@@ -84,7 +84,7 @@ Esta es la razón por la que compartir modelos de lenguaje es fundamental: compa
-El *preentrenamiento* es el acto de entrenar un modelo desde cero: los pesos se inicializan de manera aleatória y el entrenamiento empieza sin un conocimiento previo.
+El *preentrenamiento* es el acto de entrenar un modelo desde cero: los pesos se inicializan de manera aleatoria y el entrenamiento empieza sin un conocimiento previo.

@@ -121,7 +121,7 @@ En esta sección, revisaremos la arquitectura general del Transformador. No te p
El modelo está compuesto por dos bloques:
* **Codificador (izquierda)**: El codificador recibe una entrada y construye una representación de ésta (sus características). Esto significa que el modelo está optimizado para conseguir un entendimiento a partir de la entrada.
-* **Decodificador (derecha)**: El decodificador usa la representacón del codificador (características) junto con otras entradas para generar una secuencia objetivo. Esto significa que el modelo está optimizado para generar salidas.
+* **Decodificador (derecha)**: El decodificador usa la representación del codificador (características) junto con otras entradas para generar una secuencia objetivo. Esto significa que el modelo está optimizado para generar salidas.

@@ -148,9 +148,9 @@ Ahora que tienes una idea de qué son las capas de atención, echemos un vistazo
## La arquitectura original
-La arquitectura del Transformador fue diseñada originalmente para traducción. Durante el entrenamiento, el codificador recibe entradas (oraciones) en un idioma dado, mientras que el decodificador recibe las mismas oraciones en el idioma objetivo. En el codificador, las capas de atención pueden usar todas las palabras en una oración (dado que, como vimos, la traducción de una palabra dada puede ser dependiente de lo que está antes y después en la oración). Por su parte, el decodificador trabaja de manera secuencial y sólo le puede prestar atención a las palabras en la oración que ya ha traducido (es decir, sólo las palabras antes de que la palabra se ha generado). Por ejemplo, cuando hemos predecido las primeras tres palabras del objetivo de traducción se las damos al decodificador, que luego usa todas las entradas del codificador para intentar predecir la cuarta palabra.
+La arquitectura del Transformador fue diseñada originalmente para traducción. Durante el entrenamiento, el codificador recibe entradas (oraciones) en un idioma dado, mientras que el decodificador recibe las mismas oraciones en el idioma objetivo. En el codificador, las capas de atención pueden usar todas las palabras en una oración (dado que, como vimos, la traducción de una palabra dada puede ser dependiente de lo que está antes y después en la oración). Por su parte, el decodificador trabaja de manera secuencial y sólo le puede prestar atención a las palabras en la oración que ya ha traducido (es decir, sólo las palabras antes de que la palabra se ha generado). Por ejemplo, cuando hemos predicho las primeras tres palabras del objetivo de traducción se las damos al decodificador, que luego usa todas las entradas del codificador para intentar predecir la cuarta palabra.
-Para acelerar el entrenamiento (cuando el modelo tiene acceso a las oraciones objetivo), al decodificador se le alimenta el objetivo completo, pero no puede usar palabras futuras (si tuviera acceso a la palabra en la posición 2 cuando trata de predecir la palabra en la posición 2, ¡el problema no sería muy dificil!). Por ejemplo, al intentar predecir la cuarta palabra, la capa de atención sólo tendría acceso a las palabras en las posiciones 1 a 3.
+Para acelerar el entrenamiento (cuando el modelo tiene acceso a las oraciones objetivo), al decodificador se le alimenta el objetivo completo, pero no puede usar palabras futuras (si tuviera acceso a la palabra en la posición 2 cuando trata de predecir la palabra en la posición 2, ¡el problema no sería muy difícil!). Por ejemplo, al intentar predecir la cuarta palabra, la capa de atención sólo tendría acceso a las palabras en las posiciones 1 a 3.
La arquitectura original del Transformador se veía así, con el codificador a la izquierda y el decodificador a la derecha:
@@ -159,13 +159,13 @@ La arquitectura original del Transformador se veía así, con el codificador a l

-Observa que la primera capa de atención en un bloque de decodificador presta atención a todas las entradas (pasadas) al decodificador, mientras que la segunda capa de atención usa la salida del codificador. De esta manera puede acceder a toda la oración de entrada para predecir de mejor manera la palabra actual. Esto es muy útil dado que diferentes idiomas pueden tener reglas gramaticales que ponen las palabras en órden distinto o algún contexto que se provee después puede ser útil para determinar la mejor traducción de una palabra dada.
+Observa que la primera capa de atención en un bloque de decodificador presta atención a todas las entradas (pasadas) al decodificador, mientras que la segunda capa de atención usa la salida del codificador. De esta manera puede acceder a toda la oración de entrada para predecir de mejor manera la palabra actual. Esto es muy útil dado que diferentes idiomas pueden tener reglas gramaticales que ponen las palabras en orden distinto o algún contexto que se provee después puede ser útil para determinar la mejor traducción de una palabra dada.
La *máscara de atención* también se puede usar en el codificador/decodificador para evitar que el modelo preste atención a algunas palabras especiales --por ejemplo, la palabra especial de relleno que hace que todas las entradas sean de la misma longitud cuando se agrupan oraciones.
## Arquitecturas vs. puntos de control
-A medida que estudiemos a profundidad los Transformadores, verás menciones a *arquitecturas*, *puntos de control* (*checkpoints*) y *modelos*. Estos términos tienen significados ligeramentes diferentes:
+A medida que estudiemos a profundidad los Transformadores, verás menciones a *arquitecturas*, *puntos de control* (*checkpoints*) y *modelos*. Estos términos tienen significados ligeramente diferentes:
* **Arquitecturas**: Este es el esqueleto del modelo -- la definición de cada capa y cada operación que sucede al interior del modelo.
* **Puntos de control**: Estos son los pesos que serán cargados en una arquitectura dada.
diff --git a/chapters/es/chapter1/5.mdx b/chapters/es/chapter1/5.mdx
index b06cb7b75..c39f00b73 100644
--- a/chapters/es/chapter1/5.mdx
+++ b/chapters/es/chapter1/5.mdx
@@ -9,7 +9,7 @@
Los modelos de codificadores usan únicamente el codificador del Transformador. En cada etapa, las capas de atención pueden acceder a todas las palabras de la oración inicial. Estos modelos se caracterizan generalmente por tener atención "bidireccional" y se suelen llamar modelos *auto-encoding*.
-El preentrenamiento de estos modelos generalmente gira en torno a corromper de alguna manera una oración dada (por ejemplo, ocultando aleatóriamente palabras en ella) y pidiéndole al modelo que encuentre o reconstruya la oración inicial.
+El preentrenamiento de estos modelos generalmente gira en torno a corromper de alguna manera una oración dada (por ejemplo, ocultando aleatoriamente palabras en ella) y pidiéndole al modelo que encuentre o reconstruya la oración inicial.
Los modelos de codificadores son más adecuados para tareas que requieren un entendimiento de la oración completa, como la clasificación de oraciones, reconocimiento de entidades nombradas (y más generalmente clasificación de palabras) y respuesta extractiva a preguntas.
diff --git a/chapters/es/chapter1/6.mdx b/chapters/es/chapter1/6.mdx
index 3cc3f9afb..653531431 100644
--- a/chapters/es/chapter1/6.mdx
+++ b/chapters/es/chapter1/6.mdx
@@ -7,7 +7,7 @@
-Los modelos de decodificadores usan únicamente el decodificador del Transformador. En cada etapa, para una palabra dada las capas de atención pueden acceder sólamente a las palabras que se ubican antes en la oración. Estos modelos se suelen llamar modelos *auto-regressive*.
+Los modelos de decodificadores usan únicamente el decodificador del Transformador. En cada etapa, para una palabra dada las capas de atención pueden acceder solamente a las palabras que se ubican antes en la oración. Estos modelos se suelen llamar modelos *auto-regressive*.
El preentrenamiento de los modelos de decodificadores generalmente gira en torno a la predicción de la siguiente palabra en la oración.
diff --git a/chapters/es/chapter1/7.mdx b/chapters/es/chapter1/7.mdx
index 0d48876a1..265781853 100644
--- a/chapters/es/chapter1/7.mdx
+++ b/chapters/es/chapter1/7.mdx
@@ -2,9 +2,9 @@
-Los modelos codificador/decodificador (tambén llamados *modelos secuencia a secuencia*) usan ambas partes de la arquitectura del Transformador. En cada etapa, las capas de atención del codificador pueden acceder a todas las palabras de la sencuencia inicial, mientras que las capas de atención del decodificador sólo pueden acceder a las palabras que se ubican antes de una palabra dada en el texto de entrada.
+Los modelos codificador/decodificador (también llamados *modelos secuencia a secuencia*) usan ambas partes de la arquitectura del Transformador. En cada etapa, las capas de atención del codificador pueden acceder a todas las palabras de la secuencia inicial, mientras que las capas de atención del decodificador sólo pueden acceder a las palabras que se ubican antes de una palabra dada en el texto de entrada.
-El preentrenamiento de estos modelos se puede hacer usando los objetivos de los modelos de codificadores o decodificadores, pero usualmente implican algo más complejo. Por ejemplo, [T5](https://huggingface.co/t5-base) está preentrenado al reemplazar segmentos aleatórios de texto (que pueden contener varias palabras) con una palabra especial que las oculta, y el objetivo es predecir el texto que esta palabra reemplaza.
+El preentrenamiento de estos modelos se puede hacer usando los objetivos de los modelos de codificadores o decodificadores, pero usualmente implican algo más complejo. Por ejemplo, [T5](https://huggingface.co/t5-base) está preentrenado al reemplazar segmentos aleatorios de texto (que pueden contener varias palabras) con una palabra especial que las oculta, y el objetivo es predecir el texto que esta palabra reemplaza.
Los modelos secuencia a secuencia son más adecuados para tareas relacionadas con la generación de nuevas oraciones dependiendo de una entrada dada, como resumir, traducir o responder generativamente preguntas.
diff --git a/chapters/es/chapter1/8.mdx b/chapters/es/chapter1/8.mdx
index 818575337..607e95510 100644
--- a/chapters/es/chapter1/8.mdx
+++ b/chapters/es/chapter1/8.mdx
@@ -29,4 +29,4 @@ print([r["token_str"] for r in result])
Cuando se le pide llenar la palabra faltante en estas dos oraciones, el modelo devuelve solo una respuesta agnóstica de género (*waiter/waitress*). Las otras son ocupaciones que se suelen asociar con un género específico -- y si, prostituta es una de las primeras 5 posibilidades que el modelo asocia con "mujer" y "trabajo". Esto sucede a pesar de que BERT es uno de los pocos modelos de Transformadores que no se construyeron basados en datos *raspados* de todo el internet, pero usando datos aparentemente neutrales (está entrenado con los conjuntos de datos de [Wikipedia en Inglés](https://huggingface.co/datasets/wikipedia) y [BookCorpus](https://huggingface.co/datasets/bookcorpus)).
-Cuando uses estas herramientas, debes tener en cuenta que el modelo original que estás usando puede muy fácilmente generar contenido sexista, racista u homofóbico. Ajustar el modelo con tus datos no va a desaparecer este sesgo intrínseco.
+Cuando uses estas herramientas, debes tener en cuenta que el modelo original que estás usando puede muy fácilmente generar contenido sexista, racista u homófobo. Ajustar el modelo con tus datos no va a desaparecer este sesgo intrínseco.
diff --git a/chapters/es/chapter2/4.mdx b/chapters/es/chapter2/4.mdx
index b20685498..e2b954efb 100644
--- a/chapters/es/chapter2/4.mdx
+++ b/chapters/es/chapter2/4.mdx
@@ -27,11 +27,12 @@
Los tokenizadores son uno de los componentes fundamentales del pipeline en NLP. Sirven para traducir texto en datos que los modelos puedan procesar; es decir, de texto a valores numéricos. En esta sección veremos en qué se fundamenta todo el proceso de tokenizado.
En las tareas de NLP, los datos generalmente ingresan como texto crudo. Por ejemplo:
+
```
Jim Henson era un titiritero
```
-Sin embargo, necesitamos una forma de convertir el texto crudo a valores numéricos para los modelos. Eso es precisamente lo que hacen los tokenizadores, y existe una variedad de formas en que puede hacerse. El objetivo final es obetener valores que sean cortos pero muy significativos para el modelo.
+Sin embargo, necesitamos una forma de convertir el texto crudo a valores numéricos para los modelos. Eso es precisamente lo que hacen los tokenizadores, y existe una variedad de formas en que puede hacerse. El objetivo final es obtener valores que sean cortos pero muy significativos para el modelo.
Veamos algunos algoritmos de tokenización, e intentemos atacar algunas preguntas que puedas tener.
@@ -40,12 +41,13 @@ Veamos algunos algoritmos de tokenización, e intentemos atacar algunas pregunta
El primer tokenizador que nos ocurre es el _word-based_ (_basado-en-palabras_). Es generalmente sencillo, con pocas normas, y generalmente da buenos resultados. Por ejemplo, en la imagen a continuación separamos el texto en palabras y buscamos una representación numérica.
+


-Existen varias formas de separar el texto. Por ejempĺo, podríamos usar los espacios para tokenizar usando Python y la función `split()`.
+Existen varias formas de separar el texto. Por ejemplo, podríamos usar los espacios para tokenizar usando Python y la función `split()`.
```py
tokenized_text = "Jim Henson era un titiritero".split()
@@ -55,6 +57,7 @@ print(tokenized_text)
```python out
['Jim', 'Henson', 'era', 'un', 'titiritero']
```
+
También hay variaciones de tokenizadores de palabras que tienen reglas adicionales para la puntuación. Con este tipo de tokenizador, podemos acabar con unos "vocabularios" bastante grandes, donde un vocabulario se define por el número total de tokens independientes que tenemos en nuestro corpus.
A cada palabra se le asigna un ID, empezando por 0 y subiendo hasta el tamaño del vocabulario. El modelo utiliza estos ID para identificar cada palabra.
@@ -69,13 +72,12 @@ Una forma de reducir la cantidad de tokens desconocidos es ir un poco más allá
-Character-based tokenizers split the text into characters, rather than words. This has two primary benefits:
-Un tokenizador _character-based_ separa el texto en caracteres, y no en palabras. Conllevando dos beneficios principales:
+Un tokenizador _character-based_ separa el texto en caracteres, y no en palabras. Esto conlleva dos beneficios principales:
- Obtenemos un vocabulario mucho más corto.
-- Habrá muchos menos tokens por fuera del vocabulatio conocido.
+- Habrá muchos menos tokens por fuera del vocabulario conocido.
-No obstante, pueden surgir incovenientes por los espacios en blanco y signos de puntuación.
+No obstante, pueden surgir inconvenientes por los espacios en blanco y signos de puntuación.

@@ -105,7 +107,7 @@ Este es un ejemplo que muestra cómo un algoritmo de tokenización de subpalabra
Estas subpalabras terminan aportando mucho significado semántico: por ejemplo, en el ejemplo anterior, "tokenización" se dividió en "token" y "ización", dos tokens que tienen un significado semántico y a la vez son eficientes en cuanto al espacio (sólo se necesitan dos tokens para representar una palabra larga). Esto nos permite tener una cobertura relativamente buena con vocabularios pequeños y casi sin tokens desconocidos.
-Este enfoque es especialmente útil en algunos idimas como el turco, donde se pueden formar palabras complejas (casi) arbitrariamente largas encadenando subpalabras.
+Este enfoque es especialmente útil en algunos idiomas como el turco, donde se pueden formar palabras complejas (casi) arbitrariamente largas encadenando subpalabras.
### Y más!
@@ -113,7 +115,7 @@ Como es lógico, existen muchas más técnicas. Por nombrar algunas:
- Byte-level BPE (a nivel de bytes), como usa GPT-2
- WordPiece, usado por BERT
-- SentencePiece or Unigram (pedazo de sentencia o unigrama), como se usa en los modelos multilengua
+- SentencePiece or Unigram (pedazo de sentencia o unigrama), como se usa en los modelos multilingües
A este punto, deberías tener conocimientos suficientes sobre el funcionamiento de los tokenizadores para empezar a utilizar la API.
@@ -130,10 +132,10 @@ tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
```
{#if fw === 'pt'}
-Al igual que `AutoModel`, la clase `AutoTokenizer` tomará la clase de tokenizador adecuada en la biblioteca basada en el nombre del punto de control, y se puede utilizar directamente con cualquier punto de control:
+Al igual que `AutoModel`, la clase `AutoTokenizer` tomará la clase de tokenizador adecuada en la librería basada en el nombre del punto de control, y se puede utilizar directamente con cualquier punto de control:
{:else}
-Al igual que `TFAutoModel`, la clase `AutoTokenizer` tomará la clase de tokenizador adecuada en la biblioteca basada en el nombre del punto de control, y se puede utilizar directamente con cualquier punto de control:
+Al igual que `TFAutoModel`, la clase `AutoTokenizer` tomará la clase de tokenizador adecuada en la librería basada en el nombre del punto de control, y se puede utilizar directamente con cualquier punto de control:
{/if}
@@ -154,6 +156,7 @@ tokenizer("Using a Transformer network is simple")
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
+
Guardar un tokenizador es idéntico a guardar un modelo:
```py
@@ -200,6 +203,7 @@ Este tokenizador es un tokenizador de subpalabras: divide las palabras hasta obt
### De tokens a IDs de entrada
La conversión a IDs de entrada se hace con el método del tokenizador `convert_tokens_to_ids()`:
+
```py
ids = tokenizer.convert_tokens_to_ids(tokens)
@@ -230,6 +234,7 @@ print(decoded_string)
```python out
'Using a Transformer network is simple'
```
+
Notemos que el método `decode` no sólo convierte los índices de nuevo en tokens, sino que también agrupa los tokens que formaban parte de las mismas palabras para producir una frase legible. Este comportamiento será extremadamente útil cuando utilicemos modelos que predigan texto nuevo (ya sea texto generado a partir de una indicación, o para problemas de secuencia a secuencia como la traducción o el resumen).
-A estas alturas deberías entender las operaciones atómicas que un tokenizador puede manejar: tokenización, conversión a IDs, y conversión de IDs de vuelta a una cadena. Sin embargo, sólo hemos rozado la punta del iceberg. En la siguiente sección, llevaremos nuestro enfoque a sus límites y echaremos un vistazo a cómo superarlos.
\ No newline at end of file
+A estas alturas deberías entender las operaciones atómicas que un tokenizador puede manejar: tokenización, conversión a IDs, y conversión de IDs de vuelta a una cadena. Sin embargo, sólo hemos rozado la punta del iceberg. En la siguiente sección, llevaremos nuestro enfoque a sus límites y echaremos un vistazo a cómo superarlos.
diff --git a/chapters/es/chapter2/6.mdx b/chapters/es/chapter2/6.mdx
index 443ee3ee2..489b35977 100644
--- a/chapters/es/chapter2/6.mdx
+++ b/chapters/es/chapter2/6.mdx
@@ -37,7 +37,7 @@ sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
```
-Aquí la varibale `model_inputs` contiene todo lo necesario para que un modelo opere bien. Para DistilBERT, que incluye los IDs de entrada también como la máscara de atención. Otros modelos que aceptan entradas adicionales también tendrán las salidas del objeto `tokenizer`.
+Aquí la variable `model_inputs` contiene todo lo necesario para que un modelo opere bien. Para DistilBERT, que incluye los IDs de entrada también como la máscara de atención. Otros modelos que aceptan entradas adicionales también tendrán las salidas del objeto `tokenizer`.
Como veremos en los ejemplos de abajo, este método es muy poderoso. Primero, puede tokenizar una sola secuencia:
@@ -58,14 +58,14 @@ model_inputs = tokenizer(sequences)
Puede rellenar de acuerdo a varios objetivos:
```py
-# Will pad the sequences up to the maximum sequence length
+# Rellenar las secuencias hasta la mayor longitud de secuencia
model_inputs = tokenizer(sequences, padding="longest")
-# Will pad the sequences up to the model max length
-# (512 for BERT or DistilBERT)
+# Rellenar las secuencias hasta la máxima longitud del modelo
+# (512 para BERT o DistilBERT)
model_inputs = tokenizer(sequences, padding="max_length")
-# Will pad the sequences up to the specified max length
+# Rellenar las secuencias hasta la máxima longitud especificada
model_inputs = tokenizer(sequences, padding="max_length", max_length=8)
```
@@ -74,26 +74,26 @@ También puede truncar secuencias:
```py
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
-# Will truncate the sequences that are longer than the model max length
-# (512 for BERT or DistilBERT)
+# Truncar las secuencias más largas que la máxima longitud del modelo
+# (512 para BERT o DistilBERT)
model_inputs = tokenizer(sequences, truncation=True)
-# Will truncate the sequences that are longer than the specified max length
+# Truncar las secuencias más largas que la longitud especificada
model_inputs = tokenizer(sequences, max_length=8, truncation=True)
```
-El objeto `tokenizer` puede manejar la conversión a tensores de frameworks específicos, los cuales pueden ser enviados directametne al modelo. Por ejemplo, en el siguiente código de ejemplo estamos solicitando al tokenizer que regrese los tensores de los distintos frameworks — `"pt"` regresa tensores de PyTorch, `"tf"` regresa tensores de TensorFlow, y `"np"` regresa arreglos de NumPy:
+El objeto `tokenizer` puede manejar la conversión a tensores de frameworks específicos, los cuales pueden ser enviados directamente al modelo. Por ejemplo, en el siguiente código de ejemplo estamos solicitando al tokenizer que regrese los tensores de los distintos frameworks — `"pt"` regresa tensores de PyTorch, `"tf"` regresa tensores de TensorFlow, y `"np"` regresa arreglos de NumPy:
```py
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
-# Returns PyTorch tensors
+# Devuelve tensores PyTorch
model_inputs = tokenizer(sequences, padding=True, return_tensors="pt")
-# Returns TensorFlow tensors
+# Devuelve tensores TensorFlow
model_inputs = tokenizer(sequences, padding=True, return_tensors="tf")
-# Returns NumPy arrays
+# Devuelve arrays Numpy
model_inputs = tokenizer(sequences, padding=True, return_tensors="np")
```
@@ -129,13 +129,14 @@ print(tokenizer.decode(ids))
"i've been waiting for a huggingface course my whole life."
```
-El tokenizador agregó la palabra especial `[CLS]` al principio y la palabra especial `[SEP]` al final. Esto se debe a que el modelo fue preentrenado con esos, así para obtener los mismos resultados por inferencia necesitamos agregarlos también. Nota que algunos modelos no agregan palabras especiales, o agregan unas distintas; los modelos también pueden agregar estas palabras especiales sólo al principio, o sólo al final. En cualquier caso, el tokenizador sabe cuáles son las esperadas y se encargará de ello por tí.
+El tokenizador agregó la palabra especial `[CLS]` al principio y la palabra especial `[SEP]` al final. Esto se debe a que el modelo fue preentrenado con esos, así para obtener los mismos resultados por inferencia necesitamos agregarlos también. Nota que algunos modelos no agregan palabras especiales, o agregan unas distintas; los modelos también pueden agregar estas palabras especiales sólo al principio, o sólo al final. En cualquier caso, el tokenizador sabe cuáles son las esperadas y se encargará de ello por tí.
-## Conclusión: Del tokenizador al moelo
+## Conclusión: Del tokenizador al modelo
Ahora que hemos visto todos los pasos individuales que el objeto `tokenizer` usa cuando se aplica a textos, veamos una última vez cómo maneja varias secuencias (¡relleno!), secuencias muy largas (¡truncado!), y múltiples tipos de tensores con su API principal:
{#if fw === 'pt'}
+
```py
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
@@ -148,7 +149,9 @@ sequences = ["I've been waiting for a HuggingFace course my whole life.", "So ha
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
output = model(**tokens)
```
+
{:else}
+
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
@@ -161,4 +164,5 @@ sequences = ["I've been waiting for a HuggingFace course my whole life.", "So ha
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="tf")
output = model(**tokens)
```
+
{/if}
diff --git a/chapters/es/chapter2/7.mdx b/chapters/es/chapter2/7.mdx
index 6d7c470c3..d8a0ac53f 100644
--- a/chapters/es/chapter2/7.mdx
+++ b/chapters/es/chapter2/7.mdx
@@ -1,4 +1,4 @@
-# ¡Haz completado el uso básico!
+# ¡Has completado el uso básico!
Model Hub para encontrar el mejor punto de control para tu tarea!"
+ explain: "Incorrecto; aunque algunos puntos de control y modelos son capaces de manejar varios lenguajes, no hay herramientas integradas para la selección automática de punto de control de acuerdo al lenguaje. ¡Deberías dirigirte a Model Hub para encontrar el mejor punto de control para tu tarea!"
}
]}
/>
@@ -140,7 +140,7 @@
},
{
text: "Un modelo que detecta automáticamente el lenguaje usado por sus entradas para cargar los pesos correctos",
- explain: "Incorrecto; auqneu algunos puntos de control y modelos son capaced de manejar varios lenguajes, no hay herramientas integradas para la selección automática de punto de control de acuerdo al lenguaje. ¡Deberías dirigirte a Model Hub para encontrar el mejor punto de control para tu tarea!"
+ explain: "Incorrecto; aunque algunos puntos de control y modelos son capaces de manejar varios lenguajes, no hay herramientas integradas para la selección automática de punto de control de acuerdo al lenguaje. ¡Deberías dirigirte a Model Hub para encontrar el mejor punto de control para tu tarea!"
}
]}
/>
@@ -173,7 +173,7 @@
]}
/>
-### 7. ¿Cuál es el punto de aplicar una funcion SoftMax a las salidas logits por un modelo de clasificación de secuencias?
+### 7. ¿Cuál es el punto de aplicar una función SoftMax a las salidas logits por un modelo de clasificación de secuencias?
-En el [Capítulo 2](/course/chapter2) exploramos como usar los tokenizadores y modelos preentrenados para realizar predicciones. Pero qué tal si deseas ajustar un modelo preentrenado con tu propio conjunto de datos ?
+En el [Capítulo 2](/course/chapter2) exploramos cómo usar los tokenizadores y modelos preentrenados para realizar predicciones. Pero, ¿qué pasa si deseas ajustar un modelo preentrenado con tu propio conjunto de datos?
{#if fw === 'pt'}
-* Como preparar un conjunto de datos grande desde el Hub.
-* Como usar la API de alto nivel del entrenador para ajustar un modelo.
-* Como usar un bucle personalizado de entrenamiento.
-* Como aprovechar la Accelerate library 🤗 para fácilmente ejecutar el bucle personalizado de entrenamiento en cualquier configuración distribuida.
+
+* Cómo preparar un conjunto de datos grande desde el Hub.
+* Cómo usar la API de alto nivel del entrenador para ajustar un modelo.
+* Cómo usar un bucle personalizado de entrenamiento.
+* Cómo aprovechar la librería 🤗 Accelerate para fácilmente ejecutar el bucle personalizado de entrenamiento en cualquier configuración distribuida.
{:else}
-* Como preparar un conjunto de datos grande desde el Hub.
-* Como usar Keras para ajustar un modelo.
-* Como usar Keras para obtener predicciones.
-* Como usar una métrica personalizada.
+
+* Cómo preparar un conjunto de datos grande desde el Hub.
+* Cómo usar Keras para ajustar un modelo.
+* Cómo usar Keras para obtener predicciones.
+* Cómo usar una métrica personalizada.
{/if}
diff --git a/chapters/es/chapter3/2.mdx b/chapters/es/chapter3/2.mdx
index eded26291..088bbfe03 100644
--- a/chapters/es/chapter3/2.mdx
+++ b/chapters/es/chapter3/2.mdx
@@ -47,6 +47,7 @@ loss = model(**batch).loss
loss.backward()
optimizer.step()
```
+
{:else}
Continuando con el ejemplo del [capítulo anterior](/course/chapter2), aquí mostraremos como podríamos entrenar un clasificador de oraciones/sentencias en TensorFlow:
@@ -55,7 +56,7 @@ import tensorflow as tf
import numpy as np
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
-# Same as before
+# Igual que antes
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
@@ -65,11 +66,12 @@ sequences = [
]
batch = dict(tokenizer(sequences, padding=True, truncation=True, return_tensors="tf"))
-# This is new
+# Esto es nuevo
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy")
labels = tf.convert_to_tensor([1, 1])
model.train_on_batch(batch, labels)
```
+
{/if}
Por supuesto, entrenando el modelo con solo dos oraciones no va a producir muy buenos resultados. Para obtener mejores resultados, debes preparar un conjunto de datos más grande.
@@ -79,14 +81,19 @@ En esta sección usaremos como ejemplo el conjunto de datos MRPC (Cuerpo de par
### Cargando un conjunto de datos desde el Hub
{#if fw === 'pt'}
+
{:else}
{/if}
-El Hub no solo contiene modelos; sino que también tiene múltiples conjunto de datos en diferentes idiomas. Puedes explorar los conjuntos de datos [aquí](https://huggingface.co/datasets), y recomendamos que trates de cargar y procesar un nuevo conjunto de datos una vez que hayas revisado esta sección (mira la documentación general [aquí](https://huggingface.co/docs/datasets/loading_datasets.html#from-the-huggingface-hub)). Por ahora, enfoquémonos en el conjunto de datos MRPC! Este es uno de los 10 conjuntos de datos que comprende el [punto de referencia GLUE](https://gluebenchmark.com/), el cual es un punto de referencia académico que se usa para medir el desempeño de modelos ML sobre 10 tareas de clasificación de texto.
+El Hub no solo contiene modelos; sino que también tiene múltiples conjunto de datos en diferentes idiomas. Puedes explorar los conjuntos de datos [aquí](https://huggingface.co/datasets), y recomendamos que trates de cargar y procesar un nuevo conjunto de datos una vez que hayas revisado esta sección (mira la documentación general [aquí](https://huggingface.co/docs/datasets/loading)). Por ahora, enfoquémonos en el conjunto de datos MRPC! Este es uno de los 10 conjuntos de datos que comprende el [punto de referencia GLUE](https://gluebenchmark.com/), el cual es un punto de referencia académico que se usa para medir el desempeño de modelos ML sobre 10 tareas de clasificación de texto.
+
+La librería 🤗 Datasets provee un comando muy simple para descargar y memorizar un conjunto de datos en el Hub. Podemos descargar el conjunto de datos de la siguiente manera:
-La Libreria Datasets 🤗 provee un comando muy simple para descargar y memorizar un conjunto de datos en el Hub. Podemos descargar el conjunto de datos de la siguiente manera:
+
+⚠️ **Advertencia** Asegúrate de que `datasets` esté instalado ejecutando `pip install datasets`. Luego, carga el conjunto de datos MRPC y imprímelo para ver qué contiene.
+
```py
from datasets import load_dataset
@@ -147,13 +154,14 @@ Internamente, `label` es del tipo de dato `ClassLabel`, y la asociación de valo
-✏️ **Inténtalo!** Mira el elemento 15 del conjunto de datos de entrenamiento y el elemento 87 del conjunto de datos de validación. Cuáles son sus etiquetas?
+✏️ **¡Inténtalo!** Mira el elemento 15 del conjunto de datos de entrenamiento y el elemento 87 del conjunto de datos de validación. Cuáles son sus etiquetas?
### Preprocesando un conjunto de datos
{#if fw === 'pt'}
+
{:else}
@@ -179,7 +187,7 @@ inputs
```
```python out
-{
+{
'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
@@ -190,8 +198,7 @@ Nosotros consideramos las llaves `input_ids` y `attention_mask` en el [Capítulo
-✏️ **Inténtalo!** Toma el elemento 15 del conjunto de datos de entrenamiento y tokeniza las dos oraciones independientemente y como un par. Cuál es la diferencia entre los dos resultados?
-
+✏️ **¡Inténtalo!** Toma el elemento 15 del conjunto de datos de entrenamiento y tokeniza las dos oraciones independientemente y como un par. Cuál es la diferencia entre los dos resultados?
@@ -216,15 +223,15 @@ De esta manera vemos que el modelo espera las entradas de la siguiente forma `[C
Como puedes observar, las partes de la entrada que corresponden a `[CLS] sentence1 [SEP]` todas tienen un tipo de token ID `0`, mientras que las otras partes que corresponden a `sentence2 [SEP]`, todas tienen tipo ID `1`.
-Nótese que si seleccionas un punto de control diferente, no necesariamente tendrás el `token_type_ids` en tus entradas tonenizadas (por ejemplo, ellas no aparecen si usas un modelo DistilBERT). Estas aparecen cuando el modelo sabe que hacer con ellas, porque las ha visto durante su etapa de preentrenamiento.
+Nótese que si seleccionas un punto de control diferente, no necesariamente tendrás el `token_type_ids` en tus entradas tokenizadas (por ejemplo, ellas no aparecen si usas un modelo DistilBERT). Estas aparecen cuando el modelo sabe que hacer con ellas, porque las ha visto durante su etapa de preentrenamiento.
-Aquí, BERT esta preentrenado con tokens de tipo ID, y además del objetivo de modelado de lenguaje oculto que mencionamos en el [Capítulo 1](/course/chapter1), también tiene el objetivo llamado _predicción de la siguiente oración_. El objectivo con esta tarea es modelar la relación entre pares de oraciones.
+Aquí, BERT está preentrenado con tokens de tipo ID, y además del objetivo de modelado de lenguaje oculto que mencionamos en el [Capítulo 1](/course/chapter1), también tiene el objetivo llamado _predicción de la siguiente oración_. El objetivo con esta tarea es modelar la relación entre pares de oraciones.
-Para predecir la siguiente oración, el modelo recibe pares de oraciones (con tokens ocultados aleatoriamente) y se le pide que prediga si la segunda secuencia sigue a la primera. Para que la tarea no sea tan simple, la mitad de las veces las oraciones estan seguidas en el texto original de donde se obtuvieron, y la otra mitad las oraciones vienen de dos documentos distintos.
+Para predecir la siguiente oración, el modelo recibe pares de oraciones (con tokens ocultados aleatoriamente) y se le pide que prediga si la segunda secuencia sigue a la primera. Para que la tarea no sea tan simple, la mitad de las veces las oraciones están seguidas en el texto original de donde se obtuvieron, y la otra mitad las oraciones vienen de dos documentos distintos.
-En general, no debes preocuparte si los `token_type_ids` estan o no en las entradas tokenizadas: con tal que uses el mismo punto de control para el tokenizador y el modelo, todo estará bien porque el tokenizador sabe que pasarle a su modelo.
+En general, no debes preocuparte si los `token_type_ids` están o no en las entradas tokenizadas: con tal de que uses el mismo punto de control para el tokenizador y el modelo, todo estará bien porque el tokenizador sabe qué pasarle a su modelo.
-Ahora que hemos visto como nuestro tokenizador puede trabajar con un par de oraciones, podemos usarlo para tokenizar todo el conjunto de datos: como en el [capítulo anterior](/course/chapter2), podemos darle al tokenizador una lista de pares de oraciones, dándole la lista de las primeras oraciones, y luego la lista de las segundas oraciones. Esto también es compatible con las opciones de relleno y truncamiento que vimos en el [Capítulo 2](/course/chapter2). Por lo tanto, una manera de preprocessar el conjunto de datos de entrenamiento sería:
+Ahora que hemos visto como nuestro tokenizador puede trabajar con un par de oraciones, podemos usarlo para tokenizar todo el conjunto de datos: como en el [capítulo anterior](/course/es/chapter2), podemos darle al tokenizador una lista de pares de oraciones, dándole la lista de las primeras oraciones, y luego la lista de las segundas oraciones. Esto también es compatible con las opciones de relleno y truncamiento que vimos en el [Capítulo 2](/course/chapter2). Por lo tanto, una manera de preprocesar el conjunto de datos de entrenamiento sería:
```py
tokenized_dataset = tokenizer(
@@ -235,18 +242,18 @@ tokenized_dataset = tokenizer(
)
```
-Esto funciona bien, pero tiene la desventaja de que devuelve un diccionario (con nuestras llaves, `input_ids`, `attention_mask`, and `token_type_ids`, y valores que son listas de listas). Además va a trabajar solo si tienes suficiente memoria principal para almacenar todo el conjunto de datos durante la tokenización (mientras que los conjuntos de datos de la librería Datasets 🤗 son archivos [Apache Arrow](https://arrow.apache.org/) almacenados en disco, y así solo mantienes en memoria las muestras que necesitas).
+Esto funciona bien, pero tiene la desventaja de que devuelve un diccionario (con nuestras llaves, `input_ids`, `attention_mask`, and `token_type_ids`, y valores que son listas de listas). Además va a trabajar solo si tienes suficiente memoria principal para almacenar todo el conjunto de datos durante la tokenización (mientras que los conjuntos de datos de la librería 🤗 Datasets son archivos [Apache Arrow](https://arrow.apache.org/) almacenados en disco, y así solo mantienes en memoria las muestras que necesitas).
-Para mantener los datos como un conjunto de datos, usaremos el método [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map). Este también nos ofrece una flexibilidad adicional en caso de que necesitemos preprocesamiento mas allá de la tokenización. El método `map()` trabaja aplicando una función sobre cada elemento del conjunto de datos, así que definamos una función para tokenizar nuestras entradas:
+Para mantener los datos como un conjunto de datos, usaremos el método [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map). Este también nos ofrece una flexibilidad adicional en caso de que necesitemos preprocesamiento mas allá de la tokenización. El método `map()` trabaja aplicando una función sobre cada elemento del conjunto de datos, así que definamos una función para tokenizar nuestras entradas:
```py
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
```
-Esta función recibe un diccionario (como los elementos de nuestro conjunto de datos) y devuelve un nuevo diccionario con las llaves `input_ids`, `attention_mask`, y `token_type_ids`. Nótese que también funciona si el diccionario `example` contiene múltiples elementos (cada llave con una lista de oraciones) debido a que el `tokenizador` funciona con listas de pares de oraciones, como se vio anteriormente. Esto nos va a permitir usar la opción `batched=True` en nuestra llamada a `map()`, lo que acelera la tokenización significativamente. El `tokenizador` es respaldado por un tokenizador escrito en Rust que viene de la libreria [Tokenizadores 🤗](https://github.com/huggingface/tokenizers). Este tokenizador puede ser muy rápido, pero solo si le da muchas entradas al mismo tiempo.
+Esta función recibe un diccionario (como los elementos de nuestro conjunto de datos) y devuelve un nuevo diccionario con las llaves `input_ids`, `attention_mask`, y `token_type_ids`. Nótese que también funciona si el diccionario `example` contiene múltiples elementos (cada llave con una lista de oraciones) debido a que el `tokenizador` funciona con listas de pares de oraciones, como se vio anteriormente. Esto nos va a permitir usar la opción `batched=True` en nuestra llamada a `map()`, lo que acelera la tokenización significativamente. El `tokenizador` es respaldado por un tokenizador escrito en Rust que viene de la librería [🤗 Tokenizers](https://github.com/huggingface/tokenizers). Este tokenizador puede ser muy rápido, pero solo si le da muchas entradas al mismo tiempo.
-Nótese que por ahora hemos dejado el argumento `padding` fuera de nuestra función de tokenización. Esto es porque rellenar todos los elementos hasta su máxima longitud no es eficiente: es mejor rellenar los elememtos cuando se esta construyendo el lote, debido a que solo debemos rellenar hasta la máxima longitud en el lote, pero no en todo el conjunto de datos. Esto puede ahorrar mucho tiempo y poder de processamiento cuando las entradas tienen longitudes variables.
+Nótese que por ahora hemos dejado el argumento `padding` fuera de nuestra función de tokenización. Esto es porque rellenar todos los elementos hasta su máxima longitud no es eficiente: es mejor rellenar los elementos cuando se esta construyendo el lote, debido a que solo debemos rellenar hasta la máxima longitud en el lote, pero no en todo el conjunto de datos. Esto puede ahorrar mucho tiempo y poder de procesamiento cuando las entradas tienen longitudes variables.
Aquí se muestra como se aplica la función de tokenización a todo el conjunto de datos en un solo paso. Estamos usando `batched=True` en nuestra llamada a `map` para que la función sea aplicada a múltiples elementos de nuestro conjunto de datos al mismo tiempo, y no a cada elemento por separado. Esto permite un preprocesamiento más rápido.
@@ -255,7 +262,7 @@ tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
```
-La manera en que la libreria 🤗 aplica este procesamiento es a través de campos añadidos al conjunto de datos, uno por cada diccionario devuelto por la función de preprocesamiento.
+La manera en que la librería 🤗 Datasets aplica este procesamiento es a través de campos añadidos al conjunto de datos, uno por cada diccionario devuelto por la función de preprocesamiento.
```python out
DatasetDict({
@@ -274,7 +281,7 @@ DatasetDict({
})
```
-Hasta puedes usar multiprocesamiento cuando aplicas la función de preprocesamiento con `map()` pasando el argumento `num_proc`. Nosotros no usamos esta opción porque los Tokenizadores de la libreria 🤗 usa múltiples hilos de procesamiento para tokenizar rápidamente nuestros elementos, pero sino estas usando un tokenizador rápido respaldado por esta libreria, esta opción puede acelerar tu preprocesamiento.
+Hasta puedes usar multiprocesamiento cuando aplicas la función de preprocesamiento con `map()` pasando el argumento `num_proc`. Nosotros no usamos esta opción porque los tokenizadores de la librería 🤗 Tokenizers usa múltiples hilos de procesamiento para tokenizar rápidamente nuestros elementos, pero sino estas usando un tokenizador rápido respaldado por esta librería, esta opción puede acelerar tu preprocesamiento.
Nuestra función `tokenize_function` devuelve un diccionario con las llaves `input_ids`, `attention_mask`, y `token_type_ids`, así que esos tres campos son adicionados a todas las divisiones de nuestro conjunto de datos. Nótese que pudimos haber cambiado los campos existentes si nuestra función de preprocesamiento hubiese devuelto un valor nuevo para cualquiera de las llaves en el conjunto de datos al que le aplicamos `map()`.
@@ -293,20 +300,24 @@ La función responsable de juntar los elementos dentro de un lote es llamada *fu
{/if}
-Para poner esto en práctica, tenemos que definir una función de cotejo que aplique la cantidad correcta de relleno a los elementos del conjunto de datos que queremos agrupar. Afortundamente, la libreria Transformers de 🤗 nos provee esta función mediante `DataCollatorWithPadding`. Esta recibe un tokenizador cuando la creas (para saber cual token de relleno se debe usar, y si el modelo espera el relleno a la izquierda o la derecha en las entradas) y hace todo lo que necesitas:
+Para poner esto en práctica, tenemos que definir una función de cotejo que aplique la cantidad correcta de relleno a los elementos del conjunto de datos que queremos agrupar. Afortunadamente, la librería 🤗 Transformers nos provee esta función mediante `DataCollatorWithPadding`. Esta recibe un tokenizador cuando la creas (para saber cual token de relleno se debe usar, y si el modelo espera el relleno a la izquierda o la derecha en las entradas) y hace todo lo que necesitas:
{#if fw === 'pt'}
+
```py
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
+
{:else}
+
```py
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
```
+
{/if}
Para probar este nuevo juguete, tomemos algunos elementos de nuestro conjunto de datos de entrenamiento para agruparlos. Aquí, removemos las columnas `idx`, `sentence1`, and `sentence2` ya que éstas no se necesitan y contienen cadenas (y no podemos crear tensores con cadenas), miremos las longitudes de cada elemento en el lote.
@@ -346,20 +357,19 @@ batch = data_collator(samples)
'labels': torch.Size([8])}
```
-Luce bién! Ahora que hemos convertido el texto crudo a lotes que nuestro modelo puede aceptar, estamos listos para ajustarlo!
+¡Luce bien! Ahora que hemos convertido el texto crudo a lotes que nuestro modelo puede aceptar, estamos listos para ajustarlo!
{/if}
-✏️ **Inténtalo!** Reproduce el preprocesamiento en el conjunto de datos GLUE SST-2. Es un poco diferente ya que esta compuesto de oraciones individuales en lugar de pares, pero el resto de lo que hicimos deberia ser igual. Para un reto mayor, intenta escribir una función de preprocesamiento que trabaje con cualquiera de las tareas GLUE.
+✏️ **¡Inténtalo!** Reproduce el preprocesamiento en el conjunto de datos GLUE SST-2. Es un poco diferente ya que esta compuesto de oraciones individuales en lugar de pares, pero el resto de lo que hicimos debería ser igual. Para un reto mayor, intenta escribir una función de preprocesamiento que trabaje con cualquiera de las tareas GLUE.
{#if fw === 'tf'}
-Ahora que tenemos nuestro conjunto de datos y el cotejador de datos, necesitamos juntarlos. Nosotros podriamos cargar lotes de datos y cotejarlos, pero eso sería mucho trabajo, y probablemente no muy eficiente. En cambio, existe un método que ofrece una solución eficiente para este problema: `to_tf_dataset()`. Este envuelve un `tf.data.Dataset` alrededor de tu conjunto de datos, con una función opcional de cotejo. `tf.data.Dataset` es un formato nativo de TensorFlow que Keras puede usar con el `model.fit()`, así este método convierte inmediatamente un conjunto de datos 🤗 a un formato que viene listo para entrenamiento. Veámoslo en acción con nuestro conjunto de datos.
-
+Ahora que tenemos nuestro conjunto de datos y el cotejador de datos, necesitamos juntarlos. Nosotros podríamos cargar lotes de datos y cotejarlos, pero eso sería mucho trabajo, y probablemente no muy eficiente. En cambio, existe un método que ofrece una solución eficiente para este problema: `to_tf_dataset()`. Este envuelve un `tf.data.Dataset` alrededor de tu conjunto de datos, con una función opcional de cotejo. `tf.data.Dataset` es un formato nativo de TensorFlow que Keras puede usar con el `model.fit()`, así este método convierte inmediatamente un conjunto de datos 🤗 a un formato que viene listo para entrenamiento. Veámoslo en acción con nuestro conjunto de datos.
```py
tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
@@ -379,6 +389,6 @@ tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
)
```
-Y eso es todo! Ahora podemos usar esos conjuntos de datos en nuestra próxima clase, donde el entrenamiento será mas sencillo después de todo el trabajo de preprocesamiento de datos.
+¡Y eso es todo! Ahora podemos usar esos conjuntos de datos en nuestra próxima clase, donde el entrenamiento será mas sencillo después de todo el trabajo de preprocesamiento de datos.
{/if}
diff --git a/chapters/es/chapter3/3.mdx b/chapters/es/chapter3/3.mdx
new file mode 100644
index 000000000..83bacfffd
--- /dev/null
+++ b/chapters/es/chapter3/3.mdx
@@ -0,0 +1,180 @@
+
+
+# Ajuste de un modelo con la API Trainer
+
+
+
+
+
+🤗 Transformers incluye una clase `Trainer` para ayudarte a ajustar cualquiera de los modelos preentrenados proporcionados en tu dataset. Una vez que hayas hecho todo el trabajo de preprocesamiento de datos de la última sección, sólo te quedan unos pocos pasos para definir el `Trainer`. La parte más difícil será preparar el entorno para ejecutar `Trainer.train()`, ya que se ejecutará muy lentamente en una CPU. Si no tienes una GPU preparada, puedes acceder a GPUs o TPUs gratuitas en [Google Colab](https://colab.research.google.com/).
+
+Los siguientes ejemplos de código suponen que ya has ejecutado los ejemplos de la sección anterior. Aquí tienes un breve resumen de lo que necesitas:
+
+```py
+from datasets import load_dataset
+from transformers import AutoTokenizer, DataCollatorWithPadding
+
+raw_datasets = load_dataset("glue", "mrpc")
+checkpoint = "bert-base-uncased"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+
+def tokenize_function(example):
+ return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
+
+
+tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
+data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+```
+
+### Entrenamiento
+
+El primer paso antes de que podamos definir nuestro `Trainer` es definir una clase `TrainingArguments` que contendrá todos los hiperparámetros que el `Trainer` utilizará para el entrenamiento y la evaluación del modelo. El único argumento que tienes que proporcionar es el directorio donde se guardarán tanto el modelo entrenado como los puntos de control (checkpoints). Para los demás parámetros puedes dejar los valores por defecto, deberían funcionar bastante bien para un ajuste básico.
+
+```py
+from transformers import TrainingArguments
+
+training_args = TrainingArguments("test-trainer")
+```
+
+
+
+💡 Si quieres subir automáticamente tu modelo al Hub durante el entrenamiento, incluye `push_to_hub=True` en `TrainingArguments`. Aprenderemos más sobre esto en el [Capítulo 4](/course/chapter4/3).
+
+
+
+El segundo paso es definir nuestro modelo. Como en el [capítulo anterior](/course/chapter2), utilizaremos la clase `AutoModelForSequenceClassification`, con dos etiquetas:
+
+```py
+from transformers import AutoModelForSequenceClassification
+
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+```
+
+Observarás que, a diferencia del [Capítulo 2](/course/chapter2), aparece una advertencia después de instanciar este modelo preentrenado. Esto se debe a que BERT no ha sido preentrenado para la clasificación de pares de frases, por lo que la cabeza del modelo preentrenado se ha eliminado y en su lugar se ha añadido una nueva cabeza adecuada para la clasificación de secuencias. Las advertencias indican que algunos pesos no se han utilizado (los correspondientes a la cabeza de preentrenamiento eliminada) y que otros se han inicializado aleatoriamente (los correspondientes a la nueva cabeza). La advertencia concluye animándote a entrenar el modelo, que es exactamente lo que vamos a hacer ahora.
+
+Una vez que tenemos nuestro modelo, podemos definir un `Trainer` pasándole todos los objetos construidos hasta ahora: el `model`, los `training_args`, los datasets de entrenamiento y validación, nuestro `data_collator`, y nuestro `tokenizer`:
+
+```py
+from transformers import Trainer
+
+trainer = Trainer(
+ model,
+ training_args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+)
+```
+
+Ten en cuenta que cuando pasas el `tokenizer` como hicimos aquí, el `data_collator` por defecto utilizado por el `Trainer` será un `DataCollatorWithPadding` como definimos anteriormente, por lo que puedes omitir la línea `data_collator=data_collator`. De todas formas, era importante mostrarte esta parte del proceso en la sección 2.
+
+Para ajustar el modelo en nuestro dataset, sólo tenemos que llamar al método `train()` de nuestro `Trainer`:
+
+```py
+trainer.train()
+```
+
+Esto iniciará el ajuste (que debería tardar un par de minutos en una GPU) e informará de la training loss cada 500 pasos. Sin embargo, no te dirá lo bien (o mal) que está rindiendo tu modelo. Esto se debe a que:
+
+1. No le hemos dicho al `Trainer` que evalúe el modelo durante el entrenamiento especificando un valor para `evaluation_strategy`: `steps` (evaluar cada `eval_steps`) o `epoch` (evaluar al final de cada época).
+2. No hemos proporcionado al `Trainer` una función `compute_metrics()` para calcular una métrica durante dicha evaluación (de lo contrario, la evaluación sólo habría impreso la pérdida, que no es un número muy intuitivo).
+
+### Evaluación
+
+Veamos cómo podemos construir una buena función `compute_metrics()` para utilizarla la próxima vez que entrenemos. La función debe tomar un objeto `EvalPrediction` (que es una tupla nombrada con un campo `predictions` y un campo `label_ids`) y devolverá un diccionario que asigna cadenas a flotantes (las cadenas son los nombres de las métricas devueltas, y los flotantes sus valores). Para obtener algunas predicciones de nuestro modelo, podemos utilizar el comando `Trainer.predict()`:
+
+```py
+predictions = trainer.predict(tokenized_datasets["validation"])
+print(predictions.predictions.shape, predictions.label_ids.shape)
+```
+
+```python out
+(408, 2) (408,)
+```
+
+La salida del método `predict()` es otra tupla con tres campos: `predictions`, `label_ids`, y `metrics`. El campo `metrics` sólo contendrá la pérdida en el dataset proporcionado, así como algunas métricas de tiempo (cuánto se tardó en predecir, en total y de media). Una vez que completemos nuestra función `compute_metrics()` y la pasemos al `Trainer`, ese campo también contendrá las métricas devueltas por `compute_metrics()`.
+
+Como puedes ver, `predictions` es una matriz bidimensional con forma 408 x 2 (408 es el número de elementos del dataset que hemos utilizado). Esos son los logits de cada elemento del dataset que proporcionamos a `predict()` (como viste en el [capítulo anterior](/curso/capítulo2), todos los modelos Transformer devuelven logits). Para convertirlos en predicciones que podamos comparar con nuestras etiquetas, necesitamos tomar el índice con el valor máximo en el segundo eje:
+
+```py
+import numpy as np
+
+preds = np.argmax(predictions.predictions, axis=-1)
+```
+
+Ahora podemos comparar esas predicciones `preds` con las etiquetas. Para construir nuestra función `compute_metric()`, nos basaremos en las métricas de la librería 🤗 [Evaluate](https://github.com/huggingface/evaluate/). Podemos cargar las métricas asociadas al dataset MRPC tan fácilmente como cargamos el dataset, esta vez con la función `evaluate.load()`. El objeto devuelto tiene un método `compute()` que podemos utilizar para calcular de la métrica:
+
+```py
+import evaluate
+
+metric = evaluate.load("glue", "mrpc")
+metric.compute(predictions=preds, references=predictions.label_ids)
+```
+
+```python out
+{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
+```
+
+Los resultados exactos que obtengas pueden variar, ya que la inicialización aleatoria de la cabeza del modelo podría cambiar las métricas obtenidas. Aquí, podemos ver que nuestro modelo tiene una precisión del 85,78% en el conjunto de validación y una puntuación F1 de 89,97. Estas son las dos métricas utilizadas para evaluar los resultados en el dataset MRPC para la prueba GLUE. La tabla del [paper de BERT](https://arxiv.org/pdf/1810.04805.pdf) recoge una puntuación F1 de 88,9 para el modelo base. Se trataba del modelo "uncased" (el texto se reescribe en minúsculas antes de la tokenización), mientras que nosotros hemos utilizado el modelo "cased" (el texto se tokeniza sin reescribir), lo que explica el mejor resultado.
+
+Juntándolo todo obtenemos nuestra función `compute_metrics()`:
+
+```py
+def compute_metrics(eval_preds):
+ metric = evaluate.load("glue", "mrpc")
+ logits, labels = eval_preds
+ predictions = np.argmax(logits, axis=-1)
+ return metric.compute(predictions=predictions, references=labels)
+```
+
+Y para ver cómo se utiliza para informar de las métricas al final de cada época, así es como definimos un nuevo `Trainer` con nuestra función `compute_metrics()`:
+
+```py
+training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+
+trainer = Trainer(
+ model,
+ training_args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+ compute_metrics=compute_metrics,
+)
+```
+
+Ten en cuenta que hemos creado un nuevo `TrainingArguments` con su `evaluation_strategy` configurado como `"epoch"` y un nuevo modelo. De lo contrario sólo estaríamos continuando el entrenamiento del modelo que ya habíamos entrenado. Para lanzar una nueva ejecución de entrenamiento, ejecutamos:
+
+```py
+trainer.train()
+```
+
+Esta vez, nos informará de la pérdida de validación y las métricas al final de cada época, además de la pérdida de entrenamiento. De nuevo, la puntuación exacta de precisión/F1 que alcances puede ser un poco diferente de la que encontramos nosotros, debido a la inicialización aleatoria del modelo, pero debería estar en el mismo rango.
+
+El `Trainer` funciona en múltiples GPUs o TPUs y proporciona muchas opciones, como el entrenamiento de precisión mixta (usa `fp16 = True` en tus argumentos de entrenamiento). Repasaremos todo lo que ofrece en el capítulo 10.
+
+Con esto concluye la introducción al ajuste utilizando la API de `Trainer`. En el [Capítulo 7](/course/chapter7) se dará un ejemplo de cómo hacer esto para las tareas más comunes de PLN, pero ahora veamos cómo hacer lo mismo en PyTorch puro.
+
+
+
+✏️ **¡Inténtalo!** Ajusta un modelo sobre el dataset GLUE SST-2 utilizando el procesamiento de datos que has implementado en la sección 2.
+
+
diff --git a/chapters/es/chapter3/3_tf.mdx b/chapters/es/chapter3/3_tf.mdx
new file mode 100644
index 000000000..34f5dcb69
--- /dev/null
+++ b/chapters/es/chapter3/3_tf.mdx
@@ -0,0 +1,203 @@
+
+
+# Ajuste de un modelo con Keras
+
+
+
+Una vez que hayas realizado todo el trabajo de preprocesamiento de datos de la última sección, sólo te quedan unos pocos pasos para entrenar el modelo. Sin embargo, ten en cuenta que el comando `model.fit()` se ejecutará muy lentamente en una CPU. Si no dispones de una GPU, puedes acceder a GPUs o TPUs gratuitas en [Google Colab](https://colab.research.google.com/).
+
+Los siguientes ejemplos de código suponen que ya has ejecutado los ejemplos de la sección anterior. Aquí tienes un breve resumen de lo que necesitas:
+
+```py
+from datasets import load_dataset
+from transformers import AutoTokenizer, DataCollatorWithPadding
+import numpy as np
+
+raw_datasets = load_dataset("glue", "mrpc")
+checkpoint = "bert-base-uncased"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+
+def tokenize_function(example):
+ return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
+
+
+tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
+
+data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
+
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "token_type_ids"],
+ label_cols=["labels"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+
+tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "token_type_ids"],
+ label_cols=["labels"],
+ shuffle=False,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+```
+
+### Entrenamiento
+
+Los modelos TensorFlow importados de 🤗 Transformers ya son modelos Keras. A continuación, una breve introducción a Keras.
+
+
+
+Eso significa que, una vez que tenemos nuestros datos, se requiere muy poco trabajo para empezar a entrenar con ellos.
+
+
+
+Como en el [capítulo anterior](/course/chapter2), utilizaremos la clase `TFAutoModelForSequenceClassification`, con dos etiquetas:
+
+```py
+from transformers import TFAutoModelForSequenceClassification
+
+model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+```
+
+Observarás que, a diferencia del [Capítulo 2](/course/es/chapter2), aparece una advertencia después de instanciar este modelo preentrenado. Esto se debe a que BERT no ha sido preentrenado para la clasificación de pares de frases, por lo que la cabeza del modelo preentrenado se ha eliminado y en su lugar se ha añadido una nueva cabeza adecuada para la clasificación de secuencias. Las advertencias indican que algunos pesos no se han utilizado (los correspondientes a la cabeza de preentrenamiento eliminada) y que otros se han inicializado aleatoriamente (los correspondientes a la nueva cabeza). La advertencia concluye animándote a entrenar el modelo, que es exactamente lo que vamos a hacer ahora.
+
+Para afinar el modelo en nuestro dataset, sólo tenemos que compilar nuestro modelo con `compile()` y luego pasar nuestros datos al método `fit()`. Esto iniciará el proceso de ajuste (que debería tardar un par de minutos en una GPU) e informará de la pérdida de entrenamiento a medida que avanza, además de la pérdida de validación al final de cada época.
+
+
+
+Ten en cuenta que los modelos 🤗 Transformers tienen una característica especial que la mayoría de los modelos Keras no tienen - pueden usar automáticamente una pérdida apropiada que calculan internamente. Usarán esta pérdida por defecto si no estableces un argumento de pérdida en `compile()`. Tea en cuenta que para utilizar la pérdida interna tendrás que pasar las etiquetas como parte de la entrada, en vez de como una etiqueta separada como es habitual en los modelos Keras. Veremos ejemplos de esto en la Parte 2 del curso, donde definir la función de pérdida correcta puede ser complicado. Para la clasificación de secuencias, sin embargo, una función de pérdida estándar de Keras funciona bien, así que eso es lo que usaremos aquí.
+
+
+
+```py
+from tensorflow.keras.losses import SparseCategoricalCrossentropy
+
+model.compile(
+ optimizer="adam",
+ loss=SparseCategoricalCrossentropy(from_logits=True),
+ metrics=["accuracy"],
+)
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_validation_dataset,
+)
+```
+
+
+
+Ten en cuenta un fallo muy común aquí: por poder, _puedes_ pasar simplemente el nombre de la función de pérdida como una cadena a Keras, pero por defecto Keras asumirá que ya has aplicado una función softmax a tus salidas. Sin embargo, muchos modelos devuelven los valores justo antes de que se aplique la función softmax, también conocidos como _logits_. Tenemos que decirle a la función de pérdida que eso es lo que hace nuestro modelo, y la única manera de hacerlo es llamándola directamente, en lugar de pasar su nombre con una cadena.
+
+
+
+### Mejorar el rendimiento del entrenamiento
+
+
+
+Si ejecutas el código anterior seguro que funciona, pero comprobarás que la pérdida sólo disminuye lenta o esporádicamente. La causa principal es la _tasa de aprendizaje_ (learning rate en inglés). Al igual que con la pérdida, cuando pasamos a Keras el nombre de un optimizador como una cadena, Keras inicializa ese optimizador con valores por defecto para todos los parámetros, incluyendo la tasa de aprendizaje. Sin embargo, por experiencia sabemos que los transformadores se benefician de una tasa de aprendizaje mucho menor que la predeterminada para Adam, que es 1e-3, también escrito
+como 10 a la potencia de -3, o 0,001. 5e-5 (0,00005), que es unas veinte veces menor, es un punto de partida mucho mejor.
+
+Además de reducir la tasa de aprendizaje, tenemos un segundo truco en la manga: podemos reducir lentamente la tasa de aprendizaje a lo largo del entrenamiento. En la literatura, a veces se habla de _decrecimiento_ o _reducción_ de la tasa de aprendizaje. En Keras, la mejor manera de hacer esto es utilizar un _programador de tasa de aprendizaje_. Una buena opción es `PolynomialDecay` que, a pesar del nombre, con la configuración por defecto simplemente hace que la tasa de aprendizaje decaiga decae linealmente desde el valor inicial hasta el valor final durante el transcurso del entrenamiento, que es exactamente lo que queremos. Con el fin de utilizar un programador correctamente, necesitamos decirle cuánto tiempo va a durar el entrenamiento. Especificamos esto a continuación como el número de pasos de entrenamiento: `num_train_steps`.
+
+```py
+from tensorflow.keras.optimizers.schedules import PolynomialDecay
+
+batch_size = 8
+num_epochs = 3
+
+# El número de pasos de entrenamiento es el número de muestras del conjunto de datos
+# dividido por el tamaño del lote y multiplicado por el número total de épocas.
+# Ten en cuenta que el conjunto de datos tf_train_dataset es un conjunto de datos
+# tf.data.Dataset por lotes, no el conjunto de datos original de Hugging Face
+# por lo que su len() ya es num_samples // batch_size.
+
+num_train_steps = len(tf_train_dataset) * num_epochs
+lr_scheduler = PolynomialDecay(
+ initial_learning_rate=5e-5, end_learning_rate=0.0, decay_steps=num_train_steps
+)
+from tensorflow.keras.optimizers import Adam
+
+opt = Adam(learning_rate=lr_scheduler)
+```
+
+
+
+La librería 🤗 Transformers también tiene una función `create_optimizer()` que creará un optimizador `AdamW` con descenso de tasa de aprendizaje. Verás en detalle este útil atajo en próximas secciones del curso.
+
+
+
+Ahora tenemos nuestro nuevo optimizador, y podemos intentar entrenar con él. En primer lugar, vamos a recargar el modelo, para restablecer los cambios en los pesos del entrenamiento que acabamos de hacer, y luego podemos compilarlo con el nuevo optimizador:
+
+```py
+import tensorflow as tf
+
+model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
+model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])
+```
+
+Ahora, ajustamos de nuevo:
+
+```py
+model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
+```
+
+
+
+💡 Si quieres subir automáticamente tu modelo a Hub durante el entrenamiento, puedes pasar un `PushToHubCallback` en el método `model.fit()`. Aprenderemos más sobre esto en el [Capítulo 4](/course/es/chapter4/3)
+
+
+
+### Predicciones del Modelo[[model-predictions]]
+
+
+
+Entrenar y ver cómo disminuye la pérdida está muy bien, pero ¿qué pasa si queremos obtener la salida del modelo entrenado, ya sea para calcular algunas métricas o para utilizar el modelo en producción? Para ello, podemos utilizar el método `predict()`. Este devuelve los _logits_ de la cabeza de salida del modelo, uno por clase.
+
+```py
+preds = model.predict(tf_validation_dataset)["logits"]
+```
+
+Podemos convertir estos logits en predicciones de clases del modelo utilizando `argmax` para encontrar el logit más alto, que corresponde a la clase más probable:
+
+```py
+class_preds = np.argmax(preds, axis=1)
+print(preds.shape, class_preds.shape)
+```
+
+```python out
+(408, 2) (408,)
+```
+
+Ahora, ¡utilicemos esos `preds` (predicciones) para calcular métricas! Podemos cargar las métricas asociadas al conjunto de datos MRPC tan fácilmente como cargamos el conjunto de datos, esta vez con la función `evaluate.load()`. El objeto devuelto tiene un método `compute()` que podemos utilizar para calcular las métricas:
+
+```py
+import evaluate
+
+metric = evaluate.load("glue", "mrpc")
+metric.compute(predictions=class_preds, references=raw_datasets["validation"]["label"])
+```
+
+```python out
+{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
+```
+
+Los resultados exactos que obtengas pueden variar, ya que la inicialización aleatoria de la cabeza del modelo podría cambiar los valores resultantes de las métricas. Aquí, podemos ver que nuestro modelo tiene una precisión del 85,78% en el conjunto de validación y una puntuación F1 de 89,97. Estas son las dos métricas utilizadas para evaluar los resultados del conjunto de datos MRPC del benchmark GLUE. La tabla del [paper de BERT](https://arxiv.org/pdf/1810.04805.pdf) muestra una puntuación F1 de 88,9 para el modelo base. Se trataba del modelo `uncased` ("no encasillado"), mientras que nosotros utilizamos el modelo `cased` ("encasillado"), lo que explica el mejor resultado.
+
+Con esto concluye la introducción al ajuste de modelos utilizando la API de Keras. En el [Capítulo 7](/course/es/chapter7) se dará un ejemplo de cómo hacer esto para las tareas de PLN más comunes. Si quieres perfeccionar tus habilidades con la API Keras, intenta ajustar un modelo con el conjunto de datos GLUE SST-2, utilizando el procesamiento de datos que hiciste en la sección 2.
diff --git a/chapters/es/chapter3/4.mdx b/chapters/es/chapter3/4.mdx
index 8d4e84e8d..054a25639 100644
--- a/chapters/es/chapter3/4.mdx
+++ b/chapters/es/chapter3/4.mdx
@@ -30,7 +30,7 @@ data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
### Prepárate para el entrenamiento
-Antes de escribir nuestro bucle de entrenamiento, necesitaremos definir algunos objetos. Los primeros son los dataloaders que usaremos para iterar sobre lotes. Pero antes de que podamos definir esos dataloaders, necesitamos aplicar un poquito de preprocesamiento a nuestro `tokenized_datasets`, para encargarnos de algunas cosas que el `Trainer` hizo por nosotros de manera automática. Específicamente, necesitamos:
+Antes de escribir nuestro bucle de entrenamiento, necesitaremos definir algunos objetos. Los primeros son los `dataloaders` (literalmente, "cargadores de datos") que usaremos para iterar sobre lotes. Pero antes de que podamos definir esos `dataloaders`, necesitamos aplicar un poquito de preprocesamiento a nuestro `tokenized_datasets`, para encargarnos de algunas cosas que el `Trainer` hizo por nosotros de manera automática. Específicamente, necesitamos:
- Remover las columnas correspondientes a valores que el model no espera (como las columnas `sentence1` y `sentence2`).
- Renombrar la columna `label` con `labels` (porque el modelo espera el argumento llamado `labels`).
@@ -51,7 +51,7 @@ Ahora podemos verificar que el resultado solo tiene columnas que nuestro modelo
["attention_mask", "input_ids", "labels", "token_type_ids"]
```
-Ahora que esto esta hecho, es fácil definir nuestros dataloaders:
+Ahora que esto esta hecho, es fácil definir nuestros `dataloaders`:
```py
from torch.utils.data import DataLoader
@@ -100,9 +100,9 @@ print(outputs.loss, outputs.logits.shape)
tensor(0.5441, grad_fn=) torch.Size([8, 2])
```
-Todos los modelos Transformers 🤗 van a retornar la pérdida cuando se pasan los `labels`, y también obtenemos los logits (dos por cada entrada en nuestro lote, asi que es un tensor de tamaño 8 x 2).
+Todos los modelos 🤗 Transformers van a retornar la pérdida cuando se pasan los `labels`, y también obtenemos los logits (dos por cada entrada en nuestro lote, asi que es un tensor de tamaño 8 x 2).
-Estamos casi listos para escribir nuestro bucle de entrenamiento! Nos están faltando dos cosas: un optimizador y un programador de la rata de aprendizaje. Ya que estamos tratando de replicar a mano lo que el `Trainer` estaba haciendo, usaremos los mismos valores por defecto. El optimizador usado por el `Trainer` es `AdamW`, que es el mismo que Adam, pero con un cambio para la regularización de decremento de los pesos (ver ["Decoupled Weight Decay Regularization"](https://arxiv.org/abs/1711.05101) por Ilya Loshchilov y Frank Hutter):
+Estamos casi listos para escribir nuestro bucle de entrenamiento! Nos están faltando dos cosas: un optimizador y un programador de la tasa de aprendizaje. Ya que estamos tratando de replicar a mano lo que el `Trainer` estaba haciendo, usaremos los mismos valores por defecto. El optimizador usado por el `Trainer` es `AdamW`, que es el mismo que Adam, pero con un cambio para la regularización de decremento de los pesos (ver ["Decoupled Weight Decay Regularization"](https://arxiv.org/abs/1711.05101) por Ilya Loshchilov y Frank Hutter):
```py
from transformers import AdamW
@@ -110,7 +110,7 @@ from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)
```
-Finalmente, el programador por defecto de la rata de aprendizaje es un decremento lineal desde al valor máximo (5e-5) hasta 0. Para definirlo apropiadamente, necesitamos saber el número de pasos de entrenamiento que vamos a tener, el cual viene dado por el número de épocas que deseamos correr multiplicado por el número de lotes de entrenamiento (que es el largo de nuestro dataloader de entrenamiento). El `Trainer` usa tres épocas por defecto, asi que usaremos eso:
+Finalmente, el programador por defecto de la tasa de aprendizaje es un decremento lineal desde al valor máximo (5e-5) hasta 0. Para definirlo apropiadamente, necesitamos saber el número de pasos de entrenamiento que vamos a tener, el cual viene dado por el número de épocas que deseamos correr multiplicado por el número de lotes de entrenamiento (que es el largo de nuestro dataloader de entrenamiento). El `Trainer` usa tres épocas por defecto, asi que usaremos eso:
```py
from transformers import get_scheduler
@@ -146,7 +146,7 @@ device
device(type='cuda')
```
-Ya estamos listos para entrenar! Para tener una idea de cuando el entrenamiento va a terminar, adicionamos una barra de progreso sobre el número de pasos de entrenamiento, usando la libreria `tqdm`:
+¡Ya está todo listo para entrenar! Para tener una idea de cuándo va a terminar el entrenamiento, adicionamos una barra de progreso sobre el número de pasos de entrenamiento, usando la librería `tqdm`:
```py
from tqdm.auto import tqdm
@@ -171,7 +171,7 @@ Puedes ver que la parte central del bucle de entrenamiento luce bastante como el
### El bucle de evaluación
-Como lo hicimos anteriormente, usaremos una métrica ofrecida por la libreria 🤗 Evaluate. Ya hemos visto el método `metric.compute()`, pero de hecho las métricas se pueden acumular sobre los lotes a medida que avanzamos en el bucle de predicción con el método `add_batch()`. Una vez que hemos acumulado todos los lotes, podemos obtener el resultado final con `metric.compute()`. Aquí se muestra como se puede implementar en un bucle de evaluación:
+Como lo hicimos anteriormente, usaremos una métrica ofrecida por la librería 🤗 Evaluate. Ya hemos visto el método `metric.compute()`, pero de hecho las métricas se pueden acumular sobre los lotes a medida que avanzamos en el bucle de predicción con el método `add_batch()`. Una vez que hemos acumulado todos los lotes, podemos obtener el resultado final con `metric.compute()`. Aquí se muestra cómo se puede implementar en un bucle de evaluación:
```py
import evaluate
@@ -206,7 +206,7 @@ De nuevo, tus resultados serán un tanto diferente debido a la inicialización a
-El bucle de entrenamiento que definimos anteriormente trabaja bien en un solo CPU o GPU. Pero usando la libreria [Accelerate 🤗](https://github.com/huggingface/accelerate), con solo pocos ajustes podemos habilitar el entrenamiento distribuido en múltiples GPUs o CPUs. Comenzando con la creación de los dataloaders de entrenamiento y validación, aquí se muestra como luce nuestro bucle de entrenamiento:
+El bucle de entrenamiento que definimos anteriormente trabaja bien en una sola CPU o GPU. Pero usando la librería [Accelerate 🤗](https://github.com/huggingface/accelerate), con solo pocos ajustes podemos habilitar el entrenamiento distribuido en múltiples GPUs o CPUs. Comenzando con la creación de los dataloaders de entrenamiento y validación, aquí se muestra como luce nuestro bucle de entrenamiento:
```py
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
@@ -242,7 +242,7 @@ for epoch in range(num_epochs):
progress_bar.update(1)
```
-Y aqui están los cambios:
+Y aquí están los cambios:
```diff
+ from accelerate import Accelerator
@@ -286,15 +286,17 @@ Y aqui están los cambios:
progress_bar.update(1)
```
-La primera línea a agregarse es la línea del import. La segunda línea crea un objeto `Accelerator` que revisa el ambiente e inicializa la configuración distribuida apropiada. La libreria Accelerate 🤗 se encarga de asignarte el dispositivo, para que puedas remover las líneas que ponen el modelo en el dispositivo (o si prefieres, cámbialas para usar el `accelerator.device` en lugar de `device`).
+La primera línea a agregarse es la línea del `import`. La segunda línea crea un objeto `Accelerator` que revisa el ambiente e inicializa la configuración distribuida apropiada. La librería 🤗 Accelerate se encarga de asignarte el dispositivo, para que puedas remover las líneas que ponen el modelo en el dispositivo (o si prefieres, cámbialas para usar el `accelerator.device` en lugar de `device`).
-Ahora la mayor parte del trabajo se hace en la línea que envia los dataloaders, el modelo y el optimizador al `accelerator.prepare()`. Este va a envolver esos objetos en el contenedor apropiado para asegurarse que tu entrenamiento distribuido funcione como se espera. Los cambios que quedan son remover la línea que coloca el lote en el `device` (de nuevo, si deseas dejarlo asi bastaría con cambiarlo para que use el `accelerator.device`) y reemplazar `loss.backward()` con `accelerator.backward(loss)`.
+Ahora la mayor parte del trabajo se hace en la línea que envía los `dataloaders`, el modelo y el optimizador al `accelerator.prepare()`. Este va a envolver esos objetos en el contenedor apropiado para asegurarse que tu entrenamiento distribuido funcione como se espera. Los cambios que quedan son remover la línea que coloca el lote en el `device` (de nuevo, si deseas dejarlo así bastaría con cambiarlo para que use el `accelerator.device`) y reemplazar `loss.backward()` con `accelerator.backward(loss)`.
-⚠️ Para obtener el beneficio de la aceleración ofrecida por los TPUs de la nube, recomendamos rellenar las muestras hasta una longitud fija con los argumentos `padding="max_length"` y `max_length` del tokenizador.
+ ⚠️ Para obtener el beneficio de la aceleración ofrecida por los TPUs de la
+ nube, recomendamos rellenar las muestras hasta una longitud fija con los
+ argumentos `padding="max_length"` y `max_length` del tokenizador.
-Si deseas copiarlo y pegarlo para probar, así es como luce el bucle completo de entrenamiento con Accelerate 🤗:
+Si deseas copiarlo y pegarlo para probar, así es como luce el bucle completo de entrenamiento con 🤗 Accelerate:
```py
from accelerate import Accelerator
@@ -334,6 +336,7 @@ for epoch in range(num_epochs):
```
Colocando esto en un script `train.py` permitirá que el mismo sea ejecutable en cualquier configuración distribuida. Para probarlo en tu configuración distribuida, ejecuta el siguiente comando:
+
```bash
accelerate config
```
@@ -354,4 +357,4 @@ from accelerate import notebook_launcher
notebook_launcher(training_function)
```
-Puedes encontrar más ejemplos en el [repositorio Accelerate 🤗](https://github.com/huggingface/accelerate/tree/main/examples).
+Puedes encontrar más ejemplos en el [repositorio 🤗 Accelerate](https://github.com/huggingface/accelerate/tree/main/examples).
diff --git a/chapters/es/chapter3/5.mdx b/chapters/es/chapter3/5.mdx
new file mode 100644
index 000000000..0fba0735b
--- /dev/null
+++ b/chapters/es/chapter3/5.mdx
@@ -0,0 +1,24 @@
+
+
+# Ajuste de modelos, ¡hecho!
+
+
+
+¡Qué divertido! En los dos primeros capítulos aprendiste sobre modelos y tokenizadores, y ahora sabes cómo ajustarlos a tus propios datos. Para recapitular, en este capítulo:
+
+{#if fw === 'pt'}
+
+- Aprendiste sobre los conjuntos de datos del [Hub](https://huggingface.co/datasets)
+- Aprendiste a cargar y preprocesar conjuntos de datos, incluyendo el uso de padding dinámico y los "collators"
+- Implementaste tu propio ajuste (fine-tuning) y cómo evaluar un modelo
+- Implementaste un bucle de entrenamiento de bajo nivel
+- Utilizaste 🤗 Accelerate para adaptar fácilmente tu bucle de entrenamiento para que funcione en múltiples GPUs o TPUs
+
+{:else}
+
+- Aprendiste sobre los conjuntos de datos en [Hub](https://huggingface.co/datasets)
+- Aprendiste a cargar y preprocesar conjuntos de datos
+- Aprendiste a ajustar (fine-tuning) y evaluar un modelo con Keras
+- Implementaste una métrica personalizada
+
+{/if}
diff --git a/chapters/es/chapter3/6.mdx b/chapters/es/chapter3/6.mdx
new file mode 100644
index 000000000..5e5a1ba9f
--- /dev/null
+++ b/chapters/es/chapter3/6.mdx
@@ -0,0 +1,333 @@
+
+
+
+
+# Quiz de final de capítulo
+
+
+
+A ver qué has aprendido en este capítulo:
+
+### 1. El dataset `emotion` contiene mensajes de Twitter etiquetados con emociones. Búscalo en el [Hub](https://huggingface.co/datasets), y lee la tarjeta del dataset. ¿Cuál de estas no es una de sus emociones básicas?
+
+
+
+### 2. Busca el dataset `ar_sarcasm` en el [Hub](https://huggingface.co/datasets). ¿Con qué tarea es compatible?
+
+tarjeta del dataset.",
+ },
+ {
+ text: "Reconocimiento de entidades nombradas",
+ explain:
+ "No es correcto, echa otro vistazo a la tarjeta del dataset.",
+ },
+ {
+ text: "Responder preguntas",
+ explain:
+ "No es correcto, echa otro vistazo a la tarjeta del dataset.",
+ },
+ ]}
+/>
+
+### 3. ¿Cómo se procesan un par de frases según el modelo BERT?
+
+[SEP] para separar las dos frases, ¡pero falta algo más!",
+ },
+ {
+ text: "[CLS] tokens_frase_1 tokens_frase_2",
+ explain:
+ "Se necesita un token especial [CLS] al principio, ¡pero falta algo más!",
+ },
+ {
+ text: "[CLS] tokens_frase_1 [SEP] tokens_frase_2 [SEP]",
+ explain: "¡Correcto!",
+ correct: true,
+ },
+ {
+ text: "[CLS] tokens_frase_1 [SEP] tokens_frase_2",
+ explain:
+ "Se necesita un token especial [CLS] al principio y un token especial [SEP] para separar las dos frases, ¡pero falta algo más!",
+ },
+ ]}
+/>
+
+{#if fw === 'pt'}
+
+### 4. ¿Cuáles son las ventajas del método `Dataset.map()`?
+
+
+
+### 5. ¿Qué significa padding dinámico?
+
+
+
+### 6. ¿Cuál es el objetivo de la función "collate"?
+
+DataCollatorWithPadding en especial.',
+ },
+ {
+ text: "Combina todas las muestras del conjunto de datos en un lote.",
+ explain:
+ '¡Correcto! Puedes pasar una función "collate" como argumento a un DataLoader. Nosotros usamos la función DataCollatorWithPadding, que rellena todos los elementos de un lote para que tengan la misma longitud.',
+ correct: true,
+ },
+ {
+ text: "Preprocesa todo el conjunto de datos.",
+ explain:
+ 'Eso sería una función de preprocesamiento, no una función "collate".',
+ },
+ {
+ text: "Trunca las secuencias del conjunto de datos.",
+ explain:
+ 'Una función "collate" está relacionada con el procesamiento de lotes individuales, no del conjunto de datos completo. Si quieres truncar, puedes utilizar el argumento truncate del tokenizer.',
+ },
+ ]}
+/>
+
+### 7. ¿Qué ocurre cuando instancias una de las clases `AutoModelForXxx` con un modelo del lenguaje preentrenado (como `bert-base-uncased`) que corresponde a una tarea distinta de aquella para la que fue entrenado?
+
+AutoModelForSequenceClassification con bert-base-uncased, recibimos una advertencia al instanciar el modelo. La cabeza preentrenada no se puede utilizar para la tarea de clasificación de secuencias, por lo que es eliminada y se instancia una nueva cabeza con pesos aleatorios.",
+ correct: true,
+ },
+ {
+ text: "La cabeza del modelo preentrenado es eliminada.",
+ explain: "Se necesita hacer algo más, inténtalo de nuevo.",
+ },
+ {
+ text: "Nada, ya que el modelo se puede seguir ajustando para la otra tarea.",
+ explain:
+ "La cabeza del modelo preentrenado no fue entrenada para resolver esta tarea, ¡así que deberíamos eliminarla!",
+ },
+ ]}
+/>
+
+### 8. ¿Para qué sirve `TrainingArguments`?
+
+Trainer.",
+ explain: "¡Correcto!",
+ correct: true,
+ },
+ {
+ text: "Especifica el tamaño del modelo.",
+ explain:
+ "El tamaño del modelo viene definido por la configuración del modelo, no por la clase TrainingArguments.",
+ },
+ {
+ text: "Solo contiene los hiperparámetros utilizados para la evaluación.",
+ explain:
+ "En el ejemplo especificamos dónde se guardarán el modelo y sus checkpoints. ¡Inténtalo de nuevo!",
+ },
+ {
+ text: "Solo contiene los hiperparámetros utilizados para el entrenamiento.",
+ explain:
+ "En el ejemplo también utilizamos evaluation_strategy, que afecta a la evaluación. ¡Inténtalo de nuevo!",
+ },
+ ]}
+/>
+
+### 9. ¿Por qué deberías utilizar la librería 🤗 Accelerate?
+
+Trainer, no con la librería 🤗 Accelerate. ¡Vuelve a intentarlo!",
+ },
+ {
+ text: "Hace que nuestros bucles de entrenamiento funcionen con estrategias distribuidas.",
+ explain:
+ "¡Correcto! Con 🤗 Accelerate, tus bucles de entrenamiento funcionarán para múltiples GPUs y TPUs.",
+ correct: true,
+ },
+ {
+ text: "Ofrece más funciones de optimización.",
+ explain:
+ "No, la librería 🤗 Accelerate no proporciona ninguna función de optimización.",
+ },
+ ]}
+/>
+
+{:else}
+
+### 4. ¿Qué ocurre cuando instancias una de las clases `TFAutoModelForXxx` con un modelo del lenguaje preentrenado (como `bert-base-uncased`) que corresponde a una tarea distinta de aquella para la que fue entrenado?
+
+TFAutoModelForSequenceClassification con bert-base-uncased, recibimos una advertencia al instanciar el modelo. La cabeza preentrenada no se puede utilizar para la tarea de clasificación de secuencias, por lo que es eliminada y se instancia una nueva cabeza con pesos aleatorios.",
+ correct: true,
+ },
+ {
+ text: "La cabeza del modelo preentrenado es eliminada",
+ explain: "Se necesita hacer algo más, inténtalo de nuevo.",
+ },
+ {
+ text: "Nada, ya que el modelo se puede seguir ajustando para la otra tarea.",
+ explain:
+ "La cabeza del modelo preentrenado no fue entrenada para resolver esta tarea, ¡así que deberíamos eliminarla!",
+ },
+ ]}
+/>
+
+### 5. Los modelos TensorFlow de `transformers` ya son modelos Keras. ¿Qué ventajas ofrece esto?
+
+TPUStrategy, incluyendo la inicialización del modelo.",
+ },
+ {
+ text: "Puede aprovechar los métodos existentes, como compile(), fit() y predict().",
+ explain:
+ "¡Correcto! Una vez que tienes los datos, entrenar el modelo requiere muy poco esfuerzo.",
+ correct: true,
+ },
+ {
+ text: "Tienes la oportunidad de aprender Keras a la vez que transformadores.",
+ explain: "Correcto, pero estamos buscando otra respuesta :)",
+ correct: true,
+ },
+ {
+ text: "Puede calcular fácilmente las métricas relacionadas con el dataset.",
+ explain:
+ "Keras nos ayuda con el entrenamiento y la evaluación del modelo, no con el cálculo de métricas relacionadas con el dataset.",
+ },
+ ]}
+/>
+
+### 6. ¿Cómo puedes definir tu propia métrica personalizada?
+
+tf.keras.metrics.Metric.",
+ explain: "¡Genial!",
+ correct: true,
+ },
+ {
+ text: "Utilizando la API funcional de Keras.",
+ explain: "¡Inténtalo de nuevo!",
+ },
+ {
+ text: "Utilizando una función cuya firma sea metric_fn(y_true, y_pred).",
+ explain: "¡Correcto!",
+ correct: true,
+ },
+ {
+ text: "Buscándolo en Google.",
+ explain:
+ "Esta no es la respuesta que estamos buscando, pero te podría ayudar a encontrarla.",
+ correct: true,
+ },
+ ]}
+/>
+
+{/if}
diff --git a/chapters/es/chapter5/1.mdx b/chapters/es/chapter5/1.mdx
index 31a9a4c07..07db42118 100644
--- a/chapters/es/chapter5/1.mdx
+++ b/chapters/es/chapter5/1.mdx
@@ -5,7 +5,7 @@
classNames="absolute z-10 right-0 top-0"
/>
-En el [Capítulo 3](/course/chapter3) tuviste tu primer acercamento a la librería 🤗 Datasets y viste que existían 3 pasos principales para ajustar un modelo:
+En el [Capítulo 3](/course/chapter3) tuviste tu primer acercamiento a la librería 🤗 Datasets y viste que existían 3 pasos principales para ajustar un modelo:
1. Cargar un conjunto de datos del Hub de Hugging Face.
2. Preprocesar los datos con `Dataset.map()`.
diff --git a/chapters/es/chapter5/2.mdx b/chapters/es/chapter5/2.mdx
index a239ddf53..e68820743 100644
--- a/chapters/es/chapter5/2.mdx
+++ b/chapters/es/chapter5/2.mdx
@@ -50,7 +50,7 @@ De este modo, podemos ver que los archivos comprimidos son reemplazados por los
-✎ Si te preguntas por qué hay un caracter de signo de admiración (`!`) en los comandos de shell, esto es porque los estamos ejecutando desde un cuaderno de Jupyter. Si quieres descargar y descomprimir el archivo directamente desde la terminal, elimina el signo de admiración.
+✎ Si te preguntas por qué hay un carácter de signo de admiración (`!`) en los comandos de shell, esto es porque los estamos ejecutando desde un cuaderno de Jupyter. Si quieres descargar y descomprimir el archivo directamente desde la terminal, elimina el signo de admiración.
@@ -129,7 +129,7 @@ Esto es exactamente lo que queríamos. Ahora podemos aplicar varias técnicas de
-El argumento `data_files` de la función `load_dataset()` es muy flexible. Puede ser una única ruta de archivo, una lista de rutas o un diccionario que mapee los nombres de los conjuntos a las rutas de archivo. También puedes buscar archivos que cumplan con cierto patrón específico de acuerdo con las reglas usadas por el shell de Unix (e.g., puedes buscar todos los archivos JSON en una carpeta al definir `datafiles="*.json"`). Revisa la [documentación](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) para más detalles.
+El argumento `data_files` de la función `load_dataset()` es muy flexible. Puede ser una única ruta de archivo, una lista de rutas o un diccionario que mapee los nombres de los conjuntos a las rutas de archivo. También puedes buscar archivos que cumplan con cierto patrón específico de acuerdo con las reglas usadas por el shell de Unix (e.g., puedes buscar todos los archivos JSON en una carpeta al definir `datafiles="*.json"`). Revisa la [documentación](https://huggingface.co/docs/datasets/loading#local-and-remote-files) para más detalles.
@@ -161,6 +161,6 @@ Esto devuelve el mismo objeto `DatasetDict` que obtuvimos antes, pero nos ahorra
-✏️ **¡Inténtalo!** Escoge otro dataset alojado en GitHub o en el [Repositorio de Machine Learning de UCI](https://archive.ics.uci.edu/ml/index.php) e intenta cargarlo local y remotamente usando las técnicas descritas con anterioridad. Para puntos extra, intenta cargar un dataset que esté guardado en un formato CSV o de texto (revisa la [documentación](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) pata tener más información sobre estos formatos).
+✏️ **¡Inténtalo!** Escoge otro dataset alojado en GitHub o en el [Repositorio de Machine Learning de UCI](https://archive.ics.uci.edu/ml/index.php) e intenta cargarlo local y remotamente usando las técnicas descritas con anterioridad. Para puntos extra, intenta cargar un dataset que esté guardado en un formato CSV o de texto (revisa la [documentación](https://huggingface.co/docs/datasets/loading#local-and-remote-files) pata tener más información sobre estos formatos).
diff --git a/chapters/es/chapter5/3.mdx b/chapters/es/chapter5/3.mdx
index 241916c9d..daae902ea 100644
--- a/chapters/es/chapter5/3.mdx
+++ b/chapters/es/chapter5/3.mdx
@@ -11,7 +11,7 @@ La mayor parte del tiempo tus datos no estarán perfectamente listos para entren
-## Subdivdiendo nuestros datos
+## Subdividiendo nuestros datos
De manera similar a Pandas, 🤗 Datasets incluye varias funciones para manipular el contenido de los objetos `Dataset` y `DatasetDict`. Ya vimos el método `Dataset.map()` en el [Capítulo 3](/course/chapter3) y en esta sección vamos a explorar otras funciones que tenemos a nuestra disposición.
@@ -30,7 +30,7 @@ Dado que TSV es una variación de CSV en la que se usan tabulaciones en vez de c
from datasets import load_dataset
data_files = {"train": "drugsComTrain_raw.tsv", "test": "drugsComTest_raw.tsv"}
-# \t es el caracter para tabulaciones en Python
+# \t es el carácter para tabulaciones en Python
drug_dataset = load_dataset("csv", data_files=data_files, delimiter="\t")
```
@@ -54,7 +54,7 @@ drug_sample[:3]
'usefulCount': [36, 13, 128]}
```
-Puedes ver que hemos fijado la semilla en `Dataset.shuffle()` por motivos de reproducibilidad. `Dataset.select()` espera un interable de índices, así que incluimos `range(1000)` para tomar los primeros 1.000 ejemplos del conjunto de datos aleatorizado. Ya podemos ver algunos detalles para esta muestra:
+Puedes ver que hemos fijado la semilla en `Dataset.shuffle()` por motivos de reproducibilidad. `Dataset.select()` espera un iterable de índices, así que incluimos `range(1000)` para tomar los primeros 1.000 ejemplos del conjunto de datos aleatorizado. Ya podemos ver algunos detalles para esta muestra:
* La columna `Unnamed: 0` se ve sospechosamente como un ID anonimizado para cada paciente.
* La columna `condition` incluye una mezcla de niveles en mayúscula y minúscula.
@@ -215,7 +215,7 @@ drug_dataset["train"].sort("review_length")[:3]
'review_length': [1, 1, 1]}
```
-Como lo discutimos anteriormente, algunas reseñas incluyen una sola palabra, que si bien puede ser útil para el análisis de sentimientos, no sería tan informativa si quisieramos predecir la condición.
+Como lo discutimos anteriormente, algunas reseñas incluyen una sola palabra, que si bien puede ser útil para el análisis de sentimientos, no sería tan informativa si quisiéramos predecir la condición.
@@ -238,7 +238,7 @@ Como puedes ver, esto ha eliminado alrededor del 15% de las reseñas de nuestros
-✏️ **¡Inténtalo!** Usa la función `Dataset.sort()` para inspeccionar las reseñas con el mayor número de palabras. Revisa la [documentación](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.sort) para ver cuál argumento necesitas para ordenar las reseñas de mayor a menor.
+✏️ **¡Inténtalo!** Usa la función `Dataset.sort()` para inspeccionar las reseñas con el mayor número de palabras. Revisa la [documentación](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.sort) para ver cuál argumento necesitas para ordenar las reseñas de mayor a menor.
@@ -312,7 +312,7 @@ Opciones | Tokenizador rápido | Tokenizador lento
Esto significa que usar un tokenizador rápido con la opción `batched=True` es 30 veces más rápido que su contraparte lenta sin usar lotes. ¡Realmente impresionante! Esta es la razón principal por la que los tokenizadores rápidos son la opción por defecto al usar `AutoTokenizer` (y por qué se denominan "rápidos"). Estos logran tal rapidez gracias a que el código de los tokenizadores corre en Rust, que es un lenguaje que facilita la ejecución del código en paralelo.
-La paralelización también es la razón para el incremento de 6x en la velocidad del tokenizador al ejecutarse por lotes: No puedes ejecutar una única operacón de tokenización en paralelo, pero cuando quieres tokenizar muchos textos al mismo tiempo puedes dividir la ejecución en diferentes procesos, cada uno responsable de sus propios textos.
+La paralelización también es la razón para el incremento de 6x en la velocidad del tokenizador al ejecutarse por lotes: No puedes ejecutar una única operación de tokenización en paralelo, pero cuando quieres tokenizar muchos textos al mismo tiempo puedes dividir la ejecución en diferentes procesos, cada uno responsable de sus propios textos.
`Dataset.map()` también tiene algunas capacidades de paralelización. Dado que no funcionan con Rust, no van a hacer que un tokenizador lento alcance el rendimiento de uno rápido, pero aún así pueden ser útiles (especialmente si estás usando un tokenizador que no tiene una versión rápida). Para habilitar el multiprocesamiento, usa el argumento `num_proc` y especifica el número de procesos para usar en `Dataset.map()`:
@@ -329,7 +329,7 @@ tokenized_dataset = drug_dataset.map(slow_tokenize_function, batched=True, num_p
También puedes medir el tiempo para determinar el número de procesos que vas a usar. En nuestro caso, usar 8 procesos produjo la mayor ganancia de velocidad. Aquí están algunos de los números que obtuvimos con y sin multiprocesamiento:
-Opciones | Tokenizador rápido | Rokenizador lento
+Opciones | Tokenizador rápido | Tokenizador lento
:--------------:|:--------------:|:-------------:
`batched=True` | 10.8s | 4min41s
`batched=False` | 59.2s | 5min3s
@@ -348,7 +348,7 @@ Que toda esta funcionalidad está incluida en un método es algo impresionante e
-💡 Un _ejemplo_ en Machine Learning se suele definir como el conjunto de _features_ que le damos al modelo. En algunos contextos estos features serán el conjuto de columnas en un `Dataset`, mientras que en otros se pueden extraer mútiples features de un solo ejemplo que pertenecen a una columna –como aquí y en tareas de responder preguntas-.
+💡 Un _ejemplo_ en Machine Learning se suele definir como el conjunto de _features_ que le damos al modelo. En algunos contextos estos features serán el conjunto de columnas en un `Dataset`, mientras que en otros se pueden extraer múltiples features de un solo ejemplo que pertenecen a una columna –como aquí y en tareas de responder preguntas-.
@@ -385,7 +385,7 @@ tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
```
-¿Por qué no funcionó? El mensaje de error nos da una pista: hay un desajuste en las longitudes de una de las columnas, siendo una de logitud 1.463 y otra de longitud 1.000. Si has revisado la [documentación de `Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map), te habrás dado cuenta que estamos mapeando el número de muestras que le pasamos a la función: en este caso los 1.000 ejemplos nos devuelven 1.463 features, arrojando un error.
+¿Por qué no funcionó? El mensaje de error nos da una pista: hay un desajuste en las longitudes de una de las columnas, siendo una de longitud 1.463 y otra de longitud 1.000. Si has revisado la [documentación de `Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map), te habrás dado cuenta que estamos mapeando el número de muestras que le pasamos a la función: en este caso los 1.000 ejemplos nos devuelven 1.463 features, arrojando un error.
El problema es que estamos tratando de mezclar dos datasets de tamaños diferentes: las columnas de `drug_dataset` tendrán un cierto número de ejemplos (los 1.000 en el error), pero el `tokenized_dataset` que estamos construyendo tendrá más (los 1.463 en el mensaje de error). Esto no funciona para un `Dataset`, así que tenemos que eliminar las columnas del anterior dataset o volverlas del mismo tamaño del nuevo. Podemos hacer la primera operación con el argumento `remove_columns`:
diff --git a/chapters/es/chapter5/4.mdx b/chapters/es/chapter5/4.mdx
index 344fb0545..326a2a609 100644
--- a/chapters/es/chapter5/4.mdx
+++ b/chapters/es/chapter5/4.mdx
@@ -7,7 +7,7 @@
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter5/section4.ipynb"},
]} />
-Hoy en día es común que tengas que trabajar con dataset de varios GB, especialmente si planeas pre-entrenar un transformador como BERT o GPT-2 desde ceros. En estos casos, _solamente cargar_ los datos puede ser un desafío. Por ejemplo, el corpus de WebText utilizado para preentrenar GPT-2 consiste de más de 8 millones de documentos y 40 GB de texto. ¡Cargarlo en la RAM de tu computador portatil le va a causar un paro cardiaco!
+Hoy en día es común que tengas que trabajar con dataset de varios GB, especialmente si planeas pre-entrenar un transformador como BERT o GPT-2 desde ceros. En estos casos, _solamente cargar_ los datos puede ser un desafío. Por ejemplo, el corpus de WebText utilizado para preentrenar GPT-2 consiste de más de 8 millones de documentos y 40 GB de texto. ¡Cargarlo en la RAM de tu computador portátil le va a causar un paro cardíaco!
Afortunadamente, 🤗 Datasets está diseñado para superar estas limitaciones: te libera de problemas de manejo de memoria al tratar los datasets como archivos _proyectados en memoria_ (_memory-mapped_) y de límites de almacenamiento al hacer _streaming_ de las entradas en un corpus.
@@ -45,7 +45,7 @@ Como podemos ver, hay 15.518.009 filas y dos columnas en el dataset, ¡un montó
-✎ Por defecto, 🤗 Datasets va a descomprimir los archivos necesarios para cargar un dataset. Si quieres ahorrar espacio de almacenamiento, puedes usar `DownloadConfig(delete_extracted=True)` al argumento `download_config` de `load_dataset()`. Revisa la [documentación](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig) para más detalles.
+✎ Por defecto, 🤗 Datasets va a descomprimir los archivos necesarios para cargar un dataset. Si quieres ahorrar espacio de almacenamiento, puedes usar `DownloadConfig(delete_extracted=True)` al argumento `download_config` de `load_dataset()`. Revisa la [documentación](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig) para más detalles.
@@ -128,7 +128,7 @@ print(
'Iterated over 15518009 examples (about 19.5 GB) in 64.2s, i.e. 0.304 GB/s'
```
-Aquí usamos el módulo `timeit` de Python para medir el tiempo de ejecución que se toma `code_snippet`. Tipicamemente, puedes iterar a lo largo de un dataset a una velocidad de unas cuantas décimas de un GB por segundo. Esto funciona muy bien para la gran mayoría de aplicaciones, pero algunas veces tendrás que trabajar con un dataset que es tan grande para incluso almacenarse en el disco de tu computador. Por ejemplo, si quisieramos descargar el _Pile_ completo ¡necesitaríamos 825 GB de almacenamiento libre! Para trabajar con esos casos, 🤗 Datasets puede trabajar haciendo _streaming_, lo que permite la descarga y acceso a los elementos sobre la marcha, sin necesidad de descargar todo el dataset. Veamos cómo funciona:
+Aquí usamos el módulo `timeit` de Python para medir el tiempo de ejecución que se toma `code_snippet`. Típicamemente, puedes iterar a lo largo de un dataset a una velocidad de unas cuantas décimas de un GB por segundo. Esto funciona muy bien para la gran mayoría de aplicaciones, pero algunas veces tendrás que trabajar con un dataset que es tan grande para incluso almacenarse en el disco de tu computador. Por ejemplo, si quisieramos descargar el _Pile_ completo ¡necesitaríamos 825 GB de almacenamiento libre! Para trabajar con esos casos, 🤗 Datasets puede trabajar haciendo _streaming_, lo que permite la descarga y acceso a los elementos sobre la marcha, sin necesidad de descargar todo el dataset. Veamos cómo funciona:
@@ -173,7 +173,7 @@ next(iter(tokenized_dataset))
-💡 Para acelerar la tokenización con _streaming_ puedes definir `batched=True`, como lo vimos en la sección anterior. Esto va a procesar los ejemplos lote por lote. Recuerda que el tamaño por defecto de los lotes es 1.000 y puede ser expecificado con el argumento `batch_size`.
+💡 Para acelerar la tokenización con _streaming_ puedes definir `batched=True`, como lo vimos en la sección anterior. Esto va a procesar los ejemplos lote por lote. Recuerda que el tamaño por defecto de los lotes es 1.000 y puede ser especificado con el argumento `batch_size`.
@@ -189,7 +189,7 @@ next(iter(shuffled_dataset))
'text': 'Randomized study of dose or schedule modification of granulocyte colony-stimulating factor in platinum-based chemotherapy for elderly patients with lung cancer ...'}
```
-En este ejemplo, seleccionamos un ejemplo aleatório de los primeros 10.000 ejemplos en el buffer. Apenas se accede a un ejemplo, su lugar en el buffer se llena con el siguiente ejemplo en el corpus (i.e., el ejemplo número 10.001). También peudes seleccionar elementos de un dataset _streamed_ usando las funciones `IterableDataset.take()` y `IterableDataset.skip()`, que funcionan de manera similar a `Dataset.select()`. Por ejemplo, para seleccionar los 5 primeros ejemplos en el dataset de abstracts de PubMed podemos hacer lo siguiente:
+En este ejemplo, seleccionamos un ejemplo aleatorio de los primeros 10.000 ejemplos en el buffer. Apenas se accede a un ejemplo, su lugar en el buffer se llena con el siguiente ejemplo en el corpus (i.e., el ejemplo número 10.001). También puedes seleccionar elementos de un dataset _streamed_ usando las funciones `IterableDataset.take()` y `IterableDataset.skip()`, que funcionan de manera similar a `Dataset.select()`. Por ejemplo, para seleccionar los 5 primeros ejemplos en el dataset de abstracts de PubMed podemos hacer lo siguiente:
```py
dataset_head = pubmed_dataset_streamed.take(5)
@@ -209,12 +209,12 @@ list(dataset_head)
'text': 'Oxygen supply in rural africa: a personal experience ...'}]
```
-También podemos usar la función `IterableDataset.skip()` para crear conjuntos de entrenamiento y validación de un dataset ordenado aleatóriamente así:
+También podemos usar la función `IterableDataset.skip()` para crear conjuntos de entrenamiento y validación de un dataset ordenado aleatoriamente así:
```py
-# Skip the first 1,000 examples and include the rest in the training set
+# Salta las primeras 1000 muestras e incluye el resto en el conjunto de entrenamiento
train_dataset = shuffled_dataset.skip(1000)
-# Take the first 1,000 examples for the validation set
+# Toma las primeras 1000 muestras para el conjunto de validación
validation_dataset = shuffled_dataset.take(1000)
```
@@ -283,4 +283,3 @@ next(iter(pile_dataset["train"]))
Ya tienes todas las herramientas para cargar y procesar datasets de todas las formas y tamaños, pero a menos que seas muy afortunado, llegará un punto en tu camino de PLN en el que tendrás que crear el dataset tu mismo para resolver tu problema particular. De esto hablaremos en la siguiente sección.
-
diff --git a/chapters/es/chapter5/5.mdx b/chapters/es/chapter5/5.mdx
index 113138fa5..21419d4e5 100644
--- a/chapters/es/chapter5/5.mdx
+++ b/chapters/es/chapter5/5.mdx
@@ -13,7 +13,7 @@ Algunas veces el dataset que necesitas para crear una aplicación de procesamien
* Entrenar un _clasificador de etiquetas múltiples_ que pueda etiquetar issues con metadados basado en la descripción del issue (e.g., "bug", "mejora" o "pregunta")
* Crear un motor de búsqueda semántica para encontrar qué issues coinciden con la pregunta del usuario
-En esta sección nos vamos a enfocar en la creación del corpus y en la siguiente vamos a abordar la aplicación de búsqueda semántica. Para que esto sea un meta-proyecto, vamos a usar los issues de Github asociados con un proyecto popular de código abierto: 🤗 Datasets! Veamos cómo obtener los datos y explorar la información contenida en estos issues.
+En esta sección nos vamos a enfocar en la creación del corpus y en la siguiente vamos a abordar la aplicación de búsqueda semántica. Para que esto sea un meta-proyecto, vamos a usar los issues de GitHub asociados con un proyecto popular de código abierto: 🤗 Datasets! Veamos cómo obtener los datos y explorar la información contenida en estos issues.
## Obteniendo los datos
@@ -255,7 +255,7 @@ Como se muestra en la siguiente captura de pantalla, los comentarios asociados c

-El API REST de GitHub tiene un [endpoint `Comments`](https://docs.github.com/en/rest/reference/issues#list-issue-comments) que devuelve todos los comentarios asociados con un número de issue. Probémos este endpoint para ver qué devuelve:
+El API REST de GitHub tiene un [endpoint `Comments`](https://docs.github.com/en/rest/reference/issues#list-issue-comments) que devuelve todos los comentarios asociados con un número de issue. Probemos este endpoint para ver qué devuelve:
```py
issue_number = 2792
@@ -378,7 +378,7 @@ En este ejemplo, hemos creado un repositorio vacío para el dataset llamado `git
-✏️ **¡Inténtalo!** Usa tu nombre de usuario de Hugging Face Hub para obtener un token y crear un repositorio vacío llamado `girhub-issues`. Recuerda **nunca guardar tus credenciales** en Colab o cualquier otro repositorio, ya que esta información puede ser aprovechada por terceros.
+✏️ **¡Inténtalo!** Usa tu nombre de usuario de Hugging Face Hub para obtener un token y crear un repositorio vacío llamado `github-issues`. Recuerda **nunca guardar tus credenciales** en Colab o cualquier otro repositorio, ya que esta información puede ser aprovechada por terceros.
@@ -427,7 +427,7 @@ Dataset({
-💡 También puedes subir un dataset al Hub de Hugging Face directamente desde la terminal usando `huggingface-cli` y un poco de Git. Revisa la [guía de 🤗 Datasets](https://huggingface.co/docs/datasets/share.html#add-a-community-dataset) para más detalles sobre cómo hacerlo.
+💡 También puedes subir un dataset al Hub de Hugging Face directamente desde la terminal usando `huggingface-cli` y un poco de Git. Revisa la [guía de 🤗 Datasets](https://huggingface.co/docs/datasets/share#share-a-dataset-using-the-cli) para más detalles sobre cómo hacerlo.
@@ -445,7 +445,7 @@ En el Hub de Hugging Face, esta información se almacena en el archivo *README.m
2. Lee la [guía de 🤗 Datasets](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) sobre cómo crear tarjetas informativas y usarlas como plantilla.
-Puedes crear el archivo *README.md* drectamente desde el Hub y puedes encontrar una plantilla de tarjeta en el repositorio `lewtun/github-issues`. Así se ve una tarjeta de dataset diligenciada:
+Puedes crear el archivo *README.md* directamente desde el Hub y puedes encontrar una plantilla de tarjeta en el repositorio `lewtun/github-issues`. Así se ve una tarjeta de dataset diligenciada:

@@ -457,7 +457,7 @@ Puedes crear el archivo *README.md* drectamente desde el Hub y puedes encontrar
-¡Eso es todo! Hemos visto que crear un buen dataset requiere de mucho esfuerzo de tu parte, pero afortunadamente subirlo y compartirlo con la comunidad no. En la siguiente sección usaremos nuestro nuevo dataset para crear un motor de búsqueda semántica con 🤗 Datasets que pueda emparejar pregunras con los issues y comentarios más relevantes.
+¡Eso es todo! Hemos visto que crear un buen dataset requiere de mucho esfuerzo de tu parte, pero afortunadamente subirlo y compartirlo con la comunidad no. En la siguiente sección usaremos nuestro nuevo dataset para crear un motor de búsqueda semántica con 🤗 Datasets que pueda emparejar preguntas con los issues y comentarios más relevantes.
diff --git a/chapters/es/chapter5/6.mdx b/chapters/es/chapter5/6.mdx
index 2c4cbd13f..d92a1333c 100644
--- a/chapters/es/chapter5/6.mdx
+++ b/chapters/es/chapter5/6.mdx
@@ -22,7 +22,7 @@
{/if}
-En la [sección 5](/course/chapter5/5) creamos un dataset de issues y comentarios del repositorio de Github de 🤗 Datasets. En esta sección usaremos esta información para construir un motor de búsqueda que nos ayude a responder nuestras preguntas más apremiantes sobre la librería.
+En la [sección 5](/course/chapter5/5) creamos un dataset de issues y comentarios del repositorio de GitHub de 🤗 Datasets. En esta sección usaremos esta información para construir un motor de búsqueda que nos ayude a responder nuestras preguntas más apremiantes sobre la librería.
@@ -189,7 +189,7 @@ Dataset({
-✏️ **¡Inténtalo!** Prueba si puedes usar la función `Dataset.map()` para "explotar" la columna `comments` en `issues_dataset` _sin_ necesidad de usar Pandas. Esto es un poco complejo; te recomendamos revisar la sección de ["Batch mapping"](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) de la documentación de 🤗 Datasets para completar esta tarea.
+✏️ **¡Inténtalo!** Prueba si puedes usar la función `Dataset.map()` para "explotar" la columna `comments` en `issues_dataset` _sin_ necesidad de usar Pandas. Esto es un poco complejo; te recomendamos revisar la sección de ["Batch mapping"](https://huggingface.co/docs/datasets/about_map_batch#batch-mapping) de la documentación de 🤗 Datasets para completar esta tarea.
@@ -266,7 +266,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = TFAutoModel.from_pretrained(model_ckpt, from_pt=True)
```
-Ten en cuenta que hemos definido `from_pt=True` como un argumento del método `from_pretrained()`. Esto es porque el punto de control `multi-qa-mpnet-base-dot-v1` sólo tiene pesos de PyTorch, asi que usar `from_pt=True` los va a covertir automáticamente al formato TensorFlow. Como puedes ver, ¡es múy fácil cambiar entre frameworks usando 🤗 Transformers!
+Ten en cuenta que hemos definido `from_pt=True` como un argumento del método `from_pretrained()`. Esto es porque el punto de control `multi-qa-mpnet-base-dot-v1` sólo tiene pesos de PyTorch, asi que usar `from_pt=True` los va a convertir automáticamente al formato TensorFlow. Como puedes ver, ¡es múy fácil cambiar entre frameworks usando 🤗 Transformers!
{/if}
diff --git a/chapters/es/chapter5/8.mdx b/chapters/es/chapter5/8.mdx
index 4718d8faf..99f5e0ffd 100644
--- a/chapters/es/chapter5/8.mdx
+++ b/chapters/es/chapter5/8.mdx
@@ -1,6 +1,6 @@
-# Quiz
+# Quiz de final de capítulo
data_files de la función load_dataset() psara cargar archivos remotos.",
+ explain: "¡Correcto! Puedes pasar URL al argumento data_files de la función load_dataset() para cargar archivos remotos.",
correct: true
},
]}
@@ -41,7 +41,7 @@ from datasets import load_dataset
dataset = load_dataset("glue", "mrpc", split="train")
```
-¿Cuál de los sigientes comandos a a producir una muestra aleatoria de 50 elementos de `dataset`?
+¿Cuál de los siguientes comandos a a producir una muestra aleatoria de 50 elementos de `dataset`?
pets_dataset.filter(lambda x['name'].startswith('L'))",
- explain: "Esto es incorrecrto. Una función lambda toma la forma general lambda *arguments* : *expression*, así que tienes que definir los argumentos en este caso."
+ explain: "Esto es incorrecto. Una función lambda toma la forma general lambda *arguments* : *expression*, así que tienes que definir los argumentos en este caso."
},
{
- text: "Crear una funcióin como def filter_names(x): return x['name'].startswith('L') y ejecutar pets_dataset.filter(filter_names).",
+ text: "Crear una función como def filter_names(x): return x['name'].startswith('L') y ejecutar pets_dataset.filter(filter_names).",
explain: "¡Correcto! Justo como con Dataset.map(), puedes pasar funciones explícitas a Dataset.filter(). Esto es útil cuando tienes una lógica compleja que no es adecuada para una función lambda. ¿Cuál de las otras soluciones podría funcionar?",
correct: true
}
@@ -150,7 +150,7 @@ dataset[0]
]}
/>
-### 7. ¿Cuáles son los principales beneficiones de crear una tarjeta para un dataset?
+### 7. ¿Cuáles son los principales beneficios de crear una tarjeta para un dataset?
+
+En el [Capítulo 3](/course/chapter3), revisamos como hacer fine-tuning a un modelo para una tarea dada. Cuando hacemos eso, usamos el mismo tokenizador con el que el modelo fue entrenado -- pero, ¿Qué hacemos cuando queremos entrenar un modelo desde cero? En estos casos, usar un tokenizador que fue entrenado en un corpus con otro dominio u otro lenguaje típicamente no es lo más óptimo. Por ejemplo un tokenizador que es entrenado en un corpus en Inglés tendrá un desempeño pobre en un corpus de textos en Japonés porque el uso de los espacios y de la puntuación es muy diferente entre los dos lenguajes.
+
+
+En este capítulo, aprenderás como entrenar un tokenizador completamente nuevo en un corpus, para que luego pueda ser usado para pre-entrenar un modelo de lenguaje. Todo esto será hecho con la ayuda de la librería [🤗 Tokenizers](https://github.com/huggingface/tokenizers), la cual provee tokenizadores rápidos (_fast tokenizers_) en la librería [🤗 Transformers](https://github.com/huggingface/transformers). Miraremos de cerca todas las características que la provee la librería, y explorar cómo los tokenizadores rápidos (fast tokenizers) difieren de las versiones "lentas".
+
+Los temas a cubrir incluyen:
+
+* Cómo entrenar un tokenizador nuevo similar a los usados por un checkpoint dado en un nuevo corpus de texto.
+* Las características especiales de los tokenizador rápidos ("fast tokenizers").
+* Las diferencias entre los tres principales algoritmos de tokenización usados en PLN hoy.
+* Como construir un tokenizador desde cero con la librería 🤗 Tokenizers y entrenarlo en datos.
+
+Las técnicas presentadas en este capítulo te prepararán para la sección en el [Capítulo 7](/course/chapter7/6) donde estudiaremos cómo crear un modelo de lenguaje para Código Fuente en Python. Comenzaremos en primer lugar revisando qué significa "entrenar" un tokenizador.
\ No newline at end of file
diff --git a/chapters/es/chapter6/10.mdx b/chapters/es/chapter6/10.mdx
new file mode 100644
index 000000000..0b9f89193
--- /dev/null
+++ b/chapters/es/chapter6/10.mdx
@@ -0,0 +1,283 @@
+
+
+# Quiz de Final de Capítulo[[end-of-chapter-quiz]]
+
+
+
+Probemos lo que aprendimos en este capítulo!
+
+### 1. Cuando debería entrenar un nuevo tokenizador?
+
+
+
+### 2. Cuál es la ventaja de usar un generador de listas de textos comparado con una lista de listas de textos al usar `train_new_from_iterator()`?
+
+train_new_from_iterator() acepta.",
+ explain: "Una lista de listas de textos es un tipo particular de generador de listas de textos, por lo que el método aceptará esto también. Intenta de nuevo!"
+ },
+ {
+ text: "Evitarás cargar todo el conjunto de datos en memoria de una sóla vez.",
+ explain: "Correcto! Cada lote de textos será liberado de la memoria al ir iterando, y la ganancia será especialmente visible si usas la librería 🤗 Datasets para almacenar tus textos.",
+ correct: true
+ },
+ {
+ text: "Esto permite que la librería 🤗 Tokenizers library use multiprocesamiento.",
+ explain: "No, usará multiprocesamiento en ambos casos."
+ },
+ {
+ text: "El tokenizador que entrenarás generará mejores textos.",
+ explain: "El tokenizador no genera texto -- estás confundiéndolo con un modelo de lenguaje?"
+ }
+ ]}
+/>
+
+### 3. Cuáles son las ventajas de utilizar un tokenizador "rápido"?
+
+
+
+### 4. Como hace el pipeline `token-classification` para manejar entidades que se extienden a varios tokens?
+
+
+
+### 5. Cómo hace el pipeline de `question-answering` para manejar contextos largos?
+
+
+
+### 6. Qué es la normalización?
+
+
+
+### 7. Qué es la pre-tokenización para un tokenizador de subpalabra?
+
+
+
+### 8. Selecciona las afirmaciones que aplican para el modelo de tokenización BPE.
+
+
+
+### 9. Selecciona las afirmaciones que aplican para el modelo de tokenizacion WordPiece.
+
+
+
+### 10. Selecciona las afirmaciones que aplican para el modelo de tokenización Unigram.
+
+
diff --git a/chapters/es/chapter6/2.mdx b/chapters/es/chapter6/2.mdx
new file mode 100644
index 000000000..d4e629374
--- /dev/null
+++ b/chapters/es/chapter6/2.mdx
@@ -0,0 +1,250 @@
+# Entrenar un nuevo tokenizador a partir de uno existente[[training-a-new-tokenizer-from-an-old-one]]
+
+
+
+Si un modelo de lenguaje no está disponible en el lenguaje en el que estás interesado, o si el corpus es muy diferente del lenguaje original en el que el modelo de lenguaje fue entrenado, es muy probable que quieras reentrenar el modelo desde cero utilizando un tokenizador adaptado a tus datos. Eso requerirá entrenar un tokenizador nuevo en tu conjunto de datos. Pero, ¿Qué significa eso exactamente? Cuando revisamos los tokenizadores por primera vez en el [Capítulo 2](/course/chapter2), vimos que la mayoría de los modelos basados en Transformers usan un algoritmo de _tokenización basado en subpalabras_. Para identificar qué subpalabras son de interés y ocurren más frecuentemente en el corpus deseado, el tokenizador necesita mirar de manera profunda todo el texto en el corpus -- un proceso al que llamamos *entrenamiento*. Las reglas exactas que gobiernan este entrenamiento dependen en el tipo de tokenizador usado, y revisaremos los 3 algoritmos principales más tarde en el capítulo.
+
+
+
+
+
+
+⚠️ ¡Entrenar un tokenizador no es lo mismo que entrenar un modelo! Entrenar un modelo utiliza `stochastic gradient descent` para minimizar la pérdida (`loss`) en cada lote (`batch`). Es un proceso aleatorio por naturaleza (lo que signifiva que hay que fijar semillas para poder obterner los mismos resultados cuando se realiza el mismo entrenamiento dos veces). Entrenar un tokenizador es un proceso estadístico que intenta identificar cuales son las mejores subpalabras para un corpus dado, y las reglas exactas para elegir estas subpalabras dependen del algoritmo de tokenización. Es un proceso deterministico, lo que significa que siempre se obtienen los mismos resultados al entrenar el mismo algoritmo en el mismo corpus.
+
+
+
+## Ensamblando un Corpus[[assembling-a-corpus]]
+
+Hay una API muy simple en 🤗 Transformers que se puede usar para entrenar un nuevo tokenizador con las mismas características que uno existente: `AutoTokenizer.train_new_from_iterator()`. Para verlo en acción, digamos que queremos entrenar GPT-2 desde cero, pero en lenguaje distinto al Inglés. Nuestra primera tarea será reunir muchos datos en ese lenguaje en un corpus de entrenamiento. Para proveer ejemplos que todos serán capaces de entender no usaremos un lenguaje como el Ruso o el Chino, sino uno versión del inglés más especializado: Código en Python.
+
+La librería [🤗 Datasets](https://github.com/huggingface/datasets) nos puede ayudar a ensamblar un corpus de código fuente en Python. Usaremos la típica función `load_dataset()` para descargar y cachear el conjunto de datos [CodeSearchNet](https://huggingface.co/datasets/code_search_net). Este conjunto de datos fue creado para el [CodeSearchNet challenge](https://wandb.ai/github/CodeSearchNet/benchmark) y contiene millones de funciones de librerías open source en GitHub en varios lenguajes de programación. Aquí cargaremos la parte del conjunto de datos que está en Python:
+
+```py
+from datasets import load_dataset
+
+# Esto puede tomar varios minutos para cargarse, así que ¡Agarra un té o un café mientras esperas!
+raw_datasets = load_dataset("code_search_net", "python")
+```
+Podemos echar un vistazo a la porción de entrenamiento para ver a qué columnas tenemos acceso:
+
+```py
+raw_datasets["train"]
+```
+
+```python out
+Dataset({
+ features: ['repository_name', 'func_path_in_repository', 'func_name', 'whole_func_string', 'language',
+ 'func_code_string', 'func_code_tokens', 'func_documentation_string', 'func_documentation_tokens', 'split_name',
+ 'func_code_url'
+ ],
+ num_rows: 412178
+})
+```
+
+Podemos ver que el conjunto de datos separa los docstrings del código y sugiere una tokenización de ambos. Acá, sólo utilizaremos la columna `whole_func_string` para entrenar nuestro tokenizador. Podemos mirar un ejemplo de estas funciones utilizando algún índice en la porción de "train".
+
+```py
+print(raw_datasets["train"][123456]["whole_func_string"])
+```
+lo cual debería imprimir lo siguiente:
+
+```out
+def handle_simple_responses(
+ self, timeout_ms=None, info_cb=DEFAULT_MESSAGE_CALLBACK):
+ """Accepts normal responses from the device.
+
+ Args:
+ timeout_ms: Timeout in milliseconds to wait for each response.
+ info_cb: Optional callback for text sent from the bootloader.
+
+ Returns:
+ OKAY packet's message.
+ """
+ return self._accept_responses('OKAY', info_cb, timeout_ms=timeout_ms)
+```
+
+Lo primero que necesitamos hacer es transformar el dataset en un _iterador_ de listas de textos -- por ejemplo, una lista de listas de textos. utilizar listas de textos permitirá que nuestro tokenizador vaya más rápido (entrenar en batches de textos en vez de procesar textos de manera individual uno por uno), y debería ser un iterador si queremos evitar tener cargar todo en memoria de una sola vez. Si tu corpus es gigante, querrás tomar ventaja del hecho que 🤗 Datasets no carga todo en RAM sino que almacena los elementos del conjunto de datos en disco.
+Hacer lo siguiente debería crear una lista de listas de 1000 textos cada una, pero cargando todo en memoria:
+
+```py
+# Don't uncomment the following line unless your dataset is small!
+# training_corpus = [raw_datasets["train"][i: i + 1000]["whole_func_string"] for i in range(0, len(raw_datasets["train"]), 1000)]
+```
+
+Al usar un generador de Python, podemos evitar que Python cargue todo en memoria hasta que sea realmente necesario. Para crear dicho generador, solo necesitas reemplazar los corchetes con paréntesis:
+
+```py
+training_corpus = (
+ raw_datasets["train"][i : i + 1000]["whole_func_string"]
+ for i in range(0, len(raw_datasets["train"]), 1000)
+)
+```
+Esta línea de código no trae ningún elemento del conjunto de datos; sólo crea un objeto que se puede usar en Python con un ciclo `for`. Los textos sólo serán cargados cuando los necesites (es decir, cuando estás un paso del ciclo `for` que los requiera), y sólo 1000 textos a la vez serán cargados. De eso forma no agotarás toda tu memoria incluso si procesas un conjunto de datos gigante.
+
+El problema con un objeto generador es que sólo se puede usar una vez. Entonces en vea que el siguiente código nos entregue una lista de los primeros 10 dígitos dos veces:
+
+```py
+gen = (i for i in range(10))
+print(list(gen))
+print(list(gen))
+```
+Nos lo entrega una vez, y luego una lista vacía:
+
+```python out
+[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
+[]
+```
+
+Es por eso que definimos una función que retorne un generador:
+
+```py
+def get_training_corpus():
+ return (
+ raw_datasets["train"][i : i + 1000]["whole_func_string"]
+ for i in range(0, len(raw_datasets["train"]), 1000)
+ )
+
+
+training_corpus = get_training_corpus()
+```
+También puedes definir un generador dentro de un ciclo `for`utilizando el comando `yield`:
+
+```py
+def get_training_corpus():
+ dataset = raw_datasets["train"]
+ for start_idx in range(0, len(dataset), 1000):
+ samples = dataset[start_idx : start_idx + 1000]
+ yield samples["whole_func_string"]
+```
+
+el cual producirá el mismo generador anterior, pero también permitiendo usar lógicas más complejas de las que se puede hacer en un `list comprehension`.
+
+## Entrenar un nuevo Tokenizador[[training-a-new-tokenizer]]
+
+Ahora que tenemos nuestro corpus en la forma de un iterador de lotes de textos, estamos listos para entrenar un nuevo tokenizador. Para hacer esto, primero tenemos que cargar el tokenizador que queremos utilizar con nuestro modelo (en este caso, GPT-2):
+
+```py
+from transformers import AutoTokenizer
+
+old_tokenizer = AutoTokenizer.from_pretrained("gpt2")
+```
+Aunque vamos a entrenar un nuevo tokenizador, es una buena idea hacer esto para evitar comenzar de cero completamente. De esta manera, no tendremos que especificar nada acerca del algoritmo de tokenización o de los tokens especiales que queremos usar; nuestro tokenizador será exactamente el mismo que GPT-2, y lo único que cambiará será el vocabulario, el cuál será determinado por el entrenamiento en nuestro corpus.
+
+Primero, echemos un vistazo a cómo este tokenizador tratará una función de ejemplo:
+
+```py
+example = '''def add_numbers(a, b):
+ """Add the two numbers `a` and `b`."""
+ return a + b'''
+
+tokens = old_tokenizer.tokenize(example)
+tokens
+```
+
+```python out
+['def', 'Ġadd', '_', 'n', 'umbers', '(', 'a', ',', 'Ġb', '):', 'Ċ', 'Ġ', 'Ġ', 'Ġ', 'Ġ"""', 'Add', 'Ġthe', 'Ġtwo',
+ 'Ġnumbers', 'Ġ`', 'a', '`', 'Ġand', 'Ġ`', 'b', '`', '."', '""', 'Ċ', 'Ġ', 'Ġ', 'Ġ', 'Ġreturn', 'Ġa', 'Ġ+', 'Ġb']
+```
+
+Este tokenizador tiene algunos símbolos especiales como `Ġ` y `Ċ`, lo cual denota espacios y nuevas líneas (saltos de líneas) respectivamente. Como podemos ver, esto no es muy eficiente: el tokenizador retorna tokens individuales para cada espacio, cuando debería agrupar los niveles de indentación (dado que tener grupos de cuatro u ocho espacios va a ser muy común en el uso de código). Además separa el nombre de la función de manera un poco extraña al no estar acostumbrado a ver palabras separadas con el caracter `_`.
+
+Entrenemos nuestro nuevo tokenizador y veamos si resuelve nuestros problemas. Para esto usaremos el método `train_new_from_iterator()`:
+
+```py
+tokenizer = old_tokenizer.train_new_from_iterator(training_corpus, 52000)
+```
+Este comando puede tomar tiempo si tu corpus es muy largo, pero para este conjunto de datos de 1.6 GB de textos es muy rápido (1 minuto 16 segundos en un AMD Ryzen 9 3900X CPU con 12 núcleos).
+
+Nota que `AutoTokenizer.train_new_from_iterator()` sólo funciona si el tokenizador que estás usando es un tokenizador rápido (_fast tokenizer_). Cómo verás en la siguiente sección, la librería 🤗 Transformers contiene 2 tipos de tokenizadores: algunos están escritos puramente en Python y otros (los rápidos) están respaldados por la librería 🤗 Tokenizers, los cuales están escritos en lenguaje de programación [Rust](https://www.rust-lang.org). Python es el lenguaje mayormente usado en ciencia de datos y aplicaciones de deep learning, pero cuando algo necesita ser paralelizado para ser rápido, tiene que ser escrito en otro lenguaje. Por ejemplo, las multiplicaciones matriciales que están en el corazón de los cómputos de un modelo están escritos en CUDA, una librería optimizada en C para GPUs. del computation are written in CUDA, an optimized C library for GPUs.
+
+Entrenar un nuevo tokenizador en Python puro sería insoportablemente lento, razón pr la cual desarrollamos la librería 🤗 Tokenizers. Notar que de la misma manera que no tuviste que aprender el lenguaje CUDA para ser capaz de ejecutar tu modelo en un barch de inputs en una GPU, no necesitarás aprender Rust para usar los tokenizadores rápidos (_fast tokenizers_). La librería 🤗 Tokenizers provee bindings en Python para muchos métodos que internamente llaman trozos de código en Rust; por ejemplo, para paralelizar el entrenamiento de un nuevo tokenizador o, como vimos en el [Capítulo 3](/course/chapter3), la tokenización de un batch de inputs.
+
+La mayoría de los modelos Transformers tienen un tokenizador rápido (_Fast Tokenizer_) disponible (hay algunas excepciones que se pueden revisar [acá](https://huggingface.co/transformers/#supported-frameworks)), y la API `AutoTokenizer` siempre seleccionar un tokenizador rápido para ti en caso de estar disponible. En la siguiente sección echaremos un vistazo a algunas de las características especiales que tienen los tokenizadores rápidos, los cuales serán realmente útiles para tareas como clasificación de tokens y question answering. Antes de sumergirnos en eso, probemos nuestro tokenizador recién entrenado en nuestro ejemplo previo:
+
+```py
+tokens = tokenizer.tokenize(example)
+tokens
+```
+
+```python out
+['def', 'Ġadd', '_', 'numbers', '(', 'a', ',', 'Ġb', '):', 'ĊĠĠĠ', 'Ġ"""', 'Add', 'Ġthe', 'Ġtwo', 'Ġnumbers', 'Ġ`',
+ 'a', '`', 'Ġand', 'Ġ`', 'b', '`."""', 'ĊĠĠĠ', 'Ġreturn', 'Ġa', 'Ġ+', 'Ġb']
+```
+
+Acá nuevamente vemos los símbolos especiales `Ġ` y `Ċ` que denotan espacios y nuevas líneas (saltos de líneas), pero también podemos ver que nuestro tokenizador aprendió algunos tokens que son altamente específicos para el corpus de funciones en Python: por ejemplo, está el token `ĊĠĠĠ` que representa una indentación y un token `Ġ"""` que representan la triple comilla para comenzar un docstring. El tokenizador también divide correctamente los nombres de funciones usando `_`. Esta es una representación más compacta ya que utilizar un tokenizador común y corriente en inglés en el mismo ejemplo nos dara una oración más larga:
+
+
+
+```py
+print(len(tokens))
+print(len(old_tokenizer.tokenize(example)))
+```
+
+```python out
+27
+36
+```
+Echemos un vistazo al siguiente ejemplo:
+
+```python
+example = """class LinearLayer():
+ def __init__(self, input_size, output_size):
+ self.weight = torch.randn(input_size, output_size)
+ self.bias = torch.zeros(output_size)
+
+ def __call__(self, x):
+ return x @ self.weights + self.bias
+ """
+tokenizer.tokenize(example)
+```
+
+```python out
+['class', 'ĠLinear', 'Layer', '():', 'ĊĠĠĠ', 'Ġdef', 'Ġ__', 'init', '__(', 'self', ',', 'Ġinput', '_', 'size', ',',
+ 'Ġoutput', '_', 'size', '):', 'ĊĠĠĠĠĠĠĠ', 'Ġself', '.', 'weight', 'Ġ=', 'Ġtorch', '.', 'randn', '(', 'input', '_',
+ 'size', ',', 'Ġoutput', '_', 'size', ')', 'ĊĠĠĠĠĠĠĠ', 'Ġself', '.', 'bias', 'Ġ=', 'Ġtorch', '.', 'zeros', '(',
+ 'output', '_', 'size', ')', 'ĊĊĠĠĠ', 'Ġdef', 'Ġ__', 'call', '__(', 'self', ',', 'Ġx', '):', 'ĊĠĠĠĠĠĠĠ',
+ 'Ġreturn', 'Ġx', 'Ġ@', 'Ġself', '.', 'weights', 'Ġ+', 'Ġself', '.', 'bias', 'ĊĠĠĠĠ']
+```
+
+En adición al token correspondiente a la indentación, también podemos ver un token para la doble indentación: `ĊĠĠĠĠĠĠĠ`. Palabras espaciales del lenguaje Python como `class`, `init`, `call`, `self`, and `return` son tokenizadas como un sólo token y podemos ver que además de dividir en `_` y `.`, el tokenizador correctamente divide incluso en nombres que usan camel-case: `LinearLayer` es tokenizado como `["ĠLinear", "Layer"]`.
+
+## Guardar el Tokenizador[[saving-the-tokenizer]]
+
+
+Para asegurarnos que podemos usar el tokenizador más tarde, necesitamos guardar nuestro nuevo tokenizador. Al igual que los modelos, esto se hace con el método `save_pretrained()`.
+
+```py
+tokenizer.save_pretrained("code-search-net-tokenizer")
+```
+
+Esto creará una nueva carpeta llamada *code-search-net-tokenizer*, la cual contendrá todos los archivos que el tokenizador necesita para ser cargado. Si quieres compartir el tokenizador con tus colegas y amigos, puedes subirlo al Hub logeando en tu cuenta. Si estás trabajando en notebooks, hay una función conveniente para ayudarte a hacer esto:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Esto mostrará un widget donde puedes ingresar tus credenciales de Hugging Face. En caso de no estar usando un notebook, puedes escribir la siguiente línea en tu terminal:
+
+```bash
+huggingface-cli login
+```
+
+Una vez logueado puedes enviar tu tokenizador al Hub ejecutando el siguiente comando::
+
+```py
+tokenizer.push_to_hub("code-search-net-tokenizer")
+```
+Esto creará un nuevo repositorio en tu namespace con el nombre `code-search-net-tokenizer`, conteniendo el archivo del tokenizador. Luego puedes cargar tu tokenizador desde donde quieras utilizando método `from_pretrained()`.
+
+```py
+# Replace "huggingface-course" below with your actual namespace to use your own tokenizer
+tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")
+```
+Ya estás listo para entrenar un modelo de lenguaje desde cero y hacer fine-tuning en la tarea que desees. Llegaremos a eso en el [Capítulo 7](/course/chapter7), pero primero en el resto del capítulo miraremos más de cerca los tokenizadores rápidos (_Fast Tokenizers_) y explorar en detalle lo que pasa en realidad pasa cuando llamamos al método `train_new_from_iterator()`.
diff --git a/chapters/es/chapter6/3.mdx b/chapters/es/chapter6/3.mdx
new file mode 100644
index 000000000..65392631a
--- /dev/null
+++ b/chapters/es/chapter6/3.mdx
@@ -0,0 +1,478 @@
+
+
+# Los poderes especiales de los Tokenizadores Rápidos (Fast tokenizers)[[fast-tokenizers-special-powers]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+
+
+
+
+En esta sección miraremos más de cerca las capacidades de los tokenizadores en 🤗 Transformers. Hasta ahora sólo los hemos utilizado para tokenizar las entradas o decodificar los IDs en texto, pero los tokenizadores -- especialmente los que están respaldados en la librería 🤗 Tokenizers -- pueden hacer mucho más. Para ilustrar estas características adicionales, exploraremos cómo reproducir los resultados de los pipelines de `clasificación de tokens` (al que llamamos ner) y `question-answering` que nos encontramos en el [Capítulo 1](/course/chapter1).
+
+
+
+En la siguiente discusión, a menudo haremos la diferencia entre un tokenizador "lento" y uno "rápido". Los tokenizadores lentos son aquellos escritos en Python dentro de la librería Transformers, mientras que las versiones provistas por la librería 🤗 Tokenizers, son los que están escritos en Rust. Si recuerdas la tabla del [Capítulo 5](/course/chapter5/3) en la que se reportaron cuanto tomó a un tokenizador rápido y uno lento tokenizar el Drug Review Dataset, ya deberías tener una idea de por qué los llamamos rápidos y lentos:
+
+
+| | Tokenizador Rápido | Tokenizador Lento
+:--------------:|:--------------:|:-------------:
+`batched=True` | 10.8s | 4min41s
+`batched=False` | 59.2s | 5min3s
+
+
+
+⚠️ Al tokenizar una sóla oración, no siempre verás una diferencia de velocidad entre la versión lenta y la rápida del mismo tokenizador. De hecho, las versión rápida podría incluso ser más lenta! Es sólo cuando se tokenizan montones de textos en paralelos al mismo tiempo que serás capaz de ver claramente la diferencia.
+
+
+
+## Codificación en Lotes (Batch Encoding)[[batch-encoding]]
+
+
+
+La salida de un tokenizador no siempre un simple diccionario; lo que se obtiene en realidad es un objeto especial `BatchEncoding`. Es una subclase de un diccionario (razón por la cual pudimos indexar el resultado sin ningún problema anteriormente), pero con métodos adicionales que son mayormente usados por los tokenizadores rápidos (_Fast Tokenizers_).
+
+Además de sus capacidad en paralelización, la funcionalidad clave de un tokenizador rápido es que siempre llevan registro de la porción de texto de la cual los tokens finales provienen -- una característica llamada *offset mapping*. Esto permite la capacidad de mapear cada palabra con el token generado o mapear cada caracter del texto original con el token respectivo y viceversa.
+
+Echemos un vistazo a un ejemplo:
+
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+example = "My name is Sylvain and I work at Hugging Face in Brooklyn."
+encoding = tokenizer(example)
+print(type(encoding))
+```
+Como se mencionó previamente, obtenemos un objeto de tipo `BatchEncoding` como salida del tokenizador:
+
+```python out
+
+```
+
+Dado que la clase `AutoTokenizer` escoge un tokenizador rápido por defecto, podemos usar los métodos adicionales que este objeto `BatchEncoding` provee. Tenemos dos manera de chequear si el tokenizador es rápido o lento. Podemos chequear el atributo `is_fast` del tokenizador:
+
+```python
+tokenizer.is_fast
+```
+
+```python out
+True
+```
+o chequear el mismo atributo de nuestro `encoding`:
+
+```python
+encoding.is_fast
+```
+
+```python out
+True
+```
+
+Veamos lo que un tokenizador rápido nos permite hacer. Primero podemos acceder a los tokens sin tener que convertir los IDs a tokens:
+
+```py
+encoding.tokens()
+```
+
+```python out
+['[CLS]', 'My', 'name', 'is', 'S', '##yl', '##va', '##in', 'and', 'I', 'work', 'at', 'Hu', '##gging', 'Face', 'in',
+ 'Brooklyn', '.', '[SEP]']
+```
+
+En este caso el token con índice 5 is `##yl`, el cual es parte de la palabra "Sylvain" en la oración original. Podemos también utilizar el método `word_ids()` para obtener el índice de la palabra de la que cada token proviene:
+
+```py
+encoding.word_ids()
+```
+
+```python out
+[None, 0, 1, 2, 3, 3, 3, 3, 4, 5, 6, 7, 8, 8, 9, 10, 11, 12, None]
+```
+
+Podemos ver que los tokens especiales del tokenizador `[CLS]` y `[SEP]` están mapeados a `None`, y que cada token está mapeado a la palabra de la cual se origina. Esto es especialmente útil para determinar si el token está al inicio de la palabra o si dos tokens están en la misma palabra. POdríamos confiar en el prefijo `[CLS]` and `[SEP]` para eso, pero eso sólo funciona para tokenizadores tipo BERT; este método funciona para cualquier tipo de tokenizador mientras sea de tipo rápido. En el próximo capítulo, veremos como podemos usar esta capacidad para aplicar etiquetas para cada palabra de manera apropiada en tareas como Reconocimiento de Entidades (Named Entity Recognition NER), y etiquetado de partes de discurso (part-of-speech POS tagging). También podemos usarlo para enmascarar todos los tokens que provienen de la misma palabra en masked language modeling (una técnica llamada _whole word masking_).
+
+
+
+La noción de qué es una palabra es complicada. Por ejemplo "I'll" (la contracción de "I will" en inglés) ¿cuenta como una o dos palabras? De hecho depende del tokenizador y la operación de pretokenización que aplica. Algunos tokenizadores sólo separan en espacios, por lo que considerarán esto como una sóla palabra. Otros utilizan puntuación por sobre los espacios, por lo que lo considerarán como dos palabras.
+
+✏️ **Inténtalo!** Crea un tokenizador a partir de los checkpoints `bert-base-cased` y `roberta-base` y tokeniza con ellos "81s". ¿Qué observas? Cuál son los IDs de la palabra?
+
+
+
+De manera similar está el método `sentence_ids()` que podemos utilizar para mapear un token a la oración de la cuál proviene (aunque en este caso el `token_type_ids` retornado por el tokenizador puede darnos la misma información).
+
+Finalmente, podemos mapear cualquier palabra o token a los caracteres originales del texto, y viceversa, utilizando los métodos `word_to_chars()` o `token_to_chars()` y los métodos `char_to_word()` o `char_to_token()`. Por ejemplo el método `word_ids()` nos dijo que `##yl` es parte de la palabra con índice 3, pero qué palabra es en la oración? Podemos averiguarlo así:
+
+```py
+start, end = encoding.word_to_chars(3)
+example[start:end]
+```
+
+```python out
+Sylvain
+```
+
+Como mencionamos previamente, todo esto funciona gracias al hecho de que los tokenizadores rápidos llevan registro de la porción de texto del que cada token proviene en una lista de *offsets*. Para ilustrar sus usos, a continuación mostraremos como replicar los resultados del pipeline de `clasificación de tokens` de manera manual.
+
+
+
+✏️ **Inténtalo!** Crea tu propio texto de ejemplo y ve si puedes entender qué tokens están asociados con el ID de palabra, y también cómo extraer los caracteres para una palabra. Como bonus, intenta usar dos oraciones como entrada/input y ve si los IDs de oraciones te hacen sentido.
+
+
+
+## Dentro del Pipeline de `clasificación de tokens`[[inside-the-token-classification-pipeline]]
+
+En el [Capítulo 1](/course/chapter1) tuvimos nuestra primera probada aplicando NER -- donde la tarea es identificar qué partes del texto corresponden a entidades como personas, locaciones, u organizaciones -- con la función `pipeline()` de la librería 🤗 Transformers. Luego en el [Capítulo 2](/course/chapter2), vimos como un pipeline agrupa las tres etapas necesarias para obtener predicciones desde un texto crudo: tokenización, pasar los inputs a través del modelo, y post-procesamiento. Las primeras dos etapas en el pipeline de `clasificación de tokens` son las mismas que en otros pipelines, pero el post-procesamiento es un poco más complejo -- ×+/¡veamos cómo!
+
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+### Obteniendo los resultados base con el pipeline[[getting-the-base-results-with-the-pipeline]]
+
+Primero, agarremos un pipeline de clasificación de tokens para poder tener resultados que podemos comparar manualmente. El usado por defecto es [`dbmdz/bert-large-cased-finetuned-conll03-english`](https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english); el que realiza NER en oraciones:
+
+```py
+from transformers import pipeline
+
+token_classifier = pipeline("token-classification")
+token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+```python out
+[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S', 'start': 11, 'end': 12},
+ {'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl', 'start': 12, 'end': 14},
+ {'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va', 'start': 14, 'end': 16},
+ {'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in', 'start': 16, 'end': 18},
+ {'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu', 'start': 33, 'end': 35},
+ {'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging', 'start': 35, 'end': 40},
+ {'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face', 'start': 41, 'end': 45},
+ {'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+El modelo indentificó apropiadamente cada token generado por "Sylvain" como una persona, cada token generado por "Hugging Face" como una organización y el token "Brooklyn" como una locación. Podemos pedirle también al pipeline que agrupe los tokens que corresponden a la misma identidad:
+
+```py
+from transformers import pipeline
+
+token_classifier = pipeline("token-classification", aggregation_strategy="simple")
+token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+```python out
+[{'entity_group': 'PER', 'score': 0.9981694, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.97960204, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.99321055, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+La estrategia de agregación (`aggregation_strategy`) elegida cambiará los puntajes calculados para cada entidad agrupada. Con `"simple"` el puntaje es la media los puntajes de cada token en la entidad dada: por ejemplo, el puntaje de "Sylvain" es la media de los puntajes que vimos en el ejemplo previo para los tokens `S`, `##yl`, `##va`, y `##in`. Otras estrategias disponibles son:
+
+- `"first"`, donde el puntaje de cada entidad es el puntaje del primer token de la entidad (para el caso de "Sylvain" sería 0.9923828, el puntaje del token `S`)
+- `"max"`, donde el puntaje de cada entidad es el puntaje máximo de los tokens en esa entidad (para el caso de "Hugging Face" sería 0.98879766, el puntaje de "Face")
+- `"average"`, donde el puntaje de cada entidad es el promedio de los puntajes de las palabras que componen la entidad (para el caso de "Sylvain" no habría diferencia con la estrategia "simple", pero "Hugging Face" tendría un puntaje de 0.9819, el promedio de los puntajes para "Hugging", 0.975, y "Face", 0.98879)
+
+Ahora veamos como obtener estos resultados sin utilizar la función `pipeline()`!
+
+### De los inputs a las predicciones[[from-inputs-to-predictions]]
+
+{#if fw === 'pt'}
+
+Primero necesitamos tokenizar nuestro input y pasarlo a través del modelo. Esto es exactamente lo que se hace en el [Capítulo 2](/course/chapter2); instanciamos el tokenizador y el modelo usando las clases `AutoXxx` y luego los usamos en nuestro ejemplo:
+
+
+```py
+from transformers import AutoTokenizer, AutoModelForTokenClassification
+
+model_checkpoint = "dbmdz/bert-large-cased-finetuned-conll03-english"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+model = AutoModelForTokenClassification.from_pretrained(model_checkpoint)
+
+example = "My name is Sylvain and I work at Hugging Face in Brooklyn."
+inputs = tokenizer(example, return_tensors="pt")
+outputs = model(**inputs)
+```
+
+Dado que estamos usando acá `AutoModelForTokenClassification`, obtenemos un conjunto de logits para cada token en la secuencia de entrada:
+
+```py
+print(inputs["input_ids"].shape)
+print(outputs.logits.shape)
+```
+
+```python out
+torch.Size([1, 19])
+torch.Size([1, 19, 9])
+```
+
+{:else}
+
+Primero necesitamos tokenizar nuestro input y pasarlo por nuestro modelo. Esto es exactamente lo que se hace en el [Capítulo 2](/course/chapter2); instanciamos el tokenizador y el modelo usando las clases `TFAutoXxx` y luego los usamos en nuestro ejemplo:
+
+```py
+from transformers import AutoTokenizer, TFAutoModelForTokenClassification
+
+model_checkpoint = "dbmdz/bert-large-cased-finetuned-conll03-english"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+model = TFAutoModelForTokenClassification.from_pretrained(model_checkpoint)
+
+example = "My name is Sylvain and I work at Hugging Face in Brooklyn."
+inputs = tokenizer(example, return_tensors="tf")
+outputs = model(**inputs)
+```
+Dado que estamos usando acá `TFAutoModelForTokenClassification`, obtenemos un conjunto de logits para cada token en la secuencia de entrada:
+
+```py
+print(inputs["input_ids"].shape)
+print(outputs.logits.shape)
+```
+
+```python out
+(1, 19)
+(1, 19, 9)
+```
+
+{/if}
+
+Tenemos un lote de 1 secuencia con 19 tokens y el modelo tiene 9 etiquetas diferentes, por lo que la salida del modelo tiene dimensiones 1 x 19 x 9. Al igual que el pipeline de clasificación de texto, usamos la función softmax para convertir esos logits en probabilidades, y tomamos el argmax para obtener las predicciones (notar que podemos tomar el argmax de los logits directamente porque el softmax no cambia el orden):
+
+{#if fw === 'pt'}
+
+```py
+import torch
+
+probabilities = torch.nn.functional.softmax(outputs.logits, dim=-1)[0].tolist()
+predictions = outputs.logits.argmax(dim=-1)[0].tolist()
+print(predictions)
+```
+
+{:else}
+
+```py
+import tensorflow as tf
+
+probabilities = tf.math.softmax(outputs.logits, axis=-1)[0]
+probabilities = probabilities.numpy().tolist()
+predictions = tf.math.argmax(outputs.logits, axis=-1)[0]
+predictions = predictions.numpy().tolist()
+print(predictions)
+```
+
+{/if}
+
+```python out
+[0, 0, 0, 0, 4, 4, 4, 4, 0, 0, 0, 0, 6, 6, 6, 0, 8, 0, 0]
+```
+
+El atributo `model.config.id2label` contiene el mapeo de los índices con las etiquetas para que podemos hacer sentido de las predicciones:
+
+```py
+model.config.id2label
+```
+
+```python out
+{0: 'O',
+ 1: 'B-MISC',
+ 2: 'I-MISC',
+ 3: 'B-PER',
+ 4: 'I-PER',
+ 5: 'B-ORG',
+ 6: 'I-ORG',
+ 7: 'B-LOC',
+ 8: 'I-LOC'}
+```
+
+Como vimos antes, hay 9 etiquetas: `0` es la etiqueta para los tokens que no tienen ningúna entidad (proviene del inglés "outside"), y luego tenemos dos etiquetas para cada tipo de entidad (misceláneo, persona, organización, y locación). La etiqueta `B-XXX` indica que el token is el inicio de la entidad `XXX` y la etiqueta `I-XXX` indica que el token está dentro de la entidad `XXX`. For ejemplo, en el ejemplo actual esperaríamos que nuestro modelo clasificará el token `S` como `B-PER` (inicio de la entidad persona), y los tokens `##yl`, `##va` y `##in` como `I-PER` (dentro de la entidad persona).
+
+Podrías pensar que el modelo está equivocado en este caso ya que entregó la etiqueta `I-PER` a los 4 tokens, pero eso no es completamente cierto. En realidad hay 4 formatos par esas etiquetas `B-` y `I-`: *I0B1* y *I0B2*. El formato I0B2 (abajo en rosado), es el que presentamos, mientras que en el formato I0B1 (en azul), las etiquetas de comenzando con `B-` son sólo utilizadas para separar dos entidades adyacentes del mismo tipo. Al modelo que estamos usando se le hizo fine-tune en un conjunto de datos utilizando ese formato, lo cual explica por qué asigna la etiqueta `I-PER` al token `S`.
+
+
+

+

+
+

+

+
+

+

+
+
+
+
`` y '' con " y cualquier secuencia de dos o más espacios con un espacio simple, además remueve los acentos en el texto a tokenizar.
+
+El pre-tokenizador a usar para cualquier tokenizador SentencePiece es `Metaspace`:
+
+```python
+tokenizer.pre_tokenizer = pre_tokenizers.Metaspace()
+```
+
+Podemos echar un vistazo a la pre-tokenización de un texto de ejemplo como antes:
+
+```python
+tokenizer.pre_tokenizer.pre_tokenize_str("Let's test the pre-tokenizer!")
+```
+
+```python out
+[("▁Let's", (0, 5)), ('▁test', (5, 10)), ('▁the', (10, 14)), ('▁pre-tokenizer!', (14, 29))]
+```
+
+A continuación está el modelo, el cuál necesita entrenamiento. XLNet tiene varios tokens especiales:
+
+```python
+special_tokens = ["", "", "", "", "", "", ""]
+trainer = trainers.UnigramTrainer(
+ vocab_size=25000, special_tokens=special_tokens, unk_token=""
+)
+tokenizer.train_from_iterator(get_training_corpus(), trainer=trainer)
+```
+
+Un argumento muy importante a no olvidar para el `UnigramTrainer` es el `unk_token`. También podemos pasarle otros argumentos específicos al algoritmo Unigram, tales como el `shrinking_factor` para cada paso donde removemos tokens (su valor por defecto es 0.75) o el `max_piece_length` para especificar el largo máximo de un token dado (su valor por defecto es 16).
+
+Este tokenizador también se puede entrenar en archivos de texto:
+
+```python
+tokenizer.model = models.Unigram()
+tokenizer.train(["wikitext-2.txt"], trainer=trainer)
+```
+
+Ahora miremos la tokenización de un texto de muestra:
+
+```python
+encoding = tokenizer.encode("Let's test this tokenizer.")
+# print(encoding.tokens)
+```
+
+```python out
+['▁Let', "'", 's', '▁test', '▁this', '▁to', 'ken', 'izer', '.']
+```
+
+Una peculiariodad de XLNet es que coloca el token `` al final de la oración, con un ID de tipo de 2 (para distinguirlo de los otros tokens). Como el resultado el resultado se rellena a la izquierda (left padding). Podemos lidiar con todos los tokens especiales y el token de ID de tipo con una plantilla, al igual que BERT, pero primero tenemos que obtener los IDs de los tokens `` y ``:
+
+```python
+cls_token_id = tokenizer.token_to_id("")
+sep_token_id = tokenizer.token_to_id("")
+# print(cls_token_id, sep_token_id)
+```
+
+```python out
+0 1
+```
+
+La plantilla se ve así:
+
+```python
+tokenizer.post_processor = processors.TemplateProcessing(
+ single="$A:0 :0 :2",
+ pair="$A:0 :0 $B:1 :1 :2",
+ special_tokens=[("", sep_token_id), ("", cls_token_id)],
+)
+```
+
+Y podemos probar si funciona codificando un par de oraciones:
+
+```python
+encoding = tokenizer.encode("Let's test this tokenizer...", "on a pair of sentences!")
+# print(encoding.tokens)
+# print(encoding.type_ids)
+```
+
+```python out
+['▁Let', "'", 's', '▁test', '▁this', '▁to', 'ken', 'izer', '.', '.', '.', '', '▁', 'on', '▁', 'a', '▁pair',
+ '▁of', '▁sentence', 's', '!', '', '']
+[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2]
+```
+
+Finalmente, agregamos el decodificador `Metaspace`:
+
+```python
+tokenizer.decoder = decoders.Metaspace()
+```
+
+y estamos listos con este tokenizador! Podemos guardar el tokenizador como antes, y envolverlo en un `PreTrainedTokenizerFast` o `XLNetTokenizerFast` si queremos usarlo en 🤗 Transformers. Una cosa a notar al usar `PreTrainedTokenizerFast` es que además de los tokens especiales, necesitamos decirle a la librería 🤗 Transformers que rellene a la izquierda (agregar left padding):
+
+```python
+from transformers import PreTrainedTokenizerFast
+
+wrapped_tokenizer = PreTrainedTokenizerFast(
+ tokenizer_object=tokenizer,
+ bos_token="",
+ eos_token="",
+ unk_token="",
+ pad_token="",
+ cls_token="",
+ sep_token="",
+ mask_token="",
+ padding_side="left",
+)
+```
+
+O de manera alternativa:
+
+```python
+from transformers import XLNetTokenizerFast
+
+wrapped_tokenizer = XLNetTokenizerFast(tokenizer_object=tokenizer)
+```
+
+Ahora que has visto como varias de nuestras unidades más básicas se usan para construir tokenizadores existentes, deberías ser capaz de escribir cualquier tokenizador que quieras con la librería 🤗 Tokenizers y ser capaz de usarlo en la librería 🤗 Transformers.
\ No newline at end of file
diff --git a/chapters/es/chapter6/9.mdx b/chapters/es/chapter6/9.mdx
new file mode 100644
index 000000000..37efd29b3
--- /dev/null
+++ b/chapters/es/chapter6/9.mdx
@@ -0,0 +1,16 @@
+# Tokenizadores, listo![[tokenizers-check]]
+
+
+
+Gran trabajo terminando este capítulo!
+
+Luego de esta profundizacion en los tokenizadores, deberías:
+
+- Ser capaz de entrenar un nuevo tokenizador usando un existente como plantilla
+- Entender como usar los offsets para mapear las posiciones de los tokens a sus trozos de texto original
+- Conocer las diferencias entre BPE, WordPiece y Unigram
+- Ser capaz de mezclar y combinar los bloques provistos por la librería 🤗 Tokenizers para construir tu propio tokenizador
+- Ser capaz de usar el tokenizador dentro de la librería 🤗 Transformers.
diff --git a/chapters/es/glossary/1.mdx b/chapters/es/glossary/1.mdx
index 562cf2fe9..153b35f6a 100644
--- a/chapters/es/glossary/1.mdx
+++ b/chapters/es/glossary/1.mdx
@@ -36,8 +36,8 @@
| Incompatibility | Incompatibilidad |
| Inference | Inferencia |
| Key (in a dictionary) | Llave |
-| Learning rate | Rata de aprendizaje |
-| Library | Libreria |
+| Learning rate | Tasa de aprendizaje |
+| Library | Librería |
| Linux | Linux |
| Load | Cargar |
| Loss | Pérdida |
@@ -53,14 +53,14 @@
| Padding | Relleno |
| Parameter | Parámetro |
| Python | Python |
-| Pytorch | Pytorch |
+| PyTorch | PyTorch |
| Samples | Muestras |
| Save | Guardar |
| Scheduler | Programador |
| Script | Script |
| Self-Contained | Auto-contenido |
| Setup | Instalación |
-| TensorFlow | Tensorflow |
+| TensorFlow | TensorFlow |
| Terminal | Terminal |
| Tokenizer | Tokenizador |
| Train | Entrenar |
@@ -90,10 +90,10 @@ Please refer to [TRANSLATING.txt](/chapters/es/TRANSLATING.txt) for a translatio
- Refer and contribute to the glossary frequently to stay on top of the latest choices we make. This minimizes the amount of editing that is required. Add new terms alphabetically sorted.
-- In certain cases is better to accept an Enlish word. Check for the correct usage of terms in computer science and commonly used terms in other publications.
+- In certain cases is better to accept an English word. Check for the correct usage of terms in computer science and commonly used terms in other publications.
- Don't translate industry-accepted acronyms. e.g. TPU or GPU.
- If translating a technical word, keep the choice of Spanish translation consistent. This does not apply for non-technical choices, as in those cases variety actually helps keep the text engaging.
-- Be exact when choosing equivalents for technical words. Package is Paquete. Library is Libreria. Don't mix and match.
+- Be exact when choosing equivalents for technical words. Package is Paquete. Library is Librería. Don't mix and match.
diff --git a/chapters/fa/_toctree.yml b/chapters/fa/_toctree.yml
index afe4a516f..5b7f5151f 100644
--- a/chapters/fa/_toctree.yml
+++ b/chapters/fa/_toctree.yml
@@ -19,6 +19,16 @@
- local: chapter2/3
title: مدلها
+- title: ۳- کوک کردن یک مدل از پیش تعلیم دیده
+ sections:
+ - local: chapter3/1
+ title: مقدمه
+ - local: chapter3/2
+ title: پردازش داده
+ - local: chapter3/3
+ title: کوک کردن مدلها با استفاده از Trainer API یا کِراس
+ local_fw: { pt: chapter3/3, tf: chapter3/3_tf }
+
- title: ۴- به اشتراکگذاری مدلها و توکِنایزرها
sections:
- local: chapter4/1
@@ -26,13 +36,6 @@
- local: chapter4/2
title: بکارگیری مدلهای از پیش تعلیم دیده
-- title: 3. کوک کردن یک مدل از پیش تعلیم دیده
- sections:
- - local: chapter3/1
- title: مقدمه
- - local: chapter3/2
- title: پردازش داده
-
- title: واژهنامه
sections:
- local: glossary/1
diff --git a/chapters/fa/chapter0/1.mdx b/chapters/fa/chapter0/1.mdx
index d46295940..9f9cd475f 100644
--- a/chapters/fa/chapter0/1.mdx
+++ b/chapters/fa/chapter0/1.mdx
@@ -115,7 +115,7 @@
source .env/bin/activate
\# Deactivate the virtual environment
- source .env/bin/deactivate
+ deactivate
```
diff --git a/chapters/fa/chapter3/2.mdx b/chapters/fa/chapter3/2.mdx
index d553572ad..9b50e29e3 100644
--- a/chapters/fa/chapter3/2.mdx
+++ b/chapters/fa/chapter3/2.mdx
@@ -99,12 +99,15 @@ model.train_on_batch(batch, labels)
{/if}
-هاب تنها شامل مدلها نمیباشد؛ بلکه شامل دیتاسِتهای متعدد در بسیاری از زبانهای مختلف میباشد. شما میتوانید دیتاسِتها را در این [لینک](https://huggingface.co/datasets) جستجو کنید و پیشنهاد میکنیم پس از اتمام این بخش یک دیتاسِت جدید را دریافت و پردازش کنید (بخش مستندات عمومی را در [اینجا](https://huggingface.co/docs/datasets/loading_datasets.html#from-the-huggingface-hub) مشاهده کنید). اما اجازه بدهید اکنون روی دیتاسِت MRPC تمرکز کنیم! این یکی از ۱۰ دیتاسِت [GLUE benchmark](https://gluebenchmark.com/) است که یک محک تهیه شده در محیط دانشگاهی جهت اندازه گیری کارکرد مدلهای یادگیری ماشینی در ۱۰ مسئله دستهبندی متن مختلف میباشد.
+هاب تنها شامل مدلها نمیباشد؛ بلکه شامل دیتاسِتهای متعدد در بسیاری از زبانهای مختلف میباشد. شما میتوانید دیتاسِتها را در این [لینک](https://huggingface.co/datasets) جستجو کنید و پیشنهاد میکنیم پس از اتمام این بخش یک دیتاسِت جدید را دریافت و پردازش کنید (بخش مستندات عمومی را در [اینجا](https://huggingface.co/docs/datasets/loading) مشاهده کنید). اما اجازه بدهید اکنون روی دیتاسِت MRPC تمرکز کنیم! این یکی از ۱۰ دیتاسِت [GLUE benchmark](https://gluebenchmark.com/) است که یک محک تهیه شده در محیط دانشگاهی جهت اندازه گیری کارکرد مدلهای یادگیری ماشینی در ۱۰ مسئله دستهبندی متن مختلف میباشد.
کتابخانه دیتاسِت هاگینگفِیس یک دستور بسیار ساده جهت دانلود و انبار کردن یک دیتاسِت در هاب ارائه میکند. ما میتوانیم دیتاسِت MRPC را به روش زیر دانلود کنیم:
+
+⚠️ **هشدار** مطمئن شوید که `datasets` نصب شده است. برای اطمینان، دستور `pip install datasets` را اجرا کنید. سپس، مجموعه داده MRPC را بارگذاری کنید و آن را چاپ کنید تا ببینید چه چیزی در آن وجود دارد.
+
```py
from datasets import load_dataset
@@ -300,7 +303,7 @@ tokenized_dataset = tokenizer(
این روش به خوبی کار میکند، اما مشکلاش این است که دیکشنری (از کلیدهای ما شامل، `input_ids`, `attention_mask` و `token_type_ids` و مقادیر آنها که لیستهایی از لیستها هستند) برمیگرداند. همچنین این روش فقط زمانی کار میکند که حافظه موقت کافی جهت ذخیرهسازی کل دیتاسِت در حین توکِن کردن داشته باشید (در حالی که دیتاسِتهای موجود در کتابخانه `Datatasets` از هاگینگفِیس فایلهایی از نوع [Apache Arrow](https://arrow.apache.org/) هستند که روی دیسک ذخیره شدهاند، بنابراین شما فقط نمونههایی را که جهت ذخیره در حافظه درخواست کردهاید نگه میدارید).
-به منظور نگه داشتن داده به صورت یک دیتاسِت، از تابع
[`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) استفاده میکنیم. چنانچه به پیشپردازشهای بیشتری علاوه بر توکِن کردن نیاز داشته باشیم این روش انعطافپذیری لازم را به ما میدهد. تابع
`map()` با اعمال کردن یک عملیات روی هر عنصر دیتاسِت عمل میکند، بنابراین اجازه دهید تابعی تعریف کنیم که ورودیها را توکِن کند:
+به منظور نگه داشتن داده به صورت یک دیتاسِت، از تابع
[`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) استفاده میکنیم. چنانچه به پیشپردازشهای بیشتری علاوه بر توکِن کردن نیاز داشته باشیم این روش انعطافپذیری لازم را به ما میدهد. تابع
`map()` با اعمال کردن یک عملیات روی هر عنصر دیتاسِت عمل میکند، بنابراین اجازه دهید تابعی تعریف کنیم که ورودیها را توکِن کند:
@@ -498,4 +501,4 @@ tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
[^1]: Microsoft Research Paraphrase Corpus
-
\ No newline at end of file
+
diff --git a/chapters/fa/chapter3/3.mdx b/chapters/fa/chapter3/3.mdx
new file mode 100644
index 000000000..aa64dc157
--- /dev/null
+++ b/chapters/fa/chapter3/3.mdx
@@ -0,0 +1,221 @@
+
+
+
+
+# کوک کردن مدلها با استفاده از API `Trainer`
+
+
+
+
+
+ترنسفورمرهای هاگینگفِیس کلاسی به نام `Trainer` دارند که برای کمک به کوک کردن هر مدل از پیش تعلیم دیدهای که روی داده شما ارائه میدهد به کار میرود. به محض اینکه همه کارهای پیشپردازش داده در بخش آخر را انجام دادید، فقط چند مرحله باقیمانده تا تعریف `Trainer` دارید. سخت ترین قسمت، احتمالا آمادهسازی محیط جهت اجراي
`Trainer.train()` میباشد، چرا که این تابع روی CPU بسیار کند اجرا میشود. اگر GPU ندارید، میتوانید از GPU یا TPUهای مجانی روی [گوگل کولَب](https://colab.research.google.com/) استفاده کنید.
+
+نمونه کدهای زیر فرض میکنند که شما مثالهای بخش قبل را از پیش اجرا کردهاید. این یک خلاصه کوتاه است جهت یادآوری آنچه نیاز دارید:
+
+
+
+
+```py
+from datasets import load_dataset
+from transformers import AutoTokenizer, DataCollatorWithPadding
+
+raw_datasets = load_dataset("glue", "mrpc")
+checkpoint = "bert-base-uncased"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+
+def tokenize_function(example):
+ return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
+
+
+tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
+data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+```
+
+
+
+### تعلیم
+
+قبل از این که بتوانیم `Trainer` مان را تعریف کنیم اولین مرحله تعریف کلاس `TrainingArguments` میباشد که شامل همه پارامترهای سطح بالایی است که `Trainer` برای `Training` و `Evaluation` استفاده خواهد کرد. تنها آرگومانی که شما باید ارائه کنید آدرسی است که مدل تعلیم دیده به همراه نقاط تعلیم در آن ذخیره خواهند شد. بقیه پارامترها را میتوانید به حالت پیشفرض رها کنید، که برای کوک کردن پایه به خوبی کار خواهد کرد.
+
+
+
+
+```py
+from transformers import TrainingArguments
+
+training_args = TrainingArguments("test-trainer")
+```
+
+
+
+
+
+💡 اگر مایلید مدلتان را به صورت خودکار در حین تعلیم در هاب بارگذاری کنید، پارامتر `push_to_hub=True` را در `TrainingArguments` ارسال کنید. در [فصل ۴](/course/chapter4/3) در این باره بیشتر خواهیم آموخت.
+
+
+
+مرحله دوم تعریف مدلمان میباشد. مانند [فصل قبل](/course/chapter2)، از کلاس `AutoModelForSequenceClassification` با دو برچسب کلاس استفاده خواهیم کرد:
+
+
+
+```py
+from transformers import AutoModelForSequenceClassification
+
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+```
+
+
+
+شما متوجه خواهید شد که برخلاف [فصل ۲](/course/chapter2)، بعد از ساختن این مدل از پیش تعلیم دیده یک هشدار دریافت میکنید. این به این خاطر است که BERT برای دستهبندی دو جملهها از پیش تعلیم ندیده است، بنابراین لایه سَر مدل از پیش تعلیم دیده حذف شده و یک لایه سَر مناسب جهت دسته بندی رشتهها به جای آن قرار گرفته است. هشدارها نشان میدهند که برخی از وزنهای مدل استفاده نشدهاند (آنهایی که مربوط به لایه سَر حذف شده مدل از پیش تعلیم دیده هستند) و برخی دیگر به صورت تصادفی مقدار دهی شدهاند (آنهایی که مربوط به لایه سَر جدید هستند). در نتیجه این امر شما را تشویق به تعلیم مدل میکند، که دقیقا همان کاری است که میخواهیم اکنون انجام دهیم.
+
+به محض اینکه مدلمان مشخص شد میتوانیم `Trainer` را با ارسال همه اشیائی که تا کنون ساخته شدهاند -
`model`،
`training_args`، دیتاسِتهای
`training` و
`validation`،
`data_collator` و
`tokenizer` به داخل آن تعریف کنیم:
+
+
+
+```py
+from transformers import Trainer
+
+trainer = Trainer(
+ model,
+ training_args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+)
+```
+
+
+
+توجه داشته باشید زمانی که `tokenizer` را ارسال میکنید، مثل کاری که ما در اینجا انجام دادیم، `data_collator` پیشفرض مورد استفاده `Trainer`، همانطور که قبلا تعریف کردیم، `DataCollatorWithPadding` خواهد بود، در تنیجه شما میتوانید خط `data_collator=data_collator` را در این فراخوانی نادیده بگیرید. این هنوز مهم بود که این بخش از پردازش را در بخش ۲ به شما نشان دهیم!
+
+برای کوک کردن مدل روی دیتاسِتمان ما فقط باید تابع
`train()` از `Trainer`مان را صدا بزنیم:
+
+
+
+```py
+trainer.train()
+```
+
+
+
+این کار، کوک کردن را شروع میکند (که باید چند دقیقه روی GPU طول بکشد) و هزینه تعلیم را هر ۵۰۰ مرحله یکبار گزارش میکند. با این حال به شما نمیگوید که مدلتان چقدر خوب (یا بد) عمل میکند. این به این خاطر است که:
+
+۱. ما به `Trainer` نگفتیم که در حین تعلیم کیفیت مدل را اندازهگیری کند. کاری که میتوانستیم با مقداردهی پارامتر `evaluation_strategy` به `"steps"` (برای ارزیابی در هر `eval_steps`) یا به `"epoch"` (برای ارزیابی در انتهای هر epoch) انجام دهیم.
+
+۲. ما تابع
`compute_metrics()` را برای `Trainer` فراهم نکردیم تا بتواند معیارها را در حین اصطلاحا ارزیابی محاسبه کند (که در غیر این صورت، ارزیابی فقط هزینه را چاپ میکند که عدد چندان گویایی هم نیست) .
+
+### ارزیابی
+
+اجازه دهید ببینیم چگونه میتوانیم تابع
`compute_metrics()` مفیدی بسازیم و در تعلیم بعدی از آن استفاده کنیم. تابع باید یک شیء `EvalPrediction` دریافت کند (که تاپلی است شامل فیلدهای `predictions` و `label_ids`) و یک دیکشنری باز گرداند که رشتههای متنی را به اعداد حقیقی تبدیل میکند (رشتههای متنی نام معیارهای بازگردانده شونده و اعداد حقیقی مقادیر آنها می باشند). برای استخراج چند پیشبینی از مدلمان، میتوانیم از دستور
`Trainer.predict()` استفاده کنیم:
+
+
+
+```py
+predictions = trainer.predict(tokenized_datasets["validation"])
+print(predictions.predictions.shape, predictions.label_ids.shape)
+```
+
+```python out
+(408, 2) (408,)
+```
+
+
+
+خروجی تابع
`predict()` تاپل نام گذاری شده دیگری شامل سه فیلد: `predictions`، `label_ids` و `metrics` میباشد. فیلد `metrics` فقط شامل هزینه داده عبور کرده و برخی معیارهای زمان (پیشبینی، در مجموع و به طور میانگین، چقدر طول کشیده) میباشد. به محض این که تابع
`compute_metrics()` را کامل کرده و آن را به `Trainer` ارسال کنیم، آن فیلد متریکهای بازگشتی از
`compute_metrics()` را نیز در بر خواهد داشت.
+
+همانطور که میبینید، `predictions` آرایهای دو بعدی است با شکل
۴۰۸ x ۲ (که ۴۰۸ تعداد عناصر در دیتاسِت مورد استفاده ما میباشد). این ها logits مربوط به هریک از عناصر دیتاسِتی هستند که ما به تابع
`predict()` ارسال کردیم (همانطور که در [فصل قبل](/course/chapter2) دیدید، همه مدلهای ترَنسفورمِر logits را باز میگردانند). برای تبدیل logits به پیشبینیهایی که بتوانیم با برچسبهایمان مقایسه کنیم، نیاز داریم اندیس مقدار بیشینه روی بعد دوم را برداریم:
+
+
+
+```py
+import numpy as np
+
+preds = np.argmax(predictions.predictions, axis=-1)
+```
+
+
+
+اکنون میتوانیم `preds` را با برچسبها مقایسه کنیم. برای ساختن تابع
`compute_metric()`، به متریکهای کتابخانه دادههای هاگینگفِیس تکیه خواهیم کرد. ما میتوانیم متریکهای وابسته به دیتاسِت MRPC را به راحتی خود دیتاسِت، اما این بار با استفاده از تابع
`load_metric()`، بارگذاری کنیم. شیء بازگردانده شده تابعی به نام
`compute()` دارد که میتوانیم برای محاسبه متریک از آن استفاده کنیم:
+
+
+
+```py
+from datasets import load_metric
+
+metric = load_metric("glue", "mrpc")
+metric.compute(predictions=preds, references=predictions.label_ids)
+```
+
+```python out
+{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
+```
+
+
+
+از آنجایی که مقداردهی تصادفی اولیه مدل میتواند متریکهای نهایی را تغییر دهد، نتایج دقیقی که شما بدست میآورید ممکن است متفاوت باشد. در اینجا میتوانیم ببینیم که مدل ما `accuracy` معادل ۸۵.۷۸٪ و `F1 Score` معادل ۸۹.۹۷٪ روی مجموعه `validation` بدست میآورد. آنها دو متریک برای ارزیابی نتایج محک GLUE روی دیتاسِت MRPC هستند. جدول نتایج در مقاله [BERT](https://arxiv.org/pdf/1810.04805.pdf)، برای مدل پایه، `F1 Score` معادل ۸۸.۹ را گزارش میکند. توجه داشته باشید که آن مدل `uncased` بود، حال آن که در اینجا ما از مدل `cased` استفاده میکنیم، که دستیابی به نتایج بهتر را توضیح میدهد.
+
+اکنون با قرار دادن همه چیز کنارهم تابع
`compute_metrics()` را بدست خواهیم آورد:
+
+
+
+```py
+def compute_metrics(eval_preds):
+ metric = load_metric("glue", "mrpc")
+ logits, labels = eval_preds
+ predictions = np.argmax(logits, axis=-1)
+ return metric.compute(predictions=predictions, references=labels)
+```
+
+
+
+و در اینجا نشان میدهیم که چگونه یک `Trainer` جدید با استفاده از تابع
`compute_metrics()` تعریف میکنیم، تا بتوانیم عملکرد آن را در حین گزارش متریکها در پایان هر epoch مشاهده کنیم:
+
+
+
+```py
+training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+
+trainer = Trainer(
+ model,
+ training_args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+ compute_metrics=compute_metrics,
+)
+```
+
+
+
+توجه داشته باشید که ما مدلی جدید و `TrainingArguments` جدیدی که `evaluation_strategy` آن `"epoch"` است میسازیم - در غیر این صورت فقط تعلیم مدلی که از پیش تعلیم دیده بود را ادامه میدادیم. برای راهاندازی دور جدید تعلیم، دستور زیر را اجرا میکنیم:
+
+
+
+```
+trainer.train()
+```
+
+
+
+این بار هزینه validation و متریکها را در پایان هر epoch و در بالای هزینه تعلیم گزارش میکنیم. دوباره، به خاطر مقدار دهی تصادفی اولیه لایه سر مدل، مقادیر دقیق
accuracy/F1 score که شما بدست میآورید ممکن است کمی متفاوت از آنچه ما بدست آوردهایم باشد، اما این مقادیر باید در محدوده تخمینی یکسانی باشند.
+
+به صورت پیش فرض، `Trainer` روی چندین GPU یا TPU کار خواهد کرد و گزینههای فراوانی، مثل تعلیم mixed-precision (از مقدار `fp16 = True` در آرگومانهای تعلیم استفاده کنید) فراهم میکند. در فصل ۱۰ همه حالتهایی که پشتیبانی میکند را مرور خواهیم کرد.
+
+این پایان مقدمهای بر کوک کردن با استفاده از `Trainer` API میباشد. در [فصل ۷](/course/chapter7) مثالی برای نشان دادن چگونگی انجام این کار برای معمولترین مسئلههای NLP ارائه خواهیم کرد، اما اکنون اجازه دهید ببینیم چگونه همین کار را صرفا با استفاده از PyTorch انجام دهیم.
+
+
+
+✏️ **اتحان کنید!** با استفاده از پردازش دادهای که در بخش ۲ انجام دادید، مدلی را روی دیتاسِت GLUE SST-2 کوک کنید.
+
+
+
+
\ No newline at end of file
diff --git a/chapters/fa/chapter3/3_tf.mdx b/chapters/fa/chapter3/3_tf.mdx
new file mode 100644
index 000000000..fb49d492f
--- /dev/null
+++ b/chapters/fa/chapter3/3_tf.mdx
@@ -0,0 +1,240 @@
+
+
+
+
+# کوک کردن مدلها با استفاده از کِراس
+
+
+
+زمانی که همه کارهای پیشپردازش در بخش قبل را انجام دادید، فقط چند مرحله باقیمانده تا تعلیم مدل دارید. با این حال، توجه داشته باشید که دستور
`model.fit()` روی CPU بسیار آهسته اجرا خواهد شد. اگر GPU ندارید، میتوانید از GPU یا TPU مجانی روی [گوگل کولَب](https://colab.research.google.com/) استفاده کنید.
+
+نمونه کدهای زیر فرض میکنند که شما مثالهای بخش قبل را از پیش اجرا کردهاید. این یک خلاصه کوتاه است جهت یادآوری آنچه نیاز دارید:
+
+
+
+```py
+from datasets import load_dataset
+from transformers import AutoTokenizer, DataCollatorWithPadding
+import numpy as np
+
+raw_datasets = load_dataset("glue", "mrpc")
+checkpoint = "bert-base-uncased"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+
+def tokenize_function(example):
+ return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
+
+
+tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
+
+data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
+
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "token_type_ids"],
+ label_cols=["labels"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+
+tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "token_type_ids"],
+ label_cols=["labels"],
+ shuffle=False,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+```
+
+
+
+
+### تعلیم
+
+مدلهای تِنسورفِلو که از ترَنسفورمِرهای هاگینگفِیس وارد شدهاند از پیش مدلهای کِراس هستند. این هم مقدمهای کوتاه به کِراس.
+
+
+
+این به این معنی است که به محض اینکه دادهمان را در اختیار بگیریم، کار بسیار کمی لازم است تا تعلیم را روی آن شروع کنیم.
+
+
+
+مانند [فصل قبل](/course/chapter2)، ما از کلاس `TFAutoModelForSequenceClassification` با دو برچسب دسته استفاده خواهیم کرد:
+
+
+
+```py
+from transformers import TFAutoModelForSequenceClassification
+
+model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+```
+
+
+
+شما متوجه خواهید شد که برخلاف [فصل ۲](/course/chapter2)، بعد از ساختن این مدل از پیش تعلیم دیده یک هشدار دریافت میکنید. این به این خاطر است که BERT برای دستهبندی دو جملهها از پیش تعلیم ندیده است، بنابراین لایه سَر مدل از پیش تعلیم دیده حذف شده و یک لایه سَر مناسب جهت دسته بندی رشتهها به جای آن قرار گرفته است. هشدارها نشان میدهند که برخی از وزنهای مدل استفاده نشدهاند (آنهایی که مربوط به لایه سَر حذف شده مدل از پیش تعلیم دیده هستند) و برخی دیگر به صورت تصادفی مقدار دهی شدهاند (آنهایی که مربوط به لایه سَر جدید هستند). در نتیجه این امر شما را تشویق به تعلیم مدل میکند، که دقیقا همان کاری است که میخواهیم اکنون انجام دهیم.
+
+برای کوک کردن مدل روی دِیتاسِتمان، ما فقط باید مدل را
`compile()` کنیم و سپس دادهمان را به تابع
`fit()` ارسال کنیم. این کار فرایند کوک کردن را شروع میکند (که باید چند دقیقه روی GPU طول بکشد) و در همین حین هزینه `training` و هزینه `validation` را در انتهای هر epoch گزارش میدهد.
+
+
+
+توجه داشته باشید که مدلهای ترَنسفورمِر هاگینگفِیس قابلیت ویژهای دارند که بسیاری از مدلهای کِراس ندارند - آنها میتوانند به صورت خودکار از یک تابع هزینه مناسب که به صورت داخلی محاسبه میکنند استفاده کنند. در صورتی که شما آرگومانی برای تابع هزینه در زمان `compile()` تعیین نکنید آنها از این تابع هزینه به صورت پیشفرض استفاده خواهند کرد. توجه داشته باشید که جهت استفاده از تابع هزینه داخلی شما نیاز خواهید داشت برچسب دستههای خودتان را به عنوان بخشی از ورودی، نه به صورت یک برچسب دسته مجزا که روش معمول استفاده از برچسب دستهها در مدلهای کِراس میباشد، ارسال کنید. شما مثالهایی از این را در بخش ۲ این درس خواهید دید، جایی که تعیین تابع هزینهی درست میتواند تا اندازهای پیچیده باشد. به هر حال، برای دستهبندی رشتهها، یک تابع هزینه استانداد کِراس به خوبی کار میکند، چیزی که ما در اینجا استفاده خواهیم کرد.
+
+
+
+
+
+```py
+from tensorflow.keras.losses import SparseCategoricalCrossentropy
+
+model.compile(
+ optimizer="adam",
+ loss=SparseCategoricalCrossentropy(from_logits=True),
+ metrics=["accuracy"],
+)
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_validation_dataset,
+)
+```
+
+
+
+
+
+در اینجا توجه شما را به یک مسئله عام جلب میکنیم - شما *میتوانید* فقط نام تابع هزینه را به صورت یک متغیر متنی برای کِراس ارسال کنید، اما کِراس به صورت پیشفرض فکر میکند شما یک لایه softmax از پیش به خروجیتان اعمال کردهاید. با این حال، بسیاری از مدلها مقادیر را درست قبل از اینکه softmax به آنها اعمال شود به خروجی میدهند، که همچنین به عنوان *logits* شناخته میشوند. ما نیاز داریم که به تابع هزینه بگوییم، این کاری است که مدلمان انجام میدهد و تنها راه گفتن آن این است که به جای ارسال نام تابع هزینه به صورت متغیر متنی، آن را به صورت مستقیم صدا بزنیم.
+
+
+
+### بهبود کارایی تعلیم
+
+
+
+اگر کد بالا را امتحان کنید، قطعا اجرا خواهد شد، اما متوجه خواهید شد که هزینه بسیار آهسته یا به صورت گاه و بیگاه کاهش مییابد. علت اصلی این امر *نرخ یادگیری* میباشد. مانند تابع هزینه، وقتی که ما نام بهینهساز را به صورت یک متغیر متنی به کِراس ارسال میکنیم، کِراس همه پارامترهای آن، شامل نرخ یادگیری، را با مقادیر پیشفرض مقداردهی اولیه میکند. به تجربه طولانی، ما میدانیم که مدلهای ترَنسفورمِر از نرخهای یادگیری بسیار کوچکتر بهره بیشتری میبرند تا مقدار پیشفرض برای بهینهساز Adam، که
۱e-۳ میباشد و به صورت ۱۰ به توان
-۳ یا ۰،۰۰۱ نیز نوشته میشود.
+
+علاوه بر کم کردن یکباره نرخ یادگیری، ترفند دیگری نیز در آستین داریم: ما میتوانیم نرخ یادگیری را به آهستگی در طول دوره تعلیم کاهش دهیم. گاها خواهید دید که از این روش در متون مشابه با عنوان نرخ یادگیری *محو شونده* یا *بازپُختی* یاد میشود. بهترین روش برای انجام این کار در کِراس استفاده از زمانبند نرخ یادگیری است. یک زمانبند خوب برای استفاده، زمانبند `PolynomialDecay` میباشد - این زمانبند برخلاف نامش نرخ یادگیری را در حالت پیشفرض به صورت خطی از مقدار اولیه تا مقدار نهایی در طول دوره تعلیم کاهش میدهد که دقیقا همان چیزی است که ما میخواهیم. به منظور استفاده درست از زمانبند ما نیاز داریم که به آن بگویم طول زمان تعلیم چقدر خواهد بود. در زیر ما آن را به عنوان `num_train_steps` محاسبه میکنیم.
+
+
+
+```py
+from tensorflow.keras.optimizers.schedules import PolynomialDecay
+
+batch_size = 8
+num_epochs = 3
+# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
+# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
+# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
+num_train_steps = len(tf_train_dataset) * num_epochs
+lr_scheduler = PolynomialDecay(
+ initial_learning_rate=5e-5, end_learning_rate=0.0, decay_steps=num_train_steps
+)
+from tensorflow.keras.optimizers import Adam
+
+opt = Adam(learning_rate=lr_scheduler)
+```
+
+
+
+
+
+کتابخانه ترنسفورمرهای هاگینگفِیس همچنین یک تابع `create_optimizer()` دارد که بهینهسازی از نوع `AdamW`، دارای میزان کاهش نرخ یادگیری میسازد. این یک میانبر مناسب است که آن را با جزئیات در بخشهای بعدی این آموزش خواهید دید.
+
+
+
+اکنون بهینهساز کاملا جدیدمان را در اختیار داریم و میتوانیم آن را تعلیم دهیم. ابتدا، اجازه دهید مدل را مجددا بارگذاری کنیم تا تغییرات ایجاد شده بر وزنها که در تعلیم قبلی اعمال شدهاند را به حالت اولیه بازگردانیم، سپس میتوانیم مدل را با بهینه ساز جدید تدوین کنیم:
+
+
+
+```py
+import tensorflow as tf
+
+model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
+model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])
+```
+
+
+
+حالا دوباره مدل را فیت میکنیم:
+
+
+
+```py
+model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
+```
+
+
+
+
+
+
+💡 اگر مایلید مدلتان را در حین تعلیم به صورت خودکار در هاب بارگذاری کنید، میتوانید پارامتر `PushToHubCallback` را در تابع `model.fit()` ارسال کنید. در [فصل ۴](/course/chapter4/3) در این مورد بیشتر خواهیم آموخت.
+
+
+
+### پیشبینیهای مدل
+
+
+
+تعلیم و تماشای پایین رفتن هزینه خیلی خوب است، اما اگر واقعا بخواهیم از مدل تعلیم دیدهمان، چه برای محاسبه برخی معیارها و چه برای استفاده در خط تولید، خروجی دریافت کنیم باید چه کار کنیم؟ برای این منظور میتوانیم از تابع
`predict()` استفاده کنیم. این کار به ازای هر کلاس یک *logits* از لایه سَر خروجی مدل باز میگرداند.
+
+
+
+
+```py
+preds = model.predict(tf_validation_dataset)["logits"]
+```
+
+
+
+سپس میتوانیم `logits` را با استفاده از `argmax` برای یافتن بزرگترین `logit`، که نماینده محتملترین دسته میباشد، به پیشبینیهای دسته مدل تبدیل کنیم:
+
+
+
+```py
+class_preds = np.argmax(preds, axis=1)
+print(preds.shape, class_preds.shape)
+```
+
+
+
+
+
+```python out
+(408, 2) (408,)
+```
+
+
+
+اکنون، اجازه دهید از `preds` برای محاسبه برخی معیارها استفاده کنیم! ما میتوانیم معیارهای مرتبط با دیتاسِت MRPC را، به همان آسانی که دیتاسِت را بارگذاری کردیم، بارگذاری کنیم اما این بار با استفاده از تابع
`load_metric()`. شیء باز گردانده شده تابعی به نام
`compute()` دارد که میتوانیم برای محاسبه معیارها از آن استفاده کنیم:
+
+
+
+```py
+from datasets import load_metric
+
+metric = load_metric("glue", "mrpc")
+metric.compute(predictions=class_preds, references=raw_datasets["validation"]["label"])
+```
+
+
+
+
+
+```python out
+{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
+```
+
+
+
+از آنجایی که مقداردهی اولیه تصادفی در لایه سَر مدل ممکن است مقادیر معیارهای حاصل را تغییر دهد، نتایج دریافتی شما میتوانند متفاوت باشند. در اینجا میبینیم که مدل ما دقتی معادل ۸۵.۷۸٪ و
F1 score معادل ۸۹.۹۷٪ روی مجموعه `validation` دارد. اینها دو معیاری هستند که جهت سنجش نتایج روی داده MRPC در محک GLUE به کار رفتهاند. جدول نتایج در مقاله [BERT](https://arxiv.org/pdf/1810.04805.pdf)،
F1 score برابر با ۸۸.۹ برای مدل پایه گزارش کرده است. توجه داشته باشید که آن مدل `uncased` بود در حالی که اکنون ما از مدل `cased` استفاده میکنیم، که نتایج بهتر را توجیح میکند.
+
+به این ترتیب مقدمه کوک کردن با استفاده از `API` کِراس به پایان میرسد. در فصل ۷ یک مثال از انجام این کار برای معمولترین مسئلههای `NLP` ارائه خواهد شد. اگر مایلید مهارتهای خود را روی `API` کِراس تقویت کنید، سعی کنید مدلی را روی مسئله
`GLUE SST-2`، با استفاده از روش پردازش داده که در بخش ۲ انجام دادید، کوک کنید.
+
+
+
\ No newline at end of file
diff --git a/chapters/fr/chapter0/1.mdx b/chapters/fr/chapter0/1.mdx
index 47bfa9809..e47bd6044 100644
--- a/chapters/fr/chapter0/1.mdx
+++ b/chapters/fr/chapter0/1.mdx
@@ -86,7 +86,7 @@ Vous pouvez entrer et sortir de votre environnement virtuel avec les scripts `ac
source .env/bin/activate
# Deactivate the virtual environment
-source .env/bin/deactivate
+deactivate
```
Vous pouvez vous assurer que l'environnement est activé en exécutant la commande `which python` : si elle pointe vers l'environnement virtuel, alors vous l'avez activé avec succès !
diff --git a/chapters/fr/chapter2/1.mdx b/chapters/fr/chapter2/1.mdx
index aa72cc82f..2fb2880e1 100644
--- a/chapters/fr/chapter2/1.mdx
+++ b/chapters/fr/chapter2/1.mdx
@@ -11,7 +11,7 @@ La bibliothèque 🤗 *Transformers* a été créée pour résoudre ce problème
- **La facilité d'utilisation** : en seulement deux lignes de code il est possible de télécharger, charger et utiliser un modèle de NLP à l'état de l'art pour faire de l'inférence,
- **La flexibilité** : au fond, tous les modèles sont de simples classes PyTorch `nn.Module` ou TensorFlow `tf.keras.Model` et peuvent être manipulés comme n'importe quel autre modèle dans leurs *frameworks* d'apprentissage automatique respectifs,
-- **La simplicité** : pratiquement aucune abstraction n'est faite dans la bibliothèque. Avoir tout dans un fichier est un concept central : la passe avant d'un modèle est entièrement définie dans un seul fichier afin que le code lui-même soit compréhensible et piratable.
+- **La simplicité** : pratiquement aucune abstraction n'est faite dans la bibliothèque. Avoir tout dans un fichier est un concept central : la passe avant d'un modèle est entièrement définie dans un seul fichier afin que le code lui-même soit compréhensible et modifiable.
Cette dernière caractéristique rend 🤗 *Transformers* très différent des autres bibliothèques d'apprentissage automatique.
Les modèles ne sont pas construits sur des modules partagés entre plusieurs fichiers. Au lieu de cela, chaque modèle possède ses propres couches.
diff --git a/chapters/fr/chapter2/2.mdx b/chapters/fr/chapter2/2.mdx
index 1336799d4..b05f8b154 100644
--- a/chapters/fr/chapter2/2.mdx
+++ b/chapters/fr/chapter2/2.mdx
@@ -180,7 +180,7 @@ Dans cet extrait de code, nous avons téléchargé le même *checkpoint* que nou
Cette architecture ne contient que le module de *transformer* de base : étant donné certaines entrées, il produit ce que nous appellerons des *états cachés*, également connus sous le nom de *caractéristiques*.
Pour chaque entrée du modèle, nous récupérons un vecteur en grande dimension représentant la **compréhension contextuelle de cette entrée par le *transformer***.
-Si cela ne fait pas sens, ne vous inquiétez pas. Nous expliquons tout plus tard.
+Si cela n'a pas de sens, ne vous inquiétez pas. Nous expliquons tout plus tard.
Bien que ces états cachés puissent être utiles en eux-mêmes, ils sont généralement les entrées d'une autre partie du modèle, connue sous le nom de *tête*. Dans le [chapitre 1](/course/fr/chapter1), les différentes tâches auraient pu être réalisées avec la même architecture mais en ayant chacune d'elles une tête différente.
diff --git a/chapters/fr/chapter3/2.mdx b/chapters/fr/chapter3/2.mdx
index 6e36b38df..f0f74bd1c 100644
--- a/chapters/fr/chapter3/2.mdx
+++ b/chapters/fr/chapter3/2.mdx
@@ -92,10 +92,14 @@ Dans cette section, nous allons utiliser comme exemple le jeu de données MRPC (
{/if}
-Le *Hub* ne contient pas seulement des modèles mais aussi plusieurs jeux de données dans un tas de langues différentes. Vous pouvez explorer les jeux de données [ici](https://huggingface.co/datasets) et nous vous conseillons d'essayer de charger un nouveau jeu de données une fois que vous avez étudié cette section (voir la documentation générale [ici](https://huggingface.co/docs/datasets/loading_datasets.html#from-the-huggingface-hub)). Mais pour l'instant, concentrons-nous sur le jeu de données MRPC ! Il s'agit de l'un des 10 jeux de données qui constituent le [*benchmark* GLUE](https://gluebenchmark.com/) qui est un *benchmark* académique utilisé pour mesurer les performances des modèles d'apprentissage automatique sur 10 différentes tâches de classification de textes.
+Le *Hub* ne contient pas seulement des modèles mais aussi plusieurs jeux de données dans un tas de langues différentes. Vous pouvez explorer les jeux de données [ici](https://huggingface.co/datasets) et nous vous conseillons d'essayer de charger un nouveau jeu de données une fois que vous avez étudié cette section (voir la documentation générale [ici](https://huggingface.co/docs/datasets/loading)). Mais pour l'instant, concentrons-nous sur le jeu de données MRPC ! Il s'agit de l'un des 10 jeux de données qui constituent le [*benchmark* GLUE](https://gluebenchmark.com/) qui est un *benchmark* académique utilisé pour mesurer les performances des modèles d'apprentissage automatique sur 10 différentes tâches de classification de textes.
La bibliothèque 🤗 *Datasets* propose une commande très simple pour télécharger et mettre en cache un jeu de données à partir du *Hub*. On peut télécharger le jeu de données MRPC comme ceci :
+
+⚠️ **Attention** Assurez-vous que `datasets` est installé en exécutant `pip install datasets`. Ensuite, chargez le jeu de données MRPC et imprimez-le pour voir ce qu'il contient.
+
+
```py
from datasets import load_dataset
@@ -246,7 +250,7 @@ tokenized_dataset = tokenizer(
Cela fonctionne bien, mais a l'inconvénient de retourner un dictionnaire (avec nos clés, `input_ids`, `attention_mask`, et `token_type_ids`, et des valeurs qui sont des listes de listes). Cela ne fonctionnera également que si vous avez assez de RAM pour stocker l'ensemble de votre jeu de données pendant la tokenisation (alors que les jeux de données de la bibliothèque 🤗 *Datasets* sont des fichiers [Apache Arrow](https://arrow.apache.org/) stockés sur le disque, vous ne gardez donc en mémoire que les échantillons que vous demandez).
-Pour conserver les données sous forme de jeu de données, nous utiliserons la méthode [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map). Cela nous permet également une certaine flexibilité, si nous avons besoin d'un prétraitement plus poussé que la simple tokenisation. La méthode `map()` fonctionne en appliquant une fonction sur chaque élément de l'ensemble de données, donc définissons une fonction qui tokenise nos entrées :
+Pour conserver les données sous forme de jeu de données, nous utiliserons la méthode [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map). Cela nous permet également une certaine flexibilité, si nous avons besoin d'un prétraitement plus poussé que la simple tokenisation. La méthode `map()` fonctionne en appliquant une fonction sur chaque élément de l'ensemble de données, donc définissons une fonction qui tokenise nos entrées :
```py
def tokenize_function(example):
diff --git a/chapters/fr/chapter5/2.mdx b/chapters/fr/chapter5/2.mdx
index 86a218a7c..58640da8b 100644
--- a/chapters/fr/chapter5/2.mdx
+++ b/chapters/fr/chapter5/2.mdx
@@ -132,7 +132,7 @@ C'est exactement ce que nous voulions. Désormais, nous pouvons appliquer divers
-L'argument `data_files` de la fonction `load_dataset()` est assez flexible et peut être soit un chemin de fichier unique, une liste de chemins de fichiers, ou un dictionnaire qui fait correspondre les noms des échantillons aux chemins de fichiers. Vous pouvez également regrouper les fichiers correspondant à un motif spécifié selon les règles utilisées par le shell Unix. Par exemple, vous pouvez regrouper tous les fichiers JSON d'un répertoire en une seule division en définissant `data_files="*.json"`. Voir la [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) de 🤗 *Datasets* pour plus de détails.
+L'argument `data_files` de la fonction `load_dataset()` est assez flexible et peut être soit un chemin de fichier unique, une liste de chemins de fichiers, ou un dictionnaire qui fait correspondre les noms des échantillons aux chemins de fichiers. Vous pouvez également regrouper les fichiers correspondant à un motif spécifié selon les règles utilisées par le shell Unix. Par exemple, vous pouvez regrouper tous les fichiers JSON d'un répertoire en une seule division en définissant `data_files="*.json"`. Voir la [documentation](https://huggingface.co/docs/datasets/loading#local-and-remote-files) de 🤗 *Datasets* pour plus de détails.
@@ -164,6 +164,6 @@ Cela renvoie le même objet `DatasetDict` obtenu ci-dessus mais nous évite de t
-✏️ **Essayez !** Choisissez un autre jeu de données hébergé sur GitHub ou dans le [*UCI Machine Learning Repository*](https://archive.ics.uci.edu/ml/index.php) et essayez de le charger localement et à distance en utilisant les techniques présentées ci-dessus. Pour obtenir des points bonus, essayez de charger un jeu de données stocké au format CSV ou texte (voir la [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) pour plus d'informations sur ces formats).
+✏️ **Essayez !** Choisissez un autre jeu de données hébergé sur GitHub ou dans le [*UCI Machine Learning Repository*](https://archive.ics.uci.edu/ml/index.php) et essayez de le charger localement et à distance en utilisant les techniques présentées ci-dessus. Pour obtenir des points bonus, essayez de charger un jeu de données stocké au format CSV ou texte (voir la [documentation](https://huggingface.co/docs/datasets/loading#local-and-remote-files) pour plus d'informations sur ces formats).
diff --git a/chapters/fr/chapter5/3.mdx b/chapters/fr/chapter5/3.mdx
index 271396fcb..1c38a5fff 100644
--- a/chapters/fr/chapter5/3.mdx
+++ b/chapters/fr/chapter5/3.mdx
@@ -249,7 +249,7 @@ Comme vous pouvez le constater, cela a supprimé environ 15 % des avis de nos je
-✏️ **Essayez !** Utilisez la fonction `Dataset.sort()` pour inspecter les avis avec le plus grand nombre de mots. Consultez la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.sort) pour voir quel argument vous devez utiliser pour trier les avis par longueur dans l'ordre décroissant.
+✏️ **Essayez !** Utilisez la fonction `Dataset.sort()` pour inspecter les avis avec le plus grand nombre de mots. Consultez la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.sort) pour voir quel argument vous devez utiliser pour trier les avis par longueur dans l'ordre décroissant.
@@ -396,7 +396,7 @@ tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
```
-Oh non ! Cela n'a pas fonctionné ! Pourquoi ? L'examen du message d'erreur nous donne un indice : il y a une incompatibilité dans les longueurs de l'une des colonnes. L'une étant de longueur 1 463 et l'autre de longueur 1 000. Si vous avez consulté la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) de `Dataset.map()`, vous vous souvenez peut-être qu'il s'agit du nombre d'échantillons passés à la fonction que nous mappons. Ici, ces 1 000 exemples ont donné 1 463 nouvelles caractéristiques, entraînant une erreur de forme.
+Oh non ! Cela n'a pas fonctionné ! Pourquoi ? L'examen du message d'erreur nous donne un indice : il y a une incompatibilité dans les longueurs de l'une des colonnes. L'une étant de longueur 1 463 et l'autre de longueur 1 000. Si vous avez consulté la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) de `Dataset.map()`, vous vous souvenez peut-être qu'il s'agit du nombre d'échantillons passés à la fonction que nous mappons. Ici, ces 1 000 exemples ont donné 1 463 nouvelles caractéristiques, entraînant une erreur de forme.
Le problème est que nous essayons de mélanger deux jeux de données différents de tailles différentes : les colonnes `drug_dataset` auront un certain nombre d'exemples (les 1 000 dans notre erreur), mais le `tokenized_dataset` que nous construisons en aura plus (le 1 463 dans le message d'erreur). Cela ne fonctionne pas pour un `Dataset`, nous devons donc soit supprimer les colonnes de l'ancien jeu de données, soit leur donner la même taille que dans le nouveau jeu de données. Nous pouvons faire la première option avec l'argument `remove_columns` :
diff --git a/chapters/fr/chapter5/4.mdx b/chapters/fr/chapter5/4.mdx
index 1fdc67418..2d3d62ba6 100644
--- a/chapters/fr/chapter5/4.mdx
+++ b/chapters/fr/chapter5/4.mdx
@@ -48,7 +48,7 @@ Nous pouvons voir qu'il y a 15 518 009 lignes et 2 colonnes dans notre jeu de do
-✎ Par défaut, 🤗 *Datasets* décompresse les fichiers nécessaires pour charger un jeu de données. Si vous souhaitez conserver de l'espace sur le disque dur, vous pouvez passer `DownloadConfig(delete_extracted=True)` à l'argument `download_config` de `load_dataset()`. Voir la [documentation](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig) pour plus de détails.
+✎ Par défaut, 🤗 *Datasets* décompresse les fichiers nécessaires pour charger un jeu de données. Si vous souhaitez conserver de l'espace sur le disque dur, vous pouvez passer `DownloadConfig(delete_extracted=True)` à l'argument `download_config` de `load_dataset()`. Voir la [documentation](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig) pour plus de détails.
diff --git a/chapters/fr/chapter5/5.mdx b/chapters/fr/chapter5/5.mdx
index af48c82b3..63a14bf36 100644
--- a/chapters/fr/chapter5/5.mdx
+++ b/chapters/fr/chapter5/5.mdx
@@ -431,7 +431,7 @@ Cool, nous avons poussé notre jeu de données vers le *Hub* et il est disponibl
-💡 Vous pouvez également télécharger un jeu de données sur le *Hub* directement depuis le terminal en utilisant `huggingface-cli` et un peu de magie Git. Consultez le [guide de 🤗 *Datasets*](https://huggingface.co/docs/datasets/share.html#add-a-community-dataset) pour savoir comment procéder.
+💡 Vous pouvez également télécharger un jeu de données sur le *Hub* directement depuis le terminal en utilisant `huggingface-cli` et un peu de magie Git. Consultez le [guide de 🤗 *Datasets*](https://huggingface.co/docs/datasets/share#share-a-dataset-using-the-cli) pour savoir comment procéder.
diff --git a/chapters/fr/chapter5/6.mdx b/chapters/fr/chapter5/6.mdx
index 610af1078..19d2e1f5d 100644
--- a/chapters/fr/chapter5/6.mdx
+++ b/chapters/fr/chapter5/6.mdx
@@ -193,7 +193,7 @@ D'accord, cela nous a donné quelques milliers de commentaires avec lesquels tra
-✏️ **Essayez !** Voyez si vous pouvez utiliser `Dataset.map()` pour exploser la colonne `comments` de `issues_dataset` _sans_ recourir à l'utilisation de Pandas. C'est un peu délicat. La section [« Batch mapping »](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) de la documentation 🤗 *Datasets* peut être utile pour cette tâche.
+✏️ **Essayez !** Voyez si vous pouvez utiliser `Dataset.map()` pour exploser la colonne `comments` de `issues_dataset` _sans_ recourir à l'utilisation de Pandas. C'est un peu délicat. La section [« Batch mapping »](https://huggingface.co/docs/datasets/about_map_batch#batch-mapping) de la documentation 🤗 *Datasets* peut être utile pour cette tâche.
diff --git a/chapters/fr/chapter6/10.mdx b/chapters/fr/chapter6/10.mdx
index 4846966e4..66a5c11db 100644
--- a/chapters/fr/chapter6/10.mdx
+++ b/chapters/fr/chapter6/10.mdx
@@ -228,7 +228,7 @@ Testons ce que vous avez appris dans ce chapitre !
explain: "C'est la façon de faire d'un autre algorithme de tokenization."
},
{
- text: "WordPiece Les
tokenizer apprennent les règles de fusion en fusionnant la paire de
tokens la plus fréquente.",
+ text: "Les
tokenizer WordPiece apprennent les règles de fusion en fusionnant la paire de
tokens la plus fréquente.",
explain: "C'est la façon de faire d'un autre algorithme de tokenization."
},
{
diff --git a/chapters/fr/chapter6/3b.mdx b/chapters/fr/chapter6/3b.mdx
index 6e670483f..f523851ed 100644
--- a/chapters/fr/chapter6/3b.mdx
+++ b/chapters/fr/chapter6/3b.mdx
@@ -25,7 +25,7 @@
{/if}
-Nous allons maintenant nous plonger dans le pipeline de `question-answering` et voir comment exploiter les *offsets* pour extraire d'u ncontexte la réponse à la question posée. Nous verrons ensuite comment gérer les contextes très longs qui finissent par être tronqués. Vous pouvez sauter cette section si vous n'êtes pas intéressé par la tâche de réponse aux questions.
+Nous allons maintenant nous plonger dans le pipeline de `question-answering` et voir comment exploiter les *offsets* pour extraire d'un contexte la réponse à la question posée. Nous verrons ensuite comment gérer les contextes très longs qui finissent par être tronqués. Vous pouvez sauter cette section si vous n'êtes pas intéressé par la tâche de réponse aux questions.
{#if fw === 'pt'}
@@ -274,11 +274,11 @@ end_probabilities = tf.math.softmax(end_logits, axis=-1)[0].numpy()
A ce stade, nous pourrions prendre l'argmax des probabilités de début et de fin mais nous pourrions nous retrouver avec un indice de début supérieur à l'indice de fin. Nous devons donc prendre quelques précautions supplémentaires. Nous allons calculer les probabilités de chaque `start_index` et `end_index` possible où `start_index<=end_index`, puis nous prendrons le *tuple* `(start_index, end_index)` avec la plus grande probabilité.
-En supposant que les événements « La réponse commence à `start_index` » et « La réponse se termine à `end_index` » sont indépendants, la probabilité que la réponse commence à `end_index` et se termine à `end_index` est :
+En supposant que les événements « La réponse commence à `start_index` » et « La réponse se termine à `end_index` » sont indépendants, la probabilité que la réponse commence à `start_index` et se termine à `end_index` est :
$$\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]$$
-Ainsi, pour calculer tous les scores, il suffit de calculer tous les produits \\(\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]\\) où `start_index <= end_index`.
+Ainsi, pour calculer tous les scores, il suffit de calculer tous les produits $$\\(\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]\\)$$ où `start_index <= end_index`.
Calculons d'abord tous les produits possibles :
diff --git a/chapters/fr/chapter6/5.mdx b/chapters/fr/chapter6/5.mdx
index 083a8fd8a..5c9108ba3 100644
--- a/chapters/fr/chapter6/5.mdx
+++ b/chapters/fr/chapter6/5.mdx
@@ -103,7 +103,7 @@ Le mot « bug » sera traduit par « ["b", "ug"] ». Par contre, le mot « mug
-✏️ **A votre tour !** Comment pensez-vous que le mot « unhug » (détacher en français) sera tokenized ?
+✏️ **A votre tour !** Comment pensez-vous que le mot « unhug » (détacher en français) sera tokenisé ?
diff --git a/chapters/fr/chapter6/7.mdx b/chapters/fr/chapter6/7.mdx
index 2240cc023..ab970d817 100644
--- a/chapters/fr/chapter6/7.mdx
+++ b/chapters/fr/chapter6/7.mdx
@@ -25,7 +25,7 @@ Comparé au BPE et *WordPiece*, *Unigram* fonctionne dans l'autre sens : il part
À chaque étape de l'entraînement, l'algorithme *Unigram* calcule une perte sur le corpus compte tenu du vocabulaire actuel. Ensuite, pour chaque symbole du vocabulaire, l'algorithme calcule de combien la perte globale augmenterait si le symbole était supprimé et recherche les symboles qui l'augmenteraient le moins. Ces symboles ont un effet moindre sur la perte globale du corpus, ils sont donc en quelque sorte « moins nécessaires » et sont les meilleurs candidats à la suppression.
-Comme il s'agit d'une opération très coûteuse, nous ne nous contentons pas de supprimer le symbole unique associé à la plus faible augmentation de la perte mais le \\(p\\) pourcent des symboles associés à la plus faible augmentation de la perte. \(p\\) est un hyperparamètre que vous pouvez contrôler, valant généralement 10 ou 20. Ce processus est ensuite répété jusqu'à ce que le vocabulaire ait atteint la taille souhaitée.
+Comme il s'agit d'une opération très coûteuse, nous ne nous contentons pas de supprimer le symbole unique associé à la plus faible augmentation de la perte mais le \\(p\\) pourcent des symboles associés à la plus faible augmentation de la perte. \\(p\\) est un hyperparamètre que vous pouvez contrôler, valant généralement 10 ou 20. Ce processus est ensuite répété jusqu'à ce que le vocabulaire ait atteint la taille souhaitée.
Notez que nous ne supprimons jamais les caractères de base, afin de nous assurer que tout mot peut être tokenisé.
diff --git a/chapters/fr/chapter6/8.mdx b/chapters/fr/chapter6/8.mdx
index f8a740502..5bed366b9 100644
--- a/chapters/fr/chapter6/8.mdx
+++ b/chapters/fr/chapter6/8.mdx
@@ -30,14 +30,14 @@ La bibliothèque 🤗 *Tokenizers* a été construite pour fournir plusieurs opt
Plus précisément, la bibliothèque est construite autour d'une classe centrale `Tokenizer` avec les blocs de construction regroupés en sous-modules :
-- `normalizers` contient tous les types de `Normalizer` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.normalizers)),
-- `pre_tokenizers` contient tous les types de `PreTokenizer` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.pre_tokenizers)),
-- `models` contient les différents types de `Model` que vous pouvez utiliser, comme `BPE`, `WordPiece`, et `Unigram` (liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.models)),
-- `trainers` contient tous les différents types de `Trainer` que vous pouvez utiliser pour entraîner votre modèle sur un corpus (un par type de modèle ; liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.trainers)),
-- `post_processors` contient les différents types de `PostProcessor` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.processors)),
-- `decoders` contient les différents types de `Decoder` que vous pouvez utiliser pour décoder les sorties de tokenization (liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/components.html#decoders)).
-
-Vous pouvez trouver la liste complète des blocs de construction [ici](https://huggingface.co/docs/tokenizers/python/latest/components.html).
+- `normalizers` contient tous les types de `Normalizer` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/api/normalizers)),
+- `pre_tokenizers` contient tous les types de `PreTokenizer` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/api/pre-tokenizers)),
+- `models` contient les différents types de `Model` que vous pouvez utiliser, comme `BPE`, `WordPiece`, et `Unigram` (liste complète [ici](https://huggingface.co/docs/tokenizers/api/models)),
+- `trainers` contient tous les différents types de `Trainer` que vous pouvez utiliser pour entraîner votre modèle sur un corpus (un par type de modèle ; liste complète [ici](https://huggingface.co/docs/tokenizers/api/trainers)),
+- `post_processors` contient les différents types de `PostProcessor` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/api/post-processors)),
+- `decoders` contient les différents types de `Decoder` que vous pouvez utiliser pour décoder les sorties de tokenization (liste complète [ici](https://huggingface.co/docs/tokenizers/components#decoders)).
+
+Vous pouvez trouver la liste complète des blocs de construction [ici](https://huggingface.co/docs/tokenizers/components).
## Acquisition d'un corpus
diff --git a/chapters/fr/chapter7/4.mdx b/chapters/fr/chapter7/4.mdx
index 6f62da3f5..d778c8479 100644
--- a/chapters/fr/chapter7/4.mdx
+++ b/chapters/fr/chapter7/4.mdx
@@ -119,7 +119,7 @@ split_datasets["train"][1]["translation"]
```
Nous obtenons un dictionnaire contenant deux phrases dans la paire de langues qui nous intéresse.
-Une particularité de ce jeu de données rempli de termes techniques informatiques est qu'ils sont tous entièrement traduits en français. Cependant, les ingénieurs français sont souvent paresseux et laissent la plupart des mots spécifiques à l'informatique en anglais lorsqu'ils parlent. Ici, par exemple, le mot « *threads* » pourrait très bien apparaître dans une phrase française, surtout dans une conversation technique. Mais dans ce jeu de données, il a été traduit en « fils de discussion ». Le modèle pré-entraîné que nous utilisons (qui a été pré-entraîné sur un plus grand corpus de phrases françaises et anglaises) prend l'option de laisser le mot tel quel :
+Une particularité de ce jeu de données rempli de termes techniques informatiques est qu'ils sont tous entièrement traduits en français. Cependant, les ingénieurs français laissent la plupart des mots spécifiques à l'informatique en anglais lorsqu'ils parlent. Ici, par exemple, le mot « *threads* » pourrait très bien apparaître dans une phrase française, surtout dans une conversation technique. Mais dans ce jeu de données, il a été traduit en « fils de discussion ». Le modèle pré-entraîné que nous utilisons (qui a été pré-entraîné sur un plus grand corpus de phrases françaises et anglaises) prend l'option de laisser le mot tel quel :
```py
from transformers import pipeline
diff --git a/chapters/gj/chapter0/1.mdx b/chapters/gj/chapter0/1.mdx
index de32bfdb2..c62b588e1 100644
--- a/chapters/gj/chapter0/1.mdx
+++ b/chapters/gj/chapter0/1.mdx
@@ -86,7 +86,7 @@ ls -a
source .env/bin/activate
# Deactivate the virtual environment
-source .env/bin/deactivate
+deactivate
```
જો તમે verify કરવા માંગતા હોવ તો `which python` command run કરો. એ તમરા virtual environment ના ફોલ્ડર ને આઉટપુટ માં આપશે. આ એવું સાબિત કરે છે કે virtual environment સફળાપૂર્વક active છે.!
diff --git a/chapters/he/chapter0/1.mdx b/chapters/he/chapter0/1.mdx
index 9d9861223..ffc29378e 100644
--- a/chapters/he/chapter0/1.mdx
+++ b/chapters/he/chapter0/1.mdx
@@ -108,7 +108,7 @@ ls -a
source .env/bin/activate
# Deactivate the virtual environment
-source .env/bin/deactivate
+deactivate
```
diff --git a/chapters/hi/chapter0/1.mdx b/chapters/hi/chapter0/1.mdx
index 6a9490ee0..9af4ab08d 100644
--- a/chapters/hi/chapter0/1.mdx
+++ b/chapters/hi/chapter0/1.mdx
@@ -86,7 +86,7 @@ ls -a
source .env/bin/activate
# Deactivate the virtual environment
-source .env/bin/deactivate
+deactivate
```
आप यह सुनिश्चित कर सकते हैं कि `which python` आदेश चलाकर कौन सा पर्यावरण सक्रिय है: यदि यह आभासी वातावरण की ओर इशारा करता है, तो आपने इसे सफलतापूर्वक सक्रिय कर दिया है!
diff --git a/chapters/hi/chapter3/2.mdx b/chapters/hi/chapter3/2.mdx
index eb45b962d..501c3dc5e 100644
--- a/chapters/hi/chapter3/2.mdx
+++ b/chapters/hi/chapter3/2.mdx
@@ -84,10 +84,14 @@ model.train_on_batch(batch, labels)
{/if}
-हब में केवल मॉडल ही नहीं हैं; इसमें कई अलग-अलग भाषाओं में कई डेटासेट भी हैं। आप [यहां](https://huggingface.co/datasets) डेटासेट ब्राउज़ कर सकते हैं, और हम अनुशंसा करते हैं कि आप इस अनुभाग को पढ़ने के बाद एक नए डेटासेट को लोड और संसाधित करने का प्रयास करें ([यहां](https://huggingface.co/docs/datasets/loading_datasets.html#from-the-huggingface-hub) सामान्य दस्तावेज देखें)। लेकिन अभी के लिए, आइए MRPC डेटासेट पर ध्यान दें! यह [GLUE बेंचमार्क](https://gluebenchmark.com/) की रचना करने वाले 10 डेटासेट में से एक है, जो एक अकादमिक बेंचमार्क है जिसका उपयोग 10 अलग-अलग पाठ वर्गीकरण कार्यों में ML मॉडल के प्रदर्शन को मापने के लिए किया जाता है।
+हब में केवल मॉडल ही नहीं हैं; इसमें कई अलग-अलग भाषाओं में कई डेटासेट भी हैं। आप [यहां](https://huggingface.co/datasets) डेटासेट ब्राउज़ कर सकते हैं, और हम अनुशंसा करते हैं कि आप इस अनुभाग को पढ़ने के बाद एक नए डेटासेट को लोड और संसाधित करने का प्रयास करें ([यहां](https://huggingface.co/docs/datasets/loading) सामान्य दस्तावेज देखें)। लेकिन अभी के लिए, आइए MRPC डेटासेट पर ध्यान दें! यह [GLUE बेंचमार्क](https://gluebenchmark.com/) की रचना करने वाले 10 डेटासेट में से एक है, जो एक अकादमिक बेंचमार्क है जिसका उपयोग 10 अलग-अलग पाठ वर्गीकरण कार्यों में ML मॉडल के प्रदर्शन को मापने के लिए किया जाता है।
🤗 डेटासेट लाइब्रेरी एक बहुत ही सरल कमांड प्रदान करती है हब पर डेटासेट को डाउनलोड और कैश करने के लिए। हम MRPC डेटासेट को इस तरह डाउनलोड कर सकते हैं:
+
+
```py
from datasets import load_dataset
@@ -235,7 +239,7 @@ tokenized_dataset = tokenizer(
यह अच्छी तरह से काम करता है, लेकिन इसमें एक शब्दकोश (साथ में हमारी कुंजी, `input_ids`, `attention_mask`, और `token_type_ids`, और मान जो सूचियों की सूचियां हैं) के लौटने का नुकसान है। यह केवल तभी काम करेगा जब आपके पास पर्याप्त RAM हो अपने पूरे डेटासेट को टोकननाइजेशन के दौरान स्टोर करने के लिए (जबकि 🤗 डेटासेट लाइब्रेरी के डेटासेट [अपाचे एरो](https://arrow.apache.org/) फाइलें हैं जो डिस्क पर संग्रहीत है, तो आप केवल उन सैम्पल्स को रखते हैं जिन्हें आप मेमोरी मे लोड करना चाहतें है)।
-डेटा को डेटासेट के रूप में रखने के लिए, हम [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) पद्धति का उपयोग करेंगे। अगर हमें सिर्फ टोकननाइजेशन की तुलना में अधिक पूर्व प्रसंस्करण की आवश्यकता होती है, तो यह हमें कुछ अधिक लचीलेपन की भी अनुमति देता है। `map()` विधि डेटासेट के प्रत्येक तत्व पर एक फ़ंक्शन लागू करके काम करती है, तो चलिए एक फ़ंक्शन को परिभाषित करते हैं जो हमारे इनपुट को टोकननाइज़ करेगा :
+डेटा को डेटासेट के रूप में रखने के लिए, हम [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) पद्धति का उपयोग करेंगे। अगर हमें सिर्फ टोकननाइजेशन की तुलना में अधिक पूर्व प्रसंस्करण की आवश्यकता होती है, तो यह हमें कुछ अधिक लचीलेपन की भी अनुमति देता है। `map()` विधि डेटासेट के प्रत्येक तत्व पर एक फ़ंक्शन लागू करके काम करती है, तो चलिए एक फ़ंक्शन को परिभाषित करते हैं जो हमारे इनपुट को टोकननाइज़ करेगा :
```py
def tokenize_function(example):
diff --git a/chapters/id/chapter0/1.mdx b/chapters/id/chapter0/1.mdx
index 0f49326d9..b8efdcaa9 100644
--- a/chapters/id/chapter0/1.mdx
+++ b/chapters/id/chapter0/1.mdx
@@ -86,7 +86,7 @@ Instruksi dibawah adalah instruksi untuk mengaktifkan dan menonaktifkan _virtual
source .env/bin/activate
# Menonaktifkan virtual environment
-source .env/bin/deactivate
+deactivate
```
Anda bisa memastikan bahwa anda menggunakan Python versi _virtual environment_ dengan mengeksekusi `which python` di terminal: jika balasan terminal adalah Python di dalam folder *.env*, maka _virtual environment_ anda sudah aktif!
diff --git a/chapters/it/chapter0/1.mdx b/chapters/it/chapter0/1.mdx
index 844edc4f1..ac48cd479 100644
--- a/chapters/it/chapter0/1.mdx
+++ b/chapters/it/chapter0/1.mdx
@@ -86,7 +86,7 @@ Puoi entrare e uscire dall'ambiente virtuale utilizzando gli script `activate` e
source .env/bin/activate
# Deactivate the virtual environment
-source .env/bin/deactivate
+deactivate
```
Assicurati che l'ambiente sia configurato correttamente eseguendo il comando `which python`: se come risposta ottieni l'ambiente virtuale, significa che l'hai attivato bene!
diff --git a/chapters/it/chapter3/2.mdx b/chapters/it/chapter3/2.mdx
index 9de949110..c83c1601a 100644
--- a/chapters/it/chapter3/2.mdx
+++ b/chapters/it/chapter3/2.mdx
@@ -84,10 +84,14 @@ In questa sezione verrà usato come esempio il dataset MRPC (Microsoft Research
{/if}
-L'Hub non contiene solo modelli; contiene anche molti dataset in tante lingue diverse. I dataset possono essere esplorati [qui](https://huggingface.co/datasets), ed è consigliato tentare di caricare e processare un nuovo dataset dopo aver completato questa sezione (cfr. la [documentazione](https://huggingface.co/docs/datasets/loading_datasets.html#from-the-huggingface-hub)). Per ora, focalizziamoci sul dataset MRPC! Questo è uno dei 10 dataset che fanno parte del [GLUE benchmark](https://gluebenchmark.com/), che è un benchmark accademico usato per misurare la performance di modelli ML su 10 compiti di classificazione del testo.
+L'Hub non contiene solo modelli; contiene anche molti dataset in tante lingue diverse. I dataset possono essere esplorati [qui](https://huggingface.co/datasets), ed è consigliato tentare di caricare e processare un nuovo dataset dopo aver completato questa sezione (cfr. la [documentazione](https://huggingface.co/docs/datasets/loading). Per ora, focalizziamoci sul dataset MRPC! Questo è uno dei 10 dataset che fanno parte del [GLUE benchmark](https://gluebenchmark.com/), che è un benchmark accademico usato per misurare la performance di modelli ML su 10 compiti di classificazione del testo.
La libreria 🤗 Datasets fornisce un comando molto semplice per scaricare e mettere nella cache un dataset sull'Hub. Il dataset MRPC può essere scaricato così:
+
+
```py
from datasets import load_dataset
@@ -236,7 +240,7 @@ tokenized_dataset = tokenizer(
Questo metodo funziona, ma ha lo svantaggio di restituire un dizionario (avente `input_ids`, `attention_mask`, e `token_type_ids` come chiavi, e delle liste di liste come valori). Oltretutto, questo metodo funziona solo se si ha a disposizione RAM sufficiente per contenere l'intero dataset durante la tokenizzazione (mentre i dataset dalla libreria 🤗 Datasets sono file [Apache Arrow](https://arrow.apache.org/) archiviati su disco, perciò in memoria vengono caricati solo i campioni richiesti).
-Per tenere i dati come dataset, utilizzare il metodo [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map). Ciò permette anche della flessibilità extra, qualora fosse necessario del preprocessing aggiuntivo oltre alla tokenizzazione. Il metodo `map()` applica una funziona ad ogni elemento del dataset, perciò bisogna definire una funzione che tokenizzi gli input:
+Per tenere i dati come dataset, utilizzare il metodo [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map). Ciò permette anche della flessibilità extra, qualora fosse necessario del preprocessing aggiuntivo oltre alla tokenizzazione. Il metodo `map()` applica una funziona ad ogni elemento del dataset, perciò bisogna definire una funzione che tokenizzi gli input:
```py
def tokenize_function(example):
diff --git a/chapters/it/chapter5/2.mdx b/chapters/it/chapter5/2.mdx
index 738710236..c3ead7ad6 100644
--- a/chapters/it/chapter5/2.mdx
+++ b/chapters/it/chapter5/2.mdx
@@ -128,7 +128,7 @@ Questo è proprio ciò che volevamo. Ora possiamo applicare diverse tecniche di
@@ -160,7 +160,7 @@ Questo codice restituisce lo stesso oggetto `DatasetDict` visto in precedenza, m
diff --git a/chapters/it/chapter5/3.mdx b/chapters/it/chapter5/3.mdx
index 6b8bc7f8f..3eafa185e 100644
--- a/chapters/it/chapter5/3.mdx
+++ b/chapters/it/chapter5/3.mdx
@@ -241,7 +241,7 @@ Come puoi vedere, questo ha rimosso circa il 15% delle recensioni nelle sezioni
@@ -386,7 +386,7 @@ tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
```
-Oh no! Non ha funzionato! Perché? Il messaggio di errore ci dà un indizio: c'è una discordanza tra la lungheza di una delle colonne (una è lunga 1.463 e l'altra 1.000). Se hai guardato la [documentazione](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) di `Dataset.map()`, ricorderai che quello è il numero di campioni passati alla funzione map; qui quei 1.000 esempi danno 1.463 nuove feature, che risulta in un errore di shape.
+Oh no! Non ha funzionato! Perché? Il messaggio di errore ci dà un indizio: c'è una discordanza tra la lungheza di una delle colonne (una è lunga 1.463 e l'altra 1.000). Se hai guardato la [documentazione](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) di `Dataset.map()`, ricorderai che quello è il numero di campioni passati alla funzione map; qui quei 1.000 esempi danno 1.463 nuove feature, che risulta in un errore di shape.
Il problema è che stiamo cercando di mescolare due dataset diversi di grandezze diverse: le colonne del `drug_dataset` avranno un certo numero di esempi (il 1.000 del nostro errore), ma il `tokenized_dataset` che stiamo costruendo ne avrà di più (il 1.463 nel nostro messaggio di errore). Non va bene per un `Dataset`, per cui abbiamo bisogno o di rimuovere le colonne dal dataset vecchio, o renderle della stessa dimensione del nuovo dataset. La prima opzione può essere effettuata utilizzando l'argomento `remove_columns`:
diff --git a/chapters/it/chapter5/4.mdx b/chapters/it/chapter5/4.mdx
index 57f15060c..ad2f6e191 100644
--- a/chapters/it/chapter5/4.mdx
+++ b/chapters/it/chapter5/4.mdx
@@ -47,7 +47,7 @@ Possiamo vedere che ci sono 15.518.009 righe e 2 colonne nel nostro dataset -- u
diff --git a/chapters/it/chapter5/5.mdx b/chapters/it/chapter5/5.mdx
index 3a9c0f19f..a9246a463 100644
--- a/chapters/it/chapter5/5.mdx
+++ b/chapters/it/chapter5/5.mdx
@@ -430,7 +430,7 @@ Bene, abbiamo caricato il nostro dataset sull'Hub, e può essere utilizzato da t
diff --git a/chapters/it/chapter5/6.mdx b/chapters/it/chapter5/6.mdx
index b1296144f..1bd0dca34 100644
--- a/chapters/it/chapter5/6.mdx
+++ b/chapters/it/chapter5/6.mdx
@@ -190,7 +190,7 @@ Perfetto, ora abbiamo qualche migliaio di commenti con cui lavorare!
diff --git a/chapters/ja/chapter0/1.mdx b/chapters/ja/chapter0/1.mdx
index fea5d0d10..83b678d0b 100644
--- a/chapters/ja/chapter0/1.mdx
+++ b/chapters/ja/chapter0/1.mdx
@@ -86,7 +86,7 @@ ls -a
source .env/bin/activate
# Deactivate the virtual environment
-source .env/bin/deactivate
+deactivate
```
仮想環境が有効になっているかどうかは、`which python`というコマンドを実行することで確認することができます。もし以下のように仮想環境であることを示していれば、正常に有効化できています!
diff --git a/chapters/ko/chapter0/1.mdx b/chapters/ko/chapter0/1.mdx
index 0a8dd7735..90aa72de2 100644
--- a/chapters/ko/chapter0/1.mdx
+++ b/chapters/ko/chapter0/1.mdx
@@ -86,7 +86,7 @@ ls -a
source .env/bin/activate
# Deactivate the virtual environment
-source .env/bin/deactivate
+deactivate
```
환경이 제대로 활성화 되었는지 `which python` 명령어를 실행하여 확인해 봅시다. 아래와 같이 가상 환경을 보여준다면 제대로 활성화가 것입니다!
diff --git a/chapters/ko/chapter1/9.mdx b/chapters/ko/chapter1/9.mdx
index 9fee845cc..1eff01f0d 100644
--- a/chapters/ko/chapter1/9.mdx
+++ b/chapters/ko/chapter1/9.mdx
@@ -13,4 +13,4 @@
| --- | --- | --- |
| 인코더 | ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa | 문장 분류, 개체명 인식, 추출 질의 응답 |
| 디코더 | CTRL, GPT, GPT-2, Transformer XL | 텍스트 생성 |
-| 인코더-디코더 | BART, T5, Marian, mBART | 오약, 번역, 생성 질의 응답 |
\ No newline at end of file
+| 인코더-디코더 | BART, T5, Marian, mBART | 요약, 번역, 생성 질의 응답 |
diff --git a/chapters/ko/chapter2/2.mdx b/chapters/ko/chapter2/2.mdx
index 3f246f672..7468ea435 100644
--- a/chapters/ko/chapter2/2.mdx
+++ b/chapters/ko/chapter2/2.mdx
@@ -60,7 +60,7 @@ classifier(
 -La [arquitectura de los Transformadores](https://arxiv.org/abs/1706.03762) fue presentada por primera vez en junio de 2017. El trabajo original se enfocaba en tareas de traducción. A esto le siguó la introducción de numerosos modelos influyentes, que incluyen:
+La [arquitectura de los Transformadores](https://arxiv.org/abs/1706.03762) fue presentada por primera vez en junio de 2017. El trabajo original se enfocaba en tareas de traducción. A esto le siguió la introducción de numerosos modelos influyentes, que incluyen:
- **Junio de 2018**: [GPT](https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf), el primer modelo de Transformadores preentrenados, que fue usado para ajustar varias tareas de PLN y obtuvo resultados de vanguardia
@@ -50,7 +50,7 @@ Un ejemplo de una tarea es predecir la palabra siguiente en una oración con bas
-La [arquitectura de los Transformadores](https://arxiv.org/abs/1706.03762) fue presentada por primera vez en junio de 2017. El trabajo original se enfocaba en tareas de traducción. A esto le siguó la introducción de numerosos modelos influyentes, que incluyen:
+La [arquitectura de los Transformadores](https://arxiv.org/abs/1706.03762) fue presentada por primera vez en junio de 2017. El trabajo original se enfocaba en tareas de traducción. A esto le siguió la introducción de numerosos modelos influyentes, que incluyen:
- **Junio de 2018**: [GPT](https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf), el primer modelo de Transformadores preentrenados, que fue usado para ajustar varias tareas de PLN y obtuvo resultados de vanguardia
@@ -50,7 +50,7 @@ Un ejemplo de una tarea es predecir la palabra siguiente en una oración con bas
 -Otro ejemplo es el *modelado de leguaje oculto*, en el que el modelo predice una palabra oculta en la oración.
+Otro ejemplo es el *modelado de lenguaje oculto*, en el que el modelo predice una palabra oculta en la oración.
-Otro ejemplo es el *modelado de leguaje oculto*, en el que el modelo predice una palabra oculta en la oración.
+Otro ejemplo es el *modelado de lenguaje oculto*, en el que el modelo predice una palabra oculta en la oración.
 @@ -84,7 +84,7 @@ Esta es la razón por la que compartir modelos de lenguaje es fundamental: compa
@@ -84,7 +84,7 @@ Esta es la razón por la que compartir modelos de lenguaje es fundamental: compa

 -
- -
- +
+ +
+ +
+  +
+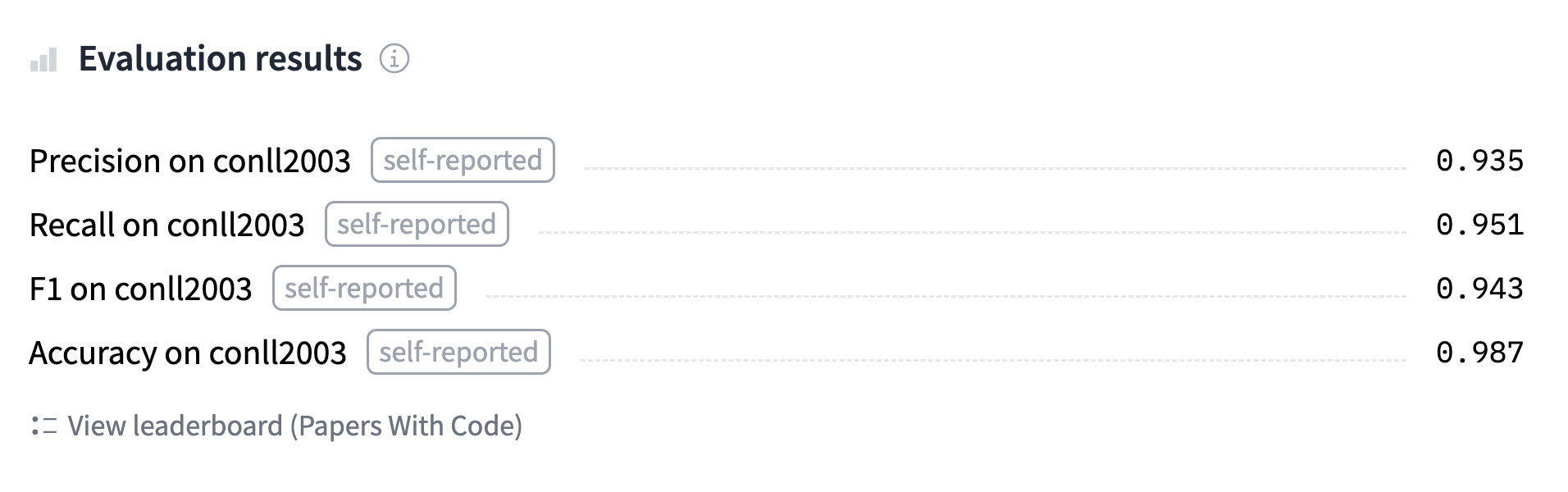 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+Давайте посмотрим на датасет:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+У нас есть 210 173 пары предложений, но в одной части, поэтому нам нужно создать собственный проверочный набор. Как мы видели в [Главе 5](../chapter5/1), у `Dataset` есть метод `train_test_split()`, который может нам помочь. Мы зададим seed для воспроизводимости:
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+Мы можем переименовать ключ `"test"` в `"validation"` следующим образом:
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+Теперь давайте рассмотрим один элемент датасета:
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+Мы получаем словарь с двумя предложениями на запрошенной паре языков. Одна из особенностей этого датасета, наполненного техническими терминами в области компьютерных наук, заключается в том, что все они полностью переведены на французский язык. Однако французские инженеры при разговоре оставляют большинство специфических для компьютерных наук слов на английском. Например, слово "threads" вполне может встретиться во французском предложении, особенно в техническом разговоре; но в данном датасете оно переведено как более правильное "fils de discussion". Используемая нами модель, предварительно обученная на большем корпусе французских и английских предложений, выбирает более простой вариант - оставить слово как есть:
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+Другой пример такого поведения можно увидеть на примере слова "plugin", которое официально не является французским словом, но большинство носителей языка поймут его и не станут переводить.
+В датасете KDE4 это слово было переведено на французский как более официальное "module d'extension":
+
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+Однако наша предварительно обученная модель придерживается компактного и знакомого английского слова:
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+Будет интересно посмотреть, сможет ли наша дообученная модель уловить эти особенности датасета (спойлер: сможет).
+
+
+
+Давайте посмотрим на датасет:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+У нас есть 210 173 пары предложений, но в одной части, поэтому нам нужно создать собственный проверочный набор. Как мы видели в [Главе 5](../chapter5/1), у `Dataset` есть метод `train_test_split()`, который может нам помочь. Мы зададим seed для воспроизводимости:
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+Мы можем переименовать ключ `"test"` в `"validation"` следующим образом:
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+Теперь давайте рассмотрим один элемент датасета:
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+Мы получаем словарь с двумя предложениями на запрошенной паре языков. Одна из особенностей этого датасета, наполненного техническими терминами в области компьютерных наук, заключается в том, что все они полностью переведены на французский язык. Однако французские инженеры при разговоре оставляют большинство специфических для компьютерных наук слов на английском. Например, слово "threads" вполне может встретиться во французском предложении, особенно в техническом разговоре; но в данном датасете оно переведено как более правильное "fils de discussion". Используемая нами модель, предварительно обученная на большем корпусе французских и английских предложений, выбирает более простой вариант - оставить слово как есть:
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+Другой пример такого поведения можно увидеть на примере слова "plugin", которое официально не является французским словом, но большинство носителей языка поймут его и не станут переводить.
+В датасете KDE4 это слово было переведено на французский как более официальное "module d'extension":
+
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+Однако наша предварительно обученная модель придерживается компактного и знакомого английского слова:
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+Будет интересно посмотреть, сможет ли наша дообученная модель уловить эти особенности датасета (спойлер: сможет).
+
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+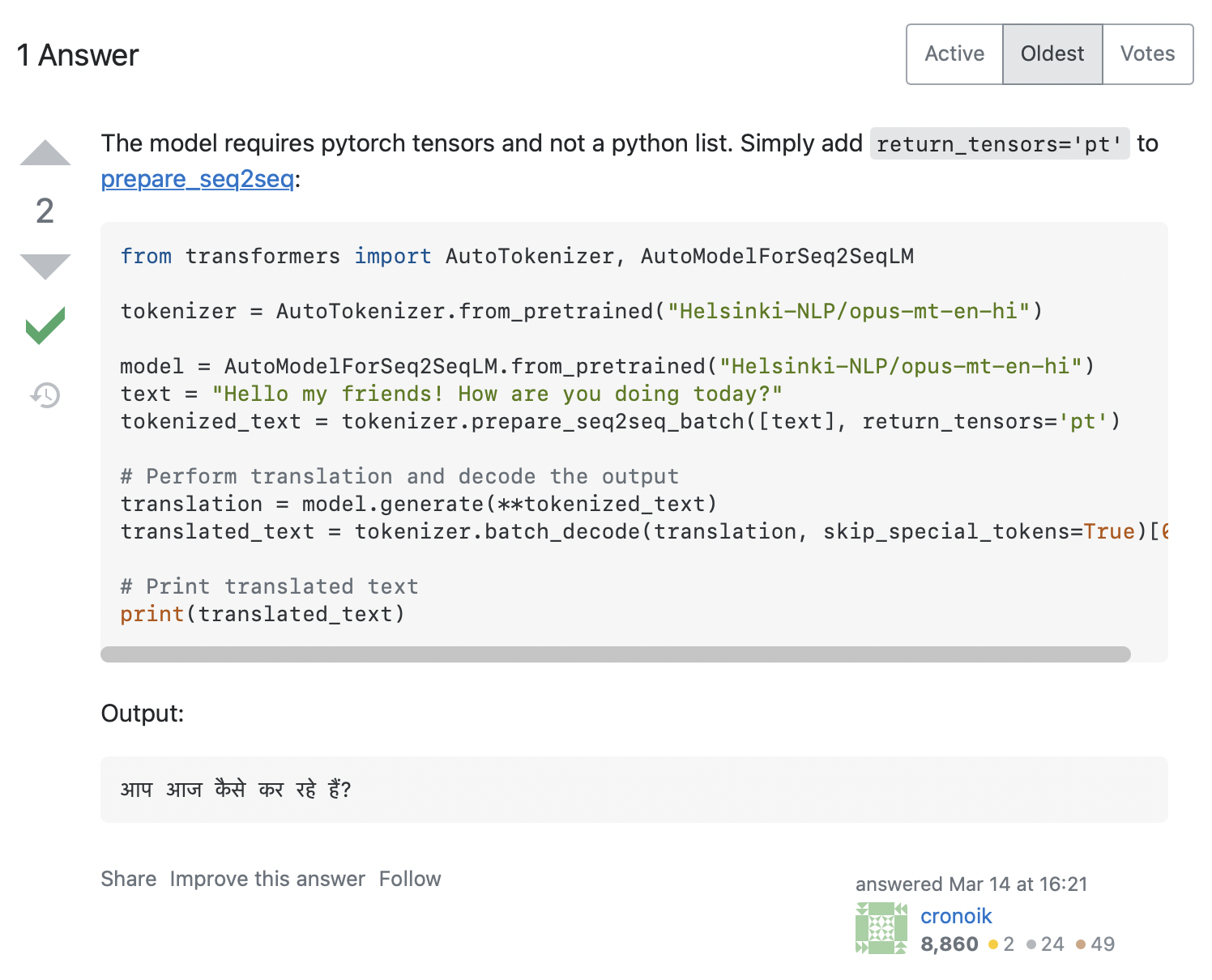 +
+ +
+ +
+ +
+ +
+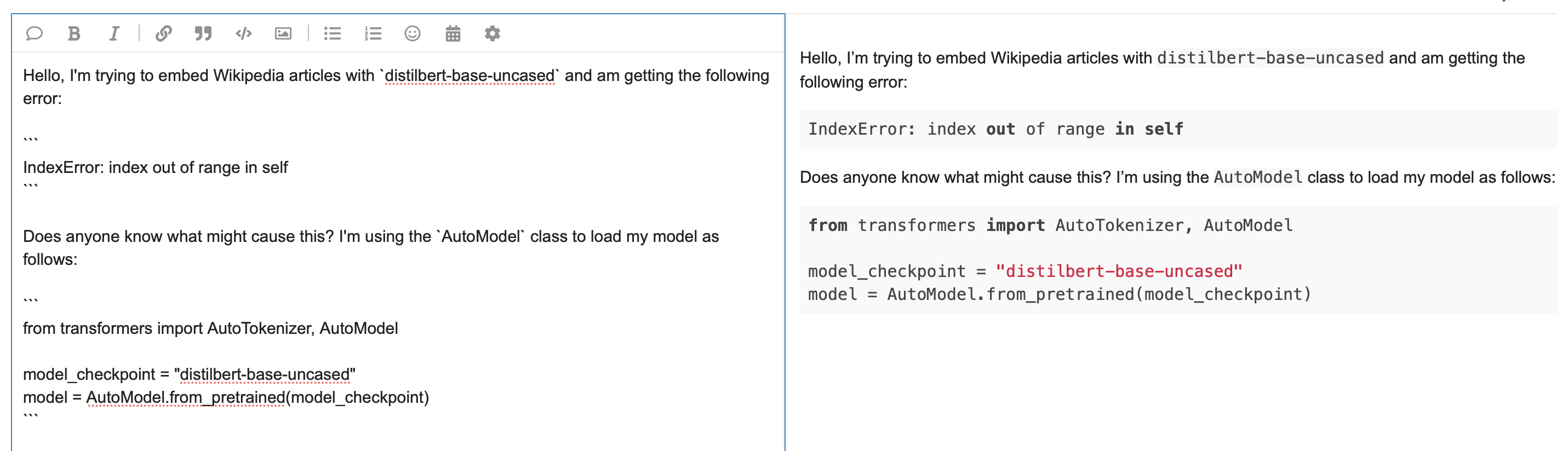 +
+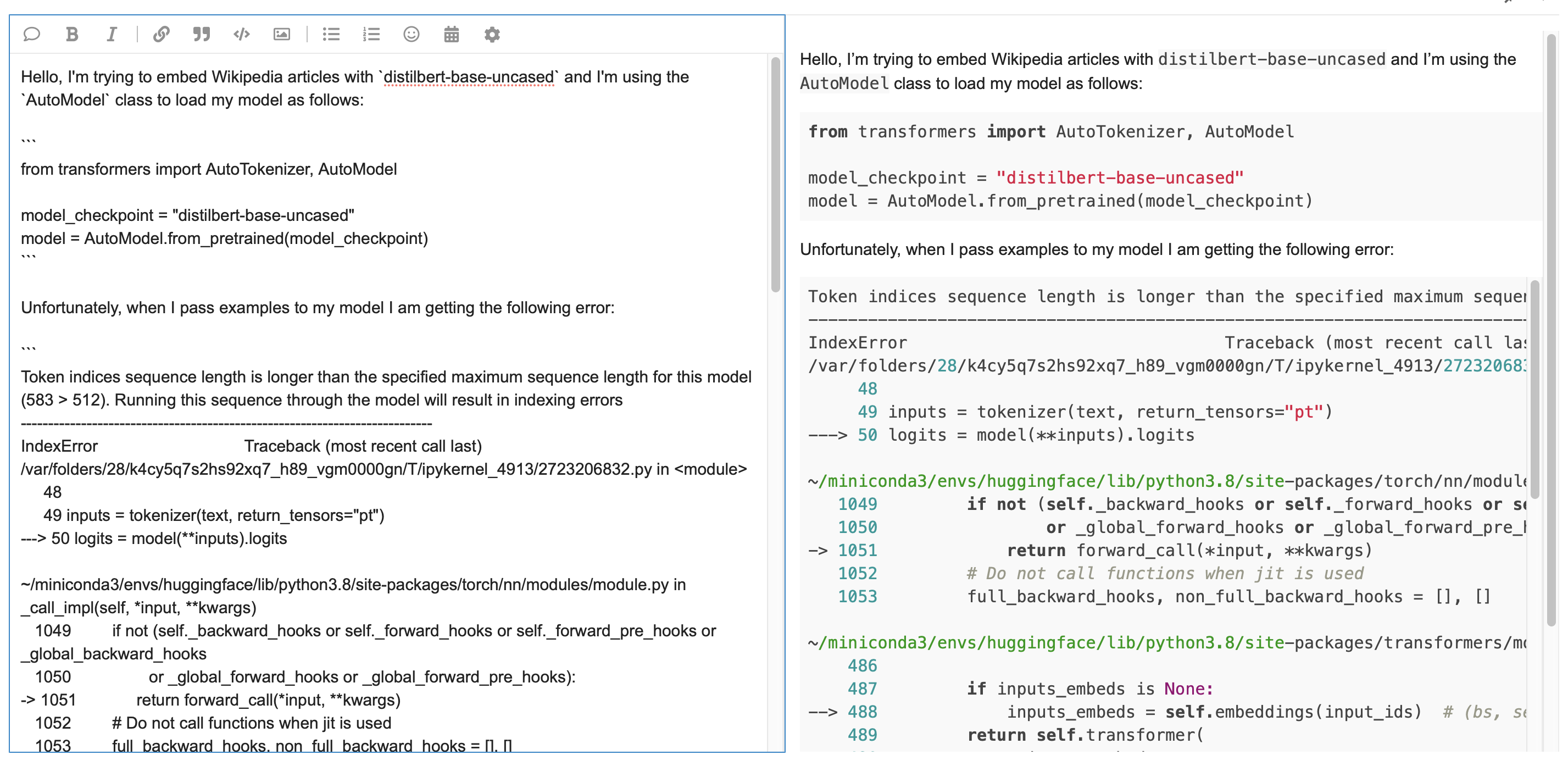 +
+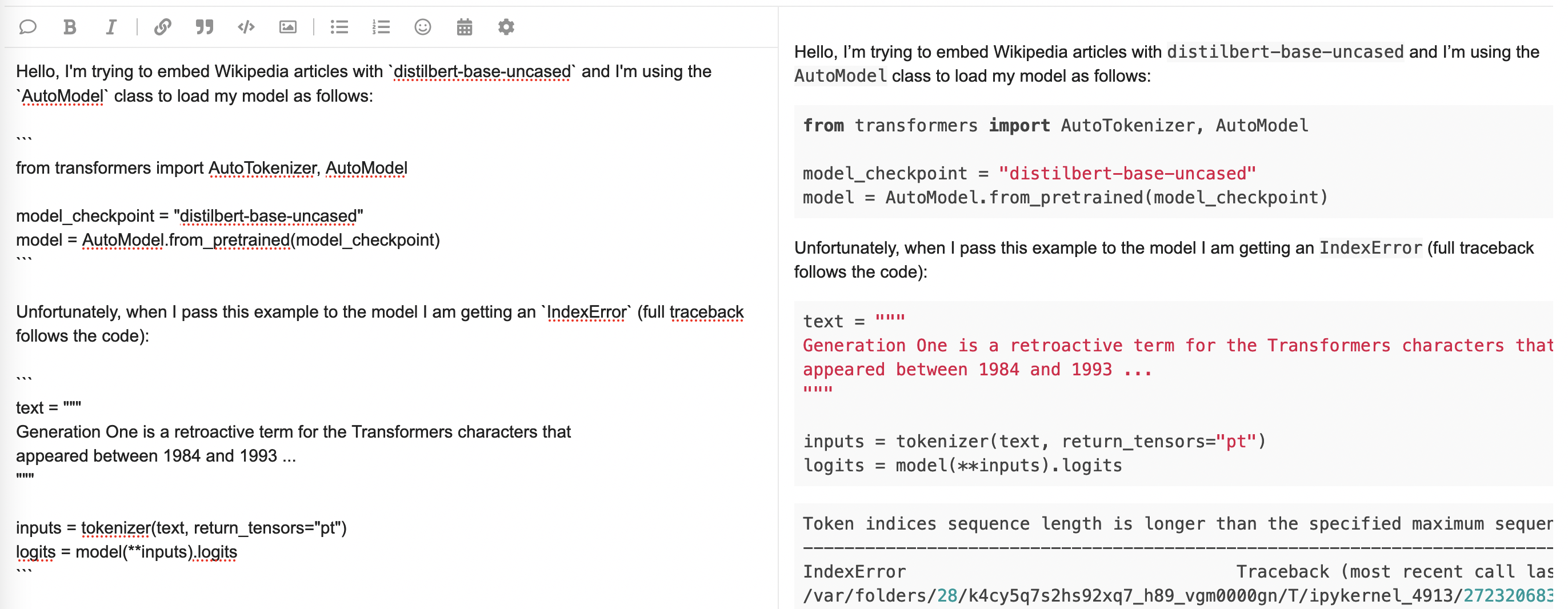 +
+ +
+ +
+ +"""
+
+article = "Check out [the original Rick and Morty Bot](https://huggingface.co/spaces/kingabzpro/Rick_and_Morty_Bot) that this demo is based off of."
+
+gr.Interface(
+ fn=predict,
+ inputs="textbox",
+ outputs="text",
+ title=title,
+ description=description,
+ article=article,
+ examples=[["What are you doing?"], ["Where should we time travel to?"]],
+).launch()
+```
+
+Используя приведенные выше варианты, мы получим более завершенный интерфейс. Попробуйте интерфейс, представленный ниже:
+
+
+
+### Распространение демо с помощью временных ссылок[[sharing-your-demo-with-temporary-links]]
+Теперь, когда у нас есть работающее демо нашей модели машинного обучения, давайте узнаем, как легко поделиться ссылкой на наш интерфейс.
+Интерфейсами можно легко поделиться публично, установив `share=True` в методе `launch()`:
+
+```python
+gr.Interface(classify_image, "image", "label").launch(share=True)
+```
+
+В результате создается общедоступная ссылка, которую вы можете отправить кому угодно! Когда вы отправляете эту ссылку, пользователь на другой стороне может опробовать модель в своем браузере в течение 72 часов. Поскольку обработка происходит на вашем устройстве (пока оно включено!), вам не нужно беспокоиться об упаковке каких-либо зависимостей. Если вы работаете в блокноте Google Colab, ссылка на общий доступ всегда создается автоматически. Обычно она выглядит примерно так: **XXXXX.gradio.app**. Хотя ссылка предоставляется через Gradio, мы являемся лишь прокси для вашего локального сервера и не храним никаких данных, передаваемых через интерфейсы.
+
+Однако не забывайте, что эти ссылки общедоступны, а значит, любой желающий может использовать вашу модель для прогнозирования! Поэтому не раскрывайте конфиденциальную информацию через написанные вами функции и не допускайте критических изменений на вашем устройстве. Если вы установите `share=False` (по умолчанию), будет создана только локальная ссылка.
+
+### Хостинг вашего демо на Hugging Face Spaces[[hosting-your-demo-on-hugging-face-spaces]]
+
+Ссылка на ресурс, которую можно передать коллегам, - это здорово, но как разместить демо на постоянном хостинге, чтобы оно существовало в своем собственном "пространстве (space)" в Интернете?
+
+Hugging Face Spaces предоставляет инфраструктуру для постоянного размещения вашей модели Gradio в интернете, **бесплатно**! Spaces позволяет вам создать и разместить в (публичном или частном) репозитории,
+где ваш Gradio
+код интерфейса будет существовать в файле `app.py`. [Прочитайте пошаговое руководство](https://huggingface.co/blog/gradio-spaces) чтобы начать работу, или посмотрите видео с примером ниже.
+
+
+"""
+
+article = "Check out [the original Rick and Morty Bot](https://huggingface.co/spaces/kingabzpro/Rick_and_Morty_Bot) that this demo is based off of."
+
+gr.Interface(
+ fn=predict,
+ inputs="textbox",
+ outputs="text",
+ title=title,
+ description=description,
+ article=article,
+ examples=[["What are you doing?"], ["Where should we time travel to?"]],
+).launch()
+```
+
+Используя приведенные выше варианты, мы получим более завершенный интерфейс. Попробуйте интерфейс, представленный ниже:
+
+
+
+### Распространение демо с помощью временных ссылок[[sharing-your-demo-with-temporary-links]]
+Теперь, когда у нас есть работающее демо нашей модели машинного обучения, давайте узнаем, как легко поделиться ссылкой на наш интерфейс.
+Интерфейсами можно легко поделиться публично, установив `share=True` в методе `launch()`:
+
+```python
+gr.Interface(classify_image, "image", "label").launch(share=True)
+```
+
+В результате создается общедоступная ссылка, которую вы можете отправить кому угодно! Когда вы отправляете эту ссылку, пользователь на другой стороне может опробовать модель в своем браузере в течение 72 часов. Поскольку обработка происходит на вашем устройстве (пока оно включено!), вам не нужно беспокоиться об упаковке каких-либо зависимостей. Если вы работаете в блокноте Google Colab, ссылка на общий доступ всегда создается автоматически. Обычно она выглядит примерно так: **XXXXX.gradio.app**. Хотя ссылка предоставляется через Gradio, мы являемся лишь прокси для вашего локального сервера и не храним никаких данных, передаваемых через интерфейсы.
+
+Однако не забывайте, что эти ссылки общедоступны, а значит, любой желающий может использовать вашу модель для прогнозирования! Поэтому не раскрывайте конфиденциальную информацию через написанные вами функции и не допускайте критических изменений на вашем устройстве. Если вы установите `share=False` (по умолчанию), будет создана только локальная ссылка.
+
+### Хостинг вашего демо на Hugging Face Spaces[[hosting-your-demo-on-hugging-face-spaces]]
+
+Ссылка на ресурс, которую можно передать коллегам, - это здорово, но как разместить демо на постоянном хостинге, чтобы оно существовало в своем собственном "пространстве (space)" в Интернете?
+
+Hugging Face Spaces предоставляет инфраструктуру для постоянного размещения вашей модели Gradio в интернете, **бесплатно**! Spaces позволяет вам создать и разместить в (публичном или частном) репозитории,
+где ваш Gradio
+код интерфейса будет существовать в файле `app.py`. [Прочитайте пошаговое руководство](https://huggingface.co/blog/gradio-spaces) чтобы начать работу, или посмотрите видео с примером ниже.
+
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
[🤗 Transformers 库](https://github.com/huggingface/transformers)提供了创建和使用这些共享模型的功能。[模型中心(hub)](https://huggingface.co/models)包含数千个任何人都可以下载和使用的预训练模型。您还可以将自己的模型上传到 Hub!
+
[🤗 Transformers 库](https://github.com/huggingface/transformers)提供了创建和使用这些共享模型的功能。[模型中心(hub)](https://huggingface.co/models)包含数千个任何人都可以下载和使用的预训练模型。您还可以将自己的模型上传到 Hub!