原文:
www.kdnuggets.com/2016/10/jupyter-notebook-best-practices-data-science.html
由 Jonathan Whitmore,硅谷数据科学。
Jupyter Notebook 是一个极其出色的工具,可以以多种方式使用。由于其灵活性,在团队环境中使用 Notebook 解决数据科学问题可能会具有挑战性。我们在这里介绍一些 SVDS 在与团队和客户合作中实施的最佳实践——这些实践也可能对你的数据科学团队有所帮助。
 1. Google 网络安全证书 - 快速开启网络安全职业生涯。
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域

需要在版本控制下进行工作,并保持共享空间而不互相干扰,这一直是一个棘手的问题。我们在这里展示了当前适合我们的系统视图——也可能对你的数据科学团队有所帮助。
在数据科学项目中有两种笔记本存储类型:实验室笔记本和可交付成果笔记本。首先是每本笔记本的组织方法。
实验室(或开发)笔记本:
让传统的纸质实验室笔记本成为你的指南:
-
每本笔记本都保留了分析过程中的历史记录(并标有日期)。
-
笔记本的目的仅仅是作为实验和开发的场所。
-
每本笔记本由一个作者控制:团队中的数据科学家(用首字母标记)。
-
当笔记本变得过长时(想象一下翻页),也可以进行拆分。
-
如果有意义的话,可以按主题拆分笔记本。
可交付成果(或报告)笔记本
-
它们是实验室笔记本的完全打磨版本。
-
它们存储分析的最终输出。
-
笔记本由整个数据科学团队控制,而不是由任何一个人控制。
这是我们如何使用 git 和 GitHub 的一个示例。GitHub 的一个美妙新功能是它们现在可以在仓库中自动渲染 Jupyter Notebooks。
当我们进行分析时,我们会对代码和数据科学输出进行内部审查。我们使用传统的拉取请求方法进行审查。然而,当发出拉取请求时,查看更新后的 .ipynb 文件之间的差异,更新并不会以有用的方式呈现。人们倾向于推荐的一个解决方案是将其转换为 .py 格式进行提交。这对于查看输入代码的差异(同时舍弃输出)非常有用,并且有助于查看变化。然而,在审查数据科学工作时,查看输出本身也是极其重要的。
例如,一位数据科学家可能会对以下初步图表提供反馈,并希望看到改进:
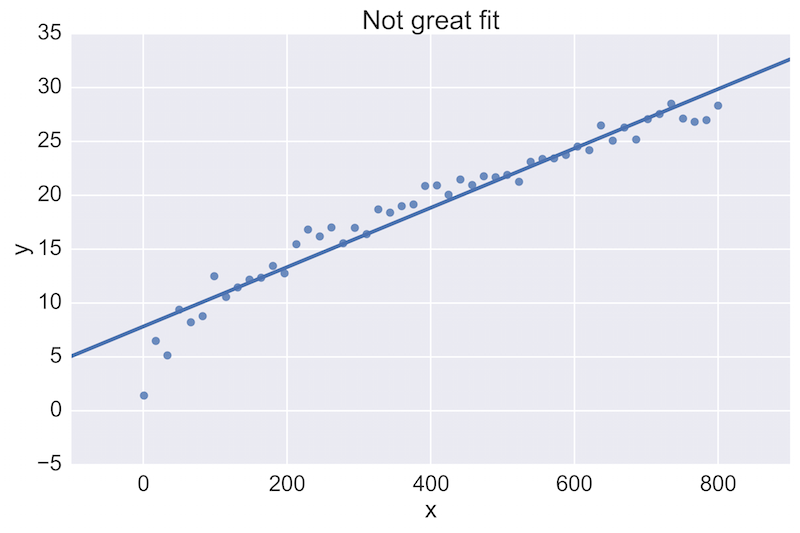
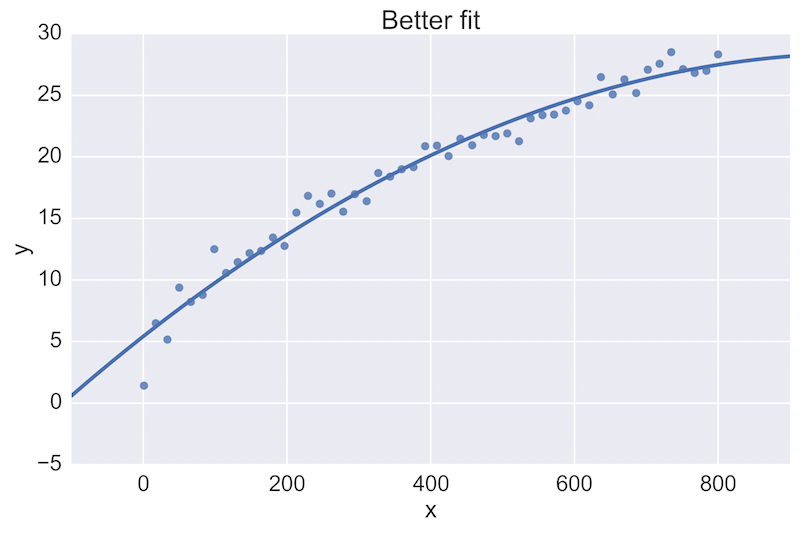
顶部的图表与数据的拟合效果较差,而底部的图表效果更好。在团队成员工作代码的拉取请求审查中直接查看这些图表是至关重要的。
查看 Github 提交示例 这里。
注意,有三种方法可以查看更新后的图形(选项在底部)。
保存后钩子
我们与许多不同的客户合作。他们的一些版本控制环境缺乏良好的渲染功能。有些公司防火墙后面部署 nbviewer 实例的选项,但有时这仍然不是一个选项。如果你遇到这种情况,并且希望保持上述代码审查框架,我们有一个解决办法。在这些情况下,我们会在每次提交中提交 .ipynb、.py 和 .html 文件。创建 .py 和 .html 文件可以通过编辑 jupyter 配置文件并添加保存后钩子,每次保存笔记本时自动完成。
默认的 jupyter 配置文件位于:
~/.jupyter/jupyter_notebook_config.py
如果你没有这个文件,请运行:
jupyter notebook --generate-config
创建这个文件,并添加以下文本:
运行jupyter notebook,你就可以开始使用了!
如果你只希望在使用特定“配置文件”时保存 .html 和 .py 文件,这会有点复杂,因为 Jupyter 不再使用配置文件的概念。
首先通过 bash 命令行创建一个新的配置文件名:
这将会在~/.jupyter_profile2/jupyter_notebook_config.py创建一个新的目录和文件。然后运行jupyter notebook,像往常一样工作。要切换回默认配置文件,你需要设置(手动、通过 shell 函数或 .bashrc)回到:
export JUPYTER_CONFIG_DIR=~/.jupyter
现在每次保存笔记本时,都会更新同名的 .py 和 .html 文件。在你的提交和拉取请求中添加这些文件,你将从每种文件格式中受益。
这是一个正在进行的项目的目录结构,并对文件命名有一些明确的规则。
示例目录结构
py` - 开发 # (实验室笔记风格) + [ISO 8601 日期]-[DS-缩写]-[2-4 字描述].ipynb + 2015-06-28-jw-initial-data-clean.html + 2015-06-28-jw-initial-data-clean.ipynb + 2015-06-28-jw-initial-data-clean.py + 2015-07-02-jw-coal-productivity-factors.html + 2015-07-02-jw-coal-productivity-factors.ipynb + 2015-07-02-jw-coal-productivity-factors.py - 交付 # (最终分析、代码、演示等) + Coal-mine-productivity.ipynb + Coal-mine-productivity.html + Coal-mine-productivity.py - 图形 + 2015-07-16-jw-production-vs-hours-worked.png - src # (模块和脚本) + init.py + load_coal_data.py + figures # (图形和图表) + production-vs-number-employees.png + production-vs-hours-worked.png - 数据 (备份,单独于版本控制) + coal_prod_cleaned.csv ```py ````
好处
这种工作流程和结构有很多好处。首要和主要的好处是它们创建了一个分析进展的历史记录。它也很容易搜索:
-
按日期 (
ls 2015-06*.ipynb) -
按作者 (
ls 2015*-jw-*.ipynb) -
按主题 (
ls *-coal-*.ipynb)
其次,在拉取请求过程中,拥有.py 文件可以让人快速查看哪些输入文本已更改,而拥有.html 文件则可以快速查看哪些输出已更改。使这成为一个无痛的后保存钩子,使得这种工作流程变得轻松。
最后,这种方法还有许多较小的优点,无法一一列举——如果你有问题或对模型有进一步改进的建议,请 联系我们! 更多相关信息,请查看来自 O'Reilly Media 的 相关视频。
简介: 乔纳森·惠特莫 是 SVDS 的数据科学家。在从事天体物理学博士后职位后,乔纳森成为了计算和天文学方面备受欢迎的演讲者。他对将机器学习和统计技术应用于工业问题感到兴奋,并开发了新颖的数据分析技术。
原始。经授权转载。
相关:
-
Python 中的统计数据分析
-
Jupyter+Spark+Mesos: 一个“有见地”的 Docker 镜像
-
数据科学入门 – Python