-
Notifications
You must be signed in to change notification settings - Fork 0
/
Copy pathindex.html
1096 lines (788 loc) · 36.9 KB
/
index.html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
998
999
1000
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" lang="" xml:lang="">
<head>
<title>R aplicado a la ECH</title>
<meta charset="utf-8" />
<meta name="author" content=" Creative Commons Attribution 4.0 International License" />
<link href="index_files/font-awesome/css/fontawesome-all.min.css" rel="stylesheet" />
<link rel="stylesheet" href="xaringan-themer.css" type="text/css" />
</head>
<body>
<textarea id="source">
class: center, middle, inverse, title-slide
# R aplicado a la ECH
## Setiembre 2020 <br> Gabriela Mathieu
### <a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/88x31.png" /></a><br /> <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Creative Commons Attribution 4.0 International License</a>
---
# ¿Qué haremos hoy?
- Exportar objetos a archivos RData. Importar archivos RData.
<br><br>
--
- Definir una función para encontrar un dato faltante
<br><br>
--
- Definir una función para encontrar un caso duplicado
<br><br>
--
- Introducción al paquete dplyr para manipular un data frame
<br><br>
--
- Operadores lógicos y de comparación. Operador %in%.
<br><br>
--
- Trabajar en proyecto (.Rproj)
---
class: inverse, center, middle
# RData
---
# Guardar un objeto a un archivo RData
- <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >RData</span> es un formato propio de R.
<br><br>
--
- Sirve para <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >guardar objetos de R</span>. Los archivos ocupan mucho menos espacio que otros formatos.
<br><br>
--

---
# Guardar un objeto a un archivo RData
La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >save()</span> permite guardar un <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >objeto</span> en un <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >archivo RData</span>
```r
# guardar un objeto (data frame) en formato R
save(ech19, file = "data/ech19.RData")
```
--
- Debo escribir el argumento <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >file</span> de lo contrario me dará error porque no es el segundo argumento de la función. Allí especifico el nombre del archivo que voy a crear.
- Adicionalmente puede incluir la ruta donde se creará el archivo. Si solo se define el nombre del archivo, se guarda en el directorio de trabajo actual: **getwd()**
<br><br>
--
- El <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >nombre</span> del objeto y el archivo pueden coincidir, pero no necesariamente.
<br><br>
--
- Es posible guardar más de un objeto en el mismo archivo RData.
---
# Leer un archivo RData
- La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >load()</span> permite cargar archivos RData.
<br><br>
--
- <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >No lo asigno a ningún objeto</span> a diferencia del resto de las funciones de importación/lectura.
<br><br>
--
```r
load("data/ech19.RData")
```
- En este caso puedo prescindir de nombrar el argumento file porque es el primero de la función.
---
# Leer un archivo RData
¿Qué pasa si lo asigno a un objeto?
<br><br>
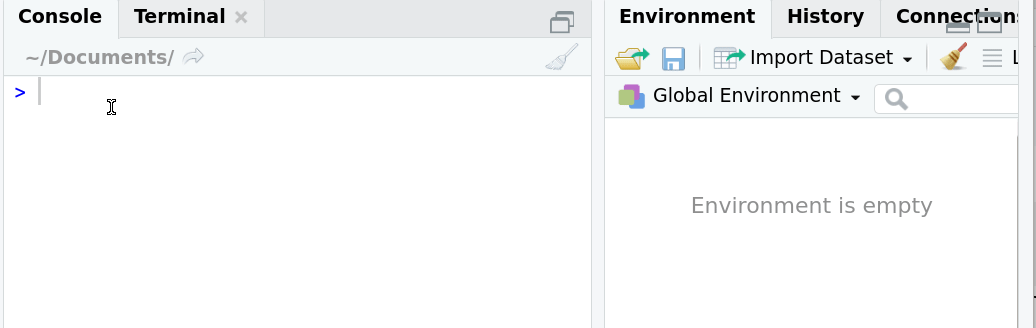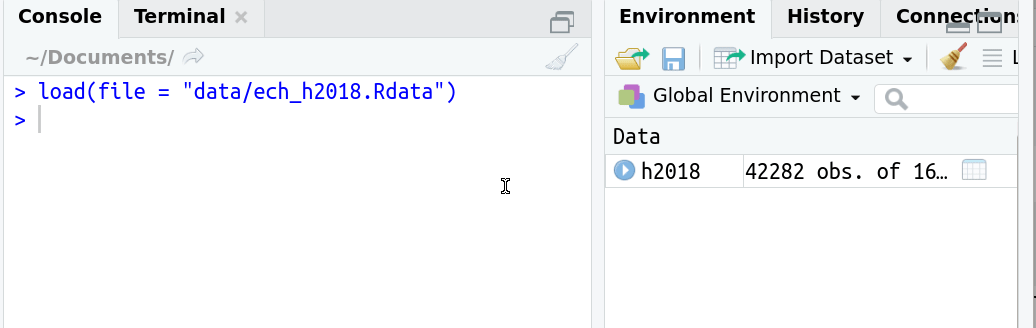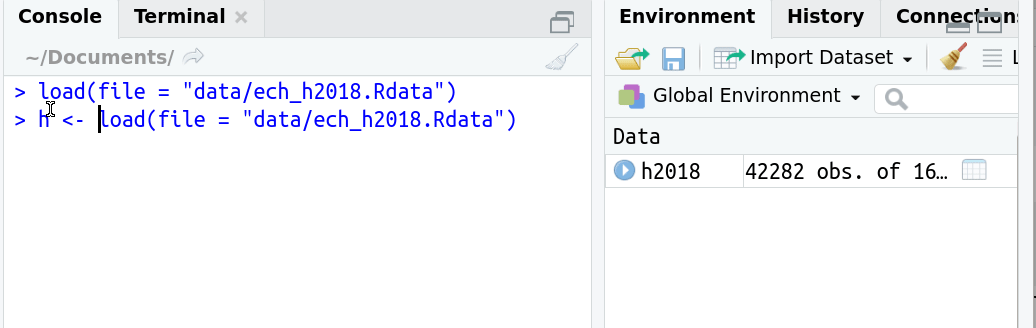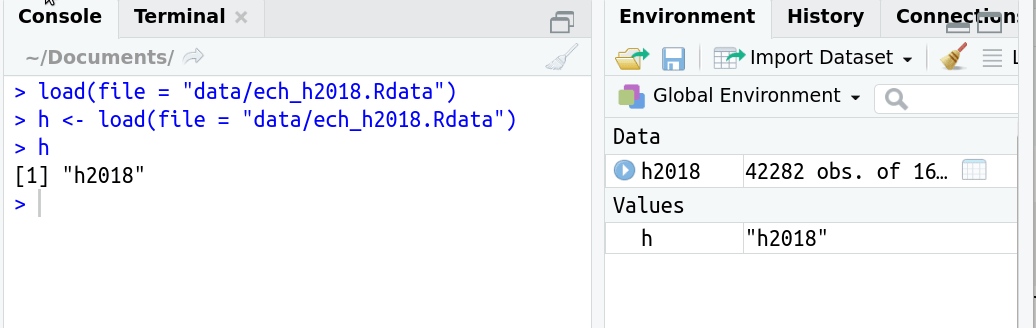
- Si existe como archivo RData tuvo que crearse primero como objeto.
<br><br>
---
# Leo los datos de ECH 2019
Es una nueva sesión así que no tengo los objetos en memoria que tenía ayer.
Voy a usar la función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >load()</span> que viene en R-base.
```r
load("/home/calcita/Desktop/ech19.RData") #cargo los datos
```
Nunca asigno a un objeto cuando uso la función load()
---
# Datos faltantes (NA)
- La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >is.na()</span> chequea si hay un dato faltante (<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >NA: not available</span>) para cada elemento de un vector.
<br><br>
--
```r
*x <- c(-22, 4, -1, 8, NA)
x
```
```
[1] -22 4 -1 8 NA
```
- ¿Cuántos datos faltantes tiene x?
--
- Devuelve un <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >vector lógico</span>, donde el TRUE indica que no hay dato y el FALSE que sí hay dato.
```r
*is.na(x)
```
```
[1] FALSE FALSE FALSE FALSE TRUE
```
---
# Ejemplo: Datos faltantes (NA)
```r
sin_pobpcoac <- is.na(ech19$pobpcoac)
```
--
- ¿Cuántos son los valores faltantes de `pobpcoac`?
```r
table(sin_pobpcoac)
```
```
sin_pobpcoac
FALSE
107871
```
```r
*sum(sin_pobpcoac)
```
```
[1] 0
```
El valor lógico <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >TRUE</span> representa al <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >1</span> y el valor <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >FALSE</span> representa al <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >0</span> por eso puedo usar la función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >sum()</span>.
---
# Observaciones duplicadas
La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >duplicated()</span> determina cuales elementos de un vector o data frame están duplicados, devuelve un vector lógico: TRUE si es duplicado y FALSE en caso contrario.
<br><br>
--
- <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >Compara un elemento del vector con todos los anteriores</span>, va asignando el valor FALSE hasta que se encuentra con un caso duplicado y en este caso le asigna TRUE y sigue comparando.
```r
*x <- c(-22, 4, 8, 8, NA)
x
```
```
[1] -22 4 8 8 NA
```
--
```r
*duplicated(x)
```
```
[1] FALSE FALSE FALSE TRUE FALSE
```
---
# Ejemplo: observaciones duplicadas
- Chequeo que haya algún <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >caso duplicado</span>, reviso todas las variables
```r
*repetidos <- duplicated(ech19) # el argumento es el data frame
*sum(repetidos) # los sumo, recordar: TRUE es 1 y FALSE es 0
```
```
[1] 0
```
- Chequeo que haya algún <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >valor duplicado</span> en la <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >variable identificatoria de cada caso</span>
```r
*repetidos <- duplicated(ech19$numero) # el argumento es una variable
*sum(repetidos)
```
```
[1] 65364
```
Si nombro a un objeto igual a uno existente, lo sobreescribo.
---
class: inverse, center, middle
# dplyr
---
# Manipular datos con dplyr
- El paquete dplyr permite representar la información de un <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >data frame</span> en forma de <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >tabla</span>, donde cada fila representa una observación y cada columna represente una variable.
<br><br>
--
- dplyr no provee ninguna funcionalidad que no pueda ser realizada con las funciones del paquete base, sin embargo, es más simple y rápido (está escrito en C++).
<br><br>
--
- Todas las funciones del paquete tiene la particularidad de que su <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >primer argumento es un data frame</span> al que le realizará la operación, mientras que los subsiguiente argumentos describen como realizar tal operación.
- Finalmente el <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >resultado</span> de todas estas funciones es un nuevo <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >data frame</span>. Esto no ocurre con las funciones de base.
---
class: center, middle
# ~~Base R vs. Tidyverse~~

---
# Instalar y cargar dplyr
- La instalación es por única vez en una computadora.
```r
# install.packages("dplyr") # ya lo tengo instalado
```
- Comenté esa línea porque ya lo tengo instalado
--
- En cada nueva sesión de RStudio lo debo cargar para poder usar sus funciones
```r
*library(dplyr)
```
Notar que en la función de instalación el nombre del paquete se escribe entre comillas pero en la función de carga va sin comillas. No hagas ~~library("dplyr")~~.
---
# Manipular datos
- Seleccionar columnas/variables
<br><br>
--
- Cambiar nombre de variables
<br><br>
--
- Transformar variables
<br><br>
--
- Crear nuevas variables
<br><br>
--
- Filtrar o eliminar observaciones
<br><br>
--
- Chequear existencia de observaciones duplicadas
<br><br>
--
- Chequear existencia de datos faltantes
<br><br>
--
- Reestructurar los datos
---
class: inverse, center, middle
# dplyr::select()
---
# Seleccionar columnas/variables
- La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >select()</span> selecciona columnas de un data frame
--
- El primer argumento es el data frame y luego la(s) variable(s) separadas por coma.
--
- `select`(<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;dataframe&gt;</span>, <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;variable&gt;</span>)
<br><br>
--
.pull-left[
```r
*select(ech19, numero)
```
```
# A tibble: 107,871 x 1
numero
<chr>
1 2019000001
2 2019000001
3 2019000002
4 2019000002
5 2019000003
6 2019000003
7 2019000004
8 2019000004
9 2019000005
10 2019000005
# … with 107,861 more rows
```
]
.pull-rigth[
```r
*select(ech19, numero, nper)
```
```
# A tibble: 107,871 x 2
numero nper
<chr> <dbl>
1 2019000001 1
2 2019000001 2
3 2019000002 1
4 2019000002 2
5 2019000003 1
6 2019000003 2
7 2019000004 1
8 2019000004 2
9 2019000005 1
10 2019000005 2
# … with 107,861 more rows
```
]
Las funciones de tidyverse permiten llamar a las variables de un data frame sin usar comillas pero esto no es aplicable al resto de los paquetes de R, incluido los del base.
---
# Seleccionar columnas/variables
.pull-left[
Seleccionar un rango de columnas: select(<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;df&gt;</span>, <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;desde&gt;:&lt;hasta&gt;</span>)
```r
select(ech19, dpto:region_3)
```
]
.pull-right[
Seleccionar todas las columnas menos una: select(<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;df&gt;</span>, <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >-&lt;variable&gt;</span>)
```r
select(ech19, -nper)
```
]
---
class: inverse, center, middle
# dplyr::slice()
---
# Seleccionar filas/observaciones por su posición
- La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >slice()</span> selecciona observaciones/filas según su posición.
--
- Esto no es robusto a un reordenamiento de las observaciones. Sirve para "ver" algunos casos.
--
- `slice`(<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;df&gt;</span>, <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;nro_fila&gt;</span>, <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;nro_fila&gt;</span>)
<br><br>
--
.pull-left[
```r
# selecciono las filas 1 y 5
*slice(ech19, 1, 5)
```
]
.pull-right[
```r
# selecciono las filas de 1 a 5
*slice(ech19, 1:5)
```
]
---
class: inverse, center, middle
# dplyr::filter()
---
# Selecciona observaciones según condición
- La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >filter()</span> selecciona observaciones/filas según una condición.
--
- Puede ser una condición que involucre a una o varias variables. Condiciono a que tome o no tome ciertos valores.
--
- `filter`(<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;df&gt;</span>, <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;condicion&gt;</span>)
<br><br>
--
```r
*mdeo <- filter(ech19, dpto == 1) # me quedo con los casos de Montevideo
head(mdeo)
```
```
# A tibble: 6 x 9
numero nper dpto nomdpto region_3 e26 e27 ht19 pobpcoac
<chr> <dbl> <dbl+lbl> <chr> <dbl+lbl> <dbl+l> <dbl> <dbl> <dbl+lbl>
1 2019000… 1 1 [Montev… MONTEVI… 1 [Montev… 2 [Muj… 32 2 2 [Ocupado…
2 2019000… 2 1 [Montev… MONTEVI… 1 [Montev… 1 [Hom… 9 2 1 [Menores…
3 2019000… 1 1 [Montev… MONTEVI… 1 [Montev… 2 [Muj… 53 2 2 [Ocupado…
4 2019000… 2 1 [Montev… MONTEVI… 1 [Montev… 2 [Muj… 13 2 1 [Menores…
5 2019000… 1 1 [Montev… MONTEVI… 1 [Montev… 2 [Muj… 85 1 10 [Inactiv…
6 2019000… 1 1 [Montev… MONTEVI… 1 [Montev… 2 [Muj… 45 1 2 [Ocupado…
```
---
class: inverse, center, middle
# Operadores comparativos
---
# Operadores de comparación
.pull-left[
Mayor que: <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&gt;</span>
```r
*filter(ech19, e27 > 90) # personas mayores de 90
```
]
.pull-rigth[
Mayor igual que: <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&gt;=</span>
```r
*filter(ech19, e27 >= 90) # personas mayores de 90 o mas
```
]
---
# Operadores de comparación
.pull-left[
Menor que: <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;</span>
```r
*filter(ech19, e27 < 10)
```
]
.pull-rigth[
Menor igual que: <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;=</span>
```r
*filter(ech19, e27 <= 10)
```
]
---
# Operadores de comparación
.pull-left[
Igual que: <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >==</span>
```r
*filter(ech19, e27 == 90)
```
]
.pull-rigth[
Diferente que: <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >!=</span>
```r
*filter(ech19, e27 != 90)
```
]
---
class: inverse, center, middle
# Operadores lógicos
---
# Operadores lógicos
O lógico: <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >|</span>
```r
# selecciono personas menores a 10 o mayores a 90
*filter(ech19, e27 < 10 | e27 > 90)
```
---
# Operadores lógicos
Y lógico: <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&amp;</span>
```r
# selecciono menores a 10 y de Salto
*filter(ech19, e27 < 10 & nomdpto == "FLORES")
```
--
---
# Operadores lógicos
No lógico: <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >!</span>
```r
# selecciono todas las personas que no tienen 90
*filter(ech19, !e27 == 90)
```
---
class: inverse, center, middle
# %in%
---
# Operador %in%
- <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >Compara cada elemento</span> de un vector con los elementos de otro vector.
--
- <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;x&gt; %in% &lt;y&gt;</span>, el primer elemento de x se compara con todos los elementos de y, el segundo elemento de x se compara con todos los elementos de y, así sucesivamente.
--
- Devuelve un TRUE o un FALSE en cada comparación. TRUE cuando el elemento de x está en y, FALSE en caso contrario.
--
- Cuando lo uso <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >en filter() se queda con los TRUE</span>.
```r
# selecciono personas Durazno y Rocha
filter(ech19, nomdpto %in% c("DURAZNO", "ROCHA"))
```
En este caso es lo mismo que:
```r
# selecciono alojamientos menor a 60 y que el tipo sea Private room
filter(ech19, nomdpto == "DURAZNO" | nomdpto == "ROCHA")
```
---
# Ejercicio (10')
- Selecciona los casos que tienen entre 3 y 5 años de edad y guarda en un objeto llamado `menores_3_5`. La variable e27 es la edad.
<!-- review_10_20 <- filter(ech19, number_of_reviews >= 10 & number_of_reviews <= 20) -->
- Selecciona los casos cuya vivienda tiene 4 o 6 habitaciones y guarda en un objeto llamado `habitaciones_4`. La variable d9 es el número de habitaciones.
<!-- availability_3_5 <- filter(ech19, availability_365 %in% c(3,5)) -->
<!-- availability_3_5 <- filter(ech19, availability_365 == 3 | availability_365 == 5) -->
- Selecciona los últimos 5 casos de ech19 y guarda en un objeto llamado `ultimos_5`.
<!-- last_5 <- slice(ech19, (nrow(ech19)-4):nrow(ech19)) -->
<!-- last_5 <- slice_tail(ech19, n = 5) -->
<!-- - Selecciona las variables referidas a reviews y guarda en un objeto llamado `reviews_name`. -->
<!-- reviews_name <- ech19 %>% select(contains("review")) -->
- Selecciona un registro por hogar y guarda en un objeto llamado `hogares`.
<!-- hogares <- filter(ech19, nper == 1) -->
- ¿De cuál departamento es el hogar con mayor cantidad de personas? Ver ?slice_max
<!-- select(slice_max(hogares, ht19), nomdpto) -->
---
class: inverse, center, middle
# dplyr::arrange()
---
# Ordenar las observaciones según una variable
```r
ech19 <- select(ech19, ht11, numero, nomdpto)
```
La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >arrange()</span> <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >ordena</span> un data frame de acuerdo a una(s) variable(s) de manera <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >creciente</span> por defecto.
--
```r
*arrange(ech19, ht11)
```
--
Para ordenar de manera <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >decreciente</span> debo incluir la función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >desc()</span>:
```r
*arrange(ech19, desc(ht11))
```
--
Para ordenar por más de una variable:
```r
arrange(ech19, desc(ht11), e27)
```
---
class: inverse, center, middle
# dplyr::summarise()
---
# Calcular un resumen de una variable
- La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >summarise()</span> o <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >summarize()</span> calcula un resumen de variables
- summarise(<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;df&gt;</span>, <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;column&gt;</span> = <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;function&gt;</span>(<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;variable&gt;</span>))
- El resultado será una data frame con una fila, a menos que los datos estén agrupados, y una columna por cada estadístico de resumen.
```r
*summarise(ech19, promedio = mean(ht19))
```
- Se puede utilizar cualquier función que cumpla con que lo datos de entrada sean numéricos y como salida se entregue una constante. Por ejemplo las funciones de resumen que vimos de R base: `mean`(), `max`(), `min`(), `median`(), `var`(), `sd`(), `sum`(), etc. Existen otras específicas de `dplyr` que iremos viendo.
---
# Calcular un resumen de una variable
- Se pueden aplicar diferentes funciones a la misma o diferentes variables
```r
# la función n() devuelve la cantidad de observaciones
*summarise(ech19, promedio = mean(ht19), varianza = var(ht19), total = n())
```
- Suele ser más claro escribirlo hacia abajo
```r
*summarise(ech19, promedio = mean(ht19),
* varianza = var(ht19),
* total = n())
```
---
class: inverse, center, middle
# dplyr::count()
---
# Cálculo frecuencias de una variable
- La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >count()</span> es la función de dplyr para hacer una tabla de frecuencias, el resultado es siempre un data frame de menor dimensión que el original.
--
- count(<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;df&gt;</span>, <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;variable&gt;</span>)
--
- En R base usamos <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >table()</span> pero el resultado no es un data frame y la salida no es muy amigable.
--
--
```r
*count(ech19, region_3)
```
```
# A tibble: 3 x 2
region_3 n
<dbl+lbl> <int>
1 1 [Montevideo] 38207
2 2 [Interior - Localidades de 5000 habitantes o más] 50854
3 3 [Interior - Localidades de menos de 5000 habitantes y zona ru] 18810
```
---
# Cálculo frecuencias entre dos variables
```r
*count(ech19, region_3, e26)
```
```
# A tibble: 6 x 3
region_3 e26 n
<dbl+lbl> <dbl+lbl> <int>
1 1 [Montevideo] 1 [Hombr… 17397
2 1 [Montevideo] 2 [Mujer] 20810
3 2 [Interior - Localidades de 5000 habitantes o más] 1 [Hombr… 23860
4 2 [Interior - Localidades de 5000 habitantes o más] 2 [Mujer] 26994
5 3 [Interior - Localidades de menos de 5000 habitantes y zona … 1 [Hombr… 9348
6 3 [Interior - Localidades de menos de 5000 habitantes y zona … 2 [Mujer] 9462
```
---
class: inverse, center, middle
# dplyr::mutate()
---
# Calculo una nueva variable
- La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >mutate()</span> permite calcular nuevas variables
--
- mutate(<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;df&gt;</span>, <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;nombre&gt;</span> = <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;calculo&gt;</span>)
--
- El resultado será de la <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >misma cantidad de observaciones</span> que el data frame original
--
- Conviene guardarlo en el mismo objeto (data frame original)
--
```r
*ech19 <- mutate(ech19, media_edad = mean(e27))
head(ech19$media_edad)
```
```
[1] 39.87829 39.87829 39.87829 39.87829 39.87829 39.87829
```
---
class: inverse, center, middle
# dplyr::case_when()
---
# Crear una variable a partir de varias condiciones
La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >case_when()</span> permite calcular una nueva variable a partir de condicionar los valores de otra
```r
ech19 <- mutate(ech19,
* mayor = case_when(
* e27 < 18 ~ "Menor",
* e27 >= 18 ~ "Mayor"))
```
---
# Agrupo los casos por cierta variable
- La función <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >group_by()</span> permite agrupar las observaciones por cierta variable.
--
- Permite hacer operaciones por grupos para posteriormente realizar otros cálculos.
--
- group_by(<span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;df&gt;</span>, <span style=" font-weight: bold; border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #b3e2cd !important;" >&lt;variable&gt;</span>)
--
```r
# promedio de precio por barrio
*ech19_gr <- group_by(ech19, nomdpto)
*summarise(ech19_gr, promedio = mean(ht19))
```
```
# A tibble: 19 x 2
nomdpto promedio
<chr> <dbl>
1 ARTIGAS 3.70
2 CANELONES 3.38
3 CERRO LARGO 3.25
4 COLONIA 3.12
5 DURAZNO 3.68
6 FLORES 3.23
7 FLORIDA 3.19
8 LAVALLEJA 3.26
9 MALDONADO 3.25
10 MONTEVIDEO 3.21
11 PAYSANDU 3.46
12 RIO NEGRO 3.40
13 RIVERA 3.43
14 ROCHA 3.11
15 SALTO 3.80
16 SAN JOSE 3.39
17 SORIANO 3.42
18 TACUAREMBO 3.45
19 TREINTA Y TRES 3.24
```
---
# Agrupo los casos por cierta variable
- También lo puedo hacer concatenando funciones
```r
*summarise(group_by(ech19, nomdpto), promedio = mean(ht19))
```
```
# A tibble: 19 x 2
nomdpto promedio
<chr> <dbl>
1 ARTIGAS 3.70
2 CANELONES 3.38
3 CERRO LARGO 3.25
4 COLONIA 3.12
5 DURAZNO 3.68
6 FLORES 3.23
7 FLORIDA 3.19
8 LAVALLEJA 3.26
9 MALDONADO 3.25
10 MONTEVIDEO 3.21
11 PAYSANDU 3.46
12 RIO NEGRO 3.40
13 RIVERA 3.43
14 ROCHA 3.11
15 SALTO 3.80
16 SAN JOSE 3.39
17 SORIANO 3.42
18 TACUAREMBO 3.45
19 TREINTA Y TRES 3.24
```
--
- En la línea anterior anidamos funciones para obtener el promedio según barrios.
- La anidación de funciones tiende a volver confuso el código...veremos luego cómo superar este inconveniente con el operador `%>%`.
---
# Ejercicio (5')
- Calcular el promedio de edad según sexo.
- Calcular la cantidad de jefas de hogar.
---
# Trabajar en proyecto
.pull-left[
Permite ordenar los diferentes archivos de un análisis y prescindir de usar setwd() y/o escribir rutas larguísimas.
Si el archivo `tesis.Rproj` está ubicado en: `/home/calcita/Escritorio/tesis`, todos los archivos que estén en la carpeta tesis voy a poder cargarlos sin definir una ruta del archivo.
```r
load("datos.csv")
```
]
.pull-right[
<img src="img/fd1.png" width="335" />
]
---
# Crear proyecto
<img src="https://raw.githubusercontent.com/calcita/Curso-rECH/master/images/create_project.gif" width="850" height="450"/>
---
# Abrir proyecto
<img src="https://raw.githubusercontent.com/calcita/Curso-rECH/master/images/open_project.gif" width="850" height="450"/>
---
# Crear script
<img src="https://raw.githubusercontent.com/calcita/Curso-rECH/master/images/create_file.gif" width="850" height="450"/>
---
# Ejercicio (5')
.left-column[
<img src="https://raw.githubusercontent.com/calcita/Curso-rECH/master/images/folder.png" width="80px" />
<br><br>
<img src="https://raw.githubusercontent.com/calcita/Curso-rECH/master/images/rproj.png" width="80px" />
<br><br>
<img src="https://raw.githubusercontent.com/calcita/Curso-rECH/master/images/web-programming.png" width="80px" />
]
.rigth-column[
<br><br>
Crear una carpeta llamada "Curso ECH"
<br><br>
Abrir Rstudio y crear un proyecto. Elegir como directorio la carpeta recién creada.
<br><br>
Crear un script de R donde guardaremos el código de este taller. Agregar a la carpeta los materiales del curso.
]
</textarea>
<style data-target="print-only">@media screen {.remark-slide-container{display:block;}.remark-slide-scaler{box-shadow:none;}}</style>
<script src="https://remarkjs.com/downloads/remark-latest.min.js"></script>
<script>var slideshow = remark.create({
"highlightStyle": "github",
"highlightLines": true,
"countIncrementalSlides": false,
"ratio": "16:9",
"slideNumberFormat": "<div class=\"progress-bar-container\"> <div class=\"progress-bar\" style=\"width: calc(%current% / %total% * 100%);\"> </div> </div>"
});
if (window.HTMLWidgets) slideshow.on('afterShowSlide', function (slide) {
window.dispatchEvent(new Event('resize'));
});
(function(d) {