ZooKeeper是一项集中式服务,分布式应用程序的分布式协调服务。
用于维护配置信息、命名,提供分布式同步以及提供组服务。所有这些类型的服务都以某种形式被分布式应用程序使用。每次实施它们时,都会进行很多工作来修复不可避免的错误和竞争条件。
由于难以实现这类服务,因此应用程序最初通常会跳过它们,从而使它们在存在更改的情况下变得脆弱并且难以管理。即使部署正确,这些服务的不同实现也会导致部署应用程序时的管理复杂性
文件系统 + 监听通知机制
- 监听通知机制:客户端注册监听它关心的目录节点,当目录节点发生变化时,Zookeeper会通知客户端
ZooKeeper设计为高性能,
为了显示随着时间的推移系统在注入故障时的行为,我们运行了由7台机器组成的ZooKeeper服务,我们使用与以前相同的饱和度基准,但是这次我们将写入百分比保持在恒定的30%,这是我们预期工作量的保守比例。
官方zookeeper下载,下载ZooKeeper,目前最新的稳定版本为 3.6.0 版本,用户可以自行选择一个速度较快的镜像来下载即可.
这边演示用的版本apache-zookeeper-3.6.0-bin.tar.gz
[root@localhost download]$ mv /data/download/apache-zookeeper-3.6.0-bin/ ../app/zookeeper/
- dataDir:指定数据存放路径
- dataLogDir:指定日志存放路径
- clientPort:指定端口号
- tickTime: 指定心跳间隔时间,毫秒,默认2000
- initLimit: 指定服务端与客户端间隔数
- syncLimit:指定服务器(Follwer)与领导者(Leader)之间过时的时间,请求和应答时间的长度
- maxClientCnxns: 指定处理最大的客户端数量
- autopurge.snapRetainCount:指定保留快照的数量
修改配置文件
路径/data/app/zookeeper/conf/下的zoo_sample.cfg 改名为 zoo.cfg ,默认读取该文件 zoo.cfg
// 数据文件存放目录
dataDir=/data/app/zookeeper/data/tmp
//日志存放目录
dataLogDir=/data/app/zookeeper/data/log
启动
[root@localhost zookeeper]$ cd ../app/zookeeper/
[root@localhost zookeeper]$ sh bin/zkServer.sh start &

真是集群部署都是不同物理节点上,本文仅为了阐述原理,所以采用的是伪集群方式,希望大家注意。
复制所需的 conf/zoo.cfg 文件,形成 zoo1.cfg、zoo2.cfg、zoo3.cfg,需要修改其中 dataDir、clientPort、dataLogDir
以下仅给出 zoo1.cfg 的配置,供参考
tickTime=2000
dataDir=/data/app/zookeeper/data/zk1
dataLogDir=/data/app/zookeeper/data/zk1/log
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
[zkshell: 0] help
ZooKeeper -server host:port cmd args
addauth scheme auth
close
config [-c] [-w] [-s]
connect host:port
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
delete [-v version] path
deleteall path
delquota [-n|-b] path
get [-s] [-w] path
getAcl [-s] path
getAllChildrenNumber path
getEphemerals path
history
listquota path
ls [-s] [-w] [-R] path
ls2 path [watch]
printwatches on|off
quit
reconfig [-s] [-v version] [[-file path] | [-members serverID=host:port1:port2;port3[,...]*]] | [-add serverId=host:port1:port2;port3[,...]]* [-remove serverId[,...]*]
redo cmdno
removewatches path [-c|-d|-a] [-l]
rmr path
set [-s] [-v version] path data
setAcl [-s] [-v version] [-R] path acl
setquota -n|-b val path
stat [-w] path
sync path
Zab 全称是 Zookeeper Atomic Broadcast,也称之为 Zookeeper原子广播,Zookeeper 是通过 Zab 协议来保证分布式事务的最终一致性<这很重要>。
它的工作模式主要有两种:崩溃恢复和消息广播
-
崩溃恢复:当整个服务框架在启动中,或者当Leader服务器出现网络中断、崩溃退出与重启等异常情况时,zab协议就会进入崩溃恢复模式并选举出新的Leader服务器。当选举产生了新的Leader服务器,同时集群中已经有过半的服务器与新的Leader服务器完成状态同步之后,ZAB协议就会退出崩溃恢复模式。
-
消息广播:ZAB协议的消息广播过程使用的是一个原子广播协议,类似于二阶段提交(2PC),针对客户端的事务请求,Leader 服务器会为其生成对应的事务Proposal,并将其发送给集群中其他所有的服务器,然后再分别收集各自的选票,最后进行事务提交。
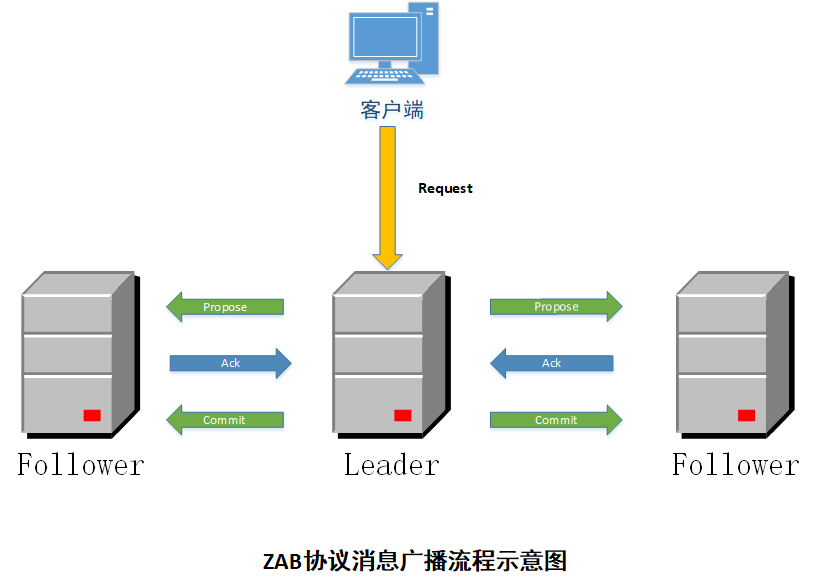
-
Zookeeper独有的协议, 支持
崩溃恢复的原子广播协议,是Zookeeper保证数据一致性的核心算法。主要借鉴Paxos算法,但又不像Paxos那样,是一种通用的分布式一致性算法。 -
利用Zab协议来实现数据一致性,以该协议,zk构筑一套主备模型(即
Leader和Follower模型)的系统架构来保证集群中各个副本之间数据的一致性。
ZXID:全局、唯一、顺序