing. Monoliths often have more tightly coupled modules where the teams maintaining them work closely together.
By contrast microservices can be indenpdently deployed assuming that the APIs that connect each service is stable. With clear system boundaries microservices are very isolated from the failure of other modules and can be deployed independently.
Also, whereas monolithic applications communicate with other modules through internal operations, there is an overhead related microservices' realiance on external APIs and communicationCareful consideration presents a fair bit of overhead.
It is common to deploy to a VPS using an operating system such as Linux. Once set up, we would then install our required languages and platforms (such as.NET, Python, or PHP) and required services such as nginx, gunicorn. Once deployed, these technologies work together and the VPS needs to be managed by you.
A VPS is still hosted on a physical via the use of virtual machines where a physical server hosts multiple VMs. There are many approaches to assist with VPS/VM management where some help with configuration (Chef or Puppet) to help manage multiple servers with coordinated and correct dependency versions.
Another approach is to use containers. Containers extend the VPS/VM concept but are even more specific to just a single application's dependencies. Each container will establish its own filesystem that houses the Operating System, service dependencies, platform packages, and source code. Containers combine all needed elements to support a single application in a self-containing manner. This allows for the host machine to simply supply compute, disk, and memory capabilities to run the container. As with VMs and VPS', many containers can run on the same physical machine where each container's environment is idependent.
Docker (https://www.docker.com/) is a common and ubiquitous example of a container platform.
The following graphic shows how to distinguish between a VM and a container.

There are a few tutorials that cover the "containerization" of a Django project:
At some point, once you are running multiple containers, you will look for a tool to assist with th is and that process is known as orchestration. Since a containerization approach is very common when opting for a microservices approach, the management of these containers also assists in the process of ensuring that these microservices can communicate across or within a container. In orchestration, it is common for microservces to discover containers, dependencies, and redundancies.
As with Docker, the most commmon orchestration tools are docker-compose and [Kubernetes].
docker-compose comes with Docker and is considered effective for small deployments and/or local development. As with most orchestration tools, docker-compose relies on a YAML to specify services and requirements which drives the docker build and run processes.
Kubernetes is common for larger and more complex projects and container clusters. K8s allows you to specify a full logical and abstract layout for containers and needed infrastructure.Kubernetes describes resources as nodes where the set of nodes specifies the container cluster. K8s will manage each node and connect nodes within a virtual network. All details are abstracted by k8s and are not managed by the deployed microservices. A K8s cluster defines the following logical layer elements:
- Pod: A Pod is a group of containers that run together as a unit. At a minimu, a pods consists of a single container. The pod is the basic management unit in Kubernetes.
- Deployment: A deployment is a collection of Pods. The Deployment defines the number of needed replicas to create the required Pods. Each Pod within a deployment can exist in different nodes.
- Service: Metadata used identify common routing to Pods and acts as a unique name for discovery much as how DNS works. A shared service name allows Pods to find the correct destination for requests. Requests are often load-balanced.
- Ingress: Used to define external access to a service. This maps incoming DNS requests to a service. Ingresses is used to provide external access to a pod. External requests are routed through Ingress and are subsequently directed to a Service, and any corresponding pods.
Application and systems architectures must lead to implementation, which is never fully removed from design.
An implemented architecture is an empirical test that will both support and validate smaller design decisions. Code structures and development approaches are just as much a part of a successful design.
We focus briefly on a few implementation issues for the purposes of establishing definitions of done and valid acceptance criteria to appraise when an implemented architecture is effective. This entails activities to ensure correctness through testing approaches like Test-Driven Design (TDD) and Behavior-Driven Design (BDD).
Additional topics include modularity and resuse, which are well supported in Python as modules and packages. We cab design, create, and maintain Python modules and upload them to PyPI even if we design them to interoperate with Django.
Mike Tyson on plans and designs...

To err is to be human and to write code that misses the mark is normal. This is true no matter how much code you use Co-pilot and ChatGPT to write for you. However, if this fact is accepted, then as with a Co-pilot, we can develop "checklists" in the form of tests that we run to validate and verify the assumptions and outputs of the code we write. Testing, validation, and verification are normal parts of the designs process as they assist in clarifying design assumptions and promote a discussion that refines.
Software testing is an error detection function that is meant to accompany design with an empirical approach that involves:
- Code testing basics
- Levels of testing
- Philosophical underpinnings of software testing
- Test-Driven Development
- Unit testing (Python and Django)
- Testing dependencies
It is hard to predict when AI/ML/Automation will take use to the realm of Star Trek and remove our need to define and configure software with programming code. However, our need to remain intimate with code and its expectations necessitates testing code. The same routines that will generate code for us will generate tests, but we must remain as "human in the loop" to confirm and validate the sanity of generated code and generated tests.
What exactly is meant by testing code?
Testing code: "any procedure that probes the application to check that it works correctly before it reaches the final customers." - Jaime Buelta
From the earliest time of using code, we are testing our code to some informal degree where informal "run it, check it" tests are common when you want to ensure that something you just wrote works as expected. This approach may work for homework and coding assignments, or for small, simple applications, but it won't scale well. Also, we must be wary of errors of regression where new features have the potential to break older features that previously worked. This is what can be frustrating as beginniner progress away from early guided and tutorial learning and into unscructured and abstract learning.
Rather than "run it, break it testing," we need better tools to be able to write complex and high-quality software. In this case, a first step to a disciplined approach to testing is to understand testing as documented and automataed procedures that confirm the proper function of all elements of an application prior to intended use (e.g. when the actual customer will use it).
Since a test must covered the elements of a software system, it is important to understand the software system at multiple levels of detail and abstraciton. This means that a good system is designed with abstractions that collate and simplify lower level and detailed elements of the system such that both details and abstractions should be tested.
When testing smaller/detailed part of the system we would employe a simpler test and narrower scope. A well designed system will be comprised of many mutually-supportive smaller and simpler units. We can best understand levels of the software system by describing the levels of testing we'll employ:
- Unit tests - tests that validate the basic logical units of a system (often the methods/functions we write)
- Integration tests - tests that validate the coordination and interoperation of units that provide a single and integrate service.
- System tests tests that validate that multiple services work harmoniously (also called end-to-end tests)
The unit test is the most basic and smallest test that validates the behavior a unit of code and is frequently used to test methods/functions. The unit is commonly a single function or a single API endpoint As unit tests validate often atomic part of the functionality of the system, they should be easy to setup and run. The full set of unit tests can thoroughly test system in the case that all functions are covered by tests. These won't capture interaction effects, but will ensure that each individual component is correct. Since a unit test validates a service in isolation, it is common to simulate or fake external requests or inputs as a part of the test.
An integration test validates the whole and collective behavior of complex service or series of inter-dependent services. Integration testing ensures the mutually-dependent modules within a service can interoperate successfully. While we could fake inputs and outputs in unit tests, integration tests must use real data as much as would be practible. This makes the design of APIs important as connected services must have reliable assumptions about communication.
Given their nature, integration test setup can be more complex than with unit tests, making integration tests more "expensive." Integration tests may not be as thorough and exhaustive as unit tests as they focus on checking for base/default cases that are often referred to as following a happy path with no errors, exceptions, or edge cases. This is so as errors and exceptions handled in unit testing. In general integration testing exists to define and validate "happy path" tests of expected and normal general behavior of a feature.
A system, or end-to-end, test validates the overall effectiveness of all services to ensure the they work correctly together to facilitate the overall function of the broader system.
A system test assumes that the system provides multiple services where the objective is that theseservices can cooperate and are correctly configured. Given their encompassing nature, system tests expensive: they require the operation of a correctly-configured whole system. The overhead of standing up a full environment that is tantamount to testing a live environment. This places greater emphasis on correct environment configuration and the need to validate each possible environment configuration.
Testing can be a matter of philosophy as there is no universal imperative for when, how often, and where. Even deeper would be question related to whether testing is worth the effort as it can seem to be "double work."
Questions of worth have to do with how time and effort are valued and can only be addressed if the costs of software defects are appraised. These defects can be distinguished from "bugs" in software. Whereas a "bug" is a kind of defect where the software behaves in a way that it's not expected to, a defect could be something that behaves correctly but provides the wrong answer - this is a flaw of design. Test are generally better at detecting bugs than design assumption defects.
Arguably more insidious, deployed defects can be more expensive to repair as their damage has already impacted real users. Deployed applications are active with users which will make defect/error detection more challenging as it will be an end-user who will likely detect the defect but may not communicate the error and may simply abandon the system and/or deem it unreliable. This may also cause regression errors where the cycle between detection and fix happens in parallel with the introduction and fixing of features. Thus, the objective of softare testing is to improve system quality by fixing defects earlier.
The levels of testing meantioner earlier each have a different impact on the cost of defects: defects detected by unit testing presents an earier, and cheaper fix. Generally, a unit test is cheaper than an integration test, and an integration test is cheaper than a system test. The cost of fixing defects increases the farther away it is from what can be controlled during development.

We use the following pattern to develop unit tests:
- Arrange: Prepare the environment for the tests. This includes all the setup to get the system right at the point before performing the next step, at a stable moment.
- Act: Perform the action that is the objective of the test.
- Assert: Check that the result of the action is the expected one.
We can arrange the same structure into a phrase or sentence:
GIVEN (Arrange) an environment known, the ACTION (Act) produces the specified RESULT (Assert)
This pattern is also known as the GIVEN, WHEN, THEN and is formalizedin the Ghekin syntax that is common with BDD tools such as Cucumber.
Here is an example:.
def the_test():
# Arrange
# Create object to test
test_object = TestClass(arg1='val',
arg2='val')
# Act step
answer = test_object.work_method(arg1='val')
# Assert step
assert answer == 'expected value'Test-Driven Development (TDD) is a philosophy on software testing where tests are the center of software design and development. TDD works in the following rough pattern of development:
- Needed new functionality is identified.
- A test is written to define the new functionality.
- Tests are run resulting in the new test(s) failing.
- New functionality is then added to the main code intended to make the test pass.
- Tests are run to show that the new feature work.
- With passing tests, new functionality is ready for use!
- Repeat the process for any new functionality.
TDD is based on three main principles:
- Write tests before writing code - test early
- Run the tests often - test often.
- Work in very small increments - fail early and often.

This is also called "red/green/refactor" pattern: red when the test is failing and green when all tests are passing.
Refactoring is a key aspect of TDD as the technique presumes a high degree of flux where the need to improve code quality is nearly constant. Improvements made possible by refactoring would include improving code readability, usability, and consistency.
The Python standard library provides the unittest package for unit testing. To use it, we create a test class wherein we define severage testing methods. Being a part of Python, unittest is widely available and works by provided a number of known assert functions. unittest also provides test setup and teardown methods to configure tests before and after test execution. More on unit testing can be found in the python documentation.
Since we are reasoning about software architecture, it might be useful to also reflect the software architect. There are reasonable questions to start with:
What do software architects do?What artifacts do they produce?How can we reconcile and quality the skills and competencies of a software architect?
Answering these questions would permit a competency or capability model for the software architect.
We can reflect on things that would make for a good architect:
- Org. Culture: Sensitivity to, and ability to worth within, institutional/organizational culture - the essence of the domain lies within this culture
- Strategically Astute - Strategic thinking is a natural and default mode for you.
- Leadership - Leadership is not simply "being the boss," but someone who is willing to seek solutions and value in the face of uncertainty.
- Solution and Design Oriented - Problems await structured solutions that resonate with the design needs of the organization.
- Integration-minded - You seek whole/part understanding to see "how the pieces fit."
- Domain-oriented - Subject matter expertise within the problem domain is matched and balance with your fondness for the solution domain.
- Socially Empathetic - Domain affinity is matched by sensitivy to the people and processes that are impacted by solutions.
- Mastery Path - You engage within the mastery path with a certainty that you can both leverage and improve your skills
The emprical output and artifacts of the architect will be realized as specifications and requirements for the system to be built. This is how the Software Architect is more than just an engineer as the artful aspects of design are also present. However, there are fluencies in design, and the materials of design, that architects and engineers share.
What distinguishes the architect is the thoughful inclusion of domain. It is the consideration of domains that lead to design instructions from the architect that preserve and linkage across and through domains.
Requirements are typically answers to the following questions:
- Events - What are the events that the system will model?
- Entities - What entities exist within the system such that their state can be adequately described?
- Business/Domain Rules - What are the operational rules of play within the system to perserve desired relationships within the system?
There are two vital domains of expertise that are essential for developing systems architectures:
- Problem Domain: At the heart of the business of the organization lies the understanding of the key factors that shape the organization:
- Industry segment
- Motivations
- Threats
- Opportuntities
- Risk
- Solution Domain: The technical competency and disposition of the organization such that it can design, procure, implement, manage, and leverage information systems assets.
Where these worlds meet can be seen in this diagram (credit: Michael Bell):

Michael Bell offers a model of Software Architecture competency that facilicates our understanding of software architecture. We can understand the Software Architect's responsibilities through key activities, deliverables, and competencies:
- Requirements - Excel at developing and brokering systems requirements
- Practices - Engage in key practices and methods that support domain requirements
- Discipline - With a mastery focus, develop expertise within denoted problem/solution domain pairings.
- Deliverables - With a mastery focus, delivered artifacts will be subject to continuous improvement.
- Duetero Learning - With a mastery focus, engage in organizational and professional metacognition that reasons with the progress of the mastery focus.
How these elements come together is illustrated in Michael Bell's model below:

It is important to note that Michael Bell's model is not a means to understand the prototypical Software Architect, but rather to identify the type of Software Architecture competencies and capabilities required within a given design context. This is so as an experienced architect will be, at least, the sum of their experiences. Should the architect be a reflective practitioner, they may may realize the "synergy" that exceeds sum of parts.