citation("[package]")
+
+
+
+
+
+
+
+ Book
+
+
+
+ Central entrypoint to the mlr3verse
+
+
+  +
+
+
+
+ The mlr3 ecosystem is a collection of R packages for machine learning. The base package mlr3 only provides the basic building blocks for machine learning. The extensions packages extent mlr3 with functionality for additional task types, learning algorithms, tuning algorithms, feature selection strategies, visualizations or preprocessing capabilities. The packages are listed bellow with a short description. For more information about the packages, check out their respective homepages.
+The dot next to the package name indicates the lifecycle stage.
+
If you use our packages in your research, please cite our articles on mlr3 (Lang et al. 2019), mlr3proba (Sonabend et al. 2021) or mlr3pipelines (Binder et al. 2021). To get the citation information of other packages, call
+citation("[package]")Feature Filters quantify the importance of each feature of a Task by assigning them a numerical score. In a second step, features can be selected by either selecting a fixed absolute or relative frequency of the best features, or by thresholding on the score value.
The Filter PipeOp allows to use filters as a preprocessing step.
Use the \(-\log_{10}()\)-transformed \(p\)-values of a Kruskal-Wallis rank sum test (implemented in kruskal.test()) for filtering features of the Pima Indian Diabetes tasks.
library("mlr3verse")Loading required package: mlr3# retrieve a task
+task = tsk("pima")
+
+# retrieve a filter
+filter = flt("kruskal_test")
+
+# calculate scores
+filter$calculate(task)
+
+# access scores
+filter$scores glucose age mass insulin triceps pregnant pedigree pressure
+39.885381 16.942901 16.740864 13.127828 9.158113 7.426955 5.922431 5.788607 # plot scores
+autoplot(filter)
# subset task to 3 most important features
+task$select(head(names(filter$scores), 3))
+task$feature_names[1] "age" "glucose" "mass" Setting time limits is an important consideration when tuning unreliable or unstable learning algorithms and when working on shared computing resources. The mlr3 ecosystem provides several mechanisms for setting time constraints for individual learners, tuning processes, and nested resampling.
+ +This section demonstrates how to impose time constraints using a support vector machine (SVM) as an illustrative example.
+library(mlr3verse)
+
+learner = lrn("classif.svm")Applying timeouts to the $train() and $predict() functions is essential for managing learners that may operate indefinitely. These time constraints are set independently for both the training and prediction stages. Generally, training a learner consumes more time than prediction. Certain learners, like k-nearest neighbors, lack a distinct training phase and require a timeout only during prediction. For the SVM’s training, we set a 10-second limit.
learner$timeout = c(train = 10, predict = Inf)To effectively terminate the process if necessary, it’s important to run the training and prediction within a separate R process. The callr package is recommended for this encapsulation, as it tends to be more reliable than the evaluate package, especially for terminating externally compiled code.
+learner$encapsulate = c(train = "callr", predict = "callr")Note that using callr increases the runtime due to the overhead of starting an R process. Additionally, it’s advisable to specify a fallback learner, such as "classif.featureless", to provide baseline predictions in case the primary learner is terminated.
learner$fallback = lrn("classif.featureless")These time constraints are now integrated into the training, resampling, and benchmarking processes. For more information on encapsulation and fallback learners, see the mlr3book. The next section will focus on setting time limits for the entire tuning process.
+When working with high-performance computing clusters, jobs are often bound by strict time constraints. Exceeding these limits results in the job being terminated and the loss of any results generated. Therefore, it’s important to ensure that the tuning process is designed to adhere to these time constraints.
+The trm("runtime") controls the duration of the tuning process. We must take into account that the terminator can only check if the time limit is reached between batches. We must therefore set the time lower than the runtime of the job. How much lower depends on the runtime or time limit of the individual learners. The last batch should be able to finish before the time limit of the cluster is reached.
terminator = trm("run_time", secs = 60)
+
+instance = ti(
+ task = tsk("sonar"),
+ learner = learner,
+ resampling = rsmp("cv", folds = 3),
+ measures = msr("classif.ce"),
+ terminator = terminator
+)With these settings, our tuning operation is configured to run for 60 seconds, while individual learners are set to terminate after 10 seconds. This approach ensures the tuning process is efficient and adheres to the constraints imposed by the high-performance computing cluster.
+When using nested resampling, time constraints become more complex as they are applied across various levels. As before, the time limit for an individual learner during the tuning is set with $timeout. The time limit for the tuning processes in the auto tuners is controlled with the trm("runtime"). It’s important to note that once the auto tuner enters the final phase of fitting the model and making predictions on the outer test set, the time limit governed by the terminator no longer applies. Additionally, the time limit previously set on the learner is temporarily deactivated, allowing the auto tuner to complete its task uninterrupted. However, a separate time limit can be assigned to each auto tuner using $timeout. This limit encompasses not only the tuning phase but also the time required for fitting the final model and predictions on the outer test set.
The best way to show this is with an example. We set the time limit for an individual learner to 10 seconds.
+learner$timeout = c(train = 10, predict = Inf)
+learner$encapsulate = c(train = "callr", predict = "callr")
+learner$fallback = lrn("classif.featureless")Next, we give each auto tuner 60 seconds to finish the tuning process.
+terminator = trm("run_time", secs = 60)Furthermore, we impose a 120-second limit for resampling each auto tuner. This effectively divides the time allocation, with around 60 seconds for tuning and another 60 seconds for final model fitting and predictions on the outer test set.
+at = auto_tuner(
+ tuner = tnr("random_search"),
+ learner = learner,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+ terminator = trm("run_time", secs = 60)
+)
+
+at$timeout = c(train = 100, predict = 20)
+at$encapsulate = c(train = "callr", predict = "callr")
+at$fallback = lrn("classif.featureless")In total, the entire nested resampling process is designed to be completed within 10 minutes (120 seconds multiplied by 5 folds).
+rr = resample(task, at, rsmp("cv", folds = 5))We delved into the setting of time constraints across different levels in the mlr3 ecosystem. From individual learners to the complexities of nested resampling, we’ve seen how effectively managing time limits can significantly enhance the efficiency and reliability of machine learning workflows. By utilizing the trm("runtime") for tuning processes and setting $timeout for individual learners and auto tuners, we can ensure that our machine learning tasks are not only effective but also adhere to the practical time constraints of shared computational resources. For more information, see also the error handling section in the mlr3book.
In the realm of data science, machine learning frameworks play an important role in streamlining and accelerating the development of analytical workflows. Among these, tidymodels and mlr3 stand out as prominent tools within the R community. They provide a unified interface for data preprocessing, model training, resampling and tuning. The streamlined and accelerated development process, while efficient, typically results in a trade-off concerning runtime performance. This article undertakes a detailed comparison of the runtime efficiency of tidymodels and mlr3, focusing on their performance in training, resampling, and tuning machine learning models. Specifically, we assess the time efficiency of these frameworks in running the rpart::rpart() and ranger::ranger() models, using the Sonar dataset as a test case. Additionally, the study delves into analyzing the runtime overhead of these frameworks by comparing their performance against training the models without a framework. Through this comparative analysis, the article aims to provide valuable insights into the operational trade-offs of using these advanced machine learning frameworks in practical data science applications.
We employ the microbenchmark package to measure the time required for training, resampling, and tuning models. This benchmarking process is applied to the Sonar dataset using the rpart and ranger algorithms.
library("mlr3verse")
+library("tidymodels")
+library("microbenchmark")
+
+task = tsk("sonar")
+data = task$data()
+formula = Class ~ .To ensure the robustness of our results, each function call within the benchmark is executed 100 times in a randomized sequence. The microbenchmark package then provides us with detailed insights, including the median, lower quartile, and upper quartile of the runtimes. To further enhance the reliability of our findings, we execute the benchmark on a cluster. Each run of microbenchmark is repeated 100 times, with different seeds applied for each iteration. Resulting in a total of 10,000 function calls of each command. The computing environment for each worker in the cluster consists of 3 cores and 12 GB of RAM. For transparency and reproducibility, the examples of the code used for this experiment are provided as snippets in the article. The complete code, along with all details of the experiment, is available in our public repository, mlr-org/mlr-benchmark.
It’s important to note that our cluster setup is not specifically optimized for single-core performance. Consequently, executing the same benchmark on a local machine with might yield faster results.
+Our benchmark starts with the fundamental task of model training. To facilitate a direct comparison, we have structured our presentation into two distinct segments. On the left, we demonstrate the initialization of the rpart model, employing both mlr3 and tidymodels frameworks. The rpart model is a decision tree classifier, which is a simple and fast-fitting algorithm for classification tasks. Simultaneously, on the right, we turn our attention to the initialization of the ranger model, known for its efficient implementation of the random forest algorithm. Our aim is to mirror the configuration as closely as possible across both frameworks, maintaining consistency in parameters and settings.
# tidymodels
+tm_mod = decision_tree() %>%
+ set_engine("rpart",
+ xval = 0L) %>%
+ set_mode("classification")
+
+# mlr3
+learner = lrn("classif.rpart",
+ xval = 0L)
+# tidymodels
+tm_mod = rand_forest(trees = 1000L) %>%
+ set_engine("ranger",
+ num.threads = 1L,
+ seed = 1) %>%
+ set_mode("classification")
+
+# mlr3
+learner = lrn("classif.ranger",
+ num.trees = 1000L,
+ num.threads = 1L,
+ seed = 1,
+ verbose = FALSE,
+ predict_type = "prob")We measure the runtime for the train functions within each framework. The result of the train function is a trained model in both frameworks. In addition, we invoke the rpart() and ranger() functions to establish a baseline for the minimum achievable runtime. This allows us to not only assess the efficiency of the train functions in each framework but also to understand how they perform relative to the base packages.
# tidymodels train
+fit(tm_mod, formula, data = data)
+
+# mlr3 train
+learner$train(task)When training an rpart model, tidymodels demonstrates superior speed, outperforming mlr3 (Table 1). Notably, the mlr3 package requires approximately twice the time compared to the baseline.
A key observation from our results is the significant relative overhead when using a framework for rpart model training. Given that rpart inherently requires a shorter training time, the additional processing time introduced by the frameworks becomes more pronounced. This aspect highlights the trade-off between the convenience offered by these frameworks and their impact on runtime for quicker tasks.
Conversely, when we shift our focus to training a ranger model, the scenario changes (Table 2). Here, the runtime performance of ranger is strikingly similar across both tidymodels and mlr3. This equality in execution time can be attributed to the inherently longer training duration required by ranger models. As a result, the relative overhead introduced by either framework becomes minimal, effectively diminishing in the face of the more time-intensive training process. This pattern suggests that for more complex or time-consuming tasks, the choice of framework may have a less significant impact on overall runtime performance.
rpart depending on the framework.
+| Framework | +LQ | +Median | +UQ | +
|---|---|---|---|
| base | +11 | +11 | +12 | +
| mlr3 | +23 | +23 | +24 | +
| tidymodels | +18 | +18 | +19 | +
ranger depending on the framework.
+| Framework | +LQ | +Median | +UQ | +
|---|---|---|---|
| base | +286 | +322 | +347 | +
| mlr3 | +301 | +335 | +357 | +
| tidymodels | +310 | +342 | +362 | +
We proceed to evaluate the runtime performance of the resampling functions within both frameworks, specifically under conditions without parallelization. This step involves the generation of resampling splits, including 3-fold, 6-fold, and 9-fold cross-validation. Additionally, we run a 100 times repeated 3-fold cross-validation.
+We generate the same resampling splits for both frameworks. This consistency is key to ensuring that any observed differences in runtime are attributable to the frameworks themselves, rather than variations in the resampling process.
+In our pursuit of a fair and balanced comparison, we address certain inherent differences between the two frameworks. Notably, tidymodels inherently includes scoring of the resampling results as part of its process. To align the comparison, we replicate this scoring step in mlr3, thus maintaining a level field for evaluation. Furthermore, mlr3 inherently saves predictions during the resampling process. To match this, we activate the saving of the predictions in tidymodels.
# tidymodels resample
+control = control_grid(save_pred = TRUE)
+metrics = metric_set(accuracy)
+
+tm_wf =
+ workflow() %>%
+ add_model(tm_mod) %>%
+ add_formula(formula)
+
+fit_resamples(tm_wf, folds, metrics = metrics, control = control)
+
+# mlr3 resample
+measure = msr("classif.acc")
+
+rr = resample(task, learner, resampling)
+rr$score(measure)When resampling the fast-fitting rpart model, mlr3 demonstrates a notable edge in speed, as detailed in Table 3. In contrast, when it comes to resampling the more computationally intensive ranger models, the performance of tidymodels and mlr3 converges closely (Table 4). This parity in performance is particularly noteworthy, considering the differing internal mechanisms and optimizations of tidymodels and mlr3. A consistent trend observed across both frameworks is a linear increase in runtime proportional to the number of folds in cross-validation (Figure 1).
rpart depending on the framework and resampling strategy.
+| Framework | +Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|---|
| mlr3 | +cv3 | +188 | +196 | +210 | +
| tidymodels | +cv3 | +233 | +242 | +257 | +
| mlr3 | +cv6 | +343 | +357 | +379 | +
| tidymodels | +cv6 | +401 | +415 | +436 | +
| mlr3 | +cv9 | +500 | +520 | +548 | +
| tidymodels | +cv9 | +568 | +588 | +616 | +
| mlr3 | +rcv100 | +15526 | +16023 | +16777 | +
| tidymodels | +rcv100 | +16409 | +16876 | +17527 | +
ranger depending on the framework and resampling strategy.
+| Framework | +Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|---|
| mlr3 | +cv3 | +923 | +1004 | +1062 | +
| tidymodels | +cv3 | +916 | +981 | +1023 | +
| mlr3 | +cv6 | +1990 | +2159 | +2272 | +
| tidymodels | +cv6 | +2089 | +2176 | +2239 | +
| mlr3 | +cv9 | +3074 | +3279 | +3441 | +
| tidymodels | +cv9 | +3260 | +3373 | +3453 | +
| mlr3 | +rcv100 | +85909 | +88642 | +91381 | +
| tidymodels | +rcv100 | +87828 | +88822 | +89843 | +
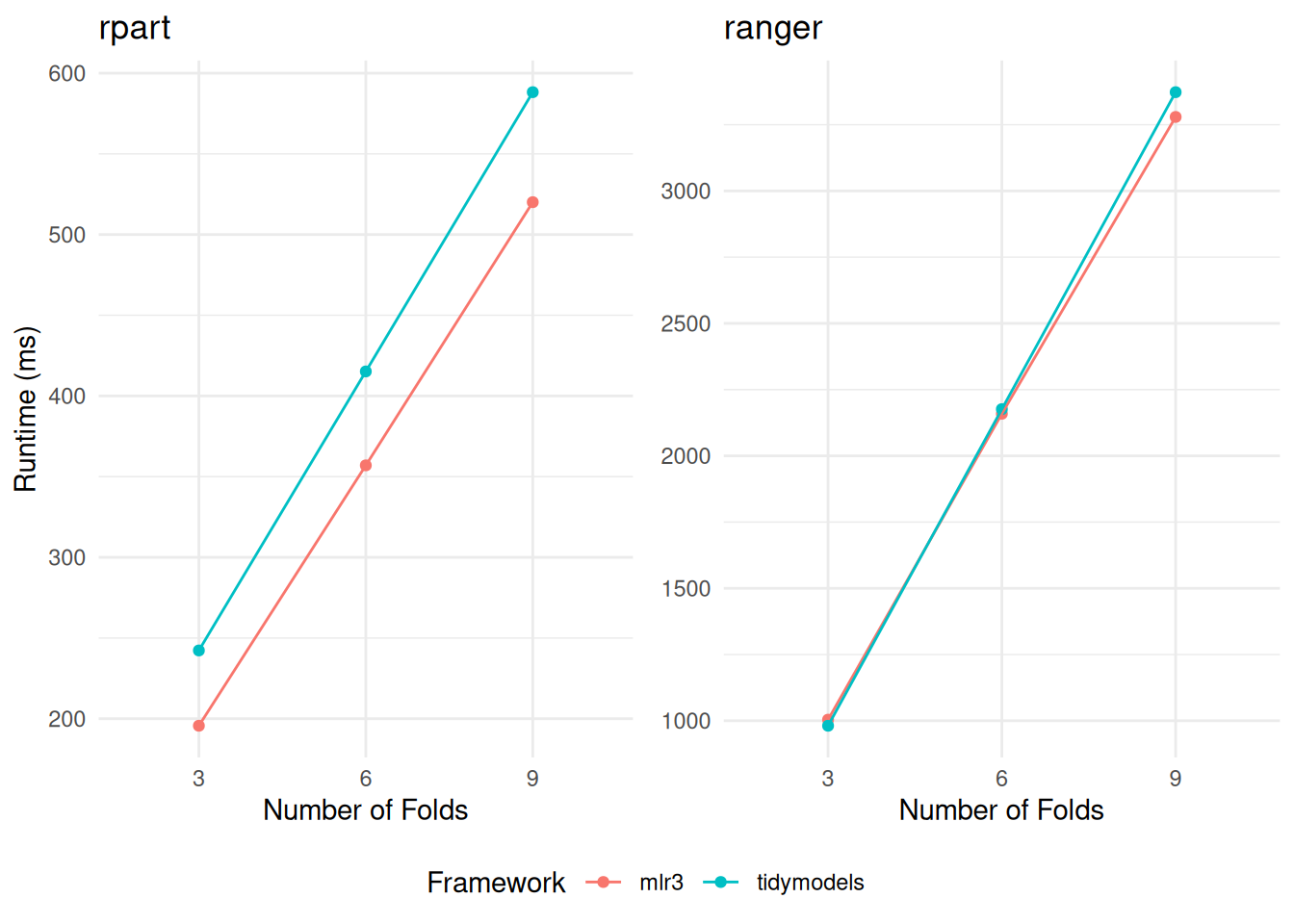 +
+rpart (displayed on the left) and ranger (on the right). The comparison encompasses variations across different frameworks and the number of folds in the cross-validation.
+We conducted a second set of resampling function tests, this time incorporating parallelization to explore its impact on runtime efficiency. In this phase, we utilized doFuture and doParallel as the primary parallelization packages for tidymodels, recognizing their robust support and compatibility. Meanwhile, for mlr3, the future package was employed to facilitate parallel processing.
Our findings, as presented in the respective tables (Table 5 and Table 6), reveal interesting dynamics about parallelization within the frameworks. When the number of folds in the resampling process is doubled, we observe only a marginal increase in the average runtime. This pattern suggests a significant overhead associated with initializing the parallel workers, a factor that becomes particularly influential in the overall efficiency of the parallelization process.
+In the case of the rpart model, the parallelization overhead appears to outweigh the potential speedup benefits, as illustrated in the left section of Figure 2. This result indicates that for less complex models like rpart, where individual training times are relatively short, the initialization cost of parallel workers may not be sufficiently offset by the reduced processing time per fold.
Conversely, for the ranger model, the utilization of parallelization demonstrates a clear advantage over the sequential version, as evidenced in the right section of Figure 2. This finding underscores that for more computationally intensive models like ranger, which have longer individual training times, the benefits of parallel processing significantly overcome the initial overhead of worker setup. This differentiation highlights the importance of considering the complexity and inherent processing time of models when deciding to implement parallelization strategies in these frameworks.
mlr3 with future and rpart depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +625 | +655 | +703 | +
| cv6 | +738 | +771 | +817 | +
| cv9 | +831 | +875 | +923 | +
| rcv100 | +8620 | +9043 | +9532 | +
mlr3 with future and ranger depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +836 | +884 | +943 | +
| cv6 | +1200 | +1249 | +1314 | +
| cv9 | +1577 | +1634 | +1706 | +
| rcv100 | +32047 | +32483 | +33022 | +
When paired with doFuture, tidymodels exhibits significantly slower runtime compared to the mlr3 package utilizing future (Table 7 and Table 8). We observed that tidymodels exports more data to the parallel workers, which notably exceeds that of mlr3. This substantial difference in data export could plausibly account for the observed slower runtime when using tidymodels on small tasks.
tidymodels with doFuture and rpart depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +2778 | +2817 | +3019 | +
| cv6 | +2808 | +2856 | +3033 | +
| cv9 | +2935 | +2975 | +3170 | +
| rcv100 | +9154 | +9302 | +9489 | +
tidymodels with doFuture and ranger depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +2982 | +3046 | +3234 | +
| cv6 | +3282 | +3366 | +3543 | +
| cv9 | +3568 | +3695 | +3869 | +
| rcv100 | +27546 | +27843 | +28166 | +
The utilization of the doParallel package demonstrates a notable improvement in handling smaller resampling tasks. In these scenarios, the resampling process consistently outperforms the mlr3 framework in terms of speed. However, it’s important to note that even with this enhanced performance, the doParallel package does not always surpass the efficiency of the sequential version, especially when working with the rpart model. This specific observation is illustrated in the left section of Figure 2.
tidymodels with doParallel and rpart depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +557 | +649 | +863 | +
| cv6 | +602 | +714 | +910 | +
| cv9 | +661 | +772 | +968 | +
| rcv100 | +10609 | +10820 | +11071 | +
tidymodels with doParallel and ranger depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +684 | +756 | +948 | +
| cv6 | +1007 | +1099 | +1272 | +
| cv9 | +1360 | +1461 | +1625 | +
| rcv100 | +31205 | +31486 | +31793 | +
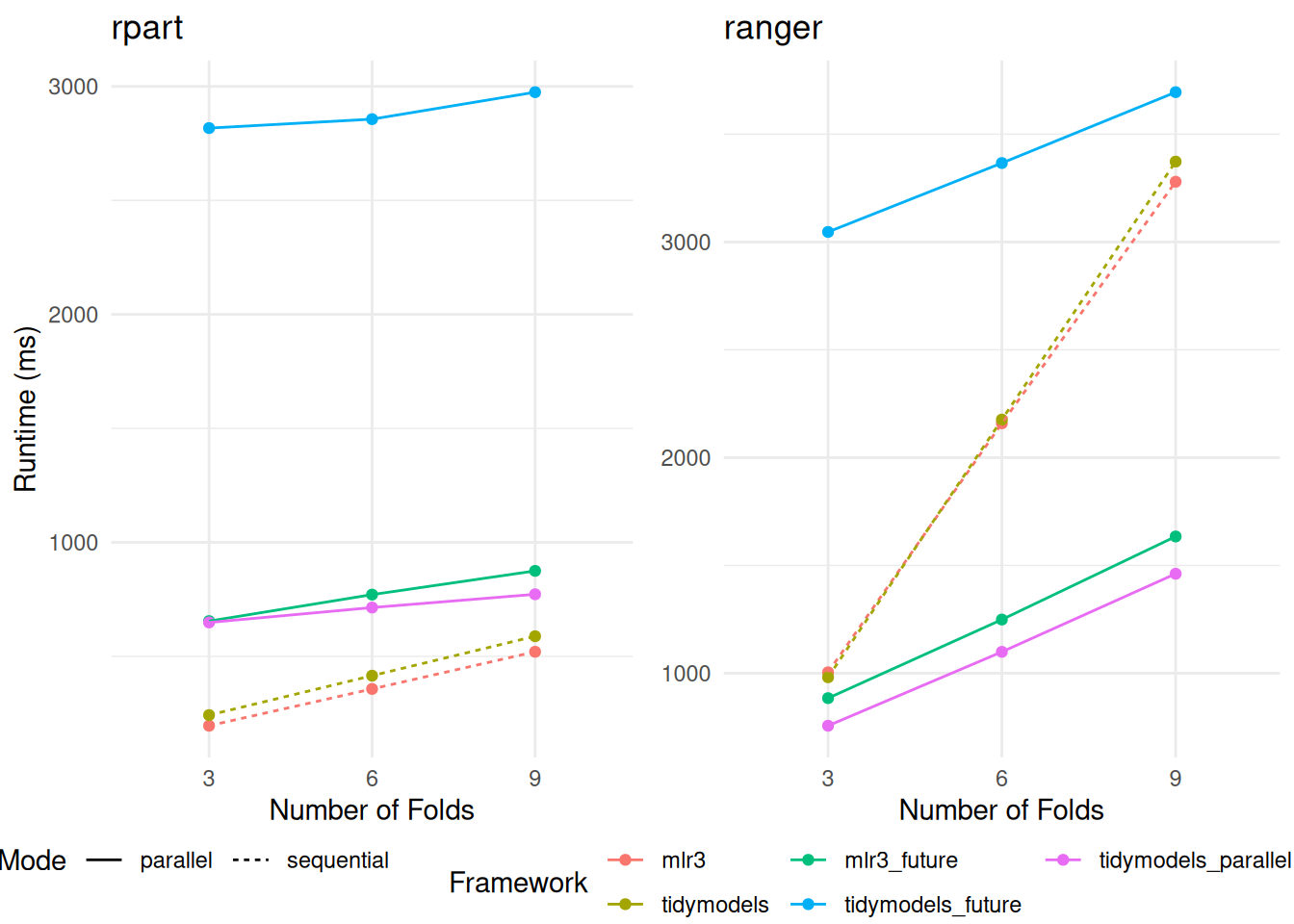 +
+rpart (displayed on the left) and ranger (on the right). The comparison encompasses variations across different frameworks, the number of folds in the cross-validation, and the implementation of parallelization.
+In the context of repeated cross-validation, our findings underscore the efficacy of parallelization (Figure 3). Across all frameworks tested, the adoption of parallel processing techniques yields a significant increase in speed. This enhancement is particularly noticeable in larger resampling tasks, where the demands on computational resources are more substantial.
+Interestingly, within these more extensive resampling scenarios, the doFuture package emerges as a more efficient option compared to doParallel. This distinction is important, as it highlights the relative strengths of different parallelization packages under varying workload conditions. While doParallel shows proficiency in smaller tasks, doFuture demonstrates its capability to handle larger, more complex resampling processes with greater speed and efficiency.
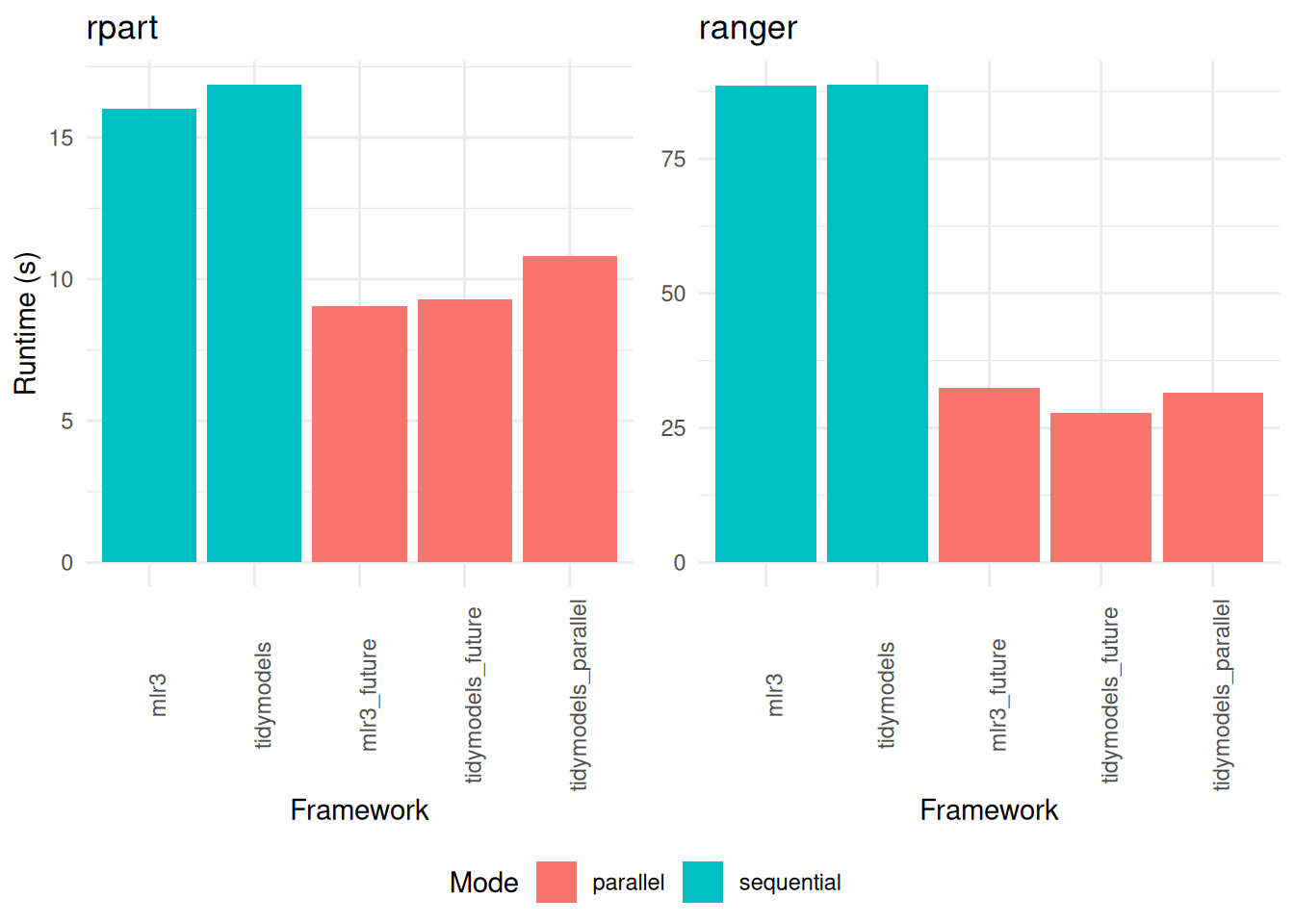 +
+rpart (displayed on the left) and ranger (on the right). The comparison encompasses variations across different frameworks and the implementation of parallelization.
+We then shift our focus to assessing the runtime performance of the tuning functions. In this phase, the tidymodels package is utilized to evaluate a predefined grid, comprising a specific set of hyperparameter configurations. To ensure a balanced and comparable analysis, we employ the "design_points" tuner from the mlr3tuning package. This approach allows us to evaluate the same grid within the mlr3 framework, maintaining consistency across both platforms. The grid used for this comparison contains 200 hyperparameter configurations each, for both the rpart and ranger models. This approach helps us to understand how each framework handles the optimization of model hyperparameters, a key aspect of building effective and efficient machine learning models.
# tidymodels
+tm_mod = decision_tree(
+ cost_complexity = tune()) %>%
+ set_engine("rpart",
+ xval = 0) %>%
+ set_mode("classification")
+
+tm_design = data.table(
+ cost_complexity = seq(0.1, 0.2, length.out = 200))
+
+# mlr3
+learner = lrn("classif.rpart",
+ xval = 0,
+ cp = to_tune())
+
+mlr3_design = data.table(
+ cp = seq(0.1, 0.2, length.out = 200))
+# tidymodels
+tm_mod = rand_forest(
+ trees = tune()) %>%
+ set_engine("ranger",
+ num.threads = 1L,
+ seed = 1) %>%
+ set_mode("classification")
+
+tm_design = data.table(
+ trees = seq(1000, 1199))
+
+# mlr3
+learner = lrn("classif.ranger",
+ num.trees = to_tune(1, 10000),
+ num.threads = 1L,
+ seed = 1,
+ verbose = FALSE,
+ predict_type = "prob")
+
+mlr3_design = data.table(
+ num.trees = seq(1000, 1199))We measure the runtime of the tune functions within each framework. Both the tidymodels and mlr3 frameworks are tasked with identifying the optimal hyperparameter configuration.
# tidymodels tune
+tune::tune_grid(
+ tm_wf,
+ resamples = resamples,
+ grid = design,
+ metrics = metrics)
+
+# mlr3 tune
+tuner = tnr("design_points", design = design, batch_size = nrow(design))
+mlr3tuning::tune(
+ tuner = tuner,
+ task = task,
+ learner = learner,
+ resampling = resampling,
+ measures = measure,
+ store_benchmark_result = FALSE)In our sequential tuning tests, mlr3 demonstrates a notable advantage in terms of speed. This finding is clearly evidenced in our results, as shown in Table Table 11 for the rpart model and Table Table 12 for the ranger model. The faster performance of mlr3 in these sequential runs highlights its efficiency in handling the tuning process without parallelization.
rpart depending on the framework.
+| Framework | +LQ | +Median | +UQ | +
|---|---|---|---|
| mlr3 | +27 | +27 | +28 | +
| tidymodels | +37 | +37 | +39 | +
ranger depending on the framework.
+| Framework | +LQ | +Median | +UQ | +
|---|---|---|---|
| mlr3 | +167 | +171 | +175 | +
| tidymodels | +194 | +195 | +196 | +
Concluding our analysis, we proceed to evaluate the runtime performance of the tune functions, this time implementing parallelization to enhance efficiency. For these runs, parallelization is executed on 3 cores.
+In the case of mlr3, we opt for the largest possible chunk size. This strategic choice means that all points within the tuning grid are sent to the workers in a single batch, effectively minimizing the overhead typically associated with parallelization. This approach is crucial in reducing the time spent in distributing tasks across multiple cores, thereby streamlining the tuning process. On the other hand, the tidymodels package also operates with the same chunk size, but this setting is determined and managed internally within the framework.
By conducting these parallelization tests, we aim to provide a deeper understanding of how each framework handles the distribution and management of computational tasks during the tuning process, particularly in a parallel computing environment. This final set of measurements is important in painting a complete picture of the runtime performance of the tune functions across both tidymodels and mlr3 under different operational settings.
options("mlr3.exec_chunk_size" = 200)Our analysis of the parallelized tuning functions reveals that the runtimes for mlr3 and tidymodels are remarkably similar. However, subtle differences emerge upon closer inspection. For instance, the mlr3 package exhibits a slightly faster performance when tuning the rpart model, as indicated in Table 13. In contrast, it falls marginally behind tidymodels in tuning the ranger model, as shown in Table 14.
Interestingly, when considering the specific context of a 3-fold cross-validation, the doParallel package outperforms doFuture in terms of speed, as demonstrated in Figure 4. This outcome suggests that the choice of parallelization package can have a significant impact on tuning efficiency, particularly in scenarios with a smaller number of folds.
A key takeaway from our study is the clear benefit of enabling parallelization, regardless of the chosen framework-backend combination. Activating parallelization consistently enhances performance, making it a highly recommended strategy for tuning machine learning models, especially in tasks involving extensive hyperparameter exploration or larger datasets. This conclusion underscores the value of parallel processing in modern machine learning workflows, offering a practical solution for accelerating model tuning across various computational settings.
+rpart depending on the framework.
+| Framework | +Backend | +LQ | +Median | +UQ | +
|---|---|---|---|---|
| mlr3 | +future | +11 | +12 | +12 | +
| tidymodels | +doFuture | +17 | +17 | +17 | +
| tidymodels | +doParallel | +13 | +13 | +13 | +
ranger depending on the framework.
+| Framework | +Backend | +LQ | +Median | +UQ | +
|---|---|---|---|---|
| mlr3 | +future | +54 | +55 | +55 | +
| tidymodels | +doFuture | +58 | +58 | +59 | +
| tidymodels | +doParallel | +54 | +54 | +55 | +
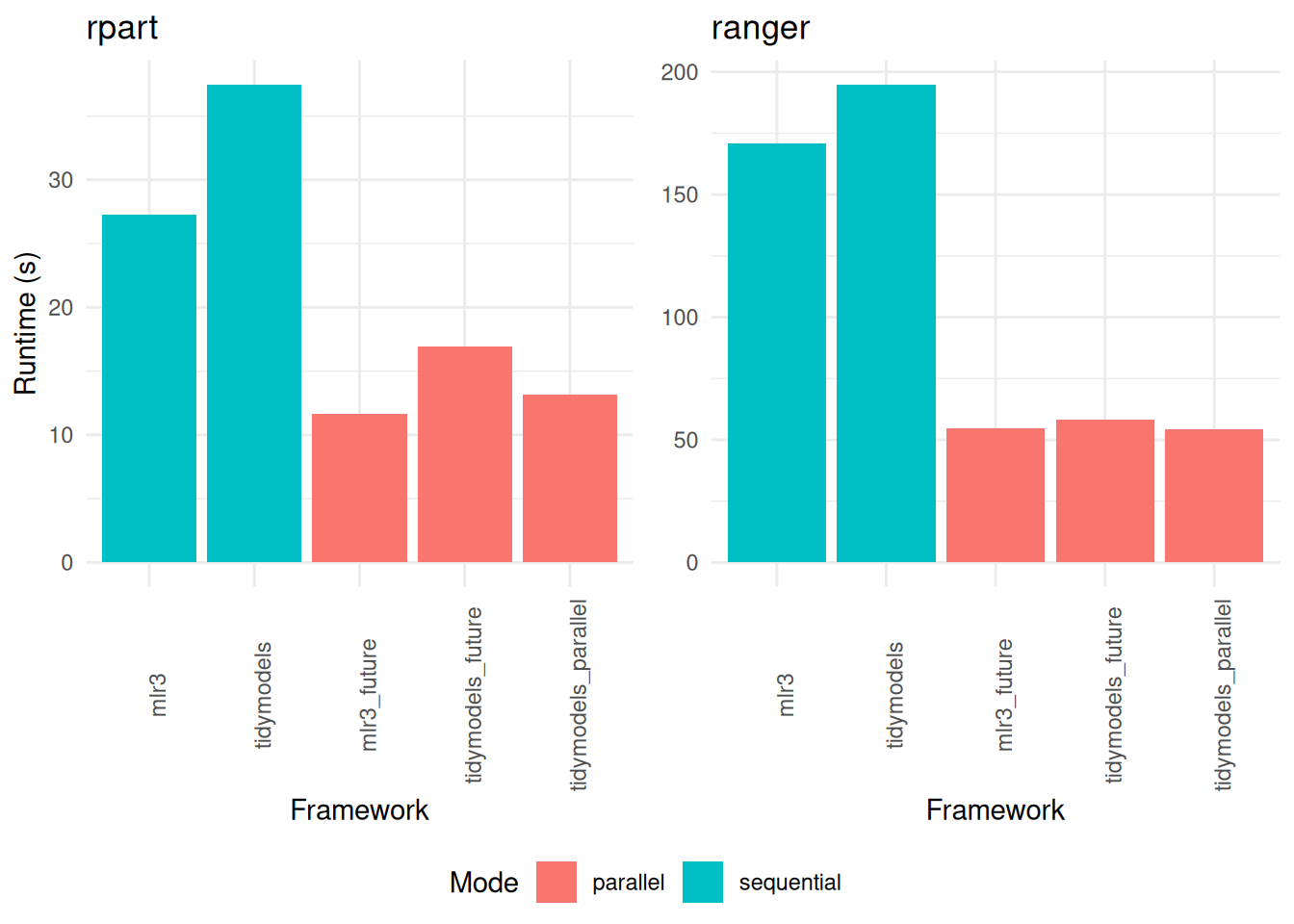 +
+rpart (displayed on the left) and ranger (on the right). The comparison encompasses variations across different frameworks and the implementation of parallelization.
+Our analysis reveals that both tidymodels and mlr3 exhibit comparable runtimes across key processes such as training, resampling, and tuning, each displaying its own set of strengths and efficiencies.
A notable observation is the relative overhead associated with using either framework, particularly when working with fast-fitting models like rpart. In these cases, the additional processing time introduced by the frameworks is more pronounced due to the inherently short training time of rpart models. This results in a higher relative overhead, reflecting the trade-offs between the convenience of a comprehensive framework and the directness of more basic approaches.
Conversely, when dealing with slower-fitting models such as ranger, the scenario shifts. For these more time-intensive models, the relative overhead introduced by the frameworks diminishes significantly. In such instances, the extended training times of the models absorb much of the frameworks’ inherent overhead, rendering it relatively negligible.
In summary, while there is no outright winner in terms of overall performance, the decision to use tidymodels or mlr3 should be informed by the specific requirements of the task at hand.
Here are some interesting reads regarding BART:
+BART R package tutorial (R. Sparapani, Spanbauer, and McCulloch 2021)We incorporated the survival BART model in mlr3extralearners and in this tutorial we will demonstrate how we can use packages like mlr3, mlr3proba and distr6 to more easily manipulate the output predictions to assess model convergence, validate our model (via several survival metrics), as well as perform model interpretation via PDPs (Partial Dependence Plots).
library(mlr3extralearners)
+library(mlr3pipelines)
+library(mlr3proba)
+library(distr6)
+library(BART) # 2.9.4
+library(dplyr)
+library(tidyr)
+library(tibble)
+library(ggplot2)We will use the Lung Cancer Dataset. We convert the time variable from days to months to ease the computational burden:
task_lung = tsk('lung')
+
+d = task_lung$data()
+# in case we want to select specific columns to keep
+# d = d[ ,colnames(d) %in% c("time", "status", "age", "sex", "ph.karno"), with = FALSE]
+d$time = ceiling(d$time/30.44)
+task_lung = as_task_surv(d, time = 'time', event = 'status', id = 'lung')
+task_lung$label = "Lung Cancer"BART implementation supports categorical features (factors). This results in different importance scores per each dummy level which doesn’t work well with mlr3. So features of type factor or character are not allowed and we leave it to the user to encode them as they please.BART implementation supports features with missing values. This is totally fine with mlr3 as well! In this example, we impute the features to show good ML practice.In our lung dataset, we encode the sex feature and perform model-based imputation with the rpart regression learner:
po_encode = po('encode', method = 'treatment')
+po_impute = po('imputelearner', lrn('regr.rpart'))
+pre = po_encode %>>% po_impute
+task = pre$train(task_lung)[[1]]
+task<TaskSurv:lung> (228 x 10): Lung Cancer
+* Target: time, status
+* Properties: -
+* Features (8):
+ - int (7): age, inst, meal.cal, pat.karno, ph.ecog, ph.karno, wt.loss
+ - dbl (1): sexNo missing values in our data:
+task$missings() time status age sex inst meal.cal pat.karno ph.ecog ph.karno wt.loss
+ 0 0 0 0 0 0 0 0 0 0 We partition the data to train and test sets:
+set.seed(42)
+part = partition(task, ratio = 0.9)We train the BART model and predict on the test set:
# default `ndpost` value: 1000. We reduce it to 50 to speed up calculations in this tutorial
+learner = lrn("surv.bart", nskip = 250, ndpost = 50, keepevery = 10, mc.cores = 10)
+learner$train(task, row_ids = part$train)
+p = learner$predict(task, row_ids = part$test)
+p<PredictionSurv> for 23 observations:
+ row_ids time status crank distr
+ 9 8 TRUE 66.19326 <list[1]>
+ 10 6 TRUE 98.43005 <list[1]>
+ 21 10 TRUE 54.82313 <list[1]>
+---
+ 160 13 FALSE 37.82089 <list[1]>
+ 163 10 FALSE 69.63534 <list[1]>
+ 194 8 FALSE 81.13678 <list[1]>See more details about BART’s parameters on the online documentation.
What kind of object is the predicted distr?
p$distrArrdist(23x31x50) Actually the $distr is an active R6 field - this means that some computation is required to create it. What the prediction object actually stores internally is a 3d survival array (can be used directly with no performance overhead):
dim(p$data$distr)[1] 23 31 50This is a more easy-to-understand and manipulate form of the full posterior survival matrix prediction from the BART package ((R. Sparapani, Spanbauer, and McCulloch 2021), pages 34-35).
Though we have optimized with C++ code the way the Arrdist object is constructed, calling the $distr field can be computationally taxing if the product of the sizes of the 3 dimensions above exceeds ~1 million. In our case, so the conversion to an
Arrdist via $distr will certainly not create performance issues.
An example using the internal prediction data: get all the posterior probabilities of the 3rd patient in the test set, at 12 months (1 year):
+p$data$distr[3, 12, ] [1] 0.26546909 0.27505937 0.21151435 0.46700513 0.26178380 0.24040003 0.29946469 0.52357780 0.40833108 0.40367780
+[11] 0.27027392 0.31781286 0.54151844 0.34460027 0.41826554 0.41866367 0.33694401 0.34511270 0.47244492 0.49423660
+[21] 0.42069678 0.20095489 0.48696980 0.48409357 0.35649439 0.47969355 0.16355660 0.33728105 0.40245228 0.42418033
+[31] 0.36336145 0.48181667 0.51858238 0.49635078 0.37238179 0.26694030 0.52219952 0.48992897 0.08572207 0.30306005
+[41] 0.33881682 0.33463870 0.29102074 0.43176131 0.38554545 0.38053756 0.36808776 0.13772665 0.21898264 0.14552514Working with the $distr interface and Arrdist objects is very efficient as we will see later for predicting survival estimates.
In survival analysis, , where
the survival function and
the cumulative distribution function (cdf). The latter can be interpreted as
risk or probability of death up to time .
We can verify the above from the prediction object:
+surv_array = 1 - distr6::gprm(p$distr, "cdf") # 3d array
+testthat::expect_equal(p$data$distr, surv_array)crank is the expected mortality (Sonabend, Bender, and Vollmer 2022) which is the sum of the predicted cumulative hazard function (as is done in random survival forest models). Higher values denote larger risk. To calculate crank, we need a survival matrix. So we have to choose which 3rd dimension we should use from the predicted survival array. This is what the which.curve parameter of the learner does:
learner$param_set$get_values()$which.curve[1] 0.5The default value ( quantile) is the median survival probability. It could be any other quantile (e.g.
). Other possible values for
which.curve are mean or a number denoting the exact posterior draw to extract (e.g. the last one, which.curve = 50).
Default score is the observed count of each feature in the trees (so the higher the score, the more important the feature):
+learner$param_set$values$importance[1] "count"learner$importance() sex meal.cal inst pat.karno ph.karno wt.loss age ph.ecog
+ 7.84 7.46 7.08 6.76 6.60 6.46 5.48 5.42 BART uses internally MCMC (Markov Chain Monte Carlo) to sample from the posterior survival distribution. We need to check that MCMC has converged, meaning that the chains have reached a stationary distribution that approximates the true posterior survival distribution (otherwise the predictions may be inaccurate, misleading and unreliable).
We use Geweke’s convergence diagnostic test as it is implemented in the BART R package. We choose 10 random patients from the train set to evaluate the MCMC convergence.
# predictions on the train set
+p_train = learner$predict(task, row_ids = part$train)
+
+# choose 10 patients from the train set randomly and make a list
+ids = as.list(sample(length(part$train), 10))
+
+z_list = lapply(ids, function(id) {
+ # matrix with columns => time points and rows => posterior draws
+ post_surv = 1 - t(distr6::gprm(p_train$distr[id], "cdf")[1,,])
+ BART::gewekediag(post_surv)$z # get the z-scores
+})
+
+# plot the z scores vs time for all patients
+dplyr::bind_rows(z_list) %>%
+ tidyr::pivot_longer(cols = everything()) %>%
+ mutate(name = as.numeric(name)) %>%
+ ggplot(aes(x = name, y = value)) +
+ geom_point() +
+ labs(x = "Time (months)", y = "Z-scores") +
+ # add critical values for a = 0.05
+ geom_hline(yintercept = 1.96, linetype = 'dashed', color = "red") +
+ geom_hline(yintercept = -1.96, linetype = 'dashed', color = "red") +
+ theme_bw(base_size = 14)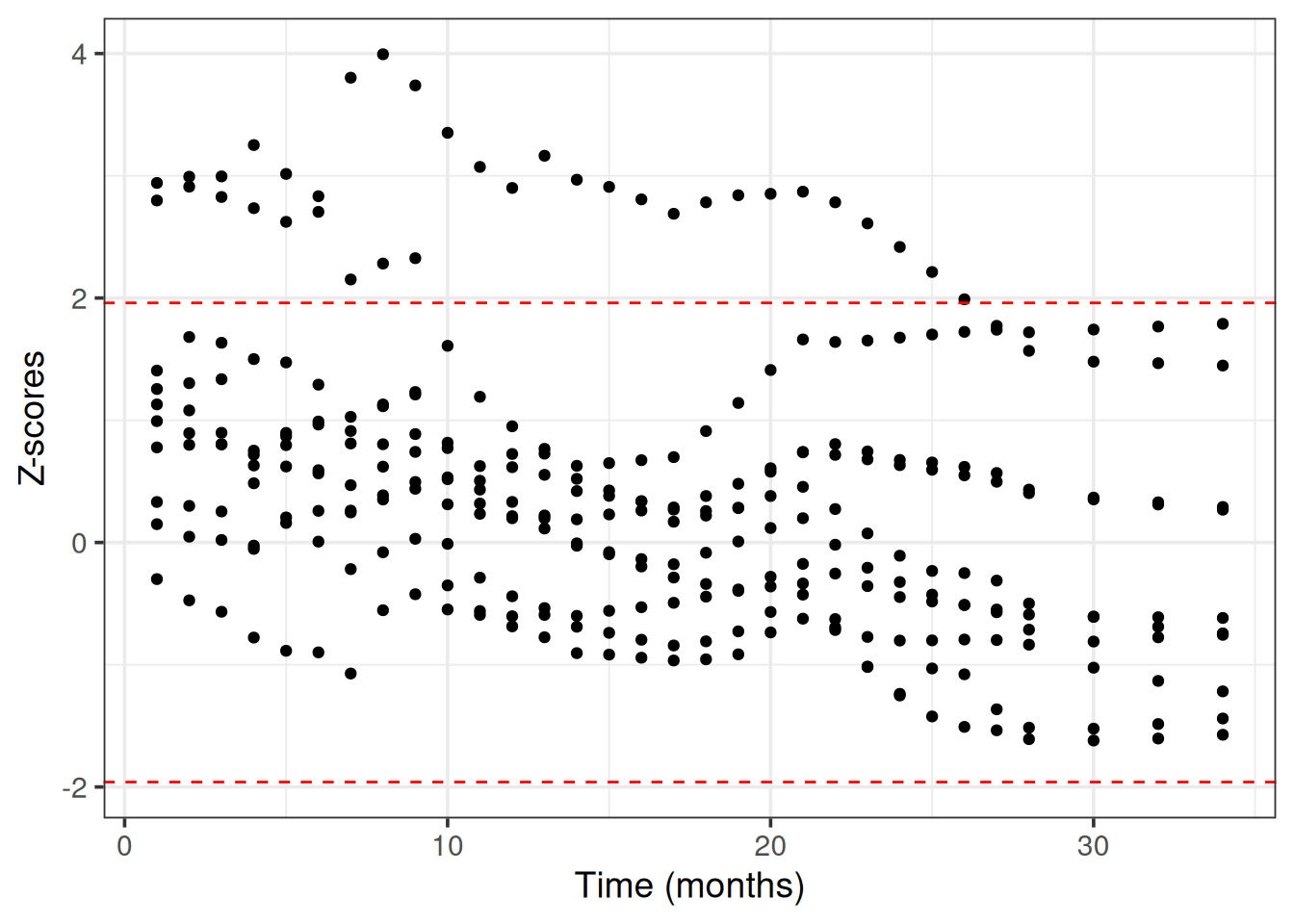
We will use the following survival metrics:
+distr)crank)For the first measure we will use the ERV (Explained Residual Variation) version, which standardizes the score against a Kaplan-Meier (KM) baseline (Sonabend et al. 2022). This means that values close to represent performance similar to a KM model, negative values denote worse performance than KM and
is the absolute best possible score.
measures = list(
+ msr("surv.graf", ERV = TRUE),
+ msr("surv.cindex", weight_meth = "G2", id = "surv.cindex.uno")
+)
+
+for (measure in measures) {
+ print(p$score(measure, task = task, train_set = part$train))
+} surv.graf
+-0.09950096
+surv.cindex.uno
+ 0.551951 All metrics use by default the median survival distribution from the 3d array, no matter what is the which.curve argument during the learner’s construction.
Performing resampling with the BART learner is very easy using mlr3.
We first stratify the data by status, so that in each resampling the proportion of censored vs un-censored patients remains the same:
task$col_roles$stratum = 'status'
+task$strata N row_id
+1: 165 1,2,4,5,7,8,...
+2: 63 3, 6,38,68,71,83,...rr = resample(task, learner, resampling = rsmp("cv", folds = 5), store_backends = TRUE)INFO [17:07:04.946] [mlr3] Applying learner 'surv.bart' on task 'lung' (iter 1/5)
+INFO [17:07:07.647] [mlr3] Applying learner 'surv.bart' on task 'lung' (iter 2/5)
+INFO [17:07:10.708] [mlr3] Applying learner 'surv.bart' on task 'lung' (iter 3/5)
+INFO [17:07:13.382] [mlr3] Applying learner 'surv.bart' on task 'lung' (iter 4/5)
+INFO [17:07:16.361] [mlr3] Applying learner 'surv.bart' on task 'lung' (iter 5/5)No errors or warnings:
+rr$errorsEmpty data.table (0 rows and 2 cols): iteration,msgrr$warningsEmpty data.table (0 rows and 2 cols): iteration,msgPerformance in each fold:
+rr$score(measures) task_id learner_id resampling_id iteration surv.graf surv.cindex.uno
+1: lung surv.bart cv 1 -0.312614598 0.5869665
+2: lung surv.bart cv 2 -0.103181391 0.5502903
+3: lung surv.bart cv 3 0.001448263 0.6178001
+4: lung surv.bart cv 4 -0.044161171 0.6157215
+5: lung surv.bart cv 5 -0.043129352 0.5688389
+Hidden columns: task, learner, resampling, predictionMean cross-validation performance:
+rr$aggregate(measures) surv.graf surv.cindex.uno
+ -0.1003276 0.5879235 We will choose two patients from the test set and plot their survival prediction posterior estimates.
+Let’s choose the patients with the worst and the best survival time:
+death_times = p$truth[,1]
+sort(death_times) [1] 3 5 5 6 6 6 7 8 8 8 8 10 10 10 12 12 12 13 15 16 17 18 27worst_indx = which(death_times == min(death_times))[1] # died first
+best_indx = which(death_times == max(death_times))[1] # died last
+
+patient_ids = c(worst_indx, best_indx)
+patient_ids # which patient IDs[1] 5 18death_times = death_times[patient_ids]
+death_times # 1st is worst, 2nd is best[1] 3 27Subset Arrdist to only the above 2 patients:
arrd = p$distr[patient_ids]
+arrdArrdist(2x31x50) We choose time points (in months) for the survival estimates:
+months = seq(1, 36) # 1 month - 3 yearsWe use the $distr interface and the $survival property to get survival probabilities from an Arrdist object as well as the quantile credible intervals (CIs). The median survival probabilities can be extracted as follows:
med = arrd$survival(months) # 'med' for median
+
+colnames(med) = paste0(patient_ids, "_med")
+med = as_tibble(med) %>% add_column(month = months)
+head(med)# A tibble: 6 × 3
+ `5_med` `18_med` month
+ <dbl> <dbl> <int>
+1 0.874 0.981 1
+2 0.767 0.962 2
+3 0.670 0.945 3
+4 0.569 0.927 4
+5 0.465 0.901 5
+6 0.366 0.869 6We can briefly verify model’s predictions: 1st patient survival probabilities on any month are lower (worst) compared to the 2nd patient.
+Note that subsetting an Arrdist (3d array) creates a Matdist (2d matrix), for example we can explicitly get the median survival probabilities:
matd_median = arrd[, 0.5] # median
+head(matd_median$survival(months)) # same as with `arrd` [,1] [,2]
+1 0.8741127 0.9808363
+2 0.7670382 0.9621618
+3 0.6701276 0.9450867
+4 0.5688809 0.9272284
+5 0.4647686 0.9007042
+6 0.3660939 0.8687270Using the mean posterior survival probabilities or the ones from the last posterior draw is also possible and can be done as follows:
matd_mean = arrd[, "mean"] # mean (if needed)
+head(matd_mean$survival(months)) [,1] [,2]
+1 0.8652006 0.9748463
+2 0.7533538 0.9521817
+3 0.6560050 0.9293229
+4 0.5623555 0.9051549
+5 0.4750038 0.8758896
+6 0.3815333 0.8360373matd_50draw = arrd[, 50] # the 50th posterior draw
+head(matd_50draw$survival(months)) [,1] [,2]
+1 0.9178342 0.9920982
+2 0.8424195 0.9842589
+3 0.7732014 0.9764815
+4 0.7096707 0.9687656
+5 0.6029119 0.9495583
+6 0.5122132 0.9307318To get the CIs we will subset the Arrdist using a quantile number (0-1), which extracts a Matdist based on the cdf. The survival function is 1 - cdf, so low and upper bounds are reversed:
low = arrd[, 0.975]$survival(months) # 2.5% bound
+high = arrd[, 0.025]$survival(months) # 97.5% bound
+colnames(low) = paste0(patient_ids, "_low")
+colnames(high) = paste0(patient_ids, "_high")
+low = as_tibble(low)
+high = as_tibble(high)The median posterior survival probabilities for the two patient of interest and the corresponding CI bounds in a tidy format are:
+surv_tbl =
+ bind_cols(low, med, high) %>%
+ pivot_longer(cols = !month, values_to = "surv",
+ names_to = c("patient_id", ".value"), names_sep = "_") %>%
+ relocate(patient_id)
+surv_tbl# A tibble: 72 × 5
+ patient_id month low med high
+ <chr> <int> <dbl> <dbl> <dbl>
+ 1 5 1 0.713 0.874 0.953
+ 2 18 1 0.929 0.981 0.996
+ 3 5 2 0.508 0.767 0.903
+ 4 18 2 0.863 0.962 0.991
+ 5 5 3 0.362 0.670 0.855
+ 6 18 3 0.801 0.945 0.985
+ 7 5 4 0.244 0.569 0.804
+ 8 18 4 0.734 0.927 0.977
+ 9 5 5 0.146 0.465 0.748
+10 18 5 0.654 0.901 0.969
+# ℹ 62 more rowsWe draw survival curves with the uncertainty for the survival probability quantified:
+my_colors = c("#E41A1C", "#4DAF4A")
+names(my_colors) = patient_ids
+
+surv_tbl %>%
+ ggplot(aes(x = month, y = med)) +
+ geom_step(aes(color = patient_id), linewidth = 1) +
+ xlab('Time (Months)') +
+ ylab('Survival Probability') +
+ geom_ribbon(aes(ymin = low, ymax = high, fill = patient_id),
+ alpha = 0.3, show.legend = F) +
+ geom_vline(xintercept = death_times[1], linetype = 'dashed', color = my_colors[1]) +
+ geom_vline(xintercept = death_times[2], linetype = 'dashed', color = my_colors[2]) +
+ theme_bw(base_size = 14) +
+ scale_color_manual(values = my_colors) +
+ scale_fill_manual(values = my_colors) +
+ guides(color = guide_legend(title = "Patient ID"))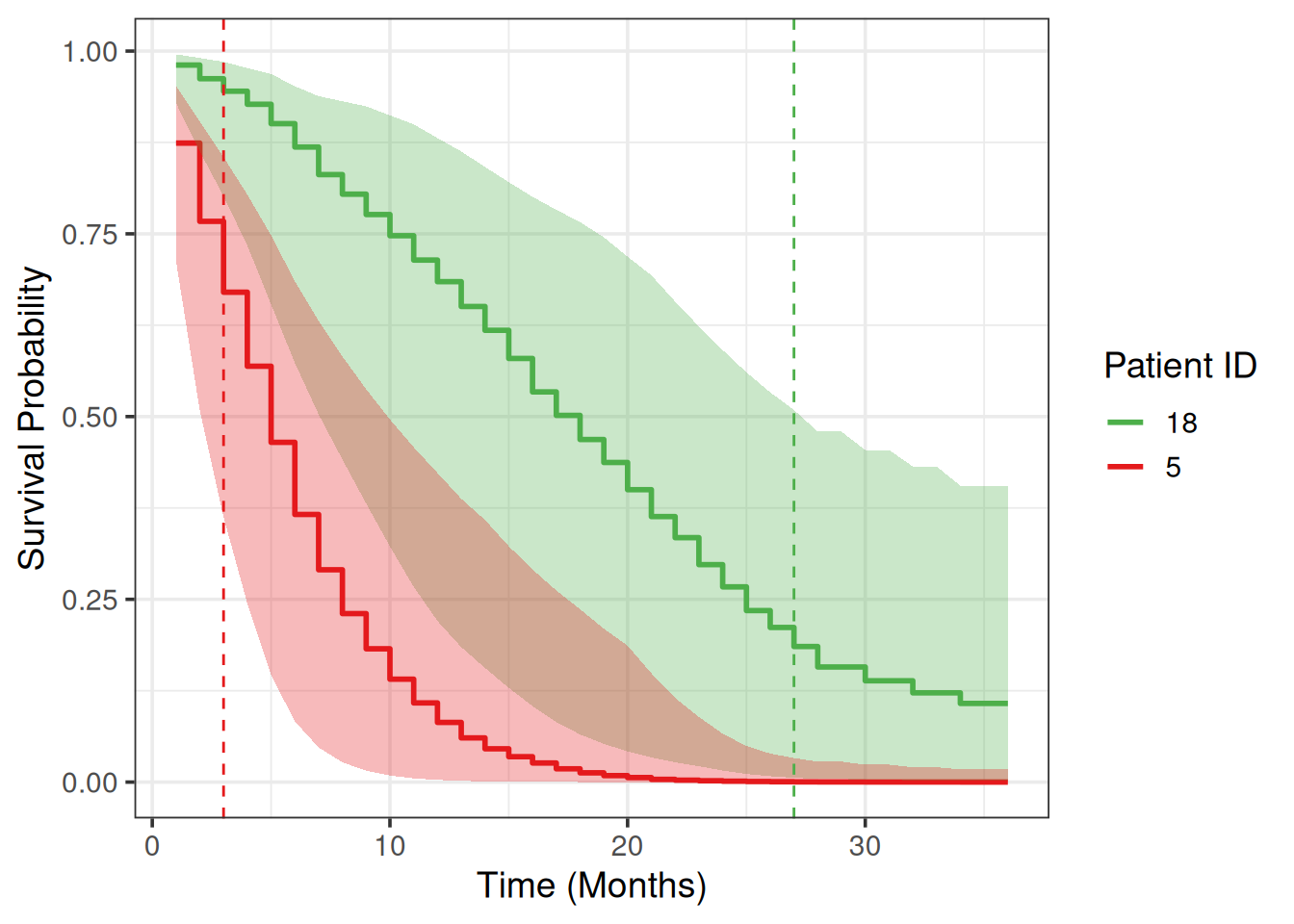
We will use a Partial Dependence Plot (PDP) (Friedman 2001) to visualize how much different are males vs females in terms of their average survival predictions across time.
+PDPs assume that features are independent. In our case we need to check that sex doesn’t correlate with any of the other features used for training the BART learner. Since sex is a categorical feature, we fit a linear model using as target variable every other feature in the data () and conduct an ANOVA (ANalysis Of VAriance) to get the variance explained or
. The square root of that value is the correlation measure we want.
# code from https://christophm.github.io/interpretable-ml-book/ale.html
+mycor = function(cnames, data) {
+ x.num = data[, cnames[1], with = FALSE][[1]]
+ x.cat = data[, cnames[2], with = FALSE][[1]]
+ # R^2 = Cor(X, Y)^2 in simple linear regression
+ sqrt(summary(lm(x.num ~ x.cat))$r.squared)
+}
+
+cnames = c("sex")
+combs = expand.grid(y = setdiff(colnames(d), "sex"), x = cnames)
+combs$cor = apply(combs, 1, mycor, data = task$data()) # use the train set
+combs y x cor
+1 time sex 0.12941337
+2 status sex 0.24343282
+3 age sex 0.12216709
+4 inst sex 0.07826337
+5 meal.cal sex 0.18389545
+6 pat.karno sex 0.04132443
+7 ph.ecog sex 0.02564987
+8 ph.karno sex 0.01702471
+9 wt.loss sex 0.13431983sex doesn’t correlate strongly with any other feature, so we can compute the PDP:
# create two datasets: one with males and one with females
+# all other features remain the same (use train data, 205 patients)
+d = task$data(rows = part$train) # `rows = part$test` to use the test set
+
+d$sex = 1
+task_males = as_task_surv(d, time = 'time', event = 'status', id = 'lung-males')
+d$sex = 0
+task_females = as_task_surv(d, time = 'time', event = 'status', id = 'lung-females')
+
+# make predictions
+p_males = learner$predict(task_males)
+p_females = learner$predict(task_females)
+
+# take the median posterior survival probability
+surv_males = p_males$distr$survival(months) # patients x times
+surv_females = p_females$distr$survival(months) # patients x times
+
+# tidy up data: average and quantiles across patients
+data_males =
+ apply(surv_males, 1, function(row) {
+ tibble(
+ low = quantile(row, probs = 0.025),
+ avg = mean(row),
+ high = quantile(row, probs = 0.975)
+ )
+ }) %>%
+ bind_rows() %>%
+ add_column(sex = 'male', month = months, .before = 1)
+
+data_females =
+ apply(surv_females, 1, function(row) {
+ tibble(
+ low = quantile(row, probs = 0.025),
+ avg = mean(row),
+ high = quantile(row, probs = 0.975)
+ )
+ }) %>%
+ bind_rows() %>%
+ add_column(sex = 'female', month = months, .before = 1)
+
+pdp_tbl = bind_rows(data_males, data_females)
+pdp_tbl# A tibble: 72 × 5
+ sex month low avg high
+ <chr> <int> <dbl> <dbl> <dbl>
+ 1 male 1 0.836 0.942 0.981
+ 2 male 2 0.704 0.889 0.963
+ 3 male 3 0.587 0.839 0.943
+ 4 male 4 0.488 0.788 0.924
+ 5 male 5 0.392 0.732 0.897
+ 6 male 6 0.304 0.663 0.860
+ 7 male 7 0.234 0.601 0.829
+ 8 male 8 0.172 0.550 0.799
+ 9 male 9 0.130 0.503 0.766
+10 male 10 0.0945 0.455 0.733
+# ℹ 62 more rowsmy_colors = c("#E41A1C", "#4DAF4A")
+names(my_colors) = c('male', 'female')
+
+pdp_tbl %>%
+ ggplot(aes(x = month, y = avg)) +
+ geom_step(aes(color = sex), linewidth = 1) +
+ xlab('Time (Months)') +
+ ylab('Survival Probability') +
+ geom_ribbon(aes(ymin = low, ymax = high, fill = sex), alpha = 0.2, show.legend = F) +
+ theme_bw(base_size = 14) +
+ scale_color_manual(values = my_colors) +
+ scale_fill_manual(values = my_colors)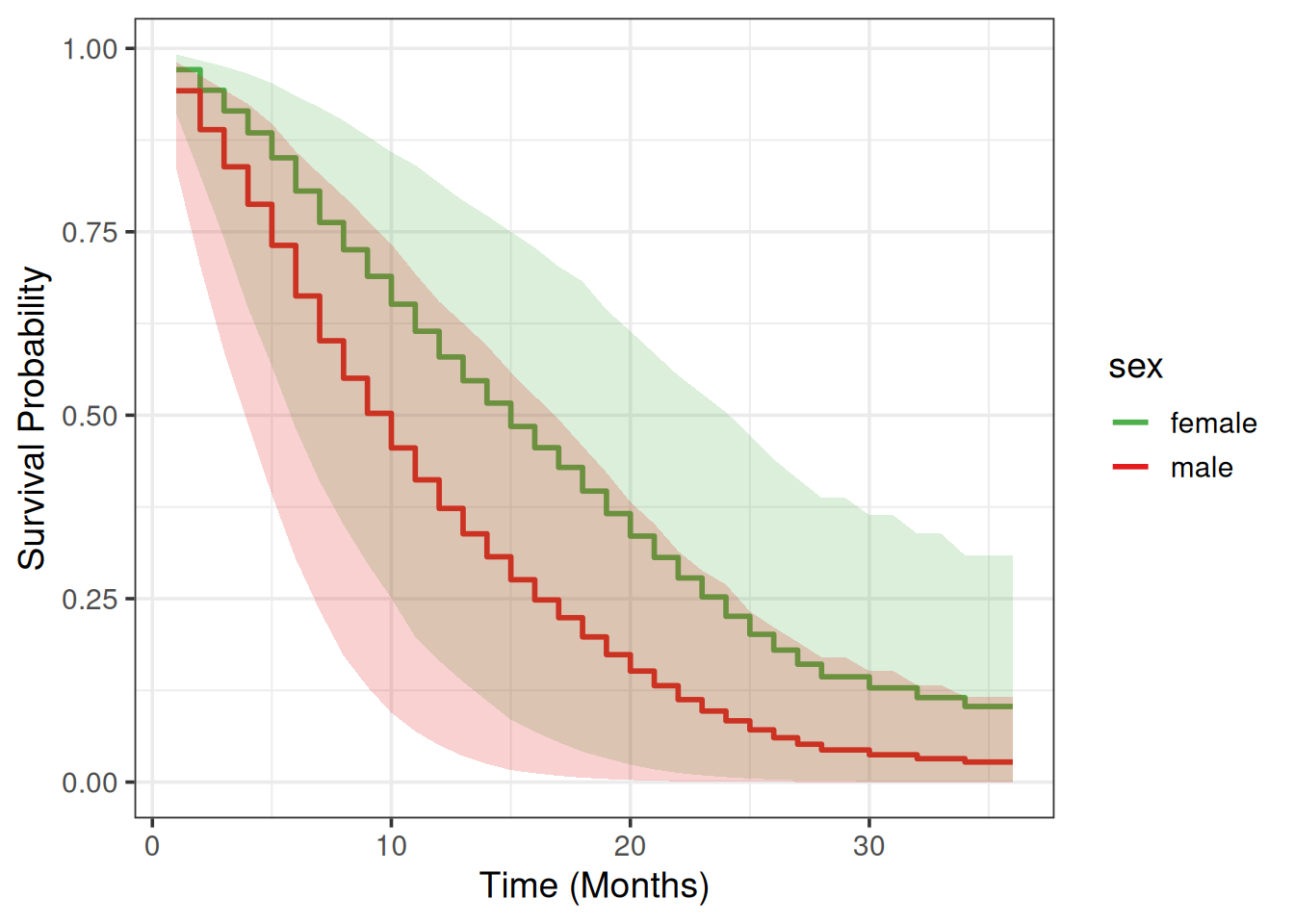
Working with spatial data in R requires a lot of data wrangling e.g. reading from different file formats, converting between spatial formats, creating tables from point layers, and predicting spatial raster images. The goal of mlr3spatial is to simplify these workflows within the mlr3 ecosystem. As a practical example, we will perform a land cover classification for the city of Leipzig, Germany. Figure 1 illustrates the typical workflow for this type of task: Load the training data, create a spatial task, train a learner with it, and predict the final raster image.
+%%{ init: { 'flowchart': { 'curve': 'bump' } } }%%
+
+flowchart LR
+ subgraph files[Files]
+ vector[Vector]
+ raster[Raster]
+ end
+ subgraph load[Load Data]
+ sf
+ terra
+ end
+ vector --> sf
+ raster --> terra
+ subgraph train_model[Train Model]
+ task[Task]
+ learner[Learner]
+ end
+ terra --> prediction_raster
+ task --> learner
+ sf --> task
+ subgraph predict[Spatial Prediction]
+ prediction_raster[Raster Image]
+ end
+ learner --> prediction_raster
+
+We assume that you are familiar with the mlr3 ecosystem and know the basic concepts of remote sensing. If not, we recommend reading the mlr3book first. If you are interested in spatial resampling, check out the book chapter on spatial analysis.
+ +Land cover is the physical material or vegetation that covers the surface of the earth, including both natural and human-made features. Understanding land cover patterns and changes over time is critical for addressing global environmental challenges, such as climate change, land degradation, and loss of biodiversity. Land cover classification is the process of assigning land cover classes to pixels in a raster image. With mlr3spatial, we can easily perform a land cover classification within the mlr3 ecosystem.
+Before we can start the land cover classification, we need to load the necessary packages. The mlr3spatial package relies on terra for processing raster data and sf for vector data. These widely used packages read all common raster and vector formats. Additionally, the stars and raster packages are supported.
+library(mlr3verse)
+library(mlr3spatial)
+library(terra, exclude = "resample")
+library(sf)We will work with a Sentinel-2 scene of the city of Leipzig which consists of 7 bands with a 10 or 20m spatial resolution and an NDVI band. The data is included in the mlr3spatial package. We use the terra::rast() to load the TIFF raster file.
leipzig_raster = rast(system.file("extdata", "leipzig_raster.tif", package = "mlr3spatial"))
+leipzig_rasterclass : SpatRaster
+dimensions : 206, 154, 8 (nrow, ncol, nlyr)
+resolution : 10, 10 (x, y)
+extent : 731810, 733350, 5692030, 5694090 (xmin, xmax, ymin, ymax)
+coord. ref. : WGS 84 / UTM zone 32N (EPSG:32632)
+source : leipzig_raster.tif
+names : b02, b03, b04, b06, b07, b08, ...
+min values : 846, 645, 366, 375, 401, 374, ...
+max values : 4705, 4880, 5451, 4330, 5162, 5749, ... The training data is a GeoPackage point layer with land cover labels and spectral features. We load the file and create a simple feature point layer.
leipzig_vector = read_sf(system.file("extdata", "leipzig_points.gpkg", package = "mlr3spatial"), stringsAsFactors = TRUE)
+leipzig_vectorSimple feature collection with 97 features and 9 fields
+Geometry type: POINT
+Dimension: XY
+Bounding box: xmin: 731930.5 ymin: 5692136 xmax: 733220.3 ymax: 5693968
+Projected CRS: WGS 84 / UTM zone 32N
+# A tibble: 97 × 10
+ b02 b03 b04 b06 b07 b08 b11 ndvi land_cover geom
+ <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <POINT [m]>
+ 1 903 772 426 2998 4240 4029 1816 0.809 forest (732480.1 5693957)
+ 2 1270 1256 1081 1998 2493 2957 2073 0.465 urban (732217.4 5692769)
+ 3 1033 996 777 2117 2748 2799 1595 0.565 urban (732737.2 5692469)
+ 4 962 773 500 465 505 396 153 -0.116 water (733169.3 5692777)
+ 5 1576 1527 1626 1715 1745 1768 1980 0.0418 urban (732202.2 5692644)
+ 6 1125 1185 920 3058 3818 3758 2682 0.607 pasture (732153 5693059)
+ 7 880 746 424 2502 3500 3397 1469 0.778 forest (731937.9 5693722)
+ 8 1332 1251 1385 1663 1799 1640 1910 0.0843 urban (732416.2 5692324)
+ 9 940 741 475 452 515 400 139 -0.0857 water (732933.7 5693344)
+10 902 802 454 2764 3821 3666 1567 0.780 forest (732411.3 5693352)
+# ℹ 87 more rowsWe plot both layers to get an overview of the data. The training points are located in the districts of Lindenau and Zentrum West.
+library(ggplot2)
+library(tidyterra, exclude = "filter")
+
+ggplot() +
+ geom_spatraster_rgb(data = leipzig_raster, r = 3, g = 2, b = 1, max_col_value = 5451) +
+ geom_spatvector(data = leipzig_vector, aes(color = land_cover)) +
+ scale_color_viridis_d(name = "Land cover", labels = c("Forest", "Pastures", "Urban", "Water")) +
+ theme_minimal()
The as_task_classif_st() function directly creates a spatial task from the point layer. This makes it unnecessary to transform the point layer to a data.frame with coordinates. Spatial tasks additionally store the coordinates of the training points. The coordinates are useful when estimating the performance of the model with spatial resampling.
task = as_task_classif_st(leipzig_vector, target = "land_cover")
+task<TaskClassifST:leipzig_vector> (97 x 9)
+* Target: land_cover
+* Properties: multiclass
+* Features (8):
+ - dbl (8): b02, b03, b04, b06, b07, b08, b11, ndvi
+* Coordinates:
+ X Y
+ 1: 732480.1 5693957
+ 2: 732217.4 5692769
+ 3: 732737.2 5692469
+ 4: 733169.3 5692777
+ 5: 732202.2 5692644
+---
+93: 733018.7 5692342
+94: 732551.4 5692887
+95: 732520.4 5692589
+96: 732542.2 5692204
+97: 732437.8 5692300Now we can train a model with the task. We use a simple decision tree learner from the rpart package. The "classif_st" task is a specialization of the "classif" task and therefore works with all "classif" learners.
learner = lrn("classif.rpart")
+learner$train(task)To get a complete land cover classification of Leipzig, we have to predict on each pixel and return a raster image with these predictions. The $predict() method of the learner only works for tabular data. To predict a raster image, we use the predict_spatial() function.
# predict land cover map
+land_cover = predict_spatial(leipzig_raster, learner)ggplot() +
+ geom_spatraster(data = land_cover) +
+ scale_fill_viridis_d(name = "Land cover", labels = c("Forest", "Pastures", "Urban", "Water")) +
+ theme_minimal()
Working with spatial data in R is very easy with the mlr3spatial package. You can quickly train a model with a point layer and predict a raster image. The mlr3spatial package is still in development and we are looking forward to your feedback and contributions.
+ + +Feature selection is the process of finding an optimal subset of features in order to improve the performance, interpretability and robustness of machine learning algorithms. In this article, we introduce the wrapper feature selection method Recursive Feature Elimination. Wrapper methods iteratively select features that optimize a performance measure. As an example, we will search for the optimal set of features for a gradient boosting machine and support vector machine on the Sonar data set. We assume that you are already familiar with the basic building blocks of the mlr3 ecosystem. If you are new to feature selection, we recommend reading the feature selection chapter of the mlr3book first.
Recursive Feature Elimination (RFE) is a widely used feature selection method for high-dimensional data sets. The idea is to iteratively remove the least predictive feature from a model until the desired number of features is reached. This feature is determined by the built-in feature importance method of the model. Currently, RFE works with support vector machines (SVM), decision tree algorithms and gradient boosting machines (GBM). Supported learners are tagged with the "importance" property. For a full list of supported learners, see the learner page on the mlr-org website and search for "importance".
Guyon et al. (2002) developed the RFE algorithm for SVMs (SVM-RFE) to select informative genes in cancer classification. The importance of the features is given by the weight vector of a linear support vector machine. This method was later extended to other machine learning algorithms. The only requirement is that the models can internally measure the feature importance. The random forest algorithm offers multiple options for measuring feature importance. The commonly used methods are the mean decrease in accuracy (MDA) and the mean decrease in impurity (MDI). The MDA measures the decrease in accuracy for a feature if it was randomly permuted in the out-of-bag sample. The MDI is the total reduction in node impurity when the feature is used for splitting. Gradient boosting algorithms like XGBoost, LightGBM and GBM use similar methods to measure the importance of the features.
Resampling strategies can be combined with the algorithm in different ways. The frameworks scikit-learn (Pedregosa et al. 2011) and caret (Kuhn 2008) implement a variant called recursive feature elimination with cross-validation (RFE-CV) that estimates the optimal number of features with cross-validation first. Then one more RFE is carried out on the complete dataset with the optimal number of features as the final feature set size. The RFE implementation in mlr3 can rank and aggregate importance scores across resampling iterations. We will explore both variants in more detail below.
+mlr3fselect is the feature selection package of the mlr3 ecosystem. It implements the RFE and RFE-CV algorithm. We load all packages of the ecosystem with the mlr3verse package.
library(mlr3verse)We retrieve the RFE optimizer with the fs() function.
optimizer = fs("rfe",
+ n_features = 1,
+ feature_number = 1,
+ aggregation = "rank")The algorithm has multiple control parameters. The optimizer stops when the number of features equals n_features. The parameters feature_number, feature_fraction and subset_size determine the number of features that are removed in each iteration. The feature_number option removes a fixed number of features in each iteration, whereas feature_fraction removes a fraction of the features. The subset_size argument is a vector that specifies exactly how many features are removed in each iteration. The parameters are mutually exclusive and the default is feature_fraction = 0.5. Usually, RFE fits a new model in each resampling iteration and calculates the feature importance again. We can deactivate this behavior by setting recursive = FALSE. The selection of feature subsets in all iterations is then based solely on the importance scores of the first model trained with all features. When running an RFE with a resampling strategy like cross-validation, multiple models and importance scores are generated. The aggregation parameter determines how the importance scores are aggregated. The option "rank" ranks the importance scores in each iteration and then averages the ranks of the features. The feature with the lowest average rank is removed. The option "mean" averages the importance scores of the features across the iterations. The "mean" should only be used if the learner’s importance scores can be reasonably averaged.
The objective of the Sonar data set is to predict whether a sonar signal bounced off a metal cylinder or a rock. The data set includes 60 numerical features (see Figure 1).
task = tsk("sonar")library(ggplot2)
+library(data.table)
+
+data = melt(as.data.table(task), id.vars = task$target_names, measure.vars = task$feature_names)
+data = data[c("V1", "V10", "V11", "V12", "V13", "V14"), , on = "variable"]
+
+ggplot(data, aes(x = value, fill = Class)) +
+ geom_density(alpha = 0.5) +
+ facet_wrap(~ variable, ncol = 6, scales = "free") +
+ scale_fill_viridis_d(end = 0.8) +
+ theme_minimal() +
+ theme(axis.title.x = element_blank())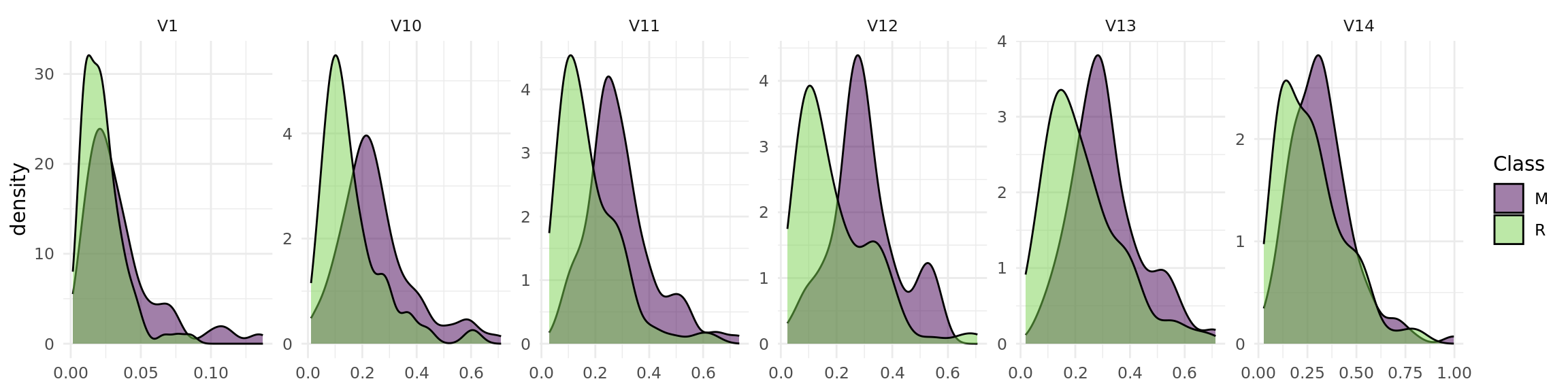 +
+We start with the GBM learner and set the predict type to "prob" to obtain class probabilities.
learner = lrn("classif.gbm",
+ distribution = "bernoulli",
+ predict_type = "prob")Now we define the feature selection problem by using the fsi() function that constructs an FSelectInstanceSingleCrit. In addition to the task and learner, we have to select a resampling strategy and performance measure to determine how the performance of a feature subset is evaluated. We pass the "none" terminator because the n_features parameter of the optimizer determines when the feature selection stops.
instance = fsi(
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 6),
+ measures = msr("classif.auc"),
+ terminator = trm("none"))We are now ready to start the RFE. To do this, we simply pass the instance to the $optimize() method of the optimizer.
optimizer$optimize(instance)The optimizer saves the best feature set and the corresponding estimated performance in instance$result.
Figure 2 shows the optimization path of the feature selection. We observe that the performance increases first as the number of features decreases. As soon as informative features are removed, the performance drops.
+library(viridisLite)
+library(mlr3misc)
+
+data = as.data.table(instance$archive)
+data[, n:= map_int(importance, length)]
+
+ggplot(data, aes(x = n, y = classif.auc)) +
+ geom_line(
+ color = viridis(1, begin = 0.5),
+ linewidth = 1) +
+ geom_point(
+ fill = viridis(1, begin = 0.5),
+ shape = 21,
+ size = 3,
+ stroke = 0.5,
+ alpha = 0.8) +
+ xlab("Number of Features") +
+ scale_x_reverse() +
+ theme_minimal()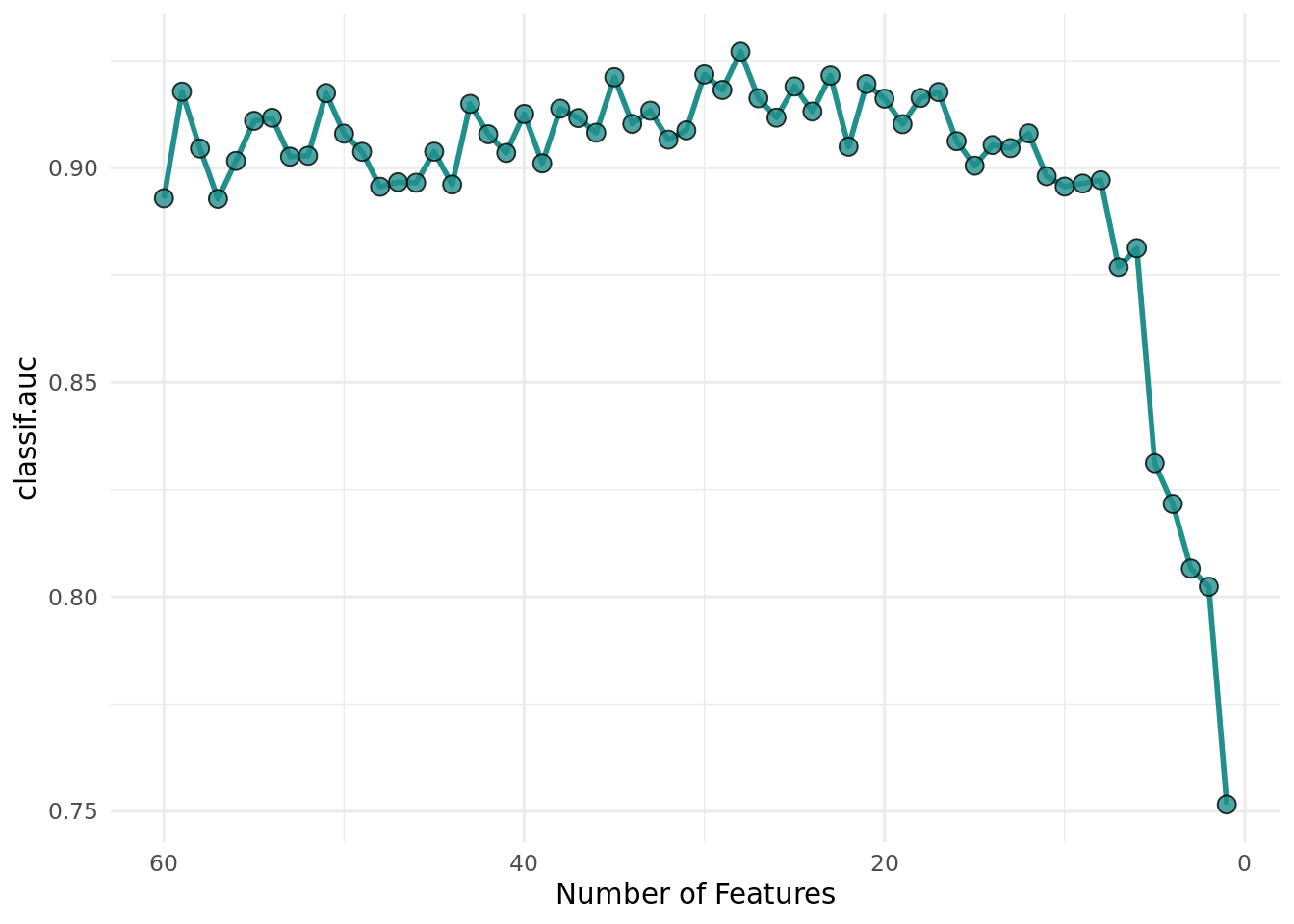 +
+The importance scores of the feature sets are recorded in the archive.
+as.data.table(instance$archive)[, list(features, classif.auc, importance)] features classif.auc importance
+ 1: V1,V10,V11,V12,V13,V14,... 0.8929304 58.83333,58.83333,54.50000,54.00000,53.33333,52.50000,...
+ 2: V1,V10,V11,V12,V13,V15,... 0.9177811 57.33333,56.00000,54.00000,53.66667,50.50000,50.00000,...
+ 3: V1,V10,V11,V12,V13,V15,... 0.9045253 54.83333,54.66667,54.66667,53.00000,51.83333,51.33333,...
+ 4: V1,V10,V11,V12,V13,V15,... 0.8927833 56.00000,55.83333,53.00000,52.00000,50.16667,50.00000,...
+ 5: V1,V10,V11,V12,V13,V15,... 0.9016274 55.50000,53.50000,51.33333,50.00000,49.00000,48.50000,...
+---
+56: V11,V12,V16,V48,V9 0.8311625 4.166667,3.333333,2.833333,2.500000,2.166667
+57: V11,V12,V16,V9 0.8216772 3.833333,2.666667,2.000000,1.500000
+58: V11,V12,V16 0.8065807 2.833333,1.833333,1.333333
+59: V11,V12 0.8023780 1.833333,1.166667
+60: V11 0.7515904 1Now we will select the optimal feature set for an SVM with a linear kernel. The importance scores are the weights of the model.
+learner = lrn("classif.svm",
+ type = "C-classification",
+ kernel = "linear",
+ predict_type = "prob")The SVM learner does not support the calculation of importance scores at first. The reason is that importance scores cannot be determined with all kernels. This can be seen by the missing "importance" property.
learner$properties[1] "multiclass" "twoclass" Using the "mlr3fselect.svm_rfe" callback however makes it possible to use a linear SVM with the RFE optimizer. The callback adds the $importance() method internally to the learner. We load the callback with the clbk() function and pass it as the "callback" argument to fsi().
instance = fsi(
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 6),
+ measures = msr("classif.auc"),
+ terminator = trm("none"),
+ callback = clbk("mlr3fselect.svm_rfe"))We start the feature selection.
+optimizer$optimize(instance)Figure 3 shows the average performance of the SVMs depending on the number of features. We can see that the performance increases significantly with a reduced feature set.
+library(viridisLite)
+library(mlr3misc)
+
+data = as.data.table(instance$archive)
+data[, n:= map_int(importance, length)]
+
+ggplot(data, aes(x = n, y = classif.auc)) +
+ geom_line(
+ color = viridis(1, begin = 0.5),
+ linewidth = 1) +
+ geom_point(
+ fill = viridis(1, begin = 0.5),
+ shape = 21,
+ size = 3,
+ stroke = 0.5,
+ alpha = 0.8) +
+ xlab("Number of Features") +
+ scale_x_reverse() +
+ theme_minimal()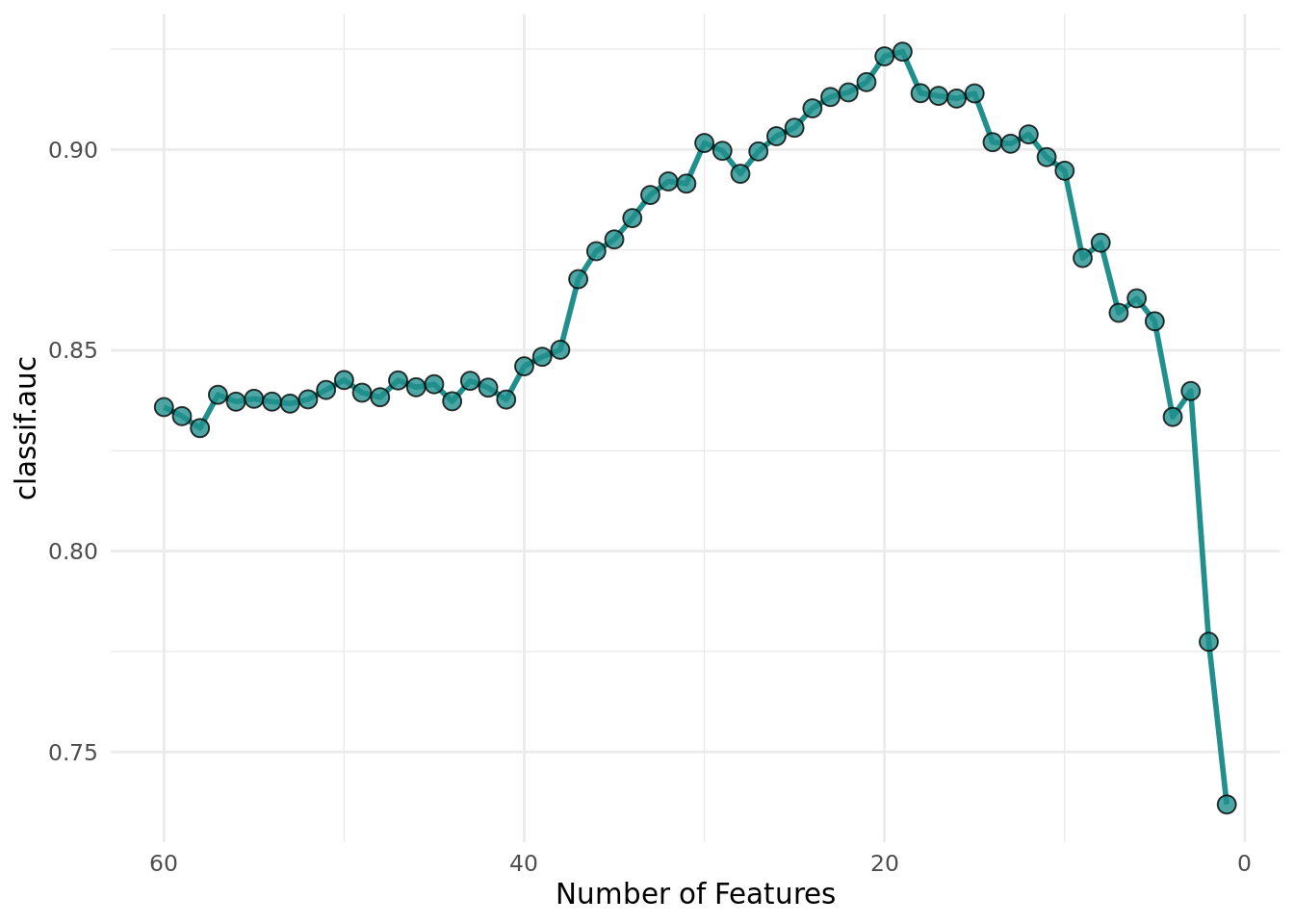 +
+For datasets with a lot of features, it is more efficient to remove several features per iteration. We show an example where 25% of the features are removed in each iteration.
+optimizer = fs("rfe", n_features = 1, feature_fraction = 0.75)
+
+instance = fsi(
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 6),
+ measures = msr("classif.auc"),
+ terminator = trm("none"),
+ callback = clbk("mlr3fselect.svm_rfe"))
+
+optimizer$optimize(instance)Figure 4 shows a similar optimization curve as Figure 3 but with fewer evaluated feature sets.
+library(viridisLite)
+library(mlr3misc)
+
+data = as.data.table(instance$archive)
+data[, n:= map_int(importance, length)]
+
+ggplot(data, aes(x = n, y = classif.auc)) +
+ geom_line(
+ color = viridis(1, begin = 0.5),
+ linewidth = 1) +
+ geom_point(
+ fill = viridis(1, begin = 0.5),
+ shape = 21,
+ size = 3,
+ stroke = 0.5,
+ alpha = 0.8) +
+ xlab("Number of Features") +
+ scale_x_reverse() +
+ theme_minimal()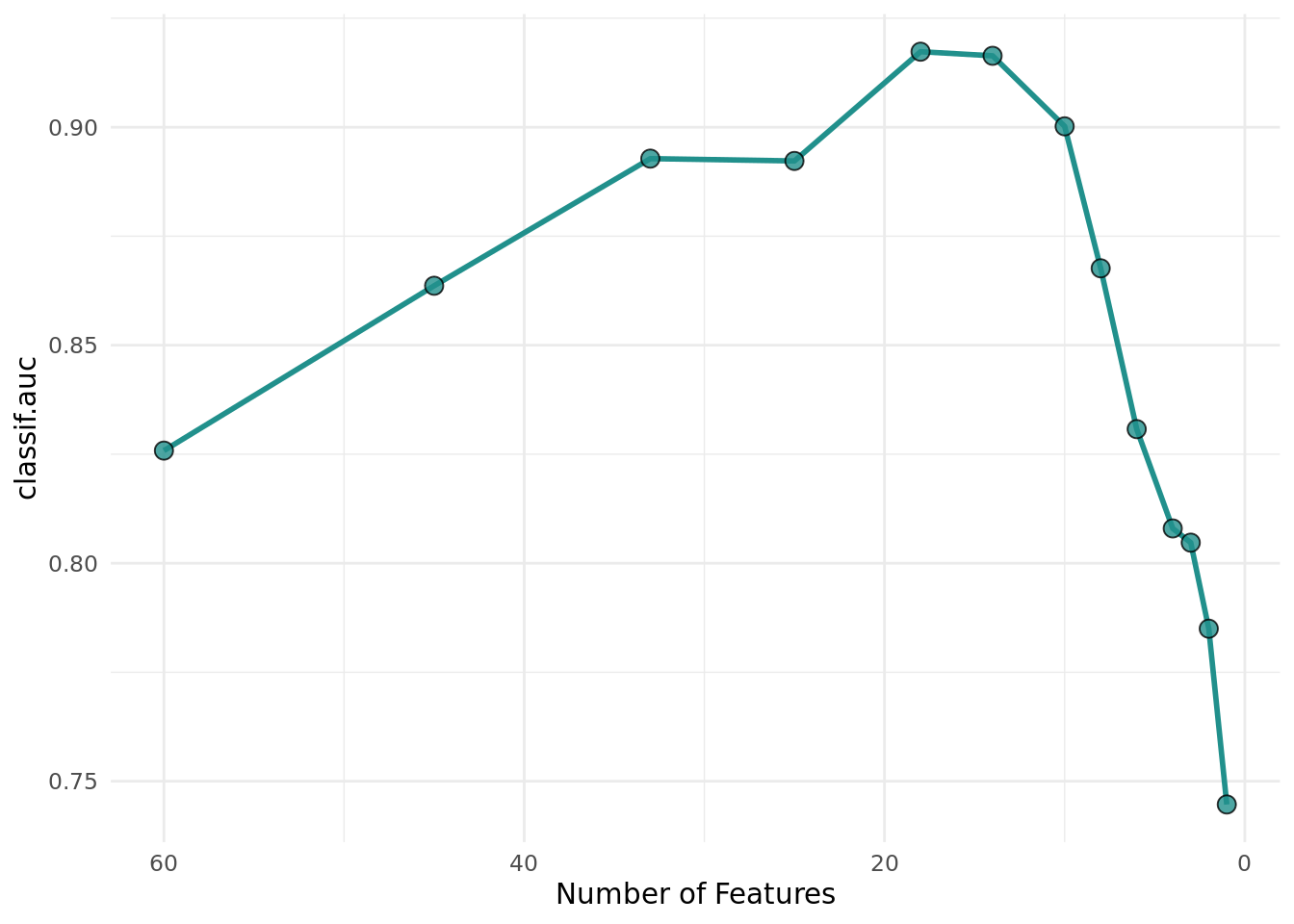 +
+RFE-CV estimates the optimal number of features before selecting a feature set. For this, an RFE is run in each resampling iteration and the number of features with the best mean performance is selected (see Figure 5). Then one more RFE is carried out on the complete dataset with the optimal number of features as the final feature set size.
+%%{ init: { 'flowchart': { 'curve': 'bump' } } }%%
+flowchart TB
+ cross-validation[3-Fold Cross-Validation]
+ cross-validation-->rfe-1
+ cross-validation-->rfe-2
+ cross-validation-->rfe-3
+ subgraph rfe-1[RFE 1]
+ direction TB
+ f14[4 Features]
+ f13[3 Features]
+ f12[2 Features]
+ f11[1 Features]
+ f14-->f13-->f12-->f11
+ style f13 fill:#ccea84
+ end
+ subgraph rfe-2[RFE 2]
+ direction TB
+ f24[4 Features]
+ f23[3 Features]
+ f22[2 Features]
+ f21[1 Features]
+ f24-->f23-->f22-->f21
+ style f23 fill:#ccea84
+ end
+ subgraph rfe-3[RFE 3]
+ direction TB
+ f34[4 Features]
+ f33[3 Features]
+ f32[2 Features]
+ f31[1 Features]
+ f34-->f33-->f32-->f31
+ style f33 fill:#ccea84
+ end
+ all_obs[All Observations]
+ rfe-1-->all_obs
+ rfe-2-->all_obs
+ rfe-3-->all_obs
+ all_obs --> rfe
+ subgraph rfe[RFE]
+ direction TB
+ f54[4 Features]
+ f53[3 Features]
+ f54-->f53
+ style f53 fill:#8e6698
+ end
+
+We retrieve the RFE-CV optimizer. RFE-CV has almost the same control parameters as the RFE optimizer. The only difference is that no aggregation is needed.
optimizer = fs("rfecv",
+ n_features = 1,
+ feature_number = 1)The chosen resampling strategy is used to estimate the optimal number of features. The 6-fold cross-validation results in 6 RFE runs. You can choose any other resampling strategy with multiple iterations. Let’s start the feature selection.
+learner = lrn("classif.svm",
+ type = "C-classification",
+ kernel = "linear",
+ predict_type = "prob")
+
+instance = fsi(
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 6),
+ measures = msr("classif.auc"),
+ terminator = trm("none"),
+ callback = clbk("mlr3fselect.svm_rfe"))
+
+optimizer$optimize(instance)The performance of the optimal feature set is calculated on the complete data set and should not be reported as the performance of the final model. Estimate the performance of the final model with nested resampling.
+We visualize the selection of the optimal number of features. Each point is the mean performance of the number of features. We achieved the best performance with 19 features.
+library(ggplot2)
+library(viridisLite)
+library(mlr3misc)
+
+data = as.data.table(instance$archive)[!is.na(iteration), ]
+aggr = data[, list("y" = mean(unlist(.SD))), by = "batch_nr", .SDcols = "classif.auc"]
+aggr[, batch_nr := 61 - batch_nr]
+
+data[, n:= map_int(importance, length)]
+
+ggplot(aggr, aes(x = batch_nr, y = y)) +
+ geom_line(
+ color = viridis(1, begin = 0.5),
+ linewidth = 1) +
+ geom_point(
+ fill = viridis(1, begin = 0.5),
+ shape = 21,
+ size = 3,
+ stroke = 0.5,
+ alpha = 0.8) +
+ geom_vline(
+ xintercept = aggr[y == max(y)]$batch_nr,
+ colour = viridis(1, begin = 0.33),
+ linetype = 3
+ ) +
+ xlab("Number of Features") +
+ ylab("Mean AUC") +
+ scale_x_reverse() +
+ theme_minimal()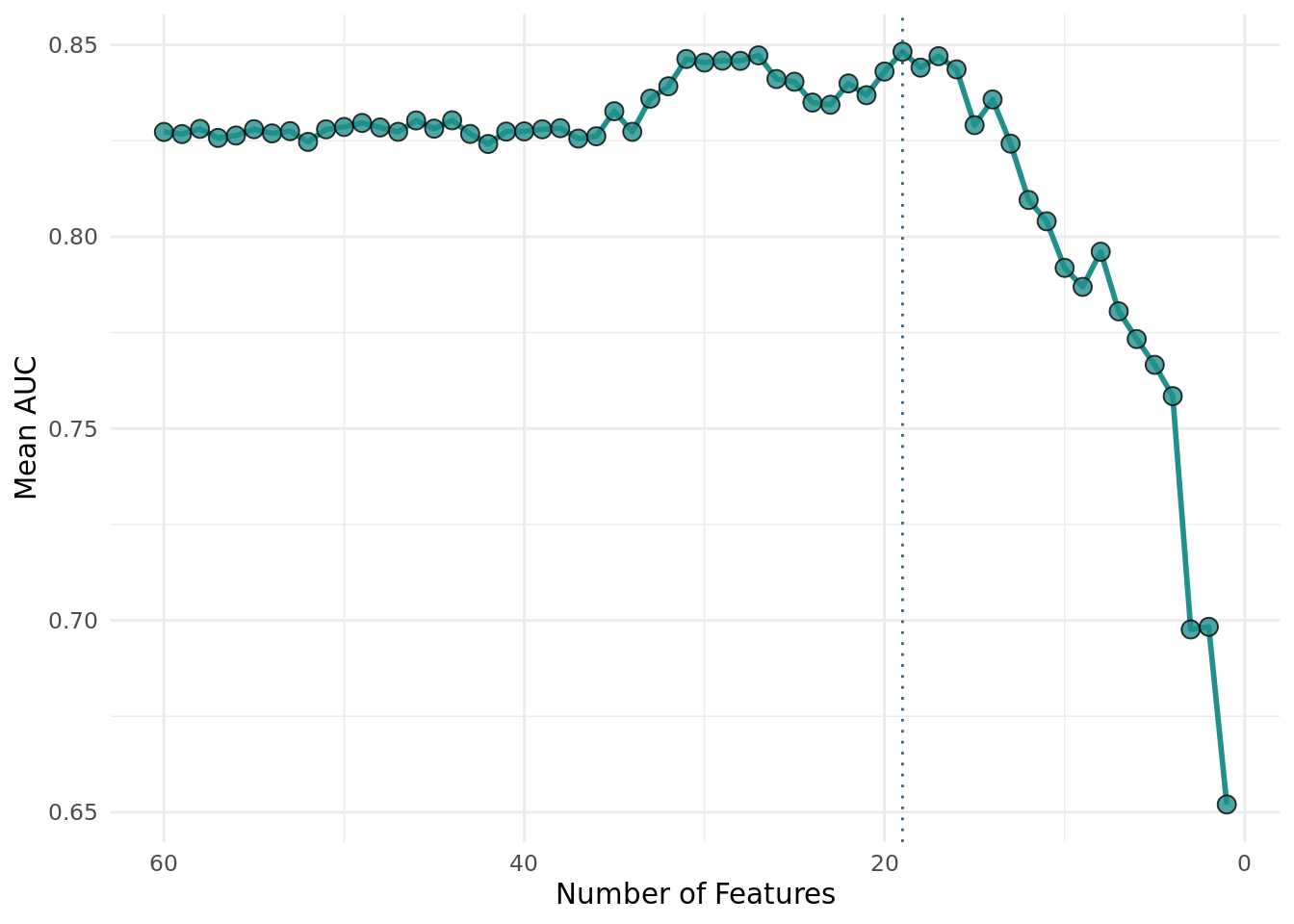 +
+The archive contains the extra column "iteration" that indicates in which resampling iteration the feature set was evaluated. The feature subsets of the final RFE run have no value in the "iteration" column because they were evaluated on the complete data set.
as.data.table(instance$archive)[, list(features, classif.auc, iteration, importance)] features classif.auc iteration importance
+ 1: V1,V10,V11,V12,V13,V14,... 0.8782895 1 2.864018,1.532774,1.408485,1.399930,1.326165,1.167745,...
+ 2: V1,V10,V11,V12,V13,V14,... 0.7026144 2 2.056442,1.706077,1.258703,1.191762,1.190752,1.178514,...
+ 3: V1,V10,V11,V12,V13,V14,... 0.8790850 3 1.950412,1.887710,1.820891,1.616219,1.231928,1.138675,...
+ 4: V1,V10,V11,V12,V13,V14,... 0.8125000 4 2.6958580,1.5623759,1.4990138,1.3902109,0.9385757,0.9232132,...
+ 5: V1,V10,V11,V12,V13,V14,... 0.8807018 5 2.487483,1.470778,1.356517,1.033764,0.635383,0.575074,...
+ ---
+398: V1,V11,V12,V16,V23,V3,... 0.9605275 NA 2.0089739,1.1047492,1.0011253,0.6602411,0.6015470,0.5431803,...
+399: V1,V12,V16,V23,V3,V30,... 0.9595988 NA 1.8337471,1.1937962,0.9853467,0.7751384,0.7296726,0.6222569,...
+400: V1,V12,V16,V23,V3,V30,... 0.9589486 NA 1.8824952,1.2468164,1.0106654,0.8090618,0.6983925,0.6568389,...
+401: V1,V12,V16,V23,V3,V30,... 0.9559766 NA 2.3872902,0.9094028,0.8809098,0.8277941,0.7841591,0.7792772,...
+402: V1,V12,V16,V23,V3,V30,... 0.9521687 NA 1.9485133,1.1482257,1.1098823,0.9591012,0.8234140,0.8118616,...The learner we use to make predictions on new data is called the final model. The final model is trained with the optimal feature set on the full data set. The optimal set consists of 19 features and is stored in instance$result_feature_set. We subset the task to the optimal feature set and train the learner.
task$select(instance$result_feature_set)
+learner$train(task)The trained model can now be used to predict new, external data.
+The RFE algorithm is a valuable feature selection method, especially for high-dimensional datasets with only a few observations. The numerous settings of the algorithm in mlr3 make it possible to apply it to many datasets and learners. If you want to know more about feature selection in general, we recommend having a look at our book.
+ + + +Feature selection is the process of finding an optimal set of features to improve the performance, interpretability and robustness of machine learning algorithms. In this article, we introduce the Shadow Variable Search algorithm which is a wrapper method for feature selection. Wrapper methods iteratively add features to the model that optimize a performance measure. As an example, we will search for the optimal set of features for a support vector machine on the Pima Indian Diabetes data set. We assume that you are already familiar with the basic building blocks of the mlr3 ecosystem. If you are new to feature selection, we recommend reading the feature selection chapter of the mlr3book first. Some knowledge about mlr3pipelines is beneficial but not necessary to understand the example.
Adding shadow variables to a data set is a well-known method in machine learning (Wu, Boos, and Stefanski 2007; Thomas et al. 2017). The idea is to add permutated copies of the original features to the data set. These permutated copies are called shadow variables or pseudovariables and the permutation breaks any relationship with the target variable, making them useless for prediction. The subsequent search is similar to the sequential forward selection algorithm, where one new feature is added in each iteration of the algorithm. This new feature is selected as the one that improves the performance of the model the most. This selection is computationally expensive, as one model for each of the not yet included features has to be trained. The difference between shadow variable search and sequential forward selection is that the former uses the selection of a shadow variable as the termination criterion. Selecting a shadow variable means that the best improvement is achieved by adding a feature that is unrelated to the target variable. Consequently, the variables not yet selected are most likely also correlated to the target variable only by chance. Therefore, only the previously selected features have a true influence on the target variable.
+mlr3fselect is the feature selection package of the mlr3 ecosystem. It implements the shadow variable search algorithm. We load all packages of the ecosystem with the mlr3verse package.
library(mlr3verse)We retrieve the shadow variable search optimizer with the fs() function. The algorithm has no control parameters.
optimizer = fs("shadow_variable_search")The objective of the Pima Indian Diabetes data set is to predict whether a person has diabetes or not. The data set includes 768 patients with 8 measurements (see Figure 1).
task = tsk("pima")library(ggplot2)
+library(data.table)
+
+data = melt(as.data.table(task), id.vars = task$target_names, measure.vars = task$feature_names)
+
+ggplot(data, aes(x = value, fill = diabetes)) +
+ geom_density(alpha = 0.5) +
+ facet_wrap(~ variable, ncol = 8, scales = "free") +
+ scale_fill_viridis_d(end = 0.8) +
+ theme_minimal() +
+ theme(axis.title.x = element_blank())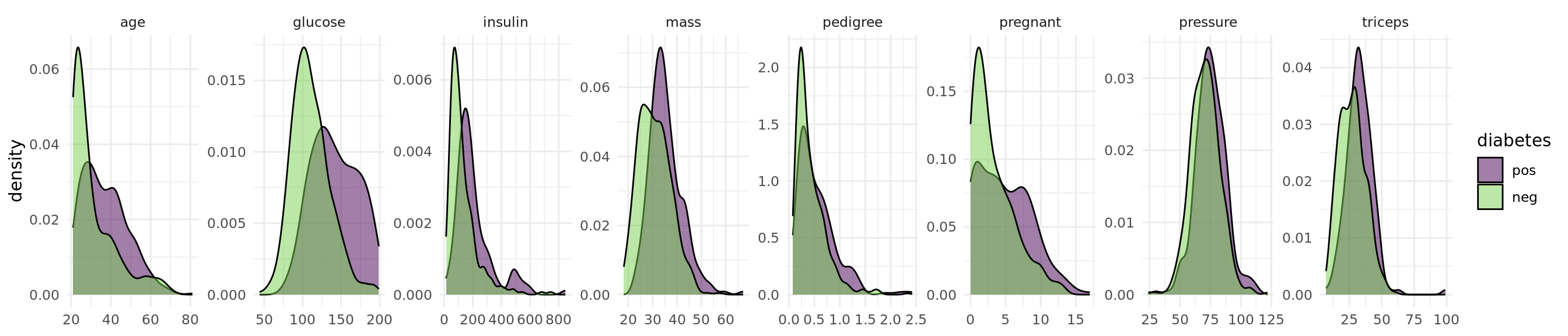 +
+The data set contains missing values.
+task$missings()diabetes age glucose insulin mass pedigree pregnant pressure triceps
+ 0 0 5 374 11 0 0 35 227 Support vector machines cannot handle missing values. We impute the missing values with the histogram imputation method.
learner = po("imputehist") %>>% lrn("classif.svm", predict_type = "prob")Now we define the feature selection problem by using the fsi() function that constructs an FSelectInstanceSingleCrit. In addition to the task and learner, we have to select a resampling strategy and performance measure to determine how the performance of a feature subset is evaluated. We pass the "none" terminator because the shadow variable search algorithm terminates by itself.
instance = fsi(
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 3),
+ measures = msr("classif.auc"),
+ terminator = trm("none")
+)We are now ready to start the shadow variable search. To do this, we simply pass the instance to the $optimize() method of the optimizer.
optimizer$optimize(instance) age glucose insulin mass pedigree pregnant pressure triceps features classif.auc
+1: TRUE TRUE FALSE TRUE TRUE FALSE FALSE FALSE age,glucose,mass,pedigree 0.835165The optimizer returns the best feature set and the corresponding estimated performance.
+Figure 2 shows the optimization path of the feature selection. The feature glucose was selected first and in the following iterations age, mass and pedigree. Then a shadow variable was selected and the feature selection was terminated.
+library(data.table)
+library(ggplot2)
+library(mlr3misc)
+library(viridisLite)
+
+data = as.data.table(instance$archive)[order(-classif.auc), head(.SD, 1), by = batch_nr][order(batch_nr)]
+data[, features := map_chr(features, str_collapse)]
+data[, batch_nr := as.character(batch_nr)]
+
+ggplot(data, aes(x = batch_nr, y = classif.auc)) +
+ geom_bar(
+ stat = "identity",
+ width = 0.5,
+ fill = viridis(1, begin = 0.5),
+ alpha = 0.8) +
+ geom_text(
+ data = data,
+ mapping = aes(x = batch_nr, y = 0, label = features),
+ hjust = 0,
+ nudge_y = 0.05,
+ color = "white",
+ size = 5
+ ) +
+ coord_flip() +
+ xlab("Iteration") +
+ theme_minimal()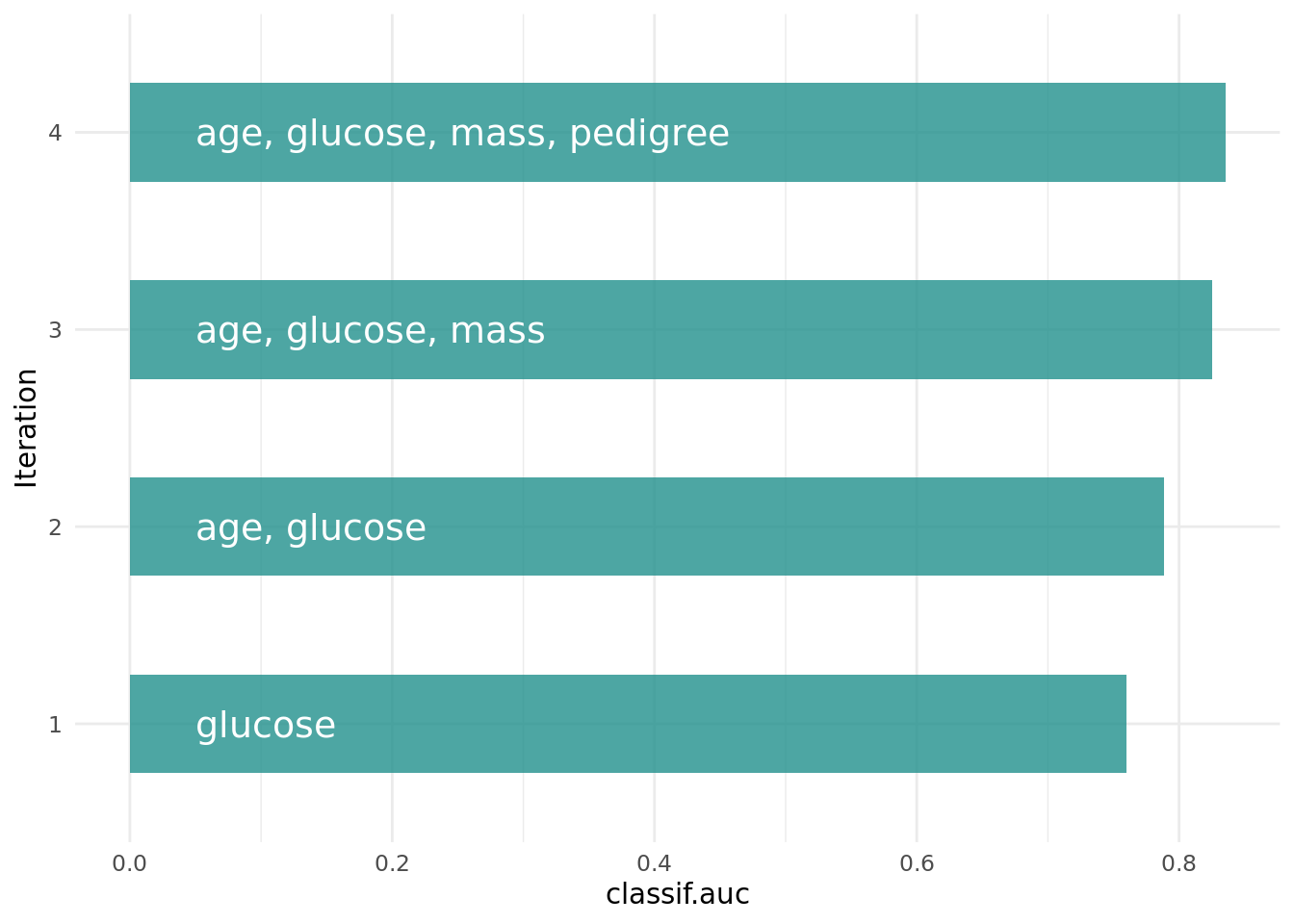 +
+The archive contains all evaluated feature sets. We can see that each feature has a corresponding shadow variable. We only show the variables age, glucose and insulin and their shadow variables here.
+as.data.table(instance$archive)[, .(age, glucose, insulin, permuted__age, permuted__glucose, permuted__insulin, classif.auc)] age glucose insulin permuted__age permuted__glucose permuted__insulin classif.auc
+ 1: TRUE FALSE FALSE FALSE FALSE FALSE 0.6437052
+ 2: FALSE TRUE FALSE FALSE FALSE FALSE 0.7598155
+ 3: FALSE FALSE TRUE FALSE FALSE FALSE 0.4900280
+ 4: FALSE FALSE FALSE FALSE FALSE FALSE 0.6424026
+ 5: FALSE FALSE FALSE FALSE FALSE FALSE 0.5690107
+---
+54: TRUE TRUE FALSE FALSE FALSE FALSE 0.8266713
+55: TRUE TRUE FALSE FALSE FALSE FALSE 0.8063568
+56: TRUE TRUE FALSE FALSE FALSE FALSE 0.8244232
+57: TRUE TRUE FALSE FALSE FALSE FALSE 0.8234605
+58: TRUE TRUE FALSE FALSE FALSE FALSE 0.8164784The learner we use to make predictions on new data is called the final model. The final model is trained with the optimal feature set on the full data set. We subset the task to the optimal feature set and train the learner.
+task$select(instance$result_feature_set)
+learner$train(task)The trained model can now be used to predict new, external data.
+The shadow variable search is a fast feature selection method that is easy to use. More information on the theoretical background can be found in Wu, Boos, and Stefanski (2007) and Thomas et al. (2017). If you want to know more about feature selection in general, we recommend having a look at our book.
+ + + +The predictive performance of modern machine learning algorithms is highly dependent on the choice of their hyperparameter configuration. Options for setting hyperparameters are tuning, manual selection by the user, and using the default configuration of the algorithm. The default configurations are chosen to work with a wide range of data sets but they usually do not achieve the best predictive performance. When tuning a learner in mlr3, we can run the default configuration as a baseline. Seeing how well it performs will tell us whether tuning pays off. If the optimized configurations perform worse, we could expand the search space or try a different optimization algorithm. Of course, it could also be that tuning on the given data set is simply not worth it.
+Probst, Boulesteix, and Bischl (2019) studied the tunability of machine learning algorithms. They found that the tunability of algorithms varies widely. Algorithms like glmnet and XGBoost are highly tunable, while algorithms like random forests work well with their default configuration. The highly tunable algorithms should thus beat their baselines more easily with optimized hyperparameters. In this article, we will tune the hyperparameters of a random forest and compare the performance of the default configuration with the optimized configurations.
+ +We tune the hyperparameters of the ranger learner on the spam data set. The search space is taken from Bischl et al. (2021).
library(mlr3verse)
+
+learner = lrn("classif.ranger",
+ mtry.ratio = to_tune(0, 1),
+ replace = to_tune(),
+ sample.fraction = to_tune(1e-1, 1),
+ num.trees = to_tune(1, 2000)
+)When creating the tuning instance, we set evaluate_default = TRUE to test the default hyperparameter configuration. The default configuration is evaluated in the first batch of the tuning run. The other batches use the specified tuning method. In this example, they are randomly drawn configurations.
instance = tune(
+ tuner = tnr("random_search", batch_size = 5),
+ task = tsk("spam"),
+ learner = learner,
+ resampling = rsmp ("holdout"),
+ measures = msr("classif.ce"),
+ term_evals = 51,
+ evaluate_default = TRUE
+)The default configuration is recorded in the first row of the archive. The other rows contain the results of the random search.
+as.data.table(instance$archive)[, .(batch_nr, mtry.ratio, replace, sample.fraction, num.trees, classif.ce)] batch_nr mtry.ratio replace sample.fraction num.trees classif.ce
+ 1: 1 0.122807018 TRUE 1.0000000 500 0.04954368
+ 2: 2 0.285388074 TRUE 0.1794772 204 0.06584094
+ 3: 2 0.097424099 FALSE 0.9475526 1441 0.04237288
+ 4: 2 0.008888587 FALSE 0.3216562 1868 0.08409387
+ 5: 2 0.335543330 TRUE 0.8122653 106 0.05345502
+---
+47: 11 0.788995735 FALSE 0.3692454 344 0.06258149
+48: 11 0.459305038 TRUE 0.3153485 1354 0.06258149
+49: 11 0.220334408 TRUE 0.9357554 817 0.05345502
+50: 11 0.868385877 TRUE 0.6743246 1040 0.06127771
+51: 11 0.015417312 FALSE 0.5627943 1836 0.08213820We plot the performances of the evaluated hyperparameter configurations. The blue line connects the best configuration of each batch. We see that the default configuration already performs well and the optimized configurations can not beat it.
+library(mlr3viz)
+
+autoplot(instance, type = "performance")
The time required to test the default configuration is negligible compared to the time required to run the hyperparameter optimization. It gives us a valuable indication of whether our tuning is properly configured. Running the default configuration as a baseline is a good practice that should be used in every tuning run.
+ + + +We continue working with the Hyperband optimization algorithm (Li et al. 2018). The previous post used the number of boosting iterations of an XGBoost model as the resource. However, Hyperband is not limited to machine learning algorithms that are trained iteratively. The resource can also be the number of features, the training time of a model, or the size of the training data set. In this post, we will tune a support vector machine and use the size of the training data set as the fidelity parameter. The time to train a support vector machine and the performance increases with the size of the data set. This makes the data set size a suitable fidelity parameter for Hyperband. This is the second part of the Hyperband series. The first part can be found here Hyperband Series - Iterative Training. If you don’t know much about Hyperband, check out the first post which explains the algorithm in detail. We assume that you are already familiar with tuning in the mlr3 ecosystem. If not, you should start with the book chapter on optimization or the Hyperparameter Optimization on the Palmer Penguins Data Set post. A little knowledge about mlr3pipelines is beneficial but not necessary to understand the example.
+ +In this post, we will optimize the hyperparameters of the support vector machine on the Sonar data set. We begin by constructing a classification machine by setting type to "C-classification".
library("mlr3verse")
+
+learner = lrn("classif.svm", id = "svm", type = "C-classification")The mlr3pipelines package features a PipeOp for subsampling.
po("subsample")PipeOp: <subsample> (not trained)
+values: <frac=0.6321, stratify=FALSE, replace=FALSE>
+Input channels <name [train type, predict type]>:
+ input [Task,Task]
+Output channels <name [train type, predict type]>:
+ output [Task,Task]The PipeOp controls the size of the training data set with the frac parameter. We connect the PipeOp with the learner and get a GraphLearner.
graph_learner = as_learner(
+ po("subsample") %>>%
+ learner
+)The graph learner subsamples and then fits a support vector machine on the data subset. The parameter set of the graph learner is a combination of the parameter sets of the PipeOp and learner.
as.data.table(graph_learner$param_set)[, .(id, lower, upper, levels)] id lower upper levels
+ 1: subsample.frac 0 Inf
+ 2: subsample.stratify NA NA TRUE,FALSE
+ 3: subsample.replace NA NA TRUE,FALSE
+ 4: svm.cachesize -Inf Inf
+ 5: svm.class.weights NA NA
+---
+15: svm.nu -Inf Inf
+16: svm.scale NA NA
+17: svm.shrinking NA NA TRUE,FALSE
+18: svm.tolerance 0 Inf
+19: svm.type NA NA C-classification,nu-classificationNext, we create the search space. We use TuneToken to mark which hyperparameters should be tuned. We have to prefix the hyperparameters with the id of the PipeOps. The subsample.frac is the fidelity parameter that must be tagged with "budget" in the search space. The data set size is increased from 3.7% to 100%. For the other hyperparameters, we took the search space for support vector machines from the Kuehn et al. (2018) article. This search space works for a wide range of data sets.
graph_learner$param_set$set_values(
+ subsample.frac = to_tune(p_dbl(3^-3, 1, tags = "budget")),
+ svm.kernel = to_tune(c("linear", "polynomial", "radial")),
+ svm.cost = to_tune(1e-4, 1e3, logscale = TRUE),
+ svm.gamma = to_tune(1e-4, 1e3, logscale = TRUE),
+ svm.tolerance = to_tune(1e-4, 2, logscale = TRUE),
+ svm.degree = to_tune(2, 5)
+)Support vector machines often crash or never finish the training with certain hyperparameter configurations. We set a timeout of 30 seconds and a fallback learner to handle these cases.
+graph_learner$encapsulate = c(train = "evaluate", predict = "evaluate")
+graph_learner$timeout = c(train = 30, predict = 30)
+graph_learner$fallback = lrn("classif.featureless")Let’s create the tuning instance. We use the "none" terminator because Hyperband controls the termination itself.
instance = ti(
+ task = tsk("sonar"),
+ learner = graph_learner,
+ resampling = rsmp("cv", folds = 3),
+ measures = msr("classif.ce"),
+ terminator = trm("none")
+)
+instance<TuningInstanceSingleCrit>
+* State: Not optimized
+* Objective: <ObjectiveTuning:subsample.svm_on_sonar>
+* Search Space:
+ id class lower upper nlevels
+1: subsample.frac ParamDbl 0.03703704 1.0000000 Inf
+2: svm.cost ParamDbl -9.21034037 6.9077553 Inf
+3: svm.degree ParamInt 2.00000000 5.0000000 4
+4: svm.gamma ParamDbl -9.21034037 6.9077553 Inf
+5: svm.kernel ParamFct NA NA 3
+6: svm.tolerance ParamDbl -9.21034037 0.6931472 Inf
+* Terminator: <TerminatorNone>We load the Hyperband tuner and set eta = 3.
library("mlr3hyperband")
+
+tuner = tnr("hyperband", eta = 3)Using eta = 3 and a lower bound of 3.7% for the data set size, results in the following schedule. Configurations with the same data set size are evaluated in parallel.
Now we are ready to start the tuning.
+tuner$optimize(instance)The best model is a support vector machine with a polynomial kernel.
+instance$result[, .(subsample.frac, svm.cost, svm.degree, svm.gamma, svm.kernel, svm.tolerance, classif.ce)] subsample.frac svm.cost svm.degree svm.gamma svm.kernel svm.tolerance classif.ce
+1: 1 1.871535 3 -2.60663 polynomial -4.573951 0.1491373The archive contains all evaluated configurations. We look at the 8 configurations that were evaluated on the complete data set. The configuration with the best classification error on the full data set was sampled in bracket 2. The classification error was estimated to be 26% on 33% of the data set and increased to 19% on the full data set (see green line in Figure 1).
+ +
+Using the data set size as the budget parameter in Hyperband allows the tuning of machine learning models that are not trained iteratively. We have tried to keep the runtime of the example low. For your optimization, you should use cross-validation and run multiple iterations of Hyperband.
+Hotstarting a learner resumes the training from an already fitted model. An example would be to train an already fit XGBoost model for an additional 500 boosting iterations. In mlr3, we call this process Hotstarting, where a learner has access to a cache of already trained models which is called a mlr3::HoststartStack We distinguish between forward and backward hotstarting. We start this post with backward hotstarting and then talk about the less efficient forward hotstarting.
In this example, we optimize the hyperparameters of a random forest and use hotstarting to reduce the runtime. Hotstarting a random forest backwards is very simple. The model remains unchanged and only a subset of the trees is used for prediction i.e. a new model is not fitted. For example, a random forest is trained with 1000 trees and a specific hyperparameter configuration. If another random forest with 500 trees but with the same hyperparameter configuration has to be trained, the model with 1000 trees is copied and only 500 trees are used for prediction.
+We load the ranger learner and set the search space from the Bischl et al. (2021) article.
library(mlr3verse)
+
+learner = lrn("classif.ranger",
+ mtry.ratio = to_tune(0, 1),
+ replace = to_tune(),
+ sample.fraction = to_tune(1e-1, 1),
+ num.trees = to_tune(1, 2000)
+)We activate hotstarting with the allow_hotstart option. When running a grid search with hotstarting, the grid is sorted by the hot start parameter. This means the models with 2000 trees are trained first. The models with less than 2000 trees hot start on the 2000 trees models which allows the training to be completed immediately.
instance = tune(
+ tuner = tnr("grid_search", resolution = 5, batch_size = 5),
+ task = tsk("spam"),
+ learner = learner,
+ resampling = rsmp("holdout"),
+ measure = msr("classif.ce"),
+ allow_hotstart = TRUE
+)For comparison, we perform the same tuning without hotstarting.
+instance_2 = tune(
+ tuner = tnr("grid_search", resolution = 5, batch_size = 5),
+ task = tsk("spam"),
+ learner = learner,
+ resampling = rsmp("holdout"),
+ measure = msr("classif.ce"),
+ allow_hotstart = FALSE
+)We plot the time of completion of each batch (see Figure 1). Each batch includes 5 configurations. We can see that tuning with hotstarting is slower at first. As soon as all models are fitted with 2000 trees, the tuning runs much faster and overtakes the tuning without hotstarting.
+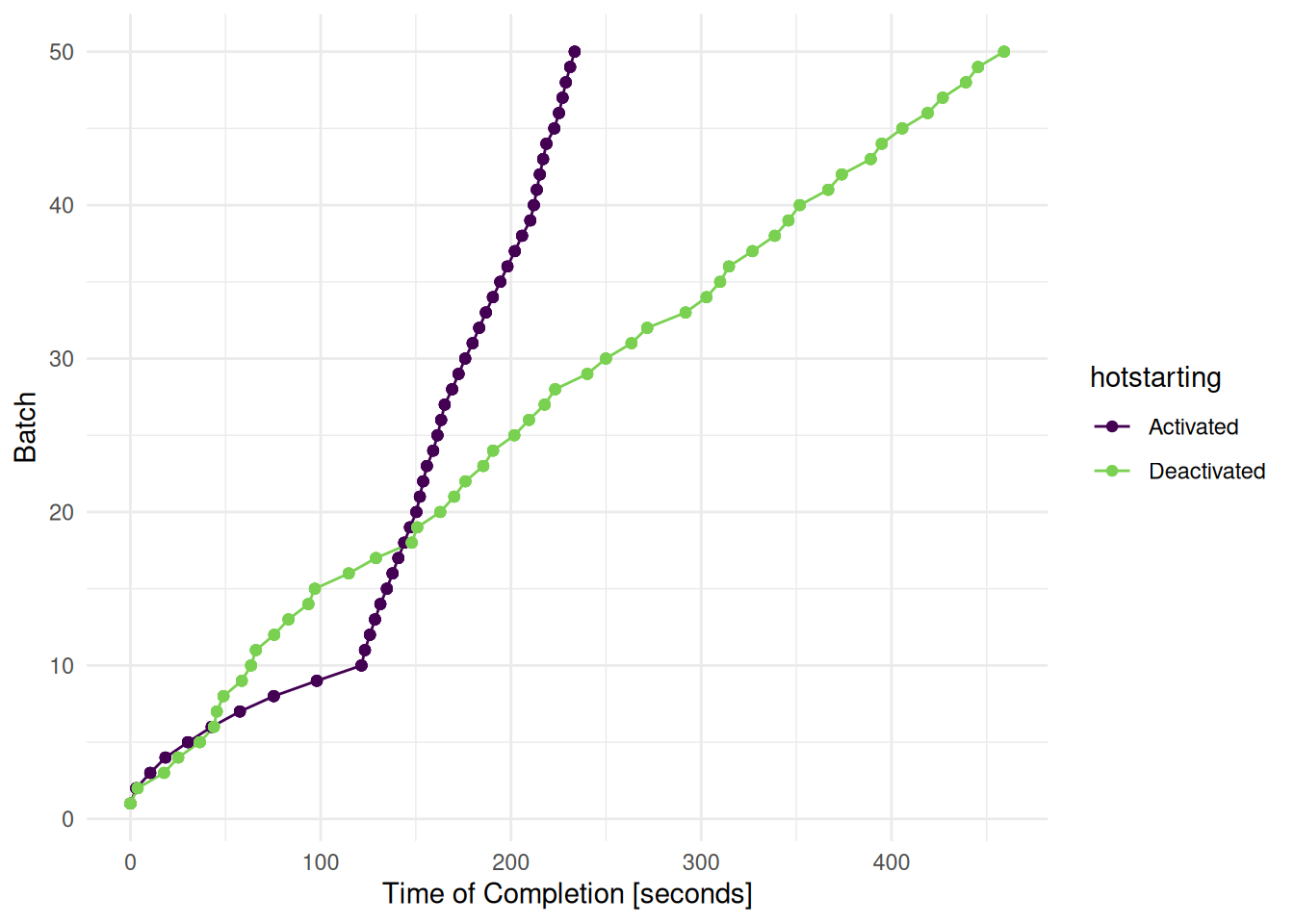 +
+Forward hotstarting is currently only supported by XGBoost. However, we have observed that hotstarting only provides a speed advantage for very large datasets and models with more than 5000 boosting rounds. The reason is that copying the models from the main process to the workers is a major bottleneck. The parallelization package future copies the models sequentially to the workers. Consequently, it takes a long time until the last worker can even start. Moreover, copying itself consumes a lot of time, and copying the model back from the worker blocks the main process again. During the development process, we overestimated the speed benefits of hotstarting and underestimated the overhead of parallelization. We can therefore only advise against using forward hotstarting during tuning. It is much more efficient to use the internal early-stopping mechanism of XGBoost. This eliminates the need to copy models to the worker. See the gallery post on early stopping for an example. We might improve the efficiency of the hotstarting mechanism in the future, if there are convincing use cases.
+Nevertheless, forward hotstarting can be useful without parallelization. If you have an already trained model and want to add more boosting iteration to it. In this example, the learner_5000 is the already trained model. We create a new learner with the same hyperparameters but double the number of boosting iteration. To activate hotstarting, we create a HotstartStack and copy it to the $hotstart_stack slot of the new learner.
task = tsk("spam")
+
+learner_5000 = lrn("classif.xgboost", nrounds = 5000, eta = 0.1)
+learner_5000$train(task)
+
+learner_10000 = lrn("classif.xgboost", nrounds = 10000, eta = 0.1)
+learner_10000$hotstart_stack = HotstartStack$new(learner_5000)
+learner_10000$train(task)Training the initial model took 59.885 seconds.
+learner_5000$state$train_time[1] 59.885Adding 5000 boosting rounds took 46.837 seconds.
+learner_10000$state$train_time - learner_5000$state$train_time[1] 46.837Training the model from the beginning would have taken about two minutes. This means, without parallelization, we get the expected speed advantage.
+We have seen how mlr3 enables to reduce the training time, by building on a hotstart stack of already trained learners. One has to be careful, however, when using forward hotstarting during tuning because of the high parallelization overhead that arises from copying the models between the processes. If a model has an internal early stopping implementation, it should usually be relied upon instead of using the mlr3 hotstarting mechanism. However, manual forward hotstarting can be helpful in some situations when we do not want to train a large model from the beginning.
+ + + +Increasingly large data sets and search spaces make hyperparameter optimization a time-consuming task. Hyperband (Li et al. 2018) solves this by approximating the performance of a configuration on a simplified version of the problem such as a small subset of the training data, with just a few training epochs in a neural network, or with only a small number of iterations in a gradient-boosting model. After starting randomly sampled configurations, Hyperband iteratively allocates more resources to promising configurations and terminates low-performing ones. This type of optimization is called multi-fidelity optimization. The fidelity parameter is part of the search space and controls the tradeoff between the runtime and accuracy of the performance approximation. In this post, we will optimize XGBoost and use the number of boosting iterations as the fidelity parameter. This means Hyperband will allocate more boosting iterations to well-performing configurations. The number of boosting iterations increases the time to train a model and improves the performance until the model is overfitting to the training data. It is therefore a suitable fidelity parameter. We assume that you are already familiar with tuning in the mlr3 ecosystem. If not, you should start with the book chapter on optimization or the Hyperparameter Optimization on the Palmer Penguins Data Set post. This is the first part of the Hyperband series. The second part can be found here Hyperband Series - Data Set Subsampling.
+ +Hyperband is an advancement of the Successive Halving algorithm by Jamieson and Talwalkar (2016). Successive Halving is initialized with the number of starting configurations , the proportion of configurations discarded in each stage
, and the minimum
and maximum
budget of a single evaluation. The algorithm starts by sampling
random configurations and allocating the minimum budget
to them. The configurations are evaluated and
of the worst-performing configurations are discarded. The remaining configurations are promoted to the next stage and evaluated on a larger budget. This continues until one or more configurations are evaluated on the maximum budget
and the best performing configuration is selected. The number of stages is calculated so that each stage consumes approximately the same budget. This sometimes results in the minimum budget having to be slightly adjusted by the algorithm. Successive Halving has the disadvantage that is not clear whether we should choose a large
and try many configurations on a small budget or choose a small
and train more configurations on the full budget.
Hyperband solves this problem by running Successive Halving with different numbers of stating configurations. The algorithm is initialized with the same parameters as Successive Halving but without . Each run of Successive Halving is called a bracket and starts with a different budget
. A smaller starting budget means that more configurations can be tried out. The most explorative bracket allocated the minimum budget
. The next bracket increases the starting budget by a factor of
. In each bracket, the starting budget increases further until the last bracket
essentially performs a random search with the full budget
. The number of brackets
is calculated with
. Under the condition that
increases by
with each bracket,
sometimes has to be adjusted slightly in order not to use more than
resources in the last bracket. The number of configurations in the base stages is calculated so that each bracket uses approximately the same amount of budget. The following table shows a full run of the Hyperband algorithm. The bracket
is the most explorative bracket and
performance a random search on the full budget.
The Hyperband implementation in mlr3hyperband evaluates configurations with the same budget in parallel. This results in all brackets finishing at approximately the same time. The colors in Figure 1 indicate batches that are evaluated in parallel.
+In this practical example, we will optimize the hyperparameters of XGBoost on the Spam data set. We begin by loading the XGBoost learner..
library("mlr3verse")
+
+learner = lrn("classif.xgboost")The next thing we do is define the search space. The nrounds parameter controls the number of boosting iterations. We set a range from 16 to 128 boosting iterations. This is used as and
by the Hyperband algorithm. We need to tag the parameter with
"budget" to identify it as a fidelity parameter. For the other hyperparameters, we take the search space for XGBoost from the Bischl et al. (2021) article. This search space works for a wide range of data sets.
learner$param_set$set_values(
+ nrounds = to_tune(p_int(16, 128, tags = "budget")),
+ eta = to_tune(1e-4, 1, logscale = TRUE),
+ max_depth = to_tune(1, 20),
+ colsample_bytree = to_tune(1e-1, 1),
+ colsample_bylevel = to_tune(1e-1, 1),
+ lambda = to_tune(1e-3, 1e3, logscale = TRUE),
+ alpha = to_tune(1e-3, 1e3, logscale = TRUE),
+ subsample = to_tune(1e-1, 1)
+)We construct the tuning instance. We use the "none" terminator because Hyperband terminates itself when all brackets are evaluated.
instance = ti(
+ task = tsk("spam"),
+ learner = learner,
+ resampling = rsmp("holdout"),
+ measures = msr("classif.ce"),
+ terminator = trm("none")
+)
+instance<TuningInstanceSingleCrit>
+* State: Not optimized
+* Objective: <ObjectiveTuning:classif.xgboost_on_spam>
+* Search Space:
+ id class lower upper nlevels
+ <char> <char> <num> <num> <num>
+1: nrounds ParamInt 16.000000 128.000000 113
+2: eta ParamDbl -9.210340 0.000000 Inf
+3: max_depth ParamInt 1.000000 20.000000 20
+4: colsample_bytree ParamDbl 0.100000 1.000000 Inf
+5: colsample_bylevel ParamDbl 0.100000 1.000000 Inf
+6: lambda ParamDbl -6.907755 6.907755 Inf
+7: alpha ParamDbl -6.907755 6.907755 Inf
+8: subsample ParamDbl 0.100000 1.000000 Inf
+* Terminator: <TerminatorNone>We load the Hyperband tuner and set eta = 2. Hyperband can start from the beginning when the last bracket is evaluated. We control the number of Hyperband runs with the repetition argument. The setting repetition = Inf is useful when a terminator should stop the optimization.
library("mlr3hyperband")
+
+tuner = tnr("hyperband", eta = 2, repetitions = 1)The Hyperband implementation in mlr3hyperband evaluates configurations with the same budget in parallel. This results in all brackets finishing at approximately the same time. You can think of it as going diagonally through Figure 1. Using eta = 2 and a range from 16 to 128 boosting iterations results in the following schedule.
Now we are ready to start the tuning.
+tuner$optimize(instance)The result of a run is the configuration with the best performance. This does not necessarily have to be a configuration evaluated with the highest budget since we can overfit the data with too many boosting iterations.
+instance$result[, .(nrounds, eta, max_depth, colsample_bytree, colsample_bylevel, lambda, alpha, subsample)] nrounds eta max_depth colsample_bytree colsample_bylevel lambda alpha subsample
+ <num> <num> <int> <num> <num> <num> <num> <num>
+1: 128 -1.985313 8 0.4828647 0.3001509 -3.816118 -4.998944 0.4464856The archive of a Hyperband run has the additional columns "bracket" and "stage".
as.data.table(instance$archive)[, .(bracket, stage, classif.ce, eta, max_depth, colsample_bytree)] bracket stage classif.ce eta max_depth colsample_bytree
+ <int> <num> <num> <num> <int> <num>
+ 1: 3 0 0.09061278 -3.6110452 20 0.2671318
+ 2: 3 0 0.06388527 -1.9853130 8 0.4828647
+ 3: 3 0 0.11147327 -2.8428844 3 0.3152709
+ 4: 3 0 0.07301173 -3.9228523 19 0.5369803
+ 5: 3 0 0.07953064 -3.6486183 17 0.2039727
+---
+31: 0 0 0.06258149 -1.8578637 9 0.7343156
+32: 3 3 0.03976532 -1.9853130 8 0.4828647
+33: 2 2 0.03976532 -0.9898459 4 0.2534038
+34: 1 1 0.05345502 -2.5345314 13 0.5260946
+35: 1 1 0.06714472 -8.5597326 16 0.9890136The handling of Hyperband in mlr3tuning is very similar to that of other tuners. We only have to select an additional fidelity parameter and tag it with "budget". We have tried to keep the runtime of the example low. For your optimization, you should use cross-validation and increase the maximum number of boosting rounds. The Bischl et al. (2021) search space suggests 5000 boosting rounds. Check out our next post on Hyperband which uses the size of the training data set as the fidelity parameter.
We showcase the visualization functions of the mlr3 ecosystem. The mlr3viz package creates a plot for almost all mlr3 objects. This post displays all available plots with their reproducible code. We start with plots of the base mlr3 objects. This includes boxplots of tasks, dendrograms of cluster learners and ROC curves of predictions. After that, we tune a classification tree and visualize the results. Finally, we show visualizations for filters.
+This article will be updated whenever a new plot is available in mlr3viz.
The mlr3viz package defines autoplot() functions to draw plots with ggplot2. Often there is more than one type of plot for an object. You can change the plot with the type argument. The help pages list all possible choices. The easiest way to access the help pages is via the pkgdown website. The plots use the viridis color pallet and the appearance is controlled with the theme argument. By default, the minimal theme is applied.
We begin with plots of the classification task Palmer Penguins. We plot the class frequency of the target variable.
library(mlr3verse)
+library(mlr3viz)
+
+task = tsk("penguins")
+task$select(c("body_mass", "bill_length"))
+
+autoplot(task, type = "target")
The "duo" plot shows the distribution of multiple features.
autoplot(task, type = "duo")
The "pairs" plot shows the pairwise comparison of multiple features. The classes of the target variable are shown in different colors.
autoplot(task, type = "pairs")
Next, we plot the regression task mtcars. We create a boxplot of the target variable.
task = tsk("mtcars")
+task$select(c("am", "carb"))
+
+autoplot(task, type = "target")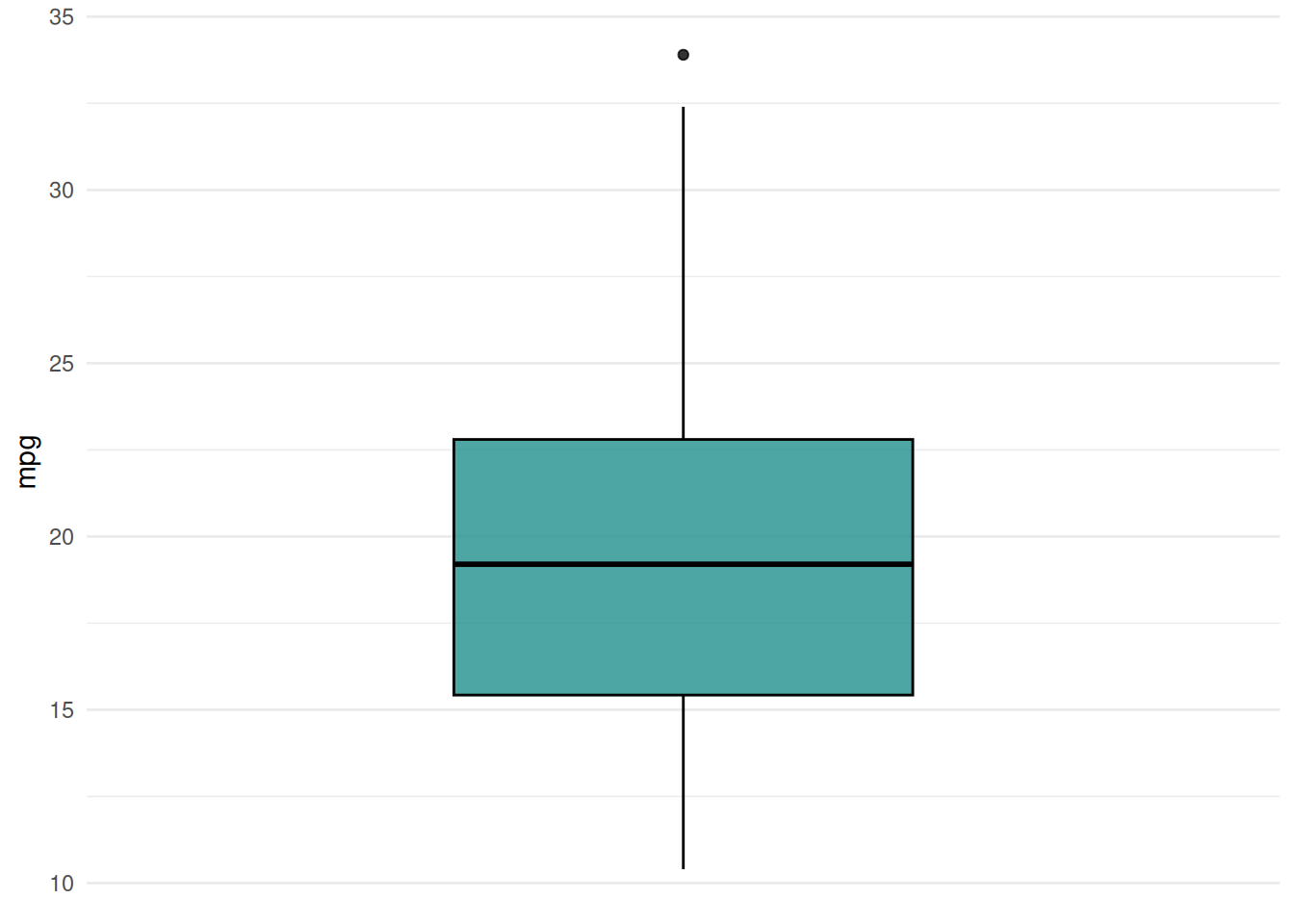
The "pairs" plot shows the pairwise comparison of mutiple features and the target variable.
autoplot(task, type = "pairs")
Finally, we plot the cluster task US Arrests. The "pairs" plot shows the pairwise comparison of mutiple features.
library(mlr3cluster)
+
+task = mlr_tasks$get("usarrests")
+
+autoplot(task, type = "pairs")
The "prediction" plot shows the decision boundary of a classification learner and the true class labels as points.
task = tsk("pima")$select(c("age", "pedigree"))
+learner = lrn("classif.rpart")
+learner$train(task)
+
+autoplot(learner, type = "prediction", task)
Using probabilities.
+task = tsk("pima")$select(c("age", "pedigree"))
+learner = lrn("classif.rpart", predict_type = "prob")
+learner$train(task)
+
+autoplot(learner, type = "prediction", task)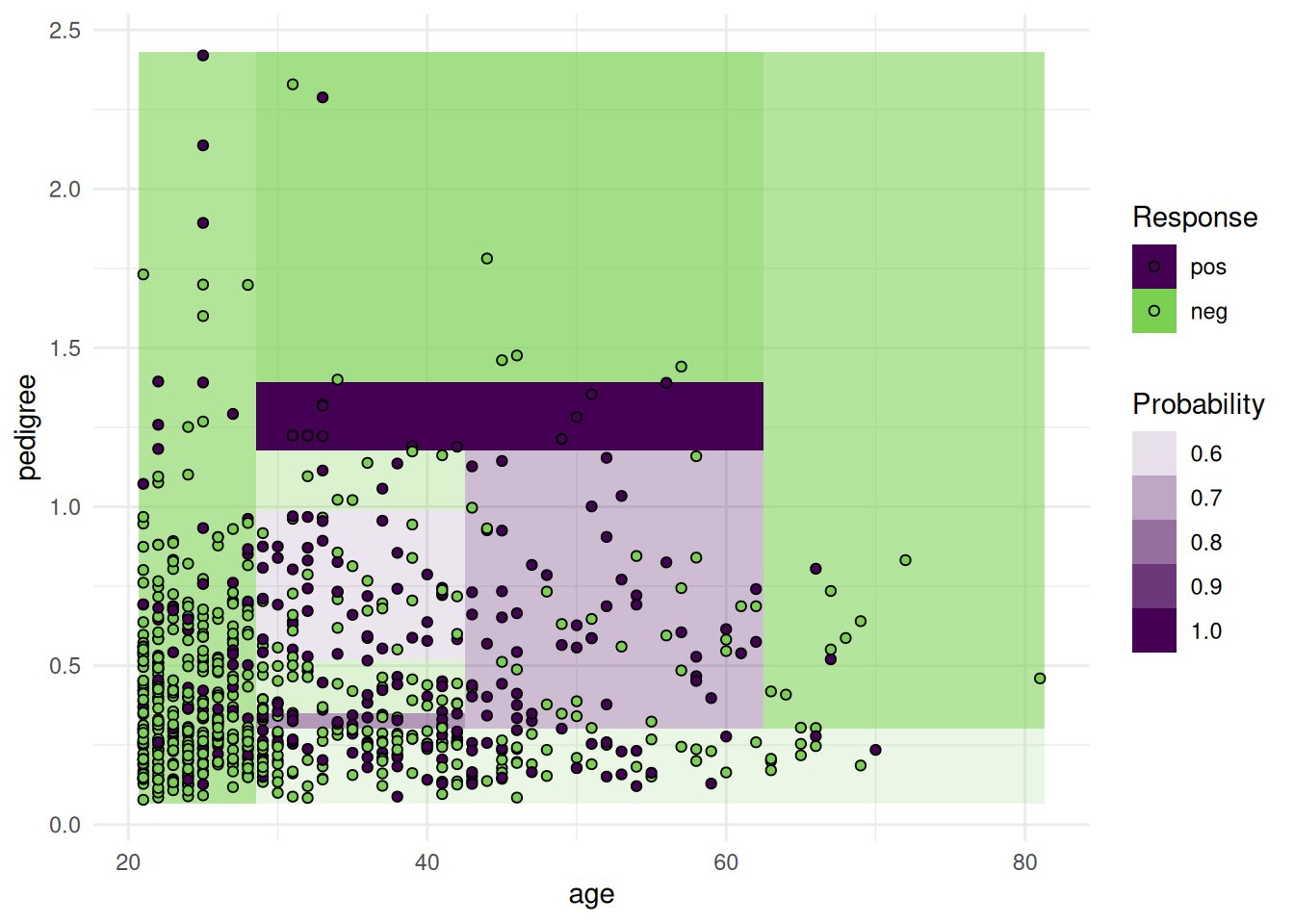
The "prediction" plot of a regression learner illustrates the decision boundary and the true response as points.
task = tsk("boston_housing")$select("age")
+learner = lrn("regr.rpart")
+learner$train(task)
+
+autoplot(learner, type = "prediction", task)
When using two features, the response surface is plotted in the background.
+task = tsk("boston_housing")$select(c("age", "rm"))
+learner = lrn("regr.rpart")
+learner$train(task)
+
+autoplot(learner, type = "prediction", task)
The classification and regression GLMNet learner is equipped with a plot function.
library(mlr3data)
+
+task = tsk("ilpd")
+task$select(setdiff(task$feature_names, "gender"))
+learner = lrn("classif.glmnet")
+learner$train(task)
+
+autoplot(learner, type = "ggfortify")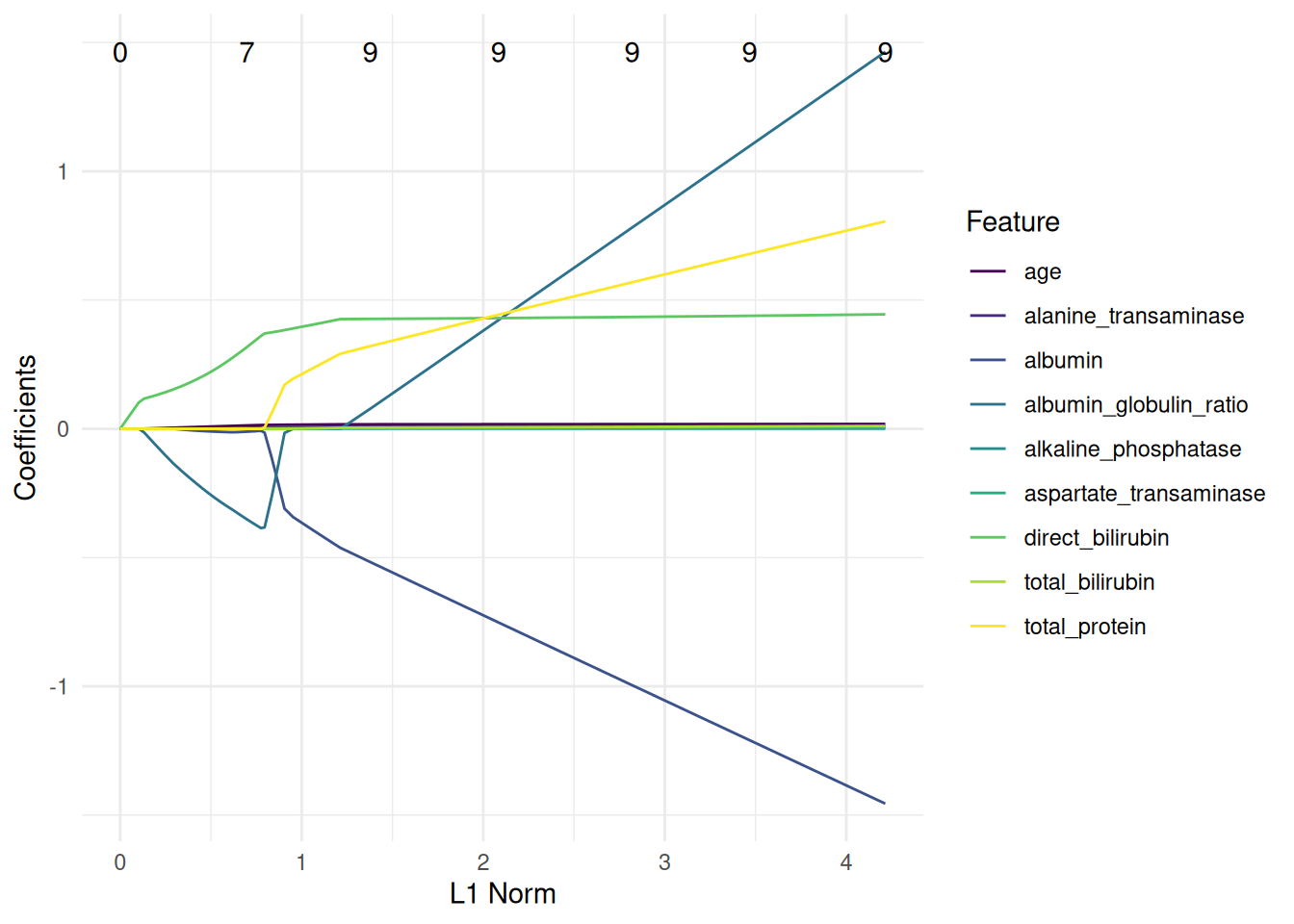
task = tsk("mtcars")
+learner = lrn("regr.glmnet")
+learner$train(task)
+
+autoplot(learner, type = "ggfortify")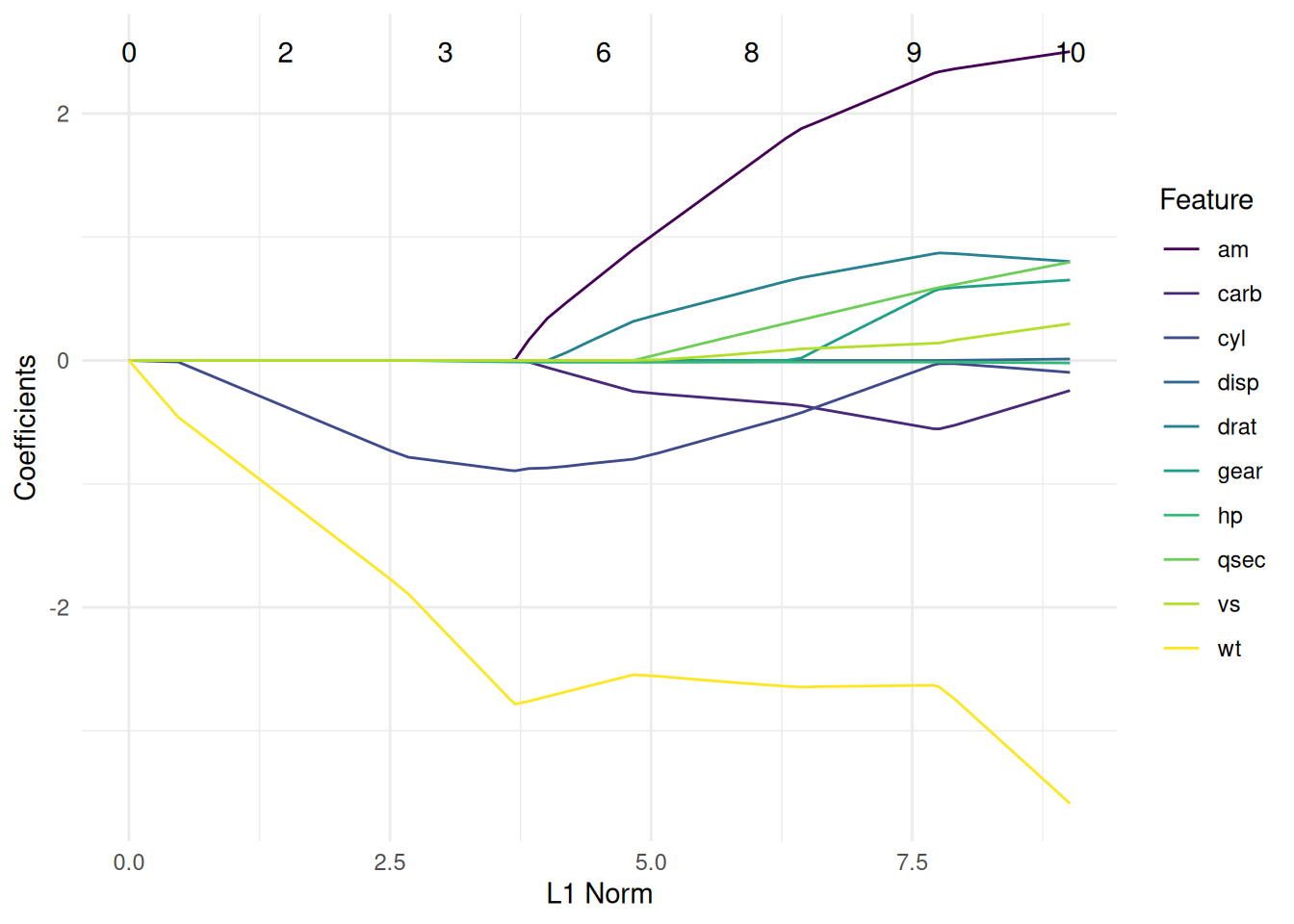
We plot a classification tree of the rpart package. We have to fit the learner with keep_model = TRUE to keep the model object.
task = tsk("penguins")
+learner = lrn("classif.rpart", keep_model = TRUE)
+learner$train(task)
+
+autoplot(learner, type = "ggparty")
We can also plot regression trees.
+task = tsk("mtcars")
+learner = lrn("regr.rpart", keep_model = TRUE)
+learner$train(task)
+
+autoplot(learner, type = "ggparty")
The "dend" plot shows the result of the hierarchical clustering of the data.
library(mlr3cluster)
+
+task = tsk("usarrests")
+learner = lrn("clust.hclust")
+learner$train(task)
+
+autoplot(learner, type = "dend", task = task)
The "scree" type plots the number of clusters and the height.
autoplot(learner, type = "scree")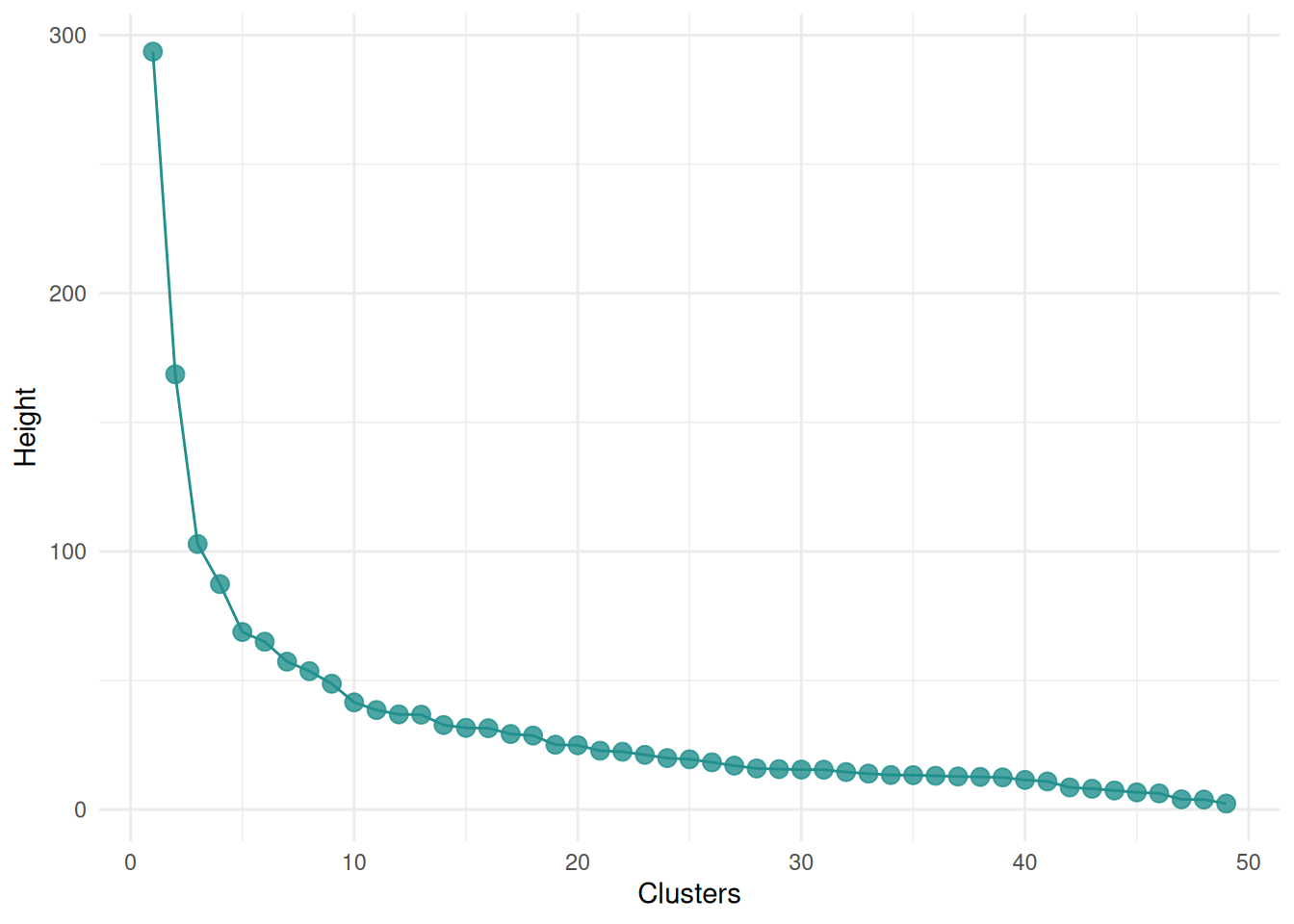
We plot the predictions of a classification learner. The "stacked" plot shows the predicted and true class labels.
task = tsk("spam")
+learner = lrn("classif.rpart", predict_type = "prob")
+pred = learner$train(task)$predict(task)
+
+autoplot(pred, type = "stacked")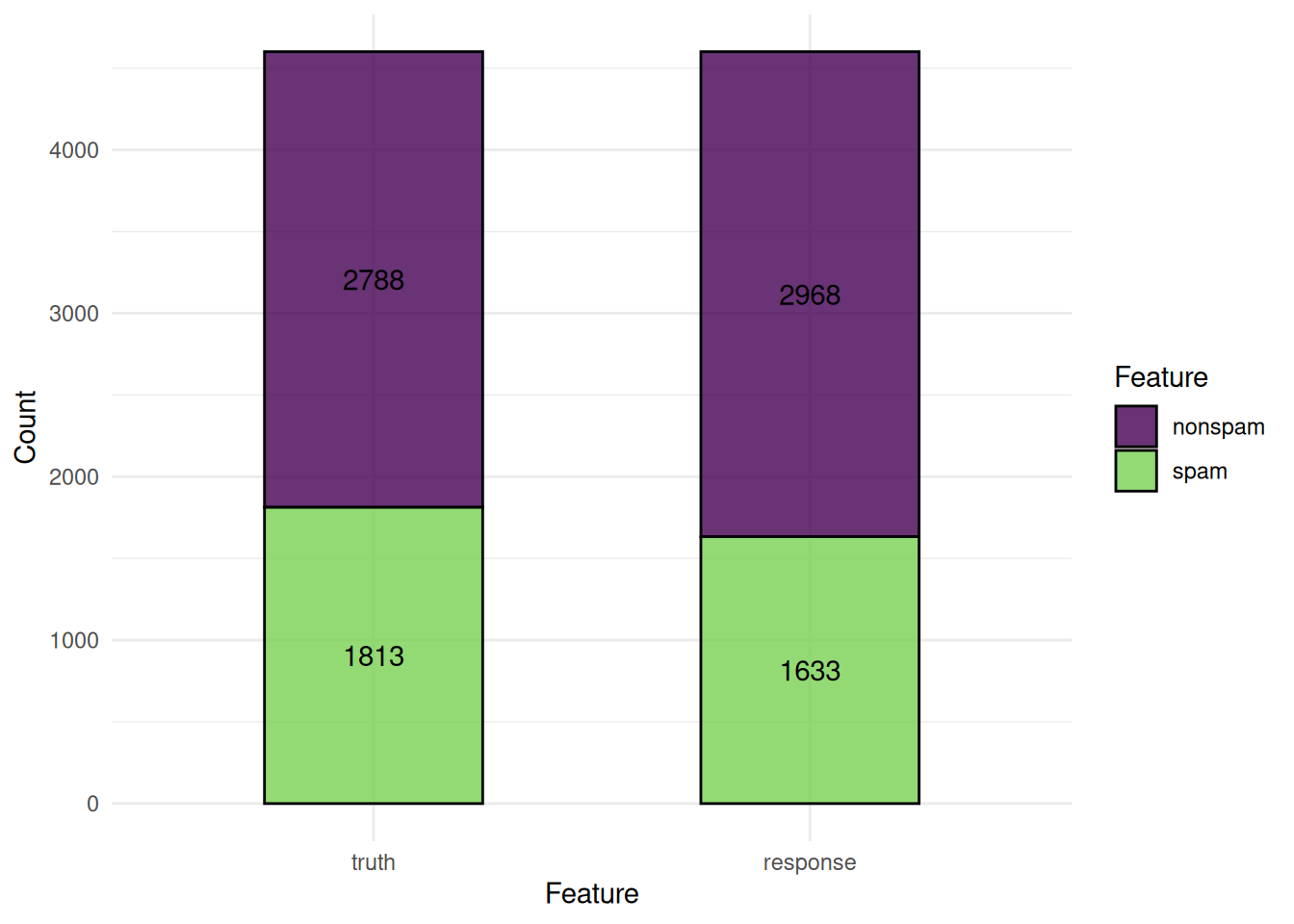
The ROC curve plots the true positive rate against the false positive rate at different thresholds.
+autoplot(pred, type = "roc")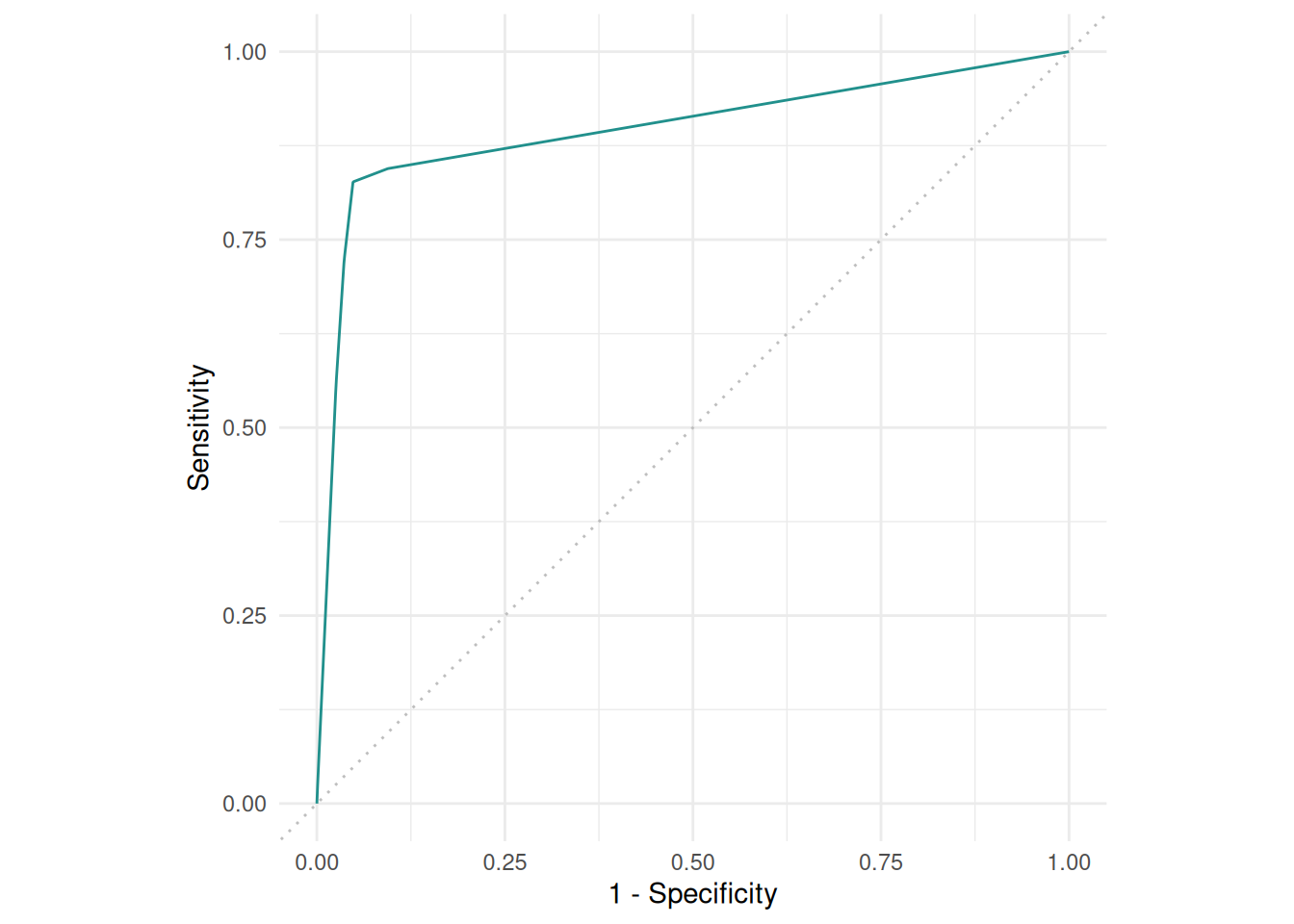
The precision-recall curve plots the precision against the recall at different thresholds.
+autoplot(pred, type = "prc")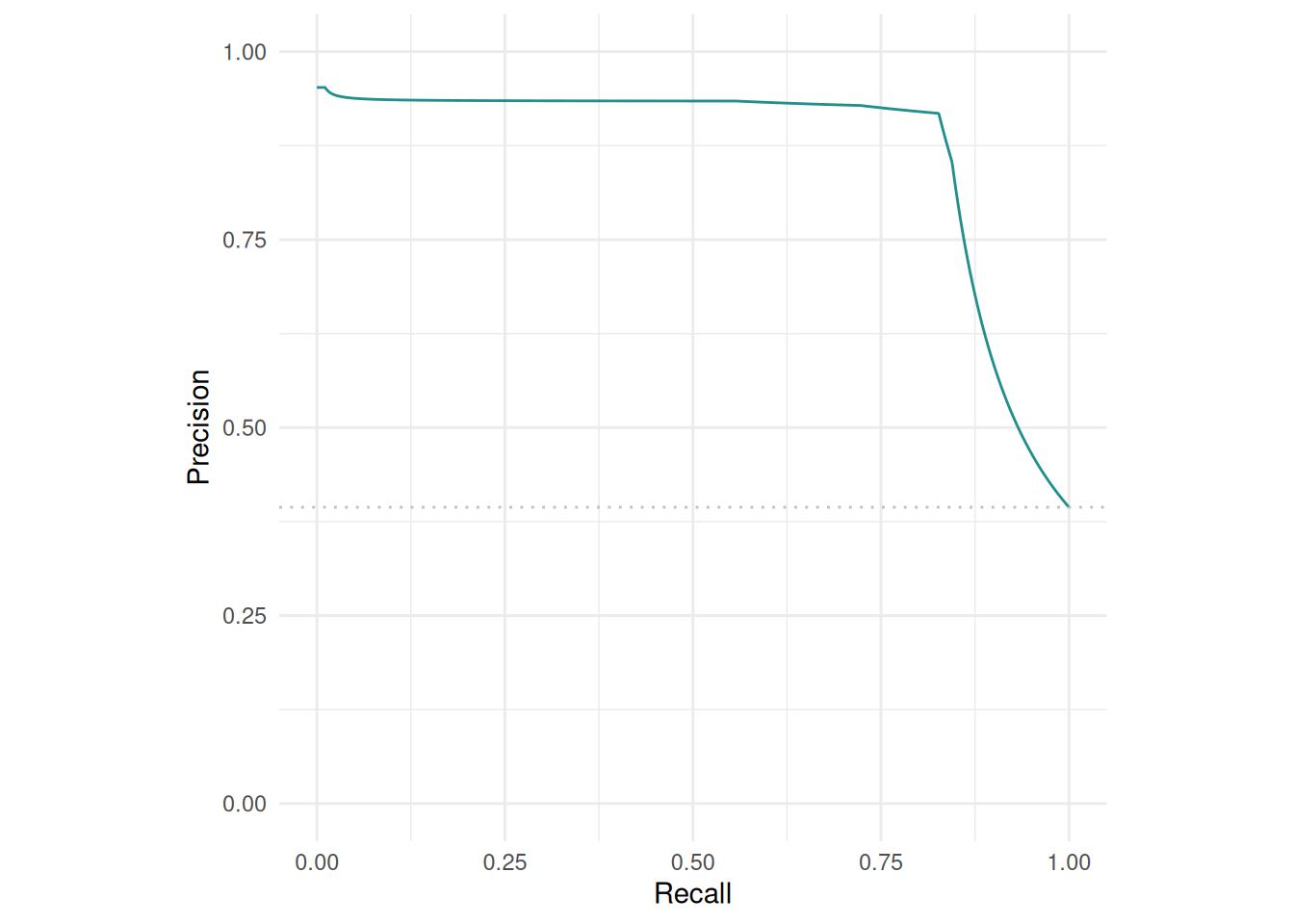
The "threshold" plot varies the threshold of a binary classification and plots against the resulting performance.
autoplot(pred, type = "threshold")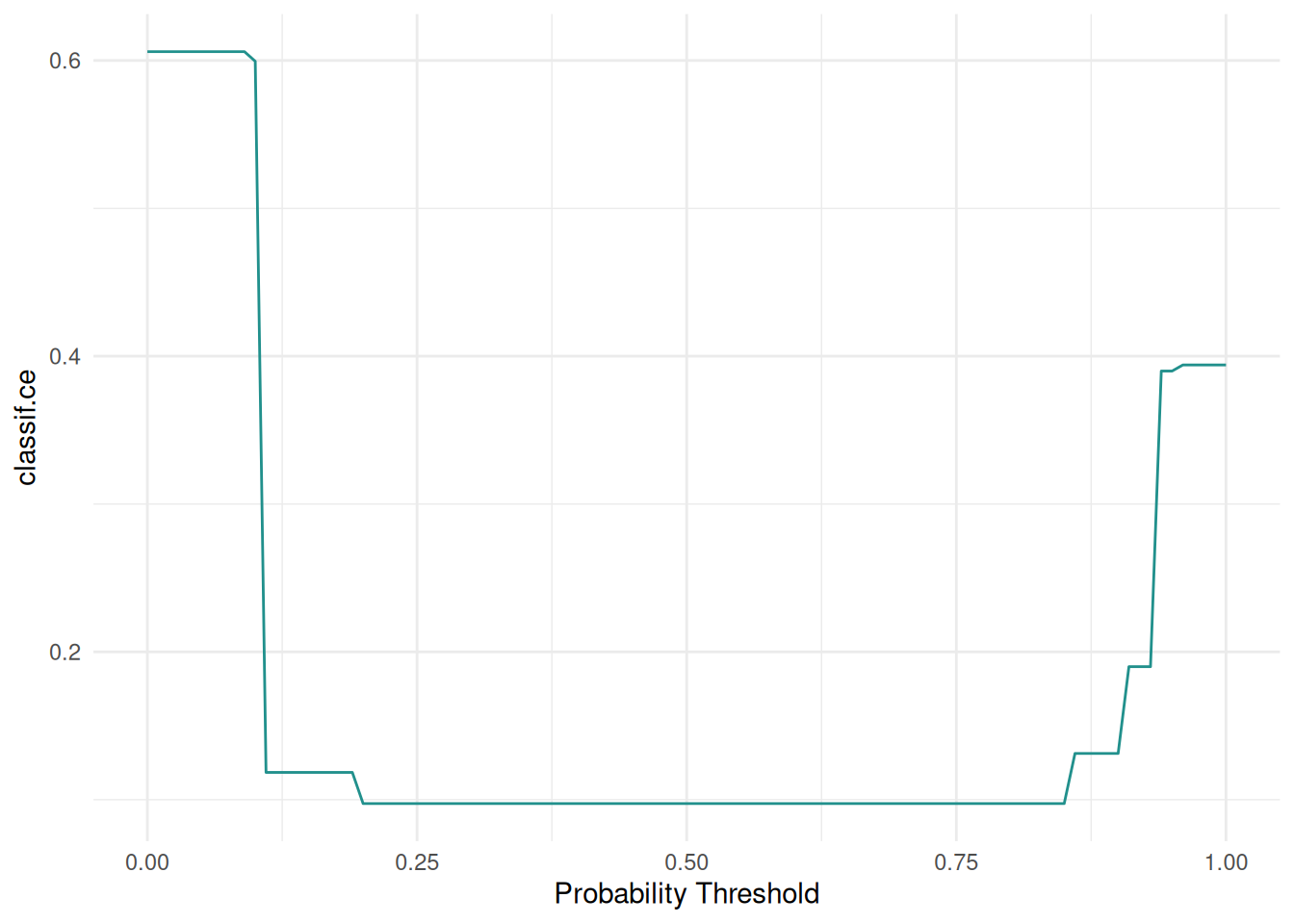
The predictions of a regression learner are often presented as a scatterplot of truth and predicted response.
+task = tsk("boston_housing")
+learner = lrn("regr.rpart")
+pred = learner$train(task)$predict(task)
+
+autoplot(pred, type = "xy")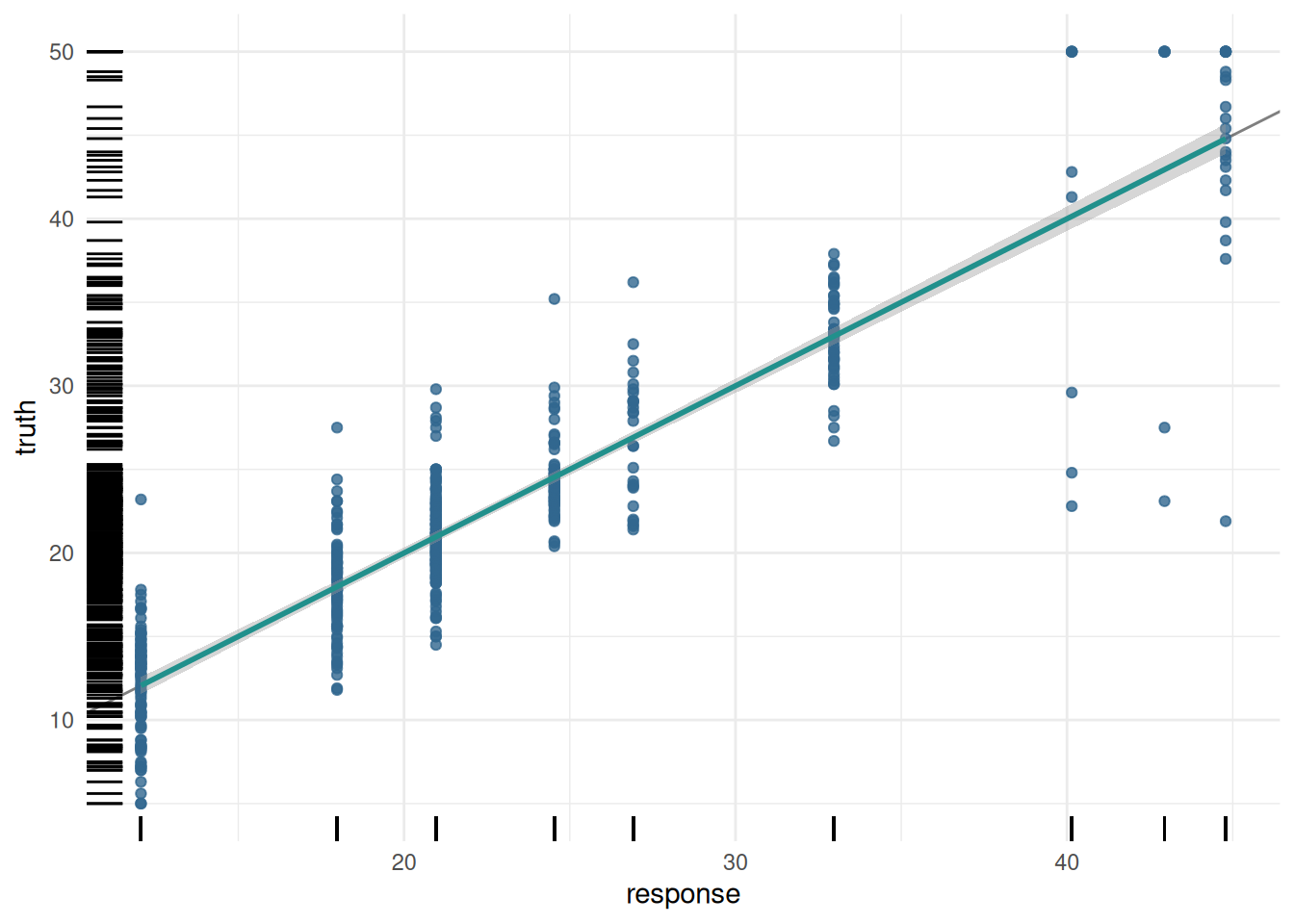
Additionally, we plot the response with the residuals.
+autoplot(pred, type = "residual")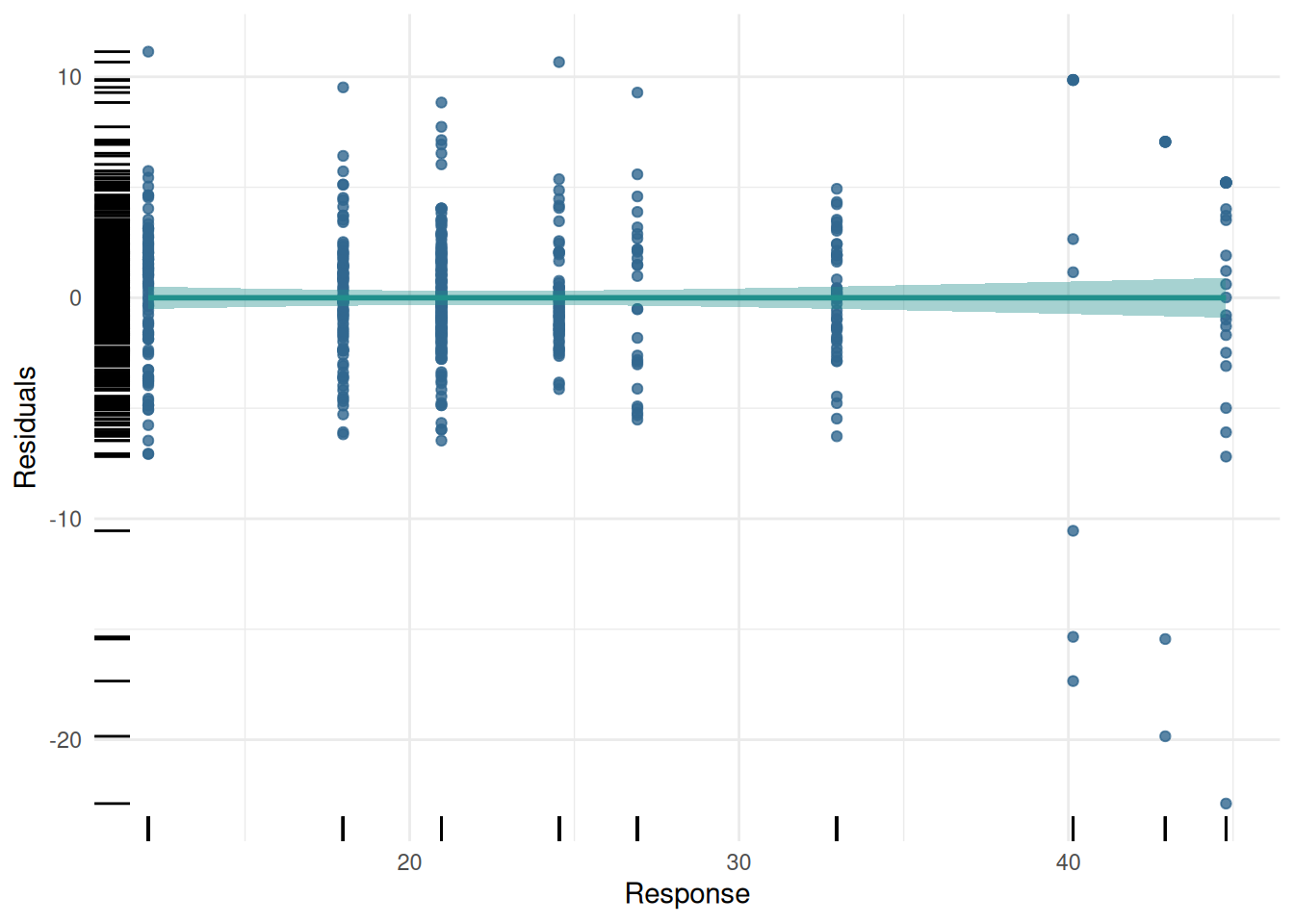
We can also plot the distribution of the residuals.
+autoplot(pred, type = "histogram")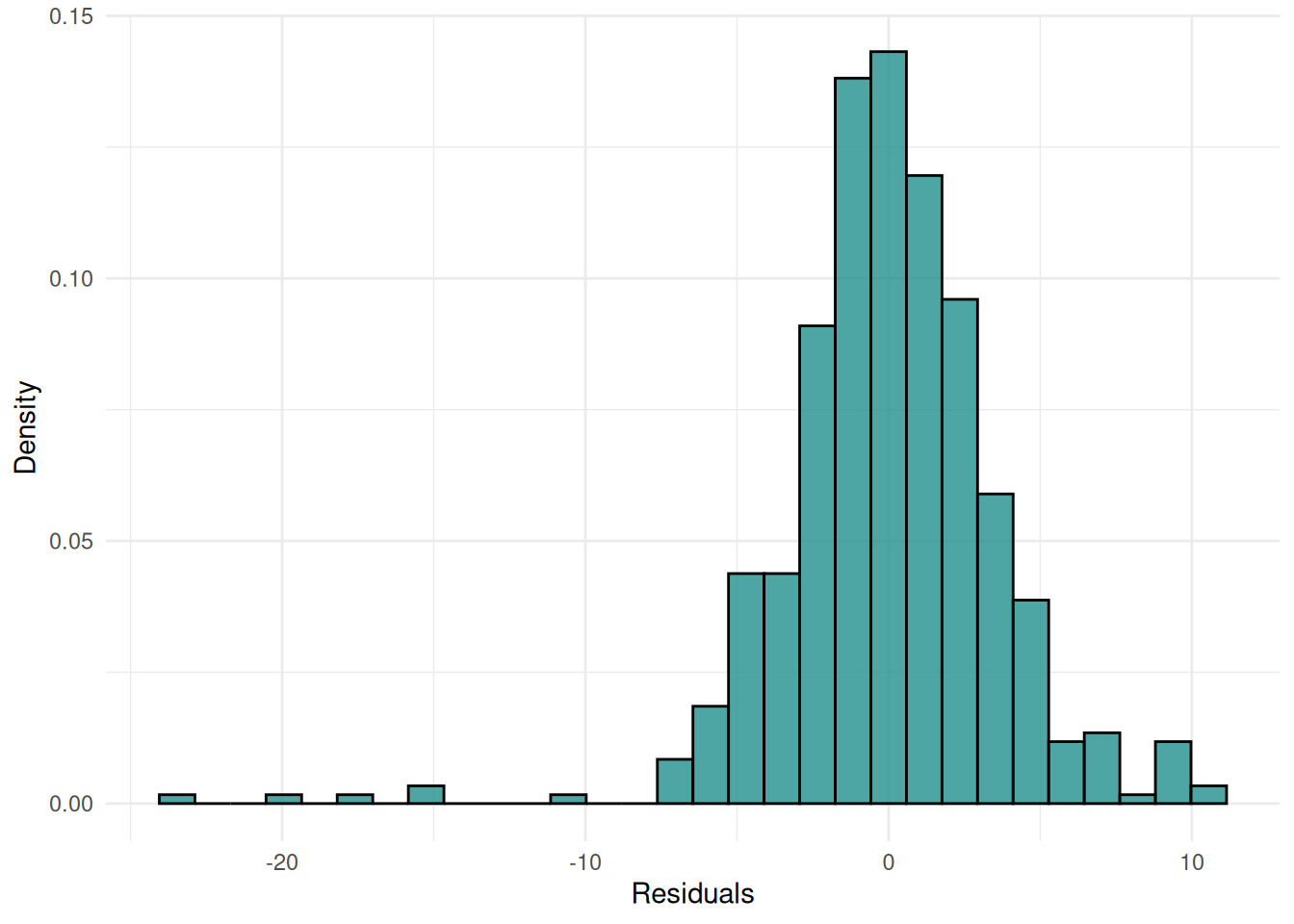
The predictions of a cluster learner are often presented as a scatterplot of the data points colored by the cluster.
+library(mlr3cluster)
+
+task = tsk("usarrests")
+learner = lrn("clust.kmeans", centers = 3)
+pred = learner$train(task)$predict(task)
+
+autoplot(pred, task, type = "scatter")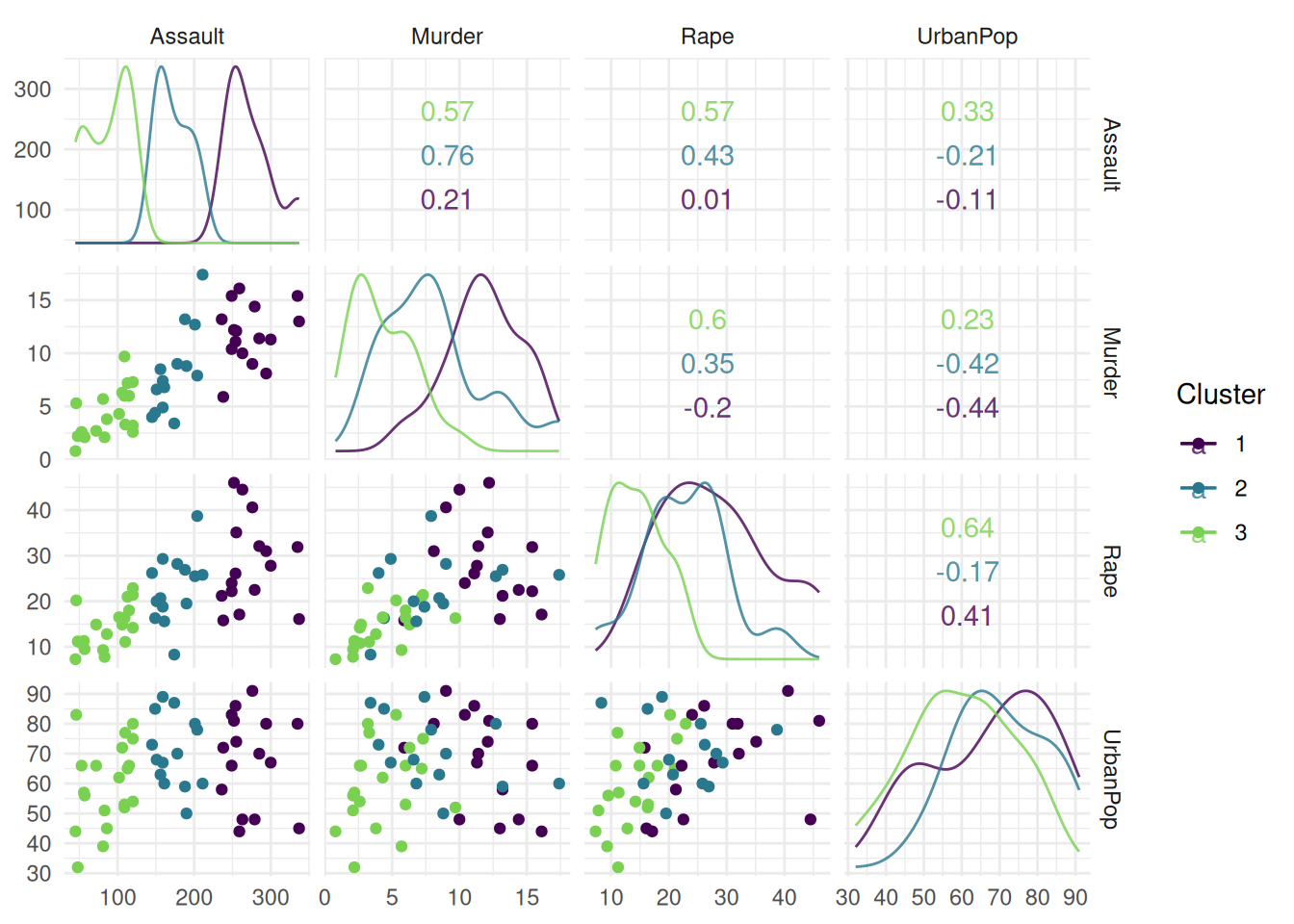
The "sil" plot shows the silhouette width of the clusters. The dashed line is the mean silhouette width.
autoplot(pred, task, type = "sil")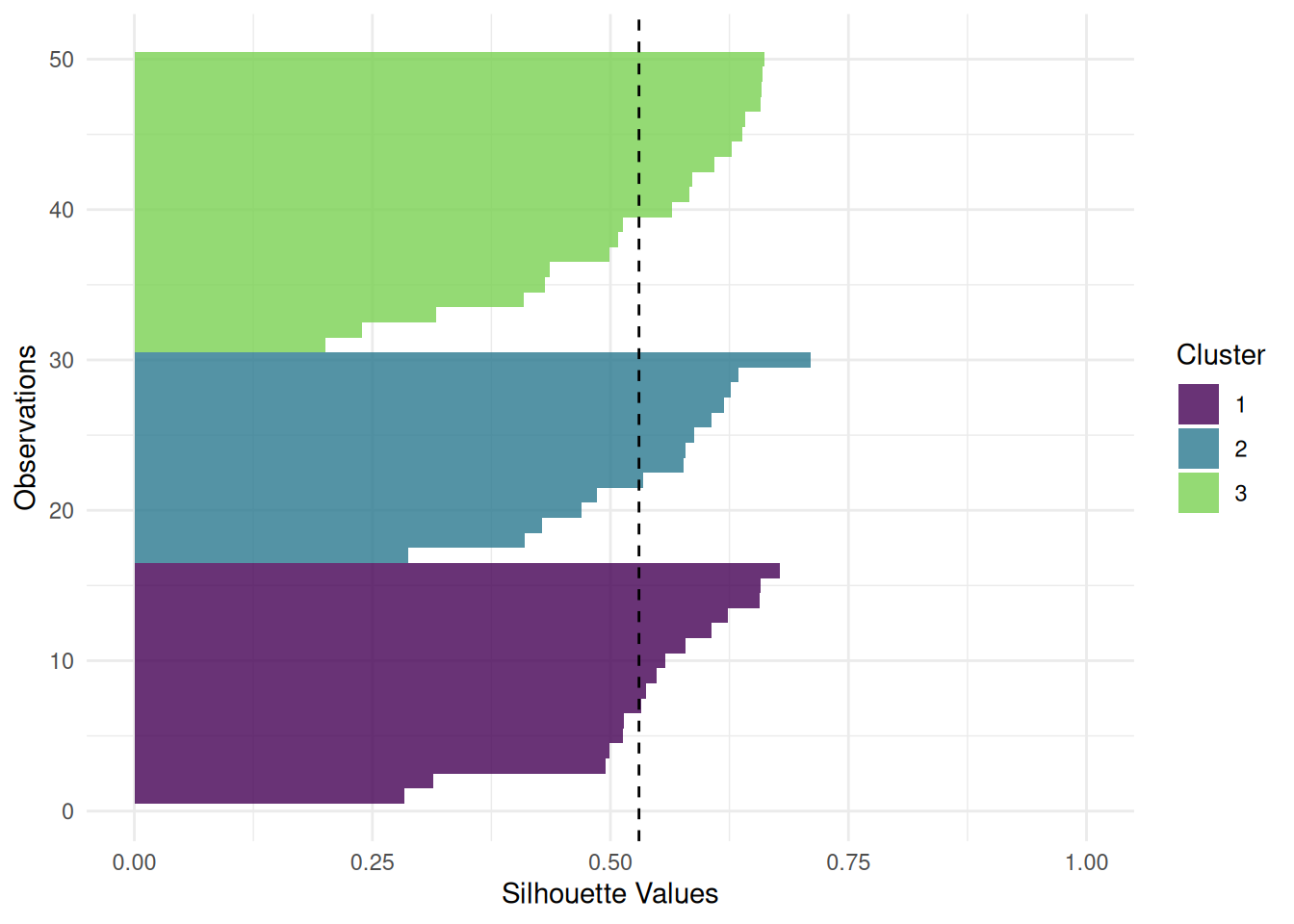
The "pca" plot shows the first two principal components of the data colored by the cluster.
autoplot(pred, task, type = "pca")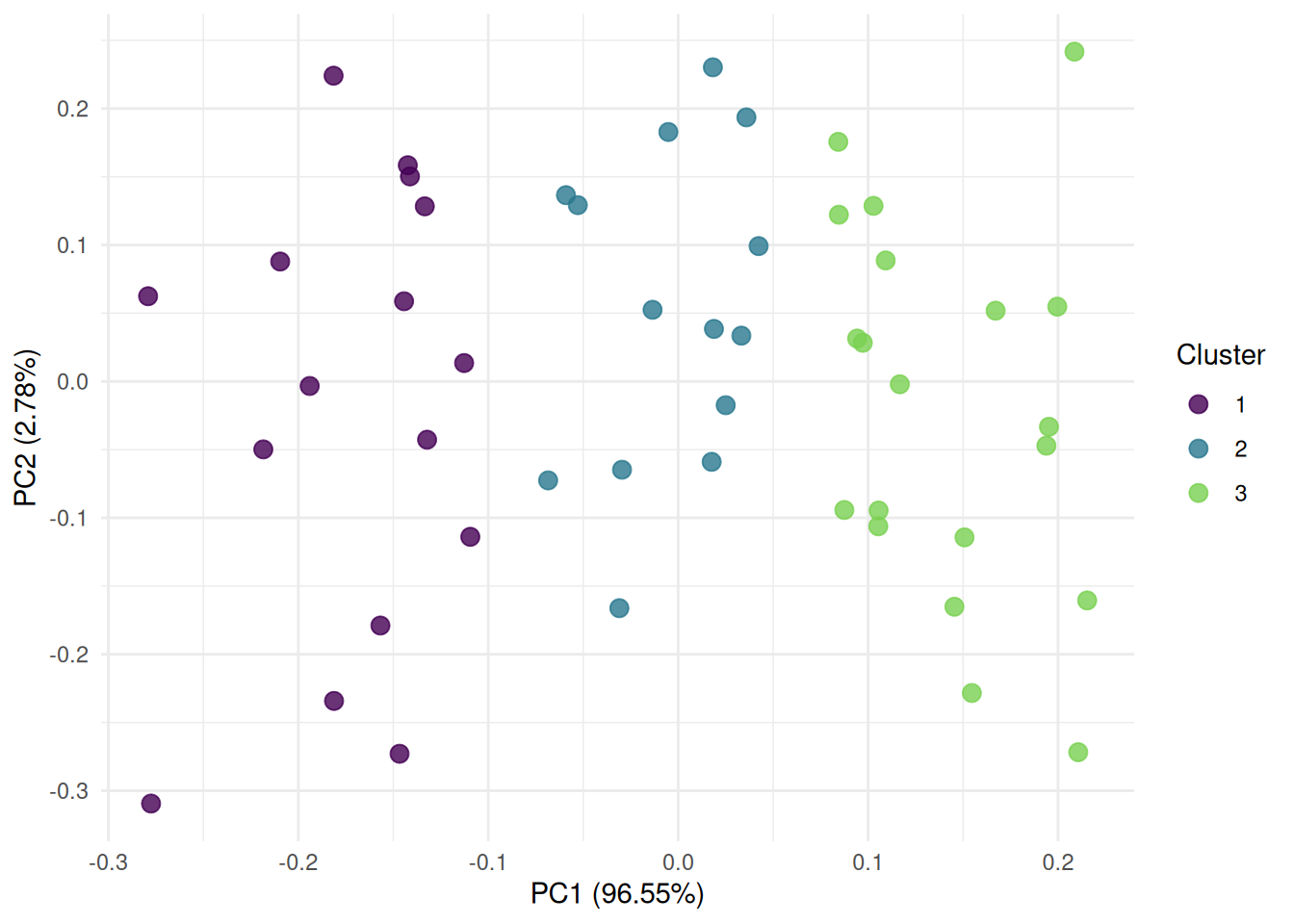
The "boxplot" shows the distribution of the performance measures.
task = tsk("sonar")
+learner = lrn("classif.rpart", predict_type = "prob")
+resampling = rsmp("cv")
+rr = resample(task, learner, resampling)
+
+autoplot(rr, type = "boxplot")
We can also plot the distribution of the performance measures as a “histogram”.
autoplot(rr, type = "histogram")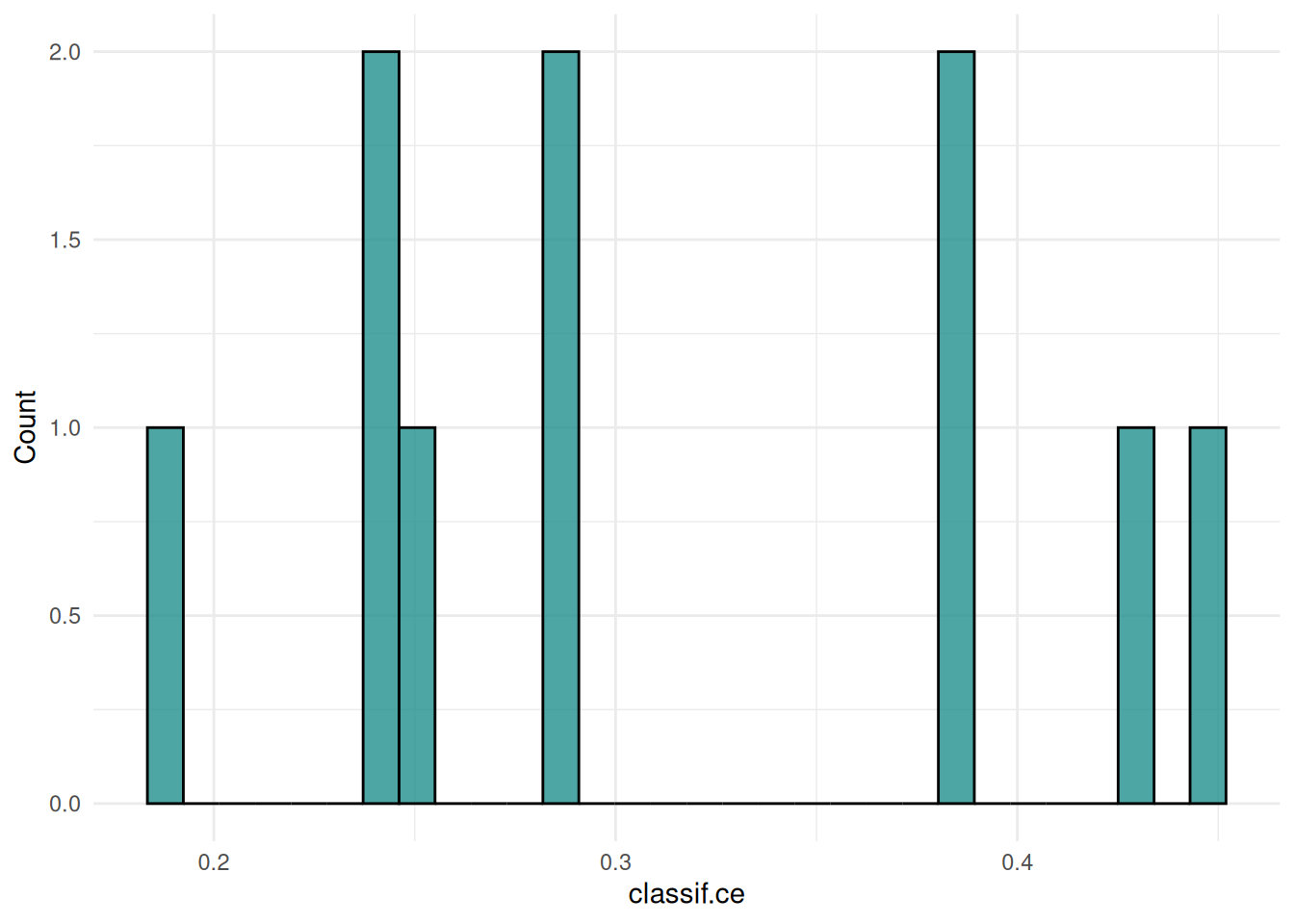
The ROC curve plots the true positive rate against the false positive rate at different thresholds.
+autoplot(rr, type = "roc")
The precision-recall curve plots the precision against the recall at different thresholds.
+autoplot(rr, type = "prc")
The "prediction" plot shows two features and the predicted class in the background. Points mark the observations of the test set and the color presents the truth.
task = tsk("pima")
+task$filter(seq(100))
+task$select(c("age", "glucose"))
+learner = lrn("classif.rpart")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")
Alternatively, we can plot class probabilities.
+task = tsk("pima")
+task$filter(seq(100))
+task$select(c("age", "glucose"))
+learner = lrn("classif.rpart", predict_type = "prob")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")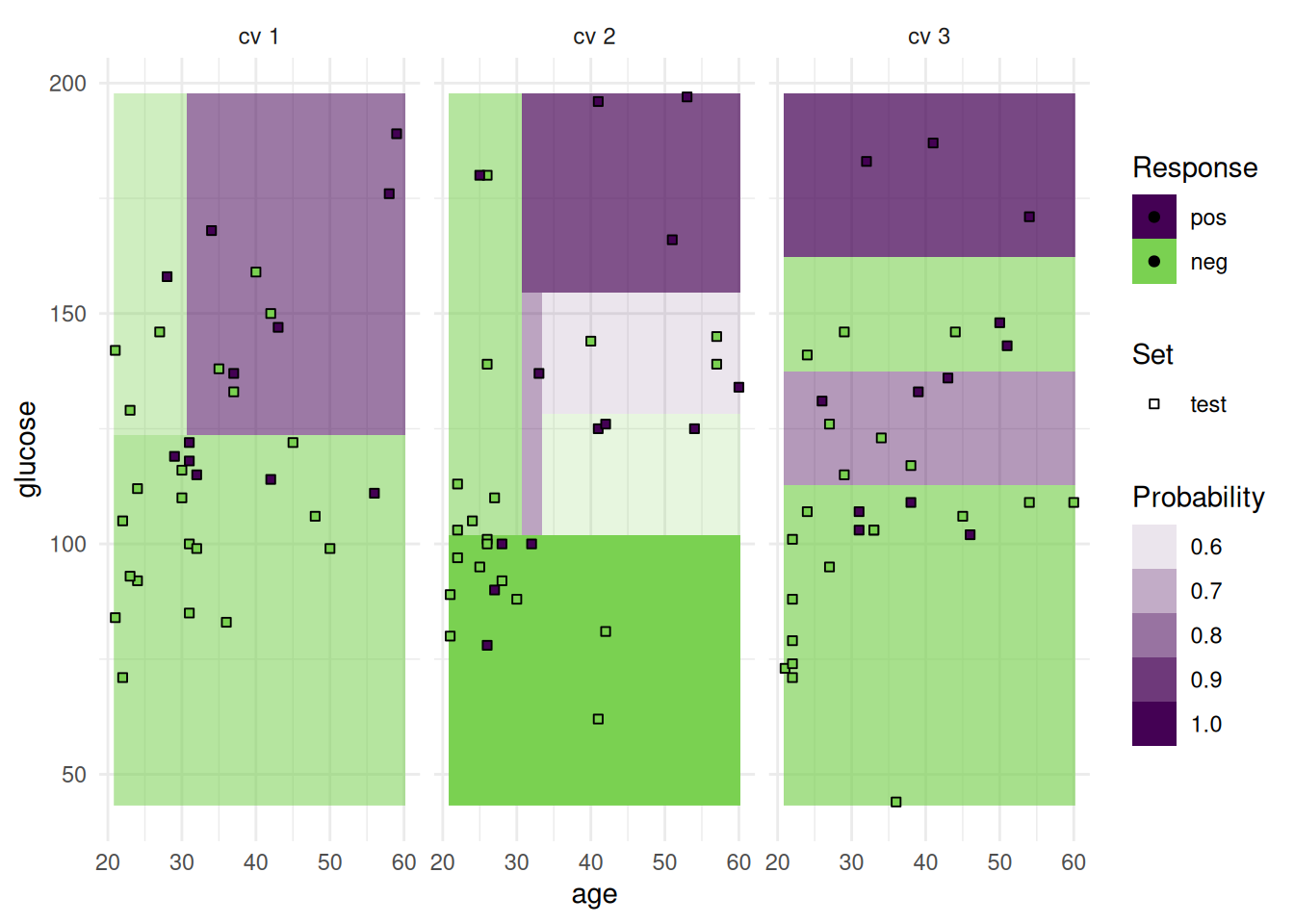
In addition to the test set, we can also plot the train set.
+task = tsk("pima")
+task$filter(seq(100))
+task$select(c("age", "glucose"))
+learner = lrn("classif.rpart", predict_type = "prob", predict_sets = c("train", "test"))
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction", predict_sets = c("train", "test"))
The "prediction" plot can also show categorical features.
task = tsk("german_credit")
+task$filter(seq(100))
+task$select(c("housing", "employment_duration"))
+learner = lrn("classif.rpart")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")
The “prediction” plot shows one feature and the response. Points mark the observations of the test set.
task = tsk("boston_housing")
+task$select("age")
+task$filter(seq(100))
+learner = lrn("regr.rpart")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")
Additionally, we can add confidence bounds.
+task = tsk("boston_housing")
+task$select("age")
+task$filter(seq(100))
+learner = lrn("regr.lm", predict_type = "se")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")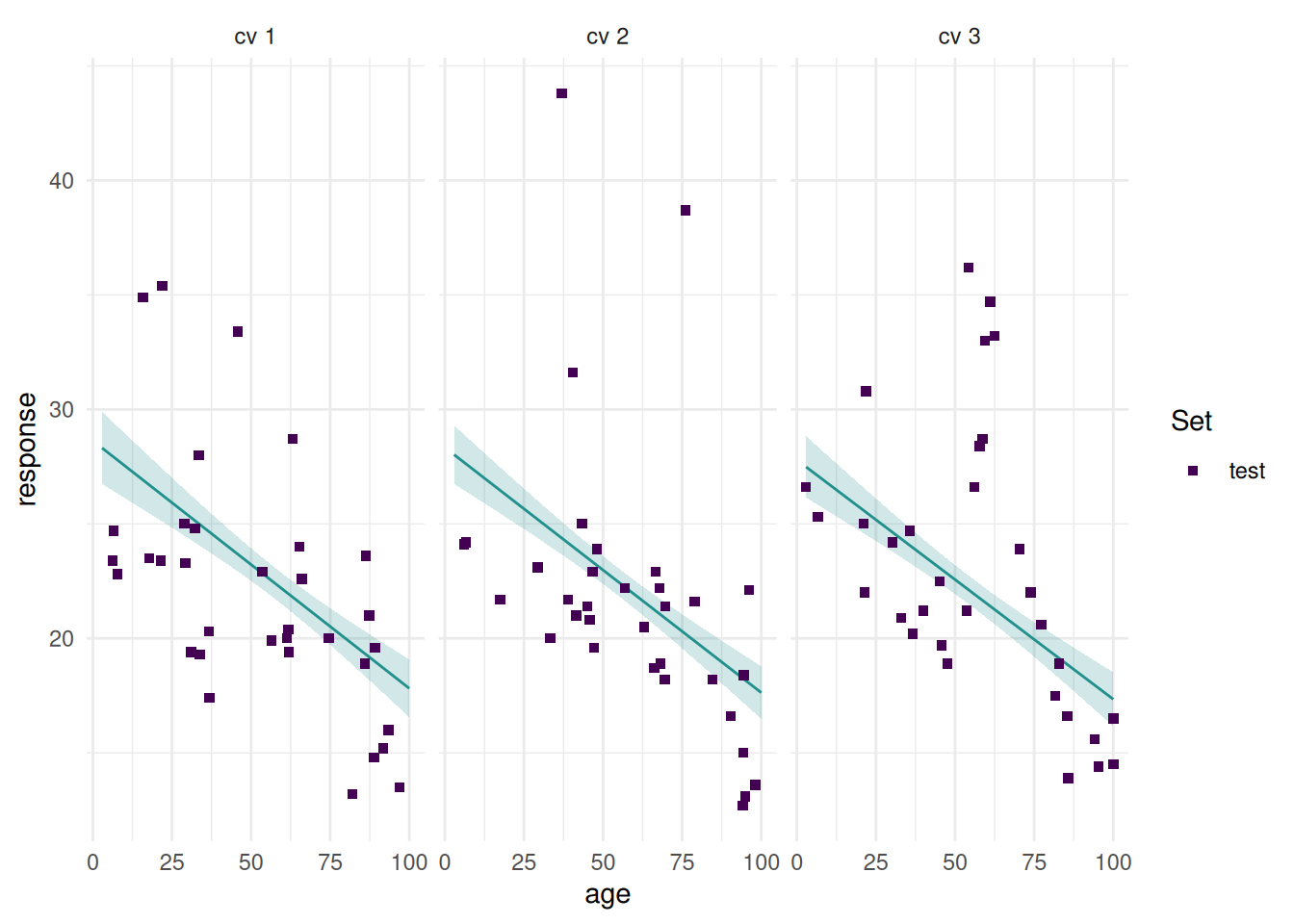
And add the train set.
+task = tsk("boston_housing")
+task$select("age")
+task$filter(seq(100))
+learner = lrn("regr.lm", predict_type = "se", predict_sets = c("train", "test"))
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction", predict_sets = c("train", "test"))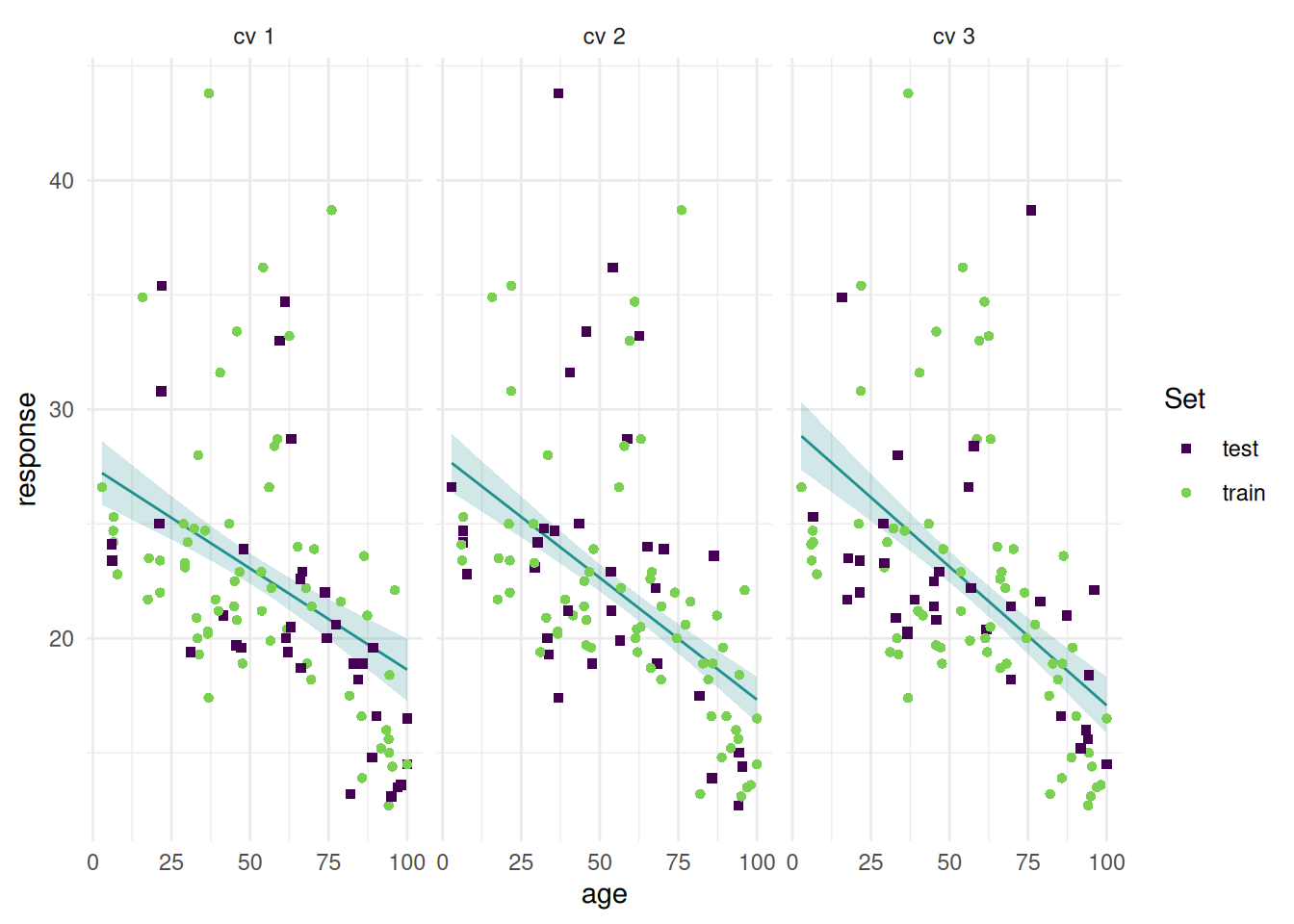
We can also add the prediction surface to the background.
+task = tsk("boston_housing")
+task$select(c("age", "rm"))
+task$filter(seq(100))
+learner = lrn("regr.rpart")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")
We show the performance distribution of a benchmark with multiple tasks.
+tasks = tsks(c("pima", "sonar"))
+learner = lrns(c("classif.featureless", "classif.rpart", "classif.xgboost"), predict_type = "prob")
+resampling = rsmps("cv")
+bmr = benchmark(benchmark_grid(tasks, learner, resampling))
+
+autoplot(bmr, type = "boxplot")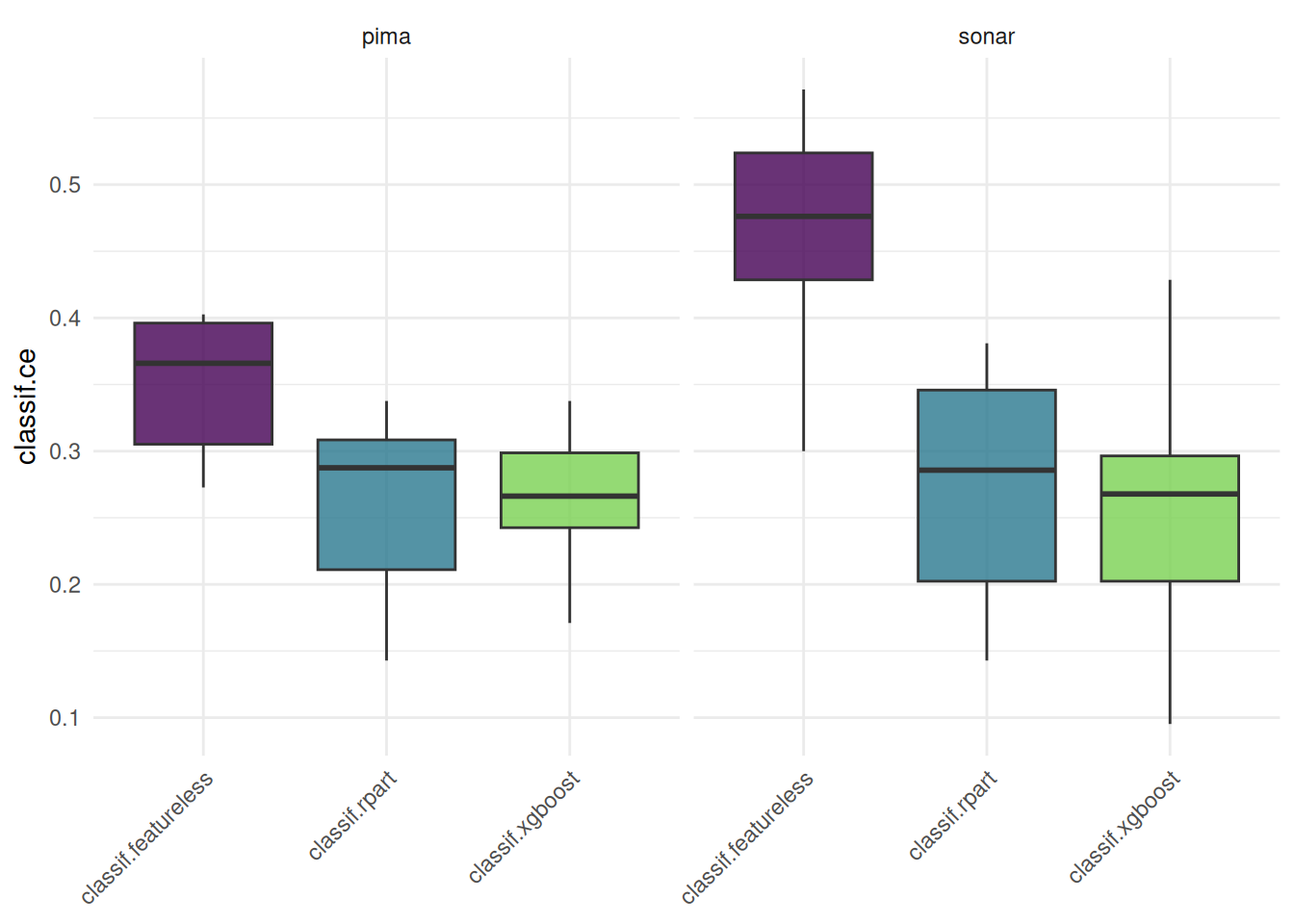
We plot a benchmark result with one task and multiple learners.
+tasks = tsk("pima")
+learner = lrns(c("classif.featureless", "classif.rpart", "classif.xgboost"), predict_type = "prob")
+resampling = rsmps("cv")
+bmr = benchmark(benchmark_grid(tasks, learner, resampling))We plot an roc curve for each learner.
+autoplot(bmr, type = "roc")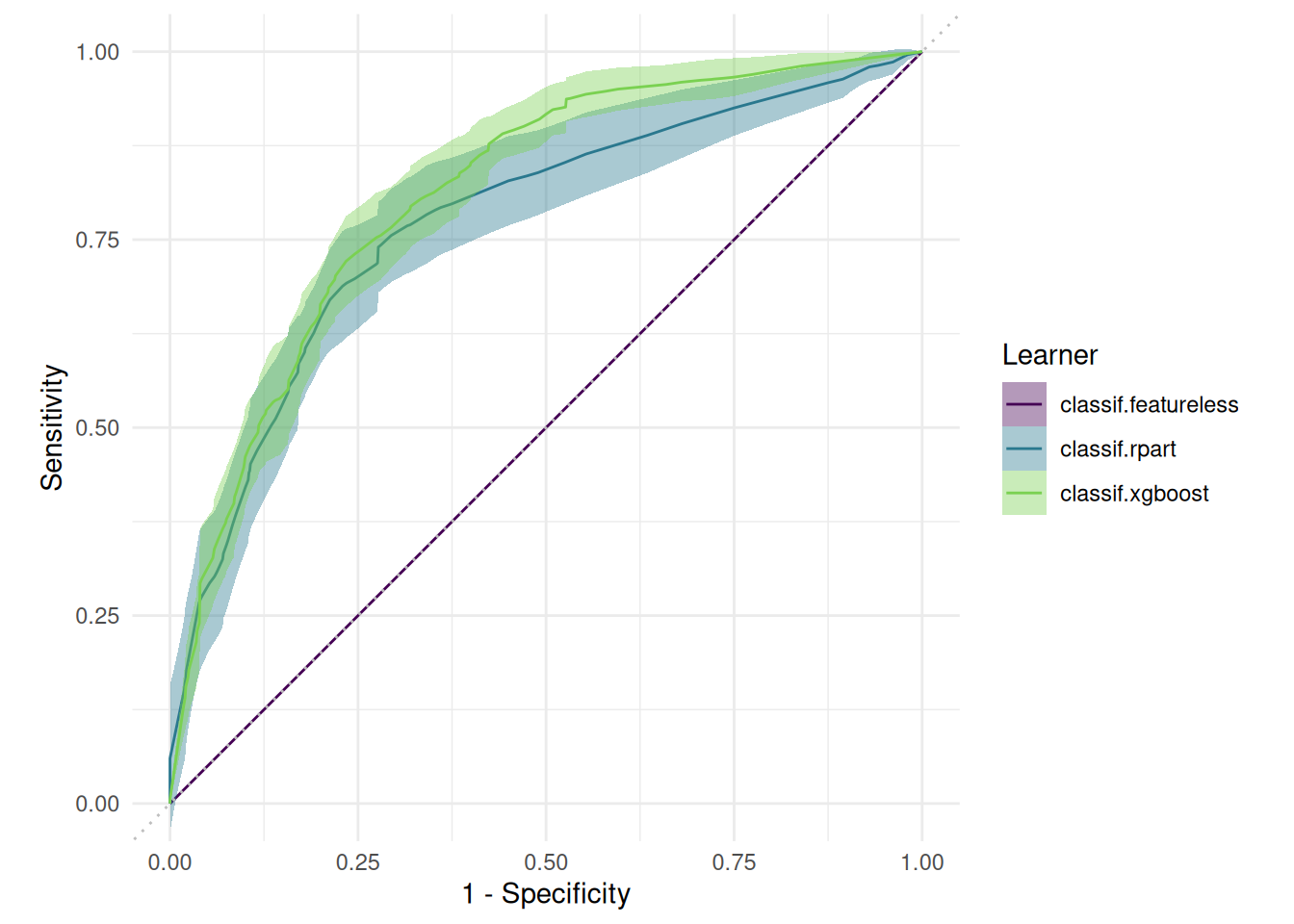
Alternatively, we can plot precision-recall curves.
+autoplot(bmr, type = "prc")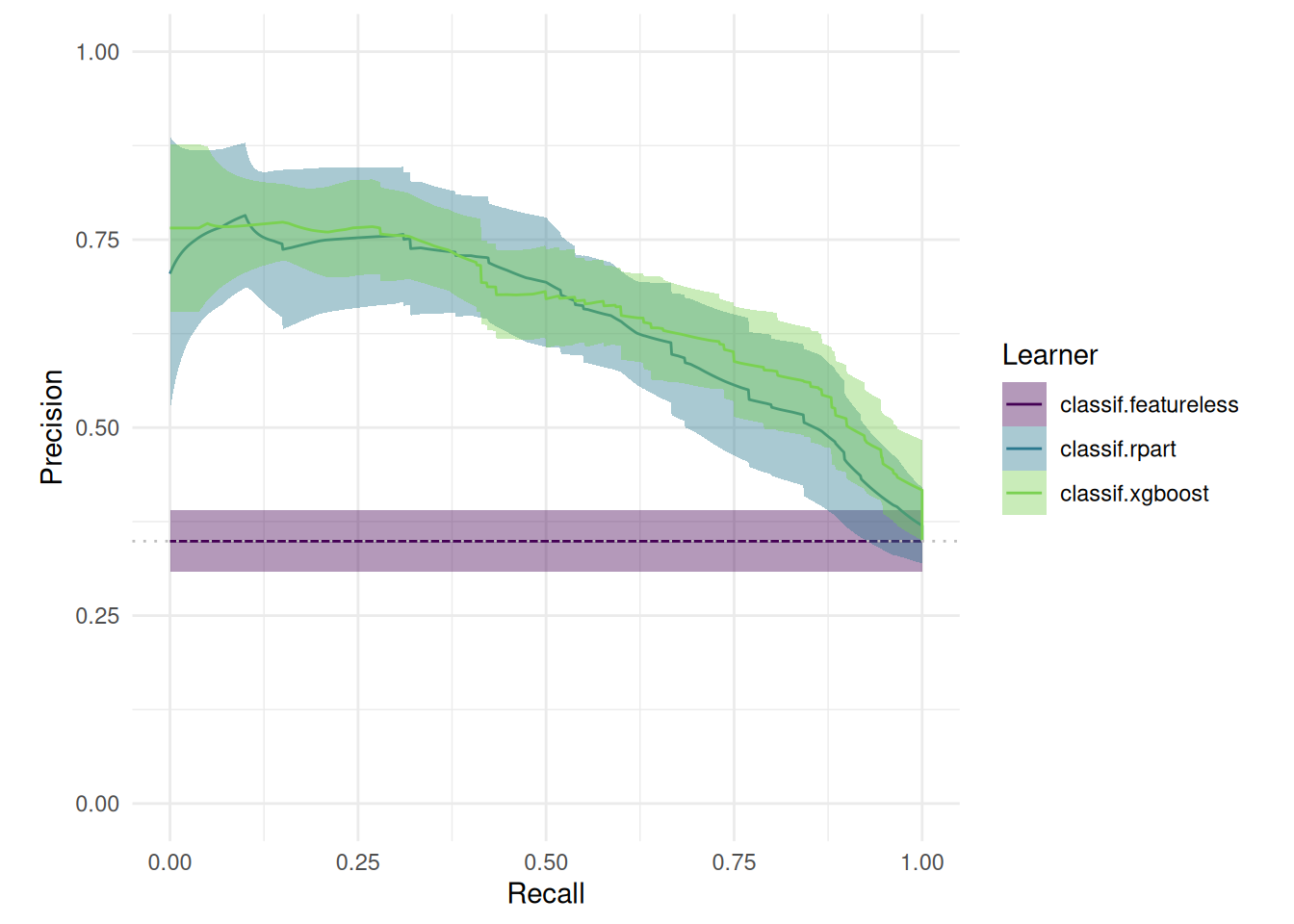
We tune the hyperparameters of a decision tree on the sonar task. The "performance" plot shows the performance over batches.
library(mlr3tuning)
+library(mlr3tuningspaces)
+library(mlr3learners)
+
+instance = tune(
+ tuner = tnr("gensa"),
+ task = tsk("sonar"),
+ learner = lts(lrn("classif.rpart")),
+ resampling = rsmp("holdout"),
+ measures = msr("classif.ce"),
+ term_evals = 100
+)
+
+autoplot(instance, type = "performance")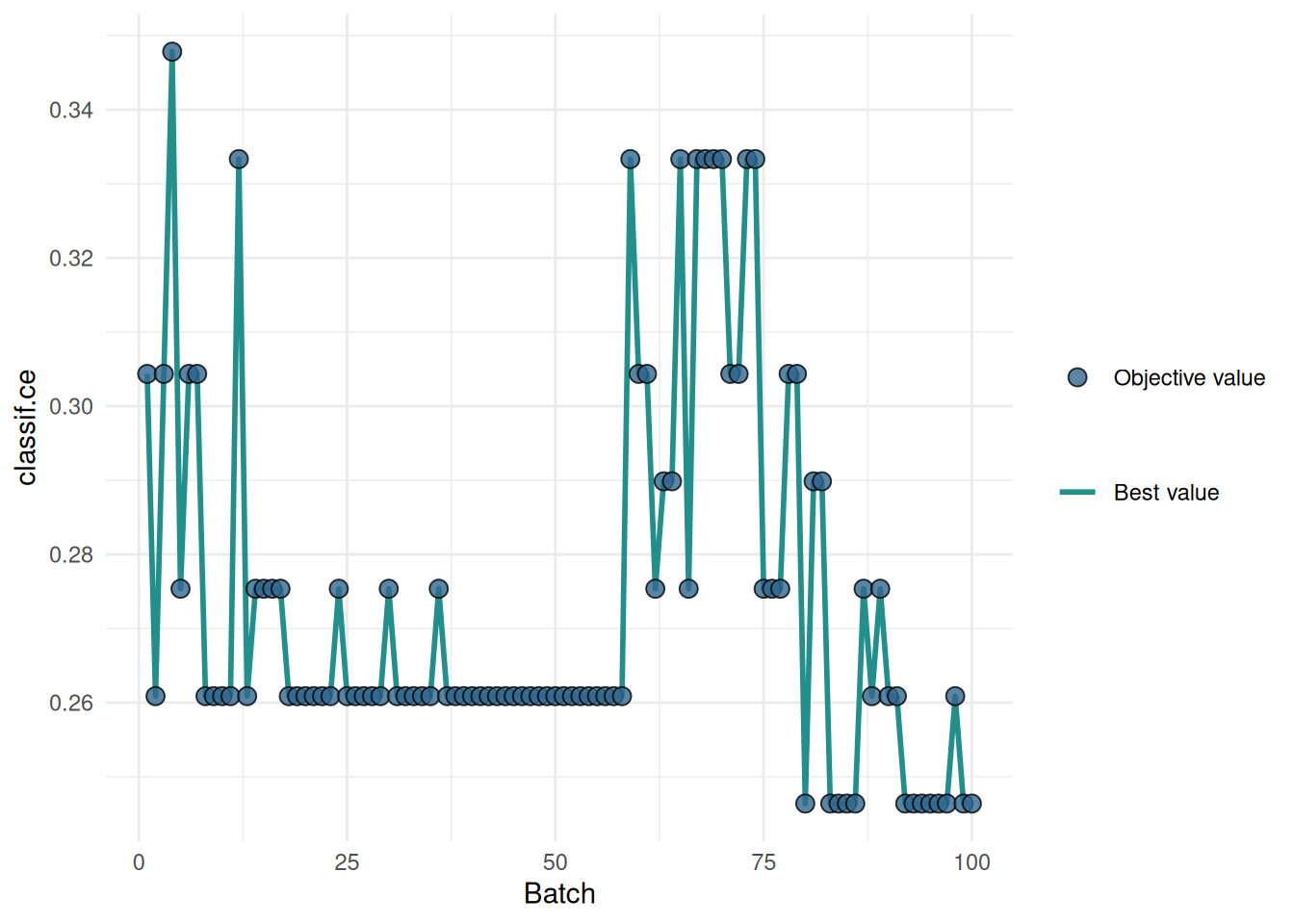
The "incumbent" plot shows the performance of the best hyperparameter setting over the number of evaluations.
autoplot(instance, type = "incumbent")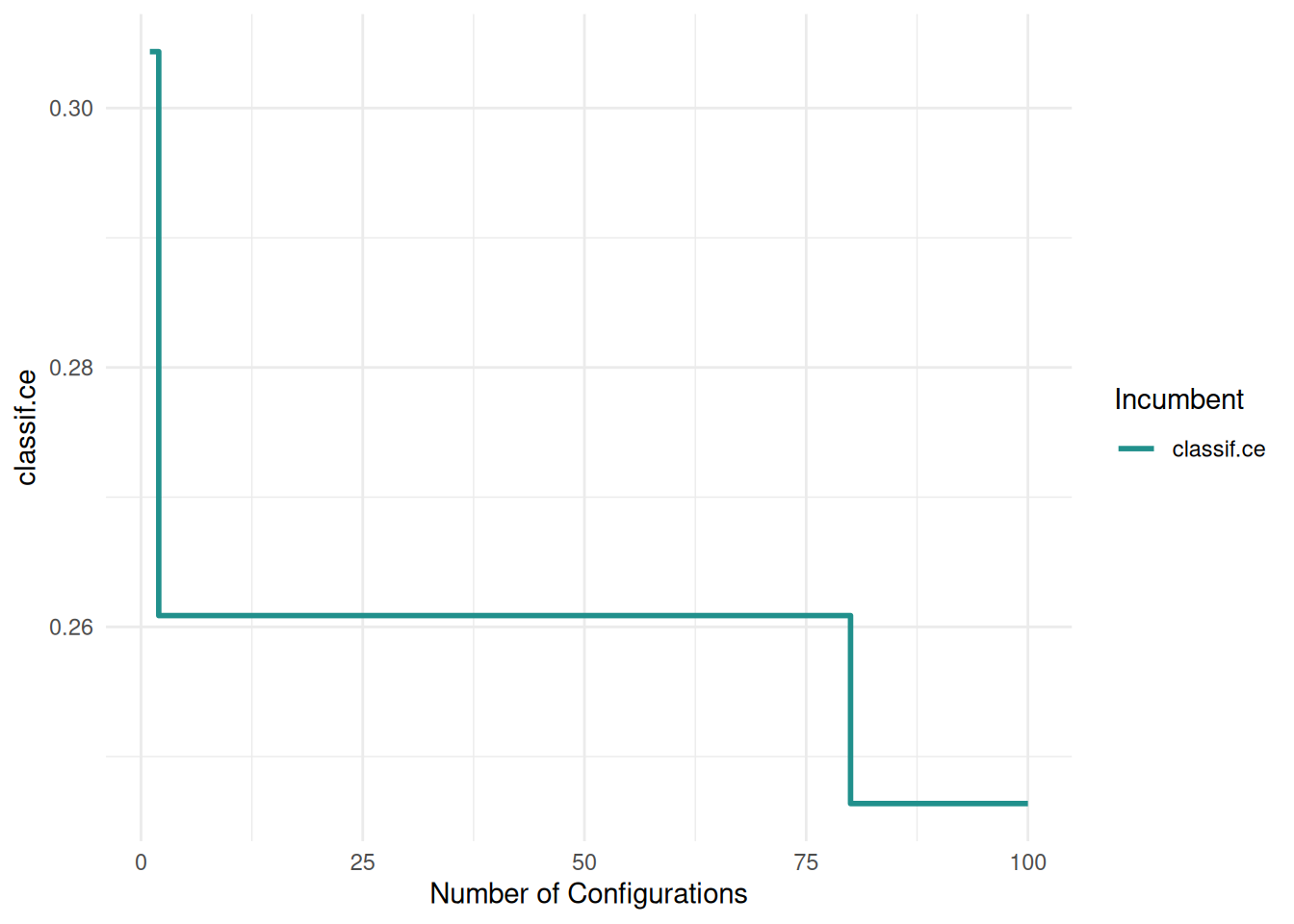
The "parameter" plot shows the performance for each hyperparameter setting.
autoplot(instance, type = "parameter", cols_x = c("cp", "minsplit"))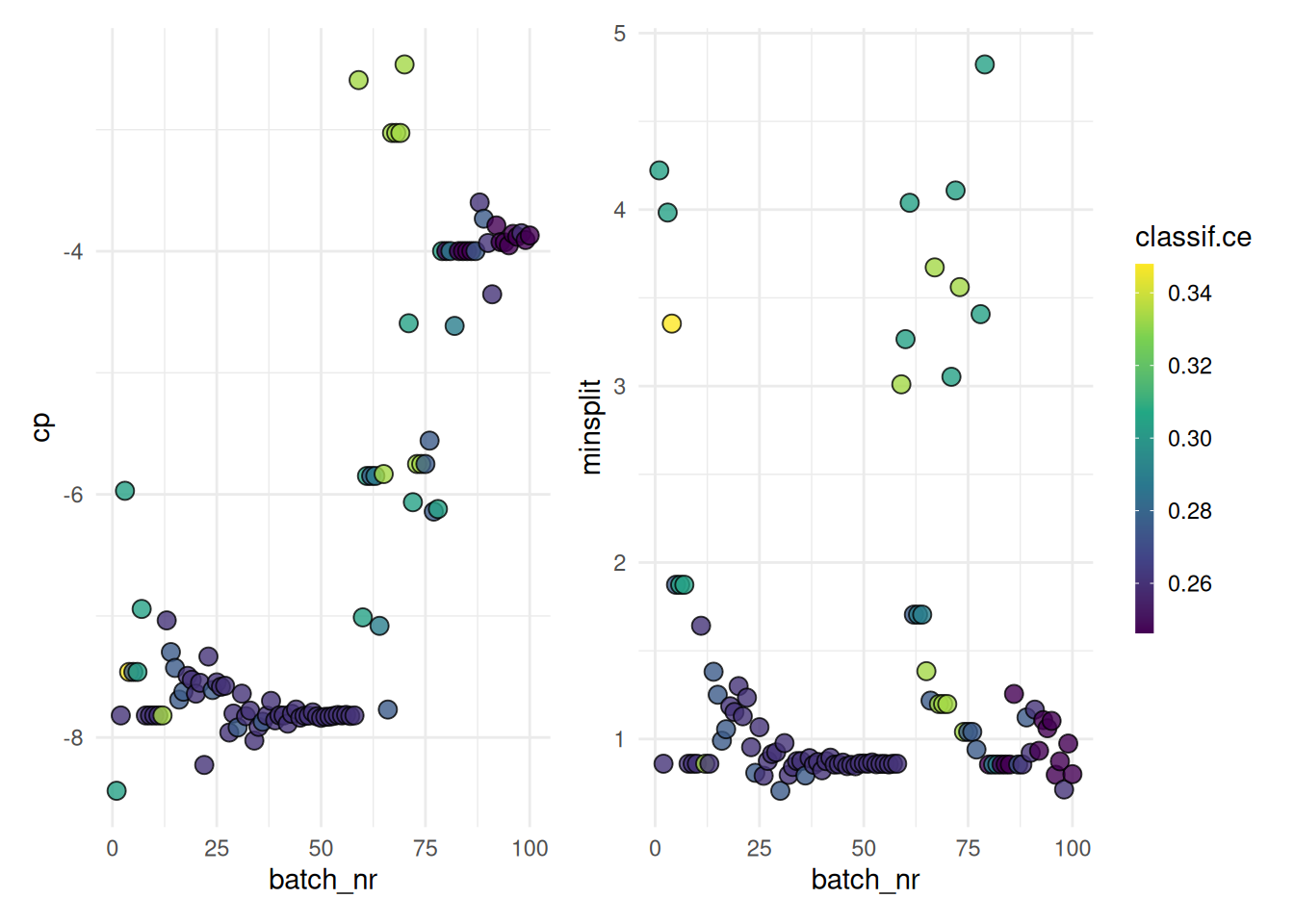
The "marginal" plot shows the performance of different hyperparameter values. The color indicates the batch.
autoplot(instance, type = "marginal", cols_x = "cp")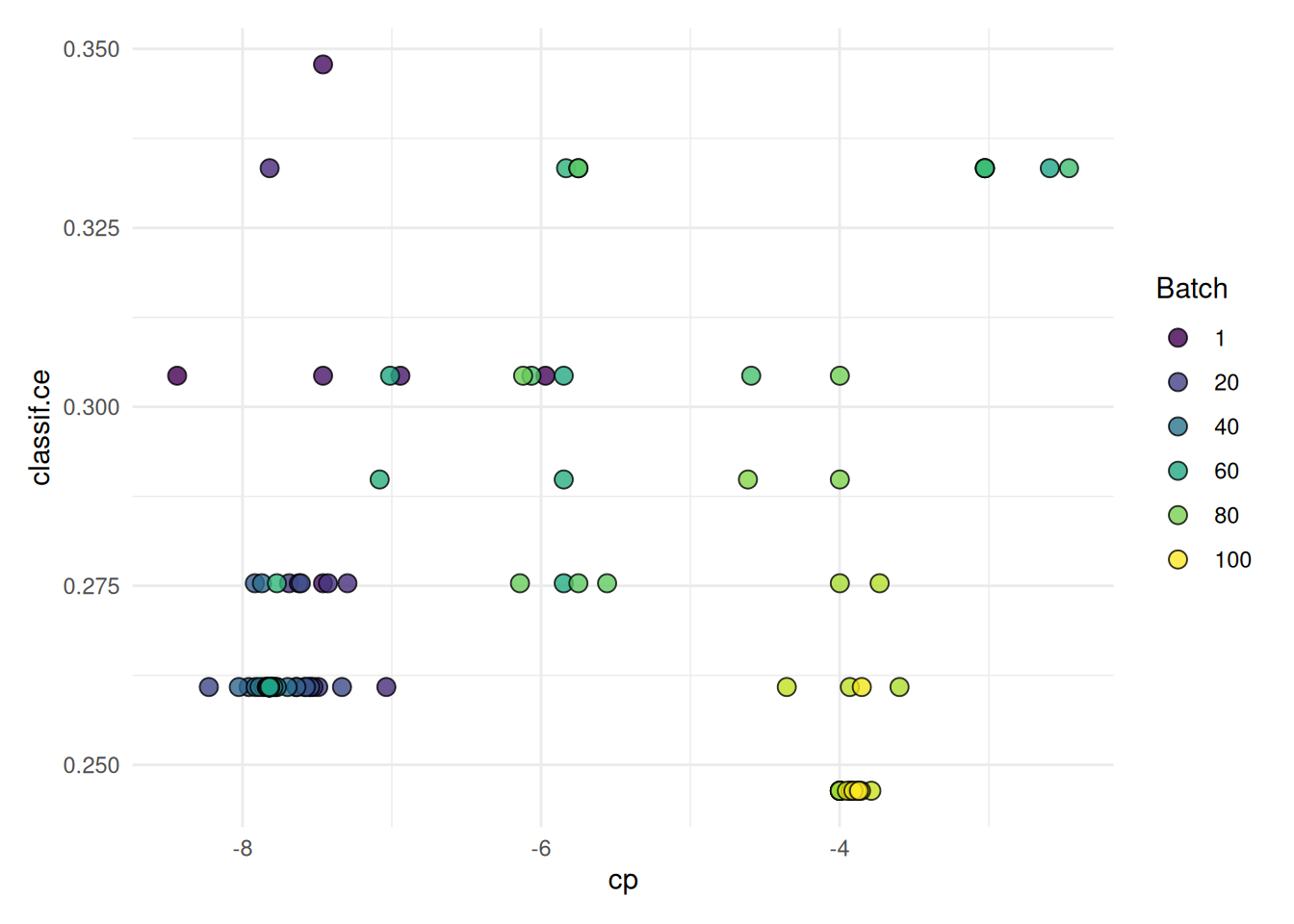
The "parallel" plot visualizes the relationship of hyperparameters.
autoplot(instance, type = "parallel")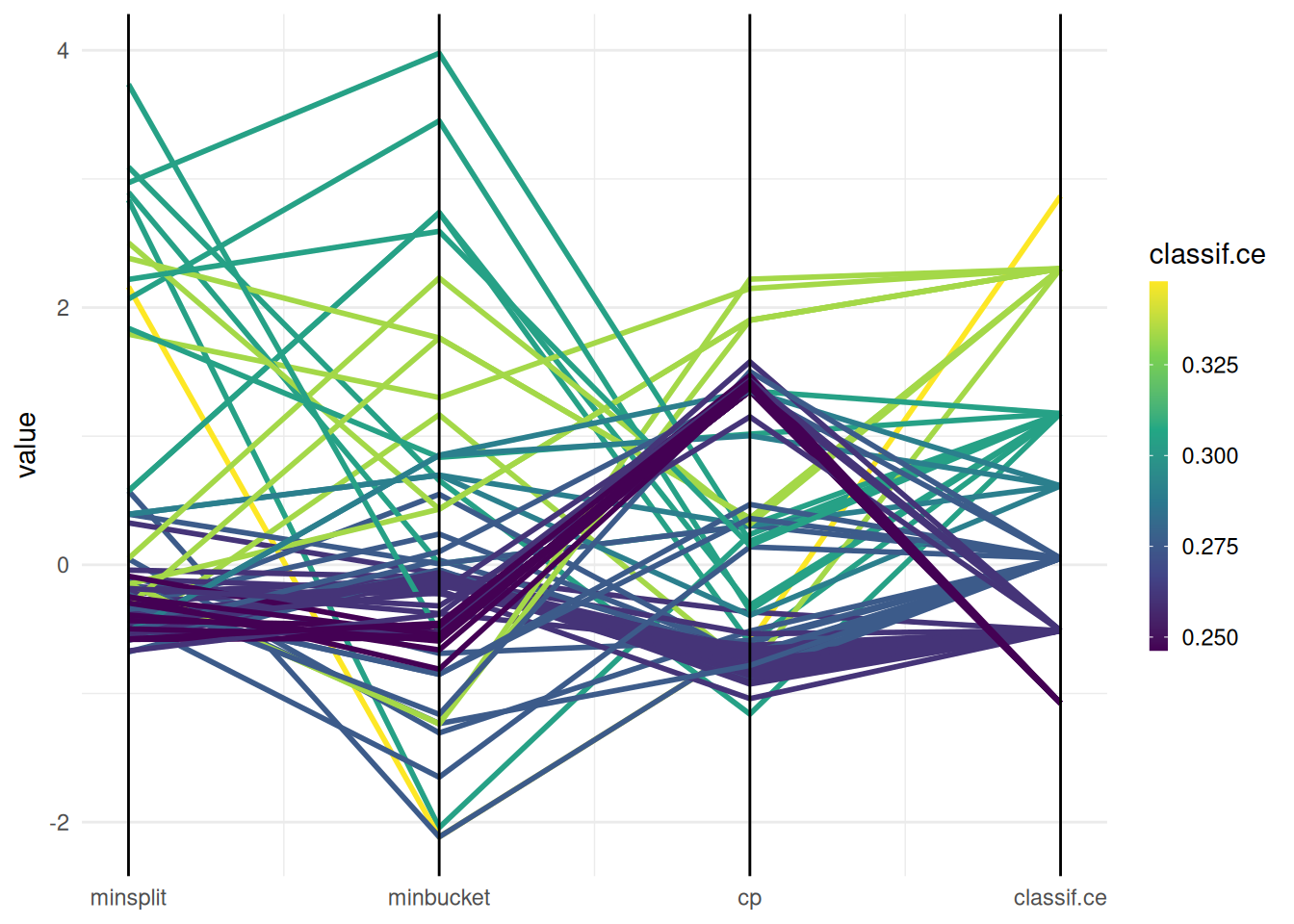
We plot cp against minsplit and color the points by the performance.
autoplot(instance, type = "points", cols_x = c("cp", "minsplit"))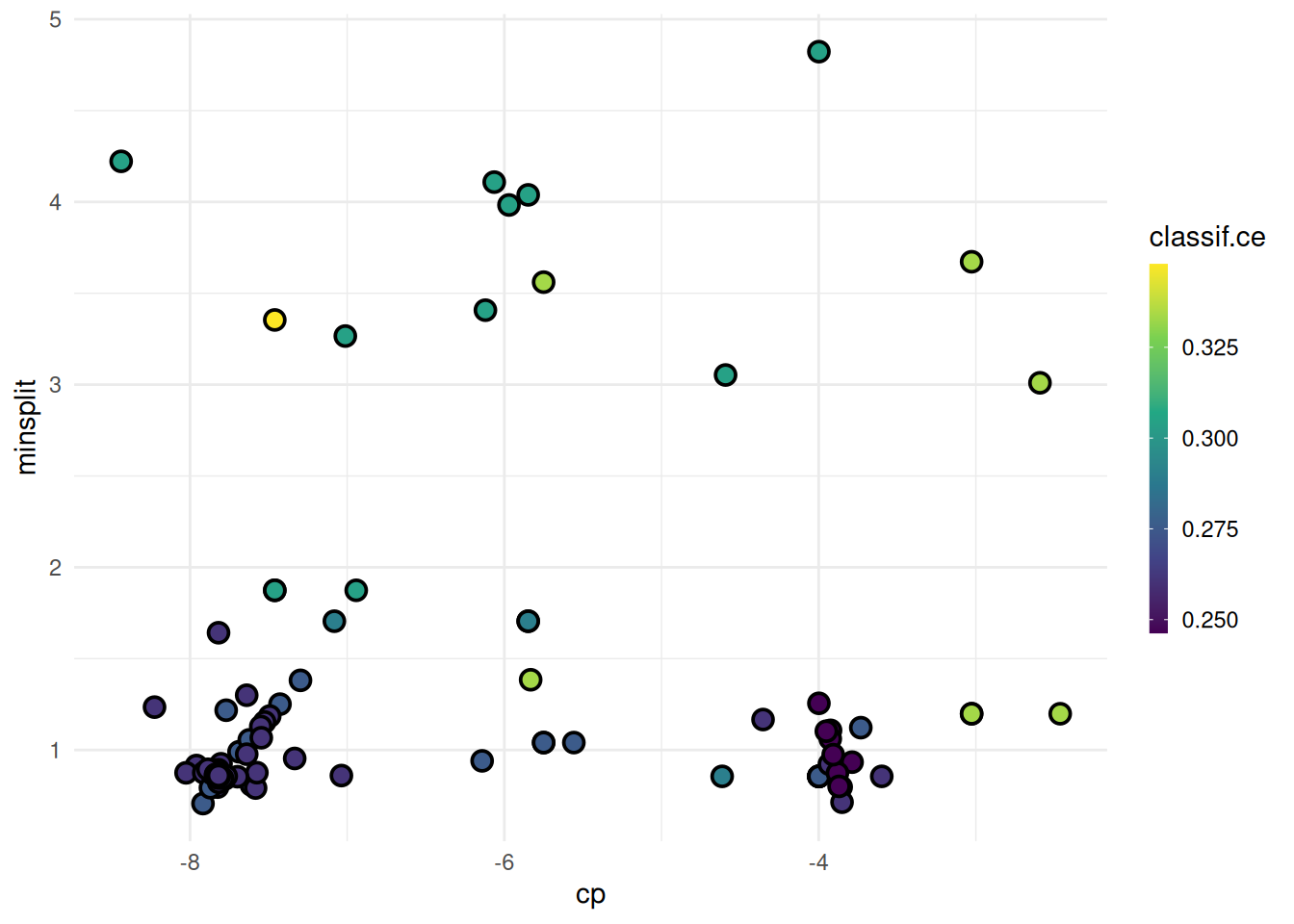
Next, we plot all hyperparameters against each other.
+autoplot(instance, type = "pairs")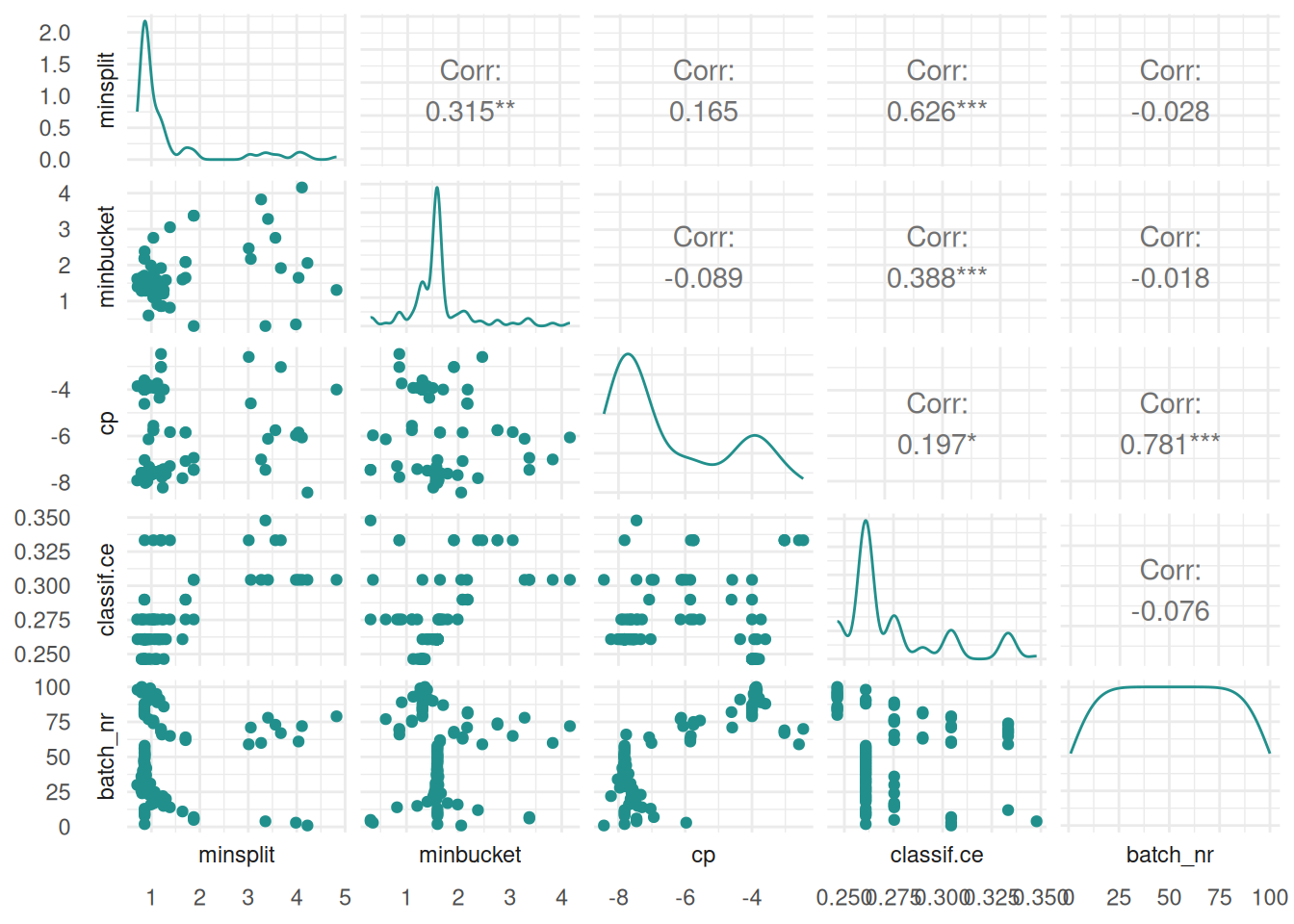
We plot the performance surface of two hyperparameters. The surface is interpolated with a learner.
+autoplot(instance, type = "surface", cols_x = c("cp", "minsplit"), learner = mlr3::lrn("regr.ranger"))
We plot filter scores for the mtcars task.
+library(mlr3filters)
+
+task = tsk("mtcars")
+f = flt("correlation")
+f$calculate(task)
+
+autoplot(f, n = 5)
The mlr3viz package brings together the visualization functions of the mlr3 ecosystem. All plots are drawn with the autoplot() function and the appearance can be customized with the theme argument. If you need to highly customize a plot e.g. for a publication, we encourage you to check our code on GitHub. The code should be easily adaptable to your needs. We are also looking forward to new visualizations. You can suggest new plots in an issue on GitHub.
In this post, we optimize the hyperparameters of a simple classification tree on the Palmer Penguins data set with only a few lines of code.
First, we introduce tuning spaces and show the importance of transformation functions. Next, we execute the tuning and present the basic building blocks of tuning in mlr3. Finally, we fit a classification tree with optimized hyperparameters on the full data set.
+ +We load the mlr3verse package which pulls the most important packages for this example. Among other packages, it loads the hyperparameter optimization package of the mlr3 ecosystem mlr3tuning.
+library(mlr3verse)In this example, we use the Palmer Penguins data set which classifies 344 penguins in three species. The data set was collected from 3 islands in the Palmer Archipelago in Antarctica. It includes the name of the island, the size (flipper length, body mass, and bill dimension), and the sex of the penguin.
tsk("penguins")<TaskClassif:penguins> (344 x 8): Palmer Penguins
+* Target: species
+* Properties: multiclass
+* Features (7):
+ - int (3): body_mass, flipper_length, year
+ - dbl (2): bill_depth, bill_length
+ - fct (2): island, sexlibrary(palmerpenguins)
+library(ggplot2)
+ggplot(data = penguins, aes(x = flipper_length_mm, y = bill_length_mm)) +
+ geom_point(aes(color = species, shape = species), size = 3, alpha = 0.8) +
+ geom_smooth(method = "lm", se = FALSE, aes(color = species)) +
+ theme_minimal() +
+ scale_color_manual(values = c("darkorange","purple","cyan4")) +
+ labs(x = "Flipper length (mm)", y = "Bill length (mm)", color = "Penguin species", shape = "Penguin species") +
+ theme(
+ legend.position = c(0.85, 0.15),
+ legend.background = element_rect(fill = "white", color = NA),
+ text = element_text(size = 10))
We use the rpart classification tree. A learner stores all information about its hyperparameters in the slot $param_set. Not all parameters are tunable. We have to choose a subset of the hyperparameters we want to tune.
learner = lrn("classif.rpart")
+as.data.table(learner$param_set)[, list(id, class, lower, upper, nlevels)] id class lower upper nlevels
+ <char> <char> <num> <num> <num>
+ 1: cp ParamDbl 0 1 Inf
+ 2: keep_model ParamLgl NA NA 2
+ 3: maxcompete ParamInt 0 Inf Inf
+ 4: maxdepth ParamInt 1 30 30
+ 5: maxsurrogate ParamInt 0 Inf Inf
+ 6: minbucket ParamInt 1 Inf Inf
+ 7: minsplit ParamInt 1 Inf Inf
+ 8: surrogatestyle ParamInt 0 1 2
+ 9: usesurrogate ParamInt 0 2 3
+10: xval ParamInt 0 Inf InfThe package mlr3tuningspaces is a collection of search spaces for hyperparameter tuning from peer-reviewed articles. We use the search space from the Bischl et al. (2021) article.
+lts("classif.rpart.default")<TuningSpace:classif.rpart.default>: Classification Rpart with Default
+ id lower upper levels logscale
+ <char> <num> <num> <list> <lgcl>
+1: minsplit 2e+00 128.0 TRUE
+2: minbucket 1e+00 64.0 TRUE
+3: cp 1e-04 0.1 TRUEThe classification tree is mainly influenced by three hyperparameters:
+cp that controls when the learner considers introducing another branch.minsplit hyperparameter that controls how many observations must be present in a leaf for another split to be attempted.minbucket hyperparameter that the minimum number of observations in any terminal node.We argument the learner with the search space in one go.
+lts(lrn("classif.rpart"))<LearnerClassifRpart:classif.rpart>: Classification Tree
+* Model: -
+* Parameters: xval=0, minsplit=<RangeTuneToken>, minbucket=<RangeTuneToken>, cp=<RangeTuneToken>
+* Packages: mlr3, rpart
+* Predict Types: [response], prob
+* Feature Types: logical, integer, numeric, factor, ordered
+* Properties: importance, missings, multiclass, selected_features, twoclass, weightsThe column logscale indicates that the hyperparameters are tuned on the logarithmic scale. The tuning algorithm proposes hyperparameter values that are transformed with the exponential function before they are passed to the learner. For example, the cp parameter is bounded between 0 and 1. The tuning algorithm searches between log(1e-04) and log(1e-01) but the learner gets the transformed values between 1e-04 and 1e-01. Using the log transformation emphasizes smaller cp values but also creates large values.
lts("classif.rpart.default")<TuningSpace:classif.rpart.default>: Classification Rpart with Default
+ id lower upper levels logscale
+ <char> <num> <num> <list> <lgcl>
+1: minsplit 2e+00 128.0 TRUE
+2: minbucket 1e+00 64.0 TRUE
+3: cp 1e-04 0.1 TRUEThe tune() function controls and executes the tuning. The method sets the optimization algorithm. The mlr3 ecosystem offers various optimization algorithms e.g. Random Search, GenSA, and Hyperband. In this example, we will use a simple grid search with a grid resolution of 5. Our three-dimensional grid consists of hyperparameter configurations. The
resampling strategy and performance measure specify how the performance of a model is evaluated. We choose a 3-fold cross-validation and use the classification error.
instance = tune(
+ tuner = tnr("grid_search", resolution = 5),
+ task = tsk("penguins"),
+ learner = lts(lrn("classif.rpart")),
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce")
+)The tune() function returns a tuning instance that includes an archive with all evaluated hyperparameter configurations.
as.data.table(instance$archive)[, list(minsplit, minbucket, cp, classif.ce, resample_result)] minsplit minbucket cp classif.ce resample_result
+ <num> <num> <num> <num> <list>
+ 1: 2.7764798 2.087194 -2.302585 0.06107297 <ResampleResult[21]>
+ 2: 1.7348135 4.174387 -2.302585 0.18001526 <ResampleResult[21]>
+ 3: 0.6931472 1.043597 -9.210340 0.02906178 <ResampleResult[21]>
+ 4: 0.6931472 3.130790 -9.210340 0.06107297 <ResampleResult[21]>
+ 5: 2.7764798 3.130790 -4.029524 0.06107297 <ResampleResult[21]>
+ ---
+121: 3.8181461 0.000000 -5.756463 0.04065599 <ResampleResult[21]>
+122: 0.6931472 0.000000 -7.483402 0.02616323 <ResampleResult[21]>
+123: 0.6931472 3.130790 -2.302585 0.06107297 <ResampleResult[21]>
+124: 1.7348135 2.087194 -4.029524 0.04937707 <ResampleResult[21]>
+125: 3.8181461 0.000000 -2.302585 0.06107297 <ResampleResult[21]>The best configuration and the corresponding measured performance can be retrieved from the tuning instance.
+instance$result minsplit minbucket cp learner_param_vals x_domain classif.ce
+ <num> <num> <num> <list> <list> <num>
+1: 0.6931472 0 -9.21034 <list[4]> <list[3]> 0.02616323The $result_learner_param_vals field contains the best hyperparameter setting on the learner scale.
instance$result_learner_param_vals$xval
+[1] 0
+
+$minsplit
+[1] 2
+
+$minbucket
+[1] 1
+
+$cp
+[1] 1e-04The learner we use to make predictions on new data is called the final model. The final model is trained on the full data set. We add the optimized hyperparameters to the learner and train the learner on the full dataset.
+learner = lrn("classif.rpart")
+learner$param_set$values = instance$result_learner_param_vals
+learner$train(tsk("penguins"))The trained model can now be used to predict new, external data.
+ + + +In this post, we use early stopping to reduce overfitting when training an XGBoost model. We start with a short recap on early stopping and overfitting. After that, we use the early stopping mechanism of XGBoost and train a model on the Spam Classification data set. Finally we show how to simultaneously tune hyperparameters and use early stopping. The reader should be familiar with tuning in the mlr3 ecosystem.
Early stopping is a technique used to reduce overfitting when fitting a model in an iterative process. Overfitting occurs when a model fits increasingly to the training data but the performance on unseen data decreases. This means the model’s training error decreases, while its test performance deteriorates. When using early stopping, the performance is monitored on a test set, and the training stops when performance decreases in a specific number of iterations.
+We initialize the random number generator with a fixed seed for reproducibility. The mlr3verse package provides all functions required for this example.
+set.seed(7832)
+
+library(mlr3verse)When training an XGBoost model, we can use early stopping to find the optimal number of boosting rounds. The partition() function splits the observations of the task into two disjoint sets. We use 80% of observations to train the model and the remaining 20% as the test set to monitor the performance.
task = tsk("spam")
+split = partition(task, ratio = 0.8)
+task$set_row_roles(split$test, "test")The early_stopping_set parameter controls which set is used to monitor the performance. Additionally, we need to define the range in which the performance must increase with early_stopping_rounds and the maximum number of boosting rounds with nrounds. In this example, the training is stopped when the classification error is not decreasing for 100 rounds or 1000 rounds are reached.
learner = lrn("classif.xgboost",
+ nrounds = 1000,
+ early_stopping_rounds = 100,
+ early_stopping_set = "test",
+ eval_metric = "error"
+)We train the learner with early stopping.
+learner$train(task)The $evaluation_log of the model stores the performance scores on the training and test set. Figure 1 shows that the classification error on the training set decreases, whereas the error on the test set increases after 20 rounds.
library(ggplot2)
+library(data.table)
+
+data = melt(
+ learner$model$evaluation_log,
+ id.vars = "iter",
+ variable.name = "set",
+ value.name = "error"
+)
+
+ggplot(data, aes(x = iter, y = error, group = set)) +
+ geom_line(aes(color = set)) +
+ geom_vline(aes(xintercept = learner$model$best_iteration), color = "grey") +
+ scale_colour_manual(values=c("#f8766d", "#00b0f6"), labels = c("Train", "Test")) +
+ labs(x = "Rounds", y = "Classification Error", color = "Set") +
+ theme_minimal()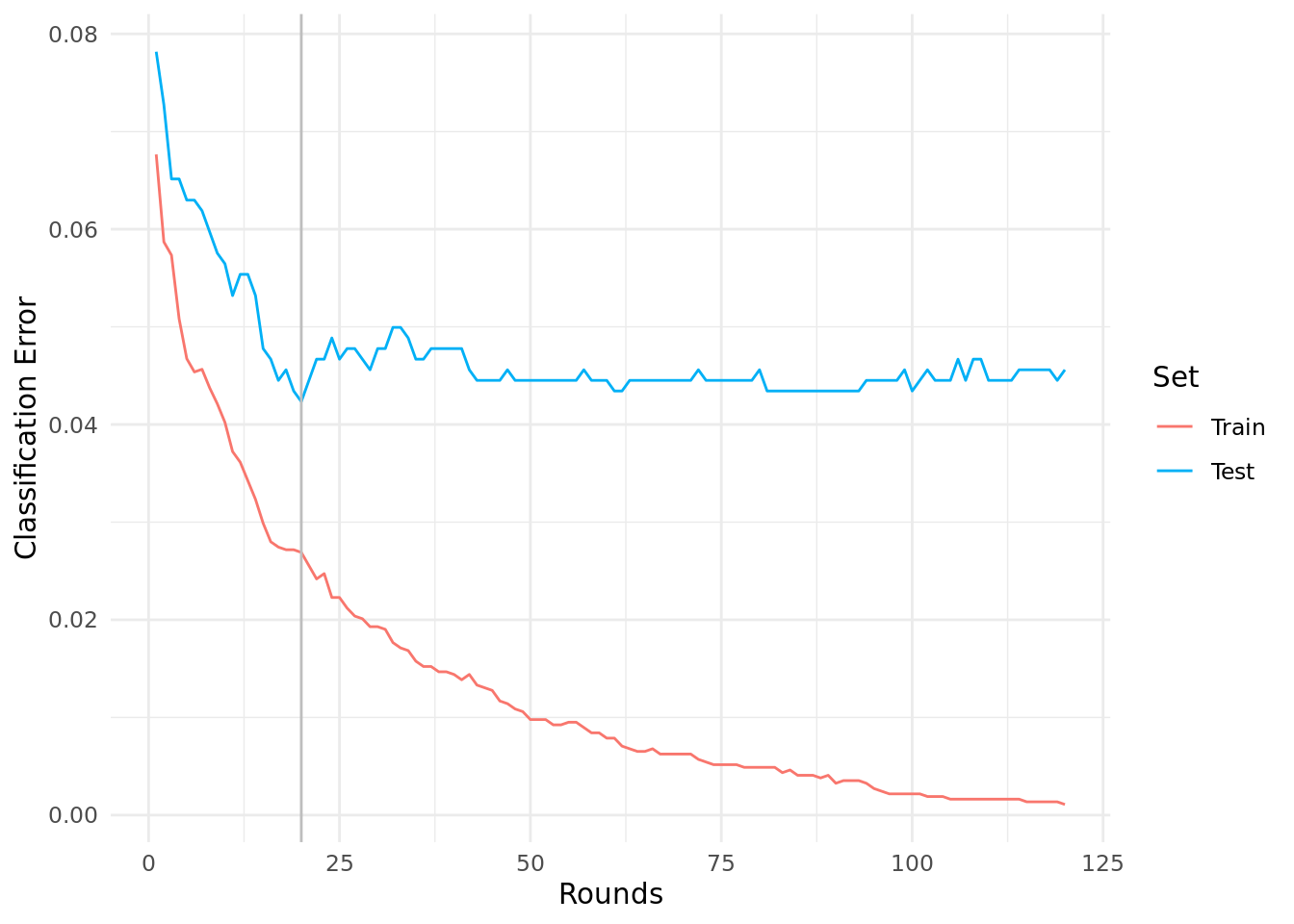
The slot $best_iteration contains the optimal number of boosting rounds.
learner$model$best_iteration[1] 20Note that, learner$predict() will use the model from the last iteration, not the best one. See the next section on how to fit a model with the optimal number of boosting rounds and hyperparameter configuration.
In this section, we want to tune the hyperparameters of an XGBoost model and find the optimal number of boosting rounds in one go. For this, we need the early stopping callback which handles early stopping during the tuning process. The performance of a hyperparameter configuration is evaluated with a resampling strategy while tuning e.g. 3-fold cross-validation. In each resampling iteration, a new XGBoost model is trained and early stopping is used to find the optimal number of boosting rounds. This results in three different optimal numbers of boosting rounds for one hyperparameter configuration when applying 3-fold cross-validation. The callback picks the maximum of the three values and writes it to the archive. It uses the maximum value because the final model is fitted on the complete data set. Now let’s start with a practical example.
First, we load the XGBoost learner and set the early stopping parameters.
+learner = lrn("classif.xgboost",
+ nrounds = 1000,
+ early_stopping_rounds = 100,
+ early_stopping_set = "test"
+)Next, we load a predefined tuning space from the mlr3tuningspaces package. The tuning space includes the most commonly tuned parameters of XGBoost.
+tuning_space = lts("classif.xgboost.default")
+as.data.table(tuning_space) id lower upper logscale
+1: eta 1e-04 1 TRUE
+2: nrounds 1e+00 5000 FALSE
+3: max_depth 1e+00 20 FALSE
+4: colsample_bytree 1e-01 1 FALSE
+5: colsample_bylevel 1e-01 1 FALSE
+6: lambda 1e-03 1000 TRUE
+7: alpha 1e-03 1000 TRUE
+8: subsample 1e-01 1 FALSEWe argument the learner with the tuning space.
+learner = lts(learner)The default tuning space contains the nrounds hyperparameter. We have to overwrite it with an upper bound for early stopping.
learner$param_set$set_values(nrounds = 1000)We run a small batch of random hyperparameter configurations.
+instance = tune(
+ tuner = tnr("random_search", batch_size = 2),
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+ term_evals = 4,
+ callbacks = clbk("mlr3tuning.early_stopping")
+)We can see that the optimal number of boosting rounds (max_nrounds) strongly depends on the other hyperparameters.
as.data.table(instance$archive)[, list(batch_nr, max_nrounds, eta, max_depth, colsample_bytree, colsample_bylevel, lambda, alpha, subsample)] batch_nr max_nrounds eta max_depth colsample_bytree colsample_bylevel lambda alpha subsample
+1: 1 1000 -4.129996 13 0.5466492 0.3051989 -0.9448420 2.535477 0.5454539
+2: 1 998 -3.338899 8 0.6193478 0.7392354 -2.2338126 1.793921 0.2294161
+3: 2 1000 -6.059897 5 0.6118892 0.5445475 -6.5698270 5.414224 0.9635730
+4: 2 1000 -4.528129 1 0.1094186 0.2526143 -0.7535105 -3.041829 0.5934376In the best hyperparameter configuration, the value of nrounds is replaced by max_nrounds and early stopping is deactivated.
instance$result_learner_param_vals$nrounds
+[1] 998
+
+$nthread
+[1] 1
+
+$verbose
+[1] 0
+
+$early_stopping_set
+[1] "none"
+
+$eta
+[1] 0.03547598
+
+$max_depth
+[1] 8
+
+$colsample_bytree
+[1] 0.6193478
+
+$colsample_bylevel
+[1] 0.7392354
+
+$lambda
+[1] 0.1071192
+
+$alpha
+[1] 6.012984
+
+$subsample
+[1] 0.2294161Finally, fit the final model on the complete data set.
+learner = lrn("classif.xgboost")
+learner$param_set$values = instance$result_learner_param_vals
+learner$train(task)The trained model can now be used to make predictions on new data.
+We can also use the AutoTuner to get a tuned XGBoost model. Note that, early stopping is deactivated when the final model is fitted.
The package mlr3tuningspaces offers a selection of published search spaces for many popular machine learning algorithms. In this post, we show how to tune a mlr3 learners with these search spaces.
The packages mlr3verse and mlr3tuningspaces are required for this demonstration:
+library(mlr3verse)
+library(mlr3tuningspaces)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")In the example, we use the pima indian diabetes data set which is used to predict whether or not a patient has diabetes. The patients are characterized by 8 numeric features, some of them have missing values.
# retrieve the task from mlr3
+task = tsk("pima")
+
+# generate a quick textual overview using the skimr package
+skimr::skim(task$data())| Name | +task$data() | +
| Number of rows | +768 | +
| Number of columns | +9 | +
| Key | +NULL | +
| _______________________ | ++ |
| Column type frequency: | ++ |
| factor | +1 | +
| numeric | +8 | +
| ________________________ | ++ |
| Group variables | +None | +
Variable type: factor
+| skim_variable | +n_missing | +complete_rate | +ordered | +n_unique | +top_counts | +
|---|---|---|---|---|---|
| diabetes | +0 | +1 | +FALSE | +2 | +neg: 500, pos: 268 | +
Variable type: numeric
+| skim_variable | +n_missing | +complete_rate | +mean | +sd | +p0 | +p25 | +p50 | +p75 | +p100 | +hist | +
|---|---|---|---|---|---|---|---|---|---|---|
| age | +0 | +1.00 | +33.24 | +11.76 | +21.00 | +24.00 | +29.00 | +41.00 | +81.00 | +▇▃▁▁▁ | +
| glucose | +5 | +0.99 | +121.69 | +30.54 | +44.00 | +99.00 | +117.00 | +141.00 | +199.00 | +▁▇▇▃▂ | +
| insulin | +374 | +0.51 | +155.55 | +118.78 | +14.00 | +76.25 | +125.00 | +190.00 | +846.00 | +▇▂▁▁▁ | +
| mass | +11 | +0.99 | +32.46 | +6.92 | +18.20 | +27.50 | +32.30 | +36.60 | +67.10 | +▅▇▃▁▁ | +
| pedigree | +0 | +1.00 | +0.47 | +0.33 | +0.08 | +0.24 | +0.37 | +0.63 | +2.42 | +▇▃▁▁▁ | +
| pregnant | +0 | +1.00 | +3.85 | +3.37 | +0.00 | +1.00 | +3.00 | +6.00 | +17.00 | +▇▃▂▁▁ | +
| pressure | +35 | +0.95 | +72.41 | +12.38 | +24.00 | +64.00 | +72.00 | +80.00 | +122.00 | +▁▃▇▂▁ | +
| triceps | +227 | +0.70 | +29.15 | +10.48 | +7.00 | +22.00 | +29.00 | +36.00 | +99.00 | +▆▇▁▁▁ | +
For tuning, it is important to create a search space that defines the type and range of the hyperparameters. A learner stores all information about its hyperparameters in the slot $param_set. Usually, we have to chose a subset of hyperparameters we want to tune.
lrn("classif.rpart")$param_set<ParamSet>
+ id class lower upper nlevels default value
+ 1: cp ParamDbl 0 1 Inf 0.01
+ 2: keep_model ParamLgl NA NA 2 FALSE
+ 3: maxcompete ParamInt 0 Inf Inf 4
+ 4: maxdepth ParamInt 1 30 30 30
+ 5: maxsurrogate ParamInt 0 Inf Inf 5
+ 6: minbucket ParamInt 1 Inf Inf <NoDefault[3]>
+ 7: minsplit ParamInt 1 Inf Inf 20
+ 8: surrogatestyle ParamInt 0 1 2 0
+ 9: usesurrogate ParamInt 0 2 3 2
+10: xval ParamInt 0 Inf Inf 10 0At the heart of mlr3tuningspaces is the R6 class TuningSpace. It stores a list of TuneToken, helper functions and additional meta information. The list of TuneToken can be directly applied to the $values slot of a learner’s ParamSet. The search spaces are stored in the mlr_tuning_spaces dictionary.
as.data.table(mlr_tuning_spaces) key label learner n_values
+ 1: classif.glmnet.default Classification GLM with Default classif.glmnet 2
+ 2: classif.glmnet.rbv1 Classification GLM with RandomBot classif.glmnet 2
+ 3: classif.glmnet.rbv2 Classification GLM with RandomBot classif.glmnet 2
+ 4: classif.kknn.default Classification KKNN with Default classif.kknn 3
+ 5: classif.kknn.rbv1 Classification KKNN with RandomBot classif.kknn 1
+ 6: classif.kknn.rbv2 Classification KKNN with RandomBot classif.kknn 1
+ 7: classif.ranger.default Classification Ranger with Default classif.ranger 4
+ 8: classif.ranger.rbv1 Classification Ranger with RandomBot classif.ranger 6
+ 9: classif.ranger.rbv2 Classification Ranger with RandomBot classif.ranger 8
+10: classif.rpart.default Classification Rpart with Default classif.rpart 3
+11: classif.rpart.rbv1 Classification Rpart with RandomBot classif.rpart 4
+12: classif.rpart.rbv2 Classification Rpart with RandomBot classif.rpart 4
+13: classif.svm.default Classification SVM with Default classif.svm 4
+14: classif.svm.rbv1 Classification SVM with RandomBot classif.svm 4
+15: classif.svm.rbv2 Classification SVM with RandomBot classif.svm 5
+16: classif.xgboost.default Classification XGBoost with Default classif.xgboost 8
+17: classif.xgboost.rbv1 Classification XGBoost with RandomBot classif.xgboost 10
+18: classif.xgboost.rbv2 Classification XGBoost with RandomBot classif.xgboost 13
+19: regr.glmnet.default Regression GLM with Default regr.glmnet 2
+20: regr.glmnet.rbv1 Regression GLM with RandomBot regr.glmnet 2
+21: regr.glmnet.rbv2 Regression GLM with RandomBot regr.glmnet 2
+22: regr.kknn.default Regression KKNN with Default regr.kknn 3
+23: regr.kknn.rbv1 Regression KKNN with RandomBot regr.kknn 1
+24: regr.kknn.rbv2 Regression KKNN with RandomBot regr.kknn 1
+25: regr.ranger.default Regression Ranger with Default regr.ranger 4
+26: regr.ranger.rbv1 Regression Ranger with RandomBot regr.ranger 6
+27: regr.ranger.rbv2 Regression Ranger with RandomBot regr.ranger 7
+28: regr.rpart.default Regression Rpart with Default regr.rpart 3
+29: regr.rpart.rbv1 Regression Rpart with RandomBot regr.rpart 4
+30: regr.rpart.rbv2 Regression Rpart with RandomBot regr.rpart 4
+31: regr.svm.default Regression SVM with Default regr.svm 4
+32: regr.svm.rbv1 Regression SVM with RandomBot regr.svm 4
+33: regr.svm.rbv2 Regression SVM with RandomBot regr.svm 5
+34: regr.xgboost.default Regression XGBoost with Default regr.xgboost 8
+35: regr.xgboost.rbv1 Regression XGBoost with RandomBot regr.xgboost 10
+36: regr.xgboost.rbv2 Regression XGBoost with RandomBot regr.xgboost 13
+ key label learner n_valuesWe can use the sugar function lts() to retrieve a TuningSpace.
tuning_space_rpart = lts("classif.rpart.default")
+tuning_space_rpart<TuningSpace:classif.rpart.default>: Classification Rpart with Default
+ id lower upper levels logscale
+1: minsplit 2e+00 128.0 TRUE
+2: minbucket 1e+00 64.0 TRUE
+3: cp 1e-04 0.1 TRUEThe $values slot contains the list of of TuneToken.
tuning_space_rpart$values$minsplit
+Tuning over:
+range [2, 128] (log scale)
+
+
+$minbucket
+Tuning over:
+range [1, 64] (log scale)
+
+
+$cp
+Tuning over:
+range [1e-04, 0.1] (log scale)We apply the search space and tune the learner.
learner = lrn("classif.rpart")
+
+learner$param_set$values = tuning_space_rpart$values
+
+instance = tune(
+ tuner = tnr("random_search"),
+ task = tsk("pima"),
+ learner = learner,
+ resampling = rsmp ("holdout"),
+ measure = msr("classif.ce"),
+ term_evals = 10)
+
+instance$result minsplit minbucket cp learner_param_vals x_domain classif.ce
+1: 3.40059 1.963618 -4.114895 <list[3]> <list[3]> 0.2539062We can also get the learner with search space already applied from the TuningSpace.
learner = tuning_space_rpart$get_learner()
+print(learner$param_set)<ParamSet>
+ id class lower upper nlevels default value
+ 1: cp ParamDbl 0 1 Inf 0.01 <RangeTuneToken[2]>
+ 2: keep_model ParamLgl NA NA 2 FALSE
+ 3: maxcompete ParamInt 0 Inf Inf 4
+ 4: maxdepth ParamInt 1 30 30 30
+ 5: maxsurrogate ParamInt 0 Inf Inf 5
+ 6: minbucket ParamInt 1 Inf Inf <NoDefault[3]> <RangeTuneToken[2]>
+ 7: minsplit ParamInt 1 Inf Inf 20 <RangeTuneToken[2]>
+ 8: surrogatestyle ParamInt 0 1 2 0
+ 9: usesurrogate ParamInt 0 2 3 2
+10: xval ParamInt 0 Inf Inf 10 0This method also allows to set constant parameters.
+learner = tuning_space_rpart$get_learner(maxdepth = 15)
+print(learner$param_set)<ParamSet>
+ id class lower upper nlevels default value
+ 1: cp ParamDbl 0 1 Inf 0.01 <RangeTuneToken[2]>
+ 2: keep_model ParamLgl NA NA 2 FALSE
+ 3: maxcompete ParamInt 0 Inf Inf 4
+ 4: maxdepth ParamInt 1 30 30 30 15
+ 5: maxsurrogate ParamInt 0 Inf Inf 5
+ 6: minbucket ParamInt 1 Inf Inf <NoDefault[3]> <RangeTuneToken[2]>
+ 7: minsplit ParamInt 1 Inf Inf 20 <RangeTuneToken[2]>
+ 8: surrogatestyle ParamInt 0 1 2 0
+ 9: usesurrogate ParamInt 0 2 3 2
+10: xval ParamInt 0 Inf Inf 10 0The lts() function sets the default search space directly to a learner.
learner = lts(lrn("classif.rpart", maxdepth = 15))
+print(learner$param_set)<ParamSet>
+ id class lower upper nlevels default value
+ 1: cp ParamDbl 0 1 Inf 0.01 <RangeTuneToken[2]>
+ 2: keep_model ParamLgl NA NA 2 FALSE
+ 3: maxcompete ParamInt 0 Inf Inf 4
+ 4: maxdepth ParamInt 1 30 30 30 15
+ 5: maxsurrogate ParamInt 0 Inf Inf 5
+ 6: minbucket ParamInt 1 Inf Inf <NoDefault[3]> <RangeTuneToken[2]>
+ 7: minsplit ParamInt 1 Inf Inf 20 <RangeTuneToken[2]>
+ 8: surrogatestyle ParamInt 0 1 2 0
+ 9: usesurrogate ParamInt 0 2 3 2
+10: xval ParamInt 0 Inf Inf 10 0This is the fourth part of the practical tuning series. The other parts can be found here:
+In this post, we teach how to run various jobs in mlr3 in parallel. The goal is to map computational jobs (e.g. evaluation of one configuration) to a pool of workers (usually physical CPU cores, sometimes remote computational nodes) to reduce the run time needed for tuning.
+ +We load the mlr3verse package which pulls in the most important packages for this example. Additionally, make sure you have installed the packages future and future.apply.
+library(mlr3verse)We decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")The workers are specified by the parallel backend which orchestrates starting up, shutting down, and communication with the workers. On a single machine, multisession and multicore are common backends. The multisession backend spawns new background R processes. It is available on all platforms.
future::plan("multisession")The multicore backend uses forked R processes which allows the workers to access R objects in a shared memory. This reduces the overhead since R objects are only copied in memory if they are modified. Unfortunately, forking processes is not supported on Windows and when running R from within RStudio.
future::plan("multicore")Both backends support the workers argument that specifies the number of used cores.
Use this code if your code should run with the multicore backend when possible.
if (future::supportsMulticore()) {
+ future::plan(future::multicore)
+} else {
+ future::plan(future::multisession)
+}The resample() and benchmark() functions in mlr3 can be executed in parallel. The parallelization is triggered by simply declaring a plan via future::plan().
future::plan("multisession")
+
+task = tsk("pima")
+learner = lrn("classif.rpart") # classification tree
+resampling = rsmp("cv", folds = 3)
+
+resample(task, learner, resampling)<ResampleResult> with 3 resampling iterations
+ task_id learner_id resampling_id iteration warnings errors
+ pima classif.rpart cv 1 0 0
+ pima classif.rpart cv 2 0 0
+ pima classif.rpart cv 3 0 0The 3-fold cross-validation gives us 3 jobs since each resampling iteration is executed in parallel.
+The benchmark() function accepts a design of experiments as input where each experiment is defined as a combination of a task, a learner, and a resampling strategy. For each experiment, resampling is performed. The nested loop over experiments and resampling iterations is flattened so that all resampling iterations of all experiments can be executed in parallel.
future::plan("multisession")
+
+tasks = list(tsk("pima"), tsk("iris"))
+learner = lrn("classif.rpart")
+resampling = rsmp("cv", folds = 3)
+
+grid = benchmark_grid(tasks, learner, resampling)
+
+benchmark(grid)<BenchmarkResult> of 6 rows with 2 resampling runs
+ nr task_id learner_id resampling_id iters warnings errors
+ 1 pima classif.rpart cv 3 0 0
+ 2 iris classif.rpart cv 3 0 0The 2 experiments and the 3-fold cross-validation result in 6 jobs which are executed in parallel.
+The mlr3tuning package internally calls benchmark() during tuning. If the tuner is capable of suggesting multiple configurations per iteration (such as random search, grid search, or hyperband), these configurations represent individual experiments, and the loop flattening of benchmark() is triggered. E.g., all resampling iterations of all hyperparameter configurations on a grid can be executed in parallel.
future::plan("multisession")
+
+learner = lrn("classif.rpart")
+learner$param_set$values$cp = to_tune(0.001, 0.1)
+learner$param_set$values$minsplit = to_tune(1, 10)
+
+instance = tune(
+ tuner = tnr("random_search", batch_size = 5), # random search suggests 5 configurations per batch
+ task = tsk("pima"),
+ learner = learner,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+ term_evals = 10
+)The batch size of 5 and the 3-fold cross-validation gives us 15 jobs. This is done twice because of the limit of 10 evaluations in total.
+Nested resampling results in two nested resampling loops. For this, an AutoTuner is passed to resample() or benchmark(). We can choose different parallelization backends for the inner and outer resampling loop, respectively. We just have to pass a list of backends.
# Runs the outer loop in parallel and the inner loop sequentially
+future::plan(list("multisession", "sequential"))
+
+# Runs the outer loop sequentially and the inner loop in parallel
+future::plan(list("sequential", "multisession"))
+
+learner = lrn("classif.rpart")
+learner$param_set$values$cp = to_tune(0.001, 0.1)
+learner$param_set$values$minsplit = to_tune(1, 10)
+
+rr = tune_nested(
+ tuner = tnr("random_search", batch_size = 5), # random search suggests 5 configurations per batch
+ task = tsk("pima"),
+ learner = learner,
+ inner_resampling = rsmp ("cv", folds = 3),
+ outer_resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+ term_evals = 10
+)While nesting real parallelization backends is often unintended and causes unnecessary overhead, it is useful in some distributed computing setups. It can be achieved with future by forcing a fixed number of workers for each loop.
+# Runs both loops in parallel
+future::plan(list(future::tweak("multisession", workers = 2),
+ future::tweak("multisession", workers = 4)))This example would run on 8 cores (= 2 * 4) on the local machine.
The mlr3book includes a chapters on parallelization. The mlr3cheatsheets contain frequently used commands and workflows of mlr3.
+ + +This is the third part of the practical tuning series. The other parts can be found here:
+In this post, we implement a simple automated machine learning (AutoML) system which includes preprocessing, a switch between multiple learners and hyperparameter tuning. For this, we build a pipeline with the mlr3pipelines extension package. Additionally, we use nested resampling to get an unbiased performance estimate of our AutoML system.
+ +We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")In this example, we use the Pima Indians Diabetes data set which is used to to predict whether or not a patient has diabetes. The patients are characterized by 8 numeric features and some have missing values.
+task = tsk("pima")We use three popular machine learning algorithms: k-nearest-neighbors, support vector machines and random forests.
+learners = list(
+ lrn("classif.kknn", id = "kknn"),
+ lrn("classif.svm", id = "svm", type = "C-classification"),
+ lrn("classif.ranger", id = "ranger")
+)The PipeOpBranch allows us to specify multiple alternatives paths. In this graph, the paths lead to the different learner models. The selection hyperparameter controls which path is executed i.e., which learner is used to fit a model. It is important to use the PipeOpBranch after the branching so that the outputs are merged into one result object. We visualize the graph with branching below.
graph =
+ po("branch", options = c("kknn", "svm", "ranger")) %>>%
+ gunion(lapply(learners, po)) %>>%
+ po("unbranch")
+graph$plot(html = FALSE)
Alternatively, we can use the ppl()-shortcut to load a predefined graph from the mlr_graphs dictionary. For this, the learner list must be named.
learners = list(
+ kknn = lrn("classif.kknn", id = "kknn"),
+ svm = lrn("classif.svm", id = "svm", type = "C-classification"),
+ ranger = lrn("classif.ranger", id = "ranger")
+)
+
+graph = ppl("branch", lapply(learners, po))The task has missing data in five columns.
+round(task$missings() / task$nrow, 2)diabetes age glucose insulin mass pedigree pregnant pressure triceps
+ 0.00 0.00 0.01 0.49 0.01 0.00 0.00 0.05 0.30 The pipeline "robustify" function creates a preprocessing pipeline based on our task. The resulting pipeline imputes missing values with PipeOpImputeHist and creates a dummy column (PipeOpMissInd) which indicates the imputed missing values. Internally, this creates two paths and the results are combined with PipeOpFeatureUnion. In contrast to PipeOpBranch, both paths are executed. Additionally, "robustify" adds PipeOpEncode to encode factor columns and PipeOpRemoveConstants to remove features with a constant value.
graph = ppl("robustify", task = task, factors_to_numeric = TRUE) %>>%
+ graph
+plot(graph, html = FALSE)
We could also create the preprocessing pipeline manually.
+gunion(list(po("imputehist"),
+ po("missind", affect_columns = selector_type(c("numeric", "integer"))))) %>>%
+ po("featureunion") %>>%
+ po("encode") %>>%
+ po("removeconstants")Graph with 5 PipeOps:
+ ID State sccssors prdcssors
+ imputehist <<UNTRAINED>> featureunion
+ missind <<UNTRAINED>> featureunion
+ featureunion <<UNTRAINED>> encode imputehist,missind
+ encode <<UNTRAINED>> removeconstants featureunion
+ removeconstants <<UNTRAINED>> encodeWe use as_learner() to create a GraphLearner which encapsulates the pipeline and can be used like a learner.
graph_learner = as_learner(graph)The parameter set of the graph learner includes all hyperparameters from all contained learners. The hyperparameter ids are prefixed with the corresponding learner ids. The hyperparameter branch.selection controls which learner is used.
as.data.table(graph_learner$param_set)[, .(id, class, lower, upper, nlevels)] id class lower upper nlevels
+ 1: removeconstants_prerobustify.ratio ParamDbl 0 1 Inf
+ 2: removeconstants_prerobustify.rel_tol ParamDbl 0 Inf Inf
+ 3: removeconstants_prerobustify.abs_tol ParamDbl 0 Inf Inf
+ 4: removeconstants_prerobustify.na_ignore ParamLgl NA NA 2
+ 5: removeconstants_prerobustify.affect_columns ParamUty NA NA Inf
+ 6: imputehist.affect_columns ParamUty NA NA Inf
+ 7: missind.which ParamFct NA NA 2
+ 8: missind.type ParamFct NA NA 4
+ 9: missind.affect_columns ParamUty NA NA Inf
+10: imputesample.affect_columns ParamUty NA NA Inf
+11: encode.method ParamFct NA NA 5
+12: encode.affect_columns ParamUty NA NA Inf
+13: removeconstants_postrobustify.ratio ParamDbl 0 1 Inf
+14: removeconstants_postrobustify.rel_tol ParamDbl 0 Inf Inf
+15: removeconstants_postrobustify.abs_tol ParamDbl 0 Inf Inf
+16: removeconstants_postrobustify.na_ignore ParamLgl NA NA 2
+17: removeconstants_postrobustify.affect_columns ParamUty NA NA Inf
+18: kknn.k ParamInt 1 Inf Inf
+19: kknn.distance ParamDbl 0 Inf Inf
+20: kknn.kernel ParamFct NA NA 10
+21: kknn.scale ParamLgl NA NA 2
+22: kknn.ykernel ParamUty NA NA Inf
+23: kknn.store_model ParamLgl NA NA 2
+24: svm.cachesize ParamDbl -Inf Inf Inf
+25: svm.class.weights ParamUty NA NA Inf
+26: svm.coef0 ParamDbl -Inf Inf Inf
+27: svm.cost ParamDbl 0 Inf Inf
+28: svm.cross ParamInt 0 Inf Inf
+29: svm.decision.values ParamLgl NA NA 2
+30: svm.degree ParamInt 1 Inf Inf
+31: svm.epsilon ParamDbl 0 Inf Inf
+32: svm.fitted ParamLgl NA NA 2
+33: svm.gamma ParamDbl 0 Inf Inf
+34: svm.kernel ParamFct NA NA 4
+35: svm.nu ParamDbl -Inf Inf Inf
+36: svm.scale ParamUty NA NA Inf
+37: svm.shrinking ParamLgl NA NA 2
+38: svm.tolerance ParamDbl 0 Inf Inf
+39: svm.type ParamFct NA NA 2
+40: ranger.alpha ParamDbl -Inf Inf Inf
+41: ranger.always.split.variables ParamUty NA NA Inf
+42: ranger.class.weights ParamUty NA NA Inf
+43: ranger.holdout ParamLgl NA NA 2
+44: ranger.importance ParamFct NA NA 4
+45: ranger.keep.inbag ParamLgl NA NA 2
+46: ranger.max.depth ParamInt 0 Inf Inf
+47: ranger.min.node.size ParamInt 1 Inf Inf
+48: ranger.min.prop ParamDbl -Inf Inf Inf
+49: ranger.minprop ParamDbl -Inf Inf Inf
+50: ranger.mtry ParamInt 1 Inf Inf
+51: ranger.mtry.ratio ParamDbl 0 1 Inf
+52: ranger.num.random.splits ParamInt 1 Inf Inf
+53: ranger.num.threads ParamInt 1 Inf Inf
+54: ranger.num.trees ParamInt 1 Inf Inf
+55: ranger.oob.error ParamLgl NA NA 2
+56: ranger.regularization.factor ParamUty NA NA Inf
+57: ranger.regularization.usedepth ParamLgl NA NA 2
+58: ranger.replace ParamLgl NA NA 2
+59: ranger.respect.unordered.factors ParamFct NA NA 3
+60: ranger.sample.fraction ParamDbl 0 1 Inf
+61: ranger.save.memory ParamLgl NA NA 2
+62: ranger.scale.permutation.importance ParamLgl NA NA 2
+63: ranger.se.method ParamFct NA NA 2
+64: ranger.seed ParamInt -Inf Inf Inf
+65: ranger.split.select.weights ParamUty NA NA Inf
+66: ranger.splitrule ParamFct NA NA 3
+67: ranger.verbose ParamLgl NA NA 2
+68: ranger.write.forest ParamLgl NA NA 2
+69: branch.selection ParamFct NA NA 3
+ id class lower upper nlevelsWe will only tune one hyperparameter for each learner in this example. Additionally, we tune the branching parameter which selects one of the three learners. We have to specify that a hyperparameter is only valid for a certain learner by using depends = branch.selection == <learner_id>.
# branch
+graph_learner$param_set$values$branch.selection =
+ to_tune(c("kknn", "svm", "ranger"))
+
+# kknn
+graph_learner$param_set$values$kknn.k =
+ to_tune(p_int(3, 50, logscale = TRUE, depends = branch.selection == "kknn"))
+
+# svm
+graph_learner$param_set$values$svm.cost =
+ to_tune(p_dbl(-1, 1, trafo = function(x) 10^x, depends = branch.selection == "svm"))
+
+# ranger
+graph_learner$param_set$values$ranger.mtry =
+ to_tune(p_int(1, 8, depends = branch.selection == "ranger"))
+
+# short learner id for printing
+graph_learner$id = "graph_learner"We define a tuning instance and select a random search which is stopped after 20 evaluated configurations.
+instance = tune(
+ tuner = tnr("random_search"),
+ task = task,
+ learner = graph_learner,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+ term_evals = 20
+)The following shows a quick way to visualize the tuning results.
+autoplot(instance, type = "marginal",
+ cols_x = c("x_domain_kknn.k", "x_domain_svm.cost", "ranger.mtry"))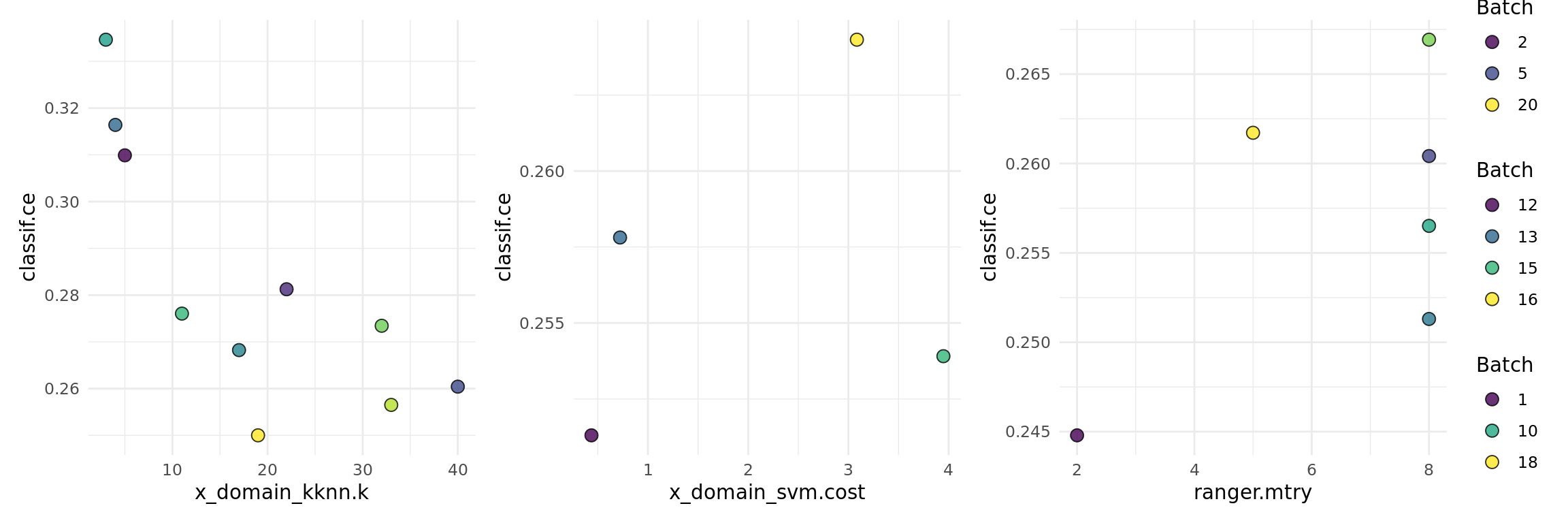
We add the optimized hyperparameters to the graph learner and train the learner on the full dataset.
+learner = as_learner(graph)
+learner$param_set$values = instance$result_learner_param_vals
+learner$train(task)The trained model can now be used to make predictions on new data. A common mistake is to report the performance estimated on the resampling sets on which the tuning was performed (instance$result_y) as the model’s performance. Instead we have to use nested resampling to get an unbiased performance estimate.
We use nested resampling to get an unbiased estimate of the predictive performance of our graph learner.
+graph_learner = as_learner(graph)
+graph_learner$param_set$values$branch.selection =
+ to_tune(c("kknn", "svm", "ranger"))
+graph_learner$param_set$values$kknn.k =
+ to_tune(p_int(3, 50, logscale = TRUE, depends = branch.selection == "kknn"))
+graph_learner$param_set$values$svm.cost =
+ to_tune(p_dbl(-1, 1, trafo = function(x) 10^x, depends = branch.selection == "svm"))
+graph_learner$param_set$values$ranger.mtry =
+ to_tune(p_int(1, 8, depends = branch.selection == "ranger"))
+graph_learner$id = "graph_learner"
+
+inner_resampling = rsmp("cv", folds = 3)
+at = AutoTuner$new(
+ learner = graph_learner,
+ resampling = inner_resampling,
+ measure = msr("classif.ce"),
+ terminator = trm("evals", n_evals = 10),
+ tuner = tnr("random_search")
+)
+
+outer_resampling = rsmp("cv", folds = 3)
+rr = resample(task, at, outer_resampling, store_models = TRUE)We check the inner tuning results for stable hyperparameters. This means that the selected hyperparameters should not vary too much. We might observe unstable models in this example because the small data set and the low number of resampling iterations might introduce too much randomness. Usually, we aim for the selection of stable hyperparameters for all outer training sets.
+extract_inner_tuning_results(rr)Next, we want to compare the predictive performances estimated on the outer resampling to the inner resampling. Significantly lower predictive performances on the outer resampling indicate that the models with the optimized hyperparameters overfit the data.
+rr$score()[, .(iteration, task_id, learner_id, resampling_id, classif.ce)] iteration task_id learner_id resampling_id classif.ce
+1: 1 pima graph_learner.tuned cv 0.2265625
+2: 2 pima graph_learner.tuned cv 0.2382812
+3: 3 pima graph_learner.tuned cv 0.2656250The aggregated performance of all outer resampling iterations is essentially the unbiased performance of the graph learner with optimal hyperparameter found by random search.
+rr$aggregate()classif.ce
+ 0.2434896 Applying nested resampling can be shortened by using the tune_nested()-shortcut.
graph_learner = as_learner(graph)
+graph_learner$param_set$values$branch.selection =
+ to_tune(c("kknn", "svm", "ranger"))
+graph_learner$param_set$values$kknn.k =
+ to_tune(p_int(3, 50, logscale = TRUE, depends = branch.selection == "kknn"))
+graph_learner$param_set$values$svm.cost =
+ to_tune(p_dbl(-1, 1, trafo = function(x) 10^x, depends = branch.selection == "svm"))
+graph_learner$param_set$values$ranger.mtry =
+ to_tune(p_int(1, 8, depends = branch.selection == "ranger"))
+graph_learner$id = "graph_learner"
+
+rr = tune_nested(
+ tuner = tnr("random_search"),
+ task = task,
+ learner = graph_learner,
+ inner_resampling = rsmp("cv", folds = 3),
+ outer_resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+ term_evals = 10,
+)The mlr3book includes chapters on pipelines and hyperparameter tuning. The mlr3cheatsheets contain frequently used commands and workflows of mlr3.
+ + +This is the second part of the practical tuning series. The other parts can be found here:
+In this post, we build a simple preprocessing pipeline and tune it. For this, we are using the mlr3pipelines extension package. First, we start by imputing missing values in the Pima Indians Diabetes data set. After that, we encode a factor column to numerical dummy columns in the data set. Next, we combine both preprocessing steps to a Graph and create a GraphLearner. Finally, nested resampling is used to compare the performance of two imputation methods.
We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")In this example, we use the Pima Indians Diabetes data set which is used to predict whether or not a patient has diabetes. The patients are characterized by 8 numeric features of which some have missing values. We alter the data set by categorizing the feature pressure (blood pressure) into the categories "low", "mid", and "high".
# retrieve the task from mlr3
+task = tsk("pima")
+
+# create data frame with categorized pressure feature
+data = task$data(cols = "pressure")
+breaks = quantile(data$pressure, probs = c(0, 0.33, 0.66, 1), na.rm = TRUE)
+data$pressure = cut(data$pressure, breaks, labels = c("low", "mid", "high"))
+
+# overwrite the feature in the task
+task$cbind(data)
+
+# generate a quick textual overview
+skimr::skim(task$data())| Name | +task$data() | +
| Number of rows | +768 | +
| Number of columns | +9 | +
| Key | +NULL | +
| _______________________ | ++ |
| Column type frequency: | ++ |
| factor | +2 | +
| numeric | +7 | +
| ________________________ | ++ |
| Group variables | +None | +
Variable type: factor
+| skim_variable | +n_missing | +complete_rate | +ordered | +n_unique | +top_counts | +
|---|---|---|---|---|---|
| diabetes | +0 | +1.00 | +FALSE | +2 | +neg: 500, pos: 268 | +
| pressure | +36 | +0.95 | +FALSE | +3 | +low: 282, mid: 245, hig: 205 | +
Variable type: numeric
+| skim_variable | +n_missing | +complete_rate | +mean | +sd | +p0 | +p25 | +p50 | +p75 | +p100 | +hist | +
|---|---|---|---|---|---|---|---|---|---|---|
| age | +0 | +1.00 | +33.24 | +11.76 | +21.00 | +24.00 | +29.00 | +41.00 | +81.00 | +▇▃▁▁▁ | +
| glucose | +5 | +0.99 | +121.69 | +30.54 | +44.00 | +99.00 | +117.00 | +141.00 | +199.00 | +▁▇▇▃▂ | +
| insulin | +374 | +0.51 | +155.55 | +118.78 | +14.00 | +76.25 | +125.00 | +190.00 | +846.00 | +▇▂▁▁▁ | +
| mass | +11 | +0.99 | +32.46 | +6.92 | +18.20 | +27.50 | +32.30 | +36.60 | +67.10 | +▅▇▃▁▁ | +
| pedigree | +0 | +1.00 | +0.47 | +0.33 | +0.08 | +0.24 | +0.37 | +0.63 | +2.42 | +▇▃▁▁▁ | +
| pregnant | +0 | +1.00 | +3.85 | +3.37 | +0.00 | +1.00 | +3.00 | +6.00 | +17.00 | +▇▃▂▁▁ | +
| triceps | +227 | +0.70 | +29.15 | +10.48 | +7.00 | +22.00 | +29.00 | +36.00 | +99.00 | +▆▇▁▁▁ | +
We choose the xgboost algorithm from the xgboost package as learner.
+learner = lrn("classif.xgboost", nrounds = 100, id = "xgboost", verbose = 0)The task has missing data in five columns.
+round(task$missings() / task$nrow, 2)diabetes age glucose insulin mass pedigree pregnant pressure triceps
+ 0.00 0.00 0.01 0.49 0.01 0.00 0.00 0.05 0.30 The xgboost learner has an internal method for handling missing data but some learners cannot handle missing values. We will try to beat the internal method in terms of predictive performance. The mlr3pipelines package offers various methods to impute missing values.
mlr_pipeops$keys("^impute")[1] "imputeconstant" "imputehist" "imputelearner" "imputemean" "imputemedian" "imputemode"
+[7] "imputeoor" "imputesample" We choose the PipeOpImputeOOR that adds the new factor level ".MISSING". to factorial features and imputes numerical features by constant values shifted below the minimum (default) or above the maximum.
imputer = po("imputeoor")
+print(imputer)PipeOp: <imputeoor> (not trained)
+values: <min=TRUE, offset=1, multiplier=1>
+Input channels <name [train type, predict type]>:
+ input [Task,Task]
+Output channels <name [train type, predict type]>:
+ output [Task,Task]As the output suggests, the in- and output of this pipe operator is a Task for both the training and the predict step. We can manually train the pipe operator to check its functionality:
task_imputed = imputer$train(list(task))[[1]]
+task_imputed$missings()diabetes age pedigree pregnant glucose insulin mass pressure triceps
+ 0 0 0 0 0 0 0 0 0 Let’s compare an observation with missing values to the observation with imputed observation.
+rbind(
+ task$data()[8,],
+ task_imputed$data()[8,]
+) diabetes age glucose insulin mass pedigree pregnant pressure triceps
+1: neg 29 115 NA 35.3 0.134 10 <NA> NA
+2: neg 29 115 -819 35.3 0.134 10 .MISSING -86Note that OOR imputation is in particular useful for tree-based models, but should not be used for linear models or distance-based models.
+The xgboost learner cannot handle categorical features. Therefore, we must to convert factor columns to numerical dummy columns. For this, we argument the xgboost learner with automatic factor encoding.
The PipeOpEncode encodes factor columns with one of six methods. In this example, we use one-hot encoding which creates a new binary column for each factor level.
factor_encoding = po("encode", method = "one-hot")We manually trigger the encoding on the task.
+factor_encoding$train(list(task))$output
+<TaskClassif:pima> (768 x 11): Pima Indian Diabetes
+* Target: diabetes
+* Properties: twoclass
+* Features (10):
+ - dbl (10): age, glucose, insulin, mass, pedigree, pregnant, pressure.high, pressure.low, pressure.mid,
+ tricepsThe factor column pressure has been converted to the three binary columns "pressure.low", "pressure.mid", and "pressure.high".
We created two preprocessing steps which could be used to create a new task with encoded factor variables and imputed missing values. However, if we do this before resampling, information from the test can leak into our training step which typically leads to overoptimistic performance measures. To avoid this, we add the preprocessing steps to the Learner itself, creating a GraphLearner. For this, we create a Graph first.
graph = po("encode") %>>%
+ po("imputeoor") %>>%
+ learner
+plot(graph, html = FALSE)
We use as_learner() to wrap the Graph into a GraphLearner with which allows us to use the graph like a normal learner.
graph_learner = as_learner(graph)
+
+# short learner id for printing
+graph_learner$id = "graph_learner"The GraphLearner can be trained and used for making predictions. Instead of calling $train() or $predict() manually, we will directly use it for resampling. We choose a 3-fold cross-validation as the resampling strategy.
resampling = rsmp("cv", folds = 3)
+
+rr = resample(task = task, learner = graph_learner, resampling = resampling)rr$score()[, c("iteration", "task_id", "learner_id", "resampling_id", "classif.ce"), with = FALSE] iteration task_id learner_id resampling_id classif.ce
+1: 1 pima graph_learner cv 0.2851562
+2: 2 pima graph_learner cv 0.2460938
+3: 3 pima graph_learner cv 0.2968750For each resampling iteration, the following steps are performed:
+Next is the predict step:
+By following this procedure, it is guaranteed that no information can leak from the training step to the predict step.
+Let’s have a look at the parameter set of the GraphLearner. It consists of the xgboost hyperparameters, and additionally, the parameter of the PipeOp encode and imputeoor. All hyperparameters are prefixed with the id of the respective PipeOp or learner.
as.data.table(graph_learner$param_set)[, c("id", "class", "lower", "upper", "nlevels"), with = FALSE] id class lower upper nlevels
+ 1: encode.method ParamFct NA NA 5
+ 2: encode.affect_columns ParamUty NA NA Inf
+ 3: imputeoor.min ParamLgl NA NA 2
+ 4: imputeoor.offset ParamDbl 0 Inf Inf
+ 5: imputeoor.multiplier ParamDbl 0 Inf Inf
+ 6: imputeoor.affect_columns ParamUty NA NA Inf
+ 7: xgboost.alpha ParamDbl 0 Inf Inf
+ 8: xgboost.approxcontrib ParamLgl NA NA 2
+ 9: xgboost.base_score ParamDbl -Inf Inf Inf
+10: xgboost.booster ParamFct NA NA 3
+11: xgboost.callbacks ParamUty NA NA Inf
+12: xgboost.colsample_bylevel ParamDbl 0 1 Inf
+13: xgboost.colsample_bynode ParamDbl 0 1 Inf
+14: xgboost.colsample_bytree ParamDbl 0 1 Inf
+15: xgboost.disable_default_eval_metric ParamLgl NA NA 2
+16: xgboost.early_stopping_rounds ParamInt 1 Inf Inf
+17: xgboost.early_stopping_set ParamFct NA NA 3
+18: xgboost.eta ParamDbl 0 1 Inf
+19: xgboost.eval_metric ParamUty NA NA Inf
+20: xgboost.feature_selector ParamFct NA NA 5
+21: xgboost.feval ParamUty NA NA Inf
+22: xgboost.gamma ParamDbl 0 Inf Inf
+23: xgboost.grow_policy ParamFct NA NA 2
+24: xgboost.interaction_constraints ParamUty NA NA Inf
+25: xgboost.iterationrange ParamUty NA NA Inf
+26: xgboost.lambda ParamDbl 0 Inf Inf
+27: xgboost.lambda_bias ParamDbl 0 Inf Inf
+28: xgboost.max_bin ParamInt 2 Inf Inf
+29: xgboost.max_delta_step ParamDbl 0 Inf Inf
+30: xgboost.max_depth ParamInt 0 Inf Inf
+31: xgboost.max_leaves ParamInt 0 Inf Inf
+32: xgboost.maximize ParamLgl NA NA 2
+33: xgboost.min_child_weight ParamDbl 0 Inf Inf
+34: xgboost.missing ParamDbl -Inf Inf Inf
+35: xgboost.monotone_constraints ParamUty NA NA Inf
+36: xgboost.normalize_type ParamFct NA NA 2
+37: xgboost.nrounds ParamInt 1 Inf Inf
+38: xgboost.nthread ParamInt 1 Inf Inf
+39: xgboost.ntreelimit ParamInt 1 Inf Inf
+40: xgboost.num_parallel_tree ParamInt 1 Inf Inf
+41: xgboost.objective ParamUty NA NA Inf
+42: xgboost.one_drop ParamLgl NA NA 2
+43: xgboost.outputmargin ParamLgl NA NA 2
+44: xgboost.predcontrib ParamLgl NA NA 2
+45: xgboost.predictor ParamFct NA NA 2
+46: xgboost.predinteraction ParamLgl NA NA 2
+47: xgboost.predleaf ParamLgl NA NA 2
+48: xgboost.print_every_n ParamInt 1 Inf Inf
+49: xgboost.process_type ParamFct NA NA 2
+50: xgboost.rate_drop ParamDbl 0 1 Inf
+51: xgboost.refresh_leaf ParamLgl NA NA 2
+52: xgboost.reshape ParamLgl NA NA 2
+53: xgboost.seed_per_iteration ParamLgl NA NA 2
+54: xgboost.sampling_method ParamFct NA NA 2
+55: xgboost.sample_type ParamFct NA NA 2
+56: xgboost.save_name ParamUty NA NA Inf
+57: xgboost.save_period ParamInt 0 Inf Inf
+58: xgboost.scale_pos_weight ParamDbl -Inf Inf Inf
+59: xgboost.skip_drop ParamDbl 0 1 Inf
+60: xgboost.strict_shape ParamLgl NA NA 2
+61: xgboost.subsample ParamDbl 0 1 Inf
+62: xgboost.top_k ParamInt 0 Inf Inf
+63: xgboost.training ParamLgl NA NA 2
+64: xgboost.tree_method ParamFct NA NA 5
+65: xgboost.tweedie_variance_power ParamDbl 1 2 Inf
+66: xgboost.updater ParamUty NA NA Inf
+67: xgboost.verbose ParamInt 0 2 3
+68: xgboost.watchlist ParamUty NA NA Inf
+69: xgboost.xgb_model ParamUty NA NA Inf
+ id class lower upper nlevelsWe will tune the encode method.
+graph_learner$param_set$values$encode.method = to_tune(c("one-hot", "treatment"))We define a tuning instance and use grid search since we want to try all encode methods.
+instance = tune(
+ tuner = tnr("grid_search"),
+ task = task,
+ learner = graph_learner,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce")
+)The archive shows us the performance of the model with different encoding methods.
+print(instance$archive)<ArchiveTuning> with 2 evaluations
+ encode.method classif.ce batch_nr warnings errors
+1: treatment 0.26 1 0 0
+2: one-hot 0.26 2 0 0We create one GraphLearner with imputeoor and test it against a GraphLearner that uses the internal imputation method of xgboost. Applying nested resampling ensures a fair comparison of the predictive performances.
graph_1 = po("encode") %>>%
+ learner
+graph_learner_1 = GraphLearner$new(graph_1)
+
+graph_learner_1$param_set$values$encode.method = to_tune(c("one-hot", "treatment"))
+
+at_1 = AutoTuner$new(
+ learner = graph_learner_1,
+ resampling = resampling,
+ measure = msr("classif.ce"),
+ terminator = trm("none"),
+ tuner = tnr("grid_search"),
+ store_models = TRUE
+)graph_2 = po("encode") %>>%
+ po("imputeoor") %>>%
+ learner
+graph_learner_2 = GraphLearner$new(graph_2)
+
+graph_learner_2$param_set$values$encode.method = to_tune(c("one-hot", "treatment"))
+
+at_2 = AutoTuner$new(
+ learner = graph_learner_2,
+ resampling = resampling,
+ measure = msr("classif.ce"),
+ terminator = trm("none"),
+ tuner = tnr("grid_search"),
+ store_models = TRUE
+)We run the benchmark.
+resampling_outer = rsmp("cv", folds = 3)
+design = benchmark_grid(task, list(at_1, at_2), resampling_outer)
+
+bmr = benchmark(design, store_models = TRUE)We compare the aggregated performances on the outer test sets which give us an unbiased performance estimate of the GraphLearners with the different encoding methods.
bmr$aggregate() nr task_id learner_id resampling_id iters classif.ce
+1: 1 pima encode.xgboost.tuned cv 3 0.2578125
+2: 2 pima encode.imputeoor.xgboost.tuned cv 3 0.2630208
+Hidden columns: resample_resultautoplot(bmr)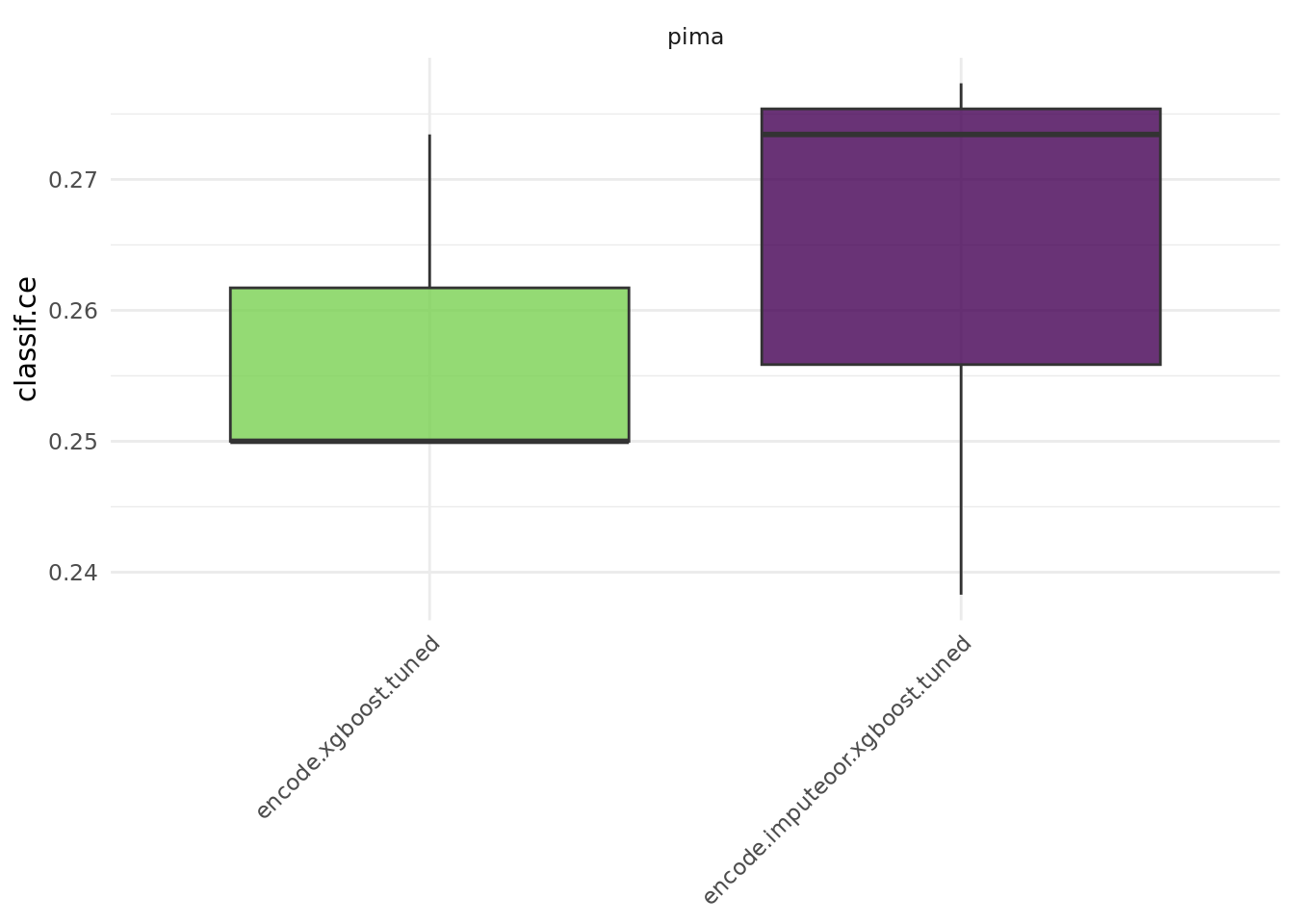
Note that in practice, it is required to tune preprocessing hyperparameters jointly with the hyperparameters of the learner. Otherwise, comparing preprocessing steps is not feasible and can lead to wrong conclusions.
+Applying nested resampling can be shortened by using the auto_tuner()-shortcut.
graph_1 = po("encode") %>>% learner
+graph_learner_1 = as_learner(graph_1)
+graph_learner_1$param_set$values$encode.method = to_tune(c("one-hot", "treatment"))
+
+at_1 = auto_tuner(
+ method = "grid_search",
+ learner = graph_learner_1,
+ resampling = resampling,
+ measure = msr("classif.ce"),
+ store_models = TRUE)
+
+graph_2 = po("encode") %>>% po("imputeoor") %>>% learner
+graph_learner_2 = as_learner(graph_2)
+graph_learner_2$param_set$values$encode.method = to_tune(c("one-hot", "treatment"))
+
+at_2 = auto_tuner(
+ method = "grid_search",
+ learner = graph_learner_2,
+ resampling = resampling,
+ measure = msr("classif.ce"),
+ store_models = TRUE)
+
+design = benchmark_grid(task, list(at_1, at_2), rsmp("cv", folds = 3))
+
+bmr = benchmark(design, store_models = TRUE)We train the chosen GraphLearner with the AutoTuner to get a final model with optimized hyperparameters.
at_2$train(task)The trained model can now be used to make predictions on new data at_2$predict(). The pipeline ensures that the preprocessing is always a part of the train and predict step.
The mlr3book includes chapters on pipelines and hyperparameter tuning. The mlr3cheatsheets contain frequently used commands and workflows of mlr3.
+ + +requireNamespace("DiceKriging")Loading required namespace: DiceKrigingThis is the first part of the practical tuning series. The other parts can be found here:
+In this post, we demonstrate how to optimize the hyperparameters of a support vector machine (SVM). We are using the mlr3 machine learning framework with the mlr3tuning extension package.
+First, we start by showing the basic building blocks of mlr3tuning and tune the cost and gamma hyperparameters of an SVM with a radial basis function on the Iris data set. After that, we use transformations to tune the both hyperparameters on the logarithmic scale. Next, we explain the importance of dependencies to tune hyperparameters like degree which are dependent on the choice of kernel. After that, we fit an SVM with optimized hyperparameters on the full dataset. Finally, nested resampling is used to compute an unbiased performance estimate of our tuned SVM.
We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")In the example, we use the Iris data set which classifies 150 flowers in three species of Iris. The flowers are characterized by sepal length and width and petal length and width. The Iris data set allows us to quickly fit models to it. However, the influence of hyperparameter tuning on the predictive performance might be minor. Other data sets might give more meaningful tuning results.
+# retrieve the task from mlr3
+task = tsk("iris")
+
+# generate a quick textual overview using the skimr package
+skimr::skim(task$data())| Name | +task$data() | +
| Number of rows | +150 | +
| Number of columns | +5 | +
| Key | +NULL | +
| _______________________ | ++ |
| Column type frequency: | ++ |
| factor | +1 | +
| numeric | +4 | +
| ________________________ | ++ |
| Group variables | +None | +
Variable type: factor
+| skim_variable | +n_missing | +complete_rate | +ordered | +n_unique | +top_counts | +
|---|---|---|---|---|---|
| Species | +0 | +1 | +FALSE | +3 | +set: 50, ver: 50, vir: 50 | +
Variable type: numeric
+| skim_variable | +n_missing | +complete_rate | +mean | +sd | +p0 | +p25 | +p50 | +p75 | +p100 | +hist | +
|---|---|---|---|---|---|---|---|---|---|---|
| Petal.Length | +0 | +1 | +3.76 | +1.77 | +1.0 | +1.6 | +4.35 | +5.1 | +6.9 | +▇▁▆▇▂ | +
| Petal.Width | +0 | +1 | +1.20 | +0.76 | +0.1 | +0.3 | +1.30 | +1.8 | +2.5 | +▇▁▇▅▃ | +
| Sepal.Length | +0 | +1 | +5.84 | +0.83 | +4.3 | +5.1 | +5.80 | +6.4 | +7.9 | +▆▇▇▅▂ | +
| Sepal.Width | +0 | +1 | +3.06 | +0.44 | +2.0 | +2.8 | +3.00 | +3.3 | +4.4 | +▁▆▇▂▁ | +
We choose the support vector machine implementation from the e1071 package (which is based on LIBSVM) and use it as a classification machine by setting type to "C-classification".
learner = lrn("classif.svm", type = "C-classification", kernel = "radial")For tuning, it is important to create a search space that defines the type and range of the hyperparameters. A learner stores all information about its hyperparameters in the slot $param_set. Not all parameters are tunable. We have to choose a subset of the hyperparameters we want to tune.
as.data.table(learner$param_set)[, .(id, class, lower, upper, nlevels)]We use the to_tune() function to define the range over which the hyperparameter should be tuned. We opt for the cost and gamma hyperparameters of the radial kernel and set the tuning ranges with lower and upper bounds.
learner$param_set$values$cost = to_tune(0.1, 10)
+learner$param_set$values$gamma = to_tune(0, 5)We specify how to evaluate the performance of the different hyperparameter configurations. For this, we choose 3-fold cross validation as the resampling strategy and the classification error as the performance measure.
+resampling = rsmp("cv", folds = 3)
+measure = msr("classif.ce")Usually, we have to select a budget for the tuning. This is done by choosing a Terminator, which stops the tuning e.g. after a performance level is reached or after a given time. However, some tuners like grid search terminate themselves. In this case, we choose a terminator that never stops and the tuning is not stopped before all grid points are evaluated.
terminator = trm("none")At this point, we can construct a TuningInstanceSingleCrit that describes the tuning problem.
instance = TuningInstanceSingleCrit$new(
+ task = task,
+ learner = learner,
+ resampling = resampling,
+ measure = measure,
+ terminator = terminator
+)
+
+print(instance)<TuningInstanceSingleCrit>
+* State: Not optimized
+* Objective: <ObjectiveTuning:classif.svm_on_iris>
+* Search Space:
+ id class lower upper nlevels
+1: cost ParamDbl 0.1 10 Inf
+2: gamma ParamDbl 0.0 5 Inf
+* Terminator: <TerminatorNone>Finally, we have to choose a Tuner. Grid Search discretizes numeric parameters into a given resolution and constructs a grid from the Cartesian product of these sets. Categorical parameters produce a grid over all levels specified in the search space. In this example, we only use a resolution of 5 to keep the runtime low. Usually, a higher resolution is used to create a denser grid.
tuner = tnr("grid_search", resolution = 5)
+
+print(tuner)<TunerGridSearch>: Grid Search
+* Parameters: resolution=5, batch_size=1
+* Parameter classes: ParamLgl, ParamInt, ParamDbl, ParamFct
+* Properties: dependencies, single-crit, multi-crit
+* Packages: mlr3tuningWe can preview the proposed configurations by using generate_design_grid(). This function is internally executed by TunerGridSearch.
generate_design_grid(learner$param_set$search_space(), resolution = 5)<Design> with 25 rows:
+ cost gamma
+ 1: 0.100 0.00
+ 2: 0.100 1.25
+ 3: 0.100 2.50
+ 4: 0.100 3.75
+ 5: 0.100 5.00
+ 6: 2.575 0.00
+ 7: 2.575 1.25
+ 8: 2.575 2.50
+ 9: 2.575 3.75
+10: 2.575 5.00
+11: 5.050 0.00
+12: 5.050 1.25
+13: 5.050 2.50
+14: 5.050 3.75
+15: 5.050 5.00
+16: 7.525 0.00
+17: 7.525 1.25
+18: 7.525 2.50
+19: 7.525 3.75
+20: 7.525 5.00
+21: 10.000 0.00
+22: 10.000 1.25
+23: 10.000 2.50
+24: 10.000 3.75
+25: 10.000 5.00
+ cost gammaWe trigger the tuning by passing the TuningInstanceSingleCrit to the $optimize() method of the Tuner. The instance is modified in-place.
tuner$optimize(instance) cost gamma learner_param_vals x_domain classif.ce
+1: 5.05 1.25 <list[4]> <list[2]> 0.06We plot the performances depending on the evaluated cost and gamma values.
autoplot(instance, type = "surface", cols_x = c("cost", "gamma"),
+ learner = lrn("regr.km"))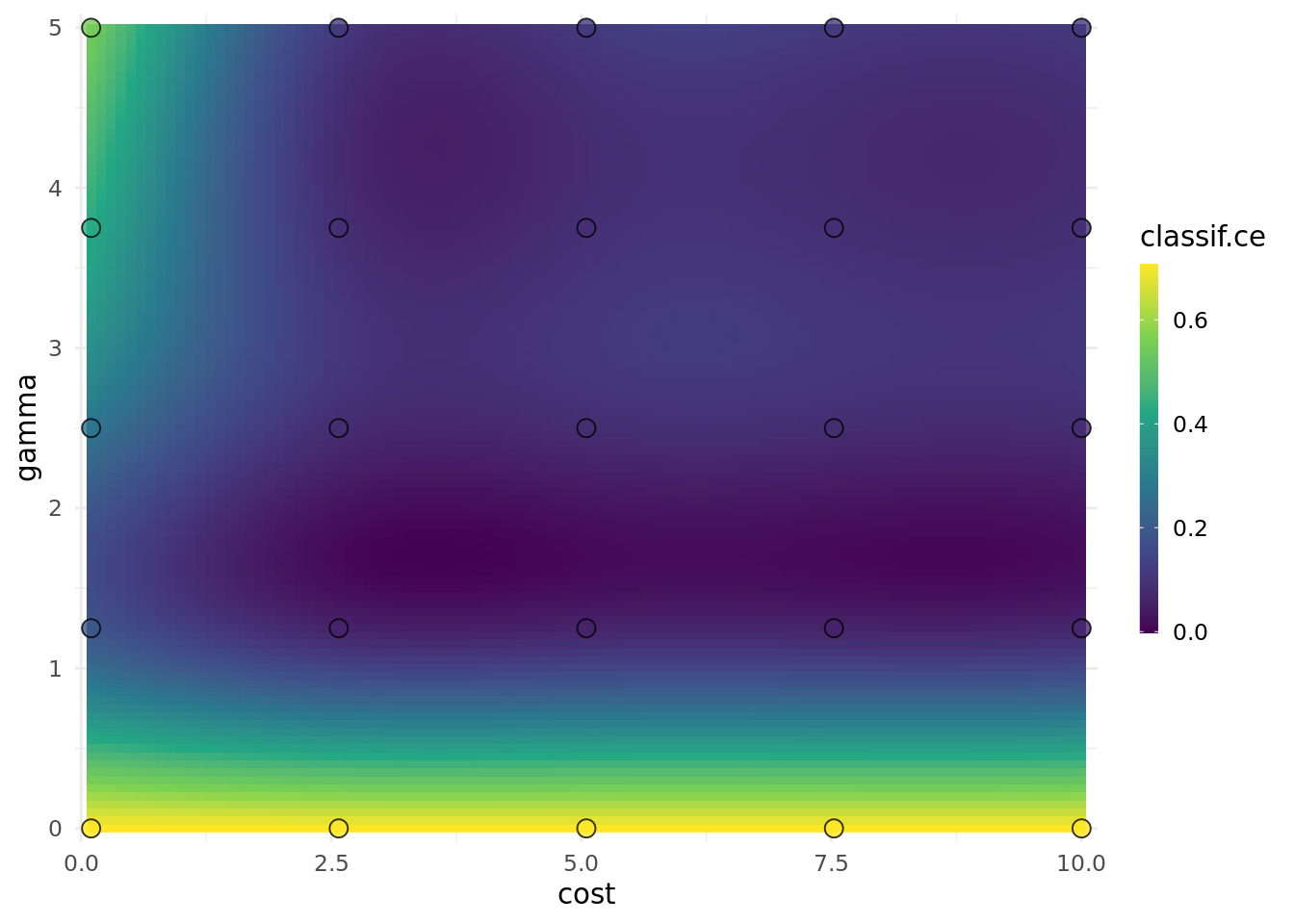
The points mark the evaluated cost and gamma values. We should not infer the performance of new values from the heatmap since it is only an interpolation. However, we can see the general interaction between the hyperparameters.
Tuning a learner can be shortened by using the tune()-shortcut.
learner = lrn("classif.svm", type = "C-classification", kernel = "radial")
+learner$param_set$values$cost = to_tune(0.1, 10)
+learner$param_set$values$gamma = to_tune(0, 5)
+
+instance = tune(
+ tuner = tnr("grid_search", resolution = 5),
+ task = tsk("iris"),
+ learner = learner,
+ resampling = rsmp ("holdout"),
+ measure = msr("classif.ce")
+)Next, we want to tune the cost and gamma hyperparameter more efficiently. It is recommended to tune cost and gamma on the logarithmic scale (Hsu, Chang, and Lin 2003). The log transformation emphasizes smaller cost and gamma values but also creates large values. Therefore, we use a log transformation to emphasize this region of the search space with a denser grid.
Generally speaking, transformations can be used to convert hyperparameters to a new scale. These transformations are applied before the proposed configuration is passed to the Learner. We can directly define the transformation in the to_tune() function. The lower and upper bound is set on the original scale.
learner = lrn("classif.svm", type = "C-classification", kernel = "radial")
+
+# tune from 2^-15 to 2^15 on a log scale
+learner$param_set$values$cost = to_tune(p_dbl(-15, 15, trafo = function(x) 2^x))
+
+# tune from 2^-15 to 2^5 on a log scale
+learner$param_set$values$gamma = to_tune(p_dbl(-15, 5, trafo = function(x) 2^x))Transformations to the log scale are the ones most commonly used. We can use a shortcut for this transformation. The lower and upper bound is set on the transformed scale.
+learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))We use the tune()-shortcut to run the tuning.
instance = tune(
+ tuner = tnr("grid_search", resolution = 5),
+ task = task,
+ learner = learner,
+ resampling = resampling,
+ measure = measure
+)The hyperparameter values after the transformation are stored in the x_domain column as lists. We can expand these lists into multiple columns by using as.data.table(). The hyperparameter names are prefixed by x_domain.
as.data.table(instance$archive)[, .(cost, gamma, x_domain_cost, x_domain_gamma)] cost gamma x_domain_cost x_domain_gamma
+ 1: -5.756463 -11.512925 3.162278e-03 1.000000e-05
+ 2: 0.000000 11.512925 1.000000e+00 1.000000e+05
+ 3: -11.512925 11.512925 1.000000e-05 1.000000e+05
+ 4: 11.512925 5.756463 1.000000e+05 3.162278e+02
+ 5: -11.512925 0.000000 1.000000e-05 1.000000e+00
+ 6: 11.512925 -5.756463 1.000000e+05 3.162278e-03
+ 7: 11.512925 0.000000 1.000000e+05 1.000000e+00
+ 8: -11.512925 5.756463 1.000000e-05 3.162278e+02
+ 9: 0.000000 0.000000 1.000000e+00 1.000000e+00
+10: 5.756463 0.000000 3.162278e+02 1.000000e+00
+11: 0.000000 -5.756463 1.000000e+00 3.162278e-03
+12: 0.000000 -11.512925 1.000000e+00 1.000000e-05
+13: -5.756463 -5.756463 3.162278e-03 3.162278e-03
+14: 11.512925 -11.512925 1.000000e+05 1.000000e-05
+15: 5.756463 11.512925 3.162278e+02 1.000000e+05
+16: 0.000000 5.756463 1.000000e+00 3.162278e+02
+17: -5.756463 0.000000 3.162278e-03 1.000000e+00
+18: 5.756463 -11.512925 3.162278e+02 1.000000e-05
+19: -5.756463 11.512925 3.162278e-03 1.000000e+05
+20: 11.512925 11.512925 1.000000e+05 1.000000e+05
+21: 5.756463 -5.756463 3.162278e+02 3.162278e-03
+22: -11.512925 -11.512925 1.000000e-05 1.000000e-05
+23: -11.512925 -5.756463 1.000000e-05 3.162278e-03
+24: 5.756463 5.756463 3.162278e+02 3.162278e+02
+25: -5.756463 5.756463 3.162278e-03 3.162278e+02
+ cost gamma x_domain_cost x_domain_gammaWe plot the performances depending on the evaluated cost and gamma values.
library(ggplot2)
+library(scales)
+autoplot(instance, type = "points", cols_x = c("x_domain_cost", "x_domain_gamma")) +
+ scale_x_continuous(
+ trans = log2_trans(),
+ breaks = trans_breaks("log10", function(x) 10^x),
+ labels = trans_format("log10", math_format(10^.x))) +
+ scale_y_continuous(
+ trans = log2_trans(),
+ breaks = trans_breaks("log10", function(x) 10^x),
+ labels = trans_format("log10", math_format(10^.x)))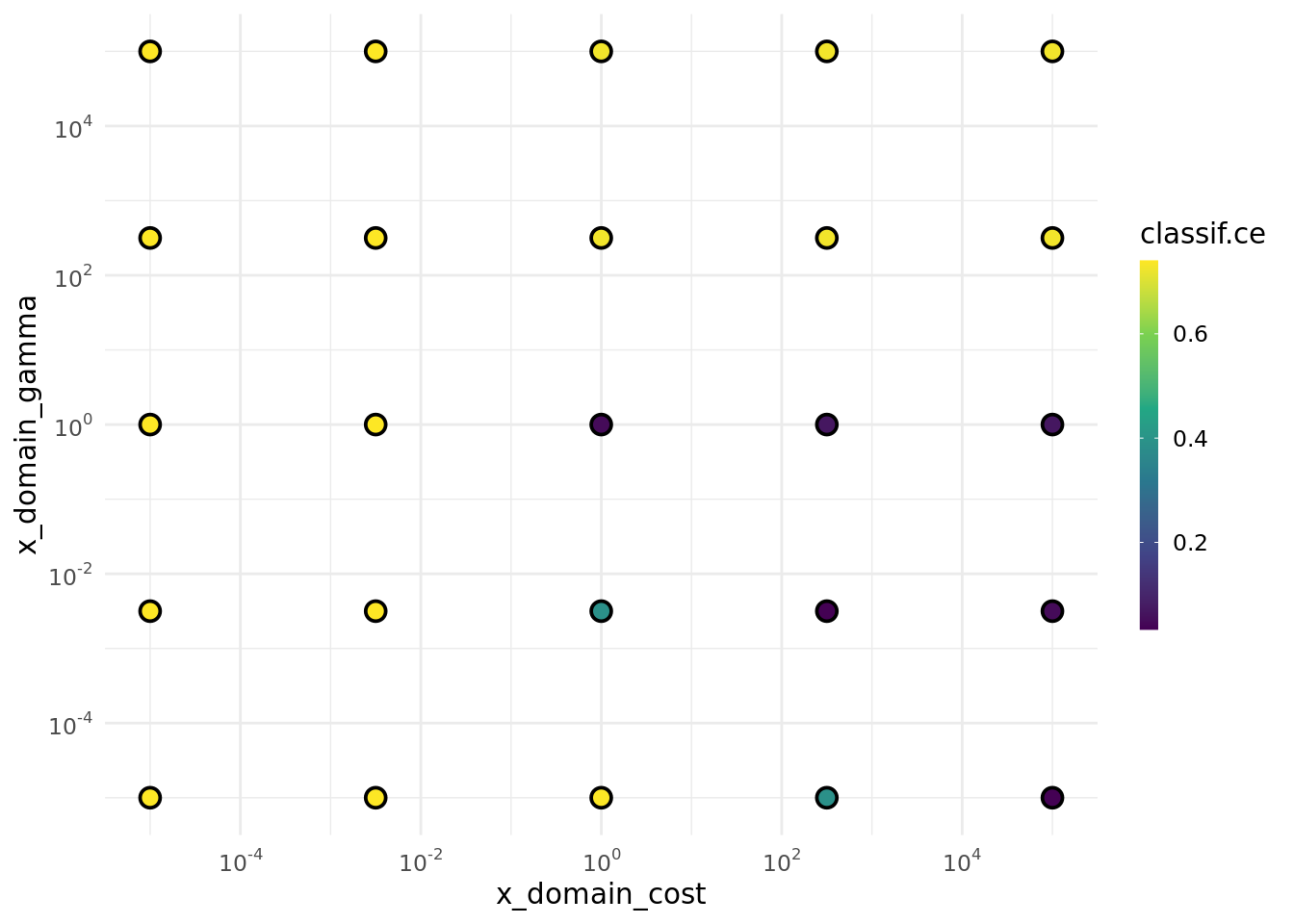
Dependencies ensure that certain parameters are only proposed depending on values of other hyperparameters. We want to tune the degree hyperparameter that is only needed for the polynomial kernel.
learner = lrn("classif.svm", type = "C-classification")
+
+learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+
+learner$param_set$values$kernel = to_tune(c("polynomial", "radial"))
+learner$param_set$values$degree = to_tune(1, 4)The dependencies are already stored in the learner parameter set.
+learner$param_set$deps id on cond
+1: cost type <CondEqual[9]>
+2: nu type <CondEqual[9]>
+3: degree kernel <CondEqual[9]>
+4: coef0 kernel <CondAnyOf[9]>
+5: gamma kernel <CondAnyOf[9]>The gamma hyperparameter depends on the kernel being polynomial, radial or sigmoid
learner$param_set$deps$cond[[5]]CondAnyOf: x ∈ {polynomial, radial, sigmoid}whereas the degree hyperparameter is solely used by the polynomial kernel.
learner$param_set$deps$cond[[3]]CondEqual: x = polynomialWe preview the grid to show the effect of the dependencies.
+generate_design_grid(learner$param_set$search_space(), resolution = 2)<Design> with 12 rows:
+ cost gamma kernel degree
+ 1: -11.51293 -11.51293 polynomial 1
+ 2: -11.51293 -11.51293 polynomial 4
+ 3: -11.51293 -11.51293 radial NA
+ 4: -11.51293 11.51293 polynomial 1
+ 5: -11.51293 11.51293 polynomial 4
+ 6: -11.51293 11.51293 radial NA
+ 7: 11.51293 -11.51293 polynomial 1
+ 8: 11.51293 -11.51293 polynomial 4
+ 9: 11.51293 -11.51293 radial NA
+10: 11.51293 11.51293 polynomial 1
+11: 11.51293 11.51293 polynomial 4
+12: 11.51293 11.51293 radial NAThe value for degree is NA if the dependency on the kernel is not satisfied.
We use the tune()-shortcut to run the tuning.
instance = tune(
+ tuner = tnr("grid_search", resolution = 3),
+ task = task,
+ learner = learner,
+ resampling = resampling,
+ measure = measure
+)instance$result cost gamma kernel degree learner_param_vals x_domain classif.ce
+1: 0 11.51293 polynomial 1 <list[5]> <list[4]> 0.02666667We add the optimized hyperparameters to the learner and train the learner on the full dataset.
+learner = lrn("classif.svm")
+learner$param_set$values = instance$result_learner_param_vals
+learner$train(task)The trained model can now be used to make predictions on new data. A common mistake is to report the performance estimated on the resampling sets on which the tuning was performed (instance$result_y) as the model’s performance. These scores might be biased and overestimate the ability of the fitted model to predict with new data. Instead, we have to use nested resampling to get an unbiased performance estimate.
Tuning should not be performed on the same resampling sets which are used for evaluating the model itself, since this would result in a biased performance estimate. Nested resampling uses an outer and inner resampling to separate the tuning from the performance estimation of the model. We can use the AutoTuner class for running nested resampling. The AutoTuner wraps a Learner and tunes the hyperparameter of the learner during $train(). This is our inner resampling loop.
learner = lrn("classif.svm", type = "C-classification")
+learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$kernel = to_tune(c("polynomial", "radial"))
+learner$param_set$values$degree = to_tune(1, 4)
+
+resampling_inner = rsmp("cv", folds = 3)
+terminator = trm("none")
+tuner = tnr("grid_search", resolution = 3)
+
+at = AutoTuner$new(
+ learner = learner,
+ resampling = resampling_inner,
+ measure = measure,
+ terminator = terminator,
+ tuner = tuner,
+ store_models = TRUE)We put the AutoTuner into a resample() call to get the outer resampling loop.
resampling_outer = rsmp("cv", folds = 3)
+rr = resample(task = task, learner = at, resampling = resampling_outer, store_models = TRUE)We check the inner tuning results for stable hyperparameters. This means that the selected hyperparameters should not vary too much. We might observe unstable models in this example because the small data set and the low number of resampling iterations might introduce too much randomness. Usually, we aim for the selection of stable hyperparameters for all outer training sets.
+extract_inner_tuning_results(rr)[, .SD, .SDcols = !c("learner_param_vals", "x_domain")] iteration cost gamma kernel degree classif.ce task_id learner_id resampling_id
+1: 1 0.00000 0.00000 polynomial 1 0.03000594 iris classif.svm.tuned cv
+2: 2 0.00000 0.00000 polynomial 1 0.03000594 iris classif.svm.tuned cv
+3: 3 11.51293 -11.51293 radial NA 0.02020202 iris classif.svm.tuned cvNext, we want to compare the predictive performances estimated on the outer resampling to the inner resampling (extract_inner_tuning_results(rr)). Significantly lower predictive performances on the outer resampling indicate that the models with the optimized hyperparameters overfit the data.
rr$score()[, .(iteration, task_id, learner_id, resampling_id, classif.ce)] iteration task_id learner_id resampling_id classif.ce
+1: 1 iris classif.svm.tuned cv 0.04
+2: 2 iris classif.svm.tuned cv 0.06
+3: 3 iris classif.svm.tuned cv 0.00The archives of the AutoTuners allows us to inspect all evaluated hyperparameters configurations with the associated predictive performances.
extract_inner_tuning_archives(rr, unnest = NULL, exclude_columns = c("resample_result", "uhash", "x_domain", "timestamp")) iteration cost gamma kernel degree classif.ce runtime_learners batch_nr warnings errors task_id
+ 1: 1 0.00000 -11.51293 polynomial 2 0.68033274 0.017 1 0 0 iris
+ 2: 1 0.00000 -11.51293 radial NA 0.64111705 0.017 2 0 0 iris
+ 3: 1 0.00000 0.00000 polynomial 1 0.03000594 0.017 3 0 0 iris
+ 4: 1 11.51293 0.00000 polynomial 1 0.05050505 0.012 4 0 0 iris
+ 5: 1 11.51293 11.51293 radial NA 0.66013072 0.014 5 0 0 iris
+ ---
+104: 3 11.51293 -11.51293 polynomial 2 0.68924540 0.013 32 0 0 iris
+105: 3 -11.51293 -11.51293 radial NA 0.68924540 0.012 33 0 0 iris
+106: 3 -11.51293 11.51293 polynomial 4 0.11883541 0.015 34 0 0 iris
+107: 3 0.00000 -11.51293 polynomial 4 0.68924540 0.015 35 0 0 iris
+108: 3 11.51293 11.51293 polynomial 1 0.06951872 0.725 36 0 0 iris
+ learner_id resampling_id
+ 1: classif.svm.tuned cv
+ 2: classif.svm.tuned cv
+ 3: classif.svm.tuned cv
+ 4: classif.svm.tuned cv
+ 5: classif.svm.tuned cv
+ ---
+104: classif.svm.tuned cv
+105: classif.svm.tuned cv
+106: classif.svm.tuned cv
+107: classif.svm.tuned cv
+108: classif.svm.tuned cvThe aggregated performance of all outer resampling iterations is essentially the unbiased performance of an SVM with optimal hyperparameter found by grid search.
+rr$aggregate()classif.ce
+0.03333333 Applying nested resampling can be shortened by using the tune_nested()-shortcut.
learner = lrn("classif.svm", type = "C-classification")
+learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$kernel = to_tune(c("polynomial", "radial"))
+learner$param_set$values$degree = to_tune(1, 4)
+
+rr = tune_nested(
+ tuner = tnr("grid_search", resolution = 3),
+ task = tsk("iris"),
+ learner = learner,
+ inner_resampling = rsmp ("cv", folds = 3),
+ outer_resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+)The mlr3book includes chapters on tuning spaces and hyperparameter tuning. The mlr3cheatsheets contain frequently used commands and workflows of mlr3.
+ + + +# include: false
+requireNamespace("bst")Loading required namespace: bstrequireNamespace("fastICA")Loading required namespace: fastICAIn this use case we show how to tune a rather complex graph consisting of different preprocessing steps and different learners where each preprocessing step and learner itself has parameters that can be tuned. You will learn the following:
+Graph that consists of two common preprocessing steps, then switches between two dimensionality reduction techniques followed by a Learner vs. no dimensionality reduction followed by another Learnergrid search to find an optimal choice of preprocessing steps and hyperparameters.Ideally you already had a look at how to tune over multiple learners.
+First, we load the packages we will need:
+library(mlr3verse)
+library(mlr3learners)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")We are going to work with some gene expression data included as a supplement in the bst package. The data consists of 2308 gene profiles in 63 training and 20 test samples. The following data preprocessing steps are done analogously as in vignette("khan", package = "bst"):
datafile = system.file("extdata", "supplemental_data", package = "bst")
+dat0 = read.delim(datafile, header = TRUE, skip = 1)[, -(1:2)]
+dat0 = t(dat0)
+dat = data.frame(dat0[!(rownames(dat0) %in%
+ c("TEST.9", "TEST.13", "TEST.5", "TEST.3", "TEST.11")), ])
+dat$class = as.factor(
+ c(substr(rownames(dat)[1:63], start = 1, stop = 2),
+ c("NB", "RM", "NB", "EW", "RM", "BL", "EW", "RM", "EW", "EW", "EW", "RM",
+ "BL", "RM", "NB", "NB", "NB", "NB", "BL", "EW")
+ )
+)We then construct our training and test Task :
task = as_task_classif(dat, target = "class", id = "SRBCT")
+task_train = task$clone(deep = TRUE)
+task_train$filter(1:63)
+task_test = task$clone(deep = TRUE)
+task_test$filter(64:83)Our graph will start with log transforming the features, followed by scaling them. Then, either a PCA or ICA is applied to extract principal / independent components followed by fitting a LDA or a ranger random forest is fitted without any preprocessing (the log transformation and scaling should most likely affect the LDA more than the ranger random forest). Regarding the PCA and ICA, both the number of principal / independent components are tuning parameters. Regarding the LDA, we can further choose different methods for estimating the mean and variance and regarding the ranger, we want to tune the mtry and num.tree parameters. Note that the PCA-LDA combination has already been successfully applied in different cancer diagnostic contexts when the feature space is of high dimensionality (Morais and Lima 2018).
To allow for switching between the PCA / ICA-LDA and ranger we can either use branching or proxy pipelines, i.e., PipeOpBranch and PipeOpUnbranch or PipeOpProxy. We will first cover branching in detail and later show how the same can be done using PipeOpProxy.
First, we have a look at the baseline classification accuracy of the LDA and ranger on the training task:
base = benchmark(benchmark_grid(
+ task_train,
+ learners = list(lrn("classif.lda"), lrn("classif.ranger")),
+ resamplings = rsmp("cv", folds = 3)))Warning in lda.default(x, grouping, ...): variables are collinear
+
+Warning in lda.default(x, grouping, ...): variables are collinear
+
+Warning in lda.default(x, grouping, ...): variables are collinearbase$aggregate(measures = msr("classif.acc")) nr task_id learner_id resampling_id iters classif.acc
+1: 1 SRBCT classif.lda cv 3 0.6666667
+2: 2 SRBCT classif.ranger cv 3 0.9206349
+Hidden columns: resample_resultThe out-of-the-box ranger appears to already have good performance on the training task. Regarding the LDA, we do get a warning message that some features are colinear. This strongly suggests to reduce the dimensionality of the feature space. Let’s see if we can get some better performance, at least for the LDA.
Our graph starts with log transforming the features (we explicitly use base 10 only for better interpretability when inspecting the model later), using PipeOpColApply, followed by scaling the features using PipeOpScale. Then, the first branch allows for switching between the PCA / ICA-LDA and ranger, and within PCA / ICA-LDA, the second branch allows for switching between PCA and ICA:
graph1 =
+ po("colapply", applicator = function(x) log(x, base = 10)) %>>%
+ po("scale") %>>%
+ # pca / ica followed by lda vs. ranger
+ po("branch", id = "branch_learner", options = c("pca_ica_lda", "ranger")) %>>%
+ gunion(list(
+ po("branch", id = "branch_preproc_lda", options = c("pca", "ica")) %>>%
+ gunion(list(
+ po("pca"), po("ica")
+ )) %>>%
+ po("unbranch", id = "unbranch_preproc_lda") %>>%
+ lrn("classif.lda"),
+ lrn("classif.ranger")
+ )) %>>%
+ po("unbranch", id = "unbranch_learner")Note that the names of the options within each branch are arbitrary, but ideally they describe what is happening. Therefore we go with "pca_ica_lda" / "ranger” and "pca" / "ica". Finally, we also could have used the branch ppl to make branching easier (we will come back to this in the Proxy section). The graph looks like the following:
graph1$plot(html = FALSE)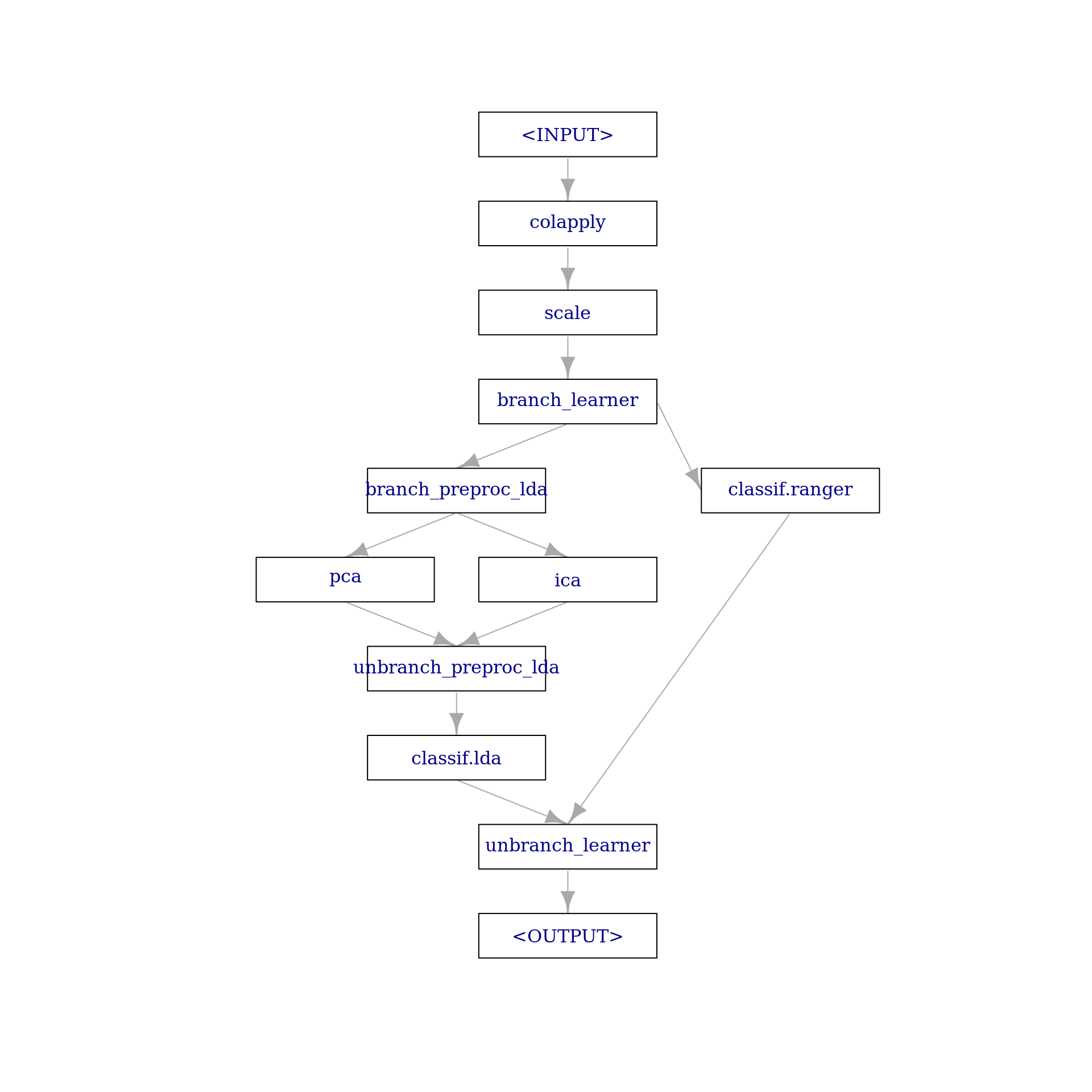
We can inspect the parameters of the ParamSet of the graph to see which parameters can be set:
graph1$param_set$ids() [1] "colapply.applicator" "colapply.affect_columns"
+ [3] "scale.center" "scale.scale"
+ [5] "scale.robust" "scale.affect_columns"
+ [7] "branch_learner.selection" "branch_preproc_lda.selection"
+ [9] "pca.center" "pca.scale."
+[11] "pca.rank." "pca.affect_columns"
+[13] "ica.n.comp" "ica.alg.typ"
+[15] "ica.fun" "ica.alpha"
+[17] "ica.method" "ica.row.norm"
+[19] "ica.maxit" "ica.tol"
+[21] "ica.verbose" "ica.w.init"
+[23] "ica.affect_columns" "classif.lda.dimen"
+[25] "classif.lda.method" "classif.lda.nu"
+[27] "classif.lda.predict.method" "classif.lda.predict.prior"
+[29] "classif.lda.prior" "classif.lda.tol"
+[31] "classif.ranger.alpha" "classif.ranger.always.split.variables"
+[33] "classif.ranger.class.weights" "classif.ranger.holdout"
+[35] "classif.ranger.importance" "classif.ranger.keep.inbag"
+[37] "classif.ranger.max.depth" "classif.ranger.min.node.size"
+[39] "classif.ranger.min.prop" "classif.ranger.minprop"
+[41] "classif.ranger.mtry" "classif.ranger.mtry.ratio"
+[43] "classif.ranger.num.random.splits" "classif.ranger.num.threads"
+[45] "classif.ranger.num.trees" "classif.ranger.oob.error"
+[47] "classif.ranger.regularization.factor" "classif.ranger.regularization.usedepth"
+[49] "classif.ranger.replace" "classif.ranger.respect.unordered.factors"
+[51] "classif.ranger.sample.fraction" "classif.ranger.save.memory"
+[53] "classif.ranger.scale.permutation.importance" "classif.ranger.se.method"
+[55] "classif.ranger.seed" "classif.ranger.split.select.weights"
+[57] "classif.ranger.splitrule" "classif.ranger.verbose"
+[59] "classif.ranger.write.forest" The id’s are prefixed by the respective PipeOp they belong to, e.g., pca.rank. refers to the rank. parameter of PipeOpPCA.
Our graph either fits a LDA after applying PCA or ICA, or alternatively a ranger with no preprocessing. These two options each define selection parameters that we can tune. Moreover, within the respective PipeOp’s we want to tune the following parameters: pca.rank., ica.n.comp, classif.lda.method, classif.ranger.mtry, and classif.ranger.num.trees. The first two parameters are integers that in-principal could range from 1 to the number of features. However, for ICA, the upper bound must not exceed the number of observations and as we will later use 3-fold cross-validation as the resampling method for the tuning, we just set the upper bound to 30 (and do the same for PCA). Regarding the classif.lda.method we will only be interested in "moment" estimation vs. minimum volume ellipsoid covariance estimation ("mve"). Moreover, we set the lower bound of classif.ranger.mtry to 200 (which is around the number of features divided by 10) and the upper bound to 1000.
tune_ps1 = ps(
+ branch_learner.selection =
+ p_fct(c("pca_ica_lda", "ranger")),
+ branch_preproc_lda.selection =
+ p_fct(c("pca", "ica"), depends = branch_learner.selection == "pca_ica_lda"),
+ pca.rank. =
+ p_int(1, 30, depends = branch_preproc_lda.selection == "pca"),
+ ica.n.comp =
+ p_int(1, 30, depends = branch_preproc_lda.selection == "ica"),
+ classif.lda.method =
+ p_fct(c("moment", "mve"), depends = branch_preproc_lda.selection == "ica"),
+ classif.ranger.mtry =
+ p_int(200, 1000, depends = branch_learner.selection == "ranger"),
+ classif.ranger.num.trees =
+ p_int(500, 2000, depends = branch_learner.selection == "ranger"))The parameter branch_learner.selection defines whether we go down the left (PCA / ICA followed by LDA) or the right branch (ranger). The parameter branch_preproc_lda.selection defines whether a PCA or ICA will be applied prior to the LDA. The other parameters directly belong to the ParamSet of the PCA / ICA / LDA / ranger. Note that it only makes sense to switch between PCA / ICA if the "pca_ica_lda" branch was selected beforehand. We have to specify this via the depends parameter.
Finally, we also could have proceeded to tune the numeric parameters on a log scale. I.e., looking at pca.rank. the performance difference between rank 1 and 2 is probably much larger than between rank 29 and rank 30. The mlr3tuning Tutorial covers such transformations.
We can now tune the parameters of our graph as defined in the search space with respect to a measure. We will use the classification accuracy. As a resampling method we use 3-fold cross-validation. We will use the TerminatorNone (i.e., no early termination) for terminating the tuning because we will apply a grid search (we use a grid search because it gives nicely plottable and understandable results but if there were much more parameters, random search or more intelligent optimization methods would be preferred to a grid search:
tune1 = TuningInstanceSingleCrit$new(
+ task_train,
+ learner = graph1,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.acc"),
+ search_space = tune_ps1,
+ terminator = trm("none")
+)We then perform a grid search using a resolution of 4 for the numeric parameters. The grid being used will look like the following (note that the dependencies we specified above are handled automatically):
generate_design_grid(tune_ps1, resolution = 4)We trigger the tuning.
+tuner_gs = tnr("grid_search", resolution = 4, batch_size = 10)
+tuner_gs$optimize(tune1) branch_learner.selection branch_preproc_lda.selection pca.rank. ica.n.comp classif.lda.method classif.ranger.mtry
+1: pca_ica_lda ica NA 10 mve NA
+ classif.ranger.num.trees learner_param_vals x_domain classif.acc
+1: NA <list[8]> <list[4]> 0.984127Now, we can inspect the results ordered by the classification accuracy:
as.data.table(tune1$archive)[order(classif.acc), ]We achieve very good accuracy using ranger, more or less regardless how mtry and num.trees are set. However, the LDA also shows very good accuracy when combined with PCA or ICA retaining 30 components.
For now, we decide to use ranger with mtry set to 200 and num.trees set to 1000.
Setting these parameters manually in our graph, then training on the training task and predicting on the test task yields an accuracy of:
+graph1$param_set$values$branch_learner.selection = "ranger"
+graph1$param_set$values$classif.ranger.mtry = 200
+graph1$param_set$values$classif.ranger.num.trees = 1000
+graph1$train(task_train)$unbranch_learner.output
+NULLgraph1$predict(task_test)[[1L]]$score(msr("classif.acc"))classif.acc
+ 1 Note that we also could have wrapped our graph in a GraphLearner and proceeded to use this as a learner in an AutoTuner.
Instead of using branches to split our graph with respect to the learner and preprocessing options, we can also use PipeOpProxy. PipeOpProxy accepts a single content parameter that can contain any other PipeOp or Graph. This is extremely flexible in the sense that we do not have to specify our options during construction. However, the parameters of the contained PipeOp or Graph are no longer directly contained in the ParamSet of the resulting graph. Therefore, when tuning the graph, we do have to make use of a trafo function.
graph2 =
+ po("colapply", applicator = function(x) log(x, base = 10)) %>>%
+ po("scale") %>>%
+ po("proxy")This graph now looks like the following:
+graph2$plot(html = FALSE)
At first, this may look like a linear graph. However, as the content parameter of PipeOpProxy can be tuned and set to contain any other PipeOp or Graph, this will allow for a similar non-linear graph as when doing branching.
graph2$param_set$ids()[1] "colapply.applicator" "colapply.affect_columns" "scale.center" "scale.scale"
+[5] "scale.robust" "scale.affect_columns" "proxy.content" We can tune the graph by using the same search space as before. However, here the trafo function is of central importance to actually set our options and parameters:
tune_ps2 = tune_ps1$clone(deep = TRUE)The trafo function does all the work, i.e., selecting either the PCA / ICA-LDA or ranger as the proxy.content as well as setting the parameters of the respective preprocessing PipeOps and Learners.
proxy_options = list(
+ pca_ica_lda =
+ ppl("branch", graphs = list(pca = po("pca"), ica = po("ica"))) %>>%
+ lrn("classif.lda"),
+ ranger = lrn("classif.ranger")
+)Above, we made use of the branch ppl allowing us to easily construct a branching graph. Of course we also could have use another nested PipeOpProxy to specify the preprocessing options ("pca" vs. "ica") within proxy_options if for some reason we do not want to do branching at all. The trafo function below selects one of the proxy_options from above and sets the respective parameters for the PCA, ICA, LDA and ranger. Here, the argument x is a list which will contain sampled / selected parameters from our ParamSet (in our case, tune_ps2). The return value is a list only including the appropriate proxy.content parameter. In each tuning iteration, the proxy.content parameter of our graph will be set to this value.
tune_ps2$trafo = function(x, param_set) {
+ proxy.content = proxy_options[[x$branch_learner.selection]]
+ if (x$branch_learner.selection == "pca_ica_lda") {
+ # pca_ica_lda
+ proxy.content$param_set$values$branch.selection = x$branch_preproc_lda.selection
+ if (x$branch_preproc_lda.selection == "pca") {
+ proxy.content$param_set$values$pca.rank. = x$pca.rank.
+ } else {
+ proxy.content$param_set$values$ica.n.comp = x$ica.n.comp
+ }
+ proxy.content$param_set$values$classif.lda.method = x$classif.lda.method
+ } else {
+ # ranger
+ proxy.content$param_set$values$mtry = x$classif.ranger.mtry
+ proxy.content$param_set$values$num.trees = x$classif.ranger.num.trees
+ }
+ list(proxy.content = proxy.content)
+}I.e., suppose that the following parameters will be selected from our ParamSet:
x = list(
+ branch_learner.selection = "ranger",
+ classif.ranger.mtry = 200,
+ classif.ranger.num.trees = 500)The trafo function will then return:
tune_ps2$trafo(x)$proxy.content
+<LearnerClassifRanger:classif.ranger>
+* Model: -
+* Parameters: num.threads=1, mtry=200, num.trees=500
+* Packages: mlr3, mlr3learners, ranger
+* Predict Types: [response], prob
+* Feature Types: logical, integer, numeric, character, factor, ordered
+* Properties: hotstart_backward, importance, multiclass, oob_error, twoclass, weightsTuning can be carried out analogously as done above:
+tune2 = TuningInstanceSingleCrit$new(
+ task_train,
+ learner = graph2,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.acc"),
+ search_space = tune_ps2,
+ terminator = trm("none")
+)
+tuner_gs$optimize(tune2)as.data.table(tune2$archive)[order(classif.acc), ]Tuner for real-valued search spaces are not able to tune on integer hyperparameters. However, it is possible to round the real values proposed by a Tuner to integers before passing them to the learner in the evaluation. We show how to apply a parameter transformation to a ParamSet and use this set in the tuning process.
We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)Loading required package: mlr3We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")In this example, we use the k-Nearest-Neighbor classification learner. We want to tune the integer-valued hyperparameter k which defines the numbers of neighbors.
learner = lrn("classif.kknn")
+print(learner$param_set$params$k) id class lower upper levels default
+1: k ParamInt 1 Inf 7We choose generalized simulated annealing as tuning strategy. The param_classes field of TunerGenSA states that the tuner only supports real-valued (ParamDbl) hyperparameter tuning.
print(tnr("gensa"))<TunerGenSA>: Generalized Simulated Annealing
+* Parameters: trace.mat=FALSE, smooth=FALSE
+* Parameter classes: ParamDbl
+* Properties: single-crit
+* Packages: mlr3tuning, bbotk, GenSATo get integer-valued hyperparameter values for k, we construct a search space with a transformation function. The as.integer() function converts any real valued number to an integer by removing the decimal places.
search_space = ps(
+ k = p_dbl(lower = 3, upper = 7.99, trafo = as.integer)
+)We start the tuning and compare the results of the search space to the results in the space of the learners hyperparameter set.
+instance = tune(
+ tuner = tnr("gensa"),
+ task = tsk("iris"),
+ learner = learner,
+ resampling = rsmp("holdout"),
+ measure = msr("classif.ce"),
+ term_evals = 20,
+ search_space = search_space)Warning in optim(theta.old, fun, gradient, control = control, method = method, : one-dimensional optimization by Nelder-Mead is unreliable:
+use "Brent" or optimize() directlyThe optimal k is still a real number in the search space.
instance$result_x_search_space k
+1: 3.82686However, in the learners hyperparameters space, k is an integer value.
instance$result_x_domain$k
+[1] 3The archive shows us that for all real-valued k proposed by GenSA, an integer-valued k in the learner hyperparameter space (x_domain_k) was created.
as.data.table(instance$archive)[, .(k, classif.ce, x_domain_k)] k classif.ce x_domain_k
+ 1: 3.826860 0.06 3
+ 2: 5.996323 0.06 5
+ 3: 5.941332 0.06 5
+ 4: 3.826860 0.06 3
+ 5: 3.826860 0.06 3
+ 6: 3.826860 0.06 3
+ 7: 4.209546 0.06 4
+ 8: 3.444174 0.06 3
+ 9: 4.018203 0.06 4
+10: 3.635517 0.06 3
+11: 3.922532 0.06 3
+12: 3.731189 0.06 3
+13: 3.874696 0.06 3
+14: 3.779024 0.06 3
+15: 3.850778 0.06 3
+16: 3.802942 0.06 3
+17: 3.838819 0.06 3
+18: 3.814901 0.06 3
+19: 3.832840 0.06 3
+20: 3.820881 0.06 3Internally, TunerGenSA was given the parameter types of the search space and therefore suggested real numbers for k. Before the performance of the different k values was evaluated, the transformation function of the search_space parameter set was called and k was transformed to an integer value.
Note that the tuner is not aware of the transformation. This has two problematic consequences: First, the tuner might propose different real valued configurations that after rounding end up to be already evaluated configurations and we end up with re-evaluating the same hyperparameter configuration. This is only problematic, if we only optimze integer parameters. Second, the rounding introduces discontinuities which can be problematic for some tuners.
+We successfully tuned a integer-valued hyperparameter with TunerGenSA which is only suitable for an real-valued search space. This technique is not limited to tuning problems. Optimizer in bbotk can be also used in the same way to produce points with integer parameters.
The use-case illustrated below touches on the following concepts:
+The relevant sections in the mlr3book are linked to for the reader’s convenience.
This use case shows how to model housing price data in King County. Following features are illustrated:
+We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)Loading required package: mlr3We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")We use the kc_housing dataset contained in the package mlr3data in order to provide a use-case for the application of mlr3 on real-world data.
data("kc_housing", package = "mlr3data")In order to get a quick impression of our data, we perform some initial Exploratory Data Analysis. This helps us to get a first impression of our data and might help us arrive at additional features that can help with the prediction of the house prices.
+We can get a quick overview using R’s summary function:
+summary(kc_housing) date price bedrooms bathrooms sqft_living sqft_lot
+ Min. :2014-05-02 00:00:00.0 Min. : 75000 Min. : 0.000 Min. :0.000 Min. : 290 Min. : 520
+ 1st Qu.:2014-07-22 00:00:00.0 1st Qu.: 321950 1st Qu.: 3.000 1st Qu.:1.750 1st Qu.: 1427 1st Qu.: 5040
+ Median :2014-10-16 00:00:00.0 Median : 450000 Median : 3.000 Median :2.250 Median : 1910 Median : 7618
+ Mean :2014-10-29 03:58:09.9 Mean : 540088 Mean : 3.371 Mean :2.115 Mean : 2080 Mean : 15107
+ 3rd Qu.:2015-02-17 00:00:00.0 3rd Qu.: 645000 3rd Qu.: 4.000 3rd Qu.:2.500 3rd Qu.: 2550 3rd Qu.: 10688
+ Max. :2015-05-27 00:00:00.0 Max. :7700000 Max. :33.000 Max. :8.000 Max. :13540 Max. :1651359
+
+ floors waterfront view condition grade sqft_above sqft_basement
+ Min. :1.000 Mode :logical Min. :0.0000 Min. :1.000 Min. : 1.000 Min. : 290 Min. : 10.0
+ 1st Qu.:1.000 FALSE:21450 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.: 7.000 1st Qu.:1190 1st Qu.: 450.0
+ Median :1.500 TRUE :163 Median :0.0000 Median :3.000 Median : 7.000 Median :1560 Median : 700.0
+ Mean :1.494 Mean :0.2343 Mean :3.409 Mean : 7.657 Mean :1788 Mean : 742.4
+ 3rd Qu.:2.000 3rd Qu.:0.0000 3rd Qu.:4.000 3rd Qu.: 8.000 3rd Qu.:2210 3rd Qu.: 980.0
+ Max. :3.500 Max. :4.0000 Max. :5.000 Max. :13.000 Max. :9410 Max. :4820.0
+ NA's :13126
+ yr_built yr_renovated zipcode lat long sqft_living15 sqft_lot15
+ Min. :1900 Min. :1934 Min. :98001 Min. :47.16 Min. :-122.5 Min. : 399 Min. : 651
+ 1st Qu.:1951 1st Qu.:1987 1st Qu.:98033 1st Qu.:47.47 1st Qu.:-122.3 1st Qu.:1490 1st Qu.: 5100
+ Median :1975 Median :2000 Median :98065 Median :47.57 Median :-122.2 Median :1840 Median : 7620
+ Mean :1971 Mean :1996 Mean :98078 Mean :47.56 Mean :-122.2 Mean :1987 Mean : 12768
+ 3rd Qu.:1997 3rd Qu.:2007 3rd Qu.:98118 3rd Qu.:47.68 3rd Qu.:-122.1 3rd Qu.:2360 3rd Qu.: 10083
+ Max. :2015 Max. :2015 Max. :98199 Max. :47.78 Max. :-121.3 Max. :6210 Max. :871200
+ NA's :20699 dim(kc_housing)[1] 21613 20Our dataset has 21613 observations and 20 columns. The variable we want to predict is price. In addition to the price column, we have several other columns:
id: A unique identifier for every house.
date: A date column, indicating when the house was sold. This column is currently not encoded as a date and requires some preprocessing.
zipcode: A column indicating the ZIP code. This is a categorical variable with many factor levels.
long, lat The longitude and latitude of the house
... several other numeric columns providing information about the house, such as number of rooms, square feet etc.
Before we continue with the analysis, we preprocess some features so that they are stored in the correct format.
+First we convert the date column to numeric. To do so, we convert the date to the POSIXct date/time class with the anytime package. Next, use difftime() to convert to days since the first day recorded in the data set:
library(anytime)
+dates = anytime(kc_housing$date)
+kc_housing$date = as.numeric(difftime(dates, min(dates), units = "days"))Afterwards, we convert the zip code to a factor:
+kc_housing$zipcode = as.factor(kc_housing$zipcode)And add a new column renovated indicating whether a house was renovated at some point.
+kc_housing$renovated = as.numeric(!is.na(kc_housing$yr_renovated))
+kc_housing$has_basement = as.numeric(!is.na(kc_housing$sqft_basement))We drop the id column which provides no information about the house prices:
+kc_housing$id = NULLAdditionally, we convert the price from Dollar to units of 1000 Dollar to improve readability.
+kc_housing$price = kc_housing$price / 1000Additionally, for now we simply drop the columns that have missing values, as some of our learners can not deal with them. A better option to deal with missing values would be imputation, i.e. replacing missing values with valid ones. We will deal with this in a separate article.
+kc_housing$yr_renovated = NULL
+kc_housing$sqft_basement = NULLWe can now plot the density of the price to get a first impression on its distribution.
+library(ggplot2)
+ggplot(kc_housing, aes(x = price)) + geom_density()
We can see that the prices for most houses lie between 75.000 and 1.5 million dollars. There are few extreme values of up to 7.7 million dollars.
+Feature engineering often allows us to incorporate additional knowledge about the data and underlying processes. This can often greatly enhance predictive performance. A simple example: A house which has yr_renovated == 0 means that is has not been renovated yet. Additionally, we want to drop features which should not have any influence (id column).
After those initial manipulations, we load all required packages and create a TaskRegr containing our data.
tsk = as_task_regr(kc_housing, target = "price")We can inspect associations between variables using mlr3viz’s autoplot function in order to get some good first impressions for our data. Note, that this does in no way prevent us from using other powerful plot functions of our choice on the original data.
The outcome we want to predict is the price variable. The autoplot function provides a good first glimpse on our data. As the resulting object is a ggplot2 object, we can use faceting and other functions from ggplot2 in order to enhance plots.
autoplot(tsk) + facet_wrap(~renovated)
We can observe that renovated flats seem to achieve higher sales values, and this might thus be a relevant feature.
+Additionally, we can for example look at the condition of the house. Again, we clearly can see that the price rises with increasing condition.
+autoplot(tsk) + facet_wrap(~condition)
In addition to the association with the target variable, the association between the features can also lead to interesting insights. We investigate using variables associated with the quality and size of the house. Note that we use $clone() and $select() to clone the task and select only a subset of the features for the autoplot function, as autoplot per default uses all features. The task is cloned before we select features in order to keep the original task intact.
# Variables associated with quality
+autoplot(tsk$clone()$select(tsk$feature_names[c(3, 17)]), type = "pairs")Registered S3 method overwritten by 'GGally':
+ method from
+ +.gg ggplot2`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
+`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
autoplot(tsk$clone()$select(tsk$feature_names[c(9:12)]), type = "pairs")
In mlr3, we do not create train and test data sets, but instead keep only a vector of train and test indices.
train.idx = sample(seq_len(tsk$nrow), 0.7 * tsk$nrow)
+test.idx = setdiff(seq_len(tsk$nrow), train.idx)We can do the same for our task:
+task_train = tsk$clone()$filter(train.idx)
+task_test = tsk$clone()$filter(test.idx)Decision trees cannot only be used as a powerful tool for predictive models but also for exploratory data analysis. In order to fit a decision tree, we first get the regr.rpart learner from the mlr_learners dictionary by using the sugar function lrn.
For now, we leave out the zipcode variable, as we also have the latitude and longitude of each house. Again, we use $clone(), so we do not change the original task.
tsk_nozip = task_train$clone()$select(setdiff(tsk$feature_names, "zipcode"))
+
+# Get the learner
+lrn = lrn("regr.rpart")
+
+# And train on the task
+lrn$train(tsk_nozip, row_ids = train.idx)plot(lrn$model)
+text(lrn$model)
The learned tree relies on several variables in order to distinguish between cheaper and pricier houses. The features we split along are grade, sqft_living, but also some features related to the area (longitude and latitude). We can visualize the price across different regions in order to get more info:
+# Load the ggmap package in order to visualize on a map
+library(ggmap)
+
+# And create a quick plot for the price
+qmplot(long, lat, maptype = "watercolor", color = log(price),
+ data = kc_housing[train.idx[1:3000], ]) +
+ scale_colour_viridis_c()
# And the zipcode
+qmplot(long, lat, maptype = "watercolor", color = zipcode,
+ data = kc_housing[train.idx[1:3000], ]) + guides(color = FALSE)Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as of ggplot2 3.3.4.
We can see that the price is clearly associated with the zipcode when comparing then two plots. As a result, we might want to indeed use the zipcode column in our future endeavors.
+After getting an initial idea for our data, we might want to construct a first baseline, in order to see what a simple model already can achieve.
+We use resample() with 3-fold cross-validation on our training data in order to get a reliable estimate of the algorithm’s performance on future data. Before we start with defining and training learners, we create a Resampling in order to make sure that we always compare on exactly the same data.
cv3 = rsmp("cv", folds = 3)For the cross-validation we only use the training data by cloning the task and selecting only observations from the training set.
+lrn_rpart = lrn("regr.rpart")
+res = resample(task = task_train, lrn_rpart, cv3)
+res$score(msr("regr.rmse")) task_id learner_id resampling_id iteration regr.rmse
+1: kc_housing regr.rpart cv 1 205.7541
+2: kc_housing regr.rpart cv 2 205.6597
+3: kc_housing regr.rpart cv 3 213.3846
+Hidden columns: task, learner, resampling, predictionsprintf("RMSE of the simple rpart: %s", round(sqrt(res$aggregate()), 2))[1] "RMSE of the simple rpart: 208.3"We might be able to improve upon the RMSE using more powerful learners. We first load the mlr3learners package, which contains the ranger learner (a package which implements the “Random Forest” algorithm).
+library(mlr3learners)
+lrn_ranger = lrn("regr.ranger", num.trees = 15L)
+res = resample(task = task_train, lrn_ranger, cv3)
+res$score(msr("regr.rmse")) task_id learner_id resampling_id iteration regr.rmse
+1: kc_housing regr.ranger cv 1 142.2424
+2: kc_housing regr.ranger cv 2 161.6867
+3: kc_housing regr.ranger cv 3 138.2549
+Hidden columns: task, learner, resampling, predictionsprintf("RMSE of the simple ranger: %s", round(sqrt(res$aggregate()), 2))[1] "RMSE of the simple ranger: 147.75"Often tuning RandomForest methods does not increase predictive performances substantially. If time permits, it can nonetheless lead to improvements and should thus be performed. In this case, we resort to tune a different kind of model: Gradient Boosted Decision Trees from the package xgboost.
+AutoTunerTuning can often further improve the performance. In this case, we tune the xgboost learner in order to see whether this can improve performance. For the AutoTuner we have to specify a Termination Criterion (how long the tuning should run) a Tuner (which tuning method to use) and a ParamSet (which space we might want to search through). For now, we do not use the zipcode column, as xgboost cannot naturally deal with categorical features. The AutoTuner automatically performs nested cross-validation.
lrn_xgb = lrn("regr.xgboost")
+
+# Define the search space
+search_space = ps(
+ eta = p_dbl(lower = 0.2, upper = .4),
+ min_child_weight = p_dbl(lower = 1, upper = 20),
+ subsample = p_dbl(lower = .7, upper = .8),
+ colsample_bytree = p_dbl(lower = .9, upper = 1),
+ colsample_bylevel = p_dbl(lower = .5, upper = .7),
+ nrounds = p_int(lower = 1L, upper = 25))
+
+at = auto_tuner(
+ tuner = tnr("random_search", batch_size = 40),
+ learner = lrn_xgb,
+ resampling = rsmp("holdout"),
+ measure = msr("regr.rmse"),
+ search_space = search_space,
+ term_evals = 10)# And resample the AutoTuner
+res = resample(tsk_nozip, at, cv3, store_models = TRUE)res$score(msr("regr.rmse")) task_id learner_id resampling_id iteration regr.rmse
+1: kc_housing regr.xgboost.tuned cv 1 147.0554
+2: kc_housing regr.xgboost.tuned cv 2 136.4282
+3: kc_housing regr.xgboost.tuned cv 3 132.4484
+Hidden columns: task, learner, resampling, predictionsprintf("RMSE of the tuned xgboost: %s", round(sqrt(res$aggregate()), 2))[1] "RMSE of the tuned xgboost: 138.78"We can obtain the resulting parameters in the respective splits by accessing the ResampleResult.
sapply(res$learners, function(x) x$learner$param_set$values)[-2, ] [,1] [,2] [,3]
+nrounds 25 23 24
+verbose 0 0 0
+early_stopping_set "none" "none" "none"
+eta 0.220869 0.3809271 0.2115116
+min_child_weight 1.885109 7.472919 1.910491
+subsample 0.7542127 0.7884631 0.7000357
+colsample_bytree 0.9032271 0.9675298 0.9120812
+colsample_bylevel 0.5259713 0.6817893 0.630818 NOTE: To keep runtime low, we only tune parts of the hyperparameter space of xgboost in this example. Additionally, we only allow for \(10\) random search iterations, which is usually too little for real-world applications. Nonetheless, we are able to obtain an improved performance when comparing to the ranger model.
+In order to further improve our results we have several options:
+Below we will investigate some of those possibilities and investigate whether this improves performance.
+In order to better cluster the zip codes, we compute a new feature: med_price: It computes the median price in each zip-code. This might help our model to improve the prediction. This is equivalent to impact encoding more information:
+We can equip a learner with impact encoding using mlr3pipelines. More information on mlr3pipelines can be obtained from other posts.
+lrn_impact = po("encodeimpact", affect_columns = selector_name("zipcode")) %>>% lrn("regr.ranger")Again, we run resample() and compute the RMSE.
res = resample(task = task_train, lrn_impact, cv3)res$score(msr("regr.rmse")) task_id learner_id resampling_id iteration regr.rmse
+1: kc_housing encodeimpact.regr.ranger cv 1 119.4597
+2: kc_housing encodeimpact.regr.ranger cv 2 146.3315
+3: kc_housing encodeimpact.regr.ranger cv 3 125.4193
+Hidden columns: task, learner, resampling, predictionsprintf("RMSE of ranger with med_price: %s", round(sqrt(res$aggregate()), 2))[1] "RMSE of ranger with med_price: 130.91"In many cases, we might want to have a sparse model. For this purpose we can use a mlr3filters::Filter implemented in mlr3filters. This can prevent our learner from overfitting make it easier for humans to interpret models as fewer variables influence the resulting prediction.
In this example, we use PipeOpFilter (via po("filter", ...)) to add a feature-filter before training the model. For a more in-depth insight, refer to the sections on mlr3pipelines and mlr3filters in the mlr3 book: Feature Selection and Pipelines.
filter = flt("mrmr")The resulting RMSE is slightly higher, and at the same time we only use \(12\) features.
+graph = po("filter", filter, param_vals = list(filter.nfeat = 12)) %>>% po("learner", lrn("regr.ranger"))
+lrn_filter = as_learner(graph)
+res = resample(task = task_train, lrn_filter, cv3)res$score(msr("regr.rmse")) task_id learner_id resampling_id iteration regr.rmse
+1: kc_housing mrmr.regr.ranger cv 1 152.6009
+2: kc_housing mrmr.regr.ranger cv 2 156.7883
+3: kc_housing mrmr.regr.ranger cv 3 149.0143
+Hidden columns: task, learner, resampling, predictionsprintf("RMSE of ranger with filtering: %s", round(sqrt(res$aggregate()), 2))[1] "RMSE of ranger with filtering: 152.83"We have seen different ways to improve models with respect to our criteria by:
+A combination of all the above would most likely yield an even better model. This is left as an exercise to the reader.
+The best model we found in this example is the ranger model with the added med_price feature. In a final step, we now want to assess the model’s quality on the held-out data we stored in our task_test. In order to do so, and to prevent data leakage, we can only add the median price from the training data.
library(data.table)
+
+data = task_train$data(cols = c("price", "zipcode"))
+data[, med_price := median(price), by = "zipcode"]
+test_data = task_test$data(cols = "zipcode")
+test = merge(test_data, unique(data[, .(zipcode, med_price)]), all.x = TRUE)
+task_test$cbind(test)Now we can use the augmented task_test to predict on new data.
lrn_ranger$train(task_train)
+pred = lrn_ranger$predict(task_test)
+pred$score(msr("regr.rmse"))regr.rmse
+ 145.01 This tutorial assumes familiarity with the basics of mlr3pipelines. Consult the mlr3book if some aspects are not fully understandable. It deals with the problem of missing data.
+The random forest implementation in the package ranger unfortunately does not support missing values. Therefore, it is required to impute missing features before passing the data to the learner.
+We show how to use mlr3pipelines to augment the ranger learner with automatic imputation.
We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)Loading required package: mlr3We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")First, we take an example task with missing values (pima) and create the ranger learner:
library(mlr3learners)
+
+task = tsk("pima")
+print(task)<TaskClassif:pima> (768 x 9): Pima Indian Diabetes
+* Target: diabetes
+* Properties: twoclass
+* Features (8):
+ - dbl (8): age, glucose, insulin, mass, pedigree, pregnant, pressure, tricepslearner = lrn("classif.ranger")
+print(learner)<LearnerClassifRanger:classif.ranger>
+* Model: -
+* Parameters: num.threads=1
+* Packages: mlr3, mlr3learners, ranger
+* Predict Types: [response], prob
+* Feature Types: logical, integer, numeric, character, factor, ordered
+* Properties: hotstart_backward, importance, multiclass, oob_error, twoclass, weightsWe can now inspect the task for missing values. task$missings() returns the count of missing values for each variable.
task$missings()diabetes age glucose insulin mass pedigree pregnant pressure triceps
+ 0 0 5 374 11 0 0 35 227 Additionally, we can see that the ranger learner can not handle missing values:
learner$properties[1] "hotstart_backward" "importance" "multiclass" "oob_error" "twoclass"
+[6] "weights" For comparison, other learners, e.g. the rpart learner can handle missing values internally.
lrn("classif.rpart")$properties[1] "importance" "missings" "multiclass" "selected_features" "twoclass"
+[6] "weights" Before we dive deeper, we quickly try to visualize the columns with many missing values:
+autoplot(task$clone()$select(c("insulin", "triceps")), type = "pairs")
An overview over implemented PipeOps for imputation can be obtained like so:
as.data.table(mlr_pipeops)[tags %in% "missings", list(key)] key
+1: imputeconstant
+2: imputehist
+3: imputelearner
+4: imputemean
+5: imputemedian
+6: imputemode
+7: imputeoor
+8: imputesamplemlr3pipelines contains several imputation methods. We focus on rather simple ones, and show how to impute missing values for factor features and numeric features respectively.
Since our task only has numeric features, we do not need to deal with imputing factor levels, and can instead concentrate on imputing numeric values:
+We do this in a two-step process: * We create new indicator columns, that tells us whether the value of a feature is “missing” or “present”. We achieve this using the missind PipeOp.
imputehist PipeOp.We also have to make sure to apply the pipe operators in the correct order!
+imp_missind = po("missind")
+imp_num = po("imputehist", affect_columns = selector_type("numeric"))In order to better understand we can look at the results of every PipeOp separately.
We can manually trigger the PipeOp to test the operator on our task:
task_ext = imp_missind$train(list(task))[[1]]
+task_ext$data() diabetes missing_glucose missing_insulin missing_mass missing_pressure missing_triceps
+ 1: pos present missing present present present
+ 2: neg present missing present present present
+ 3: pos present missing present present missing
+ 4: neg present present present present present
+ 5: pos present present present present present
+ ---
+764: neg present present present present present
+765: neg present missing present present present
+766: neg present present present present present
+767: pos present missing present present missing
+768: neg present missing present present presentFor imputehist, we can do the same:
task_ext = imp_num$train(list(task))[[1]]
+task_ext$data() diabetes age pedigree pregnant glucose insulin mass pressure triceps
+ 1: pos 50 0.627 6 148 163.11747 33.6 72 35.000000
+ 2: neg 31 0.351 1 85 160.63628 26.6 66 29.000000
+ 3: pos 32 0.672 8 183 297.18282 23.3 64 8.204983
+ 4: neg 21 0.167 1 89 94.00000 28.1 66 23.000000
+ 5: pos 33 2.288 0 137 168.00000 43.1 40 35.000000
+ ---
+764: neg 63 0.171 10 101 180.00000 32.9 76 48.000000
+765: neg 27 0.340 2 122 83.69836 36.8 70 27.000000
+766: neg 30 0.245 5 121 112.00000 26.2 72 23.000000
+767: pos 47 0.349 1 126 68.49318 30.1 60 24.460702
+768: neg 23 0.315 1 93 17.80534 30.4 70 31.000000This time we obtain the imputed data set without missing values.
task_ext$missings()diabetes age pedigree pregnant glucose insulin mass pressure triceps
+ 0 0 0 0 0 0 0 0 0 Now we have to put all PipeOps together in order to form a graph that handles imputation automatically.
We do this by creating a Graph that copies the data twice, processes each copy using the respective imputation method and afterwards unions the features. For this we need the following two PipeOps : * copy: Creates copies of the data. * featureunion Merges the two tasks together.
graph = po("copy", 2) %>>%
+ gunion(list(imp_missind, imp_num)) %>>%
+ po("featureunion")as a last step we append the learner we planned on using:
+graph = graph %>>% po(learner)We can now visualize the resulting graph:
+graph$plot()
Correct imputation is especially important when applying imputation to held-out data during the predict step. If applied incorrectly, imputation could leak info from the test set, which potentially skews our performance estimates. mlr3pipelines takes this complexity away from the user and handles correct imputation internally.
By wrapping this graph into a GraphLearner, we can now train resample the full graph, here with a 3-fold cross validation:
graph_learner = as_learner(graph)
+rr = resample(task, graph_learner, rsmp("cv", folds = 3))
+rr$aggregate()classif.ce
+ 0.2330729 In some cases, we have missing values only in the data we want to predict on. In order to showcase this, we create a copy of the task with several more missing columns.
+dt = task$data()
+dt[1:10, "age"] = NA
+dt[30:70, "pedigree"] = NA
+task_2 = as_task_classif(dt, id = "pima2", target = "diabetes")And now we learn on task, while trying to predict on task_2.
graph_learner$train(task)
+graph_learner$predict(task_2)<PredictionClassif> for 768 observations:
+ row_ids truth response
+ 1 pos pos
+ 2 neg neg
+ 3 pos pos
+---
+ 766 neg neg
+ 767 pos pos
+ 768 neg negFor factor features, the process works analogously. Instead of using imputehist, we can for example use imputeoor. This will simply replace every NA in each factor variable with a new value missing.
A full graph might the look like this:
+imp_missind = po("missind", affect_columns = NULL, which = "all")
+imp_fct = po("imputeoor", affect_columns = selector_type("factor"))
+graph = po("copy", 2) %>>%
+ gunion(list(imp_missind, imp_num %>>% imp_fct)) %>>%
+ po("featureunion")Note that we specify the parameter affect_columns = NULL when initializing missind, because we also want indicator columns for our factor features. By default, affect_columns would be set to selector_invert(selector_type(c("factor", "ordered", "character"))). We also set the parameter which to "all" to add indicator columns for all features, regardless whether values were missing during training or not.
In order to test out our new graph, we again create a situation where our task has missing factor levels. As the (pima) task does not have any factor levels, we use the famous (boston_housing) task.
# task_bh_1 is the training data without missings
+task_bh_1 = tsk("boston_housing")
+
+# task_bh_2 is the prediction data with missings
+dt = task_bh_1$data()
+dt[1:10, chas := NA][20:30, rm := NA]
+task_bh_2 = as_task_regr(dt, id = "bh", target = "medv")Now we train on task_bh_1 and predict on task_bh_2:
graph_learner = as_learner(graph %>>% po(lrn("regr.ranger")))
+graph_learner$train(task_bh_1)
+graph_learner$predict(task_bh_2)<PredictionRegr> for 506 observations:
+ row_ids truth response
+ 1 24.0 25.16204
+ 2 21.6 22.21102
+ 3 34.7 33.84124
+---
+ 504 23.9 23.68916
+ 505 22.0 22.20551
+ 506 11.9 16.14491Success! We learned how to deal with missing values in less than 10 minutes.
+ + +Remove correlated features with a pipeline.
+This is the first part in a serial of tutorials. The other parts of this series can be found here:
+ +We will walk through this tutorial interactively. The text is kept short to be followed in real time.
+Ensure all packages used in this tutorial are installed. This includes the mlr3verse package, as well as other packages for data handling, cleaning and visualization which we are going to use (data.table, ggplot2, rchallenge, and skimr).
+Then, load the main packages we are going to use:
+library("mlr3verse")
+library("mlr3learners")
+library("mlr3tuning")
+library("data.table")
+library("ggplot2")
+
+lgr::get_logger("mlr3")$set_threshold("warn")The German credit data was originally donated in 1994 by Prof. Dr. Hans Hoffman of the University of Hamburg. A description can be found at the UCI repository. The goal is to classify people by their credit risk (good or bad) using 20 personal, demographic and financial features:
+| Feature Name | +Description | +
|---|---|
| age | +age in years | +
| amount | +amount asked by applicant | +
| credit_history | +past credit history of applicant at this bank | +
| duration | +duration of the credit in months | +
| employment_duration | +present employment since | +
| foreign_worker | +is applicant foreign worker? | +
| housing | +type of apartment rented, owned, for free / no payment | +
| installment_rate | +installment rate in percentage of disposable income | +
| job | +current job information | +
| number_credits | +number of existing credits at this bank | +
| other_debtors | +other debtors/guarantors present? | +
| other_installment_plans | +other installment plans the applicant is paying | +
| people_liable | +number of people being liable to provide maintenance | +
| personal_status_sex | +combination of sex and personal status of applicant | +
| present_residence | +present residence since | +
| property | +properties that applicant has | +
| purpose | +reason customer is applying for a loan | +
| savings | +savings accounts/bonds at this bank | +
| status | +status/balance of checking account at this bank | +
| telephone | +is there any telephone registered for this customer? | +
The dataset we are going to use is a transformed version of this German credit dataset, as provided by the rchallenge package (this transformed dataset was proposed by Ulrike Grömping, with factors instead of dummy variables and corrected features):
+data("german", package = "rchallenge")First, we’ll do a thorough investigation of the dataset.
+We can get a quick overview of our dataset using R’s summary function:
+dim(german)[1] 1000 21str(german)'data.frame': 1000 obs. of 21 variables:
+ $ status : Factor w/ 4 levels "no checking account",..: 1 1 2 1 1 1 1 1 4 2 ...
+ $ duration : int 18 9 12 12 12 10 8 6 18 24 ...
+ $ credit_history : Factor w/ 5 levels "delay in paying off in the past",..: 5 5 3 5 5 5 5 5 5 3 ...
+ $ purpose : Factor w/ 11 levels "others","car (new)",..: 3 1 10 1 1 1 1 1 4 4 ...
+ $ amount : int 1049 2799 841 2122 2171 2241 3398 1361 1098 3758 ...
+ $ savings : Factor w/ 5 levels "unknown/no savings account",..: 1 1 2 1 1 1 1 1 1 3 ...
+ $ employment_duration : Factor w/ 5 levels "unemployed","< 1 yr",..: 2 3 4 3 3 2 4 2 1 1 ...
+ $ installment_rate : Ord.factor w/ 4 levels ">= 35"<"25 <= ... < 35"<..: 4 2 2 3 4 1 1 2 4 1 ...
+ $ personal_status_sex : Factor w/ 4 levels "male : divorced/separated",..: 2 3 2 3 3 3 3 3 2 2 ...
+ $ other_debtors : Factor w/ 3 levels "none","co-applicant",..: 1 1 1 1 1 1 1 1 1 1 ...
+ $ present_residence : Ord.factor w/ 4 levels "< 1 yr"<"1 <= ... < 4 yrs"<..: 4 2 4 2 4 3 4 4 4 4 ...
+ $ property : Factor w/ 4 levels "unknown / no property",..: 2 1 1 1 2 1 1 1 3 4 ...
+ $ age : int 21 36 23 39 38 48 39 40 65 23 ...
+ $ other_installment_plans: Factor w/ 3 levels "bank","stores",..: 3 3 3 3 1 3 3 3 3 3 ...
+ $ housing : Factor w/ 3 levels "for free","rent",..: 1 1 1 1 2 1 2 2 2 1 ...
+ $ number_credits : Ord.factor w/ 4 levels "1"<"2-3"<"4-5"<..: 1 2 1 2 2 2 2 1 2 1 ...
+ $ job : Factor w/ 4 levels "unemployed/unskilled - non-resident",..: 3 3 2 2 2 2 2 2 1 1 ...
+ $ people_liable : Factor w/ 2 levels "3 or more","0 to 2": 2 1 2 1 2 1 2 1 2 2 ...
+ $ telephone : Factor w/ 2 levels "no","yes (under customer name)": 1 1 1 1 1 1 1 1 1 1 ...
+ $ foreign_worker : Factor w/ 2 levels "yes","no": 2 2 2 1 1 1 1 1 2 2 ...
+ $ credit_risk : Factor w/ 2 levels "bad","good": 2 2 2 2 2 2 2 2 2 2 ...Our dataset has 1000 observations and 21 columns. The variable we want to predict is credit_risk (either good or bad), i.e., we aim to classify people by their credit risk.
We also recommend the skimr package as it creates very well readable and understandable overviews:
+skimr::skim(german)| Name | +german | +
| Number of rows | +1000 | +
| Number of columns | +21 | +
| _______________________ | ++ |
| Column type frequency: | ++ |
| factor | +18 | +
| numeric | +3 | +
| ________________________ | ++ |
| Group variables | +None | +
Variable type: factor
+| skim_variable | +n_missing | +complete_rate | +ordered | +n_unique | +top_counts | +
|---|---|---|---|---|---|
| status | +0 | +1 | +FALSE | +4 | +…: 394, no : 274, …: 269, 0<=: 63 | +
| credit_history | +0 | +1 | +FALSE | +5 | +no : 530, all: 293, exi: 88, cri: 49 | +
| purpose | +0 | +1 | +FALSE | +10 | +fur: 280, oth: 234, car: 181, car: 103 | +
| savings | +0 | +1 | +FALSE | +5 | +unk: 603, …: 183, …: 103, 100: 63 | +
| employment_duration | +0 | +1 | +FALSE | +5 | +1 <: 339, >= : 253, 4 <: 174, < 1: 172 | +
| installment_rate | +0 | +1 | +TRUE | +4 | +< 2: 476, 25 : 231, 20 : 157, >= : 136 | +
| personal_status_sex | +0 | +1 | +FALSE | +4 | +mal: 548, fem: 310, fem: 92, mal: 50 | +
| other_debtors | +0 | +1 | +FALSE | +3 | +non: 907, gua: 52, co-: 41 | +
| present_residence | +0 | +1 | +TRUE | +4 | +>= : 413, 1 <: 308, 4 <: 149, < 1: 130 | +
| property | +0 | +1 | +FALSE | +4 | +bui: 332, unk: 282, car: 232, rea: 154 | +
| other_installment_plans | +0 | +1 | +FALSE | +3 | +non: 814, ban: 139, sto: 47 | +
| housing | +0 | +1 | +FALSE | +3 | +ren: 714, for: 179, own: 107 | +
| number_credits | +0 | +1 | +TRUE | +4 | +1: 633, 2-3: 333, 4-5: 28, >= : 6 | +
| job | +0 | +1 | +FALSE | +4 | +ski: 630, uns: 200, man: 148, une: 22 | +
| people_liable | +0 | +1 | +FALSE | +2 | +0 t: 845, 3 o: 155 | +
| telephone | +0 | +1 | +FALSE | +2 | +no: 596, yes: 404 | +
| foreign_worker | +0 | +1 | +FALSE | +2 | +no: 963, yes: 37 | +
| credit_risk | +0 | +1 | +FALSE | +2 | +goo: 700, bad: 300 | +
Variable type: numeric
+| skim_variable | +n_missing | +complete_rate | +mean | +sd | +p0 | +p25 | +p50 | +p75 | +p100 | +hist | +
|---|---|---|---|---|---|---|---|---|---|---|
| duration | +0 | +1 | +20.90 | +12.06 | +4 | +12.0 | +18.0 | +24.00 | +72 | +▇▇▂▁▁ | +
| amount | +0 | +1 | +3271.25 | +2822.75 | +250 | +1365.5 | +2319.5 | +3972.25 | +18424 | +▇▂▁▁▁ | +
| age | +0 | +1 | +35.54 | +11.35 | +19 | +27.0 | +33.0 | +42.00 | +75 | +▇▆▃▁▁ | +
During an exploratory analysis meaningful discoveries could be:
+An explanatory analysis is crucial to get a feeling for your data. On the other hand the data can be validated this way. Non-plausible data can be investigated or outliers can be removed.
+After feeling confident with the data, we want to do modeling now.
+Considering how we are going to tackle the problem of classifying the credit risk relates closely to what mlr3 entities we will use.
+The typical questions that arise when building a machine learning workflow are:
+More systematically in mlr3 they can be expressed via five components:
+Task definition.Learner definition.Measures.First, we are interested in the target which we want to model. Most supervised machine learning problems are regression or classification problems. However, note that other problems include unsupervised learning or time-to-event data (covered in mlr3proba).
+Within mlr3, to distinguish between these problems, we define Tasks. If we want to solve a classification problem, we define a classification task – TaskClassif. For a regression problem, we define a regression task – TaskRegr.
In our case it is clearly our objective to model or predict the binary factor variable credit_risk. Thus, we define a TaskClassif:
task = as_task_classif(german, id = "GermanCredit", target = "credit_risk")Note that the German credit data is also given as an example task which ships with the mlr3 package. Thus, you actually don’t need to construct it yourself, just call tsk("german_credit") to retrieve the object from the dictionary mlr_tasks.
After having decided what should be modeled, we need to decide on how. This means we need to decide which learning algorithms, or Learners are appropriate. Using prior knowledge (e.g. knowing that it is a classification task or assuming that the classes are linearly separable) one ends up with one or more suitable Learners.
Many learners can be obtained via the mlr3learners package. Additionally, many learners are provided via the mlr3extralearners package, from GitHub. These two resources combined account for a large fraction of standard learning algorithms. As mlr3 usually only wraps learners from packages, it is even easy to create a formal Learner by yourself. You may find the section about extending mlr3 in the mlr3book very helpful. If you happen to write your own Learner in mlr3, we would be happy if you share it with the mlr3 community.
All available Learners (i.e. all which you have installed from mlr3, mlr3learners, mlr3extralearners, or self-written ones) are registered in the dictionary mlr_learners:
mlr_learners<DictionaryLearner> with 134 stored values
+Keys: classif.AdaBoostM1, classif.bart, classif.C50, classif.catboost, classif.cforest, classif.ctree,
+ classif.cv_glmnet, classif.debug, classif.earth, classif.featureless, classif.fnn, classif.gam,
+ classif.gamboost, classif.gausspr, classif.gbm, classif.glmboost, classif.glmer, classif.glmnet,
+ classif.IBk, classif.J48, classif.JRip, classif.kknn, classif.ksvm, classif.lda, classif.liblinear,
+ classif.lightgbm, classif.LMT, classif.log_reg, classif.lssvm, classif.mob, classif.multinom,
+ classif.naive_bayes, classif.nnet, classif.OneR, classif.PART, classif.qda, classif.randomForest,
+ classif.ranger, classif.rfsrc, classif.rpart, classif.svm, classif.xgboost, clust.agnes, clust.ap,
+ clust.cmeans, clust.cobweb, clust.dbscan, clust.diana, clust.em, clust.fanny, clust.featureless,
+ clust.ff, clust.hclust, clust.kkmeans, clust.kmeans, clust.MBatchKMeans, clust.mclust, clust.meanshift,
+ clust.pam, clust.SimpleKMeans, clust.xmeans, dens.kde_ks, dens.locfit, dens.logspline, dens.mixed,
+ dens.nonpar, dens.pen, dens.plug, dens.spline, regr.bart, regr.catboost, regr.cforest, regr.ctree,
+ regr.cubist, regr.cv_glmnet, regr.debug, regr.earth, regr.featureless, regr.fnn, regr.gam, regr.gamboost,
+ regr.gausspr, regr.gbm, regr.glm, regr.glmboost, regr.glmnet, regr.IBk, regr.kknn, regr.km, regr.ksvm,
+ regr.liblinear, regr.lightgbm, regr.lm, regr.lmer, regr.M5Rules, regr.mars, regr.mob, regr.nnet,
+ regr.randomForest, regr.ranger, regr.rfsrc, regr.rpart, regr.rsm, regr.rvm, regr.svm, regr.xgboost,
+ surv.akritas, surv.aorsf, surv.blackboost, surv.cforest, surv.coxboost, surv.coxtime, surv.ctree,
+ surv.cv_coxboost, surv.cv_glmnet, surv.deephit, surv.deepsurv, surv.dnnsurv, surv.flexible,
+ surv.gamboost, surv.gbm, surv.glmboost, surv.glmnet, surv.loghaz, surv.mboost, surv.nelson,
+ surv.obliqueRSF, surv.parametric, surv.pchazard, surv.penalized, surv.ranger, surv.rfsrc, surv.svm,
+ surv.xgboostFor our problem, a suitable learner could be one of the following: Logistic regression, CART, random forest (or many more).
+A learner can be initialized with the lrn() function and the name of the learner, e.g., lrn("classif.xxx"). Use ?mlr_learners_xxx to open the help page of a learner named xxx.
For example, a logistic regression can be initialized in the following manner (logistic regression uses R’s glm() function and is provided by the mlr3learners package):
library("mlr3learners")
+learner_logreg = lrn("classif.log_reg")
+print(learner_logreg)<LearnerClassifLogReg:classif.log_reg>
+* Model: -
+* Parameters: list()
+* Packages: mlr3, mlr3learners, stats
+* Predict Types: [response], prob
+* Feature Types: logical, integer, numeric, character, factor, ordered
+* Properties: loglik, twoclassTraining is the procedure, where a model is fitted on the (training) data.
+We start with the example of the logistic regression. However, you will immediately see that the procedure generalizes to any learner very easily.
+An initialized learner can be trained on data using $train():
learner_logreg$train(task)Typically, in machine learning, one does not use the full data which is available but a subset, the so-called training data.
+To efficiently perform a split of the data one could do the following:
+train_set = sample(task$row_ids, 0.8 * task$nrow)
+test_set = setdiff(task$row_ids, train_set)80 percent of the data is used for training. The remaining 20 percent are used for evaluation at a subsequent later point in time. train_set is an integer vector referring to the selected rows of the original dataset:
head(train_set)[1] 836 679 129 930 509 471In mlr3 the training with a subset of the data can be declared by the additional argument row_ids = train_set:
learner_logreg$train(task, row_ids = train_set)The fitted model can be accessed via:
+learner_logreg$model
+Call: stats::glm(formula = task$formula(), family = "binomial", data = data,
+ model = FALSE)
+
+Coefficients:
+ (Intercept) age
+ 0.0688846 -0.0159818
+ amount credit_historycritical account/other credits elsewhere
+ 0.0001329 0.4580373
+credit_historyno credits taken/all credits paid back duly credit_historyexisting credits paid back duly till now
+ -0.5087518 -1.0249187
+ credit_historyall credits at this bank paid back duly duration
+ -1.5582920 0.0360543
+ employment_duration< 1 yr employment_duration1 <= ... < 4 yrs
+ 0.0720620 -0.1262893
+ employment_duration4 <= ... < 7 yrs employment_duration>= 7 yrs
+ -0.5589136 -0.1545512
+ foreign_workerno housingrent
+ 1.3647905 -0.6199554
+ housingown installment_rate.L
+ -0.6851413 0.8838467
+ installment_rate.Q installment_rate.C
+ -0.0385000 -0.1072466
+ jobunskilled - resident jobskilled employee/official
+ 0.9797910 0.7657897
+ jobmanager/self-empl./highly qualif. employee number_credits.L
+ 0.5793418 0.4081443
+ number_credits.Q number_credits.C
+ -0.3386148 -0.0262034
+ other_debtorsco-applicant other_debtorsguarantor
+ 0.4995457 -0.4840799
+ other_installment_plansstores other_installment_plansnone
+ 0.1844457 -0.2035917
+ people_liable0 to 2 personal_status_sexfemale : non-single or male : single
+ -0.2306212 -0.2797497
+ personal_status_sexmale : married/widowed personal_status_sexfemale : single
+ -0.7947385 -0.4173530
+ present_residence.L present_residence.Q
+ 0.0948244 -0.4654771
+ present_residence.C propertycar or other
+ 0.2317025 0.2583020
+ propertybuilding soc. savings agr./life insurance propertyreal estate
+ 0.2595201 0.6821534
+ purposecar (new) purposecar (used)
+ -1.5120761 -0.6224479
+ purposefurniture/equipment purposeradio/television
+ -0.7776132 -0.1649750
+ purposedomestic appliances purposerepairs
+ 0.1966830 0.3824875
+ purposevacation purposeretraining
+ -1.9184037 -0.9364954
+ purposebusiness savings... < 100 DM
+ -1.2647440 -0.2148135
+ savings100 <= ... < 500 DM savings500 <= ... < 1000 DM
+ -0.5445696 -1.4241969
+ savings... >= 1000 DM status... < 0 DM
+ -1.0478097 -0.4584854
+ status0<= ... < 200 DM status... >= 200 DM / salary for at least 1 year
+ -0.8798435 -1.7552018
+ telephoneyes (under customer name)
+ -0.1798432
+
+Degrees of Freedom: 799 Total (i.e. Null); 745 Residual
+Null Deviance: 980.7
+Residual Deviance: 702.6 AIC: 812.6The stored object is a normal glm object and all its S3 methods work as expected:
class(learner_logreg$model)[1] "glm" "lm" summary(learner_logreg$model)
+Call:
+stats::glm(formula = task$formula(), family = "binomial", data = data,
+ model = FALSE)
+
+Deviance Residuals:
+ Min 1Q Median 3Q Max
+-2.3992 -0.6812 -0.3642 0.6939 2.7540
+
+Coefficients:
+ Estimate Std. Error z value Pr(>|z|)
+(Intercept) 0.0688846 1.3333299 0.052 0.958797
+age -0.0159818 0.0105444 -1.516 0.129605
+amount 0.0001329 0.0000502 2.647 0.008110 **
+credit_historycritical account/other credits elsewhere 0.4580373 0.6523911 0.702 0.482623
+credit_historyno credits taken/all credits paid back duly -0.5087518 0.4802925 -1.059 0.289484
+credit_historyexisting credits paid back duly till now -1.0249188 0.5343038 -1.918 0.055082 .
+credit_historyall credits at this bank paid back duly -1.5582920 0.4858084 -3.208 0.001338 **
+duration 0.0360543 0.0106583 3.383 0.000718 ***
+employment_duration< 1 yr 0.0720620 0.4845297 0.149 0.881770
+employment_duration1 <= ... < 4 yrs -0.1262893 0.4577516 -0.276 0.782632
+employment_duration4 <= ... < 7 yrs -0.5589136 0.5016876 -1.114 0.265250
+employment_duration>= 7 yrs -0.1545512 0.4625121 -0.334 0.738262
+foreign_workerno 1.3647905 0.6425196 2.124 0.033660 *
+housingrent -0.6199554 0.2705326 -2.292 0.021928 *
+housingown -0.6851413 0.5581021 -1.228 0.219587
+installment_rate.L 0.8838467 0.2472850 3.574 0.000351 ***
+installment_rate.Q -0.0385001 0.2217440 -0.174 0.862161
+installment_rate.C -0.1072466 0.2281857 -0.470 0.638357
+jobunskilled - resident 0.9797910 0.7877153 1.244 0.213559
+jobskilled employee/official 0.7657897 0.7627061 1.004 0.315358
+jobmanager/self-empl./highly qualif. employee 0.5793418 0.7790492 0.744 0.457087
+number_credits.L 0.4081443 0.7356488 0.555 0.579026
+number_credits.Q -0.3386148 0.6189845 -0.547 0.584345
+number_credits.C -0.0262034 0.4717322 -0.056 0.955703
+other_debtorsco-applicant 0.4995457 0.4504675 1.109 0.267452
+other_debtorsguarantor -0.4840799 0.4744964 -1.020 0.307635
+other_installment_plansstores 0.1844457 0.4733765 0.390 0.696804
+other_installment_plansnone -0.2035917 0.2881916 -0.706 0.479911
+people_liable0 to 2 -0.2306212 0.2905750 -0.794 0.427386
+personal_status_sexfemale : non-single or male : single -0.2797497 0.4602069 -0.608 0.543268
+personal_status_sexmale : married/widowed -0.7947384 0.4513890 -1.761 0.078297 .
+personal_status_sexfemale : single -0.4173530 0.5348044 -0.780 0.435165
+present_residence.L 0.0948244 0.2496873 0.380 0.704114
+present_residence.Q -0.4654771 0.2293239 -2.030 0.042379 *
+present_residence.C 0.2317025 0.2240902 1.034 0.301150
+propertycar or other 0.2583020 0.2934956 0.880 0.378812
+propertybuilding soc. savings agr./life insurance 0.2595201 0.2712751 0.957 0.338735
+propertyreal estate 0.6821535 0.4931574 1.383 0.166592
+purposecar (new) -1.5120761 0.4173677 -3.623 0.000291 ***
+purposecar (used) -0.6224479 0.2979802 -2.089 0.036718 *
+purposefurniture/equipment -0.7776132 0.2803938 -2.773 0.005549 **
+purposeradio/television -0.1649750 0.8289212 -0.199 0.842244
+purposedomestic appliances 0.1966830 0.6322897 0.311 0.755751
+purposerepairs 0.3824875 0.4657037 0.821 0.411469
+purposevacation -1.9184037 1.1948196 -1.606 0.108362
+purposeretraining -0.9364954 0.4014654 -2.333 0.019664 *
+purposebusiness -1.2647440 0.8064326 -1.568 0.116807
+savings... < 100 DM -0.2148135 0.3235401 -0.664 0.506724
+savings100 <= ... < 500 DM -0.5445696 0.5037257 -1.081 0.279660
+savings500 <= ... < 1000 DM -1.4241969 0.6223390 -2.288 0.022111 *
+savings... >= 1000 DM -1.0478097 0.3067055 -3.416 0.000635 ***
+status... < 0 DM -0.4584854 0.2481344 -1.848 0.064641 .
+status0<= ... < 200 DM -0.8798435 0.4219102 -2.085 0.037035 *
+status... >= 200 DM / salary for at least 1 year -1.7552018 0.2629099 -6.676 2.45e-11 ***
+telephoneyes (under customer name) -0.1798432 0.2322797 -0.774 0.438781
+---
+Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
+
+(Dispersion parameter for binomial family taken to be 1)
+
+ Null deviance: 980.75 on 799 degrees of freedom
+Residual deviance: 702.58 on 745 degrees of freedom
+AIC: 812.58
+
+Number of Fisher Scoring iterations: 5Just like the logistic regression, we could train a random forest instead. We use the fast implementation from the ranger package. For this, we first need to define the learner and then actually train it.
+We now additionally supply the importance argument (importance = "permutation"). Doing so, we override the default and let the learner do feature importance determination based on permutation feature importance:
learner_rf = lrn("classif.ranger", importance = "permutation")
+learner_rf$train(task, row_ids = train_set)We can access the importance values using $importance():
learner_rf$importance() status duration amount credit_history savings
+ 0.0352305897 0.0220794319 0.0126390139 0.0118909925 0.0097629159
+ age property employment_duration installment_rate other_debtors
+ 0.0089588614 0.0065744135 0.0054059438 0.0039772325 0.0029554567
+ purpose job housing personal_status_sex present_residence
+ 0.0029153698 0.0019001816 0.0017784386 0.0016809300 0.0012840096
+ telephone number_credits other_installment_plans people_liable foreign_worker
+ 0.0010803276 0.0009842075 0.0004556746 0.0003807613 0.0003657158 In order to obtain a plot for the importance values, we convert the importance to a data.table and then process it with ggplot2:
+importance = as.data.table(learner_rf$importance(), keep.rownames = TRUE)
+colnames(importance) = c("Feature", "Importance")
+ggplot(importance, aes(x = reorder(Feature, Importance), y = Importance)) +
+ geom_col() + coord_flip() + xlab("")
Let’s see what the models predict.
+After training a model, the model can be used for prediction. Usually, prediction is the main purpose of machine learning models.
+In our case, the model can be used to classify new credit applicants w.r.t. their associated credit risk (good vs. bad) on the basis of the features. Typically, machine learning models predict numeric values. In the regression case this is very natural. For classification, most models predict scores or probabilities. Based on these values, one can derive class predictions.
+First, we directly predict classes:
+prediction_logreg = learner_logreg$predict(task, row_ids = test_set)
+prediction_rf = learner_rf$predict(task, row_ids = test_set)prediction_logreg<PredictionClassif> for 200 observations:
+ row_ids truth response
+ 18 good good
+ 23 bad bad
+ 26 good good
+---
+ 996 bad good
+ 997 bad bad
+ 1000 bad goodprediction_rf<PredictionClassif> for 200 observations:
+ row_ids truth response
+ 18 good good
+ 23 bad bad
+ 26 good good
+---
+ 996 bad bad
+ 997 bad good
+ 1000 bad goodThe $predict() method returns a Prediction object. It can be converted to a data.table if one wants to use it downstream.
We can also display the prediction results aggregated in a confusion matrix:
+prediction_logreg$confusion truth
+response bad good
+ bad 28 17
+ good 30 125prediction_rf$confusion truth
+response bad good
+ bad 24 13
+ good 34 129Most learners may not only predict a class variable (“response”), but also their degree of “belief” / “uncertainty” in a given response. Typically, we achieve this by setting the $predict_type slot of a Learner to "prob". Sometimes this needs to be done before the learner is trained. Alternatively, we can directly create the learner with this option: lrn("classif.log_reg", predict_type = "prob").
learner_logreg$predict_type = "prob"learner_logreg$predict(task, row_ids = test_set)<PredictionClassif> for 200 observations:
+ row_ids truth response prob.bad prob.good
+ 18 good good 0.24602549 0.7539745
+ 23 bad bad 0.88286383 0.1171362
+ 26 good good 0.05730414 0.9426959
+---
+ 996 bad good 0.49783778 0.5021622
+ 997 bad bad 0.59947093 0.4005291
+ 1000 bad good 0.42568263 0.5743174Note that sometimes one needs to be cautious when dealing with the probability interpretation of the predictions.
+To measure the performance of a learner on new unseen data, we usually mimic the scenario of unseen data by splitting up the data into training and test set. The training set is used for training the learner, and the test set is only used for predicting and evaluating the performance of the trained learner. Numerous resampling methods (cross-validation, bootstrap) repeat the splitting process in different ways.
+Within mlr3, we need to specify the resampling strategy using the rsmp() function:
resampling = rsmp("holdout", ratio = 2/3)
+print(resampling)<ResamplingHoldout>: Holdout
+* Iterations: 1
+* Instantiated: FALSE
+* Parameters: ratio=0.6667Here, we use “holdout”, a simple train-test split (with just one iteration). We use the resample() function to undertake the resampling calculation:
res = resample(task, learner = learner_logreg, resampling = resampling)
+res<ResampleResult> of 1 iterations
+* Task: GermanCredit
+* Learner: classif.log_reg
+* Warnings: 0 in 0 iterations
+* Errors: 0 in 0 iterationsThe default score of the measure is included in the $aggregate() slot:
res$aggregate()classif.ce
+ 0.2432432 The default measure in this scenario is the classification error. Lower is better.
We can easily run different resampling strategies, e.g. repeated holdout ("subsampling"), or cross validation. Most methods perform repeated train/predict cycles on different data subsets and aggregate the result (usually as the mean). Doing this manually would require us to write loops. mlr3 does the job for us:
resampling = rsmp("subsampling", repeats = 10)
+rr = resample(task, learner = learner_logreg, resampling = resampling)
+rr$aggregate()classif.ce
+ 0.2474474 Instead, we could also run cross-validation:
+resampling = resampling = rsmp("cv", folds = 10)
+rr = resample(task, learner = learner_logreg, resampling = resampling)
+rr$aggregate()classif.ce
+ 0.257 mlr3 features scores for many more measures. Here, we apply mlr_measures_classif.fpr for the false positive rate, and mlr_measures_classif.fnr for the false negative rate. Multiple measures can be provided as a list of measures (which can directly be constructed via msrs():
# false positive rate
+rr$aggregate(msr("classif.fpr"))classif.fpr
+ 0.1472895 # false positive rate and false negative
+measures = msrs(c("classif.fpr", "classif.fnr"))
+rr$aggregate(measures)classif.fpr classif.fnr
+ 0.1472895 0.5197922 There are a few more resampling methods, and quite a few more measures (implemented in mlr3measures). They are automatically registered in the respective dictionaries:
+mlr_resamplings<DictionaryResampling> with 9 stored values
+Keys: bootstrap, custom, custom_cv, cv, holdout, insample, loo, repeated_cv, subsamplingmlr_measures<DictionaryMeasure> with 67 stored values
+Keys: aic, bic, classif.acc, classif.auc, classif.bacc, classif.bbrier, classif.ce, classif.costs,
+ classif.dor, classif.fbeta, classif.fdr, classif.fn, classif.fnr, classif.fomr, classif.fp, classif.fpr,
+ classif.logloss, classif.mauc_au1p, classif.mauc_au1u, classif.mauc_aunp, classif.mauc_aunu,
+ classif.mbrier, classif.mcc, classif.npv, classif.ppv, classif.prauc, classif.precision, classif.recall,
+ classif.sensitivity, classif.specificity, classif.tn, classif.tnr, classif.tp, classif.tpr, clust.ch,
+ clust.db, clust.dunn, clust.silhouette, clust.wss, debug_classif, oob_error, regr.bias, regr.ktau,
+ regr.mae, regr.mape, regr.maxae, regr.medae, regr.medse, regr.mse, regr.msle, regr.pbias, regr.rae,
+ regr.rmse, regr.rmsle, regr.rrse, regr.rse, regr.rsq, regr.sae, regr.smape, regr.srho, regr.sse,
+ selected_features, sim.jaccard, sim.phi, time_both, time_predict, time_trainTo get help on a resampling method, use ?mlr_resamplings_xxx, for a measure do ?mlr_measures_xxx. You can also browse the mlr3 reference online.
Note that some measures, for example AUC, require the prediction of probabilities.
We could compare Learners by evaluating resample() for each of them manually. However, benchmark() automatically performs resampling evaluations for multiple learners and tasks. benchmark_grid() creates fully crossed designs: Multiple Learners for multiple Tasks are compared w.r.t. multiple Resamplings.
learners = lrns(c("classif.log_reg", "classif.ranger"), predict_type = "prob")
+grid = benchmark_grid(
+ tasks = task,
+ learners = learners,
+ resamplings = rsmp("cv", folds = 10)
+)
+bmr = benchmark(grid)Careful, large benchmarks may take a long time! This one should take less than a minute, however. In general, we want to use parallelization to speed things up on multi-core machines. For parallelization, mlr3 relies on the future package:
+# future::plan("multicore") # uncomment for parallelizationIn the benchmark we can compare different measures. Here, we look at the misclassification rate and the AUC:
measures = msrs(c("classif.ce", "classif.auc"))
+performances = bmr$aggregate(measures)
+performances[, c("learner_id", "classif.ce", "classif.auc")] learner_id classif.ce classif.auc
+1: classif.log_reg 0.250 0.7646559
+2: classif.ranger 0.239 0.7977865We see that the two models perform very similarly.
+The previously shown techniques build the backbone of a mlr3-featured machine learning workflow. However, in most cases one would never proceed in the way we did. While many R packages have carefully selected default settings, they will not perform optimally in any scenario. Typically, we can select the values of such hyperparameters. The (hyper)parameters of a Learner can be accessed and set via its ParamSet $param_set:
learner_rf$param_set<ParamSet>
+ id class lower upper nlevels default parents value
+ 1: alpha ParamDbl -Inf Inf Inf 0.5
+ 2: always.split.variables ParamUty NA NA Inf <NoDefault[3]>
+ 3: class.weights ParamUty NA NA Inf
+ 4: holdout ParamLgl NA NA 2 FALSE
+ 5: importance ParamFct NA NA 4 <NoDefault[3]> permutation
+ 6: keep.inbag ParamLgl NA NA 2 FALSE
+ 7: max.depth ParamInt 0 Inf Inf
+ 8: min.node.size ParamInt 1 Inf Inf
+ 9: min.prop ParamDbl -Inf Inf Inf 0.1
+10: minprop ParamDbl -Inf Inf Inf 0.1
+11: mtry ParamInt 1 Inf Inf <NoDefault[3]>
+12: mtry.ratio ParamDbl 0 1 Inf <NoDefault[3]>
+13: num.random.splits ParamInt 1 Inf Inf 1 splitrule
+14: num.threads ParamInt 1 Inf Inf 1 1
+15: num.trees ParamInt 1 Inf Inf 500
+16: oob.error ParamLgl NA NA 2 TRUE
+17: regularization.factor ParamUty NA NA Inf 1
+18: regularization.usedepth ParamLgl NA NA 2 FALSE
+19: replace ParamLgl NA NA 2 TRUE
+20: respect.unordered.factors ParamFct NA NA 3 ignore
+21: sample.fraction ParamDbl 0 1 Inf <NoDefault[3]>
+22: save.memory ParamLgl NA NA 2 FALSE
+23: scale.permutation.importance ParamLgl NA NA 2 FALSE importance
+24: se.method ParamFct NA NA 2 infjack
+25: seed ParamInt -Inf Inf Inf
+26: split.select.weights ParamUty NA NA Inf
+27: splitrule ParamFct NA NA 3 gini
+28: verbose ParamLgl NA NA 2 TRUE
+29: write.forest ParamLgl NA NA 2 TRUE
+ id class lower upper nlevels default parents valuelearner_rf$param_set$values = list(verbose = FALSE)We can choose parameters for our learners in two distinct manners. If we have prior knowledge on how the learner should be (hyper-)parameterized, the way to go would be manually entering the parameters in the parameter set. In most cases, however, we would want to tune the learner so that it can search “good” model configurations itself. For now, we only want to compare a few models.
+To get an idea on which parameters can be manipulated, we can investigate the parameters of the original package version or look into the parameter set of the learner:
+## ?ranger::ranger
+as.data.table(learner_rf$param_set)[, .(id, class, lower, upper)] id class lower upper
+ 1: alpha ParamDbl -Inf Inf
+ 2: always.split.variables ParamUty NA NA
+ 3: class.weights ParamUty NA NA
+ 4: holdout ParamLgl NA NA
+ 5: importance ParamFct NA NA
+ 6: keep.inbag ParamLgl NA NA
+ 7: max.depth ParamInt 0 Inf
+ 8: min.node.size ParamInt 1 Inf
+ 9: min.prop ParamDbl -Inf Inf
+10: minprop ParamDbl -Inf Inf
+11: mtry ParamInt 1 Inf
+12: mtry.ratio ParamDbl 0 1
+13: num.random.splits ParamInt 1 Inf
+14: num.threads ParamInt 1 Inf
+15: num.trees ParamInt 1 Inf
+16: oob.error ParamLgl NA NA
+17: regularization.factor ParamUty NA NA
+18: regularization.usedepth ParamLgl NA NA
+19: replace ParamLgl NA NA
+20: respect.unordered.factors ParamFct NA NA
+21: sample.fraction ParamDbl 0 1
+22: save.memory ParamLgl NA NA
+23: scale.permutation.importance ParamLgl NA NA
+24: se.method ParamFct NA NA
+25: seed ParamInt -Inf Inf
+26: split.select.weights ParamUty NA NA
+27: splitrule ParamFct NA NA
+28: verbose ParamLgl NA NA
+29: write.forest ParamLgl NA NA
+ id class lower upperFor the random forest two meaningful parameters which steer model complexity are num.trees and mtry. num.trees defaults to 500 and mtry to floor(sqrt(ncol(data) - 1)), in our case 4.
In the following we aim to train three different learners:
+num.trees and low mtry.num.trees and high mtry.We will benchmark their performance on the German credit dataset. For this we construct the three learners and set the parameters accordingly:
+rf_med = lrn("classif.ranger", id = "med", predict_type = "prob")
+
+rf_low = lrn("classif.ranger", id = "low", predict_type = "prob",
+ num.trees = 5, mtry = 2)
+
+rf_high = lrn("classif.ranger", id = "high", predict_type = "prob",
+ num.trees = 1000, mtry = 11)Once the learners are defined, we can benchmark them:
+learners = list(rf_low, rf_med, rf_high)
+grid = benchmark_grid(
+ tasks = task,
+ learners = learners,
+ resamplings = rsmp("cv", folds = 10)
+)bmr = benchmark(grid)
+print(bmr)<BenchmarkResult> of 30 rows with 3 resampling runs
+ nr task_id learner_id resampling_id iters warnings errors
+ 1 GermanCredit low cv 10 0 0
+ 2 GermanCredit med cv 10 0 0
+ 3 GermanCredit high cv 10 0 0We compare misclassification rate and AUC again:
+measures = msrs(c("classif.ce", "classif.auc"))
+performances = bmr$aggregate(measures)
+performances[, .(learner_id, classif.ce, classif.auc)] learner_id classif.ce classif.auc
+1: low 0.278 0.7287261
+2: med 0.240 0.7973700
+3: high 0.233 0.7891017autoplot(bmr)
The “low” settings seem to underfit a bit, the “high” setting is comparable to the default setting “med”.
+This tutorial was a detailed introduction to machine learning workflows within mlr3. Having followed this tutorial you should be able to run your first models yourself. Next to that we spiked into performance evaluation and benchmarking. Furthermore, we showed how to customize learners.
+The next parts of the tutorial will go more into depth into additional mlr3 topics:
+Part II - Tuning introduces you to the mlr3tuning package
Part III - Pipelines introduces you to the mlr3pipelines package
This is the third part of a serial of use cases with the German credit dataset. The other parts of this series can be found here:
+ +In this tutorial, we continue working with the German credit dataset. We already used different Learners on it and tried to optimize their hyperparameters. Now we will do four additional things:
Learners in an ensemble modelLearners able to tackle challenging datasets that they could not handle otherwise (we are going to outline what challenging means in particular later on)First, load the packages we are going to use:
+library("mlr3verse")
+library("data.table")
+library("ggplot2")We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")We again use the German credit dataset, but will restrict ourselves to the factorial features. To make things interesting or to make it a bit harder for our Learners, we introduce missing values in the dataset:
task = tsk("german_credit")
+credit_full = task$data()
+credit = credit_full[, sapply(credit_full, FUN = is.factor), with = FALSE]
+
+# sample values to NA
+credit = credit[, lapply(.SD, function(x) {
+ x[sample(c(TRUE, NA), length(x), replace = TRUE, prob = c(.9, .1))]
+})]
+credit$credit_risk = credit_full$credit_risk
+task = TaskClassif$new("GermanCredit", credit, "credit_risk")We instantiate a Resampling instance for this Task to be able to compare resampling performance:
cv10 = rsmp("cv")$instantiate(task)We also might want to use multiple cores to reduce long run times of tuning runs.
+future::plan("multiprocess")In this use case, we will take a look at composite machine learning algorithms that may incorporate data preprocessing or the combination of multiple Learners (“ensemble methods”).
We use the mlr3pipelines package that enables us to chain PipeOps into data flow Graphs.
Available PipeOps are listed in the mlr_pipeops dictionary:
mlr_pipeops<DictionaryPipeOp> with 64 stored values
+Keys: boxcox, branch, chunk, classbalancing, classifavg, classweights, colapply, collapsefactors, colroles,
+ copy, datefeatures, encode, encodeimpact, encodelmer, featureunion, filter, fixfactors, histbin, ica,
+ imputeconstant, imputehist, imputelearner, imputemean, imputemedian, imputemode, imputeoor, imputesample,
+ kernelpca, learner, learner_cv, missind, modelmatrix, multiplicityexply, multiplicityimply, mutate, nmf,
+ nop, ovrsplit, ovrunite, pca, proxy, quantilebin, randomprojection, randomresponse, regravg,
+ removeconstants, renamecolumns, replicate, scale, scalemaxabs, scalerange, select, smote, spatialsign,
+ subsample, targetinvert, targetmutate, targettrafoscalerange, textvectorizer, threshold, tunethreshold,
+ unbranch, vtreat, yeojohnsonWe have just introduced missing values into our data. While some Learners can deal with missing value, many cannot. Trying to train a random forest fails because of this:
ranger = lrn("classif.ranger")
+ranger$train(task)Error: Task 'GermanCredit' has missing values in column(s) 'credit_history', 'employment_duration', 'foreign_worker', 'housing', 'installment_rate', 'job', 'number_credits', 'other_debtors', 'other_installment_plans', 'people_liable', 'personal_status_sex', 'present_residence', 'property', 'purpose', 'savings', 'status', 'telephone', but learner 'classif.ranger' does not support thisWe can perform imputation of missing values using a PipeOp. To find out which imputation PipeOps are available, we do the following:
mlr_pipeops$keys("^impute")[1] "imputeconstant" "imputehist" "imputelearner" "imputemean" "imputemedian" "imputemode"
+[7] "imputeoor" "imputesample" We choose to impute factorial features using a new level (via PipeOpImputeOOR). Let’s use the PipeOp itself to create an imputed Task. This shows us how the PipeOp actually works:
imputer = po("imputeoor")
+task_imputed = imputer$train(list(task))[[1]]
+task_imputed$missings()
+head(task_imputed$data())We do not only need complete data during training but also during prediction. Using the same imputation heuristic for both is the most consistent strategy. This way the imputation strategy can, in fact, be seen as a part of the complete learner (which could be tuned).
+If we used the imputed Task for Resampling, we would leak information from the test set into the training set. Therefore, it is mandatory to attach the imputation operator to the Learner itself, creating a GraphLearner:
graph_learner_ranger = as_learner(po("imputeoor") %>>% ranger)
+
+graph_learner_ranger$train(task)This GraphLearner can be used for resampling – like an ordinary Learner:
rr = resample(task, learner = graph_learner_ranger, resampling = cv10)
+rr$aggregate()classif.ce
+ 0.287 Typically, sparse models, i.e. having models with few(er) features, are desirable. This is due to a variety of reasons, e.g., enhanced interpretability or decreased costs of acquiring data. Furthermore, sparse models may actually be associated with increased performance (especially if overfitting is anticipated). We can use feature filter to only keep features with the highest information. Filters are implemented in the mlr3filters package and listed in the following dictionary:
+mlr_filters<DictionaryFilter> with 21 stored values
+Keys: anova, auc, carscore, carsurvscore, cmim, correlation, disr, find_correlation, importance,
+ information_gain, jmi, jmim, kruskal_test, mim, mrmr, njmim, performance, permutation, relief,
+ selected_features, varianceWe apply the FilterMIM (mutual information maximization) Filter as implemented in the praznik package. This Filter allows for the selection of the top-k features of best mutual information.
filter = flt("mim")
+filter$calculate(task_imputed)$scores status credit_history savings purpose property
+ 1.0000 0.9375 0.8750 0.8125 0.7500
+ housing employment_duration other_installment_plans personal_status_sex other_debtors
+ 0.6875 0.6250 0.5625 0.5000 0.4375
+ installment_rate foreign_worker job number_credits telephone
+ 0.3750 0.3125 0.2500 0.1875 0.1250
+ present_residence people_liable
+ 0.0625 0.0000 Making use of this Filter, you may wonder at which costs the reduction of the feature space comes. We can investigate the trade-off between features and performance by tuning. We incorporate our filtering strategy into the pipeline using PipeOpFilter. Like before, we need to perform imputation as the Filter also relies on complete data:
fpipe = po("imputeoor") %>>% po("filter", flt("mim"), filter.nfeat = 3)
+fpipe$train(task)[[1]]$head() credit_risk credit_history savings
+1: good all credits at this bank paid back duly ... >= 1000 DM
+2: bad no credits taken/all credits paid back duly unknown/no savings account
+3: good all credits at this bank paid back duly unknown/no savings account
+4: good no credits taken/all credits paid back duly unknown/no savings account
+5: bad existing credits paid back duly till now unknown/no savings account
+6: good .MISSING ... >= 1000 DM
+ status
+1: no checking account
+2: ... < 0 DM
+3: ... >= 200 DM / salary for at least 1 year
+4: no checking account
+5: no checking account
+6: ... >= 200 DM / salary for at least 1 yearWe can now tune over the mim.filter.nfeat parameter. It steers how many features are kept by the Filter and eventually used by the learner:
search_space = ps(
+ mim.filter.nfeat = p_int(lower = 1, upper = length(task$feature_names))
+)The problem is one-dimensional (i.e. only one parameter is tuned). Thus, we make use of a grid search. For higher dimensions, strategies like random search are more appropriate. The tuning procedure may take some time:
+instance = tune(
+ tuner = tnr("grid_search"),
+ task,
+ learner = fpipe %>>% lrn("classif.ranger"),
+ resampling = cv10,
+ measure = msr("classif.ce"),
+ search_space = search_space)We can plot the performance against the number of features. If we do so, we see the possible trade-off between sparsity and predictive performance:
+autoplot(instance, type = "marginal")
We want to build a model that is based on the predictions of other Learners. This means that we are in the state that we need predictions already during training. This is a very specific case that is luckily handled by PipeOpLearnerCV. PipeOpLearnerCV performs cross-validation during the training phase and returns the cross-validated predictions. We use "prob" predictions because they carry more information than response prediction:
graph_stack = po("imputeoor") %>>%
+ gunion(list(
+ po("learner_cv", lrn("classif.ranger", predict_type = "prob")),
+ po("learner_cv", lrn("classif.kknn", predict_type = "prob")))) %>>%
+ po("featureunion") %>>% lrn("classif.log_reg")We built a pretty complex Graph already. Therefore, we plot it:
graph_stack$plot(html = FALSE)
We now compare the performance of the stacked learner to the performance of the individual Learners:
grid = benchmark_grid(
+ task = task,
+ learner = list(
+ graph_stack,
+ as_learner(po("imputeoor") %>>% lrn("classif.ranger")),
+ as_learner(po("imputeoor") %>>% lrn("classif.kknn")),
+ as_learner(po("imputeoor") %>>% lrn("classif.log_reg"))),
+ resampling = cv10)
+
+bmr = benchmark(grid) learner_id classif.ce
+1: imputeoor.classif.ranger.classif.kknn.featureunion.classif.log_reg 0.282
+2: imputeoor.classif.ranger 0.292
+3: imputeoor.classif.kknn 0.299
+4: imputeoor.classif.log_reg 0.283If we train the stacked learner and look into the final Learner (the logistic regression), we can see how “important” each Learner of the stacked learner is:
graph_stack$train(task)$classif.log_reg.output
+NULLsummary(graph_stack$pipeops$classif.log_reg$state$model)
+Call:
+stats::glm(formula = task$formula(), family = "binomial", data = data,
+ model = FALSE)
+
+Coefficients: (2 not defined because of singularities)
+ Estimate Std. Error z value Pr(>|z|)
+(Intercept) -3.3179 0.3527 -9.406 < 2e-16 ***
+classif.ranger.prob.good 5.4010 0.5648 9.563 < 2e-16 ***
+classif.ranger.prob.bad NA NA NA NA
+classif.kknn.prob.good 0.8502 0.3169 2.683 0.00729 **
+classif.kknn.prob.bad NA NA NA NA
+---
+Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
+
+(Dispersion parameter for binomial family taken to be 1)
+
+ Null deviance: 1221.7 on 999 degrees of freedom
+Residual deviance: 1054.1 on 997 degrees of freedom
+AIC: 1060.1
+
+Number of Fisher Scoring iterations: 4The random forest has a higher contribution.
+We now shift the context, using the complete German credit dataset:
+task = tsk("german_credit")There is a potential practical problem for both, small data sets and data sets with covariates having many factor levels: It may occur that not all possible factor levels have been used by the Learner during training. This happens because these rare instances are simply not sampled. The prediction then may fail because the Learner does not know how to handle unseen factor levels:
task_unseen = task$clone()$filter(1:30)
+learner_logreg = lrn("classif.log_reg")
+learner_logreg$train(task_unseen)
+learner_logreg$predict(task)Error in model.frame.default(Terms, newdata, na.action = na.action, xlev = object$xlevels): factor job has new levels unemployed/unskilled - non-residentNot only logistic regression but also many other Learners cannot handle new levels during prediction. Thus, we use PipeOpFixFactors to prevent that. PipeOpFixFactors introduces NA values for unseen levels. This means that we may need to impute afterwards. To solve this issue we can use PipeOpImputeSample, but with affect_columns set to only factorial features.
Another observation is that all-constant features may also be a problem:
+task_constant = task$clone()$filter(1:2)
+learner_logreg = lrn("classif.log_reg")
+learner_logreg$train(task_constant)Error in `contrasts<-`(`*tmp*`, value = contr.funs[1 + isOF[nn]]): contrasts can be applied only to factors with 2 or more levelsThis can be fixed using PipeOpRemoveConstants.
Both, handling unseen levels and all-constant features can be handled simultaneously using the following Graph:
robustify = po("fixfactors") %>>%
+ po("removeconstants") %>>%
+ po("imputesample", affect_columns = selector_type(c("ordered", "factor")))
+
+robustify$plot(html = FALSE)
This robust learner works even in very pathological conditions:
+graph_learner_robustify = as_learner(robustify %>>% learner_logreg)
+
+graph_learner_robustify$train(task_constant)
+graph_learner_robustify$predict(task)<PredictionClassif> for 1000 observations:
+ row_ids truth response
+ 1 good good
+ 2 bad bad
+ 3 good good
+---
+ 998 good bad
+ 999 bad bad
+ 1000 good badThere are various possibilities for preprocessing with PipeOps. You can try different methods for preprocessing and training. Feel free to discover this variety by yourself! Here are only a few hints that help when working with PipeOps:
PipeOps with the same ID in a Graph
+PipeOp with po("...", id = "xyz") to change its ID on constructionGraphs involving complicated optimizations, like many "learner_cv", they may need a long time to trainaffect_columns parameter if you want a PipeOp to only operate on part of the datapo("select") if you want to remove certain columns (possibly only along a single branch of multiple parallel branches). Both take selector_xxx() arguments, e.g. selector_type("integer")PipeOps are available by inspecting mlr_pipeops$keys(), and get help about them using ?mlr_pipeops_xxxThis is the second part of a serial of tutorials. The other parts of this series can be found here:
+ +We will continue working with the German credit dataset. In Part I, we peeked into the dataset by using and comparing some learners with their default parameters. We will now see how to:
+First, load the packages we are going to use:
+library("mlr3verse")
+library("data.table")
+library("mlr3tuning")
+library("ggplot2")We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")We use the same Task as in Part I:
task = tsk("german_credit")We also might want to use multiple cores to reduce long run times of tuning runs.
+future::plan("multiprocess")We will evaluate all hyperparameter configurations using 10-fold cross-validation. We use a fixed train-test split, i.e. the same splits for each evaluation. Otherwise, some evaluation could get unusually “hard” splits, which would make comparisons unfair.
+cv10 = rsmp("cv", folds = 10)
+
+# fix the train-test splits using the $instantiate() method
+cv10$instantiate(task)
+
+# have a look at the test set instances per fold
+cv10$instance row_id fold
+ 1: 18 1
+ 2: 19 1
+ 3: 35 1
+ 4: 38 1
+ 5: 55 1
+ ---
+ 996: 973 10
+ 997: 975 10
+ 998: 981 10
+ 999: 993 10
+1000: 998 10Parameter tuning in mlr3 needs two packages:
+The packages are loaded by the mlr3verse package.
+First, we need to decide what Learner we want to optimize. We will use LearnerClassifKKNN, the “kernelized” k-nearest neighbor classifier. We will use kknn as a normal kNN without weighting first (i.e., using the rectangular kernel):
knn = lrn("classif.kknn", predict_type = "prob", kernel = "rectangular")As a next step, we decide what parameters we optimize over. Before that, though, we are interested in the parameter set on which we could tune:
+knn$param_set id class lower upper nlevels
+1: k ParamInt 1 Inf Inf
+2: distance ParamDbl 0 Inf Inf
+3: kernel ParamFct NA NA 10
+4: scale ParamLgl NA NA 2
+5: ykernel ParamUty NA NA Inf
+6: store_model ParamLgl NA NA 2We first tune the k parameter (i.e. the number of nearest neighbors), between 3 to 20. Second, we tune the distance function, allowing L1 and L2 distances. To do so, we use the paradox package to define a search space (see the online vignette for a more complete introduction.
search_space = ps(
+ k = p_int(3, 20),
+ distance = p_int(1, 2)
+)As a next step, we define a TuningInstanceSingleCrit that represents the problem we are trying to optimize.
instance_grid = TuningInstanceSingleCrit$new(
+ task = task,
+ learner = knn,
+ resampling = cv10,
+ measure = msr("classif.ce"),
+ terminator = trm("none"),
+ search_space = search_space
+)After having set up a tuning instance, we can start tuning. Before that, we need a tuning strategy, though. A simple tuning method is to try all possible combinations of parameters: Grid Search. While it is very intuitive and simple, it is inefficient if the search space is large. For this simple use case, it suffices, though. We get the grid_search tuner via:
tuner_grid = tnr("grid_search", resolution = 18, batch_size = 36)Tuning works by calling $optimize(). Note that the tuning procedure modifies our tuning instance (as usual for R6 class objects). The result can be found in the instance object. Before tuning it is empty:
instance_grid$resultNULLNow, we tune:
+tuner_grid$optimize(instance_grid) k distance learner_param_vals x_domain classif.ce
+1: 7 1 <list[3]> <list[2]> 0.25The result is returned by $optimize() together with its performance. It can be also accessed with the $result slot:
instance_grid$result k distance learner_param_vals x_domain classif.ce
+1: 7 1 <list[3]> <list[2]> 0.25We can also look at the Archive of evaluated configurations:
head(as.data.table(instance_grid$archive)) k distance classif.ce runtime_learners timestamp batch_nr warnings errors
+1: 3 1 0.273 1.458 2023-10-30 15:10:10 1 0 0
+2: 3 2 0.280 0.435 2023-10-30 15:10:10 1 0 0
+3: 4 1 0.290 0.790 2023-10-30 15:10:10 1 0 0
+4: 4 2 0.266 0.658 2023-10-30 15:10:10 1 0 0
+5: 5 1 0.268 0.716 2023-10-30 15:10:10 1 0 0
+6: 5 2 0.256 0.374 2023-10-30 15:10:10 1 0 0We plot the performances depending on the sampled k and distance:
ggplot(as.data.table(instance_grid$archive),
+ aes(x = k, y = classif.ce, color = as.factor(distance))) +
+ geom_line() + geom_point(size = 3)
On average, the Euclidean distance (distance = 2) seems to work better. However, there is much randomness introduced by the resampling instance. So you, the reader, may see a different result, when you run the experiment yourself and set a different random seed. For k, we find that values between 7 and 13 perform well.
Let’s have a look at a larger search space. For example, we could tune all available parameters and limit k to large values (50). We also now tune the distance param continuously from 1 to 3 as a double and tune distance kernel and whether we scale the features.
We may find two problems when doing so:
+First, the resulting difference in performance between k = 3 and k = 4 is probably larger than the difference between k = 49 and k = 50. While 4 is 33% larger than 3, 50 is only 2 percent larger than 49. To account for this we will use a transformation function for k and optimize in log-space. We define the range for k from log(3) to log(50) and exponentiate in the transformation. Now, as k has become a double instead of an int (in the search space, before transformation), we round it in the extra_trafo.
search_space_large = ps(
+ k = p_dbl(log(3), log(50)),
+ distance = p_dbl(1, 3),
+ kernel = p_fct(c("rectangular", "gaussian", "rank", "optimal")),
+ scale = p_lgl(),
+ .extra_trafo = function(x, param_set) {
+ x$k = round(exp(x$k))
+ x
+ }
+)The second problem is that grid search may (and often will) take a long time. For instance, trying out three different values for k, distance, kernel, and the two values for scale will take 54 evaluations. Because of this, we use a different search algorithm, namely the Random Search. We need to specify in the tuning instance a termination criterion. The criterion tells the search algorithm when to stop. Here, we will terminate after 36 evaluations:
tuner_random = tnr("random_search", batch_size = 36)
+
+instance_random = TuningInstanceSingleCrit$new(
+ task = task,
+ learner = knn,
+ resampling = cv10,
+ measure = msr("classif.ce"),
+ terminator = trm("evals", n_evals = 36),
+ search_space = search_space_large
+)tuner_random$optimize(instance_random) k distance kernel scale learner_param_vals x_domain classif.ce
+1: 1.683743 1.985146 gaussian TRUE <list[4]> <list[4]> 0.254Like before, we can review the Archive. It includes the points before and after the transformation. The archive includes a column for each parameter the Tuner sampled on the search space (values before the transformation) and additional columns with prefix x_domain_* that refer to the parameters used by the learner (values after the transformation):
as.data.table(instance_random$archive)Let’s now investigate the performance by parameters. This is especially easy using visualization:
+ggplot(as.data.table(instance_random$archive),
+ aes(x = x_domain_k, y = classif.ce, color = x_domain_scale)) +
+ geom_point(size = 3) + geom_line()
The previous plot suggests that scale has a strong influence on performance. For the kernel, there does not seem to be a strong influence:
ggplot(as.data.table(instance_random$archive),
+ aes(x = x_domain_k, y = classif.ce, color = x_domain_kernel)) +
+ geom_point(size = 3) + geom_line()
Having determined tuned configurations that seem to work well, we want to find out which performance we can expect from them. However, this may require more than this naive approach:
+instance_random$result_yclassif.ce
+ 0.254 instance_grid$result_yclassif.ce
+ 0.25 The problem associated with evaluating tuned models is overtuning. The more we search, the more optimistically biased the associated performance metrics from tuning become.
+There is a solution to this problem, namely Nested Resampling.
+The mlr3tuning package provides an AutoTuner that acts like our tuning method but is actually a Learner. The $train() method facilitates tuning of hyperparameters on the training data, using a resampling strategy (below we use 5-fold cross-validation). Then, we actually train a model with optimal hyperparameters on the whole training data.
The AutoTuner finds the best parameters and uses them for training:
at_grid = AutoTuner$new(
+ learner = knn,
+ resampling = rsmp("cv", folds = 5), # we can NOT use fixed resampling here
+ measure = msr("classif.ce"),
+ terminator = trm("none"),
+ tuner = tnr("grid_search", resolution = 18),
+ search_space = search_space
+)The AutoTuner behaves just like a regular Learner. It can be used to combine the steps of hyperparameter tuning and model fitting but is especially useful for resampling and fair comparison of performance through benchmarking:
rr = resample(task, at_grid, cv10, store_models = TRUE)We check the inner tuning results for stable hyperparameters. This means that the selected hyperparameters should not vary too much. We might observe unstable models in this example because the small data set and the low number of resampling iterations might introduce too much randomness. Usually, we aim for the selection of stable hyperparameters for all outer training sets.
+extract_inner_tuning_results(rr) iteration k distance classif.ce task_id learner_id resampling_id
+ 1: 1 7 1 0.2588889 german_credit classif.kknn.tuned cv
+ 2: 2 5 2 0.2377778 german_credit classif.kknn.tuned cv
+ 3: 3 10 2 0.2500000 german_credit classif.kknn.tuned cv
+ 4: 4 9 2 0.2488889 german_credit classif.kknn.tuned cv
+ 5: 5 7 2 0.2477778 german_credit classif.kknn.tuned cv
+ 6: 6 8 2 0.2411111 german_credit classif.kknn.tuned cv
+ 7: 7 8 2 0.2688889 german_credit classif.kknn.tuned cv
+ 8: 8 7 2 0.2477778 german_credit classif.kknn.tuned cv
+ 9: 9 7 2 0.2655556 german_credit classif.kknn.tuned cv
+10: 10 7 2 0.2455556 german_credit classif.kknn.tuned cvNext, we want to compare the predictive performances estimated on the outer resampling to the inner resampling (extract_inner_tuning_results(rr)). Significantly lower predictive performances on the outer resampling indicate that the models with the optimized hyperparameters overfit the data.
rr$score()The archives of the AutoTuners allows us to inspect all evaluated hyperparameters configurations with the associated predictive performances.
extract_inner_tuning_archives(rr)We aggregate the performances of all resampling iterations:
+rr$aggregate()classif.ce
+ 0.255 Essentially, this is the performance of a “knn with optimal hyperparameters found by grid search”. Note that at_grid is not changed since resample() creates a clone for each resampling iteration.
The trained AutoTuner objects can be accessed by using
rr$learners[[1]]<AutoTuner:classif.kknn.tuned>
+* Model: list
+* Search Space:
+<ParamSet>
+ id class lower upper nlevels default value
+1: k ParamInt 3 20 18 <NoDefault[3]>
+2: distance ParamInt 1 2 2 <NoDefault[3]>
+* Packages: mlr3, mlr3tuning, mlr3learners, kknn
+* Predict Type: prob
+* Feature Types: logical, integer, numeric, factor, ordered
+* Properties: multiclass, twoclassrr$learners[[1]]$tuning_result k distance learner_param_vals x_domain classif.ce
+1: 7 1 <list[3]> <list[2]> 0.2588889It is always interesting to look at what could have been. The following dataset contains an optimization run result with 3600 evaluations – more than above by a factor of 100:
+The scale effect is just as visible as before with fewer data:
+ggplot(perfdata, aes(x = x_domain_k, y = classif.ce, color = scale)) +
+ geom_point(size = 2, alpha = 0.3)
Now, there seems to be a visible pattern by kernel as well:
+ggplot(perfdata, aes(x = x_domain_k, y = classif.ce, color = kernel)) +
+ geom_point(size = 2, alpha = 0.3)
In fact, if we zoom in to (5, 40) \(\times\) (0.23, 0.28) and do decrease smoothing we see that different kernels have their optimum at different values of k:
ggplot(perfdata, aes(x = x_domain_k, y = classif.ce, color = kernel,
+ group = interaction(kernel, scale))) +
+ geom_point(size = 2, alpha = 0.3) + geom_smooth() +
+ xlim(5, 40) + ylim(0.23, 0.28)`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
What about the distance parameter? If we select all results with k between 10 and 20 and plot distance and kernel we see an approximate relationship:
ggplot(perfdata[x_domain_k > 10 & x_domain_k < 20 & scale == TRUE],
+ aes(x = distance, y = classif.ce, color = kernel)) +
+ geom_point(size = 2) + geom_smooth()`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
In sum our observations are: The scale parameter is very influential, and scaling is beneficial. The distance type seems to be the least influential. There seems to be an interaction between ‘k’ and ‘kernel’.
This use case compares different approaches to handle class imbalance for the Optical Recognition of Handwritten Digits (optdigits) binary classification data set using the mlr3 package. We mainly focus on undersampling the majority class, oversampling the minority class, and the SMOTE imbalance correction (Chawla et al. 2002) that enriches the minority class with synthetic data. The use case requires prior knowledge in basic ML concepts (issues imbalanced data, hyperparameter tuning, nested cross-validation). The R packages mlr3, mlr3pipelines and mlr3tuning will be used. You can find most of the content here also in the mlr3book explained in a more detailed way.
These steps are performed:
+OpenMLGraphs (undersampling, oversampling and SMOTE) with mlr3pipelinesGraph together with a learner using mlr3tuningGraph and visualize the results using mlr3vizWe load the most important packages for this post.
+library(mlr3verse)Loading required package: mlr3library(mlr3learners)
+library(OpenML)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")OpenML.org is an open machine learning platform, which allows users to share data, code and machine learning experiments. The OpenML R package can query available data sets using a filter-like approach by providing desired dataset characteristics like number.of.classes or number.of.features.
# get list of curated binary classification data sets (see https://arxiv.org/abs/1708.03731v2)
+ds = listOMLDataSets(
+ number.of.classes = 2,
+ number.of.features = c(1, 100),
+ number.of.instances = c(5000, 10000)
+)
+# select imbalanced data sets (without categorical features as SMOTE cannot handle them)
+ds = subset(ds, minority.class.size / number.of.instances < 0.2 &
+ number.of.symbolic.features == 1)
+ds
+
+# pick one data set from list above
+d = getOMLDataSet(980)
+dAfter downloading the chosen data set, we create an mlr3 classification task:
+# make sure target is a factor and create mlr3 tasks
+data = as.data.frame(d)
+data[[d$target.features]] = as.factor(data[[d$target.features]])
+task = as_task_classif(data, id = d$desc$name, target = d$target.features)
+taskPlease note that the optdigits dataset is also included in the mlr3data package where you can get the preprocessed (integers properly encoded as such, etc.) data via:
+data("optdigits", package = "mlr3data")
+task = as_task_classif(optdigits, target = "binaryclass", positive = "P")Quick overview of the data:
+skimr::skim(task$data())| Name | +task$data() | +
| Number of rows | +5620 | +
| Number of columns | +65 | +
| Key | +NULL | +
| _______________________ | ++ |
| Column type frequency: | ++ |
| factor | +1 | +
| numeric | +64 | +
| ________________________ | ++ |
| Group variables | +None | +
Variable type: factor
+| skim_variable | +n_missing | +complete_rate | +ordered | +n_unique | +top_counts | +
|---|---|---|---|---|---|
| binaryclass | +0 | +1 | +FALSE | +2 | +N: 5048, P: 572 | +
Variable type: numeric
+| skim_variable | +n_missing | +complete_rate | +mean | +sd | +p0 | +p25 | +p50 | +p75 | +p100 | +hist | +
|---|---|---|---|---|---|---|---|---|---|---|
| input1 | +0 | +1 | +0.00 | +0.00 | +0 | +0 | +0 | +0 | +0 | +▁▁▇▁▁ | +
| input10 | +0 | +1 | +1.97 | +3.10 | +0 | +0 | +0 | +3 | +16 | +▇▁▁▁▁ | +
| input11 | +0 | +1 | +10.51 | +5.43 | +0 | +6 | +12 | +15 | +16 | +▃▂▂▂▇ | +
| input12 | +0 | +1 | +11.80 | +4.00 | +0 | +9 | +13 | +15 | +16 | +▁▂▂▃▇ | +
| input13 | +0 | +1 | +10.51 | +4.79 | +0 | +7 | +11 | +15 | +16 | +▂▂▃▃▇ | +
| input14 | +0 | +1 | +8.26 | +5.97 | +0 | +2 | +9 | +14 | +16 | +▇▂▃▃▇ | +
| input15 | +0 | +1 | +2.09 | +3.92 | +0 | +0 | +0 | +2 | +16 | +▇▁▁▁▁ | +
| input16 | +0 | +1 | +0.14 | +0.94 | +0 | +0 | +0 | +0 | +15 | +▇▁▁▁▁ | +
| input17 | +0 | +1 | +0.00 | +0.10 | +0 | +0 | +0 | +0 | +5 | +▇▁▁▁▁ | +
| input18 | +0 | +1 | +2.60 | +3.49 | +0 | +0 | +1 | +4 | +16 | +▇▂▁▁▁ | +
| input19 | +0 | +1 | +9.68 | +5.83 | +0 | +4 | +12 | +15 | +16 | +▅▂▂▃▇ | +
| input2 | +0 | +1 | +0.30 | +0.88 | +0 | +0 | +0 | +0 | +8 | +▇▁▁▁▁ | +
| input20 | +0 | +1 | +6.82 | +5.88 | +0 | +1 | +6 | +12 | +16 | +▇▃▂▂▅ | +
| input21 | +0 | +1 | +7.16 | +6.15 | +0 | +1 | +6 | +13 | +16 | +▇▂▂▂▆ | +
| input22 | +0 | +1 | +7.97 | +6.26 | +0 | +0 | +9 | +14 | +16 | +▇▂▂▃▇ | +
| input23 | +0 | +1 | +1.96 | +3.48 | +0 | +0 | +0 | +3 | +16 | +▇▁▁▁▁ | +
| input24 | +0 | +1 | +0.05 | +0.44 | +0 | +0 | +0 | +0 | +8 | +▇▁▁▁▁ | +
| input25 | +0 | +1 | +0.00 | +0.03 | +0 | +0 | +0 | +0 | +1 | +▇▁▁▁▁ | +
| input26 | +0 | +1 | +2.38 | +3.11 | +0 | +0 | +1 | +4 | +16 | +▇▂▁▁▁ | +
| input27 | +0 | +1 | +9.19 | +6.15 | +0 | +3 | +11 | +15 | +16 | +▅▂▂▂▇ | +
| input28 | +0 | +1 | +9.03 | +5.90 | +0 | +4 | +10 | +15 | +16 | +▅▂▂▃▇ | +
| input29 | +0 | +1 | +9.75 | +6.24 | +0 | +3 | +12 | +16 | +16 | +▅▁▂▂▇ | +
| input3 | +0 | +1 | +5.39 | +4.67 | +0 | +1 | +5 | +9 | +16 | +▇▃▃▂▂ | +
| input30 | +0 | +1 | +7.77 | +5.96 | +0 | +1 | +8 | +14 | +16 | +▇▃▃▃▇ | +
| input31 | +0 | +1 | +2.33 | +3.64 | +0 | +0 | +0 | +4 | +16 | +▇▁▁▁▁ | +
| input32 | +0 | +1 | +0.00 | +0.06 | +0 | +0 | +0 | +0 | +2 | +▇▁▁▁▁ | +
| input33 | +0 | +1 | +0.00 | +0.03 | +0 | +0 | +0 | +0 | +1 | +▇▁▁▁▁ | +
| input34 | +0 | +1 | +2.14 | +3.30 | +0 | +0 | +0 | +4 | +15 | +▇▁▁▁▁ | +
| input35 | +0 | +1 | +7.66 | +6.28 | +0 | +0 | +8 | +14 | +16 | +▇▂▂▂▇ | +
| input36 | +0 | +1 | +9.18 | +6.22 | +0 | +3 | +11 | +16 | +16 | +▅▂▂▂▇ | +
| input37 | +0 | +1 | +10.33 | +5.92 | +0 | +6 | +13 | +16 | +16 | +▃▁▂▂▇ | +
| input38 | +0 | +1 | +9.05 | +5.88 | +0 | +4 | +10 | +15 | +16 | +▅▂▂▃▇ | +
| input39 | +0 | +1 | +2.91 | +3.50 | +0 | +0 | +1 | +6 | +14 | +▇▂▂▁▁ | +
| input4 | +0 | +1 | +11.82 | +4.26 | +0 | +10 | +13 | +15 | +16 | +▁▁▂▃▇ | +
| input40 | +0 | +1 | +0.00 | +0.00 | +0 | +0 | +0 | +0 | +0 | +▁▁▇▁▁ | +
| input41 | +0 | +1 | +0.02 | +0.27 | +0 | +0 | +0 | +0 | +7 | +▇▁▁▁▁ | +
| input42 | +0 | +1 | +1.46 | +2.95 | +0 | +0 | +0 | +2 | +16 | +▇▁▁▁▁ | +
| input43 | +0 | +1 | +6.59 | +6.52 | +0 | +0 | +4 | +14 | +16 | +▇▁▁▂▅ | +
| input44 | +0 | +1 | +7.20 | +6.46 | +0 | +0 | +7 | +14 | +16 | +▇▂▂▂▆ | +
| input45 | +0 | +1 | +7.84 | +6.30 | +0 | +1 | +8 | +14 | +16 | +▇▂▂▂▇ | +
| input46 | +0 | +1 | +8.53 | +5.77 | +0 | +3 | +9 | +14 | +16 | +▆▂▃▃▇ | +
| input47 | +0 | +1 | +3.49 | +4.36 | +0 | +0 | +1 | +7 | +16 | +▇▂▂▁▁ | +
| input48 | +0 | +1 | +0.02 | +0.25 | +0 | +0 | +0 | +0 | +6 | +▇▁▁▁▁ | +
| input49 | +0 | +1 | +0.01 | +0.25 | +0 | +0 | +0 | +0 | +10 | +▇▁▁▁▁ | +
| input5 | +0 | +1 | +11.58 | +4.46 | +0 | +9 | +13 | +15 | +16 | +▁▁▂▃▇ | +
| input50 | +0 | +1 | +0.78 | +1.93 | +0 | +0 | +0 | +0 | +16 | +▇▁▁▁▁ | +
| input51 | +0 | +1 | +7.75 | +5.66 | +0 | +2 | +8 | +13 | +16 | +▇▃▃▅▇ | +
| input52 | +0 | +1 | +9.77 | +5.17 | +0 | +6 | +10 | +15 | +16 | +▃▃▃▃▇ | +
| input53 | +0 | +1 | +9.65 | +5.31 | +0 | +5 | +10 | +15 | +16 | +▃▃▃▃▇ | +
| input54 | +0 | +1 | +9.12 | +5.97 | +0 | +3 | +11 | +15 | +16 | +▅▂▂▃▇ | +
| input55 | +0 | +1 | +3.74 | +4.91 | +0 | +0 | +1 | +7 | +16 | +▇▂▁▁▁ | +
| input56 | +0 | +1 | +0.17 | +0.84 | +0 | +0 | +0 | +0 | +13 | +▇▁▁▁▁ | +
| input57 | +0 | +1 | +0.00 | +0.02 | +0 | +0 | +0 | +0 | +1 | +▇▁▁▁▁ | +
| input58 | +0 | +1 | +0.28 | +0.93 | +0 | +0 | +0 | +0 | +10 | +▇▁▁▁▁ | +
| input59 | +0 | +1 | +5.76 | +5.02 | +0 | +1 | +5 | +10 | +16 | +▇▃▃▂▂ | +
| input6 | +0 | +1 | +5.59 | +5.63 | +0 | +0 | +4 | +10 | +16 | +▇▂▂▂▃ | +
| input60 | +0 | +1 | +11.99 | +4.35 | +0 | +10 | +13 | +15 | +16 | +▁▁▁▃▇ | +
| input61 | +0 | +1 | +11.57 | +4.98 | +0 | +9 | +13 | +16 | +16 | +▂▁▁▃▇ | +
| input62 | +0 | +1 | +6.72 | +5.82 | +0 | +0 | +6 | +12 | +16 | +▇▂▂▃▅ | +
| input63 | +0 | +1 | +2.09 | +4.05 | +0 | +0 | +0 | +2 | +16 | +▇▁▁▁▁ | +
| input64 | +0 | +1 | +0.25 | +1.42 | +0 | +0 | +0 | +0 | +16 | +▇▁▁▁▁ | +
| input7 | +0 | +1 | +1.38 | +3.36 | +0 | +0 | +0 | +0 | +16 | +▇▁▁▁▁ | +
| input8 | +0 | +1 | +0.14 | +1.05 | +0 | +0 | +0 | +0 | +16 | +▇▁▁▁▁ | +
| input9 | +0 | +1 | +0.00 | +0.09 | +0 | +0 | +0 | +0 | +5 | +▇▁▁▁▁ | +
In mlr3pipelines , there is a class balancing and a smote pipe operator that can be combined with any learner. Below, we define the undersampling, oversampling and SMOTE PipeOps/Graph. All three imbalance correction methods have hyperparameters to control the degree of class imbalance. We apply the PipeOps/Graph to the current task with specific hyperparameter values to see how the class balance changes:
# check original class balance
+table(task$truth())
+ P N
+ 572 5048 # undersample majority class (relative to majority class)
+po_under = po("classbalancing",
+ id = "undersample", adjust = "major",
+ reference = "major", shuffle = FALSE, ratio = 1 / 6)
+# reduce majority class by factor '1/ratio'
+table(po_under$train(list(task))$output$truth())
+ P N
+572 841 # oversample majority class (relative to majority class)
+po_over = po("classbalancing",
+ id = "oversample", adjust = "minor",
+ reference = "minor", shuffle = FALSE, ratio = 6)
+# enrich minority class by factor 'ratio'
+table(po_over$train(list(task))$output$truth())
+ P N
+3432 5048 Note that the original SMOTE algorithm only accepts numeric features (see smotefamily::SMOTE). To keep it simple, we therefore preprocess the data and coerce integers to numerics prior to running SMOTE and reverse this afterwards:
# SMOTE enriches the minority class with synthetic data
+gr_smote =
+ po("colapply", id = "int_to_num",
+ applicator = as.numeric, affect_columns = selector_type("integer")) %>>%
+ po("smote", dup_size = 6) %>>%
+ po("colapply", id = "num_to_int",
+ applicator = function(x) as.integer(round(x, 0L)), affect_columns = selector_type("numeric"))
+# enrich minority class by factor (dup_size + 1)
+table(gr_smote$train(task)[[1L]]$truth())
+ P N
+4004 5048 AutoTunerWe combine the PipeOps/Graph with a learner (here ranger) to make each pipeline graph behave like a learner:
# create random forest learner
+learner = lrn("classif.ranger", num.trees = 50)
+
+# combine learner with pipeline graph
+learner_under = as_learner(po_under %>>% learner)
+learner_under$id = "undersample.ranger"
+learner_over = as_learner(po_over %>>% learner)
+learner_over$id = "oversample.ranger"
+learner_smote = as_learner(gr_smote %>>% learner)
+learner_smote$id = "smote.ranger"We define the search space in order to tune the hyperparameters of the class imbalance methods.
+# define parameter search space for each method
+search_space_under = ps(undersample.ratio = p_dbl(1 / 6, 1))
+search_space_over = ps(oversample.ratio = p_dbl(1, 6))
+search_space_smote = ps(
+ smote.dup_size = p_int(1, 6),
+ smote.K = p_int(1, 6),
+ # makes sure we use numbers to the power of two to better explore the parameter space
+ .extra_trafo = function(x, param_set) {
+ x$smote.K = round(2^(x$smote.K))
+ x
+ }
+)We create an AutoTuner class from the learner to tune the graph (random forest learner + imbalance correction method) based on a 3-fold cross-validation using the F-beta Score as performance measure. To keep runtime low, we define the search space only for the imbalance correction method. However, one can also jointly tune the hyperparameter of the learner along with the imbalance correction method by extending the search space with the learner’s hyperparameters. Note that SMOTE has two hyperparameters K and dup_size. While K changes the behavior of the SMOTE algorithm, dup_size will affect oversampling rate. To focus on the effect of the oversampling rate on the performance, we will consider SMOTE with K = 2 as a different imbalance correction method as SMOTE with K = 4 (and so on). Hence, we use grid search with 5 different hyperparameter configurations for the undersampling method, the oversampling method and each SMOTE variant for tuning:
inner_cv3 = rsmp("cv", folds = 3)
+measure = msr("classif.fbeta")
+
+learns = list(
+ auto_tuner(
+ tuner = tnr("grid_search", resolution = 6),
+ learner = learner_under,
+ resampling = inner_cv3,
+ measure = measure,
+ search_space = search_space_under
+ ),
+ auto_tuner(
+ tuner = tnr("grid_search", resolution = 6),
+ learner = learner_over,
+ resampling = inner_cv3,
+ measure = measure,
+ search_space = search_space_over
+ ),
+ auto_tuner(
+ tuner = tnr("grid_search", resolution = 6),
+ learner = learner_smote,
+ resampling = inner_cv3,
+ measure = measure,
+ search_space = search_space_smote
+ )
+)AutoTunerThe AutoTuner is a fully tuned graph that behaves like a usual learner. For the tuning a 3-fold CV is used. Now, we use the benchmark() function to compare the tuned class imbalance pipeline graphs based on a holdout for the outer evaluation:
outer_holdout = rsmp("holdout")
+design = benchmark_grid(
+ tasks = task,
+ learners = learns,
+ resamplings = outer_holdout
+)
+print(design) task learner resampling
+1: optdigits undersample.ranger.tuned holdout
+2: optdigits oversample.ranger.tuned holdout
+3: optdigits smote.ranger.tuned holdoutlgr::get_logger("bbotk")$set_threshold("warn")
+# NOTE: This code runs about 5 minutes
+bmr = benchmark(design, store_models = TRUE)bmr$aggregate(measure) nr task_id learner_id resampling_id iters classif.fbeta
+1: 1 optdigits undersample.ranger.tuned holdout 1 0.9453552
+2: 2 optdigits oversample.ranger.tuned holdout 1 0.9508197
+3: 3 optdigits smote.ranger.tuned holdout 1 0.9539295
+Hidden columns: resample_result# one value per boxplot since we used holdout as outer resampling
+autoplot(bmr, measure = measure)
With store_models = TRUE we allow the benchmark() function to store each single model that was computed during tuning. Therefore, we can plot the tuning path of the best learner from the subsampling iterations:
library(ggplot2)
+bmr_data_learners = as.data.table(bmr)$learner
+utune_path = bmr_data_learners[[1]]$model$tuning_instance$archive$data
+utune_gg = ggplot(utune_path, aes(x = undersample.ratio, y = classif.fbeta)) +
+ geom_point(size = 3) +
+ geom_line() + ylim(0.9, 1)
+
+otune_path = bmr_data_learners[[2]]$model$tuning_instance$archive$data
+otune_gg = ggplot(otune_path, aes(x = oversample.ratio, y = classif.fbeta)) +
+ geom_point(size = 3) +
+ geom_line() + ylim(0.9, 1)
+
+stune_path = bmr_data_learners[[3]]$model$tuning_instance$archive$data
+stune_gg = ggplot(stune_path, aes(
+ x = smote.dup_size,
+ y = classif.fbeta, col = factor(smote.K))) +
+ geom_point(size = 3) +
+ geom_line() + ylim(0.9, 1)
+
+library(ggpubr)
+ggarrange(utune_gg, otune_gg, stune_gg, common.legend = TRUE, nrow = 1)
The results show that oversampling the minority class (for simple oversampling as well as for SMOTE) and undersampling the majority class yield a better performance for this specific data set.
+In this post, we tuned and compared 5 different settings of sampling ratios for the undersampling method, the oversampling method and different SMOTE variants (using different values of K nearest neighbors during the sampling process). If you want to know more, read the mlr3book and the documentation of the mentioned packages.
In this tutorial, we demonstrate how mlr3pipelines can be used to easily engineer features based on date-time variables. Relying on the Bike Sharing Dataset and the ranger learner we compare the root mean square error (RMSE) of a random forest using the original features (baseline), to the RMSE of a random forest using newly engineered features on top of the original ones.
A single date-time variable (i.e., a POSIXct column) contains plenty of information ranging from year, month, day, hour, minute and second to other features such as week of the year, or day of the week. Moreover, most of these features are of cyclical nature, i.e., the eleventh and twelfth hour of a day are one hour apart, but so are the 23rd hour and midnight of the other day (see also this blog post and fastai for more information).
Not respecting this cyclical nature results in treating hours on a linear continuum. One way to handle a cyclical feature \(\mathbf{x}\) is to compute the sine and cosine transformation of \(\frac{2 \pi \mathbf{x}}{\mathbf{x}_{\text{max}}}\), with \(\mathbf{x}_{\text{max}} = 24\) for hours and \(60\) for minutes and seconds.
+This results in a two-dimensional representation of the feature:
+
mlr3pipelines provides the PipeOpDateFeatures pipeline which can be used to automatically engineer features based on POSIXct columns, including handling of cyclical features.
This is useful as most learners naturally cannot handle dates and POSIXct variables and therefore require conversion prior to training.
We load the mlr3verse package which pulls in the most important packages for this example. The mlr3learners package loads additional learners.
library(mlr3verse)
+library(mlr3learners)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")The Bike Sharing Dataset contains the hourly count of rental bikes between years 2011 and 2012 in Capital bikeshare system with the corresponding weather and seasonal information. The dataset can be downloaded from the UCI Machine Learning Repository. After reading in the data, we fix some factor levels, and convert some data types:
+The Bike Sharing Dataset contains the hourly count of rental bikes between years 2011 and 2012 in Capital bikeshare system with the corresponding weather and seasonal information. We load the data set from the mlr3data package.
data("bike_sharing", package = "mlr3data")Our goal will be to predict the total number of rented bikes on a given day: cnt.
skimr::skim(bike_sharing)| Name | +bike_sharing | +
| Number of rows | +17379 | +
| Number of columns | +14 | +
| Key | +NULL | +
| _______________________ | ++ |
| Column type frequency: | ++ |
| character | +1 | +
| factor | +2 | +
| logical | +2 | +
| numeric | +9 | +
| ________________________ | ++ |
| Group variables | +None | +
Variable type: character
+| skim_variable | +n_missing | +complete_rate | +min | +max | +empty | +n_unique | +whitespace | +
|---|---|---|---|---|---|---|---|
| date | +0 | +1 | +10 | +10 | +0 | +731 | +0 | +
Variable type: factor
+| skim_variable | +n_missing | +complete_rate | +ordered | +n_unique | +top_counts | +
|---|---|---|---|---|---|
| season | +0 | +1 | +FALSE | +4 | +sum: 4496, spr: 4409, win: 4242, fal: 4232 | +
| weather | +0 | +1 | +FALSE | +4 | +1: 11413, 2: 4544, 3: 1419, 4: 3 | +
Variable type: logical
+| skim_variable | +n_missing | +complete_rate | +mean | +count | +
|---|---|---|---|---|
| holiday | +0 | +1 | +0.03 | +FAL: 16879, TRU: 500 | +
| working_day | +0 | +1 | +0.68 | +TRU: 11865, FAL: 5514 | +
Variable type: numeric
+| skim_variable | +n_missing | +complete_rate | +mean | +sd | +p0 | +p25 | +p50 | +p75 | +p100 | +hist | +
|---|---|---|---|---|---|---|---|---|---|---|
| year | +0 | +1 | +0.50 | +0.50 | +0.00 | +0.00 | +1.00 | +1.00 | +1.00 | +▇▁▁▁▇ | +
| month | +0 | +1 | +6.54 | +3.44 | +1.00 | +4.00 | +7.00 | +10.00 | +12.00 | +▇▆▆▅▇ | +
| hour | +0 | +1 | +11.55 | +6.91 | +0.00 | +6.00 | +12.00 | +18.00 | +23.00 | +▇▇▆▇▇ | +
| weekday | +0 | +1 | +3.00 | +2.01 | +0.00 | +1.00 | +3.00 | +5.00 | +6.00 | +▇▃▃▃▇ | +
| temperature | +0 | +1 | +0.50 | +0.19 | +0.02 | +0.34 | +0.50 | +0.66 | +1.00 | +▂▇▇▇▁ | +
| apparent_temperature | +0 | +1 | +0.48 | +0.17 | +0.00 | +0.33 | +0.48 | +0.62 | +1.00 | +▁▆▇▆▁ | +
| humidity | +0 | +1 | +0.63 | +0.19 | +0.00 | +0.48 | +0.63 | +0.78 | +1.00 | +▁▃▇▇▆ | +
| windspeed | +0 | +1 | +0.19 | +0.12 | +0.00 | +0.10 | +0.19 | +0.25 | +0.85 | +▇▆▂▁▁ | +
| count | +0 | +1 | +189.46 | +181.39 | +1.00 | +40.00 | +142.00 | +281.00 | +977.00 | +▇▃▁▁▁ | +
The original dataset does not contain a POSIXct column, but we can easily generate one based on the other variables available (note that as no information regarding minutes and seconds is available, we set them to :00:00):
bike_sharing$date = as.POSIXct(paste0(bike_sharing$date, " ", bike_sharing$hour, ":00:00"),
+ tz = "GMT", format = "%Y-%m-%d %H:%M:%S")
We construct a new regression task and keep a holdout set.
+task = as_task_regr(bike_sharing, target = "count")
+
+validation_set = sample(seq_len(task$nrow), size = 0.3 * task$nrow)
+
+task$set_row_roles(validation_set, roles = "holdout")To estimate the performance on unseen data, we will use a 3-fold cross-validation. Note that this involves validating on past data, which is usually bad practice but should suffice for this example:
+cv3 = rsmp("cv", folds = 3)To obtain reliable estimates on how well our model generalizes to the future, we would have to split our training and test sets according to the date variable.
+As our baseline model, we use a random forest, ranger learner. For the baseline, we dropdate, our new POSIXct variable which we will only use later.
learner_ranger = lrn("regr.ranger")
+task_ranger = task$clone()
+task_ranger$select(setdiff(task$feature_names, c("date")))We can then use resample() with 3-fold cross-validation:
rr_ranger = resample(task_ranger, learner = learner_ranger, resampling = cv3)
+
+rr_ranger$score(msr("regr.mse"))[, .(iteration, task_id, learner_id, resampling_id, regr.mse)] iteration task_id learner_id resampling_id regr.mse
+1: 1 bike_sharing regr.ranger cv 4543.904
+2: 2 bike_sharing regr.ranger cv 4276.996
+3: 3 bike_sharing regr.ranger cv 4767.763We calculate the average RMSE.
+rr_ranger$aggregate()regr.mse
+4529.554 We now want to improve our baseline model by using newly engineered features based on the date POSIXct column.
To engineer new features we use PipeOpDateFeatures. This pipeline automatically dispatches on POSIXct columns of the data and by default adds plenty of new date-time related features. Here, we want to add all except for minute and second, because this information is not available. As we additionally want to use cyclical versions of the features we set cyclic = TRUE:
pipeop_date = po("datefeatures", cyclic = TRUE, minute = FALSE, second = FALSE)Training this pipeline will result in simply adding the new features (and removing the original POSIXct feature(s) used for the feature engineering, see also the keep_date_var parameter). In our task, we can now drop the features, yr, mnth, hr, and weekday, because our pipeline will generate these anyways:
task_ex = task$clone()
+task_ex$select(setdiff(task$feature_names,
+ c("instant", "dteday", "yr", "mnth", "hr", "weekday", "casual", "registered")))
+
+pipeop_date$train(list(task_ex))$output
+<TaskRegr:bike_sharing> (12166 x 32)
+* Target: count
+* Properties: -
+* Features (31):
+ - dbl (23): apparent_temperature, date.day_of_month, date.day_of_month_cos, date.day_of_month_sin,
+ date.day_of_week, date.day_of_week_cos, date.day_of_week_sin, date.day_of_year, date.day_of_year_cos,
+ date.day_of_year_sin, date.hour, date.hour_cos, date.hour_sin, date.month, date.month_cos,
+ date.month_sin, date.week_of_year, date.week_of_year_cos, date.week_of_year_sin, date.year, humidity,
+ temperature, windspeed
+ - lgl (3): date.is_day, holiday, working_day
+ - int (3): hour, month, year
+ - fct (2): season, weatherNote that it may be useful to familiarize yourself with PipeOpRemoveConstants which can be used after the feature engineering to remove features that are constant. PipeOpDateFeatures does not do this step automatically.
To combine this feature engineering step with a random forest, ranger learner, we now construct a GraphLearner.
We create a GraphLearner consisting of the PipeOpDateFeatures pipeline and a ranger learner. This GraphLearner then behaves like any other Learner:
graph = po("datefeatures", cyclic = TRUE, minute = FALSE, second = FALSE) %>>%
+ lrn("regr.ranger")
+
+graph_learner = as_learner(graph)
+
+plot(graph, html = FALSE)
Using resample() with 3-fold cross-validation on the task yields:
task_graph_learner = task$clone()
+task_graph_learner$select(setdiff(task$feature_names,
+ c("instant", "dteday", "yr", "mnth", "hr", "weekday", "casual", "registered")))
+
+rr_graph_learner = resample(task_graph_learner, learner = graph_learner, resampling = cv3)
+
+rr_graph_learner$score(msr("regr.mse")) task_id learner_id resampling_id iteration regr.mse
+1: bike_sharing datefeatures.regr.ranger cv 1 2521.642
+2: bike_sharing datefeatures.regr.ranger cv 2 2229.746
+3: bike_sharing datefeatures.regr.ranger cv 3 2254.390
+Hidden columns: task, learner, resampling, predictionWe calculate the average RMSE.
+rr_graph_learner$aggregate()regr.mse
+2335.259 and therefore improved by almost 94%!
+Finally, we fit our GraphLearner on the complete training set and predict on the validation set:
task$select(setdiff(task$feature_names, c("year", "month", "hour", "weekday")))
+
+graph_learner$train(task)
+
+prediction = graph_learner$predict(task, row_ids = task$row_roles$validation)Where we can obtain the RMSE on the held-out validation data.
+prediction$score(msr("regr.mse"))regr.mse
+460.0281 Download data from OpenML data and impute missing values.
+ +
+ This use case shows how to easily work with datasets available via OpenML into an mlr3 workflow.
+The following operations are illustrated:
+# various functions of the mlr3 ecosystem
+library("mlr3verse")
+# about a dozen reasonable learners
+library("mlr3learners")
+# retrieving the data
+library("OpenML")We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")We can use the OpenML package to retrieve data (and more) straight away. OpenML is is an inclusive movement to build an open, organized, online ecosystem for machine learning. Typically, you can retrieve the data with an data.id. The id can be found on OpenML. We choose the data set 41021. The related web page can be accessed here. This data set was uploaded by Joaquin Vanschoren.
oml_data = getOMLDataSet(data.id = 41021)Downloading from 'http://www.openml.org/api/v1/data/41021' to '/tmp/RtmpIRWjZy/cache/datasets/41021/description.xml'.Downloading from 'https://api.openml.org/data/v1/download/18626236/Moneyball.arff' to '/tmp/RtmpIRWjZy/cache/datasets/41021/dataset.arff'Loading required package: readrThe description indicates that the data set is associated with baseball or more precisely the story of Moneyball.
+head(as.data.table(oml_data))However, the description within the OpenML object is not very detailed. The previously referenced page however states the following:
+In the early 2000s, Billy Beane and Paul DePodesta worked for the Oakland Athletics. During their work there, they disrupted the game of baseball. They didn’t do it using a bat or glove, and they certainly didn’t do it by throwing money at the issue; in fact, money was the issue. They didn’t have enough of it, but they were still expected to keep up with teams that had more substantial endorsements. This is where Statistics came riding down the hillside on a white horse to save the day. This data set contains some of the information that was available to Beane and DePodesta in the early 2000s, and it can be used to better understand their methods.
+This data set contains a set of variables that Beane and DePodesta emphasized in their work. They determined that statistics like on-base percentage (obp) and slugging percentage (slg) were very important when it came to scoring runs, however, they were largely undervalued by most scouts at the time. This translated to a gold mine for Beane and DePodesta. Since these players weren’t being looked at by other teams, they could recruit these players on a small budget. The variables are as follows:
+While Beane and DePodesta defined most of these statistics and measures for individual players, this data set is on the team level.
+These statistics seem very informative if you are into baseball. If baseball of rather obscure to you, simply take these features as given or give this article a quick read.
+Finally, note that the moneyball dataset is also included in the mlr3data package where you can get the preprocessed (integers properly encoded as such, etc.) data via:
data("moneyball", package = "mlr3data")
+skimr::skim(moneyball)| Name | +moneyball | +
| Number of rows | +1232 | +
| Number of columns | +15 | +
| _______________________ | ++ |
| Column type frequency: | ++ |
| factor | +6 | +
| numeric | +9 | +
| ________________________ | ++ |
| Group variables | +None | +
Variable type: factor
+| skim_variable | +n_missing | +complete_rate | +ordered | +n_unique | +top_counts | +
|---|---|---|---|---|---|
| team | +0 | +1.0 | +FALSE | +39 | +BAL: 47, BOS: 47, CHC: 47, CHW: 47 | +
| league | +0 | +1.0 | +FALSE | +2 | +AL: 616, NL: 616 | +
| playoffs | +0 | +1.0 | +FALSE | +2 | +0: 988, 1: 244 | +
| rankseason | +988 | +0.2 | +FALSE | +8 | +2: 53, 1: 52, 3: 44, 4: 44 | +
| rankplayoffs | +988 | +0.2 | +FALSE | +5 | +3: 80, 4: 68, 1: 47, 2: 47 | +
| g | +0 | +1.0 | +FALSE | +8 | +162: 954, 161: 139, 163: 93, 160: 23 | +
Variable type: numeric
+| skim_variable | +n_missing | +complete_rate | +mean | +sd | +p0 | +p25 | +p50 | +p75 | +p100 | +hist | +
|---|---|---|---|---|---|---|---|---|---|---|
| year | +0 | +1.00 | +1988.96 | +14.82 | +1962.00 | +1976.75 | +1989.00 | +2002.00 | +2012.00 | +▆▆▇▆▇ | +
| rs | +0 | +1.00 | +715.08 | +91.53 | +463.00 | +652.00 | +711.00 | +775.00 | +1009.00 | +▁▆▇▃▁ | +
| ra | +0 | +1.00 | +715.08 | +93.08 | +472.00 | +649.75 | +709.00 | +774.25 | +1103.00 | +▂▇▆▂▁ | +
| w | +0 | +1.00 | +80.90 | +11.46 | +40.00 | +73.00 | +81.00 | +89.00 | +116.00 | +▁▃▇▆▁ | +
| obp | +0 | +1.00 | +0.33 | +0.02 | +0.28 | +0.32 | +0.33 | +0.34 | +0.37 | +▁▃▇▅▁ | +
| slg | +0 | +1.00 | +0.40 | +0.03 | +0.30 | +0.38 | +0.40 | +0.42 | +0.49 | +▁▅▇▅▁ | +
| ba | +0 | +1.00 | +0.26 | +0.01 | +0.21 | +0.25 | +0.26 | +0.27 | +0.29 | +▁▂▇▆▂ | +
| oobp | +812 | +0.34 | +0.33 | +0.02 | +0.29 | +0.32 | +0.33 | +0.34 | +0.38 | +▂▇▇▃▁ | +
| oslg | +812 | +0.34 | +0.42 | +0.03 | +0.35 | +0.40 | +0.42 | +0.44 | +0.50 | +▁▆▇▅▁ | +
The summary shows how this data we are dealing with looks like: Some data is missing, however, this has structural reasons. There are 39 teams with each maximally 47 years (1962 - 2012). For 988 cases the information on rankseason and rankplayoffs is missing. This is since these simply did not reach the playoffs and hence have no reported rank.
summary(moneyball[moneyball$playoffs == 0, c("rankseason", "rankplayoffs")]) rankseason rankplayoffs
+ 1 : 0 1 : 0
+ 2 : 0 2 : 0
+ 3 : 0 3 : 0
+ 4 : 0 4 : 0
+ 5 : 0 5 : 0
+ (Other): 0 NA's:988
+ NA's :988 On the other hand, oobp and oslg have \(812\) missing values. It seems as if these measures were not available before \(1998\).
library(ggplot2)
+library(naniar)
+
+ggplot(moneyball, aes(x = year, y = oobp)) +
+ geom_miss_point()
We seem to have a missing data problem. Typically, in this case, we have three options: They are:
+Complete case analysis: Exclude all observation with missing values.
Complete feature analysis: Exclude all features with missing values.
Missing value imputation: Use a model to “guess” the missing values (based on the underlying distribution of the data.
Usually, missing value imputation is preferred over the first two. However, in machine learning, one can try out all options and see which performs best for the underlying problem. For now, we limit ourselves to a rather simple imputation technique, imputation by randomly sampling from the univariate distribution. Note that this does not take the multivariate distribution into account properly and that there are more elaborate approaches. We only aim to impute oobp and oslg. For the other missing (categorical) features, we simply add a new level which indicates that information is missing (i.e. all missing values belong to).
It is important to note that in this case here the vast majority of information on the features is missing. In this case, imputation is performed to not throw away the existing information of the features.
+mlr3 has some solutions for that within the mlr3pipelines package. We start with an easy PipeOp which only performs numeric imputation.
imp_num = po("imputehist", affect_columns = selector_type(c("integer", "numeric")))Next, we append the second imputation job for factors.
+imp_fct = po("imputeoor", affect_columns = selector_type("factor"))
+graph = imp_num %>>% imp_fct
+graph$plot(html = FALSE)
The fact that there is missing data does not affect the task definition. The task determines what is the problem to be solved by machine learning. We want to explain the runs scored (rs). rs is an important measure as a run is equivalent to a ‘point’ scored in other sports. Naturally, the aim of a coach should be to maximise runs scored and minimise runs allowed. As runs scored and runs allowed are both legitimate targets we ignore the runs allowed here. The task is defined by:
# creates a `mlr3` task from scratch, from a data.frame
+# 'target' names the column in the dataset we want to learn to predict
+task = as_task_regr(moneyball, target = "rs")
+task$missings()The $missings() method indicates what we already knew: our missing values. Missing values are not always a problem. Some learners can deal with them pretty well. However, we want to use a random forest for our task.
# creates a learner
+test_learner = lrn("regr.ranger")
+
+# displays the properties
+test_learner$properties[1] "hotstart_backward" "importance" "oob_error" "weights" Typically, in mlr3 the $properties field would tell us whether missing values are a problem to this learner or not. As it is not listed here, the random forest cannot deal with missing values.
As we aim to use imputation beforehand, we incorporate it into the learner. Our selected learner is going to be a random forest from the ranger package.
+One can allow the embedding of the preprocessing (imputation) into a learner by creating a PipeOpLearner. This special Learner can be put into a graph together with the imputer.
# convert learner to pipeop learner and set hyperparameter
+pipeop_learner = po(lrn("regr.ranger"), num.trees = 1000, importance = "permutation")
+
+# add pipeop learner to graph and create graph learner
+graph_learner = as_learner(graph %>>% pipeop_learner)The final graph looks like the following:
+graph_learner$graph$plot(html = FALSE)
To get a feeling of how our model performs we simply train the Learner on a subset of the data and predict the hold-out data.
# defines the training and testing data; 95% is used for training
+train_set = sample(task$nrow, 0.95 * task$nrow)
+test_set = setdiff(seq_len(task$nrow), train_set)
+
+# train learner on subset of task
+graph_learner$train(task, row_ids = train_set)
+
+# predict using held out observations
+prediction = graph_learner$predict(task, row_ids = test_set)
+
+head(as.data.table(prediction))Viewing the predicted values it seems like the model predicts reasonable values that are fairly close to the truth.
+While the prediction indicated that the model is doing what it is supposed to, we want to have a more systematic understanding of the model performance. That means we want to know by how much our model is away from the truth on average. Cross-validation investigates this question. In mlr3 10-fold cross-validation is constructed as follows:
+cv10 = rsmp("cv", folds = 10)
+rr = resample(task, graph_learner, cv10)We choose some of the performance measures provided by:
+as.data.table(mlr_measures)We choose the mean absolute error and the mean squared error.
rr$score(msrs(c("regr.mae", "regr.mse")))We can also compute now by how much our model was on average wrong when predicting the runs scored.
+rr$aggregate(msr("regr.mae"))regr.mae
+19.39997 That seems not too bad. Considering that on average approximately 715 runs per team per season have been scored.
+mean(moneyball$rs)[1] 715.082To assess if imputation was beneficial, we can compare our current learner with a learner which ignores the missing features. Normally, one would set up a benchmark for this. However, we want to keep things short in this use case. Thus, we only set up the alternative learner (with identical hyperparameters) and compare the 10-fold cross-validated mean absolute error.
+As we are mostly interested in the numeric imputation we leave the remaining graph as it is.
+impute_oor = po("imputeoor", affect_columns = selector_type("factor"))Subsequently, we create a pipeline with PipeOpSelect.
feature_names = colnames(moneyball)[!sapply(moneyball, anyNA)]
+feature_names = c(feature_names[feature_names %in% task$feature_names],
+ "rankseason", "rankplayoffs")
+select_na = po("select", selector = selector_name(feature_names))
+
+graph_2 = impute_oor %>>% select_na
+graph_2$plot(html = FALSE)
Now we complete the learner and apply resampling as before.
+graph_learner_2 = as_learner(graph_2 %>>% pipeop_learner)
+rr_2 = resample(task, graph_learner_2, cv10)
+rr_2$aggregate(msr("regr.mae"))regr.mae
+19.03752 Surprisingly, the performance seems to be approximately the same. That means that the imputed features seem not very helpful. We can use the variable.importance of the random forest.
sort(graph_learner$model$regr.ranger$model$variable.importance, decreasing = TRUE)We see that according to this the left out oobp and oslg seem to have solely rudimentary explanatory power. This may be because there were simply too many instances or because the features are themselves not very powerful.
So, to sum up, what we have learned: We can access very cool data straight away with the OpenML package. (We are working on a better direct implementation into mlr3 at the moment.) We can work with missing data very well in mlr3. Nevertheless, we discovered that sometimes imputation does not lead to the intended goals. We also learned how to use some PipeOps from the mlr3pipelines package.
But most importantly, we found a way to predict the runs scored of MLB teams.
+If you want to know more, read the mlr3book and the documentation of the mentioned packages.
+ + +Visualize the decision boundaries of multiple classification learners on some artificial data sets.
+
+ The visualization of decision boundaries helps to understand what the pros and cons of individual classification learners are. This posts demonstrates how to create such plots.
+We load the mlr3 package.
+library("mlr3")We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")The three artificial data sets are generated by task generators (implemented in mlr3):
N <- 200
+tasks <- list(
+ tgen("xor")$generate(N),
+ tgen("moons")$generate(N),
+ tgen("circle")$generate(N)
+)Points are distributed on a 2-dimensional cube with corners \((\pm 1, \pm 1)\). Class is "red" if \(x\) and \(y\) have the same sign, and "black" otherwise.
plot(tgen("xor"))
Two circles with same center but different radii. Points in the smaller circle are "black", points only in the larger circle are "red".
plot(tgen("circle"))
Two interleaving half circles (“moons”).
+plot(tgen("moons"))
We consider the following learners:
+library("mlr3learners")
+
+learners <- list(
+ # k-nearest neighbours classifier
+ lrn("classif.kknn", id = "kkn", predict_type = "prob", k = 3),
+
+ # linear svm
+ lrn("classif.svm", id = "lin. svm", predict_type = "prob", kernel = "linear"),
+
+ # radial-basis function svm
+ lrn("classif.svm",
+ id = "rbf svm", predict_type = "prob", kernel = "radial",
+ gamma = 2, cost = 1, type = "C-classification"
+ ),
+
+ # naive bayes
+ lrn("classif.naive_bayes", id = "naive bayes", predict_type = "prob"),
+
+ # single decision tree
+ lrn("classif.rpart", id = "tree", predict_type = "prob", cp = 0, maxdepth = 5),
+
+ # random forest
+ lrn("classif.ranger", id = "random forest", predict_type = "prob")
+)The hyperparameters are chosen in a way that the decision boundaries look “typical” for the respective classifier. Of course, with different hyperparameters, results may look very different.
+To apply each learner on each task, we first build an exhaustive grid design of experiments with benchmark_grid() and then pass it to benchmark() to do the actual work. A simple holdout resampling is used here:
design <- benchmark_grid(
+ tasks = tasks,
+ learners = learners,
+ resamplings = rsmp("holdout")
+)
+
+bmr <- benchmark(design, store_models = TRUE)A quick look into the performance values:
+perf <- bmr$aggregate(msr("classif.acc"))[, c("task_id", "learner_id", "classif.acc")]
+perf task_id learner_id classif.acc
+ 1: xor_200 kkn 0.9402985
+ 2: xor_200 lin. svm 0.5223881
+ 3: xor_200 rbf svm 0.9701493
+ 4: xor_200 naive bayes 0.4328358
+ 5: xor_200 tree 0.9402985
+ 6: xor_200 random forest 1.0000000
+ 7: moons_200 kkn 1.0000000
+ 8: moons_200 lin. svm 0.8805970
+ 9: moons_200 rbf svm 1.0000000
+10: moons_200 naive bayes 0.8955224
+11: moons_200 tree 0.8955224
+12: moons_200 random forest 0.9552239
+13: circle_200 kkn 0.8805970
+14: circle_200 lin. svm 0.4925373
+15: circle_200 rbf svm 0.8955224
+16: circle_200 naive bayes 0.7014925
+17: circle_200 tree 0.7462687
+18: circle_200 random forest 0.7761194To generate the plots, we iterate over the individual ResampleResult objects stored in the BenchmarkResult, and in each iteration we store the plot of the learner prediction generated by the mlr3viz package.
library("mlr3viz")
+
+n <- bmr$n_resample_results
+plots <- vector("list", n)
+for (i in seq_len(n)) {
+ rr <- bmr$resample_result(i)
+ plots[[i]] <- autoplot(rr, type = "prediction")
+}We now have a list of plots. Each one can be printed individually:
+print(plots[[1]])
Note that only observations from the test data is plotted as points.
+To get a nice annotated overview, we arranged all plots together in a single pdf file. The number in the upper right is the respective accuracy on the test set.
+pdf(file = "plot_learner_prediction.pdf", width = 20, height = 6)
+ntasks <- length(tasks)
+nlearners <- length(learners)
+m <- msr("classif.acc")
+
+# for each plot
+for (i in seq_along(plots)) {
+ plots[[i]] <- plots[[i]] +
+ # remove legend
+ ggplot2::theme(legend.position = "none") +
+ # remove labs
+ ggplot2::xlab("") + ggplot2::ylab("") +
+ # add accuracy score as annotation
+ ggplot2::annotate("text",
+ label = sprintf("%.2f", bmr$resample_result(i)$aggregate(m)),
+ x = Inf, y = Inf, vjust = 2, hjust = 1.5
+ )
+}
+
+# for each plot of the first column
+for (i in seq_len(ntasks)) {
+ ii <- (i - 1) * nlearners + 1L
+ plots[[ii]] <- plots[[ii]] + ggplot2::ylab(sub("_[0-9]+$", "", tasks[[i]]$id))
+}
+
+# for each plot of the first row
+for (i in seq_len(nlearners)) {
+ plots[[i]] <- plots[[i]] + ggplot2::ggtitle(learners[[i]]$id)
+}
+
+gridExtra::grid.arrange(grobs = plots, nrow = length(tasks))
+dev.off()As you can see, the decision boundaries look very different. Some are linear, others are parallel to the axis, and yet others are highly non-linear. The boundaries are partly very smooth with a slow transition of probabilities, others are very abrupt. All these properties are important during model selection, and should be considered for your problem at hand.
+ + +This use case provides an introduction to mlr3keras via the boston housing dataset.
+requireNamespace("DiceKriging")Loading required namespace: DiceKrigingThis is the first part of the practical tuning series. The other parts can be found here:
+In this post, we demonstrate how to optimize the hyperparameters of a support vector machine (SVM). We are using the mlr3 machine learning framework with the mlr3tuning extension package.
+First, we start by showing the basic building blocks of mlr3tuning and tune the cost and gamma hyperparameters of an SVM with a radial basis function on the Iris data set. After that, we use transformations to tune the both hyperparameters on the logarithmic scale. Next, we explain the importance of dependencies to tune hyperparameters like degree which are dependent on the choice of kernel. After that, we fit an SVM with optimized hyperparameters on the full dataset. Finally, nested resampling is used to compute an unbiased performance estimate of our tuned SVM.
We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")In the example, we use the Iris data set which classifies 150 flowers in three species of Iris. The flowers are characterized by sepal length and width and petal length and width. The Iris data set allows us to quickly fit models to it. However, the influence of hyperparameter tuning on the predictive performance might be minor. Other data sets might give more meaningful tuning results.
+# retrieve the task from mlr3
+task = tsk("iris")
+
+# generate a quick textual overview using the skimr package
+skimr::skim(task$data())| Name | +task$data() | +
| Number of rows | +150 | +
| Number of columns | +5 | +
| Key | +NULL | +
| _______________________ | ++ |
| Column type frequency: | ++ |
| factor | +1 | +
| numeric | +4 | +
| ________________________ | ++ |
| Group variables | +None | +
Variable type: factor
+| skim_variable | +n_missing | +complete_rate | +ordered | +n_unique | +top_counts | +
|---|---|---|---|---|---|
| Species | +0 | +1 | +FALSE | +3 | +set: 50, ver: 50, vir: 50 | +
Variable type: numeric
+| skim_variable | +n_missing | +complete_rate | +mean | +sd | +p0 | +p25 | +p50 | +p75 | +p100 | +hist | +
|---|---|---|---|---|---|---|---|---|---|---|
| Petal.Length | +0 | +1 | +3.76 | +1.77 | +1.0 | +1.6 | +4.35 | +5.1 | +6.9 | +▇▁▆▇▂ | +
| Petal.Width | +0 | +1 | +1.20 | +0.76 | +0.1 | +0.3 | +1.30 | +1.8 | +2.5 | +▇▁▇▅▃ | +
| Sepal.Length | +0 | +1 | +5.84 | +0.83 | +4.3 | +5.1 | +5.80 | +6.4 | +7.9 | +▆▇▇▅▂ | +
| Sepal.Width | +0 | +1 | +3.06 | +0.44 | +2.0 | +2.8 | +3.00 | +3.3 | +4.4 | +▁▆▇▂▁ | +
We choose the support vector machine implementation from the e1071 package (which is based on LIBSVM) and use it as a classification machine by setting type to "C-classification".
learner = lrn("classif.svm", type = "C-classification", kernel = "radial")For tuning, it is important to create a search space that defines the type and range of the hyperparameters. A learner stores all information about its hyperparameters in the slot $param_set. Not all parameters are tunable. We have to choose a subset of the hyperparameters we want to tune.
as.data.table(learner$param_set)[, .(id, class, lower, upper, nlevels)]We use the to_tune() function to define the range over which the hyperparameter should be tuned. We opt for the cost and gamma hyperparameters of the radial kernel and set the tuning ranges with lower and upper bounds.
learner$param_set$values$cost = to_tune(0.1, 10)
+learner$param_set$values$gamma = to_tune(0, 5)We specify how to evaluate the performance of the different hyperparameter configurations. For this, we choose 3-fold cross validation as the resampling strategy and the classification error as the performance measure.
+resampling = rsmp("cv", folds = 3)
+measure = msr("classif.ce")Usually, we have to select a budget for the tuning. This is done by choosing a Terminator, which stops the tuning e.g. after a performance level is reached or after a given time. However, some tuners like grid search terminate themselves. In this case, we choose a terminator that never stops and the tuning is not stopped before all grid points are evaluated.
terminator = trm("none")At this point, we can construct a TuningInstanceSingleCrit that describes the tuning problem.
instance = TuningInstanceSingleCrit$new(
+ task = task,
+ learner = learner,
+ resampling = resampling,
+ measure = measure,
+ terminator = terminator
+)
+
+print(instance)<TuningInstanceSingleCrit>
+* State: Not optimized
+* Objective: <ObjectiveTuning:classif.svm_on_iris>
+* Search Space:
+ id class lower upper nlevels
+1: cost ParamDbl 0.1 10 Inf
+2: gamma ParamDbl 0.0 5 Inf
+* Terminator: <TerminatorNone>Finally, we have to choose a Tuner. Grid Search discretizes numeric parameters into a given resolution and constructs a grid from the Cartesian product of these sets. Categorical parameters produce a grid over all levels specified in the search space. In this example, we only use a resolution of 5 to keep the runtime low. Usually, a higher resolution is used to create a denser grid.
tuner = tnr("grid_search", resolution = 5)
+
+print(tuner)<TunerGridSearch>: Grid Search
+* Parameters: resolution=5, batch_size=1
+* Parameter classes: ParamLgl, ParamInt, ParamDbl, ParamFct
+* Properties: dependencies, single-crit, multi-crit
+* Packages: mlr3tuningWe can preview the proposed configurations by using generate_design_grid(). This function is internally executed by TunerGridSearch.
generate_design_grid(learner$param_set$search_space(), resolution = 5)<Design> with 25 rows:
+ cost gamma
+ 1: 0.100 0.00
+ 2: 0.100 1.25
+ 3: 0.100 2.50
+ 4: 0.100 3.75
+ 5: 0.100 5.00
+ 6: 2.575 0.00
+ 7: 2.575 1.25
+ 8: 2.575 2.50
+ 9: 2.575 3.75
+10: 2.575 5.00
+11: 5.050 0.00
+12: 5.050 1.25
+13: 5.050 2.50
+14: 5.050 3.75
+15: 5.050 5.00
+16: 7.525 0.00
+17: 7.525 1.25
+18: 7.525 2.50
+19: 7.525 3.75
+20: 7.525 5.00
+21: 10.000 0.00
+22: 10.000 1.25
+23: 10.000 2.50
+24: 10.000 3.75
+25: 10.000 5.00
+ cost gammaWe trigger the tuning by passing the TuningInstanceSingleCrit to the $optimize() method of the Tuner. The instance is modified in-place.
tuner$optimize(instance) cost gamma learner_param_vals x_domain classif.ce
+1: 5.05 1.25 <list[4]> <list[2]> 0.06We plot the performances depending on the evaluated cost and gamma values.
autoplot(instance, type = "surface", cols_x = c("cost", "gamma"),
+ learner = lrn("regr.km"))
The points mark the evaluated cost and gamma values. We should not infer the performance of new values from the heatmap since it is only an interpolation. However, we can see the general interaction between the hyperparameters.
Tuning a learner can be shortened by using the tune()-shortcut.
learner = lrn("classif.svm", type = "C-classification", kernel = "radial")
+learner$param_set$values$cost = to_tune(0.1, 10)
+learner$param_set$values$gamma = to_tune(0, 5)
+
+instance = tune(
+ tuner = tnr("grid_search", resolution = 5),
+ task = tsk("iris"),
+ learner = learner,
+ resampling = rsmp ("holdout"),
+ measure = msr("classif.ce")
+)Next, we want to tune the cost and gamma hyperparameter more efficiently. It is recommended to tune cost and gamma on the logarithmic scale (Hsu, Chang, and Lin 2003). The log transformation emphasizes smaller cost and gamma values but also creates large values. Therefore, we use a log transformation to emphasize this region of the search space with a denser grid.
Generally speaking, transformations can be used to convert hyperparameters to a new scale. These transformations are applied before the proposed configuration is passed to the Learner. We can directly define the transformation in the to_tune() function. The lower and upper bound is set on the original scale.
learner = lrn("classif.svm", type = "C-classification", kernel = "radial")
+
+# tune from 2^-15 to 2^15 on a log scale
+learner$param_set$values$cost = to_tune(p_dbl(-15, 15, trafo = function(x) 2^x))
+
+# tune from 2^-15 to 2^5 on a log scale
+learner$param_set$values$gamma = to_tune(p_dbl(-15, 5, trafo = function(x) 2^x))Transformations to the log scale are the ones most commonly used. We can use a shortcut for this transformation. The lower and upper bound is set on the transformed scale.
+learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))We use the tune()-shortcut to run the tuning.
instance = tune(
+ tuner = tnr("grid_search", resolution = 5),
+ task = task,
+ learner = learner,
+ resampling = resampling,
+ measure = measure
+)The hyperparameter values after the transformation are stored in the x_domain column as lists. We can expand these lists into multiple columns by using as.data.table(). The hyperparameter names are prefixed by x_domain.
as.data.table(instance$archive)[, .(cost, gamma, x_domain_cost, x_domain_gamma)] cost gamma x_domain_cost x_domain_gamma
+ 1: -5.756463 -11.512925 3.162278e-03 1.000000e-05
+ 2: 0.000000 11.512925 1.000000e+00 1.000000e+05
+ 3: -11.512925 11.512925 1.000000e-05 1.000000e+05
+ 4: 11.512925 5.756463 1.000000e+05 3.162278e+02
+ 5: -11.512925 0.000000 1.000000e-05 1.000000e+00
+ 6: 11.512925 -5.756463 1.000000e+05 3.162278e-03
+ 7: 11.512925 0.000000 1.000000e+05 1.000000e+00
+ 8: -11.512925 5.756463 1.000000e-05 3.162278e+02
+ 9: 0.000000 0.000000 1.000000e+00 1.000000e+00
+10: 5.756463 0.000000 3.162278e+02 1.000000e+00
+11: 0.000000 -5.756463 1.000000e+00 3.162278e-03
+12: 0.000000 -11.512925 1.000000e+00 1.000000e-05
+13: -5.756463 -5.756463 3.162278e-03 3.162278e-03
+14: 11.512925 -11.512925 1.000000e+05 1.000000e-05
+15: 5.756463 11.512925 3.162278e+02 1.000000e+05
+16: 0.000000 5.756463 1.000000e+00 3.162278e+02
+17: -5.756463 0.000000 3.162278e-03 1.000000e+00
+18: 5.756463 -11.512925 3.162278e+02 1.000000e-05
+19: -5.756463 11.512925 3.162278e-03 1.000000e+05
+20: 11.512925 11.512925 1.000000e+05 1.000000e+05
+21: 5.756463 -5.756463 3.162278e+02 3.162278e-03
+22: -11.512925 -11.512925 1.000000e-05 1.000000e-05
+23: -11.512925 -5.756463 1.000000e-05 3.162278e-03
+24: 5.756463 5.756463 3.162278e+02 3.162278e+02
+25: -5.756463 5.756463 3.162278e-03 3.162278e+02
+ cost gamma x_domain_cost x_domain_gammaWe plot the performances depending on the evaluated cost and gamma values.
library(ggplot2)
+library(scales)
+autoplot(instance, type = "points", cols_x = c("x_domain_cost", "x_domain_gamma")) +
+ scale_x_continuous(
+ trans = log2_trans(),
+ breaks = trans_breaks("log10", function(x) 10^x),
+ labels = trans_format("log10", math_format(10^.x))) +
+ scale_y_continuous(
+ trans = log2_trans(),
+ breaks = trans_breaks("log10", function(x) 10^x),
+ labels = trans_format("log10", math_format(10^.x)))
Dependencies ensure that certain parameters are only proposed depending on values of other hyperparameters. We want to tune the degree hyperparameter that is only needed for the polynomial kernel.
learner = lrn("classif.svm", type = "C-classification")
+
+learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+
+learner$param_set$values$kernel = to_tune(c("polynomial", "radial"))
+learner$param_set$values$degree = to_tune(1, 4)The dependencies are already stored in the learner parameter set.
+learner$param_set$deps id on cond
+1: cost type <CondEqual[9]>
+2: nu type <CondEqual[9]>
+3: degree kernel <CondEqual[9]>
+4: coef0 kernel <CondAnyOf[9]>
+5: gamma kernel <CondAnyOf[9]>The gamma hyperparameter depends on the kernel being polynomial, radial or sigmoid
learner$param_set$deps$cond[[5]]CondAnyOf: x ∈ {polynomial, radial, sigmoid}whereas the degree hyperparameter is solely used by the polynomial kernel.
learner$param_set$deps$cond[[3]]CondEqual: x = polynomialWe preview the grid to show the effect of the dependencies.
+generate_design_grid(learner$param_set$search_space(), resolution = 2)<Design> with 12 rows:
+ cost gamma kernel degree
+ 1: -11.51293 -11.51293 polynomial 1
+ 2: -11.51293 -11.51293 polynomial 4
+ 3: -11.51293 -11.51293 radial NA
+ 4: -11.51293 11.51293 polynomial 1
+ 5: -11.51293 11.51293 polynomial 4
+ 6: -11.51293 11.51293 radial NA
+ 7: 11.51293 -11.51293 polynomial 1
+ 8: 11.51293 -11.51293 polynomial 4
+ 9: 11.51293 -11.51293 radial NA
+10: 11.51293 11.51293 polynomial 1
+11: 11.51293 11.51293 polynomial 4
+12: 11.51293 11.51293 radial NAThe value for degree is NA if the dependency on the kernel is not satisfied.
We use the tune()-shortcut to run the tuning.
instance = tune(
+ tuner = tnr("grid_search", resolution = 3),
+ task = task,
+ learner = learner,
+ resampling = resampling,
+ measure = measure
+)instance$result cost gamma kernel degree learner_param_vals x_domain classif.ce
+1: 0 11.51293 polynomial 1 <list[5]> <list[4]> 0.02666667We add the optimized hyperparameters to the learner and train the learner on the full dataset.
+learner = lrn("classif.svm")
+learner$param_set$values = instance$result_learner_param_vals
+learner$train(task)The trained model can now be used to make predictions on new data. A common mistake is to report the performance estimated on the resampling sets on which the tuning was performed (instance$result_y) as the model’s performance. These scores might be biased and overestimate the ability of the fitted model to predict with new data. Instead, we have to use nested resampling to get an unbiased performance estimate.
Tuning should not be performed on the same resampling sets which are used for evaluating the model itself, since this would result in a biased performance estimate. Nested resampling uses an outer and inner resampling to separate the tuning from the performance estimation of the model. We can use the AutoTuner class for running nested resampling. The AutoTuner wraps a Learner and tunes the hyperparameter of the learner during $train(). This is our inner resampling loop.
learner = lrn("classif.svm", type = "C-classification")
+learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$kernel = to_tune(c("polynomial", "radial"))
+learner$param_set$values$degree = to_tune(1, 4)
+
+resampling_inner = rsmp("cv", folds = 3)
+terminator = trm("none")
+tuner = tnr("grid_search", resolution = 3)
+
+at = AutoTuner$new(
+ learner = learner,
+ resampling = resampling_inner,
+ measure = measure,
+ terminator = terminator,
+ tuner = tuner,
+ store_models = TRUE)We put the AutoTuner into a resample() call to get the outer resampling loop.
resampling_outer = rsmp("cv", folds = 3)
+rr = resample(task = task, learner = at, resampling = resampling_outer, store_models = TRUE)We check the inner tuning results for stable hyperparameters. This means that the selected hyperparameters should not vary too much. We might observe unstable models in this example because the small data set and the low number of resampling iterations might introduce too much randomness. Usually, we aim for the selection of stable hyperparameters for all outer training sets.
+extract_inner_tuning_results(rr)[, .SD, .SDcols = !c("learner_param_vals", "x_domain")] iteration cost gamma kernel degree classif.ce task_id learner_id resampling_id
+1: 1 0.00000 0.00000 polynomial 1 0.03000594 iris classif.svm.tuned cv
+2: 2 0.00000 0.00000 polynomial 1 0.03000594 iris classif.svm.tuned cv
+3: 3 11.51293 -11.51293 radial NA 0.02020202 iris classif.svm.tuned cvNext, we want to compare the predictive performances estimated on the outer resampling to the inner resampling (extract_inner_tuning_results(rr)). Significantly lower predictive performances on the outer resampling indicate that the models with the optimized hyperparameters overfit the data.
rr$score()[, .(iteration, task_id, learner_id, resampling_id, classif.ce)] iteration task_id learner_id resampling_id classif.ce
+1: 1 iris classif.svm.tuned cv 0.04
+2: 2 iris classif.svm.tuned cv 0.06
+3: 3 iris classif.svm.tuned cv 0.00The archives of the AutoTuners allows us to inspect all evaluated hyperparameters configurations with the associated predictive performances.
extract_inner_tuning_archives(rr, unnest = NULL, exclude_columns = c("resample_result", "uhash", "x_domain", "timestamp")) iteration cost gamma kernel degree classif.ce runtime_learners batch_nr warnings errors task_id
+ 1: 1 0.00000 -11.51293 polynomial 2 0.68033274 0.017 1 0 0 iris
+ 2: 1 0.00000 -11.51293 radial NA 0.64111705 0.017 2 0 0 iris
+ 3: 1 0.00000 0.00000 polynomial 1 0.03000594 0.017 3 0 0 iris
+ 4: 1 11.51293 0.00000 polynomial 1 0.05050505 0.012 4 0 0 iris
+ 5: 1 11.51293 11.51293 radial NA 0.66013072 0.014 5 0 0 iris
+ ---
+104: 3 11.51293 -11.51293 polynomial 2 0.68924540 0.013 32 0 0 iris
+105: 3 -11.51293 -11.51293 radial NA 0.68924540 0.012 33 0 0 iris
+106: 3 -11.51293 11.51293 polynomial 4 0.11883541 0.015 34 0 0 iris
+107: 3 0.00000 -11.51293 polynomial 4 0.68924540 0.015 35 0 0 iris
+108: 3 11.51293 11.51293 polynomial 1 0.06951872 0.725 36 0 0 iris
+ learner_id resampling_id
+ 1: classif.svm.tuned cv
+ 2: classif.svm.tuned cv
+ 3: classif.svm.tuned cv
+ 4: classif.svm.tuned cv
+ 5: classif.svm.tuned cv
+ ---
+104: classif.svm.tuned cv
+105: classif.svm.tuned cv
+106: classif.svm.tuned cv
+107: classif.svm.tuned cv
+108: classif.svm.tuned cvThe aggregated performance of all outer resampling iterations is essentially the unbiased performance of an SVM with optimal hyperparameter found by grid search.
+rr$aggregate()classif.ce
+0.03333333 Applying nested resampling can be shortened by using the tune_nested()-shortcut.
learner = lrn("classif.svm", type = "C-classification")
+learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
+learner$param_set$values$kernel = to_tune(c("polynomial", "radial"))
+learner$param_set$values$degree = to_tune(1, 4)
+
+rr = tune_nested(
+ tuner = tnr("grid_search", resolution = 3),
+ task = tsk("iris"),
+ learner = learner,
+ inner_resampling = rsmp ("cv", folds = 3),
+ outer_resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+)The mlr3book includes chapters on tuning spaces and hyperparameter tuning. The mlr3cheatsheets contain frequently used commands and workflows of mlr3.
+ + + +This is the second part of the practical tuning series. The other parts can be found here:
+In this post, we build a simple preprocessing pipeline and tune it. For this, we are using the mlr3pipelines extension package. First, we start by imputing missing values in the Pima Indians Diabetes data set. After that, we encode a factor column to numerical dummy columns in the data set. Next, we combine both preprocessing steps to a Graph and create a GraphLearner. Finally, nested resampling is used to compare the performance of two imputation methods.
We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")In this example, we use the Pima Indians Diabetes data set which is used to predict whether or not a patient has diabetes. The patients are characterized by 8 numeric features of which some have missing values. We alter the data set by categorizing the feature pressure (blood pressure) into the categories "low", "mid", and "high".
# retrieve the task from mlr3
+task = tsk("pima")
+
+# create data frame with categorized pressure feature
+data = task$data(cols = "pressure")
+breaks = quantile(data$pressure, probs = c(0, 0.33, 0.66, 1), na.rm = TRUE)
+data$pressure = cut(data$pressure, breaks, labels = c("low", "mid", "high"))
+
+# overwrite the feature in the task
+task$cbind(data)
+
+# generate a quick textual overview
+skimr::skim(task$data())| Name | +task$data() | +
| Number of rows | +768 | +
| Number of columns | +9 | +
| Key | +NULL | +
| _______________________ | ++ |
| Column type frequency: | ++ |
| factor | +2 | +
| numeric | +7 | +
| ________________________ | ++ |
| Group variables | +None | +
Variable type: factor
+| skim_variable | +n_missing | +complete_rate | +ordered | +n_unique | +top_counts | +
|---|---|---|---|---|---|
| diabetes | +0 | +1.00 | +FALSE | +2 | +neg: 500, pos: 268 | +
| pressure | +36 | +0.95 | +FALSE | +3 | +low: 282, mid: 245, hig: 205 | +
Variable type: numeric
+| skim_variable | +n_missing | +complete_rate | +mean | +sd | +p0 | +p25 | +p50 | +p75 | +p100 | +hist | +
|---|---|---|---|---|---|---|---|---|---|---|
| age | +0 | +1.00 | +33.24 | +11.76 | +21.00 | +24.00 | +29.00 | +41.00 | +81.00 | +▇▃▁▁▁ | +
| glucose | +5 | +0.99 | +121.69 | +30.54 | +44.00 | +99.00 | +117.00 | +141.00 | +199.00 | +▁▇▇▃▂ | +
| insulin | +374 | +0.51 | +155.55 | +118.78 | +14.00 | +76.25 | +125.00 | +190.00 | +846.00 | +▇▂▁▁▁ | +
| mass | +11 | +0.99 | +32.46 | +6.92 | +18.20 | +27.50 | +32.30 | +36.60 | +67.10 | +▅▇▃▁▁ | +
| pedigree | +0 | +1.00 | +0.47 | +0.33 | +0.08 | +0.24 | +0.37 | +0.63 | +2.42 | +▇▃▁▁▁ | +
| pregnant | +0 | +1.00 | +3.85 | +3.37 | +0.00 | +1.00 | +3.00 | +6.00 | +17.00 | +▇▃▂▁▁ | +
| triceps | +227 | +0.70 | +29.15 | +10.48 | +7.00 | +22.00 | +29.00 | +36.00 | +99.00 | +▆▇▁▁▁ | +
We choose the xgboost algorithm from the xgboost package as learner.
+learner = lrn("classif.xgboost", nrounds = 100, id = "xgboost", verbose = 0)The task has missing data in five columns.
+round(task$missings() / task$nrow, 2)diabetes age glucose insulin mass pedigree pregnant pressure triceps
+ 0.00 0.00 0.01 0.49 0.01 0.00 0.00 0.05 0.30 The xgboost learner has an internal method for handling missing data but some learners cannot handle missing values. We will try to beat the internal method in terms of predictive performance. The mlr3pipelines package offers various methods to impute missing values.
mlr_pipeops$keys("^impute")[1] "imputeconstant" "imputehist" "imputelearner" "imputemean" "imputemedian" "imputemode"
+[7] "imputeoor" "imputesample" We choose the PipeOpImputeOOR that adds the new factor level ".MISSING". to factorial features and imputes numerical features by constant values shifted below the minimum (default) or above the maximum.
imputer = po("imputeoor")
+print(imputer)PipeOp: <imputeoor> (not trained)
+values: <min=TRUE, offset=1, multiplier=1>
+Input channels <name [train type, predict type]>:
+ input [Task,Task]
+Output channels <name [train type, predict type]>:
+ output [Task,Task]As the output suggests, the in- and output of this pipe operator is a Task for both the training and the predict step. We can manually train the pipe operator to check its functionality:
task_imputed = imputer$train(list(task))[[1]]
+task_imputed$missings()diabetes age pedigree pregnant glucose insulin mass pressure triceps
+ 0 0 0 0 0 0 0 0 0 Let’s compare an observation with missing values to the observation with imputed observation.
+rbind(
+ task$data()[8,],
+ task_imputed$data()[8,]
+) diabetes age glucose insulin mass pedigree pregnant pressure triceps
+1: neg 29 115 NA 35.3 0.134 10 <NA> NA
+2: neg 29 115 -819 35.3 0.134 10 .MISSING -86Note that OOR imputation is in particular useful for tree-based models, but should not be used for linear models or distance-based models.
+The xgboost learner cannot handle categorical features. Therefore, we must to convert factor columns to numerical dummy columns. For this, we argument the xgboost learner with automatic factor encoding.
The PipeOpEncode encodes factor columns with one of six methods. In this example, we use one-hot encoding which creates a new binary column for each factor level.
factor_encoding = po("encode", method = "one-hot")We manually trigger the encoding on the task.
+factor_encoding$train(list(task))$output
+<TaskClassif:pima> (768 x 11): Pima Indian Diabetes
+* Target: diabetes
+* Properties: twoclass
+* Features (10):
+ - dbl (10): age, glucose, insulin, mass, pedigree, pregnant, pressure.high, pressure.low, pressure.mid,
+ tricepsThe factor column pressure has been converted to the three binary columns "pressure.low", "pressure.mid", and "pressure.high".
We created two preprocessing steps which could be used to create a new task with encoded factor variables and imputed missing values. However, if we do this before resampling, information from the test can leak into our training step which typically leads to overoptimistic performance measures. To avoid this, we add the preprocessing steps to the Learner itself, creating a GraphLearner. For this, we create a Graph first.
graph = po("encode") %>>%
+ po("imputeoor") %>>%
+ learner
+plot(graph, html = FALSE)
We use as_learner() to wrap the Graph into a GraphLearner with which allows us to use the graph like a normal learner.
graph_learner = as_learner(graph)
+
+# short learner id for printing
+graph_learner$id = "graph_learner"The GraphLearner can be trained and used for making predictions. Instead of calling $train() or $predict() manually, we will directly use it for resampling. We choose a 3-fold cross-validation as the resampling strategy.
resampling = rsmp("cv", folds = 3)
+
+rr = resample(task = task, learner = graph_learner, resampling = resampling)rr$score()[, c("iteration", "task_id", "learner_id", "resampling_id", "classif.ce"), with = FALSE] iteration task_id learner_id resampling_id classif.ce
+1: 1 pima graph_learner cv 0.2851562
+2: 2 pima graph_learner cv 0.2460938
+3: 3 pima graph_learner cv 0.2968750For each resampling iteration, the following steps are performed:
+Next is the predict step:
+By following this procedure, it is guaranteed that no information can leak from the training step to the predict step.
+Let’s have a look at the parameter set of the GraphLearner. It consists of the xgboost hyperparameters, and additionally, the parameter of the PipeOp encode and imputeoor. All hyperparameters are prefixed with the id of the respective PipeOp or learner.
as.data.table(graph_learner$param_set)[, c("id", "class", "lower", "upper", "nlevels"), with = FALSE] id class lower upper nlevels
+ 1: encode.method ParamFct NA NA 5
+ 2: encode.affect_columns ParamUty NA NA Inf
+ 3: imputeoor.min ParamLgl NA NA 2
+ 4: imputeoor.offset ParamDbl 0 Inf Inf
+ 5: imputeoor.multiplier ParamDbl 0 Inf Inf
+ 6: imputeoor.affect_columns ParamUty NA NA Inf
+ 7: xgboost.alpha ParamDbl 0 Inf Inf
+ 8: xgboost.approxcontrib ParamLgl NA NA 2
+ 9: xgboost.base_score ParamDbl -Inf Inf Inf
+10: xgboost.booster ParamFct NA NA 3
+11: xgboost.callbacks ParamUty NA NA Inf
+12: xgboost.colsample_bylevel ParamDbl 0 1 Inf
+13: xgboost.colsample_bynode ParamDbl 0 1 Inf
+14: xgboost.colsample_bytree ParamDbl 0 1 Inf
+15: xgboost.disable_default_eval_metric ParamLgl NA NA 2
+16: xgboost.early_stopping_rounds ParamInt 1 Inf Inf
+17: xgboost.early_stopping_set ParamFct NA NA 3
+18: xgboost.eta ParamDbl 0 1 Inf
+19: xgboost.eval_metric ParamUty NA NA Inf
+20: xgboost.feature_selector ParamFct NA NA 5
+21: xgboost.feval ParamUty NA NA Inf
+22: xgboost.gamma ParamDbl 0 Inf Inf
+23: xgboost.grow_policy ParamFct NA NA 2
+24: xgboost.interaction_constraints ParamUty NA NA Inf
+25: xgboost.iterationrange ParamUty NA NA Inf
+26: xgboost.lambda ParamDbl 0 Inf Inf
+27: xgboost.lambda_bias ParamDbl 0 Inf Inf
+28: xgboost.max_bin ParamInt 2 Inf Inf
+29: xgboost.max_delta_step ParamDbl 0 Inf Inf
+30: xgboost.max_depth ParamInt 0 Inf Inf
+31: xgboost.max_leaves ParamInt 0 Inf Inf
+32: xgboost.maximize ParamLgl NA NA 2
+33: xgboost.min_child_weight ParamDbl 0 Inf Inf
+34: xgboost.missing ParamDbl -Inf Inf Inf
+35: xgboost.monotone_constraints ParamUty NA NA Inf
+36: xgboost.normalize_type ParamFct NA NA 2
+37: xgboost.nrounds ParamInt 1 Inf Inf
+38: xgboost.nthread ParamInt 1 Inf Inf
+39: xgboost.ntreelimit ParamInt 1 Inf Inf
+40: xgboost.num_parallel_tree ParamInt 1 Inf Inf
+41: xgboost.objective ParamUty NA NA Inf
+42: xgboost.one_drop ParamLgl NA NA 2
+43: xgboost.outputmargin ParamLgl NA NA 2
+44: xgboost.predcontrib ParamLgl NA NA 2
+45: xgboost.predictor ParamFct NA NA 2
+46: xgboost.predinteraction ParamLgl NA NA 2
+47: xgboost.predleaf ParamLgl NA NA 2
+48: xgboost.print_every_n ParamInt 1 Inf Inf
+49: xgboost.process_type ParamFct NA NA 2
+50: xgboost.rate_drop ParamDbl 0 1 Inf
+51: xgboost.refresh_leaf ParamLgl NA NA 2
+52: xgboost.reshape ParamLgl NA NA 2
+53: xgboost.seed_per_iteration ParamLgl NA NA 2
+54: xgboost.sampling_method ParamFct NA NA 2
+55: xgboost.sample_type ParamFct NA NA 2
+56: xgboost.save_name ParamUty NA NA Inf
+57: xgboost.save_period ParamInt 0 Inf Inf
+58: xgboost.scale_pos_weight ParamDbl -Inf Inf Inf
+59: xgboost.skip_drop ParamDbl 0 1 Inf
+60: xgboost.strict_shape ParamLgl NA NA 2
+61: xgboost.subsample ParamDbl 0 1 Inf
+62: xgboost.top_k ParamInt 0 Inf Inf
+63: xgboost.training ParamLgl NA NA 2
+64: xgboost.tree_method ParamFct NA NA 5
+65: xgboost.tweedie_variance_power ParamDbl 1 2 Inf
+66: xgboost.updater ParamUty NA NA Inf
+67: xgboost.verbose ParamInt 0 2 3
+68: xgboost.watchlist ParamUty NA NA Inf
+69: xgboost.xgb_model ParamUty NA NA Inf
+ id class lower upper nlevelsWe will tune the encode method.
+graph_learner$param_set$values$encode.method = to_tune(c("one-hot", "treatment"))We define a tuning instance and use grid search since we want to try all encode methods.
+instance = tune(
+ tuner = tnr("grid_search"),
+ task = task,
+ learner = graph_learner,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce")
+)The archive shows us the performance of the model with different encoding methods.
+print(instance$archive)<ArchiveTuning> with 2 evaluations
+ encode.method classif.ce batch_nr warnings errors
+1: treatment 0.26 1 0 0
+2: one-hot 0.26 2 0 0We create one GraphLearner with imputeoor and test it against a GraphLearner that uses the internal imputation method of xgboost. Applying nested resampling ensures a fair comparison of the predictive performances.
graph_1 = po("encode") %>>%
+ learner
+graph_learner_1 = GraphLearner$new(graph_1)
+
+graph_learner_1$param_set$values$encode.method = to_tune(c("one-hot", "treatment"))
+
+at_1 = AutoTuner$new(
+ learner = graph_learner_1,
+ resampling = resampling,
+ measure = msr("classif.ce"),
+ terminator = trm("none"),
+ tuner = tnr("grid_search"),
+ store_models = TRUE
+)graph_2 = po("encode") %>>%
+ po("imputeoor") %>>%
+ learner
+graph_learner_2 = GraphLearner$new(graph_2)
+
+graph_learner_2$param_set$values$encode.method = to_tune(c("one-hot", "treatment"))
+
+at_2 = AutoTuner$new(
+ learner = graph_learner_2,
+ resampling = resampling,
+ measure = msr("classif.ce"),
+ terminator = trm("none"),
+ tuner = tnr("grid_search"),
+ store_models = TRUE
+)We run the benchmark.
+resampling_outer = rsmp("cv", folds = 3)
+design = benchmark_grid(task, list(at_1, at_2), resampling_outer)
+
+bmr = benchmark(design, store_models = TRUE)We compare the aggregated performances on the outer test sets which give us an unbiased performance estimate of the GraphLearners with the different encoding methods.
bmr$aggregate() nr task_id learner_id resampling_id iters classif.ce
+1: 1 pima encode.xgboost.tuned cv 3 0.2578125
+2: 2 pima encode.imputeoor.xgboost.tuned cv 3 0.2630208
+Hidden columns: resample_resultautoplot(bmr)
Note that in practice, it is required to tune preprocessing hyperparameters jointly with the hyperparameters of the learner. Otherwise, comparing preprocessing steps is not feasible and can lead to wrong conclusions.
+Applying nested resampling can be shortened by using the auto_tuner()-shortcut.
graph_1 = po("encode") %>>% learner
+graph_learner_1 = as_learner(graph_1)
+graph_learner_1$param_set$values$encode.method = to_tune(c("one-hot", "treatment"))
+
+at_1 = auto_tuner(
+ method = "grid_search",
+ learner = graph_learner_1,
+ resampling = resampling,
+ measure = msr("classif.ce"),
+ store_models = TRUE)
+
+graph_2 = po("encode") %>>% po("imputeoor") %>>% learner
+graph_learner_2 = as_learner(graph_2)
+graph_learner_2$param_set$values$encode.method = to_tune(c("one-hot", "treatment"))
+
+at_2 = auto_tuner(
+ method = "grid_search",
+ learner = graph_learner_2,
+ resampling = resampling,
+ measure = msr("classif.ce"),
+ store_models = TRUE)
+
+design = benchmark_grid(task, list(at_1, at_2), rsmp("cv", folds = 3))
+
+bmr = benchmark(design, store_models = TRUE)We train the chosen GraphLearner with the AutoTuner to get a final model with optimized hyperparameters.
at_2$train(task)The trained model can now be used to make predictions on new data at_2$predict(). The pipeline ensures that the preprocessing is always a part of the train and predict step.
The mlr3book includes chapters on pipelines and hyperparameter tuning. The mlr3cheatsheets contain frequently used commands and workflows of mlr3.
+ + +This is the third part of the practical tuning series. The other parts can be found here:
+In this post, we implement a simple automated machine learning (AutoML) system which includes preprocessing, a switch between multiple learners and hyperparameter tuning. For this, we build a pipeline with the mlr3pipelines extension package. Additionally, we use nested resampling to get an unbiased performance estimate of our AutoML system.
+We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")In this example, we use the Pima Indians Diabetes data set which is used to to predict whether or not a patient has diabetes. The patients are characterized by 8 numeric features and some have missing values.
+task = tsk("pima")We use three popular machine learning algorithms: k-nearest-neighbors, support vector machines and random forests.
+learners = list(
+ lrn("classif.kknn", id = "kknn"),
+ lrn("classif.svm", id = "svm", type = "C-classification"),
+ lrn("classif.ranger", id = "ranger")
+)The PipeOpBranch allows us to specify multiple alternatives paths. In this graph, the paths lead to the different learner models. The selection hyperparameter controls which path is executed i.e., which learner is used to fit a model. It is important to use the PipeOpBranch after the branching so that the outputs are merged into one result object. We visualize the graph with branching below.
graph =
+ po("branch", options = c("kknn", "svm", "ranger")) %>>%
+ gunion(lapply(learners, po)) %>>%
+ po("unbranch")
+graph$plot(html = FALSE)
Alternatively, we can use the ppl()-shortcut to load a predefined graph from the mlr_graphs dictionary. For this, the learner list must be named.
learners = list(
+ kknn = lrn("classif.kknn", id = "kknn"),
+ svm = lrn("classif.svm", id = "svm", type = "C-classification"),
+ ranger = lrn("classif.ranger", id = "ranger")
+)
+
+graph = ppl("branch", lapply(learners, po))The task has missing data in five columns.
+round(task$missings() / task$nrow, 2)diabetes age glucose insulin mass pedigree pregnant pressure triceps
+ 0.00 0.00 0.01 0.49 0.01 0.00 0.00 0.05 0.30 The pipeline "robustify" function creates a preprocessing pipeline based on our task. The resulting pipeline imputes missing values with PipeOpImputeHist and creates a dummy column (PipeOpMissInd) which indicates the imputed missing values. Internally, this creates two paths and the results are combined with PipeOpFeatureUnion. In contrast to PipeOpBranch, both paths are executed. Additionally, "robustify" adds PipeOpEncode to encode factor columns and PipeOpRemoveConstants to remove features with a constant value.
graph = ppl("robustify", task = task, factors_to_numeric = TRUE) %>>%
+ graph
+plot(graph, html = FALSE)
We could also create the preprocessing pipeline manually.
+gunion(list(po("imputehist"),
+ po("missind", affect_columns = selector_type(c("numeric", "integer"))))) %>>%
+ po("featureunion") %>>%
+ po("encode") %>>%
+ po("removeconstants")Graph with 5 PipeOps:
+ ID State sccssors prdcssors
+ imputehist <<UNTRAINED>> featureunion
+ missind <<UNTRAINED>> featureunion
+ featureunion <<UNTRAINED>> encode imputehist,missind
+ encode <<UNTRAINED>> removeconstants featureunion
+ removeconstants <<UNTRAINED>> encodeWe use as_learner() to create a GraphLearner which encapsulates the pipeline and can be used like a learner.
graph_learner = as_learner(graph)The parameter set of the graph learner includes all hyperparameters from all contained learners. The hyperparameter ids are prefixed with the corresponding learner ids. The hyperparameter branch.selection controls which learner is used.
as.data.table(graph_learner$param_set)[, .(id, class, lower, upper, nlevels)] id class lower upper nlevels
+ 1: removeconstants_prerobustify.ratio ParamDbl 0 1 Inf
+ 2: removeconstants_prerobustify.rel_tol ParamDbl 0 Inf Inf
+ 3: removeconstants_prerobustify.abs_tol ParamDbl 0 Inf Inf
+ 4: removeconstants_prerobustify.na_ignore ParamLgl NA NA 2
+ 5: removeconstants_prerobustify.affect_columns ParamUty NA NA Inf
+ 6: imputehist.affect_columns ParamUty NA NA Inf
+ 7: missind.which ParamFct NA NA 2
+ 8: missind.type ParamFct NA NA 4
+ 9: missind.affect_columns ParamUty NA NA Inf
+10: imputesample.affect_columns ParamUty NA NA Inf
+11: encode.method ParamFct NA NA 5
+12: encode.affect_columns ParamUty NA NA Inf
+13: removeconstants_postrobustify.ratio ParamDbl 0 1 Inf
+14: removeconstants_postrobustify.rel_tol ParamDbl 0 Inf Inf
+15: removeconstants_postrobustify.abs_tol ParamDbl 0 Inf Inf
+16: removeconstants_postrobustify.na_ignore ParamLgl NA NA 2
+17: removeconstants_postrobustify.affect_columns ParamUty NA NA Inf
+18: kknn.k ParamInt 1 Inf Inf
+19: kknn.distance ParamDbl 0 Inf Inf
+20: kknn.kernel ParamFct NA NA 10
+21: kknn.scale ParamLgl NA NA 2
+22: kknn.ykernel ParamUty NA NA Inf
+23: kknn.store_model ParamLgl NA NA 2
+24: svm.cachesize ParamDbl -Inf Inf Inf
+25: svm.class.weights ParamUty NA NA Inf
+26: svm.coef0 ParamDbl -Inf Inf Inf
+27: svm.cost ParamDbl 0 Inf Inf
+28: svm.cross ParamInt 0 Inf Inf
+29: svm.decision.values ParamLgl NA NA 2
+30: svm.degree ParamInt 1 Inf Inf
+31: svm.epsilon ParamDbl 0 Inf Inf
+32: svm.fitted ParamLgl NA NA 2
+33: svm.gamma ParamDbl 0 Inf Inf
+34: svm.kernel ParamFct NA NA 4
+35: svm.nu ParamDbl -Inf Inf Inf
+36: svm.scale ParamUty NA NA Inf
+37: svm.shrinking ParamLgl NA NA 2
+38: svm.tolerance ParamDbl 0 Inf Inf
+39: svm.type ParamFct NA NA 2
+40: ranger.alpha ParamDbl -Inf Inf Inf
+41: ranger.always.split.variables ParamUty NA NA Inf
+42: ranger.class.weights ParamUty NA NA Inf
+43: ranger.holdout ParamLgl NA NA 2
+44: ranger.importance ParamFct NA NA 4
+45: ranger.keep.inbag ParamLgl NA NA 2
+46: ranger.max.depth ParamInt 0 Inf Inf
+47: ranger.min.node.size ParamInt 1 Inf Inf
+48: ranger.min.prop ParamDbl -Inf Inf Inf
+49: ranger.minprop ParamDbl -Inf Inf Inf
+50: ranger.mtry ParamInt 1 Inf Inf
+51: ranger.mtry.ratio ParamDbl 0 1 Inf
+52: ranger.num.random.splits ParamInt 1 Inf Inf
+53: ranger.num.threads ParamInt 1 Inf Inf
+54: ranger.num.trees ParamInt 1 Inf Inf
+55: ranger.oob.error ParamLgl NA NA 2
+56: ranger.regularization.factor ParamUty NA NA Inf
+57: ranger.regularization.usedepth ParamLgl NA NA 2
+58: ranger.replace ParamLgl NA NA 2
+59: ranger.respect.unordered.factors ParamFct NA NA 3
+60: ranger.sample.fraction ParamDbl 0 1 Inf
+61: ranger.save.memory ParamLgl NA NA 2
+62: ranger.scale.permutation.importance ParamLgl NA NA 2
+63: ranger.se.method ParamFct NA NA 2
+64: ranger.seed ParamInt -Inf Inf Inf
+65: ranger.split.select.weights ParamUty NA NA Inf
+66: ranger.splitrule ParamFct NA NA 3
+67: ranger.verbose ParamLgl NA NA 2
+68: ranger.write.forest ParamLgl NA NA 2
+69: branch.selection ParamFct NA NA 3
+ id class lower upper nlevelsWe will only tune one hyperparameter for each learner in this example. Additionally, we tune the branching parameter which selects one of the three learners. We have to specify that a hyperparameter is only valid for a certain learner by using depends = branch.selection == <learner_id>.
# branch
+graph_learner$param_set$values$branch.selection =
+ to_tune(c("kknn", "svm", "ranger"))
+
+# kknn
+graph_learner$param_set$values$kknn.k =
+ to_tune(p_int(3, 50, logscale = TRUE, depends = branch.selection == "kknn"))
+
+# svm
+graph_learner$param_set$values$svm.cost =
+ to_tune(p_dbl(-1, 1, trafo = function(x) 10^x, depends = branch.selection == "svm"))
+
+# ranger
+graph_learner$param_set$values$ranger.mtry =
+ to_tune(p_int(1, 8, depends = branch.selection == "ranger"))
+
+# short learner id for printing
+graph_learner$id = "graph_learner"We define a tuning instance and select a random search which is stopped after 20 evaluated configurations.
+instance = tune(
+ tuner = tnr("random_search"),
+ task = task,
+ learner = graph_learner,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+ term_evals = 20
+)The following shows a quick way to visualize the tuning results.
+autoplot(instance, type = "marginal",
+ cols_x = c("x_domain_kknn.k", "x_domain_svm.cost", "ranger.mtry"))
We add the optimized hyperparameters to the graph learner and train the learner on the full dataset.
+learner = as_learner(graph)
+learner$param_set$values = instance$result_learner_param_vals
+learner$train(task)The trained model can now be used to make predictions on new data. A common mistake is to report the performance estimated on the resampling sets on which the tuning was performed (instance$result_y) as the model’s performance. Instead we have to use nested resampling to get an unbiased performance estimate.
We use nested resampling to get an unbiased estimate of the predictive performance of our graph learner.
+graph_learner = as_learner(graph)
+graph_learner$param_set$values$branch.selection =
+ to_tune(c("kknn", "svm", "ranger"))
+graph_learner$param_set$values$kknn.k =
+ to_tune(p_int(3, 50, logscale = TRUE, depends = branch.selection == "kknn"))
+graph_learner$param_set$values$svm.cost =
+ to_tune(p_dbl(-1, 1, trafo = function(x) 10^x, depends = branch.selection == "svm"))
+graph_learner$param_set$values$ranger.mtry =
+ to_tune(p_int(1, 8, depends = branch.selection == "ranger"))
+graph_learner$id = "graph_learner"
+
+inner_resampling = rsmp("cv", folds = 3)
+at = AutoTuner$new(
+ learner = graph_learner,
+ resampling = inner_resampling,
+ measure = msr("classif.ce"),
+ terminator = trm("evals", n_evals = 10),
+ tuner = tnr("random_search")
+)
+
+outer_resampling = rsmp("cv", folds = 3)
+rr = resample(task, at, outer_resampling, store_models = TRUE)We check the inner tuning results for stable hyperparameters. This means that the selected hyperparameters should not vary too much. We might observe unstable models in this example because the small data set and the low number of resampling iterations might introduce too much randomness. Usually, we aim for the selection of stable hyperparameters for all outer training sets.
+extract_inner_tuning_results(rr)Next, we want to compare the predictive performances estimated on the outer resampling to the inner resampling. Significantly lower predictive performances on the outer resampling indicate that the models with the optimized hyperparameters overfit the data.
+rr$score()[, .(iteration, task_id, learner_id, resampling_id, classif.ce)] iteration task_id learner_id resampling_id classif.ce
+1: 1 pima graph_learner.tuned cv 0.2265625
+2: 2 pima graph_learner.tuned cv 0.2382812
+3: 3 pima graph_learner.tuned cv 0.2656250The aggregated performance of all outer resampling iterations is essentially the unbiased performance of the graph learner with optimal hyperparameter found by random search.
+rr$aggregate()classif.ce
+ 0.2434896 Applying nested resampling can be shortened by using the tune_nested()-shortcut.
graph_learner = as_learner(graph)
+graph_learner$param_set$values$branch.selection =
+ to_tune(c("kknn", "svm", "ranger"))
+graph_learner$param_set$values$kknn.k =
+ to_tune(p_int(3, 50, logscale = TRUE, depends = branch.selection == "kknn"))
+graph_learner$param_set$values$svm.cost =
+ to_tune(p_dbl(-1, 1, trafo = function(x) 10^x, depends = branch.selection == "svm"))
+graph_learner$param_set$values$ranger.mtry =
+ to_tune(p_int(1, 8, depends = branch.selection == "ranger"))
+graph_learner$id = "graph_learner"
+
+rr = tune_nested(
+ tuner = tnr("random_search"),
+ task = task,
+ learner = graph_learner,
+ inner_resampling = rsmp("cv", folds = 3),
+ outer_resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+ term_evals = 10,
+)The mlr3book includes chapters on pipelines and hyperparameter tuning. The mlr3cheatsheets contain frequently used commands and workflows of mlr3.
+ + +Apply predefined search spaces from scientific articles.
+ +
+ Simultaneously optimize hyperparameters and use early stopping.
+ +
+ In this post, we use early stopping to reduce overfitting when training an XGBoost model. We start with a short recap on early stopping and overfitting. After that, we use the early stopping mechanism of XGBoost and train a model on the Spam Classification data set. Finally we show how to simultaneously tune hyperparameters and use early stopping. The reader should be familiar with tuning in the mlr3 ecosystem.
Early stopping is a technique used to reduce overfitting when fitting a model in an iterative process. Overfitting occurs when a model fits increasingly to the training data but the performance on unseen data decreases. This means the model’s training error decreases, while its test performance deteriorates. When using early stopping, the performance is monitored on a test set, and the training stops when performance decreases in a specific number of iterations.
+We initialize the random number generator with a fixed seed for reproducibility. The mlr3verse package provides all functions required for this example.
+set.seed(7832)
+
+library(mlr3verse)When training an XGBoost model, we can use early stopping to find the optimal number of boosting rounds. The partition() function splits the observations of the task into two disjoint sets. We use 80% of observations to train the model and the remaining 20% as the test set to monitor the performance.
task = tsk("spam")
+split = partition(task, ratio = 0.8)
+task$set_row_roles(split$test, "test")The early_stopping_set parameter controls which set is used to monitor the performance. Additionally, we need to define the range in which the performance must increase with early_stopping_rounds and the maximum number of boosting rounds with nrounds. In this example, the training is stopped when the classification error is not decreasing for 100 rounds or 1000 rounds are reached.
learner = lrn("classif.xgboost",
+ nrounds = 1000,
+ early_stopping_rounds = 100,
+ early_stopping_set = "test",
+ eval_metric = "error"
+)We train the learner with early stopping.
+learner$train(task)The $evaluation_log of the model stores the performance scores on the training and test set. Figure 1 shows that the classification error on the training set decreases, whereas the error on the test set increases after 20 rounds.
library(ggplot2)
+library(data.table)
+
+data = melt(
+ learner$model$evaluation_log,
+ id.vars = "iter",
+ variable.name = "set",
+ value.name = "error"
+)
+
+ggplot(data, aes(x = iter, y = error, group = set)) +
+ geom_line(aes(color = set)) +
+ geom_vline(aes(xintercept = learner$model$best_iteration), color = "grey") +
+ scale_colour_manual(values=c("#f8766d", "#00b0f6"), labels = c("Train", "Test")) +
+ labs(x = "Rounds", y = "Classification Error", color = "Set") +
+ theme_minimal()
The slot $best_iteration contains the optimal number of boosting rounds.
learner$model$best_iteration[1] 20Note that, learner$predict() will use the model from the last iteration, not the best one. See the next section on how to fit a model with the optimal number of boosting rounds and hyperparameter configuration.
In this section, we want to tune the hyperparameters of an XGBoost model and find the optimal number of boosting rounds in one go. For this, we need the early stopping callback which handles early stopping during the tuning process. The performance of a hyperparameter configuration is evaluated with a resampling strategy while tuning e.g. 3-fold cross-validation. In each resampling iteration, a new XGBoost model is trained and early stopping is used to find the optimal number of boosting rounds. This results in three different optimal numbers of boosting rounds for one hyperparameter configuration when applying 3-fold cross-validation. The callback picks the maximum of the three values and writes it to the archive. It uses the maximum value because the final model is fitted on the complete data set. Now let’s start with a practical example.
First, we load the XGBoost learner and set the early stopping parameters.
+learner = lrn("classif.xgboost",
+ nrounds = 1000,
+ early_stopping_rounds = 100,
+ early_stopping_set = "test"
+)Next, we load a predefined tuning space from the mlr3tuningspaces package. The tuning space includes the most commonly tuned parameters of XGBoost.
+tuning_space = lts("classif.xgboost.default")
+as.data.table(tuning_space) id lower upper logscale
+1: eta 1e-04 1 TRUE
+2: nrounds 1e+00 5000 FALSE
+3: max_depth 1e+00 20 FALSE
+4: colsample_bytree 1e-01 1 FALSE
+5: colsample_bylevel 1e-01 1 FALSE
+6: lambda 1e-03 1000 TRUE
+7: alpha 1e-03 1000 TRUE
+8: subsample 1e-01 1 FALSEWe argument the learner with the tuning space.
+learner = lts(learner)The default tuning space contains the nrounds hyperparameter. We have to overwrite it with an upper bound for early stopping.
learner$param_set$set_values(nrounds = 1000)We run a small batch of random hyperparameter configurations.
+instance = tune(
+ tuner = tnr("random_search", batch_size = 2),
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+ term_evals = 4,
+ callbacks = clbk("mlr3tuning.early_stopping")
+)We can see that the optimal number of boosting rounds (max_nrounds) strongly depends on the other hyperparameters.
as.data.table(instance$archive)[, list(batch_nr, max_nrounds, eta, max_depth, colsample_bytree, colsample_bylevel, lambda, alpha, subsample)] batch_nr max_nrounds eta max_depth colsample_bytree colsample_bylevel lambda alpha subsample
+1: 1 1000 -4.129996 13 0.5466492 0.3051989 -0.9448420 2.535477 0.5454539
+2: 1 998 -3.338899 8 0.6193478 0.7392354 -2.2338126 1.793921 0.2294161
+3: 2 1000 -6.059897 5 0.6118892 0.5445475 -6.5698270 5.414224 0.9635730
+4: 2 1000 -4.528129 1 0.1094186 0.2526143 -0.7535105 -3.041829 0.5934376In the best hyperparameter configuration, the value of nrounds is replaced by max_nrounds and early stopping is deactivated.
instance$result_learner_param_vals$nrounds
+[1] 998
+
+$nthread
+[1] 1
+
+$verbose
+[1] 0
+
+$early_stopping_set
+[1] "none"
+
+$eta
+[1] 0.03547598
+
+$max_depth
+[1] 8
+
+$colsample_bytree
+[1] 0.6193478
+
+$colsample_bylevel
+[1] 0.7392354
+
+$lambda
+[1] 0.1071192
+
+$alpha
+[1] 6.012984
+
+$subsample
+[1] 0.2294161Finally, fit the final model on the complete data set.
+learner = lrn("classif.xgboost")
+learner$param_set$values = instance$result_learner_param_vals
+learner$train(task)The trained model can now be used to make predictions on new data.
+We can also use the AutoTuner to get a tuned XGBoost model. Note that, early stopping is deactivated when the final model is fitted.
Optimize the hyperparameters of a classification tree with a few lines of code.
+
+
+ In this post, we optimize the hyperparameters of a simple classification tree on the Palmer Penguins data set with only a few lines of code.
First, we introduce tuning spaces and show the importance of transformation functions. Next, we execute the tuning and present the basic building blocks of tuning in mlr3. Finally, we fit a classification tree with optimized hyperparameters on the full data set.
+We load the mlr3verse package which pulls the most important packages for this example. Among other packages, it loads the hyperparameter optimization package of the mlr3 ecosystem mlr3tuning.
+library(mlr3verse)In this example, we use the Palmer Penguins data set which classifies 344 penguins in three species. The data set was collected from 3 islands in the Palmer Archipelago in Antarctica. It includes the name of the island, the size (flipper length, body mass, and bill dimension), and the sex of the penguin.
tsk("penguins")<TaskClassif:penguins> (344 x 8): Palmer Penguins
+* Target: species
+* Properties: multiclass
+* Features (7):
+ - int (3): body_mass, flipper_length, year
+ - dbl (2): bill_depth, bill_length
+ - fct (2): island, sexlibrary(palmerpenguins)
+library(ggplot2)
+ggplot(data = penguins, aes(x = flipper_length_mm, y = bill_length_mm)) +
+ geom_point(aes(color = species, shape = species), size = 3, alpha = 0.8) +
+ geom_smooth(method = "lm", se = FALSE, aes(color = species)) +
+ theme_minimal() +
+ scale_color_manual(values = c("darkorange","purple","cyan4")) +
+ labs(x = "Flipper length (mm)", y = "Bill length (mm)", color = "Penguin species", shape = "Penguin species") +
+ theme(
+ legend.position = c(0.85, 0.15),
+ legend.background = element_rect(fill = "white", color = NA),
+ text = element_text(size = 10))
We use the rpart classification tree. A learner stores all information about its hyperparameters in the slot $param_set. Not all parameters are tunable. We have to choose a subset of the hyperparameters we want to tune.
learner = lrn("classif.rpart")
+as.data.table(learner$param_set)[, list(id, class, lower, upper, nlevels)] id class lower upper nlevels
+ <char> <char> <num> <num> <num>
+ 1: cp ParamDbl 0 1 Inf
+ 2: keep_model ParamLgl NA NA 2
+ 3: maxcompete ParamInt 0 Inf Inf
+ 4: maxdepth ParamInt 1 30 30
+ 5: maxsurrogate ParamInt 0 Inf Inf
+ 6: minbucket ParamInt 1 Inf Inf
+ 7: minsplit ParamInt 1 Inf Inf
+ 8: surrogatestyle ParamInt 0 1 2
+ 9: usesurrogate ParamInt 0 2 3
+10: xval ParamInt 0 Inf InfThe package mlr3tuningspaces is a collection of search spaces for hyperparameter tuning from peer-reviewed articles. We use the search space from the Bischl et al. (2021) article.
+lts("classif.rpart.default")<TuningSpace:classif.rpart.default>: Classification Rpart with Default
+ id lower upper levels logscale
+ <char> <num> <num> <list> <lgcl>
+1: minsplit 2e+00 128.0 TRUE
+2: minbucket 1e+00 64.0 TRUE
+3: cp 1e-04 0.1 TRUEThe classification tree is mainly influenced by three hyperparameters:
+cp that controls when the learner considers introducing another branch.minsplit hyperparameter that controls how many observations must be present in a leaf for another split to be attempted.minbucket hyperparameter that the minimum number of observations in any terminal node.We argument the learner with the search space in one go.
+lts(lrn("classif.rpart"))<LearnerClassifRpart:classif.rpart>: Classification Tree
+* Model: -
+* Parameters: xval=0, minsplit=<RangeTuneToken>, minbucket=<RangeTuneToken>, cp=<RangeTuneToken>
+* Packages: mlr3, rpart
+* Predict Types: [response], prob
+* Feature Types: logical, integer, numeric, factor, ordered
+* Properties: importance, missings, multiclass, selected_features, twoclass, weightsThe column logscale indicates that the hyperparameters are tuned on the logarithmic scale. The tuning algorithm proposes hyperparameter values that are transformed with the exponential function before they are passed to the learner. For example, the cp parameter is bounded between 0 and 1. The tuning algorithm searches between log(1e-04) and log(1e-01) but the learner gets the transformed values between 1e-04 and 1e-01. Using the log transformation emphasizes smaller cp values but also creates large values.
lts("classif.rpart.default")<TuningSpace:classif.rpart.default>: Classification Rpart with Default
+ id lower upper levels logscale
+ <char> <num> <num> <list> <lgcl>
+1: minsplit 2e+00 128.0 TRUE
+2: minbucket 1e+00 64.0 TRUE
+3: cp 1e-04 0.1 TRUEThe tune() function controls and executes the tuning. The method sets the optimization algorithm. The mlr3 ecosystem offers various optimization algorithms e.g. Random Search, GenSA, and Hyperband. In this example, we will use a simple grid search with a grid resolution of 5. Our three-dimensional grid consists of \(5^3 = 125\) hyperparameter configurations. The resampling strategy and performance measure specify how the performance of a model is evaluated. We choose a 3-fold cross-validation and use the classification error.
instance = tune(
+ tuner = tnr("grid_search", resolution = 5),
+ task = tsk("penguins"),
+ learner = lts(lrn("classif.rpart")),
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce")
+)The tune() function returns a tuning instance that includes an archive with all evaluated hyperparameter configurations.
as.data.table(instance$archive)[, list(minsplit, minbucket, cp, classif.ce, resample_result)] minsplit minbucket cp classif.ce resample_result
+ <num> <num> <num> <num> <list>
+ 1: 2.7764798 2.087194 -2.302585 0.06107297 <ResampleResult[21]>
+ 2: 1.7348135 4.174387 -2.302585 0.18001526 <ResampleResult[21]>
+ 3: 0.6931472 1.043597 -9.210340 0.02906178 <ResampleResult[21]>
+ 4: 0.6931472 3.130790 -9.210340 0.06107297 <ResampleResult[21]>
+ 5: 2.7764798 3.130790 -4.029524 0.06107297 <ResampleResult[21]>
+ ---
+121: 3.8181461 0.000000 -5.756463 0.04065599 <ResampleResult[21]>
+122: 0.6931472 0.000000 -7.483402 0.02616323 <ResampleResult[21]>
+123: 0.6931472 3.130790 -2.302585 0.06107297 <ResampleResult[21]>
+124: 1.7348135 2.087194 -4.029524 0.04937707 <ResampleResult[21]>
+125: 3.8181461 0.000000 -2.302585 0.06107297 <ResampleResult[21]>The best configuration and the corresponding measured performance can be retrieved from the tuning instance.
+instance$result minsplit minbucket cp learner_param_vals x_domain classif.ce
+ <num> <num> <num> <list> <list> <num>
+1: 0.6931472 0 -9.21034 <list[4]> <list[3]> 0.02616323The $result_learner_param_vals field contains the best hyperparameter setting on the learner scale.
instance$result_learner_param_vals$xval
+[1] 0
+
+$minsplit
+[1] 2
+
+$minbucket
+[1] 1
+
+$cp
+[1] 1e-04The learner we use to make predictions on new data is called the final model. The final model is trained on the full data set. We add the optimized hyperparameters to the learner and train the learner on the full dataset.
+learner = lrn("classif.rpart")
+learner$param_set$values = instance$result_learner_param_vals
+learner$train(tsk("penguins"))The trained model can now be used to predict new, external data.
+ + + +Optimize the hyperparameters of an XGBoost model with Hyperband.
+
+ Resume the training of learners.
+
+ Hotstarting a learner resumes the training from an already fitted model. An example would be to train an already fit XGBoost model for an additional 500 boosting iterations. In mlr3, we call this process Hotstarting, where a learner has access to a cache of already trained models which is called a mlr3::HoststartStack We distinguish between forward and backward hotstarting. We start this post with backward hotstarting and then talk about the less efficient forward hotstarting.
In this example, we optimize the hyperparameters of a random forest and use hotstarting to reduce the runtime. Hotstarting a random forest backwards is very simple. The model remains unchanged and only a subset of the trees is used for prediction i.e. a new model is not fitted. For example, a random forest is trained with 1000 trees and a specific hyperparameter configuration. If another random forest with 500 trees but with the same hyperparameter configuration has to be trained, the model with 1000 trees is copied and only 500 trees are used for prediction.
+We load the ranger learner and set the search space from the Bischl et al. (2021) article.
library(mlr3verse)
+
+learner = lrn("classif.ranger",
+ mtry.ratio = to_tune(0, 1),
+ replace = to_tune(),
+ sample.fraction = to_tune(1e-1, 1),
+ num.trees = to_tune(1, 2000)
+)We activate hotstarting with the allow_hotstart option. When running a grid search with hotstarting, the grid is sorted by the hot start parameter. This means the models with 2000 trees are trained first. The models with less than 2000 trees hot start on the 2000 trees models which allows the training to be completed immediately.
instance = tune(
+ tuner = tnr("grid_search", resolution = 5, batch_size = 5),
+ task = tsk("spam"),
+ learner = learner,
+ resampling = rsmp("holdout"),
+ measure = msr("classif.ce"),
+ allow_hotstart = TRUE
+)For comparison, we perform the same tuning without hotstarting.
+instance_2 = tune(
+ tuner = tnr("grid_search", resolution = 5, batch_size = 5),
+ task = tsk("spam"),
+ learner = learner,
+ resampling = rsmp("holdout"),
+ measure = msr("classif.ce"),
+ allow_hotstart = FALSE
+)We plot the time of completion of each batch (see Figure 1). Each batch includes 5 configurations. We can see that tuning with hotstarting is slower at first. As soon as all models are fitted with 2000 trees, the tuning runs much faster and overtakes the tuning without hotstarting.
+ +
+Forward hotstarting is currently only supported by XGBoost. However, we have observed that hotstarting only provides a speed advantage for very large datasets and models with more than 5000 boosting rounds. The reason is that copying the models from the main process to the workers is a major bottleneck. The parallelization package future copies the models sequentially to the workers. Consequently, it takes a long time until the last worker can even start. Moreover, copying itself consumes a lot of time, and copying the model back from the worker blocks the main process again. During the development process, we overestimated the speed benefits of hotstarting and underestimated the overhead of parallelization. We can therefore only advise against using forward hotstarting during tuning. It is much more efficient to use the internal early-stopping mechanism of XGBoost. This eliminates the need to copy models to the worker. See the gallery post on early stopping for an example. We might improve the efficiency of the hotstarting mechanism in the future, if there are convincing use cases.
+Nevertheless, forward hotstarting can be useful without parallelization. If you have an already trained model and want to add more boosting iteration to it. In this example, the learner_5000 is the already trained model. We create a new learner with the same hyperparameters but double the number of boosting iteration. To activate hotstarting, we create a HotstartStack and copy it to the $hotstart_stack slot of the new learner.
task = tsk("spam")
+
+learner_5000 = lrn("classif.xgboost", nrounds = 5000, eta = 0.1)
+learner_5000$train(task)
+
+learner_10000 = lrn("classif.xgboost", nrounds = 10000, eta = 0.1)
+learner_10000$hotstart_stack = HotstartStack$new(learner_5000)
+learner_10000$train(task)Training the initial model took 59.885 seconds.
+learner_5000$state$train_time[1] 59.885Adding 5000 boosting rounds took 46.837 seconds.
+learner_10000$state$train_time - learner_5000$state$train_time[1] 46.837Training the model from the beginning would have taken about two minutes. This means, without parallelization, we get the expected speed advantage.
+We have seen how mlr3 enables to reduce the training time, by building on a hotstart stack of already trained learners. One has to be careful, however, when using forward hotstarting during tuning because of the high parallelization overhead that arises from copying the models between the processes. If a model has an internal early stopping implementation, it should usually be relied upon instead of using the mlr3 hotstarting mechanism. However, manual forward hotstarting can be helpful in some situations when we do not want to train a large model from the beginning.
+ + + +Optimize the hyperparameters of a Support Vector Machine with Hyperband.
+
+ We continue working with the Hyperband optimization algorithm (Li et al. 2018). The previous post used the number of boosting iterations of an XGBoost model as the resource. However, Hyperband is not limited to machine learning algorithms that are trained iteratively. The resource can also be the number of features, the training time of a model, or the size of the training data set. In this post, we will tune a support vector machine and use the size of the training data set as the fidelity parameter. The time to train a support vector machine and the performance increases with the size of the data set. This makes the data set size a suitable fidelity parameter for Hyperband. This is the second part of the Hyperband series. The first part can be found here Hyperband Series - Iterative Training. If you don’t know much about Hyperband, check out the first post which explains the algorithm in detail. We assume that you are already familiar with tuning in the mlr3 ecosystem. If not, you should start with the book chapter on optimization or the Hyperparameter Optimization on the Palmer Penguins Data Set post. A little knowledge about mlr3pipelines is beneficial but not necessary to understand the example.
+In this post, we will optimize the hyperparameters of the support vector machine on the Sonar data set. We begin by constructing a classification machine by setting type to "C-classification".
library("mlr3verse")
+
+learner = lrn("classif.svm", id = "svm", type = "C-classification")The mlr3pipelines package features a PipeOp for subsampling.
po("subsample")PipeOp: <subsample> (not trained)
+values: <frac=0.6321, stratify=FALSE, replace=FALSE>
+Input channels <name [train type, predict type]>:
+ input [Task,Task]
+Output channels <name [train type, predict type]>:
+ output [Task,Task]The PipeOp controls the size of the training data set with the frac parameter. We connect the PipeOp with the learner and get a GraphLearner.
graph_learner = as_learner(
+ po("subsample") %>>%
+ learner
+)The graph learner subsamples and then fits a support vector machine on the data subset. The parameter set of the graph learner is a combination of the parameter sets of the PipeOp and learner.
as.data.table(graph_learner$param_set)[, .(id, lower, upper, levels)] id lower upper levels
+ 1: subsample.frac 0 Inf
+ 2: subsample.stratify NA NA TRUE,FALSE
+ 3: subsample.replace NA NA TRUE,FALSE
+ 4: svm.cachesize -Inf Inf
+ 5: svm.class.weights NA NA
+---
+15: svm.nu -Inf Inf
+16: svm.scale NA NA
+17: svm.shrinking NA NA TRUE,FALSE
+18: svm.tolerance 0 Inf
+19: svm.type NA NA C-classification,nu-classificationNext, we create the search space. We use TuneToken to mark which hyperparameters should be tuned. We have to prefix the hyperparameters with the id of the PipeOps. The subsample.frac is the fidelity parameter that must be tagged with "budget" in the search space. The data set size is increased from 3.7% to 100%. For the other hyperparameters, we took the search space for support vector machines from the Kuehn et al. (2018) article. This search space works for a wide range of data sets.
graph_learner$param_set$set_values(
+ subsample.frac = to_tune(p_dbl(3^-3, 1, tags = "budget")),
+ svm.kernel = to_tune(c("linear", "polynomial", "radial")),
+ svm.cost = to_tune(1e-4, 1e3, logscale = TRUE),
+ svm.gamma = to_tune(1e-4, 1e3, logscale = TRUE),
+ svm.tolerance = to_tune(1e-4, 2, logscale = TRUE),
+ svm.degree = to_tune(2, 5)
+)Support vector machines often crash or never finish the training with certain hyperparameter configurations. We set a timeout of 30 seconds and a fallback learner to handle these cases.
+graph_learner$encapsulate = c(train = "evaluate", predict = "evaluate")
+graph_learner$timeout = c(train = 30, predict = 30)
+graph_learner$fallback = lrn("classif.featureless")Let’s create the tuning instance. We use the "none" terminator because Hyperband controls the termination itself.
instance = ti(
+ task = tsk("sonar"),
+ learner = graph_learner,
+ resampling = rsmp("cv", folds = 3),
+ measures = msr("classif.ce"),
+ terminator = trm("none")
+)
+instance<TuningInstanceSingleCrit>
+* State: Not optimized
+* Objective: <ObjectiveTuning:subsample.svm_on_sonar>
+* Search Space:
+ id class lower upper nlevels
+1: subsample.frac ParamDbl 0.03703704 1.0000000 Inf
+2: svm.cost ParamDbl -9.21034037 6.9077553 Inf
+3: svm.degree ParamInt 2.00000000 5.0000000 4
+4: svm.gamma ParamDbl -9.21034037 6.9077553 Inf
+5: svm.kernel ParamFct NA NA 3
+6: svm.tolerance ParamDbl -9.21034037 0.6931472 Inf
+* Terminator: <TerminatorNone>We load the Hyperband tuner and set eta = 3.
library("mlr3hyperband")
+
+tuner = tnr("hyperband", eta = 3)Using eta = 3 and a lower bound of 3.7% for the data set size, results in the following schedule. Configurations with the same data set size are evaluated in parallel.
Now we are ready to start the tuning.
+tuner$optimize(instance)The best model is a support vector machine with a polynomial kernel.
+instance$result[, .(subsample.frac, svm.cost, svm.degree, svm.gamma, svm.kernel, svm.tolerance, classif.ce)] subsample.frac svm.cost svm.degree svm.gamma svm.kernel svm.tolerance classif.ce
+1: 1 1.871535 3 -2.60663 polynomial -4.573951 0.1491373The archive contains all evaluated configurations. We look at the 8 configurations that were evaluated on the complete data set. The configuration with the best classification error on the full data set was sampled in bracket 2. The classification error was estimated to be 26% on 33% of the data set and increased to 19% on the full data set (see green line in Figure 1).
+ +
+Using the data set size as the budget parameter in Hyperband allows the tuning of machine learning models that are not trained iteratively. We have tried to keep the runtime of the example low. For your optimization, you should use cross-validation and run multiple iterations of Hyperband.
+Run the default hyperparameter configuration of learners as a baseline.
+
+ The predictive performance of modern machine learning algorithms is highly dependent on the choice of their hyperparameter configuration. Options for setting hyperparameters are tuning, manual selection by the user, and using the default configuration of the algorithm. The default configurations are chosen to work with a wide range of data sets but they usually do not achieve the best predictive performance. When tuning a learner in mlr3, we can run the default configuration as a baseline. Seeing how well it performs will tell us whether tuning pays off. If the optimized configurations perform worse, we could expand the search space or try a different optimization algorithm. Of course, it could also be that tuning on the given data set is simply not worth it.
+Probst, Boulesteix, and Bischl (2019) studied the tunability of machine learning algorithms. They found that the tunability of algorithms varies widely. Algorithms like glmnet and XGBoost are highly tunable, while algorithms like random forests work well with their default configuration. The highly tunable algorithms should thus beat their baselines more easily with optimized hyperparameters. In this article, we will tune the hyperparameters of a random forest and compare the performance of the default configuration with the optimized configurations.
+We tune the hyperparameters of the ranger learner on the spam data set. The search space is taken from Bischl et al. (2021).
library(mlr3verse)
+
+learner = lrn("classif.ranger",
+ mtry.ratio = to_tune(0, 1),
+ replace = to_tune(),
+ sample.fraction = to_tune(1e-1, 1),
+ num.trees = to_tune(1, 2000)
+)When creating the tuning instance, we set evaluate_default = TRUE to test the default hyperparameter configuration. The default configuration is evaluated in the first batch of the tuning run. The other batches use the specified tuning method. In this example, they are randomly drawn configurations.
instance = tune(
+ tuner = tnr("random_search", batch_size = 5),
+ task = tsk("spam"),
+ learner = learner,
+ resampling = rsmp ("holdout"),
+ measures = msr("classif.ce"),
+ term_evals = 51,
+ evaluate_default = TRUE
+)The default configuration is recorded in the first row of the archive. The other rows contain the results of the random search.
+as.data.table(instance$archive)[, .(batch_nr, mtry.ratio, replace, sample.fraction, num.trees, classif.ce)] batch_nr mtry.ratio replace sample.fraction num.trees classif.ce
+ 1: 1 0.122807018 TRUE 1.0000000 500 0.04954368
+ 2: 2 0.285388074 TRUE 0.1794772 204 0.06584094
+ 3: 2 0.097424099 FALSE 0.9475526 1441 0.04237288
+ 4: 2 0.008888587 FALSE 0.3216562 1868 0.08409387
+ 5: 2 0.335543330 TRUE 0.8122653 106 0.05345502
+---
+47: 11 0.788995735 FALSE 0.3692454 344 0.06258149
+48: 11 0.459305038 TRUE 0.3153485 1354 0.06258149
+49: 11 0.220334408 TRUE 0.9357554 817 0.05345502
+50: 11 0.868385877 TRUE 0.6743246 1040 0.06127771
+51: 11 0.015417312 FALSE 0.5627943 1836 0.08213820We plot the performances of the evaluated hyperparameter configurations. The blue line connects the best configuration of each batch. We see that the default configuration already performs well and the optimized configurations can not beat it.
+library(mlr3viz)
+
+autoplot(instance, type = "performance")
The time required to test the default configuration is negligible compared to the time required to run the hyperparameter optimization. It gives us a valuable indication of whether our tuning is properly configured. Running the default configuration as a baseline is a good practice that should be used in every tuning run.
+ + + +Run a feature selection with permutated features.
+
+ Feature selection is the process of finding an optimal set of features to improve the performance, interpretability and robustness of machine learning algorithms. In this article, we introduce the Shadow Variable Search algorithm which is a wrapper method for feature selection. Wrapper methods iteratively add features to the model that optimize a performance measure. As an example, we will search for the optimal set of features for a support vector machine on the Pima Indian Diabetes data set. We assume that you are already familiar with the basic building blocks of the mlr3 ecosystem. If you are new to feature selection, we recommend reading the feature selection chapter of the mlr3book first. Some knowledge about mlr3pipelines is beneficial but not necessary to understand the example.
Adding shadow variables to a data set is a well-known method in machine learning (Wu, Boos, and Stefanski 2007; Thomas et al. 2017). The idea is to add permutated copies of the original features to the data set. These permutated copies are called shadow variables or pseudovariables and the permutation breaks any relationship with the target variable, making them useless for prediction. The subsequent search is similar to the sequential forward selection algorithm, where one new feature is added in each iteration of the algorithm. This new feature is selected as the one that improves the performance of the model the most. This selection is computationally expensive, as one model for each of the not yet included features has to be trained. The difference between shadow variable search and sequential forward selection is that the former uses the selection of a shadow variable as the termination criterion. Selecting a shadow variable means that the best improvement is achieved by adding a feature that is unrelated to the target variable. Consequently, the variables not yet selected are most likely also correlated to the target variable only by chance. Therefore, only the previously selected features have a true influence on the target variable.
+mlr3fselect is the feature selection package of the mlr3 ecosystem. It implements the shadow variable search algorithm. We load all packages of the ecosystem with the mlr3verse package.
library(mlr3verse)We retrieve the shadow variable search optimizer with the fs() function. The algorithm has no control parameters.
optimizer = fs("shadow_variable_search")The objective of the Pima Indian Diabetes data set is to predict whether a person has diabetes or not. The data set includes 768 patients with 8 measurements (see Figure 1).
task = tsk("pima")library(ggplot2)
+library(data.table)
+
+data = melt(as.data.table(task), id.vars = task$target_names, measure.vars = task$feature_names)
+
+ggplot(data, aes(x = value, fill = diabetes)) +
+ geom_density(alpha = 0.5) +
+ facet_wrap(~ variable, ncol = 8, scales = "free") +
+ scale_fill_viridis_d(end = 0.8) +
+ theme_minimal() +
+ theme(axis.title.x = element_blank()) +
+The data set contains missing values.
+task$missings()diabetes age glucose insulin mass pedigree pregnant pressure triceps
+ 0 0 5 374 11 0 0 35 227 Support vector machines cannot handle missing values. We impute the missing values with the histogram imputation method.
learner = po("imputehist") %>>% lrn("classif.svm", predict_type = "prob")Now we define the feature selection problem by using the fsi() function that constructs an FSelectInstanceSingleCrit. In addition to the task and learner, we have to select a resampling strategy and performance measure to determine how the performance of a feature subset is evaluated. We pass the "none" terminator because the shadow variable search algorithm terminates by itself.
instance = fsi(
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 3),
+ measures = msr("classif.auc"),
+ terminator = trm("none")
+)We are now ready to start the shadow variable search. To do this, we simply pass the instance to the $optimize() method of the optimizer.
optimizer$optimize(instance) age glucose insulin mass pedigree pregnant pressure triceps features classif.auc
+1: TRUE TRUE FALSE TRUE TRUE FALSE FALSE FALSE age,glucose,mass,pedigree 0.835165The optimizer returns the best feature set and the corresponding estimated performance.
+Figure 2 shows the optimization path of the feature selection. The feature glucose was selected first and in the following iterations age, mass and pedigree. Then a shadow variable was selected and the feature selection was terminated.
+library(data.table)
+library(ggplot2)
+library(mlr3misc)
+library(viridisLite)
+
+data = as.data.table(instance$archive)[order(-classif.auc), head(.SD, 1), by = batch_nr][order(batch_nr)]
+data[, features := map_chr(features, str_collapse)]
+data[, batch_nr := as.character(batch_nr)]
+
+ggplot(data, aes(x = batch_nr, y = classif.auc)) +
+ geom_bar(
+ stat = "identity",
+ width = 0.5,
+ fill = viridis(1, begin = 0.5),
+ alpha = 0.8) +
+ geom_text(
+ data = data,
+ mapping = aes(x = batch_nr, y = 0, label = features),
+ hjust = 0,
+ nudge_y = 0.05,
+ color = "white",
+ size = 5
+ ) +
+ coord_flip() +
+ xlab("Iteration") +
+ theme_minimal() +
+The archive contains all evaluated feature sets. We can see that each feature has a corresponding shadow variable. We only show the variables age, glucose and insulin and their shadow variables here.
+as.data.table(instance$archive)[, .(age, glucose, insulin, permuted__age, permuted__glucose, permuted__insulin, classif.auc)] age glucose insulin permuted__age permuted__glucose permuted__insulin classif.auc
+ 1: TRUE FALSE FALSE FALSE FALSE FALSE 0.6437052
+ 2: FALSE TRUE FALSE FALSE FALSE FALSE 0.7598155
+ 3: FALSE FALSE TRUE FALSE FALSE FALSE 0.4900280
+ 4: FALSE FALSE FALSE FALSE FALSE FALSE 0.6424026
+ 5: FALSE FALSE FALSE FALSE FALSE FALSE 0.5690107
+---
+54: TRUE TRUE FALSE FALSE FALSE FALSE 0.8266713
+55: TRUE TRUE FALSE FALSE FALSE FALSE 0.8063568
+56: TRUE TRUE FALSE FALSE FALSE FALSE 0.8244232
+57: TRUE TRUE FALSE FALSE FALSE FALSE 0.8234605
+58: TRUE TRUE FALSE FALSE FALSE FALSE 0.8164784The learner we use to make predictions on new data is called the final model. The final model is trained with the optimal feature set on the full data set. We subset the task to the optimal feature set and train the learner.
+task$select(instance$result_feature_set)
+learner$train(task)The trained model can now be used to predict new, external data.
+The shadow variable search is a fast feature selection method that is easy to use. More information on the theoretical background can be found in Wu, Boos, and Stefanski (2007) and Thomas et al. (2017). If you want to know more about feature selection in general, we recommend having a look at our book.
+ + + +Utilize the built-in feature importance of models.
+
+ Feature selection is the process of finding an optimal subset of features in order to improve the performance, interpretability and robustness of machine learning algorithms. In this article, we introduce the wrapper feature selection method Recursive Feature Elimination. Wrapper methods iteratively select features that optimize a performance measure. As an example, we will search for the optimal set of features for a gradient boosting machine and support vector machine on the Sonar data set. We assume that you are already familiar with the basic building blocks of the mlr3 ecosystem. If you are new to feature selection, we recommend reading the feature selection chapter of the mlr3book first.
Recursive Feature Elimination (RFE) is a widely used feature selection method for high-dimensional data sets. The idea is to iteratively remove the least predictive feature from a model until the desired number of features is reached. This feature is determined by the built-in feature importance method of the model. Currently, RFE works with support vector machines (SVM), decision tree algorithms and gradient boosting machines (GBM). Supported learners are tagged with the "importance" property. For a full list of supported learners, see the learner page on the mlr-org website and search for "importance".
Guyon et al. (2002) developed the RFE algorithm for SVMs (SVM-RFE) to select informative genes in cancer classification. The importance of the features is given by the weight vector of a linear support vector machine. This method was later extended to other machine learning algorithms. The only requirement is that the models can internally measure the feature importance. The random forest algorithm offers multiple options for measuring feature importance. The commonly used methods are the mean decrease in accuracy (MDA) and the mean decrease in impurity (MDI). The MDA measures the decrease in accuracy for a feature if it was randomly permuted in the out-of-bag sample. The MDI is the total reduction in node impurity when the feature is used for splitting. Gradient boosting algorithms like XGBoost, LightGBM and GBM use similar methods to measure the importance of the features.
Resampling strategies can be combined with the algorithm in different ways. The frameworks scikit-learn (Pedregosa et al. 2011) and caret (Kuhn 2008) implement a variant called recursive feature elimination with cross-validation (RFE-CV) that estimates the optimal number of features with cross-validation first. Then one more RFE is carried out on the complete dataset with the optimal number of features as the final feature set size. The RFE implementation in mlr3 can rank and aggregate importance scores across resampling iterations. We will explore both variants in more detail below.
+mlr3fselect is the feature selection package of the mlr3 ecosystem. It implements the RFE and RFE-CV algorithm. We load all packages of the ecosystem with the mlr3verse package.
library(mlr3verse)We retrieve the RFE optimizer with the fs() function.
optimizer = fs("rfe",
+ n_features = 1,
+ feature_number = 1,
+ aggregation = "rank")The algorithm has multiple control parameters. The optimizer stops when the number of features equals n_features. The parameters feature_number, feature_fraction and subset_size determine the number of features that are removed in each iteration. The feature_number option removes a fixed number of features in each iteration, whereas feature_fraction removes a fraction of the features. The subset_size argument is a vector that specifies exactly how many features are removed in each iteration. The parameters are mutually exclusive and the default is feature_fraction = 0.5. Usually, RFE fits a new model in each resampling iteration and calculates the feature importance again. We can deactivate this behavior by setting recursive = FALSE. The selection of feature subsets in all iterations is then based solely on the importance scores of the first model trained with all features. When running an RFE with a resampling strategy like cross-validation, multiple models and importance scores are generated. The aggregation parameter determines how the importance scores are aggregated. The option "rank" ranks the importance scores in each iteration and then averages the ranks of the features. The feature with the lowest average rank is removed. The option "mean" averages the importance scores of the features across the iterations. The "mean" should only be used if the learner’s importance scores can be reasonably averaged.
The objective of the Sonar data set is to predict whether a sonar signal bounced off a metal cylinder or a rock. The data set includes 60 numerical features (see Figure 1).
task = tsk("sonar")library(ggplot2)
+library(data.table)
+
+data = melt(as.data.table(task), id.vars = task$target_names, measure.vars = task$feature_names)
+data = data[c("V1", "V10", "V11", "V12", "V13", "V14"), , on = "variable"]
+
+ggplot(data, aes(x = value, fill = Class)) +
+ geom_density(alpha = 0.5) +
+ facet_wrap(~ variable, ncol = 6, scales = "free") +
+ scale_fill_viridis_d(end = 0.8) +
+ theme_minimal() +
+ theme(axis.title.x = element_blank())We start with the GBM learner and set the predict type to "prob" to obtain class probabilities.
learner = lrn("classif.gbm",
+ distribution = "bernoulli",
+ predict_type = "prob")Now we define the feature selection problem by using the fsi() function that constructs an FSelectInstanceSingleCrit. In addition to the task and learner, we have to select a resampling strategy and performance measure to determine how the performance of a feature subset is evaluated. We pass the "none" terminator because the n_features parameter of the optimizer determines when the feature selection stops.
instance = fsi(
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 6),
+ measures = msr("classif.auc"),
+ terminator = trm("none"))We are now ready to start the RFE. To do this, we simply pass the instance to the $optimize() method of the optimizer.
optimizer$optimize(instance)The optimizer saves the best feature set and the corresponding estimated performance in instance$result.
Figure 2 shows the optimization path of the feature selection. We observe that the performance increases first as the number of features decreases. As soon as informative features are removed, the performance drops.
+library(viridisLite)
+library(mlr3misc)
+
+data = as.data.table(instance$archive)
+data[, n:= map_int(importance, length)]
+
+ggplot(data, aes(x = n, y = classif.auc)) +
+ geom_line(
+ color = viridis(1, begin = 0.5),
+ linewidth = 1) +
+ geom_point(
+ fill = viridis(1, begin = 0.5),
+ shape = 21,
+ size = 3,
+ stroke = 0.5,
+ alpha = 0.8) +
+ xlab("Number of Features") +
+ scale_x_reverse() +
+ theme_minimal() +
+The importance scores of the feature sets are recorded in the archive.
+as.data.table(instance$archive)[, list(features, classif.auc, importance)] features classif.auc importance
+ 1: V1,V10,V11,V12,V13,V14,... 0.8929304 58.83333,58.83333,54.50000,54.00000,53.33333,52.50000,...
+ 2: V1,V10,V11,V12,V13,V15,... 0.9177811 57.33333,56.00000,54.00000,53.66667,50.50000,50.00000,...
+ 3: V1,V10,V11,V12,V13,V15,... 0.9045253 54.83333,54.66667,54.66667,53.00000,51.83333,51.33333,...
+ 4: V1,V10,V11,V12,V13,V15,... 0.8927833 56.00000,55.83333,53.00000,52.00000,50.16667,50.00000,...
+ 5: V1,V10,V11,V12,V13,V15,... 0.9016274 55.50000,53.50000,51.33333,50.00000,49.00000,48.50000,...
+---
+56: V11,V12,V16,V48,V9 0.8311625 4.166667,3.333333,2.833333,2.500000,2.166667
+57: V11,V12,V16,V9 0.8216772 3.833333,2.666667,2.000000,1.500000
+58: V11,V12,V16 0.8065807 2.833333,1.833333,1.333333
+59: V11,V12 0.8023780 1.833333,1.166667
+60: V11 0.7515904 1Now we will select the optimal feature set for an SVM with a linear kernel. The importance scores are the weights of the model.
+learner = lrn("classif.svm",
+ type = "C-classification",
+ kernel = "linear",
+ predict_type = "prob")The SVM learner does not support the calculation of importance scores at first. The reason is that importance scores cannot be determined with all kernels. This can be seen by the missing "importance" property.
learner$properties[1] "multiclass" "twoclass" Using the "mlr3fselect.svm_rfe" callback however makes it possible to use a linear SVM with the RFE optimizer. The callback adds the $importance() method internally to the learner. We load the callback with the clbk() function and pass it as the "callback" argument to fsi().
instance = fsi(
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 6),
+ measures = msr("classif.auc"),
+ terminator = trm("none"),
+ callback = clbk("mlr3fselect.svm_rfe"))We start the feature selection.
+optimizer$optimize(instance)Figure 3 shows the average performance of the SVMs depending on the number of features. We can see that the performance increases significantly with a reduced feature set.
+library(viridisLite)
+library(mlr3misc)
+
+data = as.data.table(instance$archive)
+data[, n:= map_int(importance, length)]
+
+ggplot(data, aes(x = n, y = classif.auc)) +
+ geom_line(
+ color = viridis(1, begin = 0.5),
+ linewidth = 1) +
+ geom_point(
+ fill = viridis(1, begin = 0.5),
+ shape = 21,
+ size = 3,
+ stroke = 0.5,
+ alpha = 0.8) +
+ xlab("Number of Features") +
+ scale_x_reverse() +
+ theme_minimal() +
+For datasets with a lot of features, it is more efficient to remove several features per iteration. We show an example where 25% of the features are removed in each iteration.
+optimizer = fs("rfe", n_features = 1, feature_fraction = 0.75)
+
+instance = fsi(
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 6),
+ measures = msr("classif.auc"),
+ terminator = trm("none"),
+ callback = clbk("mlr3fselect.svm_rfe"))
+
+optimizer$optimize(instance)Figure 4 shows a similar optimization curve as Figure 3 but with fewer evaluated feature sets.
+library(viridisLite)
+library(mlr3misc)
+
+data = as.data.table(instance$archive)
+data[, n:= map_int(importance, length)]
+
+ggplot(data, aes(x = n, y = classif.auc)) +
+ geom_line(
+ color = viridis(1, begin = 0.5),
+ linewidth = 1) +
+ geom_point(
+ fill = viridis(1, begin = 0.5),
+ shape = 21,
+ size = 3,
+ stroke = 0.5,
+ alpha = 0.8) +
+ xlab("Number of Features") +
+ scale_x_reverse() +
+ theme_minimal() +
+RFE-CV estimates the optimal number of features before selecting a feature set. For this, an RFE is run in each resampling iteration and the number of features with the best mean performance is selected (see Figure 5). Then one more RFE is carried out on the complete dataset with the optimal number of features as the final feature set size.
+%%{ init: { 'flowchart': { 'curve': 'bump' } } }%%
+flowchart TB
+ cross-validation[3-Fold Cross-Validation]
+ cross-validation-->rfe-1
+ cross-validation-->rfe-2
+ cross-validation-->rfe-3
+ subgraph rfe-1[RFE 1]
+ direction TB
+ f14[4 Features]
+ f13[3 Features]
+ f12[2 Features]
+ f11[1 Features]
+ f14-->f13-->f12-->f11
+ style f13 fill:#ccea84
+ end
+ subgraph rfe-2[RFE 2]
+ direction TB
+ f24[4 Features]
+ f23[3 Features]
+ f22[2 Features]
+ f21[1 Features]
+ f24-->f23-->f22-->f21
+ style f23 fill:#ccea84
+ end
+ subgraph rfe-3[RFE 3]
+ direction TB
+ f34[4 Features]
+ f33[3 Features]
+ f32[2 Features]
+ f31[1 Features]
+ f34-->f33-->f32-->f31
+ style f33 fill:#ccea84
+ end
+ all_obs[All Observations]
+ rfe-1-->all_obs
+ rfe-2-->all_obs
+ rfe-3-->all_obs
+ all_obs --> rfe
+ subgraph rfe[RFE]
+ direction TB
+ f54[4 Features]
+ f53[3 Features]
+ f54-->f53
+ style f53 fill:#8e6698
+ end
+
+We retrieve the RFE-CV optimizer. RFE-CV has almost the same control parameters as the RFE optimizer. The only difference is that no aggregation is needed.
optimizer = fs("rfecv",
+ n_features = 1,
+ feature_number = 1)The chosen resampling strategy is used to estimate the optimal number of features. The 6-fold cross-validation results in 6 RFE runs. You can choose any other resampling strategy with multiple iterations. Let’s start the feature selection.
+learner = lrn("classif.svm",
+ type = "C-classification",
+ kernel = "linear",
+ predict_type = "prob")
+
+instance = fsi(
+ task = task,
+ learner = learner,
+ resampling = rsmp("cv", folds = 6),
+ measures = msr("classif.auc"),
+ terminator = trm("none"),
+ callback = clbk("mlr3fselect.svm_rfe"))
+
+optimizer$optimize(instance)The performance of the optimal feature set is calculated on the complete data set and should not be reported as the performance of the final model. Estimate the performance of the final model with nested resampling.
+We visualize the selection of the optimal number of features. Each point is the mean performance of the number of features. We achieved the best performance with 19 features.
+library(ggplot2)
+library(viridisLite)
+library(mlr3misc)
+
+data = as.data.table(instance$archive)[!is.na(iteration), ]
+aggr = data[, list("y" = mean(unlist(.SD))), by = "batch_nr", .SDcols = "classif.auc"]
+aggr[, batch_nr := 61 - batch_nr]
+
+data[, n:= map_int(importance, length)]
+
+ggplot(aggr, aes(x = batch_nr, y = y)) +
+ geom_line(
+ color = viridis(1, begin = 0.5),
+ linewidth = 1) +
+ geom_point(
+ fill = viridis(1, begin = 0.5),
+ shape = 21,
+ size = 3,
+ stroke = 0.5,
+ alpha = 0.8) +
+ geom_vline(
+ xintercept = aggr[y == max(y)]$batch_nr,
+ colour = viridis(1, begin = 0.33),
+ linetype = 3
+ ) +
+ xlab("Number of Features") +
+ ylab("Mean AUC") +
+ scale_x_reverse() +
+ theme_minimal() +
+The archive contains the extra column "iteration" that indicates in which resampling iteration the feature set was evaluated. The feature subsets of the final RFE run have no value in the "iteration" column because they were evaluated on the complete data set.
as.data.table(instance$archive)[, list(features, classif.auc, iteration, importance)] features classif.auc iteration importance
+ 1: V1,V10,V11,V12,V13,V14,... 0.8782895 1 2.864018,1.532774,1.408485,1.399930,1.326165,1.167745,...
+ 2: V1,V10,V11,V12,V13,V14,... 0.7026144 2 2.056442,1.706077,1.258703,1.191762,1.190752,1.178514,...
+ 3: V1,V10,V11,V12,V13,V14,... 0.8790850 3 1.950412,1.887710,1.820891,1.616219,1.231928,1.138675,...
+ 4: V1,V10,V11,V12,V13,V14,... 0.8125000 4 2.6958580,1.5623759,1.4990138,1.3902109,0.9385757,0.9232132,...
+ 5: V1,V10,V11,V12,V13,V14,... 0.8807018 5 2.487483,1.470778,1.356517,1.033764,0.635383,0.575074,...
+ ---
+398: V1,V11,V12,V16,V23,V3,... 0.9605275 NA 2.0089739,1.1047492,1.0011253,0.6602411,0.6015470,0.5431803,...
+399: V1,V12,V16,V23,V3,V30,... 0.9595988 NA 1.8337471,1.1937962,0.9853467,0.7751384,0.7296726,0.6222569,...
+400: V1,V12,V16,V23,V3,V30,... 0.9589486 NA 1.8824952,1.2468164,1.0106654,0.8090618,0.6983925,0.6568389,...
+401: V1,V12,V16,V23,V3,V30,... 0.9559766 NA 2.3872902,0.9094028,0.8809098,0.8277941,0.7841591,0.7792772,...
+402: V1,V12,V16,V23,V3,V30,... 0.9521687 NA 1.9485133,1.1482257,1.1098823,0.9591012,0.8234140,0.8118616,...The learner we use to make predictions on new data is called the final model. The final model is trained with the optimal feature set on the full data set. The optimal set consists of 19 features and is stored in instance$result_feature_set. We subset the task to the optimal feature set and train the learner.
task$select(instance$result_feature_set)
+learner$train(task)The trained model can now be used to predict new, external data.
+The RFE algorithm is a valuable feature selection method, especially for high-dimensional datasets with only a few observations. The numerous settings of the algorithm in mlr3 make it possible to apply it to many datasets and learners. If you want to know more about feature selection in general, we recommend having a look at our book.
+ + + +This use case shows how to tune over multiple learners for a single task. You will learn the following:
+This is an advanced use case. What should you know before:
+AutoTunerAssume, you are given some ML task and what to compare a couple of learners, probably because you want to select the best of them at the end of the analysis. That’s a super standard scenario, it actually sounds so common that you might wonder: Why an (advanced) blog post about this? With pipelines? We will consider 2 cases: (a) Running the learners in their default, so without tuning, and (b) with tuning.
+We load the mlr3verse package which pulls in the most important packages for this example. The mlr3learners package loads additional learners.
library(mlr3verse)
+library(mlr3tuning)
+library(mlr3learners)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")Let’s define our learners.
+learners = list(
+ lrn("classif.xgboost", id = "xgb", eval_metric = "logloss"),
+ lrn("classif.ranger", id = "rf")
+)
+learners_ids = sapply(learners, function(x) x$id)
+
+task = tsk("sonar") # some random data for this demo
+inner_cv2 = rsmp("cv", folds = 2) # inner loop for nested CV
+outer_cv5 = rsmp("cv", folds = 5) # outer loop for nested CVAssume we don’t want to perform tuning and or with running all learner in their respective defaults. Simply run benchmark on the learners and the tasks. That tabulates our results nicely and shows us what works best.
+grid = benchmark_grid(task, learners, outer_cv5)
+bmr = benchmark(grid)
+bmr$aggregate(measures = msr("classif.ce")) nr task_id learner_id resampling_id iters classif.ce
+1: 1 sonar xgb cv 5 0.2736353
+2: 2 sonar rf cv 5 0.1973287
+Hidden columns: resample_resultOk, why would we ever want to change the simple approach above - and use pipelines / tuning for this? Three reasons:
+benchmark() is actually statistically flawed, insofar if we report the error of the numerically best method from the benchmark table as its estimated future performance. If we do that we have “optimized on the CV” (we basically ran a grid search over our learners!) and we know that this is will produce optimistically biased results. NB: This is a somewhat ridiculous criticism if we are going over only a handful of options, and the bias will be very small. But it will be noticeable if we do this over hundreds of learners, so it is important to understand the underlying problem. This is a somewhat subtle point, and this gallery post is more about technical hints for mlr3, so we will stop this discussion here.The pipeline just has a single purpose in this example: It should allow us to switch between different learners, depending on a hyperparameter. The pipe consists of three elements:
+branch pipes incoming data to one of the following elements, on different data channels. We can name these channel on construction with options.gunion())unbranch combines the forked paths at the end.graph =
+ po("branch", options = learners_ids) %>>%
+ gunion(lapply(learners, po)) %>>%
+ po("unbranch")
+plot(graph, html = FALSE)
The pipeline has now quite a lot of available hyperparameters. It includes all hyperparameters from all contained learners. But as we don’t tune them here (yet), we don’t care (yet). But the first hyperparameter is special. branch.selection controls over which (named) branching channel our data flows.
graph$param_set$ids() [1] "branch.selection" "xgb.alpha" "xgb.approxcontrib"
+ [4] "xgb.base_score" "xgb.booster" "xgb.callbacks"
+ [7] "xgb.colsample_bylevel" "xgb.colsample_bynode" "xgb.colsample_bytree"
+[10] "xgb.disable_default_eval_metric" "xgb.early_stopping_rounds" "xgb.early_stopping_set"
+[13] "xgb.eta" "xgb.eval_metric" "xgb.feature_selector"
+[16] "xgb.feval" "xgb.gamma" "xgb.grow_policy"
+[19] "xgb.interaction_constraints" "xgb.iterationrange" "xgb.lambda"
+[22] "xgb.lambda_bias" "xgb.max_bin" "xgb.max_delta_step"
+[25] "xgb.max_depth" "xgb.max_leaves" "xgb.maximize"
+[28] "xgb.min_child_weight" "xgb.missing" "xgb.monotone_constraints"
+[31] "xgb.normalize_type" "xgb.nrounds" "xgb.nthread"
+[34] "xgb.ntreelimit" "xgb.num_parallel_tree" "xgb.objective"
+[37] "xgb.one_drop" "xgb.outputmargin" "xgb.predcontrib"
+[40] "xgb.predictor" "xgb.predinteraction" "xgb.predleaf"
+[43] "xgb.print_every_n" "xgb.process_type" "xgb.rate_drop"
+[46] "xgb.refresh_leaf" "xgb.reshape" "xgb.seed_per_iteration"
+[49] "xgb.sampling_method" "xgb.sample_type" "xgb.save_name"
+[52] "xgb.save_period" "xgb.scale_pos_weight" "xgb.skip_drop"
+[55] "xgb.strict_shape" "xgb.subsample" "xgb.top_k"
+[58] "xgb.training" "xgb.tree_method" "xgb.tweedie_variance_power"
+[61] "xgb.updater" "xgb.verbose" "xgb.watchlist"
+[64] "xgb.xgb_model" "rf.alpha" "rf.always.split.variables"
+[67] "rf.class.weights" "rf.holdout" "rf.importance"
+[70] "rf.keep.inbag" "rf.max.depth" "rf.min.node.size"
+[73] "rf.min.prop" "rf.minprop" "rf.mtry"
+[76] "rf.mtry.ratio" "rf.num.random.splits" "rf.num.threads"
+[79] "rf.num.trees" "rf.oob.error" "rf.regularization.factor"
+[82] "rf.regularization.usedepth" "rf.replace" "rf.respect.unordered.factors"
+[85] "rf.sample.fraction" "rf.save.memory" "rf.scale.permutation.importance"
+[88] "rf.se.method" "rf.seed" "rf.split.select.weights"
+[91] "rf.splitrule" "rf.verbose" "rf.write.forest" graph$param_set$params$branch.selection id class lower upper levels default
+1: branch.selection ParamFct NA NA xgb,rf <NoDefault[3]>We can now tune over this pipeline, and probably running grid search seems a good idea to “touch” every available learner. NB: We have now written down in (much more complicated code) what we did before with benchmark.
graph_learner = as_learner(graph)
+graph_learner$id = "g"
+
+search_space = ps(
+ branch.selection = p_fct(c("rf", "xgb"))
+)
+
+instance = tune(
+ tuner = tnr("grid_search"),
+ task = task,
+ learner = graph_learner,
+ resampling = inner_cv2,
+ measure = msr("classif.ce"),
+ search_space = search_space
+)
+
+as.data.table(instance$archive)[, list(branch.selection, classif.ce)] branch.selection classif.ce
+1: rf 0.1778846
+2: xgb 0.3269231But: Via this approach we can now get unbiased performance results via nested resampling and using the AutoTuner (which would make much more sense if we would select from 100 models and not 2).
at = auto_tuner(
+ tuner = tnr("grid_search"),
+ learner = graph_learner,
+ resampling = inner_cv2,
+ measure = msr("classif.ce"),
+ search_space = search_space
+)
+
+rr = resample(task, at, outer_cv5, store_models = TRUE)Access inner tuning result.
+extract_inner_tuning_results(rr)[, list(iteration, branch.selection, classif.ce)] iteration branch.selection classif.ce
+1: 1 rf 0.2349398
+2: 2 rf 0.1626506
+3: 3 rf 0.3012048
+4: 4 rf 0.2813396
+5: 5 rf 0.2932444Access inner tuning archives.
+extract_inner_tuning_archives(rr)[, list(iteration, branch.selection, classif.ce, resample_result)] iteration branch.selection classif.ce resample_result
+ 1: 1 rf 0.2349398 <ResampleResult[21]>
+ 2: 1 xgb 0.2469880 <ResampleResult[21]>
+ 3: 2 rf 0.1626506 <ResampleResult[21]>
+ 4: 2 xgb 0.2530120 <ResampleResult[21]>
+ 5: 3 xgb 0.3795181 <ResampleResult[21]>
+ 6: 3 rf 0.3012048 <ResampleResult[21]>
+ 7: 4 xgb 0.3714859 <ResampleResult[21]>
+ 8: 4 rf 0.2813396 <ResampleResult[21]>
+ 9: 5 xgb 0.3353414 <ResampleResult[21]>
+10: 5 rf 0.2932444 <ResampleResult[21]>Now let’s select from our given set of models and tune their hyperparameters. One way to do this is to define a search space for each individual learner, wrap them all with the AutoTuner, then call benchmark() on them. As this is pretty standard, we will skip this here, and show an even neater option, where you can tune over models and hyperparameters in one go. If you have quite a large space of potential learners and combine this with an efficient tuning algorithm, this can save quite some time in tuning as you can learn during optimization which options work best and focus on them. NB: Many AutoML systems work in a very similar way.
Remember, that the pipeline contains a joint set of all contained hyperparameters. Prefixed with the respective PipeOp ID, to make names unique.
+as.data.table(graph$param_set)[, list(id, class, lower, upper, nlevels)] id class lower upper nlevels
+ 1: branch.selection ParamFct NA NA 2
+ 2: xgb.alpha ParamDbl 0 Inf Inf
+ 3: xgb.approxcontrib ParamLgl NA NA 2
+ 4: xgb.base_score ParamDbl -Inf Inf Inf
+ 5: xgb.booster ParamFct NA NA 3
+ 6: xgb.callbacks ParamUty NA NA Inf
+ 7: xgb.colsample_bylevel ParamDbl 0 1 Inf
+ 8: xgb.colsample_bynode ParamDbl 0 1 Inf
+ 9: xgb.colsample_bytree ParamDbl 0 1 Inf
+10: xgb.disable_default_eval_metric ParamLgl NA NA 2
+11: xgb.early_stopping_rounds ParamInt 1 Inf Inf
+12: xgb.early_stopping_set ParamFct NA NA 3
+13: xgb.eta ParamDbl 0 1 Inf
+14: xgb.eval_metric ParamUty NA NA Inf
+15: xgb.feature_selector ParamFct NA NA 5
+16: xgb.feval ParamUty NA NA Inf
+17: xgb.gamma ParamDbl 0 Inf Inf
+18: xgb.grow_policy ParamFct NA NA 2
+19: xgb.interaction_constraints ParamUty NA NA Inf
+20: xgb.iterationrange ParamUty NA NA Inf
+21: xgb.lambda ParamDbl 0 Inf Inf
+22: xgb.lambda_bias ParamDbl 0 Inf Inf
+23: xgb.max_bin ParamInt 2 Inf Inf
+24: xgb.max_delta_step ParamDbl 0 Inf Inf
+25: xgb.max_depth ParamInt 0 Inf Inf
+26: xgb.max_leaves ParamInt 0 Inf Inf
+27: xgb.maximize ParamLgl NA NA 2
+28: xgb.min_child_weight ParamDbl 0 Inf Inf
+29: xgb.missing ParamDbl -Inf Inf Inf
+30: xgb.monotone_constraints ParamUty NA NA Inf
+31: xgb.normalize_type ParamFct NA NA 2
+32: xgb.nrounds ParamInt 1 Inf Inf
+33: xgb.nthread ParamInt 1 Inf Inf
+34: xgb.ntreelimit ParamInt 1 Inf Inf
+35: xgb.num_parallel_tree ParamInt 1 Inf Inf
+36: xgb.objective ParamUty NA NA Inf
+37: xgb.one_drop ParamLgl NA NA 2
+38: xgb.outputmargin ParamLgl NA NA 2
+39: xgb.predcontrib ParamLgl NA NA 2
+40: xgb.predictor ParamFct NA NA 2
+41: xgb.predinteraction ParamLgl NA NA 2
+42: xgb.predleaf ParamLgl NA NA 2
+43: xgb.print_every_n ParamInt 1 Inf Inf
+44: xgb.process_type ParamFct NA NA 2
+45: xgb.rate_drop ParamDbl 0 1 Inf
+46: xgb.refresh_leaf ParamLgl NA NA 2
+47: xgb.reshape ParamLgl NA NA 2
+48: xgb.seed_per_iteration ParamLgl NA NA 2
+49: xgb.sampling_method ParamFct NA NA 2
+50: xgb.sample_type ParamFct NA NA 2
+51: xgb.save_name ParamUty NA NA Inf
+52: xgb.save_period ParamInt 0 Inf Inf
+53: xgb.scale_pos_weight ParamDbl -Inf Inf Inf
+54: xgb.skip_drop ParamDbl 0 1 Inf
+55: xgb.strict_shape ParamLgl NA NA 2
+56: xgb.subsample ParamDbl 0 1 Inf
+57: xgb.top_k ParamInt 0 Inf Inf
+58: xgb.training ParamLgl NA NA 2
+59: xgb.tree_method ParamFct NA NA 5
+60: xgb.tweedie_variance_power ParamDbl 1 2 Inf
+61: xgb.updater ParamUty NA NA Inf
+62: xgb.verbose ParamInt 0 2 3
+63: xgb.watchlist ParamUty NA NA Inf
+64: xgb.xgb_model ParamUty NA NA Inf
+65: rf.alpha ParamDbl -Inf Inf Inf
+66: rf.always.split.variables ParamUty NA NA Inf
+67: rf.class.weights ParamUty NA NA Inf
+68: rf.holdout ParamLgl NA NA 2
+69: rf.importance ParamFct NA NA 4
+70: rf.keep.inbag ParamLgl NA NA 2
+71: rf.max.depth ParamInt 0 Inf Inf
+72: rf.min.node.size ParamInt 1 Inf Inf
+73: rf.min.prop ParamDbl -Inf Inf Inf
+74: rf.minprop ParamDbl -Inf Inf Inf
+75: rf.mtry ParamInt 1 Inf Inf
+76: rf.mtry.ratio ParamDbl 0 1 Inf
+77: rf.num.random.splits ParamInt 1 Inf Inf
+78: rf.num.threads ParamInt 1 Inf Inf
+79: rf.num.trees ParamInt 1 Inf Inf
+80: rf.oob.error ParamLgl NA NA 2
+81: rf.regularization.factor ParamUty NA NA Inf
+82: rf.regularization.usedepth ParamLgl NA NA 2
+83: rf.replace ParamLgl NA NA 2
+84: rf.respect.unordered.factors ParamFct NA NA 3
+85: rf.sample.fraction ParamDbl 0 1 Inf
+86: rf.save.memory ParamLgl NA NA 2
+87: rf.scale.permutation.importance ParamLgl NA NA 2
+88: rf.se.method ParamFct NA NA 2
+89: rf.seed ParamInt -Inf Inf Inf
+90: rf.split.select.weights ParamUty NA NA Inf
+91: rf.splitrule ParamFct NA NA 3
+92: rf.verbose ParamLgl NA NA 2
+93: rf.write.forest ParamLgl NA NA 2
+ id class lower upper nlevelsWe decide to tune the mtry parameter of the random forest and the nrounds parameter of xgboost. Additionally, we tune branching parameter that selects our learner.
We also have to reflect the hierarchical order of the parameter sets (admittedly, this is somewhat inconvenient). We can only set the mtry value if the pipe is configured to use the random forest (ranger). The same applies for the xgboost parameter.
search_space = ps(
+ branch.selection = p_fct(c("rf", "xgb")),
+ rf.mtry = p_int(1L, 20L, depends = branch.selection == "rf"),
+ xgb.nrounds = p_int(1, 500, depends = branch.selection == "xgb"))Very similar code as before, we just swap out the search space. And now use random search.
+instance = tune(
+ tuner = tnr("random_search"),
+ task = task,
+ learner = graph_learner,
+ resampling = inner_cv2,
+ measure = msr("classif.ce"),
+ term_evals = 10,
+ search_space = search_space
+)
+
+as.data.table(instance$archive)[, list(branch.selection, xgb.nrounds, rf.mtry, classif.ce)] branch.selection xgb.nrounds rf.mtry classif.ce
+ 1: xgb 292 NA 0.1875000
+ 2: rf NA 19 0.2692308
+ 3: rf NA 5 0.2307692
+ 4: xgb 229 NA 0.1875000
+ 5: xgb 301 NA 0.1875000
+ 6: rf NA 20 0.2596154
+ 7: rf NA 8 0.2355769
+ 8: rf NA 2 0.2355769
+ 9: rf NA 5 0.2500000
+10: rf NA 18 0.2451923The following shows a quick way to visualize the tuning results.
+autoplot(instance, cols_x = c("xgb.nrounds","rf.mtry"))
Nested resampling, now really needed:
+rr = tune_nested(
+ tuner = tnr("grid_search"),
+ task = task,
+ learner = graph_learner,
+ inner_resampling = inner_cv2,
+ outer_resampling = outer_cv5,
+ measure = msr("classif.ce"),
+ term_evals = 10L,
+ search_space = search_space)Access inner tuning result.
+extract_inner_tuning_results(rr)[, list(iteration, branch.selection, classif.ce)] iteration branch.selection classif.ce
+1: 1 rf 0.2108434
+2: 2 rf 0.1807229
+3: 3 rf 0.2289157
+4: 4 xgb 0.1915519
+5: 5 rf 0.1858147In this tutorial we demonstrate how to use mlr3pipelines to handle multi-target regression by arranging regression models as a chain, i.e., creating a linear sequence of regression models.
+In a simple regression chain, regression models are arranged in a linear sequence. Here, the first model will use the input to predict a single output and the second model will use the input and the prediction output of the first model to make its own prediction and so on. For more details, see e.g. Spyromitros-Xioufis et al. (2016).
+The following sections describe an approach towards working with tasks that have multiple targets. E.g., in the example below, we have three target variables \(y_{1}\) to \(y_{3}\). This type of Task can be created via the mlr3multioutput package (currently under development) in the future. mlr3multioutput will also offer simple chaining approaches as pre-built pipelines (so called ppls). The current goal of this post is to show how such modeling steps can be written as a relatively small amount of pipeline steps and how such steps can be put together. Writing pipelines with such steps allows for great flexibility in modeling more complicated scenarios such as the ones described below.
We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)Loading required package: mlr3We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")In the following, we rely on some toy data. We simulate 100 responses to three target variables, \(y_{1}\), \(y_{2}\), and \(y_{3}\) following a multivariate normal distribution with a mean and covariance matrix of:
+library(data.table)
+library(mvtnorm)
+set.seed(2409)
+n = 100
+(mean <- c(y1 = 1, y2 = 2, y3 = 3))y1 y2 y3
+ 1 2 3 (sigma <- matrix(c(1, -0.5, 0.25, -0.5, 1, -0.25, 0.25, -0.25, 1),
+ nrow = 3, ncol = 3, byrow = TRUE
+)) [,1] [,2] [,3]
+[1,] 1.00 -0.50 0.25
+[2,] -0.50 1.00 -0.25
+[3,] 0.25 -0.25 1.00Y = rmvnorm(n, mean = mean, sigma = sigma)The feature variables \(x_{1}\), and \(x_{2}\) are simulated as follows: \(x_{1}\) is simply given by \(y_{1}\) and an independent normally distributed error term and \(x_{2}\) is given by \(y_{2}\) and an independent normally distributed error term.
+x1 = Y[, 1] + rnorm(n, sd = 0.1)
+x2 = Y[, 2] + rnorm(n, sd = 0.1)The final data is given as:
+data = as.data.table(cbind(Y, x1, x2))
+str(data)Classes 'data.table' and 'data.frame': 100 obs. of 5 variables:
+ $ y1: num 0.681 1.836 0.355 1.783 0.974 ...
+ $ y2: num 2.33 1.735 3.126 0.691 1.573 ...
+ $ y3: num 3.19 3.14 2.74 4.31 2.77 ...
+ $ x1: num 0.788 1.754 0.174 1.844 1.05 ...
+ $ x2: num 2.336 1.665 2.967 0.651 1.634 ...
+ - attr(*, ".internal.selfref")=<externalptr> This simulates a situation where we have multiple target variables that are correlated with each other, such that predicting them along with each other can improve the resulting prediction model. As a real-world example for such a situation, consider e.g. hospital data, where time spent in the ICU (not known a priori) heavily influences the cost incurred by a patient’s treatment.
+If you feel confident to already have a good feeling of the data, feel free to skip this section. If not, you can use the rgl package to play around with the following four 3D plots with either the feature variables or \(y_{1}\) and \(y_{2}\) on the x- and y-axis and the target variables on the respective z-axes:
+library(rgl)
+colfun = colorRampPalette(c("#161B1D", "#ADD8E6"))setorder(data, y1)
+plot3d(data$x1, data$x2, data$y1,
+ xlab = "x1", ylab = "x2", zlab = "y1",
+ type = "s", radius = 0.1, col = colfun(n)
+)setorder(data, y2)
+plot3d(data$x1, data$x2, data$y2,
+ xlab = "x1", ylab = "x2", zlab = "y2",
+ type = "s", radius = 0.1, col = colfun(n)
+)setorder(data, y3)
+plot3d(data$x1, data$x2, data$y3,
+ xlab = "x1", ylab = "x2", zlab = "y3",
+ type = "s", radius = 0.1, col = colfun(n)
+)setorder(data, y3)
+plot3d(data$y1, data$y2, data$y3,
+ xlab = "y1", ylab = "y2", zlab = "y3",
+ type = "s", radius = 0.1, col = colfun(n)
+)In our regression chain, the first model will predict \(y_{1}\). Therefore, we initialize our Task with respect to this target:
task = as_task_regr(data, id = "multiregression", target = "y1")As Learners we will use simple linear regression models. Our pipeline building the regression chain then has to do the following:
To combine predictions of a Learner with the previous input, we rely on PipeOpLearnerCV and PipeOpNOP arranged in parallel via gunion() combined via PipeOpFeatureUnion. To drop the respective remaining target variables as features, we rely on PipeOpColRoles. The first step of predicting \(y_{1}\) looks like the following:
step1 = po("copy", outnum = 2, id = "copy1") %>>%
+ gunion(list(
+ po("colroles",
+ id = "drop_y2_y3",
+ new_role = list(y2 = character(), y3 = character())
+ ) %>>%
+ po("learner_cv", learner = lrn("regr.lm"), id = "y1_learner"),
+ po("nop", id = "nop1")
+ )) %>>%
+ po("featureunion", id = "union1")
+step1$plot(html = FALSE)
Training using the input Task, shows us how the output and the $state look like:
step1_out = step1$train(task)[[1]]
+step1_out<TaskRegr:multiregression> (100 x 6)
+* Target: y1
+* Properties: -
+* Features (5):
+ - dbl (5): x1, x2, y1_learner.response, y2, y3step1$state$copy1
+list()
+
+$drop_y2_y3
+$drop_y2_y3$dt_columns
+[1] "x1" "x2" "y2" "y3"
+
+$drop_y2_y3$affected_cols
+[1] "x1" "x2" "y2" "y3"
+
+$drop_y2_y3$intasklayout
+ id type
+1: x1 numeric
+2: x2 numeric
+3: y2 numeric
+4: y3 numeric
+
+$drop_y2_y3$outtasklayout
+ id type
+1: x1 numeric
+2: x2 numeric
+
+$drop_y2_y3$outtaskshell
+Empty data.table (0 rows and 3 cols): y1,x1,x2
+
+
+$y1_learner
+$y1_learner$model
+
+Call:
+stats::lm(formula = task$formula(), data = task$data())
+
+Coefficients:
+(Intercept) x1 x2
+ -0.03762 0.99851 0.01364
+
+
+$y1_learner$log
+Empty data.table (0 rows and 3 cols): stage,class,msg
+
+$y1_learner$train_time
+[1] 0.004
+
+$y1_learner$param_vals
+named list()
+
+$y1_learner$task_hash
+[1] "933a5b384a9aaebf"
+
+$y1_learner$data_prototype
+Empty data.table (0 rows and 3 cols): y1,x1,x2
+
+$y1_learner$task_prototype
+Empty data.table (0 rows and 3 cols): y1,x1,x2
+
+$y1_learner$mlr3_version
+[1] '0.16.1'
+
+$y1_learner$train_task
+<TaskRegr:multiregression> (100 x 3)
+* Target: y1
+* Properties: -
+* Features (2):
+ - dbl (2): x1, x2
+
+$y1_learner$affected_cols
+[1] "x1" "x2"
+
+$y1_learner$intasklayout
+ id type
+1: x1 numeric
+2: x2 numeric
+
+$y1_learner$outtasklayout
+ id type
+1: y1_learner.response numeric
+
+$y1_learner$outtaskshell
+Empty data.table (0 rows and 2 cols): y1,y1_learner.response
+
+
+$nop1
+list()
+
+$union1
+list()Within the second step we then have to define \(y_{2}\) as the new target. This can be done using PipeOpUpdateTarget (note that PipeOpUpdateTarget currently is not exported but will be in a future version). By default, PipeOpUpdateTarget drops the original target from the feature set, here \(y_{1}\).
mlr_pipeops$add("update_target", mlr3pipelines:::PipeOpUpdateTarget)step2 = po("update_target",
+ id = "y2_target",
+ new_target_name = "y2"
+) %>>%
+ po("copy", outnum = 2, id = "copy2") %>>%
+ gunion(list(
+ po("colroles",
+ id = "drop_y3",
+ new_role = list(y3 = character())
+ ) %>>%
+ po("learner_cv", learner = lrn("regr.lm"), id = "y2_learner"),
+ po("nop", id = "nop2")
+ )) %>>%
+ po("featureunion", id = "union2")Again, we can train to see how the output and $state look like, but now using the output of step1 as the input:
step2_out = step2$train(step1_out)[[1]]
+step2_out<TaskRegr:multiregression> (100 x 6)
+* Target: y2
+* Properties: -
+* Features (5):
+ - dbl (5): x1, x2, y1_learner.response, y2_learner.response, y3step2$state$y2_target
+list()
+
+$copy2
+list()
+
+$drop_y3
+$drop_y3$dt_columns
+[1] "x1" "x2" "y1_learner.response" "y3"
+
+$drop_y3$affected_cols
+[1] "y1_learner.response" "x1" "x2" "y3"
+
+$drop_y3$intasklayout
+ id type
+1: x1 numeric
+2: x2 numeric
+3: y1_learner.response numeric
+4: y3 numeric
+
+$drop_y3$outtasklayout
+ id type
+1: x1 numeric
+2: x2 numeric
+3: y1_learner.response numeric
+
+$drop_y3$outtaskshell
+Empty data.table (0 rows and 4 cols): y2,y1_learner.response,x1,x2
+
+
+$y2_learner
+$y2_learner$model
+
+Call:
+stats::lm(formula = task$formula(), data = task$data())
+
+Coefficients:
+ (Intercept) y1_learner.response x1 x2
+ 0.07135 0.22773 -0.25186 0.97877
+
+
+$y2_learner$log
+Empty data.table (0 rows and 3 cols): stage,class,msg
+
+$y2_learner$train_time
+[1] 0.01
+
+$y2_learner$param_vals
+named list()
+
+$y2_learner$task_hash
+[1] "1bc5196bab655ff5"
+
+$y2_learner$data_prototype
+Empty data.table (0 rows and 4 cols): y2,y1_learner.response,x1,x2
+
+$y2_learner$task_prototype
+Empty data.table (0 rows and 4 cols): y2,y1_learner.response,x1,x2
+
+$y2_learner$mlr3_version
+[1] '0.16.1'
+
+$y2_learner$train_task
+<TaskRegr:multiregression> (100 x 4)
+* Target: y2
+* Properties: -
+* Features (3):
+ - dbl (3): x1, x2, y1_learner.response
+
+$y2_learner$affected_cols
+[1] "y1_learner.response" "x1" "x2"
+
+$y2_learner$intasklayout
+ id type
+1: x1 numeric
+2: x2 numeric
+3: y1_learner.response numeric
+
+$y2_learner$outtasklayout
+ id type
+1: y2_learner.response numeric
+
+$y2_learner$outtaskshell
+Empty data.table (0 rows and 2 cols): y2,y2_learner.response
+
+
+$nop2
+list()
+
+$union2
+list()In the final third step we define \(y_{3}\) as the new target (again, PipeOpUpdateTarget drops the previous original target from the feature set, here \(y_{2}\)):
step3 = po("update_target",
+ id = "y3_target",
+ new_target_name = "y3"
+) %>>%
+ po("learner", learner = lrn("regr.lm"), id = "y3_learner")Using the output of step2 as input:
step3_out = step3$train(step2_out)[[1]]
+step3_outNULLstep3$state$y3_target
+list()
+
+$y3_learner
+$y3_learner$model
+
+Call:
+stats::lm(formula = task$formula(), data = task$data())
+
+Coefficients:
+ (Intercept) y2_learner.response y1_learner.response x1 x2
+ 2.6445 0.8155 3.8776 -3.5217 -0.7304
+
+
+$y3_learner$log
+Empty data.table (0 rows and 3 cols): stage,class,msg
+
+$y3_learner$train_time
+[1] 0.013
+
+$y3_learner$param_vals
+named list()
+
+$y3_learner$task_hash
+[1] "24dbd64658d33d6d"
+
+$y3_learner$data_prototype
+Empty data.table (0 rows and 5 cols): y3,y2_learner.response,y1_learner.response,x1,x2
+
+$y3_learner$task_prototype
+Empty data.table (0 rows and 5 cols): y3,y2_learner.response,y1_learner.response,x1,x2
+
+$y3_learner$mlr3_version
+[1] '0.16.1'
+
+$y3_learner$train_task
+<TaskRegr:multiregression> (100 x 5)
+* Target: y3
+* Properties: -
+* Features (4):
+ - dbl (4): x1, x2, y1_learner.response, y2_learner.responseThe complete pipeline, more precisely Graph, looks like the following:
graph = step1 %>>% step2 %>>% step3
+graph$plot(html = FALSE)
By wrapping our Graph in a GraphLearner, we can perform 3-fold cross-validation and get an estimated average of the root-mean-square error (of course, in a real world setting splitting the data in a training and test set should have been done):
learner = as_learner(graph)
+rr = resample(task, learner, rsmp("cv", folds = 3))
+rr$aggregate(msr("regr.mse")) regr.mse
+0.7265587 For completeness, we also show how a prediction step without having any target variable data available would look like:
+data_predict = as.data.table(cbind(x1, x2, y1 = NA, y2 = NA, y3 = NA))
+learner$train(task)
+learner$predict_newdata(data_predict)<PredictionRegr> for 100 observations:
+ row_ids truth response
+ 1 NA 3.116960
+ 2 NA 3.327345
+ 3 NA 3.010821
+---
+ 98 NA 3.462541
+ 99 NA 3.020585
+ 100 NA 3.664326Note that we have to initialize the Task with \(y_{1}\) as the target but the pipeline will automatically predict \(y_{3}\) in the final step as our final target, which was our ultimate goal here.
mlr3pipelines offers a very flexible way to create data preprocessing steps. This is achieved by a modular approach using PipeOps. For detailed overview check the mlr3book.
Recommended prior readings:
+ +This post covers:
+We load the mlr3verse package which pulls in the most important packages for this example.
+library(mlr3verse)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")The Pima Indian Diabetes classification task will be used.
task_pima = tsk("pima")
+skimr::skim(task_pima$data())| Name | +task_pima$data() | +
| Number of rows | +768 | +
| Number of columns | +9 | +
| Key | +NULL | +
| _______________________ | ++ |
| Column type frequency: | ++ |
| factor | +1 | +
| numeric | +8 | +
| ________________________ | ++ |
| Group variables | +None | +
Variable type: factor
+| skim_variable | +n_missing | +complete_rate | +ordered | +n_unique | +top_counts | +
|---|---|---|---|---|---|
| diabetes | +0 | +1 | +FALSE | +2 | +neg: 500, pos: 268 | +
Variable type: numeric
+| skim_variable | +n_missing | +complete_rate | +mean | +sd | +p0 | +p25 | +p50 | +p75 | +p100 | +hist | +
|---|---|---|---|---|---|---|---|---|---|---|
| age | +0 | +1.00 | +33.24 | +11.76 | +21.00 | +24.00 | +29.00 | +41.00 | +81.00 | +▇▃▁▁▁ | +
| glucose | +5 | +0.99 | +121.69 | +30.54 | +44.00 | +99.00 | +117.00 | +141.00 | +199.00 | +▁▇▇▃▂ | +
| insulin | +374 | +0.51 | +155.55 | +118.78 | +14.00 | +76.25 | +125.00 | +190.00 | +846.00 | +▇▂▁▁▁ | +
| mass | +11 | +0.99 | +32.46 | +6.92 | +18.20 | +27.50 | +32.30 | +36.60 | +67.10 | +▅▇▃▁▁ | +
| pedigree | +0 | +1.00 | +0.47 | +0.33 | +0.08 | +0.24 | +0.37 | +0.63 | +2.42 | +▇▃▁▁▁ | +
| pregnant | +0 | +1.00 | +3.85 | +3.37 | +0.00 | +1.00 | +3.00 | +6.00 | +17.00 | +▇▃▂▁▁ | +
| pressure | +35 | +0.95 | +72.41 | +12.38 | +24.00 | +64.00 | +72.00 | +80.00 | +122.00 | +▁▃▇▂▁ | +
| triceps | +227 | +0.70 | +29.15 | +10.48 | +7.00 | +22.00 | +29.00 | +36.00 | +99.00 | +▆▇▁▁▁ | +
Several features of the pima task have missing values:
task_pima$missings()diabetes age glucose insulin mass pedigree pregnant pressure triceps
+ 0 0 5 374 11 0 0 35 227 A common approach in such situations is to impute the missing values and to add a missing indicator column as explained in the Impute missing variables post. Suppose we want to use
+PipeOpImputeHist on features “glucose”, “mass” and “pressure” which have only few missing values andPipeOpImputeMedian on features “insulin” and “triceps” which have much more missing values.In the following subsections, we show two approaches to implement this.
+Using the affect_columns argument of a PipeOp to define the variables on which a PipeOp will operate with an appropriate Selector function:
# imputes values based on histogram
+imputer_hist = po("imputehist",
+ affect_columns = selector_name(c("glucose", "mass", "pressure")))
+# imputes values using the median
+imputer_median = po("imputemedian",
+ affect_columns = selector_name(c("insulin", "triceps")))
+# adds an indicator column for each feature with missing values
+miss_ind = po("missind")When PipeOps are constructed this way, they will perform the specified preprocessing step on the appropriate features and pass all the input features to the subsequent steps:
# no missings in "glucose", "mass" and "pressure"
+imputer_hist$train(list(task_pima))[[1]]$missings()diabetes age insulin pedigree pregnant triceps glucose mass pressure
+ 0 0 374 0 0 227 0 0 0 # no missings in "insulin" and "triceps"
+imputer_median$train(list(task_pima))[[1]]$missings()diabetes age glucose mass pedigree pregnant pressure insulin triceps
+ 0 0 5 11 0 0 35 0 0 We construct a pipeline that combines imputer_hist and imputer_median. Here, imputer_hist will impute the features “glucose”, “mass” and “pressure”, and imputer_median will impute “insulin” and “triceps”. In each preprocessing step, all the input features are passed to the next step. In the end, we obtain a data set without missing values:
# combine the two impuation methods
+impute_graph = imputer_hist %>>% imputer_median
+impute_graph$plot(html = FALSE)
impute_graph$train(task_pima)[[1]]$missings()diabetes age pedigree pregnant glucose mass pressure insulin triceps
+ 0 0 0 0 0 0 0 0 0 The PipeOpMissInd operator replaces features with missing values with a missing value indicator:
miss_ind$train(list(task_pima))[[1]]$data() diabetes missing_glucose missing_insulin missing_mass missing_pressure missing_triceps
+ 1: pos present missing present present present
+ 2: neg present missing present present present
+ 3: pos present missing present present missing
+ 4: neg present present present present present
+ 5: pos present present present present present
+ ---
+764: neg present present present present present
+765: neg present missing present present present
+766: neg present present present present present
+767: pos present missing present present missing
+768: neg present missing present present presentObviously, this step can not be applied to the already imputed data as there are no missing values. If we want to combine the previous two imputation steps with a third step that adds missing value indicators, we would need to PipeOpCopy the data two times and supply the first copy to impute_graph and the second copy to miss_ind using gunion(). Finally, the two outputs can be combined with PipeOpFeatureUnion:
impute_missind = po("copy", 2) %>>%
+ gunion(list(impute_graph, miss_ind)) %>>%
+ po("featureunion")
+impute_missind$plot(html = FALSE)
impute_missind$train(task_pima)[[1]]$data() diabetes age pedigree pregnant glucose mass pressure insulin triceps missing_glucose missing_insulin missing_mass
+ 1: pos 50 0.627 6 148 33.6 72 125 35 present missing present
+ 2: neg 31 0.351 1 85 26.6 66 125 29 present missing present
+ 3: pos 32 0.672 8 183 23.3 64 125 29 present missing present
+ 4: neg 21 0.167 1 89 28.1 66 94 23 present present present
+ 5: pos 33 2.288 0 137 43.1 40 168 35 present present present
+ ---
+764: neg 63 0.171 10 101 32.9 76 180 48 present present present
+765: neg 27 0.340 2 122 36.8 70 125 27 present missing present
+766: neg 30 0.245 5 121 26.2 72 112 23 present present present
+767: pos 47 0.349 1 126 30.1 60 125 29 present missing present
+768: neg 23 0.315 1 93 30.4 70 125 31 present missing present
+ missing_pressure missing_triceps
+ 1: present present
+ 2: present present
+ 3: present missing
+ 4: present present
+ 5: present present
+ ---
+764: present present
+765: present present
+766: present present
+767: present missing
+768: present presentWe can use the PipeOpSelect to select the appropriate features and then apply the desired impute PipeOp on them:
imputer_hist_2 = po("select",
+ selector = selector_name(c("glucose", "mass", "pressure")),
+ id = "slct1") %>>% # unique id so we can combine it in a pipeline with other select PipeOps
+ po("imputehist")
+
+imputer_hist_2$plot(html = FALSE)
imputer_hist_2$train(task_pima)[[1]]$data() diabetes glucose mass pressure
+ 1: pos 148 33.6 72
+ 2: neg 85 26.6 66
+ 3: pos 183 23.3 64
+ 4: neg 89 28.1 66
+ 5: pos 137 43.1 40
+ ---
+764: neg 101 32.9 76
+765: neg 122 36.8 70
+766: neg 121 26.2 72
+767: pos 126 30.1 60
+768: neg 93 30.4 70imputer_median_2 =
+ po("select", selector = selector_name(c("insulin", "triceps")), id = "slct2") %>>%
+ po("imputemedian")
+
+imputer_median_2$train(task_pima)[[1]]$data() diabetes insulin triceps
+ 1: pos 125 35
+ 2: neg 125 29
+ 3: pos 125 29
+ 4: neg 94 23
+ 5: pos 168 35
+ ---
+764: neg 180 48
+765: neg 125 27
+766: neg 112 23
+767: pos 125 29
+768: neg 125 31To reproduce the result of the fist example (1.), we need to copy the data four times and apply imputer_hist_2, imputer_median_2 and miss_ind on each of the three copies. The fourth copy is required to select the features without missing values and to append it to the final result. We can do this as follows:
other_features = task_pima$feature_names[task_pima$missings()[-1] == 0]
+
+imputer_missind_2 = po("copy", 4) %>>%
+ gunion(list(imputer_hist_2,
+ imputer_median_2,
+ miss_ind,
+ po("select", selector = selector_name(other_features), id = "slct3"))) %>>%
+ po("featureunion")
+
+imputer_missind_2$plot(html = FALSE)
imputer_missind_2$train(task_pima)[[1]]$data() diabetes glucose mass pressure insulin triceps missing_glucose missing_insulin missing_mass missing_pressure
+ 1: pos 148 33.6 72 125 35 present missing present present
+ 2: neg 85 26.6 66 125 29 present missing present present
+ 3: pos 183 23.3 64 125 29 present missing present present
+ 4: neg 89 28.1 66 94 23 present present present present
+ 5: pos 137 43.1 40 168 35 present present present present
+ ---
+764: neg 101 32.9 76 180 48 present present present present
+765: neg 122 36.8 70 125 27 present missing present present
+766: neg 121 26.2 72 112 23 present present present present
+767: pos 126 30.1 60 125 29 present missing present present
+768: neg 93 30.4 70 125 31 present missing present present
+ missing_triceps age pedigree pregnant
+ 1: present 50 0.627 6
+ 2: present 31 0.351 1
+ 3: missing 32 0.672 8
+ 4: present 21 0.167 1
+ 5: present 33 2.288 0
+ ---
+764: present 63 0.171 10
+765: present 27 0.340 2
+766: present 30 0.245 5
+767: missing 47 0.349 1
+768: present 23 0.315 1Note that when there is one input channel, it is automatically copied as many times as needed for the downstream PipeOps. In other words, the code above works also without po("copy", 4):
imputer_missind_3 = gunion(list(imputer_hist_2,
+ imputer_median_2,
+ miss_ind,
+ po("select", selector = selector_name(other_features), id = "slct3"))) %>>%
+ po("featureunion")
+
+imputer_missind_3$train(task_pima)[[1]]$data() diabetes glucose mass pressure insulin triceps missing_glucose missing_insulin missing_mass missing_pressure
+ 1: pos 148 33.6 72 125 35 present missing present present
+ 2: neg 85 26.6 66 125 29 present missing present present
+ 3: pos 183 23.3 64 125 29 present missing present present
+ 4: neg 89 28.1 66 94 23 present present present present
+ 5: pos 137 43.1 40 168 35 present present present present
+ ---
+764: neg 101 32.9 76 180 48 present present present present
+765: neg 122 36.8 70 125 27 present missing present present
+766: neg 121 26.2 72 112 23 present present present present
+767: pos 126 30.1 60 125 29 present missing present present
+768: neg 93 30.4 70 125 31 present missing present present
+ missing_triceps age pedigree pregnant
+ 1: present 50 0.627 6
+ 2: present 31 0.351 1
+ 3: missing 32 0.672 8
+ 4: present 21 0.167 1
+ 5: present 33 2.288 0
+ ---
+764: present 63 0.171 10
+765: present 27 0.340 2
+766: present 30 0.245 5
+767: missing 47 0.349 1
+768: present 23 0.315 1Usually, po("copy") is required when there are more than one input channels and multiple output channels, and their numbers do not match.
We can not know if the combination of a learner with this preprocessing graph will benefit from the imputation steps and the added missing value indicators. Maybe it would have been better to just use imputemedian on all the variables. We could investigate this assumption by adding an alternative path to the graph with the mentioned imputemedian. This is possible using the “branch” PipeOp:
imputer_median_3 = po("imputemedian", id = "simple_median") # add the id so it does not clash with `imputer_median`
+
+branches = c("impute_missind", "simple_median") # names of the branches
+
+graph_branch = po("branch", branches) %>>%
+ gunion(list(impute_missind, imputer_median_3)) %>>%
+ po("unbranch")
+
+graph_branch$plot(html = FALSE)
To finalize the graph, we combine it with a rpart learner:
+graph = graph_branch %>>%
+ lrn("classif.rpart")
+
+graph$plot(html = FALSE)
To define the parameters to be tuned, we first check the available ones in the graph:
+as.data.table(graph$param_set)[, .(id, class, lower, upper, nlevels)] id class lower upper nlevels
+ 1: branch.selection ParamFct NA NA 2
+ 2: imputehist.affect_columns ParamUty NA NA Inf
+ 3: imputemedian.affect_columns ParamUty NA NA Inf
+ 4: missind.which ParamFct NA NA 2
+ 5: missind.type ParamFct NA NA 4
+ 6: missind.affect_columns ParamUty NA NA Inf
+ 7: simple_median.affect_columns ParamUty NA NA Inf
+ 8: classif.rpart.cp ParamDbl 0 1 Inf
+ 9: classif.rpart.keep_model ParamLgl NA NA 2
+10: classif.rpart.maxcompete ParamInt 0 Inf Inf
+11: classif.rpart.maxdepth ParamInt 1 30 30
+12: classif.rpart.maxsurrogate ParamInt 0 Inf Inf
+13: classif.rpart.minbucket ParamInt 1 Inf Inf
+14: classif.rpart.minsplit ParamInt 1 Inf Inf
+15: classif.rpart.surrogatestyle ParamInt 0 1 2
+16: classif.rpart.usesurrogate ParamInt 0 2 3
+17: classif.rpart.xval ParamInt 0 Inf InfWe decide to jointly tune the "branch.selection", "classif.rpart.cp" and "classif.rpart.minbucket" hyperparameters:
search_space = ps(
+ branch.selection = p_fct(c("impute_missind", "simple_median")),
+ classif.rpart.cp = p_dbl(0.001, 0.1),
+ classif.rpart.minbucket = p_int(1, 10))In order to tune the graph, it needs to be converted to a learner:
+graph_learner = as_learner(graph)
+
+cv3 = rsmp("cv", folds = 3)
+
+cv3$instantiate(task_pima) # to generate folds for cross validation
+
+instance = tune(
+ tuner = tnr("random_search"),
+ task = task_pima,
+ learner = graph_learner,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.ce"),
+ search_space = search_space,
+ term_evals = 5)
+
+as.data.table(instance$archive, unnest = NULL, exclude_columns = c("x_domain", "uhash", "resample_result")) branch.selection classif.rpart.cp classif.rpart.minbucket classif.ce runtime_learners timestamp batch_nr
+1: simple_median 0.02172886 2 0.2799479 2.774 2023-11-02 16:33:12 1
+2: impute_missind 0.07525939 1 0.2760417 2.701 2023-11-02 16:33:25 2
+3: impute_missind 0.09207969 3 0.2773438 1.031 2023-11-02 16:33:36 3
+4: impute_missind 0.03984117 6 0.2721354 2.184 2023-11-02 16:33:47 4
+5: impute_missind 0.09872643 7 0.2773438 2.507 2023-11-02 16:33:57 5
+ warnings errors
+1: 0 0
+2: 0 0
+3: 0 0
+4: 0 0
+5: 0 0The best performance in this short tuned experiment was achieved with:
+instance$result branch.selection classif.rpart.cp classif.rpart.minbucket learner_param_vals x_domain classif.ce
+1: impute_missind 0.03984117 6 <list[9]> <list[3]> 0.2721354This post shows ways on how to specify features on which preprocessing steps are to be performed. In addition it shows how to create alternative paths in the learner graph. The preprocessing steps that can be used are not limited to imputation. Check the list of available PipeOp.
This is the second post of the titanic use case series. You can find the first use case here.
+In this section we will focus on more advanced usage of mlr3pipelines . Specifically, this section illustrates the different options when it comes to data imputation and feature engineering. Furthermore, the section shows how to benchmark, feature engineer and compare our results.
+We load the mlr3verse package which pulls in the most important packages for this example. The mlr3learners package loads additional learners. The data is part of the mlr3data package.
library(mlr3verse)
+library(mlr3learners)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")
+future::plan("multicore")As in the basics chapter, we use the titanic data set. To recap we have undertaken the following steps:
+data("titanic", package = "mlr3data")
+
+# setting up the task
+task = as_task_classif(titanic, target = "survived", positive = "yes")
+task$set_row_roles(892:1309, "holdout")
+task$select(cols = setdiff(task$feature_names, c("cabin", "name", "ticket")))
+
+# setting up the learner
+learner = lrn("classif.rpart")
+
+#setting up our resampling method
+resampling = rsmp("cv", folds = 3L)$instantiate(task)
+
+res = resample(task, learner, resampling, store_models = TRUE)A very simple way to do this to just impute a constant value for each feature. We could i.e. impute every character or factor column with missing and every numeric column with -999. And depending on the model, this might actually be fine. This approach has a few drawbacks though:
-999 could be a real value in the data.-999 skews the distribution of the data, which might result in bad models.As a result, instead of imputing a constant value, we will do two things: * Draw samples from each numeric features’ histogram using PipeOpImputeHist * Add an additional column for each variable that indicates whether a value was missing or not. If the information that a value was missing is important, this column contains this information.
This imputation scheme is called ‘imputation with constants’ and is already implemented in mlr3pipelines . It can be done using PipeOpImputeConstant.
Remember that we are trying to optimize our predictive power by using a random forest model (mlr_learners_classif.ranger). Now, random forest models do not naturally handle missing values which is the reason why we need imputation. Before imputation, our data looks as follows:
task$missings()survived age embarked fare parch pclass sex sib_sp
+ 0 177 2 0 0 0 0 0 Let’s first deal with the categorical variables:
+po_newlvl = po("imputeoor")
+task_newlvl = po_newlvl$train(list(task))[[1]]Note that we use the PipeOp in an unusual way, which is why the syntax does not look very clean. We’ll learn how to use a full graph below.
First, let’s look at the result:
+task_newlvl$missings()survived fare parch pclass sex sib_sp age embarked
+ 0 0 0 0 0 0 0 0 Cool! embarked does not have missing values anymore. Note that PipeOpImputeOOR by default affects character, factor and ordered columns.
For the numeric features we want to do two things, impute values and add an indicator column. In order to do this, we need a more complicated structure, a Graph.
Our po_indicator creates the indicator column. We tell it to only do this for numeric and integer columns via its param_vals, and additionally tell it to create a numeric column (0 = “not missing”, 1 = “missing”).
po_indicator = po("missind",
+ affect_columns = selector_type(c("numeric", "integer")), type = "numeric")Now we can simultaneously impute features from the histogram and create indicator columns. This can be achieved using the gunion function, which puts two operations in parallel:
graph = gunion(list(po_indicator, po("imputehist")))
+graph = graph %>>% po("featureunion")Afterwards, we cbind the resulting data using po("featureunion"), connecting the different operations using our graph connector: %>>%. We can now also connect the newlvl imputation:
graph = graph %>>% po("imputeoor")and see what happens when we now train the whole Graph:
+task_imputed = graph$clone()$train(task)[[1]]
+task_imputed$missings() survived missing_age pclass sex fare parch sib_sp age embarked
+ 0 0 0 0 0 0 0 0 0 Awesome, now we do not have any missing values!
+autoplot(task_imputed)
We could now use task_imputed for resampling and see whether a ranger model does better. But this is dangerous! If we preprocess all training data at once, data could leak through the different cross-validation folds. In order to do this properly, we have to process the training data in every fold separately. Luckily, this is automatically handled in our Graph, if we use it through a GraphLearner.
We can simply append a ranger learner to the Graph and create a GraphLearner from this.
graph_learner = as_learner(graph$clone() %>>%
+ po("imputesample") %>>%
+ po("fixfactors") %>>%
+ po(learner))We needed to use the following commands for the Graph: * PipeOpFixFactors: Removes empty factor levels and removes factor levels that do not exist during training. * PipeOpImputeSample: In some cases, if missing factor levels do not occur during training but only while predicting, PipeOpImputeOOR does not create a new level. For those, we sample a random value.
rr = resample(task, graph_learner, resampling, store_models = TRUE)
+rr$aggregate(msr("classif.acc"))classif.acc
+ 0.7934905 So our model has not improved heavily, currently it has an accuracy of 0.79.
We will do this using PipeOpMutate in order to showcase the power of mlr3pipelines . Additionally, we will make use of the character columns. Hence, we will re-select them:
task$col_roles$feature = c(task$feature_names, c("cabin", "name", "ticket"))library("stringi")
+po_ftextract = po("mutate", mutation = list(
+ fare_per_person = ~ fare / (parch + sib_sp + 1),
+ deck = ~ factor(stri_sub(cabin, 1, 1)),
+ title = ~ factor(stri_match(name, regex = ", (.*)\\.")[, 2]),
+ surname = ~ factor(stri_match(name, regex = "(.*),")[, 2]),
+ ticket_prefix = ~ factor(stri_replace_all_fixed(stri_trim(stri_match(ticket, regex = "(.*) ")[, 2]), ".", ""))
+))Quickly checking what happens:
+task_eng = po_ftextract$clone()$train(list(task))[[1]]
+task_eng$data() survived age embarked fare parch pclass sex sib_sp cabin name
+ 1: no 22 S 7.2500 0 3 male 1 <NA> Braund, Mr. Owen Harris
+ 2: yes 38 C 71.2833 0 1 female 1 C85 Cumings, Mrs. John Bradley (Florence Briggs Thayer)
+ 3: yes 26 S 7.9250 0 3 female 0 <NA> Heikkinen, Miss. Laina
+ 4: yes 35 S 53.1000 0 1 female 1 C123 Futrelle, Mrs. Jacques Heath (Lily May Peel)
+ 5: no 35 S 8.0500 0 3 male 0 <NA> Allen, Mr. William Henry
+ ---
+887: no 27 S 13.0000 0 2 male 0 <NA> Montvila, Rev. Juozas
+888: yes 19 S 30.0000 0 1 female 0 B42 Graham, Miss. Margaret Edith
+889: no NA S 23.4500 2 3 female 1 <NA> Johnston, Miss. Catherine Helen "Carrie"
+890: yes 26 C 30.0000 0 1 male 0 C148 Behr, Mr. Karl Howell
+891: no 32 Q 7.7500 0 3 male 0 <NA> Dooley, Mr. Patrick
+ ticket fare_per_person deck title surname ticket_prefix
+ 1: A/5 21171 3.62500 <NA> Mr Braund A/5
+ 2: PC 17599 35.64165 C Mrs Cumings PC
+ 3: STON/O2. 3101282 7.92500 <NA> Miss Heikkinen STON/O2
+ 4: 113803 26.55000 C Mrs Futrelle <NA>
+ 5: 373450 8.05000 <NA> Mr Allen <NA>
+ ---
+887: 211536 13.00000 <NA> Rev Montvila <NA>
+888: 112053 30.00000 B Miss Graham <NA>
+889: W./C. 6607 5.86250 <NA> Miss Johnston W/C
+890: 111369 30.00000 C Mr Behr <NA>
+891: 370376 7.75000 <NA> Mr Dooley <NA>autoplot(task_eng$clone()$select(c("sex", "age")), type = "pairs")Registered S3 method overwritten by 'GGally':
+ method from
+ +.gg ggplot2Warning: Removed 177 rows containing non-finite values (`stat_boxplot()`).`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 177 rows containing non-finite values (`stat_bin()`).Warning: Removed 177 rows containing non-finite values (`stat_density()`).Warning: Removed 177 rows containing non-finite values (`stat_boxplot()`).`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 177 rows containing non-finite values (`stat_bin()`).
Now we can put everything together again, we concatenate our new PipeOp with the Graph created above and use PipeOpSelect in order to de-select the character features we used for feature extraction. Additionally, we collapse the ‘surname’, so only surnames that make up more than 0.6 % of the data are kept.
In summary, we do the following:
+mutate: The po_ftextract we defined above extracts additional features from the data.collapsefactors: Removes factor levels that make up less then 3 % of the data.select: Drops character columns.gunion: Puts two PipeOps in parallel.
+missind: po_indicator adds a column for each numeric with the info whether the value is NA or not.imputehist: Imputes numeric and integer columns by sampling from the histogram.featureunion: Cbind’s parallel data streams.imputeoor: Imputes factor and ordered columns.fixfactors: Removes empty factor levels and removes factor levels that do not exist during training.imputesample: In some cases, if missing factor levels do not occur during training but only while predicting, imputeoor does not create a new level. For those, we sample a random value.Learner: Appends a learner to the Graph.The full graph we created is the following:
+learner = lrn("classif.ranger", num.trees = 500, min.node.size = 4)graph_final = po_ftextract %>>%
+ po("collapsefactors", param_vals = list(no_collapse_above_prevalence = 0.03)) %>>%
+ po("select", param_vals = list(selector = selector_invert(selector_type("character")))) %>>%
+ gunion(list(po_indicator, po("imputehist"))) %>>%
+ po("featureunion") %>>%
+ po("imputeoor") %>>%
+ po("fixfactors") %>>%
+ po("imputesample") %>>%
+ po(learner)Let us see if things have improved:
+graph_learner = as_learner(graph_final)
+
+rr = resample(task, graph_learner, resampling, store_models = TRUE)
+
+rr$aggregate(msr("classif.acc"))classif.acc
+ 0.8249158 We have improved even more!
+To undertake benchmarking, we need to set up a benchmarking design. The first step is creating a list with the learners we used, namely the learners form the first and second part of this use case.
+learners = list(
+ lrn("classif.rpart", predict_type = "prob"),
+ lrn("classif.ranger", predict_type = "prob")
+)Now we can define our benchmark design. This is done to ensure exhaustive and consistent resampling for all learners. This step is needed to execute over the same train/test split for each task.
+bm_design = benchmark_grid(task_imputed, learners, rsmp("cv", folds = 10))
+bmr = benchmark(bm_design, store_models = TRUE)
+print(bmr)<BenchmarkResult> of 20 rows with 2 resampling runs
+ nr task_id learner_id resampling_id iters warnings errors
+ 1 titanic classif.rpart cv 10 0 0
+ 2 titanic classif.ranger cv 10 0 0So, where do we go from here? We could for instance use a boxplot:
+autoplot(bmr)
Further we are able to compare sensitivity and specificity. Here we need to ensure that the benchmark results only contain a single Task:
+autoplot(bmr$clone()$filter(task_id = "titanic"), type = "roc")
Moreover, one can compare the precision-recall:
+# Precision vs Recall
+ggplot2::autoplot(bmr, type = "prc")
As one can see, there are various options when it comes to benchmarking and visualizing. You could have a look at some other use cases in our gallery for inspiration.
+In this case we have examined a number of different features, but there are many more things to explore! We could extract even more information from the different features and see what happens. But now you are left to yourself! There are many kaggle kernels that treat the Titanic Dataset available. This can be a great starter to find even better models.
+ + +Tune a multilevel stacking model.
+
+ Multilevel stacking is an ensemble technique, where predictions of several learners are added as new features to extend the orginal data on different levels. On each level, the extended data is used to train a new level of learners. This can be repeated for several iterations until a final learner is trained. To avoid overfitting, it is advisable to use test set (out-of-bag) predictions in each level.
+In this post, a multilevel stacking example will be created using mlr3pipelines and tuned using mlr3tuning . A similar example is available in the mlr3book. However, we additionally explain how to tune the hyperparameters of the whole ensemble and each underlying learner jointly.
+In our stacking example, we proceed as follows:
+rpart, glmnet and lda) on a sparser feature space obtained using different feature filter methods from mlr3filters to obtain slightly decorrelated predictions. The test set predictions of these learners are attached to the original data (used in level 0) and will serve as input for the learners in level 1.rpart, glmnet and lda). The test set predictions of the level 1 learners are attached to input data used in level 1.ranger learner to the data extended by level 1. Note that the number of features selected by the feature filter method in level 0 and the number of principal components retained in level 1 will be jointly tuned with some other hyperparameters of the learners in each level.We load the mlr3verse package which pulls in the most important packages for this example. The mlr3learners package loads additional learners.
library(mlr3verse)
+library(mlr3learners)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")For the stacking example, we use the sonar classification task:
+task_sonar = tsk("sonar")
+task_sonar$col_roles$stratum = task_sonar$target_names # stratificationAs mentioned, the level 0 learners are rpart, glmnet and lda:
learner_rpart = lrn("classif.rpart", predict_type = "prob")
+learner_glmnet = lrn("classif.glmnet", predict_type = "prob")
+learner_lda = lrn("classif.lda", predict_type = "prob")To create the learner out-of-bag predictions, we use PipeOpLearnerCV:
cv1_rpart = po("learner_cv", learner_rpart, id = "rprt_1")
+cv1_glmnet = po("learner_cv", learner_glmnet, id = "glmnet_1")
+cv1_lda = po("learner_cv", learner_lda, id = "lda_1")A sparser representation of the input data in level 0 is obtained using the following filters:
+anova = po("filter", flt("anova"), id = "filt1")
+mrmr = po("filter", flt("mrmr"), id = "filt2")
+find_cor = po("filter", flt("find_correlation"), id = "filt3")To summarize these steps into level 0, we use the gunion() function. The out-of-bag predictions of all level 0 learners is attached using PipeOpFeatureUnion along with the original data passed via PipeOpNOP:
level0 = gunion(list(
+ anova %>>% cv1_rpart,
+ mrmr %>>% cv1_glmnet,
+ find_cor %>>% cv1_lda,
+ po("nop", id = "nop1"))) %>>%
+ po("featureunion", id = "union1")We can have a look at the graph from level 0:
+level0$plot(html = FALSE)
Now, we create the level 1 learners:
+cv2_rpart = po("learner_cv", learner_rpart, id = "rprt_2")
+cv2_glmnet = po("learner_cv", learner_glmnet, id = "glmnet_2")
+cv2_lda = po("learner_cv", learner_lda, id = "lda_2")All level 1 learners will use PipeOpPCA transformed data as input:
level1 = level0 %>>%
+ po("copy", 4) %>>%
+ gunion(list(
+ po("pca", id = "pca2_1", param_vals = list(scale. = TRUE)) %>>% cv2_rpart,
+ po("pca", id = "pca2_2", param_vals = list(scale. = TRUE)) %>>% cv2_glmnet,
+ po("pca", id = "pca2_3", param_vals = list(scale. = TRUE)) %>>% cv2_lda,
+ po("nop", id = "nop2"))) %>>%
+ po("featureunion", id = "union2")We can have a look at the graph from level 1:
+level1$plot(html = FALSE)
The out-of-bag predictions of the level 1 learners are attached to the input data from level 1 and a final ranger learner will be trained:
+ranger_lrn = lrn("classif.ranger", predict_type = "prob")
+
+ensemble = level1 %>>% ranger_lrn
+ensemble$plot(html = FALSE)
In order to tune the ensemble’s hyperparameter jointly, we define the search space using ParamSet from the paradox package:
search_space_ensemble = ps(
+ filt1.filter.nfeat = p_int(5, 50),
+ filt2.filter.nfeat = p_int(5, 50),
+ filt3.filter.nfeat = p_int(5, 50),
+ pca2_1.rank. = p_int(3, 50),
+ pca2_2.rank. = p_int(3, 50),
+ pca2_3.rank. = p_int(3, 20),
+ rprt_1.cp = p_dbl(0.001, 0.1),
+ rprt_1.minbucket = p_int(1, 10),
+ glmnet_1.alpha = p_dbl(0, 1),
+ rprt_2.cp = p_dbl(0.001, 0.1),
+ rprt_2.minbucket = p_int(1, 10),
+ glmnet_2.alpha = p_dbl(0, 1),
+ classif.ranger.mtry = p_int(1, 10),
+ classif.ranger.sample.fraction = p_dbl(0.5, 1),
+ classif.ranger.num.trees = p_int(50, 200))Even with a simple ensemble, there is quite a few things to setup. We compare the performance of the ensemble with a simple tuned ranger learner.
To proceed, we convert the ensemble pipeline as a GraphLearner:
learner_ensemble = as_learner(ensemble)
+learner_ensemble$id = "ensemble"
+learner_ensemble$predict_type = "prob"We define the search space for the simple ranger learner:
+search_space_ranger = ps(
+ mtry = p_int(1, 10),
+ sample.fraction = p_dbl(0.5, 1),
+ num.trees = p_int(50, 200))For performance comparison, we use the benchmark() function that requires a design incorporating a list of learners and a list of tasks. Here, we have two learners (the simple ranger learner and the ensemble) and one task. Since we want to tune the simple ranger learner as well as the whole ensemble learner, we need to create an AutoTuner for each learner to be compared. To do so, we need to define a resampling strategy for the tuning in the inner loop (we use 3-fold cross-validation) and for the final evaluation (outer loop) use use holdout validation:
inner_resampling = rsmp("cv", folds = 3)
+
+# AutoTuner for the ensemble learner
+at_1 = auto_tuner(
+ tuner = tnr("random_search"),
+ learner = learner_ensemble,
+ resampling = inner_resampling,
+ measure = msr("classif.auc"),
+ search_space = search_space_ensemble,
+ term_evals = 3) # to limit running time
+
+# AutoTuner for the simple ranger learner
+at_2 = auto_tuner(
+ tuner = tnr("random_search"),
+ learner = ranger_lrn,
+ resampling = inner_resampling,
+ measure = msr("classif.auc"),
+ search_space = search_space_ranger,
+ term_evals = 3) # to limit running time
+
+# Define the list of learners
+learners = list(at_1, at_2)
+
+# For benchmarking, we use a simple holdout
+outer_resampling = rsmp("holdout")
+outer_resampling$instantiate(task_sonar)
+
+design = benchmark_grid(
+ tasks = task_sonar,
+ learners = learners,
+ resamplings = outer_resampling
+)bmr = benchmark(design, store_models = TRUE)Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()
+
+Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $train()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_1's $predict()Warning: Multiple lambdas have been fit. Lambda will be set to 0.01 (see parameter 's').
+This happened PipeOp glmnet_2's $predict()bmr$aggregate(msr("classif.auc"))[, .(nr, task_id, learner_id, resampling_id, iters, classif.auc)]For a more reliable comparison, the number of evaluation of the random search should be increased.
+This example shows the versatility of mlr3pipelines. By using more learners, varied representations of the data set as well as more levels, a powerful yet compute hungry pipeline can be created. It is important to note that care should be taken to avoid name clashes of pipeline objects.
+ + +Transform the target variable.
+ +
+ Transforming the target variable often can lead to predictive improvement and is a widely used tool. Typical transformations are for example the \(\log\) transformation of the target aiming at minimizing (right) skewness, or the Box Cox and Yeo-Johnson transformations being more flexible but having a similar goal.
+One option to perform, e.g., a \(\log\) transformation would be to manually transform the target prior to training a Learner (and also predicting from it) and then manually invert this transformation via \(\exp\) after predicting from the Learner. This is quite cumbersome, especially if a transformation and inverse transformation require information about both the training and prediction data.
In this post, we show how to do various kinds of target transformations using mlr3pipelines and explain the design of the target transformation and inversion PipeOps.
You will:
+learn how to do simple target transformations using PipeOpTargetMutate
be introduced to the abstract base class to implement custom target transformations, PipeOpTargetTrafo
implement a custom target transformation PipeOp, PipeOpTargetTrafoBoxCox
As a prerequisite, you should be quite familiar with mlr3pipelines, i.e, know about the $state field of PipeOps, input and output channels, as well as Graphs. We will start with a PipeOp for simple target transformations, PipeOpTargetMutate.
We load the most important packages for this example.
+library(mlr3)
+library(mlr3learners)
+library(mlr3pipelines)
+library(paradox)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")In all sections we will use the mtcars regression task with mpg being a numerical, positive target:
task = tsk("mtcars")
+summary(task$data(cols = task$target_names)) mpg
+ Min. :10.40
+ 1st Qu.:15.43
+ Median :19.20
+ Mean :20.09
+ 3rd Qu.:22.80
+ Max. :33.90 Moreover, as a Learner we will use an ordinary linear regression learner:
learner_lm = lrn("regr.lm")The term simple refers to transformations that are given by a function of the target, relying on no other arguments (constants are of course allowed). The most prominent example is given by the \(\log\) transformation which we can later invert by applying the \(\exp\) transformation.
+If you are only interested in doing such a transformation and you do not have the time to read more of this post, simply use the following syntactic sugar:
+g_ppl = ppl("targettrafo", graph = learner_lm)
+g_ppl$param_set$values$targetmutate.trafo = function(x) log(x)
+g_ppl$param_set$values$targetmutate.inverter = function(x) list(response = exp(x$response))This constructs a Graph that will \(\log\) transform the target prior to training the linear regression learner (or predicting from it) and \(\exp\) transform the target after predicting from it. Note that you can supply any other Learner or even a whole Graph as the graph argument.
Now, we will go into more detail about how this actually works:
+We can perform a \(\log\) transformation of our numerical, positive target, mpg, using PipeOpTargetMutate (by default, ppl("targettrafo") uses this target transformation PipeOp):
trafo = po("targetmutate", param_vals = list(trafo = function(x) log(x)))We have to specify the trafo parameter as a function of x (which will internally be evaluated to be the target of the Task): trafo = function(x) log(x)). In principle, this is all that is needed to transform the target prior to training a Learner (or predicting from it), i.e., if we now train this PipeOp, we see that the target is transformed as specified:
trafo$train(list(task))$output$data(cols = task$target_names) mpg
+ 1: 3.044522
+ 2: 3.044522
+ 3: 3.126761
+ 4: 3.063391
+ 5: 2.928524
+ 6: 2.895912
+ 7: 2.660260
+ 8: 3.194583
+ 9: 3.126761
+10: 2.954910
+11: 2.879198
+12: 2.797281
+13: 2.850707
+14: 2.721295
+15: 2.341806
+16: 2.341806
+17: 2.687847
+18: 3.478158
+19: 3.414443
+20: 3.523415
+21: 3.068053
+22: 2.740840
+23: 2.721295
+24: 2.587764
+25: 2.954910
+26: 3.306887
+27: 3.258097
+28: 3.414443
+29: 2.760010
+30: 2.980619
+31: 2.708050
+32: 3.063391
+ mpgAfter having predicted from the Learner we could then proceed to apply the inverse transformation function in a similar manner. However, in mlr3pipelines, we decided to go with a more unified design of handling target transformations. In all target transformation PipeOps also the inverse transformation function of the target has to be specified. Therefore, in PipeOpTargetMutate, the parameter inverter also has to be correctly specified:
trafo$param_set$values$inverter = function(x) list(response = exp(x$response))Internally, this function will be applied to the data.table downstream of a Prediction object without the $row_id and $truth columns, and we specify that the $response column should be transformed. Note that applying the inverse transformation will typically only be done to the $response column, because transforming standard errors or probabilities is often not straightforward.
To actually carry out the inverse transformation function after predicting from the Learner, we then rely on PipeOpTargetInvert. PipeOpTargetInvert has an empty ParamSet and its sole purpose is to apply the inverse transformation function after having predicted from a Learner (note that this whole design of target transformations may seem somewhat over-engineered at first glance, however, we will learn of its advantages when we later move to the advanced section).
PipeOpTargetInvert has two input channels named "fun" and "prediction". During training, both take NULL as input (because this is what a Learner’s "output" output and PipeOpTargetMutate’s "fun" output will return during training). During prediction, the "prediction" input takes a Prediction, and the "fun" input takes the "fun" output from PipeOpTargetMutate (you may have noticed already, that PipeOpTargetMutate has actually two outputs, "fun" and "output", with "fun" returning NULL during training and a function during prediction, while "output" always returns the transformed input Task). We can see this, if we look at:
trafo$output name train predict
+1: fun NULL function
+2: output Task Tasktrafo$predict(list(task))$fun
+function(inputs) {
+ assert_list(inputs, len = 1L, types = "Prediction")
+ list(private$.invert(inputs[[1L]], predict_phase_state))
+ }
+<bytecode: 0x555be761be00>
+<environment: 0x555be76215b0>
+
+$output
+<TaskRegr:mtcars> (32 x 11): Motor Trends
+* Target: mpg
+* Properties: -
+* Features (10):
+ - dbl (10): am, carb, cyl, disp, drat, gear, hp, qsec, vs, wtWe will talk more about such technical details in the advanced section. For now, to finally construct our target transformation pipeline, we build a Graph:
g = Graph$new()
+g$add_pipeop(trafo)
+g$add_pipeop(learner_lm)
+g$add_pipeop(po("targetinvert"))Manually connecting the edges is quite cumbersome. First we connect the "output" output of "targetmutate" to the "input" input of "regr.lm":
g$add_edge(src_id = "targetmutate", dst_id = "regr.lm",
+ src_channel = 2, dst_channel = 1)Then we connect the "output" output of "regr.lm" to the "prediction" input of "targetinvert":
g$add_edge(src_id = "regr.lm", dst_id = "targetinvert",
+ src_channel = 1, dst_channel = 2)Finally, we connect the "fun" output of "targetmutate" to the "fun" input of "targetinvert":
g$add_edge(src_id = "targetmutate", dst_id = "targetinvert",
+ src_channel = 1, dst_channel = 1)This graph (which is conceptually the same graph as constructed via the ppl("targettrafo") syntactic sugar above) looks like the following:
g$plot(html = FALSE)![]()
We can then finally call $train() and $predict() (prior to this we wrap the Graph in a GraphLearner):
gl = GraphLearner$new(g)
+gl$train(task)
+gl$state$model
+$model$targetmutate
+list()
+
+$model$regr.lm
+$model$regr.lm$model
+
+Call:
+stats::lm(formula = task$formula(), data = task$data())
+
+Coefficients:
+(Intercept) am carb cyl disp drat gear hp qsec
+ 2.776e+00 4.738e-02 -2.012e-02 7.657e-03 4.989e-05 2.220e-02 5.925e-02 -8.964e-04 3.077e-02
+ vs wt
+ -2.874e-03 -1.723e-01
+
+
+$model$regr.lm$log
+Empty data.table (0 rows and 3 cols): stage,class,msg
+
+$model$regr.lm$train_time
+[1] 0.012
+
+$model$regr.lm$param_vals
+named list()
+
+$model$regr.lm$task_hash
+[1] "6ca8c90cdf732078"
+
+$model$regr.lm$data_prototype
+Empty data.table (0 rows and 11 cols): mpg,am,carb,cyl,disp,drat...
+
+$model$regr.lm$task_prototype
+Empty data.table (0 rows and 11 cols): mpg,am,carb,cyl,disp,drat...
+
+$model$regr.lm$mlr3_version
+[1] '0.16.1'
+
+$model$regr.lm$train_task
+<TaskRegr:mtcars> (32 x 11): Motor Trends
+* Target: mpg
+* Properties: -
+* Features (10):
+ - dbl (10): am, carb, cyl, disp, drat, gear, hp, qsec, vs, wt
+
+
+$model$targetinvert
+list()
+
+
+$log
+Empty data.table (0 rows and 3 cols): stage,class,msg
+
+$train_time
+[1] 0.098
+
+$param_vals
+$param_vals$targetmutate.trafo
+function(x) log(x)
+<bytecode: 0x555be6fb60f0>
+
+$param_vals$targetmutate.inverter
+function(x) list(response = exp(x$response))
+
+
+$task_hash
+[1] "58a137d2055e8406"
+
+$data_prototype
+Empty data.table (0 rows and 11 cols): mpg,am,carb,cyl,disp,drat...
+
+$task_prototype
+Empty data.table (0 rows and 11 cols): mpg,am,carb,cyl,disp,drat...
+
+$mlr3_version
+[1] '0.16.1'
+
+$train_task
+<TaskRegr:mtcars> (32 x 11): Motor Trends
+* Target: mpg
+* Properties: -
+* Features (10):
+ - dbl (10): am, carb, cyl, disp, drat, gear, hp, qsec, vs, wtgl$predict(task)<PredictionRegr> for 32 observations:
+ row_ids truth response
+ 1 21.0 21.67976
+ 2 21.0 21.10831
+ 3 22.8 25.73690
+---
+ 30 19.7 19.58533
+ 31 15.0 14.11015
+ 32 21.4 23.11105and contrast this with $train() and $predict() of the naive linear regression learner (also look at the estimated coefficients of the linear regression contained in $state$model):
learner_lm$train(task)
+learner_lm$state$model
+
+Call:
+stats::lm(formula = task$formula(), data = task$data())
+
+Coefficients:
+(Intercept) am carb cyl disp drat gear hp qsec
+ 12.30337 2.52023 -0.19942 -0.11144 0.01334 0.78711 0.65541 -0.02148 0.82104
+ vs wt
+ 0.31776 -3.71530
+
+
+$log
+Empty data.table (0 rows and 3 cols): stage,class,msg
+
+$train_time
+[1] 0.004
+
+$param_vals
+named list()
+
+$task_hash
+[1] "58a137d2055e8406"
+
+$data_prototype
+Empty data.table (0 rows and 11 cols): mpg,am,carb,cyl,disp,drat...
+
+$task_prototype
+Empty data.table (0 rows and 11 cols): mpg,am,carb,cyl,disp,drat...
+
+$mlr3_version
+[1] '0.16.1'
+
+$train_task
+<TaskRegr:mtcars> (32 x 11): Motor Trends
+* Target: mpg
+* Properties: -
+* Features (10):
+ - dbl (10): am, carb, cyl, disp, drat, gear, hp, qsec, vs, wtlearner_lm$predict(task)<PredictionRegr> for 32 observations:
+ row_ids truth response
+ 1 21.0 22.59951
+ 2 21.0 22.11189
+ 3 22.8 26.25064
+---
+ 30 19.7 19.69383
+ 31 15.0 13.94112
+ 32 21.4 24.36827You should continue reading, if you are interested in more advanced target transformations, i.e., where the transformation and inverse transformation require information about both the training and prediction data.
+First we will introduce the abstract base class for doing target transformations, PipeOpTargetTrafo, from which PipeOpTargetMutate inherits.
No matter how “complicated” the actual target transformation and inverse transformation may be, applying the inverse transformation function after having predicted from a Learner will always be done via PipeOpTargetInvert (as already outlined above, PipeOpTargetInvert has an empty ParamSet and its sole purpose is to apply the inverse transformation function after having predicted from a Learner). All Graphs for doing target transformations will therefore look similar like the simple one above, i.e., a target transformation PipeOp followed by some Learner or a whole Graph, followed by PipeOpTargetInvert. Therefore, using ppl("targettrafo") to construct such Graphs is highly recommended.
To allow for more advanced target transformations, we now have a closer look at the abstract base class, PipeOpTargetTrafo:
PipeOpTargetTrafo has one input channel, named "input" taking a Task both during training and prediction. It’s two output channels are named "fun" and "output". During training "fun" returns NULL and during prediction "fun" returns a function that will be used by PipeOpTargetInvert to perform the inverse target transformation on PipeOpTargetInvert’s "prediction" input. "output" returns the modified input Task both during training and prediction.
Subclasses can overload up to four functions:
+.get_state() takes the input Task and returns a list() which will internally be used to set the $state. Typically it is sensible to make use of the $state during .transform() and .train_invert(). The base implementation returns list() and should be overloaded if setting the state is desired.
.transform() takes the input Task and returns a modified Task (i.e., the Task with the transformed target). This is the main function for doing the actual target transformation. Note that .get_state() is evaluated a single time during training right before .transform() and therefore, you can rely on the $state that has been set. To update the input Task with respect to the transformed target, subclasses should make use of the convert_task() function and drop the original target from the Task. .transform() also accepts a phase argument that will receive "train" during training and "predict" during prediction. This can be used to enable different behavior during training and prediction. .transform() should always be overloaded by subclasses.
.train_invert() takes the input Task and returns a predict_phase_state object. This can be anything. Note that .train_invert() should not modify the input Task. The base implementation returns a list with a single argument, the $truth column of the input Task and should be overloaded if a more training-phase-dependent state is desired.
.invert() takes a Prediction and a predict_phase_state object as inputs and returns a Prediction. This is the main function for specifying the actual inverse target transformation that will later be carried out by PipeOpTargetInvert. Internally a private helper function , .invert_help() will construct the function that will be returned by the "fun" output of PipeOpTargetTrafo so that PipeOpTargetInvert can later simply dispatch this inverse target transformation on its "prediction" input.
The supposed workflow of a class inherited from PipeOpTargetTrafo is given in the following figure:

To solidify our understanding we will design a new target transformation PipeOp in the next section: PipeOpTargetTrafoBoxCox
library(R6)The Box-Cox transformation of a target \(y_{i}\) is given as:
+\[y_{i}(\lambda) = \begin{cases} +\frac{y_{i}^{\lambda} - 1}{\lambda} & \text{if}~\lambda \neq 0; \\ +\log(y_{i}) & \text{if}~\lambda = 0 +\end{cases}\]
+mlr3pipelines already supports the Box-Cox transformation for numerical, positive features, see ?PipeOpBoxCox.
Here we will design a PipeOp to apply the Box-Cox transformation as a target transformation. The \(\lambda\) parameter of the transformation is estimated during training and used for both the training and prediction transformation. After predicting from a Learner we will as always apply the inverse transformation function. To do the actual transformation we will use bestNormalize::boxcox().
First, we inherit from PipeOpTargetTrafo and overload the initialize() function:
PipeOpTargetTrafoBoxCox = R6Class("PipeOpTargetTrafoBoxCox",
+ inherit = PipeOpTargetTrafo,
+ public = list(
+ initialize = function(id = "targettrafoboxcox", param_vals = list()) {
+ param_set = ps(
+ standardize = p_lgl(default = TRUE, tags = c("train", "boxcox")),
+ eps = p_dbl(default = 0.001, lower = 0, tags = c("train", "boxcox")),
+ lower = p_dbl(default = -1L, tags = c("train", "boxcox")),
+ upper = p_dbl(default = 2L, tags = c("train", "boxcox"))
+ )
+ super$initialize(id = id, param_set = param_set, param_vals = param_vals,
+ packages = "bestNormalize", task_type_in = "TaskRegr",
+ task_type_out = "TaskRegr")
+ }
+ ),
+ private = list(
+
+ .get_state = function(task) {
+ ...
+ },
+
+ .transform = function(task, phase) {
+ ...
+ },
+
+ .train_invert = function(task) {
+ ...
+ },
+
+ .invert = function(prediction, predict_phase_state) {
+ ...
+ }
+ )
+)As parameters, we allow "standardize" (whether to center and scale the transformed values to attempt a standard normal distribution), "eps" (tolerance parameter to identify if the \(\lambda\) parameter is equal to zero), "lower" (lower value for the estimation of the \(\lambda\) parameter) and "upper" (upper value for the estimation of the \(\lambda\) parameter). Note that we set task_type_in = "TaskRegr" and task_type_out = "TaskRegr" to specify that this PipeOp only works for regression Tasks.
Second, we overload the four functions as mentioned above.
+We start with .get_state(). We extract the target and apply the Box-Cox transformation to the target. This yields an object of class "boxcox" which we will wrap in a list() and set as the $state (bc$x.t = NULL and bc$x = NULL is done to save some memory because we do not need the transformed original data and original data later):
.get_state = function(task) {
+ target = task$data(cols = task$target_names)[[1L]]
+ bc = mlr3misc::invoke(bestNormalize::boxcox, target,
+ .args = self$param_set$get_values(tags = "boxcox"))
+ bc$x.t = NULL
+ bc$x = NULL
+ list(bc = bc)
+ },Next, we tackle .transform(). This is quite straightforward, because objects of class "boxcox" have their own predict method which we can use here to carry out the actual Box-Cox transformation based on the learned \(\lambda\) parameter as stored in the "boxcox" object in the $state (both during training and prediction). We then rename the target, add it to the task and finally update the task with respect to this new target:
.transform = function(task, phase) {
+ target = task$data(cols = task$target_names)[[1L]]
+ new_target = as.data.table(predict(self$state$bc, newdata = target))
+ colnames(new_target) = paste0(task$target_names, ".bc")
+ task$cbind(new_target)
+ convert_task(task, target = colnames(new_target),
+ drop_original_target = TRUE)
+ },Time to overload .train_invert(). This is even more straightforward, because the prediction method for objects of class "boxcox" directly allows for inverting the transformation via setting the argument inverse = TRUE. Therefore, we only need the "boxcox" object stored in the $state along the $truth column of the input Task (remember that this list will later be available as the predict_phase_state object):
.train_invert = function(task) {
+ list(truth = task$truth(), bc = self$state$bc)
+ },Finally, we overload .invert(). We extract the truth from the predict_phase_state and the response from the Prediction. We then apply the inverse Box-Cox transformation to the response based on the \(\lambda\) parameter and the mean and standard deviation learned during training, relying on the predict_phase_state object. Finally, we construct a new Prediction object:
.invert = function(prediction, predict_phase_state) {
+ truth = predict_phase_state$truth
+ response = predict(predict_phase_state$bc, newdata = prediction$response,
+ inverse = TRUE)
+ PredictionRegr$new(row_ids = prediction$row_ids, truth = truth,
+ response = response)
+ }Note that this PipeOp is ill-equipped to handle the case of predict_type = "se", i.e., we always only return a response prediction (as outlined above, this is the case for most target transformations, because transforming standard errors or probabilities of a prediction is often not straightforward). We could of course check whether the predict_type is set to "se" and if this is the case, return NA as the standard errors.
To construct our final target transformation Graph with our linear regression learner, we again simply make use of ppl("targettrafo"):
g_bc = ppl("targettrafo", graph = learner_lm,
+ trafo_pipeop = PipeOpTargetTrafoBoxCox$new())The following plot should already look quite familiar:
+g_bc$plot(html = FALSE)![]()
Finally we $train() and $predict() on the task (again, we wrap the Graph in a GraphLearner):
gl_bc = GraphLearner$new(g_bc)
+gl_bc$train(task)
+gl_bc$state$model
+$model$regr.lm
+$model$regr.lm$model
+
+Call:
+stats::lm(formula = task$formula(), data = task$data())
+
+Coefficients:
+(Intercept) am carb cyl disp drat gear hp qsec
+ -0.6272999 0.1670950 -0.0663126 0.0237529 0.0002376 0.0759944 0.1963335 -0.0030367 0.1043210
+ vs wt
+ -0.0080166 -0.5800635
+
+
+$model$regr.lm$log
+Empty data.table (0 rows and 3 cols): stage,class,msg
+
+$model$regr.lm$train_time
+[1] 0.007
+
+$model$regr.lm$param_vals
+named list()
+
+$model$regr.lm$task_hash
+[1] "612ab4e0ad596159"
+
+$model$regr.lm$data_prototype
+Empty data.table (0 rows and 11 cols): mpg.bc,am,carb,cyl,disp,drat...
+
+$model$regr.lm$task_prototype
+Empty data.table (0 rows and 11 cols): mpg.bc,am,carb,cyl,disp,drat...
+
+$model$regr.lm$mlr3_version
+[1] '0.16.1'
+
+$model$regr.lm$train_task
+<TaskRegr:mtcars> (32 x 11): Motor Trends
+* Target: mpg.bc
+* Properties: -
+* Features (10):
+ - dbl (10): am, carb, cyl, disp, drat, gear, hp, qsec, vs, wt
+
+
+$model$targettrafoboxcox
+$model$targettrafoboxcox$bc
+Standardized Box Cox Transformation with 32 nonmissing obs.:
+ Estimated statistics:
+ - lambda = 0.02955701
+ - mean (before standardization) = 3.092016
+ - sd (before standardization) = 0.324959
+
+
+$model$targetinvert
+list()
+
+
+$log
+Empty data.table (0 rows and 3 cols): stage,class,msg
+
+$train_time
+[1] 0.075
+
+$param_vals
+named list()
+
+$task_hash
+[1] "58a137d2055e8406"
+
+$data_prototype
+Empty data.table (0 rows and 11 cols): mpg,am,carb,cyl,disp,drat...
+
+$task_prototype
+Empty data.table (0 rows and 11 cols): mpg,am,carb,cyl,disp,drat...
+
+$mlr3_version
+[1] '0.16.1'
+
+$train_task
+<TaskRegr:mtcars> (32 x 11): Motor Trends
+* Target: mpg
+* Properties: -
+* Features (10):
+ - dbl (10): am, carb, cyl, disp, drat, gear, hp, qsec, vs, wtgl_bc$predict(task)<PredictionRegr> for 32 observations:
+ row_ids truth response
+ 1 21.0 21.70854
+ 2 21.0 21.13946
+ 3 22.8 25.75242
+---
+ 30 19.7 19.58934
+ 31 15.0 14.10658
+ 32 21.4 23.15263We could now proceed to benchmark our different target transformations:
+bg = benchmark_grid(list(task), learners = list(learner_lm, gl, gl_bc),
+ resamplings = list(rsmp("cv", folds = 10)))
+bmr = benchmark(bg)bmr$aggregate(msr("regr.mse")) nr task_id learner_id resampling_id iters regr.mse
+1: 1 mtcars regr.lm cv 10 11.866071
+2: 2 mtcars targetmutate.regr.lm.targetinvert cv 10 7.793303
+3: 3 mtcars targettrafoboxcox.regr.lm.targetinvert cv 10 8.230192
+Hidden columns: resample_resultTune and benchmark pipelines.
+The following examples were created as part of the Introduction to Machine Learning Lecture at LMU Munich. The goal of the project was to create and compare one or several machine learning pipelines for the problem at hand together with exploratory analysis and an exposition of results. The posts were contributed to the mlr3gallery by the authors and edited for better legibility by the editor. We want to thank the authors for allowing us to publish their results. Note, that correctness of the results can not be guaranteed.
+This tutorial assumes familiarity with the basics of mlr3tuning and mlr3pipelines. Consult the mlr3book if some aspects are not fully understandable. We load the most important packages for this example.
+library(mlr3verse)
+library(dplyr)
+library(tidyr)
+library(DataExplorer)
+library(ggplot2)
+library(gridExtra)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
+set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")Note, that expensive calculations are pre-saved in rds files in this tutorial to save computational time.
+Machine learning (ML), a branch of both computer science and statistics, in conjunction with new computing technologies has been transforming research and industries across the board over the past decade. A prime example for this is the healthcare industry, where applications of ML, as well as artificial intelligence in general, have become more and more popular in recent years. One very frequently researched and applied use of ML in the medical field is the area of disease identification and diagnosis. ML technologies have shown potential in detecting anomalies and diseases through pattern recognition, even though an entirely digital diagnosis by a computer is probably still something for the far future. However, suitable and reliable models estimating the risk of diseases could help real doctors make quicker and better decisions today already. In this use case we examined machine learning algorithms and learners for the specific application of liver disease detection. The task is therefore a binary classification task to predict whether a patient has liver disease or not based on some common diagnostic measurements. This report is organized as follows. Section 1 introduces the data and section 2 provides more in-depth data exploration. Section 3 presents learners and their hyperparameter tuning while section 4, dealing with model fitting and benchmarking, presents results and conclusions.
+The data set we used for our project is the “Indian Liver Patient Dataset” which was obtained from the mlr3data package. It was donated by three professors from India in 2012 “UCI Machine Learning Repository” (n.d.).
+# Importing data
+data("ilpd", package = "mlr3data")It contains data for 583 patients collected in the north east of Andhra Pradesh, one of the 28 states of India. The observations are divided into two classes based on the patient having liver disease or not. Besides the class variable, which is our target, ten, mostly numerical, features are provided. To describe the features in more detail, the table below lists the variables included in the dataset.
+| Variable | +Description | +
|---|---|
| age | +Age of the patient (all patients above 89 are labelled as 90 | +
| gender | +Sex of the patient (1 = female, 0 = male) | +
| total_bilirubin | +Total serum bilirubin (in mg/dL) | +
| direct_bilirubin | +Direct bilirubin level (in mg/dL) | +
| alkaline_phosphatase | +Serum alkaline phosphatase level (in U/L) | +
| alanine_transaminase | +Serum alanine transaminase level (in U/L) | +
| aspartate_transaminase | +Serum aspartate transaminase level (in U/L) | +
| total_protein | +Total serum protein (in g/dL) | +
| albumin | +Serum albumin level (in g/dL) | +
| albumin_globulin_ratio | +Albumin-to-globulin ratio | +
| diseased | +Target variable (1 = liver disease, 0 = no liver disease) | +
As one can see, besides age and gender, the dataset contains eight additional numerical features. While the names and corresponding measurements look rather cryptic to the uninformed eye, they are all part of standard blood tests conducted to gather information about the state of a patient’s liver, so-called liver function tests. All of these measurements are frequently used markers for liver disease. For the first five, measuring the chemical compound bilirubin and the three enzymes alkaline phosphatase, alanine transaminase and aspartate transaminase, elevated levels indicate liver disease Gowda et al. (2009) Oh and Hustead (2011). For the remaining three, which concern protein levels, lower-than-normal values suggest a liver problem Carvalho and Machado (2018) “Total Protein, Albumin-Globulin (A/G) Ratio” (n.d.). Lastly, one should note that some of the measurements are part of more than one variable. For example, the total serum bilirubin is simply the sum of both the direct and indirect bilirubin levels and the amount of albumin is used to calculate the values of the total serum protein as well as the albumin-to-globulin ratio. So, one might already suspect that some of the features are highly correlated to one another, but more on that kind of analysis in the following section.
+Next, we looked into the univariate distribution of each of the variables. We began with the target and the only discrete feature, gender, which are both binary.
+
The distribution of the target variable is quite imbalanced, as the barplot shows: the number of patients with and without liver disease equals 416 and 167, respectively. The underrepresentation of a class, in our case those without liver disease, might worsen the performance of ML models. In order to examine this, we additionally fitted the models on a dataset where we randomly over-sampled the minority class, resulting in a perfectly balanced dataset. Furthermore, we applied stratified sampling to ensure the proportion of the classes is maintained during cross-validation.
+The only discrete feature gender is quite imbalanced, too. As one can see in the next section, this proportion is also observed within each target class. Prior to that, we looked into the distributions of the metric features.
+
Strikingly, some of the metric features are extremely right-skewed and contain several extreme values. To reduce the impact of outliers and since some models assume normality of features, we log-transformed these variables.
+To picture the relationship between the target and the features, we analysed the distributions of the features by class. First, we examined the discrete feature gender.
+
The percentage of males in the “disease” class is slightly higher, but overall the difference is small. Besides that, the gender imbalance can be observed in both classes, as we mentioned before. To see the differences in metric features, we compare the following boxplots, where right-skewed features are not log-transformed yet.
+
Except for the total amount of protein, for each feature we obtain differences between the median values of the two classes. Notably, in the case of strongly right-skewed features the “disease” class contains far more extreme values than the “no disease” class, which is probably because of its larger size. This effect is weakened by log-transforming such features, as can be seen in the boxplots below. Moreover, the dispersion in the class “disease” is greater for these features, as the length of the boxes indicates. Overall, the features seem to be correlated to the target, so it makes sense to use them for this task and model their relationship with the target.
+
Note, that the same result can be achieved more easily by using PipeOpMutate from mlr3pipelines. This PipeOp provides a smooth implementation to scale numeric features for mlr3 tasks.
As we mentioned in the description of the data, there are features that are indirectly measured by another one. This suggests that they are highly correlated. Some of the models we want to compare assume independent features or have problems with multicollinearity. Therefore, we checked for correlations between features.
+Registered S3 method overwritten by 'GGally':
+ method from
+ +.gg ggplot2Warning in cor(data, use = method[1], method = method[2]): the standard deviation is zero
For four of the pairs we obtained a very high correlation coefficient. Looking at these features, it is clear they affect each other. As the complexity of the model should be minimized and due to multicollinearity concerns, we decided to take only one of each pair. When deciding on which features to keep, we chose those that are more specific and relevant regarding liver disease. Therefore, we chose albumin over the ratio between albumin and globulin and also over the total amount of protein. The same argument applies to using the amount of direct bilirubin instead of the total amount of bilirubin. Regarding aspartate transaminase and alanine transaminase, it was not clear which one to use, especially since we have no given real world implementation for the task and no medical training. Since we did not notice any fundamental differences in the data for these two features, we arbitrarily chose aspartate transaminase.
+## Reducing, transforming and scaling dataset
+ilpd = ilpd %>%
+ select(-total_bilirubin, -alanine_transaminase, -total_protein,
+ -albumin_globulin_ratio) %>%
+ mutate(
+ # Recode gender
+ gender = as.numeric(ifelse(gender == "Female", 1, 0)),
+ # Remove labels for class
+ diseased = factor(ifelse(diseased == "yes", 1, 0)),
+ # Log for features with skewed distributions
+ alkaline_phosphatase = log(alkaline_phosphatase),
+ aspartate_transaminase = log(aspartate_transaminase),
+ direct_bilirubin = log(direct_bilirubin)
+ )
+
+po_scale = po("scale")
+po_scale$param_set$values$affect_columns =
+ selector_name(c("age", "direct_bilirubin", "alkaline_phosphatase",
+ "aspartate_transaminase", "albumin"))Lastly, we standardized all metric features, as different ranges and units might weigh features. This is especially important for the k-NN model. The following table shows the final dataset and the transformations we applied. Note: Different from log or other transformation, scaling depends on the data themselves. Scaling data before data are split leads to data leakage, were information of train and test set are shared. As Data Leakage causes higher performance, scaling should always be applied in each data split induced by the ML workflow separately. Therefore we strongly recommend the usage of PipeOpScale in such cases.
| Variable | +Transformation | +
|---|---|
| age | +scaled | +
| albumin | +scaled | +
| alkaline_phosphatase | +scaled and log-transformed | +
| aspartate_transaminase | +scaled and log-transformed | +
| direct_bilirubin | +scaled and log-transformed | +
| diseased | +none | +
| gender | +none | +
First, we need to define a task which contains the final dataset and some meta information. Further we need to specify the positive class since the package takes the first one as the positive class by default. The specification of the positive class has an impact on the evaluation later on.
+## Task definition
+task_liver = as_task_classif(ilpd, target = "diseased", positive = "1")In the following we are going to evaluate logistic regression, linear discriminant analysis (LDA), quadratic discriminant analysis (QDA), naive Bayes, k-nearest neighbour (k-NN), classification trees (CART) and random forest on the binary target.
+## Learner definition
+# Use predict type "prob" for the AUC score. Predict on train and test sets to
+# detect overfitting
+
+learners = list(
+ learner_logreg = lrn("classif.log_reg", predict_type = "prob",
+ predict_sets = c("train", "test")),
+ learner_lda = lrn("classif.lda", predict_type = "prob",
+ predict_sets = c("train", "test")),
+ learner_qda = lrn("classif.qda", predict_type = "prob",
+ predict_sets = c("train", "test")),
+ learner_nb = lrn("classif.naive_bayes", predict_type = "prob",
+ predict_sets = c("train", "test")),
+ learner_knn = lrn("classif.kknn", scale = FALSE,
+ predict_type = "prob"),
+ learner_rpart = lrn("classif.rpart",
+ predict_type = "prob"),
+ learner_rf = lrn("classif.ranger", num.trees = 1000,
+ predict_type = "prob")
+)In order to find optimal hyperparameters through tuning, we used random search to better cover the hyperparameter space. We define the hyperparameters to tune. We only tuned hyperparameters for k-NN, CART and random forest since the other methods have strong assumptions and serve as baseline. The following table shows the assumptions of the methods we chose.
+| Learners | +Assumption | +
|---|---|
| Logistic regression | +No (or little) multicollinearity among features | +
| Linear discriminant analysis | +Normality of classes, equal covariance (target) | +
| Quadratic discriminant analysis | +Normality of classes | +
| Naive Bayes | +Conditional independence of features | +
| CART | +None | +
| k-NN | +None | +
| Random forest | +None | +
The following table shows the hyperparameters we tuned.
+| Learner | +Hyperparameters | +
|---|---|
| k-NN | +k, distance, kernel | +
| CART | +minsplit, cp | +
| Random forest | +min.node.size, mtry | +
For k-NN we chose 3 as the lower limit and 50 as the upper limit for k (number of neighbors). A too small k can lead to overfitting. We also tried different distance measures (e.g. 1 for Manhattan distance, 2 for Euclidean distance) and kernels. For CART we tuned the hyperparameters cp (complexity parameter) and minsplit (minimum number of observations in a node in order to attempt a split). cp controls the size of the tree: small values can result in overfitting while large values can cause underfitting. We also tuned parameters for the minimum size of terminal nodes and the number of variables randomly sampled as candidates at each split (from 1 to number of features) for random forest.
tune_ps_knn = ps(
+ k = p_int(lower = 3, upper = 50), # Number of neighbors considered
+ distance = p_dbl(lower = 1, upper = 3),
+ kernel = p_fct(levels = c("rectangular", "gaussian", "rank", "optimal"))
+)
+tune_ps_rpart = ps(
+ # Minimum number of observations that must exist in a node in order for a
+ # split to be attempted
+ minsplit = p_int(lower = 10, upper = 40),
+ cp = p_dbl(lower = 0.001, upper = 0.1) # Complexity parameter
+)
+tune_ps_rf = ps(
+ # Minimum size of terminal nodes
+ min.node.size = p_int(lower = 10, upper = 50),
+ # Number of variables randomly sampled as candidates at each split
+ mtry = p_int(lower = 1, upper = 6)
+)The next step is to instantiate the AutoTuner from mlr3tuning. We employed 5-fold cross-validation for the inner loop of the nested resampling. The number of evaluations was set to 100 as the stopping criterion. As an evaluation metric we used AUC.
+# AutoTuner for k-NN, CART and random forest
+learners$learner_knn = auto_tuner(
+ tuner = tnr("random_search"),
+ learner = learners$learner_knn,
+ resampling = rsmp("cv", folds = 5L),
+ measure = msr("classif.auc"),
+ search_space = tune_ps_knn,
+ term_evals = 100,
+)
+learners$learner_knn$predict_sets = c("train", "test")
+
+learners$learner_rpart = auto_tuner(
+ tuner = tnr("random_search"),
+ learner = learners$learner_rpart,
+ resampling = rsmp("cv", folds = 5L),
+ measure = msr("classif.auc"),
+ search_space = tune_ps_rpart,
+ term_evals = 100,
+)
+learners$learner_rpart$predict_sets = c("train", "test")
+
+learners$learner_rf = auto_tuner(
+ tuner = tnr("random_search"),
+ learner = learners$learner_rf,
+ resampling = rsmp("cv", folds = 5L),
+ measure = msr("classif.auc"),
+ search_space = tune_ps_rf,
+ term_evals = 100,
+)
+learners$learner_rf$predict_sets = c("train", "test")During our research we found that oversampling can potentially increase the performance of the learners. As mentioned in section 2.2, we opted for perfectly balancing the classes. By using mlr3pipelines we can apply the benchmark function later on.
+# Oversampling minority class to get perfectly balanced classes
+po_over = po("classbalancing", id = "oversample", adjust = "minor",
+ reference = "minor", shuffle = FALSE, ratio = 416/167)
+table(po_over$train(list(task_liver))$output$truth()) # Check class balance
+ 1 0
+416 416 # Learners with balanced/oversampled data
+learners_bal = lapply(learners, function(x) {
+ GraphLearner$new(po_scale %>>% po_over %>>% x)
+})
+lapply(learners_bal, function(x) x$predict_sets = c("train", "test"))With the learners defined, the inner method of the nested resampling chosen and the tuners set up, we proceeded to choose the outer resampling method. We opted for stratified 5-fold cross-validation to maintain the distribution of the target variable, independent of oversampling. However, it turned out that normal cross-validation without stratification yields very similar results.
+# 5-fold cross-validation
+resampling_outer = rsmp(id = "cv", .key = "cv", folds = 5L)
+
+# Stratification
+task_liver$col_roles$stratum = task_liver$target_namesTo rank the different learners and finally decide which one fits best for the task at hand, we used benchmarking. The following code chunk executes our benchmarking with all learners.
+design = benchmark_grid(
+ tasks = task_liver,
+ learners = c(learners, learners_bal),
+ resamplings = resampling_outer
+)
+
+bmr = benchmark(design, store_models = FALSE)As mentioned above, stratified 5-fold cross-validation was chosen. This means that performance is determined as the average across five model evaluations with a train-test-split of 80% to 20%. Furthermore, the choice of performance metrics is crucial in ranking different learners. While each one of them has its specific use case, we opted for AUC, a performance metric taking into account both sensitivity and specificity, which we also used for hyperparameter tuning.
+We first present a comparison of all learners by AUC, with and without oversampling, and for both training and test data.
+ learner_id auc_train auc_test
+ 1: classif.log_reg 0.7555646 0.7416606
+ 2: classif.lda 0.7555611 0.7390708
+ 3: classif.qda 0.7697367 0.7347738
+ 4: classif.naive_bayes 0.7539943 0.7457096
+ 5: classif.kknn.tuned 0.8876589 0.7323200
+ 6: classif.rpart.tuned 0.8045344 0.6627003
+ 7: classif.ranger.tuned 0.9535820 0.7421109
+ 8: scale.oversample.classif.log_reg 0.7556586 0.7434089
+ 9: scale.oversample.classif.lda 0.7547323 0.7434744
+10: scale.oversample.classif.qda 0.7678794 0.7340827
+11: scale.oversample.classif.naive_bayes 0.7537216 0.7441955
+12: scale.oversample.classif.kknn.tuned 1.0000000 0.7026322
+13: scale.oversample.classif.rpart.tuned 0.8611873 0.6250559
+14: scale.oversample.classif.ranger.tuned 1.0000000 0.7433473As can be seen in the results above, regardless of whether oversampling was applied or not, logistic regression, LDA, QDA, and naive Bayes have very similar performance on training and test data. On the other hand, k-NN, CART and random forest predict much better on the training data, indicating overfitting.
+Furthermore, oversampling leaves AUC performance almost untouched for all learners.
+The boxplots below graphically summarize AUC performance of all learners, with the blue dots indicating mean AUC performance.
+Warning: The `fun.y` argument of `stat_summary()` is deprecated as of ggplot2 3.3.0.
+ℹ Please use the `fun` argument instead.
Random forest is the learner with the best AUC performance, both with and without oversampling. Whereas mean AUC is roughly between 0.65 and 0.75 for all learners, the individual components of AUC might differ substantially.
+As a first step towards “AUC decomposition”, we consider the ROC curve, which provides valuable graphical insights into performance - even more so since AUC is directly derived from it.
+Subsequently, sensitivity, specificity, false negative rate (FNR), and false positive rate (FPR) for each learner are shown explicitly in the output below, next to AUC.
+ learner_id classif.auc classif.sensitivity classif.specificity classif.fnr classif.fpr
+ 1: classif.log_reg 0.7416606 0.8920252 0.2452763 0.10797476 0.7547237
+ 2: classif.lda 0.7390708 0.9135972 0.1673797 0.08640275 0.8326203
+ 3: classif.qda 0.7347738 0.6875215 0.6709447 0.31247849 0.3290553
+ 4: classif.naive_bayes 0.7457096 0.6393574 0.7606061 0.36064257 0.2393939
+ 5: classif.kknn.tuned 0.7323200 0.8339931 0.3896613 0.16600688 0.6103387
+ 6: classif.rpart.tuned 0.6627003 0.8436317 0.1982175 0.15636833 0.8017825
+ 7: classif.ranger.tuned 0.7421109 0.9422834 0.1315508 0.05771658 0.8684492
+ 8: scale.oversample.classif.log_reg 0.7434089 0.6202524 0.7609626 0.37974756 0.2390374
+ 9: scale.oversample.classif.lda 0.7434744 0.5865175 0.7848485 0.41348250 0.2151515
+10: scale.oversample.classif.qda 0.7340827 0.5552209 0.8267380 0.44477912 0.1732620
+11: scale.oversample.classif.naive_bayes 0.7441955 0.5407917 0.8386809 0.45920826 0.1613191
+12: scale.oversample.classif.kknn.tuned 0.7026322 0.7281985 0.5254902 0.27180149 0.4745098
+13: scale.oversample.classif.rpart.tuned 0.6250559 0.6032702 0.6060606 0.39672978 0.3939394
+14: scale.oversample.classif.ranger.tuned 0.7433473 0.7548480 0.5327986 0.24515204 0.4672014As it turned out, without oversampling logistic regression, LDA, k-NN, CART, and random forest score very high on sensitivity and rather low on specificity; QDA and naive Bayes, on the other hand, score relatively high on specificity, but not as high on sensitivity. By definition, high sensitivity (specificity) results from a low false negative (positive) rate, which is also represented in the data.
+With oversampling, specificity increases at the cost of sensitivity for all learners (even for those which already had high specificity), as can be seen in the two graphs below.
+For a given learner, say random forest, the different performance metrics and their dependence upon target variable balance are shown in the following graph.
+To get a look at performance from yet another angle, we next considered the confusion matrix for each learner, which simply contrasts the absolute numbers of predictions and true values by category, with and without oversampling. You can have a look at all the confusion matrices, if you run the script.
+The confusion matrices confirm the above conclusions: without oversampling, all learners (except QDA and naive Bayes) display very high numbers of true positives, but also of false positives, implying high sensitivity and low specificity. Also note that a trivial model classifying all individuals as “1” would cause fewer misclassifications than all of our models except random forest, casting doubt on the predictive power of the features in our dataset. Regarding learner performance with oversampling, the confusion matrices add another valuable insight:
+The final decision regarding which learner works best - and also whether oversampling should be used or not - strongly depends on the real world implications of sensitivity and specificity. One of the two might outweigh the other many times over in terms of practical importance. Think of the typical HIV rapid diagnostic test example, where high sensitivity at the cost of low specificity might cause an (unwarranted) shock but is otherwise not dangerous, whereas low sensitivity would be highly perilous. As is usually the case, no black and white “best model” exists here - recall that, even with oversampling, none of our models perform well on both sensitivity and specificity. In our case, we would need to ask ourselves: what would be the consequences of high specificity at the cost of low sensitivity, which implies telling many patients with a liver disease that they are healthy; versus what would be the consequences of high sensitivity at the cost of low specificity, which would mean telling many healthy patients they have a liver disease. In absence of further topic-specific information, we can only state the best-performing learners for the particular performance metric chosen. As mentioned above, random forest performs best based on AUC. Random forest is furthermore the learner with the highest sensitivity score (and the lowest FNR), while naive Bayes is the one with the best specificity (and the lowest FPR) These results - and the ranking of learners in general, independent of the performance metric - are not affected by oversampling.
+The analysis we conducted is, however, by no means exhaustive. On the feature level, while we focused almost exclusively on the machine learning and statistical analysis aspect during our analysis, one could also dig deeper into the actual topic (liver disease) and try to understand the variables as well as potential correlations and interactions more thoroughly. This might also mean to consider already thrown out variables again. Furthermore, feature engineering as well as data preprocessing, for instance using principal component analysis, could be applied to the dataset. Regarding hyperparameter tuning, different hyperparameters with larger hyperparameter spaces and numbers of evaluations could be considered. Furthermore, tuning could also be applied to some of those learners that we labeled as baseline learners, though to a lesser extent. Finally, we limited ourselves to those classifiers discussed in detail in the course. More classifiers exist, however; in particular, gradient boosting and support vector machines could additionally be applied to this task and potentially yield better results.
+ + + +Tune a preprocessing pipeline and multiple tuners at once.
+
+ # include: false
+requireNamespace("bst")Loading required namespace: bstrequireNamespace("fastICA")Loading required namespace: fastICAIn this use case we show how to tune a rather complex graph consisting of different preprocessing steps and different learners where each preprocessing step and learner itself has parameters that can be tuned. You will learn the following:
+Graph that consists of two common preprocessing steps, then switches between two dimensionality reduction techniques followed by a Learner vs. no dimensionality reduction followed by another Learnergrid search to find an optimal choice of preprocessing steps and hyperparameters.Ideally you already had a look at how to tune over multiple learners.
+First, we load the packages we will need:
+library(mlr3verse)
+library(mlr3learners)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
+lgr::get_logger("mlr3")$set_threshold("warn")
+lgr::get_logger("bbotk")$set_threshold("warn")We are going to work with some gene expression data included as a supplement in the bst package. The data consists of 2308 gene profiles in 63 training and 20 test samples. The following data preprocessing steps are done analogously as in vignette("khan", package = "bst"):
datafile = system.file("extdata", "supplemental_data", package = "bst")
+dat0 = read.delim(datafile, header = TRUE, skip = 1)[, -(1:2)]
+dat0 = t(dat0)
+dat = data.frame(dat0[!(rownames(dat0) %in%
+ c("TEST.9", "TEST.13", "TEST.5", "TEST.3", "TEST.11")), ])
+dat$class = as.factor(
+ c(substr(rownames(dat)[1:63], start = 1, stop = 2),
+ c("NB", "RM", "NB", "EW", "RM", "BL", "EW", "RM", "EW", "EW", "EW", "RM",
+ "BL", "RM", "NB", "NB", "NB", "NB", "BL", "EW")
+ )
+)We then construct our training and test Task :
task = as_task_classif(dat, target = "class", id = "SRBCT")
+task_train = task$clone(deep = TRUE)
+task_train$filter(1:63)
+task_test = task$clone(deep = TRUE)
+task_test$filter(64:83)Our graph will start with log transforming the features, followed by scaling them. Then, either a PCA or ICA is applied to extract principal / independent components followed by fitting a LDA or a ranger random forest is fitted without any preprocessing (the log transformation and scaling should most likely affect the LDA more than the ranger random forest). Regarding the PCA and ICA, both the number of principal / independent components are tuning parameters. Regarding the LDA, we can further choose different methods for estimating the mean and variance and regarding the ranger, we want to tune the mtry and num.tree parameters. Note that the PCA-LDA combination has already been successfully applied in different cancer diagnostic contexts when the feature space is of high dimensionality (Morais and Lima 2018).
To allow for switching between the PCA / ICA-LDA and ranger we can either use branching or proxy pipelines, i.e., PipeOpBranch and PipeOpUnbranch or PipeOpProxy. We will first cover branching in detail and later show how the same can be done using PipeOpProxy.
First, we have a look at the baseline classification accuracy of the LDA and ranger on the training task:
base = benchmark(benchmark_grid(
+ task_train,
+ learners = list(lrn("classif.lda"), lrn("classif.ranger")),
+ resamplings = rsmp("cv", folds = 3)))Warning in lda.default(x, grouping, ...): variables are collinear
+
+Warning in lda.default(x, grouping, ...): variables are collinear
+
+Warning in lda.default(x, grouping, ...): variables are collinearbase$aggregate(measures = msr("classif.acc")) nr task_id learner_id resampling_id iters classif.acc
+1: 1 SRBCT classif.lda cv 3 0.6666667
+2: 2 SRBCT classif.ranger cv 3 0.9206349
+Hidden columns: resample_resultThe out-of-the-box ranger appears to already have good performance on the training task. Regarding the LDA, we do get a warning message that some features are colinear. This strongly suggests to reduce the dimensionality of the feature space. Let’s see if we can get some better performance, at least for the LDA.
Our graph starts with log transforming the features (we explicitly use base 10 only for better interpretability when inspecting the model later), using PipeOpColApply, followed by scaling the features using PipeOpScale. Then, the first branch allows for switching between the PCA / ICA-LDA and ranger, and within PCA / ICA-LDA, the second branch allows for switching between PCA and ICA:
graph1 =
+ po("colapply", applicator = function(x) log(x, base = 10)) %>>%
+ po("scale") %>>%
+ # pca / ica followed by lda vs. ranger
+ po("branch", id = "branch_learner", options = c("pca_ica_lda", "ranger")) %>>%
+ gunion(list(
+ po("branch", id = "branch_preproc_lda", options = c("pca", "ica")) %>>%
+ gunion(list(
+ po("pca"), po("ica")
+ )) %>>%
+ po("unbranch", id = "unbranch_preproc_lda") %>>%
+ lrn("classif.lda"),
+ lrn("classif.ranger")
+ )) %>>%
+ po("unbranch", id = "unbranch_learner")Note that the names of the options within each branch are arbitrary, but ideally they describe what is happening. Therefore we go with "pca_ica_lda" / "ranger” and "pca" / "ica". Finally, we also could have used the branch ppl to make branching easier (we will come back to this in the Proxy section). The graph looks like the following:
graph1$plot(html = FALSE)
We can inspect the parameters of the ParamSet of the graph to see which parameters can be set:
graph1$param_set$ids() [1] "colapply.applicator" "colapply.affect_columns"
+ [3] "scale.center" "scale.scale"
+ [5] "scale.robust" "scale.affect_columns"
+ [7] "branch_learner.selection" "branch_preproc_lda.selection"
+ [9] "pca.center" "pca.scale."
+[11] "pca.rank." "pca.affect_columns"
+[13] "ica.n.comp" "ica.alg.typ"
+[15] "ica.fun" "ica.alpha"
+[17] "ica.method" "ica.row.norm"
+[19] "ica.maxit" "ica.tol"
+[21] "ica.verbose" "ica.w.init"
+[23] "ica.affect_columns" "classif.lda.dimen"
+[25] "classif.lda.method" "classif.lda.nu"
+[27] "classif.lda.predict.method" "classif.lda.predict.prior"
+[29] "classif.lda.prior" "classif.lda.tol"
+[31] "classif.ranger.alpha" "classif.ranger.always.split.variables"
+[33] "classif.ranger.class.weights" "classif.ranger.holdout"
+[35] "classif.ranger.importance" "classif.ranger.keep.inbag"
+[37] "classif.ranger.max.depth" "classif.ranger.min.node.size"
+[39] "classif.ranger.min.prop" "classif.ranger.minprop"
+[41] "classif.ranger.mtry" "classif.ranger.mtry.ratio"
+[43] "classif.ranger.num.random.splits" "classif.ranger.num.threads"
+[45] "classif.ranger.num.trees" "classif.ranger.oob.error"
+[47] "classif.ranger.regularization.factor" "classif.ranger.regularization.usedepth"
+[49] "classif.ranger.replace" "classif.ranger.respect.unordered.factors"
+[51] "classif.ranger.sample.fraction" "classif.ranger.save.memory"
+[53] "classif.ranger.scale.permutation.importance" "classif.ranger.se.method"
+[55] "classif.ranger.seed" "classif.ranger.split.select.weights"
+[57] "classif.ranger.splitrule" "classif.ranger.verbose"
+[59] "classif.ranger.write.forest" The id’s are prefixed by the respective PipeOp they belong to, e.g., pca.rank. refers to the rank. parameter of PipeOpPCA.
Our graph either fits a LDA after applying PCA or ICA, or alternatively a ranger with no preprocessing. These two options each define selection parameters that we can tune. Moreover, within the respective PipeOp’s we want to tune the following parameters: pca.rank., ica.n.comp, classif.lda.method, classif.ranger.mtry, and classif.ranger.num.trees. The first two parameters are integers that in-principal could range from 1 to the number of features. However, for ICA, the upper bound must not exceed the number of observations and as we will later use 3-fold cross-validation as the resampling method for the tuning, we just set the upper bound to 30 (and do the same for PCA). Regarding the classif.lda.method we will only be interested in "moment" estimation vs. minimum volume ellipsoid covariance estimation ("mve"). Moreover, we set the lower bound of classif.ranger.mtry to 200 (which is around the number of features divided by 10) and the upper bound to 1000.
tune_ps1 = ps(
+ branch_learner.selection =
+ p_fct(c("pca_ica_lda", "ranger")),
+ branch_preproc_lda.selection =
+ p_fct(c("pca", "ica"), depends = branch_learner.selection == "pca_ica_lda"),
+ pca.rank. =
+ p_int(1, 30, depends = branch_preproc_lda.selection == "pca"),
+ ica.n.comp =
+ p_int(1, 30, depends = branch_preproc_lda.selection == "ica"),
+ classif.lda.method =
+ p_fct(c("moment", "mve"), depends = branch_preproc_lda.selection == "ica"),
+ classif.ranger.mtry =
+ p_int(200, 1000, depends = branch_learner.selection == "ranger"),
+ classif.ranger.num.trees =
+ p_int(500, 2000, depends = branch_learner.selection == "ranger"))The parameter branch_learner.selection defines whether we go down the left (PCA / ICA followed by LDA) or the right branch (ranger). The parameter branch_preproc_lda.selection defines whether a PCA or ICA will be applied prior to the LDA. The other parameters directly belong to the ParamSet of the PCA / ICA / LDA / ranger. Note that it only makes sense to switch between PCA / ICA if the "pca_ica_lda" branch was selected beforehand. We have to specify this via the depends parameter.
Finally, we also could have proceeded to tune the numeric parameters on a log scale. I.e., looking at pca.rank. the performance difference between rank 1 and 2 is probably much larger than between rank 29 and rank 30. The mlr3tuning Tutorial covers such transformations.
We can now tune the parameters of our graph as defined in the search space with respect to a measure. We will use the classification accuracy. As a resampling method we use 3-fold cross-validation. We will use the TerminatorNone (i.e., no early termination) for terminating the tuning because we will apply a grid search (we use a grid search because it gives nicely plottable and understandable results but if there were much more parameters, random search or more intelligent optimization methods would be preferred to a grid search:
tune1 = TuningInstanceSingleCrit$new(
+ task_train,
+ learner = graph1,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.acc"),
+ search_space = tune_ps1,
+ terminator = trm("none")
+)We then perform a grid search using a resolution of 4 for the numeric parameters. The grid being used will look like the following (note that the dependencies we specified above are handled automatically):
generate_design_grid(tune_ps1, resolution = 4)We trigger the tuning.
+tuner_gs = tnr("grid_search", resolution = 4, batch_size = 10)
+tuner_gs$optimize(tune1) branch_learner.selection branch_preproc_lda.selection pca.rank. ica.n.comp classif.lda.method classif.ranger.mtry
+1: pca_ica_lda ica NA 10 mve NA
+ classif.ranger.num.trees learner_param_vals x_domain classif.acc
+1: NA <list[8]> <list[4]> 0.984127Now, we can inspect the results ordered by the classification accuracy:
as.data.table(tune1$archive)[order(classif.acc), ]We achieve very good accuracy using ranger, more or less regardless how mtry and num.trees are set. However, the LDA also shows very good accuracy when combined with PCA or ICA retaining 30 components.
For now, we decide to use ranger with mtry set to 200 and num.trees set to 1000.
Setting these parameters manually in our graph, then training on the training task and predicting on the test task yields an accuracy of:
+graph1$param_set$values$branch_learner.selection = "ranger"
+graph1$param_set$values$classif.ranger.mtry = 200
+graph1$param_set$values$classif.ranger.num.trees = 1000
+graph1$train(task_train)$unbranch_learner.output
+NULLgraph1$predict(task_test)[[1L]]$score(msr("classif.acc"))classif.acc
+ 1 Note that we also could have wrapped our graph in a GraphLearner and proceeded to use this as a learner in an AutoTuner.
Instead of using branches to split our graph with respect to the learner and preprocessing options, we can also use PipeOpProxy. PipeOpProxy accepts a single content parameter that can contain any other PipeOp or Graph. This is extremely flexible in the sense that we do not have to specify our options during construction. However, the parameters of the contained PipeOp or Graph are no longer directly contained in the ParamSet of the resulting graph. Therefore, when tuning the graph, we do have to make use of a trafo function.
graph2 =
+ po("colapply", applicator = function(x) log(x, base = 10)) %>>%
+ po("scale") %>>%
+ po("proxy")This graph now looks like the following:
+graph2$plot(html = FALSE)
At first, this may look like a linear graph. However, as the content parameter of PipeOpProxy can be tuned and set to contain any other PipeOp or Graph, this will allow for a similar non-linear graph as when doing branching.
graph2$param_set$ids()[1] "colapply.applicator" "colapply.affect_columns" "scale.center" "scale.scale"
+[5] "scale.robust" "scale.affect_columns" "proxy.content" We can tune the graph by using the same search space as before. However, here the trafo function is of central importance to actually set our options and parameters:
tune_ps2 = tune_ps1$clone(deep = TRUE)The trafo function does all the work, i.e., selecting either the PCA / ICA-LDA or ranger as the proxy.content as well as setting the parameters of the respective preprocessing PipeOps and Learners.
proxy_options = list(
+ pca_ica_lda =
+ ppl("branch", graphs = list(pca = po("pca"), ica = po("ica"))) %>>%
+ lrn("classif.lda"),
+ ranger = lrn("classif.ranger")
+)Above, we made use of the branch ppl allowing us to easily construct a branching graph. Of course we also could have use another nested PipeOpProxy to specify the preprocessing options ("pca" vs. "ica") within proxy_options if for some reason we do not want to do branching at all. The trafo function below selects one of the proxy_options from above and sets the respective parameters for the PCA, ICA, LDA and ranger. Here, the argument x is a list which will contain sampled / selected parameters from our ParamSet (in our case, tune_ps2). The return value is a list only including the appropriate proxy.content parameter. In each tuning iteration, the proxy.content parameter of our graph will be set to this value.
tune_ps2$trafo = function(x, param_set) {
+ proxy.content = proxy_options[[x$branch_learner.selection]]
+ if (x$branch_learner.selection == "pca_ica_lda") {
+ # pca_ica_lda
+ proxy.content$param_set$values$branch.selection = x$branch_preproc_lda.selection
+ if (x$branch_preproc_lda.selection == "pca") {
+ proxy.content$param_set$values$pca.rank. = x$pca.rank.
+ } else {
+ proxy.content$param_set$values$ica.n.comp = x$ica.n.comp
+ }
+ proxy.content$param_set$values$classif.lda.method = x$classif.lda.method
+ } else {
+ # ranger
+ proxy.content$param_set$values$mtry = x$classif.ranger.mtry
+ proxy.content$param_set$values$num.trees = x$classif.ranger.num.trees
+ }
+ list(proxy.content = proxy.content)
+}I.e., suppose that the following parameters will be selected from our ParamSet:
x = list(
+ branch_learner.selection = "ranger",
+ classif.ranger.mtry = 200,
+ classif.ranger.num.trees = 500)The trafo function will then return:
tune_ps2$trafo(x)$proxy.content
+<LearnerClassifRanger:classif.ranger>
+* Model: -
+* Parameters: num.threads=1, mtry=200, num.trees=500
+* Packages: mlr3, mlr3learners, ranger
+* Predict Types: [response], prob
+* Feature Types: logical, integer, numeric, character, factor, ordered
+* Properties: hotstart_backward, importance, multiclass, oob_error, twoclass, weightsTuning can be carried out analogously as done above:
+tune2 = TuningInstanceSingleCrit$new(
+ task_train,
+ learner = graph2,
+ resampling = rsmp("cv", folds = 3),
+ measure = msr("classif.acc"),
+ search_space = tune_ps2,
+ terminator = trm("none")
+)
+tuner_gs$optimize(tune2)as.data.table(tune2$archive)[order(classif.acc), ]We showcase the visualization functions of the mlr3 ecosystem. The mlr3viz package creates a plot for almost all mlr3 objects. This post displays all available plots with their reproducible code. We start with plots of the base mlr3 objects. This includes boxplots of tasks, dendrograms of cluster learners and ROC curves of predictions. After that, we tune a classification tree and visualize the results. Finally, we show visualizations for filters.
+This article will be updated whenever a new plot is available in mlr3viz.
The mlr3viz package defines autoplot() functions to draw plots with ggplot2. Often there is more than one type of plot for an object. You can change the plot with the type argument. The help pages list all possible choices. The easiest way to access the help pages is via the pkgdown website. The plots use the viridis color pallet and the appearance is controlled with the theme argument. By default, the minimal theme is applied.
We begin with plots of the classification task Palmer Penguins. We plot the class frequency of the target variable.
library(mlr3verse)
+library(mlr3viz)
+
+task = tsk("penguins")
+task$select(c("body_mass", "bill_length"))
+
+autoplot(task, type = "target")
The "duo" plot shows the distribution of multiple features.
autoplot(task, type = "duo")
The "pairs" plot shows the pairwise comparison of multiple features. The classes of the target variable are shown in different colors.
autoplot(task, type = "pairs")
Next, we plot the regression task mtcars. We create a boxplot of the target variable.
task = tsk("mtcars")
+task$select(c("am", "carb"))
+
+autoplot(task, type = "target")
The "pairs" plot shows the pairwise comparison of mutiple features and the target variable.
autoplot(task, type = "pairs")
Finally, we plot the cluster task US Arrests. The "pairs" plot shows the pairwise comparison of mutiple features.
library(mlr3cluster)
+
+task = mlr_tasks$get("usarrests")
+
+autoplot(task, type = "pairs")
The "prediction" plot shows the decision boundary of a classification learner and the true class labels as points.
task = tsk("pima")$select(c("age", "pedigree"))
+learner = lrn("classif.rpart")
+learner$train(task)
+
+autoplot(learner, type = "prediction", task)
Using probabilities.
+task = tsk("pima")$select(c("age", "pedigree"))
+learner = lrn("classif.rpart", predict_type = "prob")
+learner$train(task)
+
+autoplot(learner, type = "prediction", task)
The "prediction" plot of a regression learner illustrates the decision boundary and the true response as points.
task = tsk("boston_housing")$select("age")
+learner = lrn("regr.rpart")
+learner$train(task)
+
+autoplot(learner, type = "prediction", task)
When using two features, the response surface is plotted in the background.
+task = tsk("boston_housing")$select(c("age", "rm"))
+learner = lrn("regr.rpart")
+learner$train(task)
+
+autoplot(learner, type = "prediction", task)
The classification and regression GLMNet learner is equipped with a plot function.
library(mlr3data)
+
+task = tsk("ilpd")
+task$select(setdiff(task$feature_names, "gender"))
+learner = lrn("classif.glmnet")
+learner$train(task)
+
+autoplot(learner, type = "ggfortify")
task = tsk("mtcars")
+learner = lrn("regr.glmnet")
+learner$train(task)
+
+autoplot(learner, type = "ggfortify")
We plot a classification tree of the rpart package. We have to fit the learner with keep_model = TRUE to keep the model object.
task = tsk("penguins")
+learner = lrn("classif.rpart", keep_model = TRUE)
+learner$train(task)
+
+autoplot(learner, type = "ggparty")
We can also plot regression trees.
+task = tsk("mtcars")
+learner = lrn("regr.rpart", keep_model = TRUE)
+learner$train(task)
+
+autoplot(learner, type = "ggparty")
The "dend" plot shows the result of the hierarchical clustering of the data.
library(mlr3cluster)
+
+task = tsk("usarrests")
+learner = lrn("clust.hclust")
+learner$train(task)
+
+autoplot(learner, type = "dend", task = task)
The "scree" type plots the number of clusters and the height.
autoplot(learner, type = "scree")
We plot the predictions of a classification learner. The "stacked" plot shows the predicted and true class labels.
task = tsk("spam")
+learner = lrn("classif.rpart", predict_type = "prob")
+pred = learner$train(task)$predict(task)
+
+autoplot(pred, type = "stacked")
The ROC curve plots the true positive rate against the false positive rate at different thresholds.
+autoplot(pred, type = "roc")
The precision-recall curve plots the precision against the recall at different thresholds.
+autoplot(pred, type = "prc")
The "threshold" plot varies the threshold of a binary classification and plots against the resulting performance.
autoplot(pred, type = "threshold")
The predictions of a regression learner are often presented as a scatterplot of truth and predicted response.
+task = tsk("boston_housing")
+learner = lrn("regr.rpart")
+pred = learner$train(task)$predict(task)
+
+autoplot(pred, type = "xy")
Additionally, we plot the response with the residuals.
+autoplot(pred, type = "residual")
We can also plot the distribution of the residuals.
+autoplot(pred, type = "histogram")
The predictions of a cluster learner are often presented as a scatterplot of the data points colored by the cluster.
+library(mlr3cluster)
+
+task = tsk("usarrests")
+learner = lrn("clust.kmeans", centers = 3)
+pred = learner$train(task)$predict(task)
+
+autoplot(pred, task, type = "scatter")
The "sil" plot shows the silhouette width of the clusters. The dashed line is the mean silhouette width.
autoplot(pred, task, type = "sil")
The "pca" plot shows the first two principal components of the data colored by the cluster.
autoplot(pred, task, type = "pca")
The "boxplot" shows the distribution of the performance measures.
task = tsk("sonar")
+learner = lrn("classif.rpart", predict_type = "prob")
+resampling = rsmp("cv")
+rr = resample(task, learner, resampling)
+
+autoplot(rr, type = "boxplot")
We can also plot the distribution of the performance measures as a “histogram”.
autoplot(rr, type = "histogram")
The ROC curve plots the true positive rate against the false positive rate at different thresholds.
+autoplot(rr, type = "roc")
The precision-recall curve plots the precision against the recall at different thresholds.
+autoplot(rr, type = "prc")
The "prediction" plot shows two features and the predicted class in the background. Points mark the observations of the test set and the color presents the truth.
task = tsk("pima")
+task$filter(seq(100))
+task$select(c("age", "glucose"))
+learner = lrn("classif.rpart")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")
Alternatively, we can plot class probabilities.
+task = tsk("pima")
+task$filter(seq(100))
+task$select(c("age", "glucose"))
+learner = lrn("classif.rpart", predict_type = "prob")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")
In addition to the test set, we can also plot the train set.
+task = tsk("pima")
+task$filter(seq(100))
+task$select(c("age", "glucose"))
+learner = lrn("classif.rpart", predict_type = "prob", predict_sets = c("train", "test"))
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction", predict_sets = c("train", "test"))
The "prediction" plot can also show categorical features.
task = tsk("german_credit")
+task$filter(seq(100))
+task$select(c("housing", "employment_duration"))
+learner = lrn("classif.rpart")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")
The “prediction” plot shows one feature and the response. Points mark the observations of the test set.
task = tsk("boston_housing")
+task$select("age")
+task$filter(seq(100))
+learner = lrn("regr.rpart")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")
Additionally, we can add confidence bounds.
+task = tsk("boston_housing")
+task$select("age")
+task$filter(seq(100))
+learner = lrn("regr.lm", predict_type = "se")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")
And add the train set.
+task = tsk("boston_housing")
+task$select("age")
+task$filter(seq(100))
+learner = lrn("regr.lm", predict_type = "se", predict_sets = c("train", "test"))
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction", predict_sets = c("train", "test"))
We can also add the prediction surface to the background.
+task = tsk("boston_housing")
+task$select(c("age", "rm"))
+task$filter(seq(100))
+learner = lrn("regr.rpart")
+resampling = rsmp("cv", folds = 3)
+rr = resample(task, learner, resampling, store_models = TRUE)
+
+autoplot(rr, type = "prediction")
We show the performance distribution of a benchmark with multiple tasks.
+tasks = tsks(c("pima", "sonar"))
+learner = lrns(c("classif.featureless", "classif.rpart", "classif.xgboost"), predict_type = "prob")
+resampling = rsmps("cv")
+bmr = benchmark(benchmark_grid(tasks, learner, resampling))
+
+autoplot(bmr, type = "boxplot")
We plot a benchmark result with one task and multiple learners.
+tasks = tsk("pima")
+learner = lrns(c("classif.featureless", "classif.rpart", "classif.xgboost"), predict_type = "prob")
+resampling = rsmps("cv")
+bmr = benchmark(benchmark_grid(tasks, learner, resampling))We plot an roc curve for each learner.
+autoplot(bmr, type = "roc")
Alternatively, we can plot precision-recall curves.
+autoplot(bmr, type = "prc")
We tune the hyperparameters of a decision tree on the sonar task. The "performance" plot shows the performance over batches.
library(mlr3tuning)
+library(mlr3tuningspaces)
+library(mlr3learners)
+
+instance = tune(
+ tuner = tnr("gensa"),
+ task = tsk("sonar"),
+ learner = lts(lrn("classif.rpart")),
+ resampling = rsmp("holdout"),
+ measures = msr("classif.ce"),
+ term_evals = 100
+)
+
+autoplot(instance, type = "performance")
The "incumbent" plot shows the performance of the best hyperparameter setting over the number of evaluations.
autoplot(instance, type = "incumbent")
The "parameter" plot shows the performance for each hyperparameter setting.
autoplot(instance, type = "parameter", cols_x = c("cp", "minsplit"))
The "marginal" plot shows the performance of different hyperparameter values. The color indicates the batch.
autoplot(instance, type = "marginal", cols_x = "cp")
The "parallel" plot visualizes the relationship of hyperparameters.
autoplot(instance, type = "parallel")
We plot cp against minsplit and color the points by the performance.
autoplot(instance, type = "points", cols_x = c("cp", "minsplit"))
Next, we plot all hyperparameters against each other.
+autoplot(instance, type = "pairs")
We plot the performance surface of two hyperparameters. The surface is interpolated with a learner.
+autoplot(instance, type = "surface", cols_x = c("cp", "minsplit"), learner = mlr3::lrn("regr.ranger"))
We plot filter scores for the mtcars task.
+library(mlr3filters)
+
+task = tsk("mtcars")
+f = flt("correlation")
+f$calculate(task)
+
+autoplot(f, n = 5)
The mlr3viz package brings together the visualization functions of the mlr3 ecosystem. All plots are drawn with the autoplot() function and the appearance can be customized with the theme argument. If you need to highly customize a plot e.g. for a publication, we encourage you to check our code on GitHub. The code should be easily adaptable to your needs. We are also looking forward to new visualizations. You can suggest new plots in an issue on GitHub.
Run a land cover classification of the city of Leipzig.
+
+ Working with spatial data in R requires a lot of data wrangling e.g. reading from different file formats, converting between spatial formats, creating tables from point layers, and predicting spatial raster images. The goal of mlr3spatial is to simplify these workflows within the mlr3 ecosystem. As a practical example, we will perform a land cover classification for the city of Leipzig, Germany. Figure 1 illustrates the typical workflow for this type of task: Load the training data, create a spatial task, train a learner with it, and predict the final raster image.
+%%{ init: { 'flowchart': { 'curve': 'bump' } } }%%
+
+flowchart LR
+ subgraph files[Files]
+ vector[Vector]
+ raster[Raster]
+ end
+ subgraph load[Load Data]
+ sf
+ terra
+ end
+ vector --> sf
+ raster --> terra
+ subgraph train_model[Train Model]
+ task[Task]
+ learner[Learner]
+ end
+ terra --> prediction_raster
+ task --> learner
+ sf --> task
+ subgraph predict[Spatial Prediction]
+ prediction_raster[Raster Image]
+ end
+ learner --> prediction_raster
+
+We assume that you are familiar with the mlr3 ecosystem and know the basic concepts of remote sensing. If not, we recommend reading the mlr3book first. If you are interested in spatial resampling, check out the book chapter on spatial analysis.
+Land cover is the physical material or vegetation that covers the surface of the earth, including both natural and human-made features. Understanding land cover patterns and changes over time is critical for addressing global environmental challenges, such as climate change, land degradation, and loss of biodiversity. Land cover classification is the process of assigning land cover classes to pixels in a raster image. With mlr3spatial, we can easily perform a land cover classification within the mlr3 ecosystem.
+Before we can start the land cover classification, we need to load the necessary packages. The mlr3spatial package relies on terra for processing raster data and sf for vector data. These widely used packages read all common raster and vector formats. Additionally, the stars and raster packages are supported.
+library(mlr3verse)
+library(mlr3spatial)
+library(terra, exclude = "resample")
+library(sf)We will work with a Sentinel-2 scene of the city of Leipzig which consists of 7 bands with a 10 or 20m spatial resolution and an NDVI band. The data is included in the mlr3spatial package. We use the terra::rast() to load the TIFF raster file.
leipzig_raster = rast(system.file("extdata", "leipzig_raster.tif", package = "mlr3spatial"))
+leipzig_rasterclass : SpatRaster
+dimensions : 206, 154, 8 (nrow, ncol, nlyr)
+resolution : 10, 10 (x, y)
+extent : 731810, 733350, 5692030, 5694090 (xmin, xmax, ymin, ymax)
+coord. ref. : WGS 84 / UTM zone 32N (EPSG:32632)
+source : leipzig_raster.tif
+names : b02, b03, b04, b06, b07, b08, ...
+min values : 846, 645, 366, 375, 401, 374, ...
+max values : 4705, 4880, 5451, 4330, 5162, 5749, ... The training data is a GeoPackage point layer with land cover labels and spectral features. We load the file and create a simple feature point layer.
leipzig_vector = read_sf(system.file("extdata", "leipzig_points.gpkg", package = "mlr3spatial"), stringsAsFactors = TRUE)
+leipzig_vectorSimple feature collection with 97 features and 9 fields
+Geometry type: POINT
+Dimension: XY
+Bounding box: xmin: 731930.5 ymin: 5692136 xmax: 733220.3 ymax: 5693968
+Projected CRS: WGS 84 / UTM zone 32N
+# A tibble: 97 × 10
+ b02 b03 b04 b06 b07 b08 b11 ndvi land_cover geom
+ <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <POINT [m]>
+ 1 903 772 426 2998 4240 4029 1816 0.809 forest (732480.1 5693957)
+ 2 1270 1256 1081 1998 2493 2957 2073 0.465 urban (732217.4 5692769)
+ 3 1033 996 777 2117 2748 2799 1595 0.565 urban (732737.2 5692469)
+ 4 962 773 500 465 505 396 153 -0.116 water (733169.3 5692777)
+ 5 1576 1527 1626 1715 1745 1768 1980 0.0418 urban (732202.2 5692644)
+ 6 1125 1185 920 3058 3818 3758 2682 0.607 pasture (732153 5693059)
+ 7 880 746 424 2502 3500 3397 1469 0.778 forest (731937.9 5693722)
+ 8 1332 1251 1385 1663 1799 1640 1910 0.0843 urban (732416.2 5692324)
+ 9 940 741 475 452 515 400 139 -0.0857 water (732933.7 5693344)
+10 902 802 454 2764 3821 3666 1567 0.780 forest (732411.3 5693352)
+# ℹ 87 more rowsWe plot both layers to get an overview of the data. The training points are located in the districts of Lindenau and Zentrum West.
+library(ggplot2)
+library(tidyterra, exclude = "filter")
+
+ggplot() +
+ geom_spatraster_rgb(data = leipzig_raster, r = 3, g = 2, b = 1, max_col_value = 5451) +
+ geom_spatvector(data = leipzig_vector, aes(color = land_cover)) +
+ scale_color_viridis_d(name = "Land cover", labels = c("Forest", "Pastures", "Urban", "Water")) +
+ theme_minimal()
The as_task_classif_st() function directly creates a spatial task from the point layer. This makes it unnecessary to transform the point layer to a data.frame with coordinates. Spatial tasks additionally store the coordinates of the training points. The coordinates are useful when estimating the performance of the model with spatial resampling.
task = as_task_classif_st(leipzig_vector, target = "land_cover")
+task<TaskClassifST:leipzig_vector> (97 x 9)
+* Target: land_cover
+* Properties: multiclass
+* Features (8):
+ - dbl (8): b02, b03, b04, b06, b07, b08, b11, ndvi
+* Coordinates:
+ X Y
+ 1: 732480.1 5693957
+ 2: 732217.4 5692769
+ 3: 732737.2 5692469
+ 4: 733169.3 5692777
+ 5: 732202.2 5692644
+---
+93: 733018.7 5692342
+94: 732551.4 5692887
+95: 732520.4 5692589
+96: 732542.2 5692204
+97: 732437.8 5692300Now we can train a model with the task. We use a simple decision tree learner from the rpart package. The "classif_st" task is a specialization of the "classif" task and therefore works with all "classif" learners.
learner = lrn("classif.rpart")
+learner$train(task)To get a complete land cover classification of Leipzig, we have to predict on each pixel and return a raster image with these predictions. The $predict() method of the learner only works for tabular data. To predict a raster image, we use the predict_spatial() function.
# predict land cover map
+land_cover = predict_spatial(leipzig_raster, learner)ggplot() +
+ geom_spatraster(data = land_cover) +
+ scale_fill_viridis_d(name = "Land cover", labels = c("Forest", "Pastures", "Urban", "Water")) +
+ theme_minimal()
Working with spatial data in R is very easy with the mlr3spatial package. You can quickly train a model with a point layer and predict a raster image. The mlr3spatial package is still in development and we are looking forward to your feedback and contributions.
+ + +Here are some interesting reads regarding BART:
+BART R package tutorial (R. Sparapani, Spanbauer, and McCulloch 2021)We incorporated the survival BART model in mlr3extralearners and in this tutorial we will demonstrate how we can use packages like mlr3, mlr3proba and distr6 to more easily manipulate the output predictions to assess model convergence, validate our model (via several survival metrics), as well as perform model interpretation via PDPs (Partial Dependence Plots).
library(mlr3extralearners)
+library(mlr3pipelines)
+library(mlr3proba)
+library(distr6)
+library(BART) # 2.9.4
+library(dplyr)
+library(tidyr)
+library(tibble)
+library(ggplot2)We will use the Lung Cancer Dataset. We convert the time variable from days to months to ease the computational burden:
task_lung = tsk('lung')
+
+d = task_lung$data()
+# in case we want to select specific columns to keep
+# d = d[ ,colnames(d) %in% c("time", "status", "age", "sex", "ph.karno"), with = FALSE]
+d$time = ceiling(d$time/30.44)
+task_lung = as_task_surv(d, time = 'time', event = 'status', id = 'lung')
+task_lung$label = "Lung Cancer"BART implementation supports categorical features (factors). This results in different importance scores per each dummy level which doesn’t work well with mlr3. So features of type factor or character are not allowed and we leave it to the user to encode them as they please.BART implementation supports features with missing values. This is totally fine with mlr3 as well! In this example, we impute the features to show good ML practice.In our lung dataset, we encode the sex feature and perform model-based imputation with the rpart regression learner:
po_encode = po('encode', method = 'treatment')
+po_impute = po('imputelearner', lrn('regr.rpart'))
+pre = po_encode %>>% po_impute
+task = pre$train(task_lung)[[1]]
+task<TaskSurv:lung> (228 x 10): Lung Cancer
+* Target: time, status
+* Properties: -
+* Features (8):
+ - int (7): age, inst, meal.cal, pat.karno, ph.ecog, ph.karno, wt.loss
+ - dbl (1): sexNo missing values in our data:
+task$missings() time status age sex inst meal.cal pat.karno ph.ecog ph.karno wt.loss
+ 0 0 0 0 0 0 0 0 0 0 We partition the data to train and test sets:
+set.seed(42)
+part = partition(task, ratio = 0.9)We train the BART model and predict on the test set:
# default `ndpost` value: 1000. We reduce it to 50 to speed up calculations in this tutorial
+learner = lrn("surv.bart", nskip = 250, ndpost = 50, keepevery = 10, mc.cores = 10)
+learner$train(task, row_ids = part$train)
+p = learner$predict(task, row_ids = part$test)
+p<PredictionSurv> for 23 observations:
+ row_ids time status crank distr
+ 9 8 TRUE 66.19326 <list[1]>
+ 10 6 TRUE 98.43005 <list[1]>
+ 21 10 TRUE 54.82313 <list[1]>
+---
+ 160 13 FALSE 37.82089 <list[1]>
+ 163 10 FALSE 69.63534 <list[1]>
+ 194 8 FALSE 81.13678 <list[1]>See more details about BART’s parameters on the online documentation.
What kind of object is the predicted distr?
p$distrArrdist(23x31x50) Actually the $distr is an active R6 field - this means that some computation is required to create it. What the prediction object actually stores internally is a 3d survival array (can be used directly with no performance overhead):
dim(p$data$distr)[1] 23 31 50This is a more easy-to-understand and manipulate form of the full posterior survival matrix prediction from the BART package ((R. Sparapani, Spanbauer, and McCulloch 2021), pages 34-35).
Though we have optimized with C++ code the way the Arrdist object is constructed, calling the $distr field can be computationally taxing if the product of the sizes of the 3 dimensions above exceeds ~1 million. In our case, \(23 \times 31 \times 50 = 35650\) so the conversion to an Arrdist via $distr will certainly not create performance issues.
An example using the internal prediction data: get all the posterior probabilities of the 3rd patient in the test set, at 12 months (1 year):
+p$data$distr[3, 12, ] [1] 0.26546909 0.27505937 0.21151435 0.46700513 0.26178380 0.24040003 0.29946469 0.52357780 0.40833108 0.40367780
+[11] 0.27027392 0.31781286 0.54151844 0.34460027 0.41826554 0.41866367 0.33694401 0.34511270 0.47244492 0.49423660
+[21] 0.42069678 0.20095489 0.48696980 0.48409357 0.35649439 0.47969355 0.16355660 0.33728105 0.40245228 0.42418033
+[31] 0.36336145 0.48181667 0.51858238 0.49635078 0.37238179 0.26694030 0.52219952 0.48992897 0.08572207 0.30306005
+[41] 0.33881682 0.33463870 0.29102074 0.43176131 0.38554545 0.38053756 0.36808776 0.13772665 0.21898264 0.14552514Working with the $distr interface and Arrdist objects is very efficient as we will see later for predicting survival estimates.
In survival analysis, \(S(t) = 1 - F(t)\), where \(S(t)\) the survival function and \(F(t)\) the cumulative distribution function (cdf). The latter can be interpreted as risk or probability of death up to time \(t\).
We can verify the above from the prediction object:
+surv_array = 1 - distr6::gprm(p$distr, "cdf") # 3d array
+testthat::expect_equal(p$data$distr, surv_array)crank is the expected mortality (Sonabend, Bender, and Vollmer 2022) which is the sum of the predicted cumulative hazard function (as is done in random survival forest models). Higher values denote larger risk. To calculate crank, we need a survival matrix. So we have to choose which 3rd dimension we should use from the predicted survival array. This is what the which.curve parameter of the learner does:
learner$param_set$get_values()$which.curve[1] 0.5The default value (\(0.5\) quantile) is the median survival probability. It could be any other quantile (e.g. \(0.25\)). Other possible values for which.curve are mean or a number denoting the exact posterior draw to extract (e.g. the last one, which.curve = 50).
Default score is the observed count of each feature in the trees (so the higher the score, the more important the feature):
+learner$param_set$values$importance[1] "count"learner$importance() sex meal.cal inst pat.karno ph.karno wt.loss age ph.ecog
+ 7.84 7.46 7.08 6.76 6.60 6.46 5.48 5.42 BART uses internally MCMC (Markov Chain Monte Carlo) to sample from the posterior survival distribution. We need to check that MCMC has converged, meaning that the chains have reached a stationary distribution that approximates the true posterior survival distribution (otherwise the predictions may be inaccurate, misleading and unreliable).
We use Geweke’s convergence diagnostic test as it is implemented in the BART R package. We choose 10 random patients from the train set to evaluate the MCMC convergence.
# predictions on the train set
+p_train = learner$predict(task, row_ids = part$train)
+
+# choose 10 patients from the train set randomly and make a list
+ids = as.list(sample(length(part$train), 10))
+
+z_list = lapply(ids, function(id) {
+ # matrix with columns => time points and rows => posterior draws
+ post_surv = 1 - t(distr6::gprm(p_train$distr[id], "cdf")[1,,])
+ BART::gewekediag(post_surv)$z # get the z-scores
+})
+
+# plot the z scores vs time for all patients
+dplyr::bind_rows(z_list) %>%
+ tidyr::pivot_longer(cols = everything()) %>%
+ mutate(name = as.numeric(name)) %>%
+ ggplot(aes(x = name, y = value)) +
+ geom_point() +
+ labs(x = "Time (months)", y = "Z-scores") +
+ # add critical values for a = 0.05
+ geom_hline(yintercept = 1.96, linetype = 'dashed', color = "red") +
+ geom_hline(yintercept = -1.96, linetype = 'dashed', color = "red") +
+ theme_bw(base_size = 14)
We will use the following survival metrics:
+distr)crank)For the first measure we will use the ERV (Explained Residual Variation) version, which standardizes the score against a Kaplan-Meier (KM) baseline (Sonabend et al. 2022). This means that values close to \(0\) represent performance similar to a KM model, negative values denote worse performance than KM and \(1\) is the absolute best possible score.
+measures = list(
+ msr("surv.graf", ERV = TRUE),
+ msr("surv.cindex", weight_meth = "G2", id = "surv.cindex.uno")
+)
+
+for (measure in measures) {
+ print(p$score(measure, task = task, train_set = part$train))
+} surv.graf
+-0.09950096
+surv.cindex.uno
+ 0.551951 All metrics use by default the median survival distribution from the 3d array, no matter what is the which.curve argument during the learner’s construction.
Performing resampling with the BART learner is very easy using mlr3.
We first stratify the data by status, so that in each resampling the proportion of censored vs un-censored patients remains the same:
task$col_roles$stratum = 'status'
+task$strata N row_id
+1: 165 1,2,4,5,7,8,...
+2: 63 3, 6,38,68,71,83,...rr = resample(task, learner, resampling = rsmp("cv", folds = 5), store_backends = TRUE)INFO [17:07:04.946] [mlr3] Applying learner 'surv.bart' on task 'lung' (iter 1/5)
+INFO [17:07:07.647] [mlr3] Applying learner 'surv.bart' on task 'lung' (iter 2/5)
+INFO [17:07:10.708] [mlr3] Applying learner 'surv.bart' on task 'lung' (iter 3/5)
+INFO [17:07:13.382] [mlr3] Applying learner 'surv.bart' on task 'lung' (iter 4/5)
+INFO [17:07:16.361] [mlr3] Applying learner 'surv.bart' on task 'lung' (iter 5/5)No errors or warnings:
+rr$errorsEmpty data.table (0 rows and 2 cols): iteration,msgrr$warningsEmpty data.table (0 rows and 2 cols): iteration,msgPerformance in each fold:
+rr$score(measures) task_id learner_id resampling_id iteration surv.graf surv.cindex.uno
+1: lung surv.bart cv 1 -0.312614598 0.5869665
+2: lung surv.bart cv 2 -0.103181391 0.5502903
+3: lung surv.bart cv 3 0.001448263 0.6178001
+4: lung surv.bart cv 4 -0.044161171 0.6157215
+5: lung surv.bart cv 5 -0.043129352 0.5688389
+Hidden columns: task, learner, resampling, predictionMean cross-validation performance:
+rr$aggregate(measures) surv.graf surv.cindex.uno
+ -0.1003276 0.5879235 We will choose two patients from the test set and plot their survival prediction posterior estimates.
+Let’s choose the patients with the worst and the best survival time:
+death_times = p$truth[,1]
+sort(death_times) [1] 3 5 5 6 6 6 7 8 8 8 8 10 10 10 12 12 12 13 15 16 17 18 27worst_indx = which(death_times == min(death_times))[1] # died first
+best_indx = which(death_times == max(death_times))[1] # died last
+
+patient_ids = c(worst_indx, best_indx)
+patient_ids # which patient IDs[1] 5 18death_times = death_times[patient_ids]
+death_times # 1st is worst, 2nd is best[1] 3 27Subset Arrdist to only the above 2 patients:
arrd = p$distr[patient_ids]
+arrdArrdist(2x31x50) We choose time points (in months) for the survival estimates:
+months = seq(1, 36) # 1 month - 3 yearsWe use the $distr interface and the $survival property to get survival probabilities from an Arrdist object as well as the quantile credible intervals (CIs). The median survival probabilities can be extracted as follows:
med = arrd$survival(months) # 'med' for median
+
+colnames(med) = paste0(patient_ids, "_med")
+med = as_tibble(med) %>% add_column(month = months)
+head(med)# A tibble: 6 × 3
+ `5_med` `18_med` month
+ <dbl> <dbl> <int>
+1 0.874 0.981 1
+2 0.767 0.962 2
+3 0.670 0.945 3
+4 0.569 0.927 4
+5 0.465 0.901 5
+6 0.366 0.869 6We can briefly verify model’s predictions: 1st patient survival probabilities on any month are lower (worst) compared to the 2nd patient.
+Note that subsetting an Arrdist (3d array) creates a Matdist (2d matrix), for example we can explicitly get the median survival probabilities:
matd_median = arrd[, 0.5] # median
+head(matd_median$survival(months)) # same as with `arrd` [,1] [,2]
+1 0.8741127 0.9808363
+2 0.7670382 0.9621618
+3 0.6701276 0.9450867
+4 0.5688809 0.9272284
+5 0.4647686 0.9007042
+6 0.3660939 0.8687270Using the mean posterior survival probabilities or the ones from the last posterior draw is also possible and can be done as follows:
matd_mean = arrd[, "mean"] # mean (if needed)
+head(matd_mean$survival(months)) [,1] [,2]
+1 0.8652006 0.9748463
+2 0.7533538 0.9521817
+3 0.6560050 0.9293229
+4 0.5623555 0.9051549
+5 0.4750038 0.8758896
+6 0.3815333 0.8360373matd_50draw = arrd[, 50] # the 50th posterior draw
+head(matd_50draw$survival(months)) [,1] [,2]
+1 0.9178342 0.9920982
+2 0.8424195 0.9842589
+3 0.7732014 0.9764815
+4 0.7096707 0.9687656
+5 0.6029119 0.9495583
+6 0.5122132 0.9307318To get the CIs we will subset the Arrdist using a quantile number (0-1), which extracts a Matdist based on the cdf. The survival function is 1 - cdf, so low and upper bounds are reversed:
low = arrd[, 0.975]$survival(months) # 2.5% bound
+high = arrd[, 0.025]$survival(months) # 97.5% bound
+colnames(low) = paste0(patient_ids, "_low")
+colnames(high) = paste0(patient_ids, "_high")
+low = as_tibble(low)
+high = as_tibble(high)The median posterior survival probabilities for the two patient of interest and the corresponding CI bounds in a tidy format are:
+surv_tbl =
+ bind_cols(low, med, high) %>%
+ pivot_longer(cols = !month, values_to = "surv",
+ names_to = c("patient_id", ".value"), names_sep = "_") %>%
+ relocate(patient_id)
+surv_tbl# A tibble: 72 × 5
+ patient_id month low med high
+ <chr> <int> <dbl> <dbl> <dbl>
+ 1 5 1 0.713 0.874 0.953
+ 2 18 1 0.929 0.981 0.996
+ 3 5 2 0.508 0.767 0.903
+ 4 18 2 0.863 0.962 0.991
+ 5 5 3 0.362 0.670 0.855
+ 6 18 3 0.801 0.945 0.985
+ 7 5 4 0.244 0.569 0.804
+ 8 18 4 0.734 0.927 0.977
+ 9 5 5 0.146 0.465 0.748
+10 18 5 0.654 0.901 0.969
+# ℹ 62 more rowsWe draw survival curves with the uncertainty for the survival probability quantified:
+my_colors = c("#E41A1C", "#4DAF4A")
+names(my_colors) = patient_ids
+
+surv_tbl %>%
+ ggplot(aes(x = month, y = med)) +
+ geom_step(aes(color = patient_id), linewidth = 1) +
+ xlab('Time (Months)') +
+ ylab('Survival Probability') +
+ geom_ribbon(aes(ymin = low, ymax = high, fill = patient_id),
+ alpha = 0.3, show.legend = F) +
+ geom_vline(xintercept = death_times[1], linetype = 'dashed', color = my_colors[1]) +
+ geom_vline(xintercept = death_times[2], linetype = 'dashed', color = my_colors[2]) +
+ theme_bw(base_size = 14) +
+ scale_color_manual(values = my_colors) +
+ scale_fill_manual(values = my_colors) +
+ guides(color = guide_legend(title = "Patient ID"))
We will use a Partial Dependence Plot (PDP) (Friedman 2001) to visualize how much different are males vs females in terms of their average survival predictions across time.
+PDPs assume that features are independent. In our case we need to check that sex doesn’t correlate with any of the other features used for training the BART learner. Since sex is a categorical feature, we fit a linear model using as target variable every other feature in the data (\(lm(feature \sim sex)\)) and conduct an ANOVA (ANalysis Of VAriance) to get the variance explained or \(R^2\). The square root of that value is the correlation measure we want.
# code from https://christophm.github.io/interpretable-ml-book/ale.html
+mycor = function(cnames, data) {
+ x.num = data[, cnames[1], with = FALSE][[1]]
+ x.cat = data[, cnames[2], with = FALSE][[1]]
+ # R^2 = Cor(X, Y)^2 in simple linear regression
+ sqrt(summary(lm(x.num ~ x.cat))$r.squared)
+}
+
+cnames = c("sex")
+combs = expand.grid(y = setdiff(colnames(d), "sex"), x = cnames)
+combs$cor = apply(combs, 1, mycor, data = task$data()) # use the train set
+combs y x cor
+1 time sex 0.12941337
+2 status sex 0.24343282
+3 age sex 0.12216709
+4 inst sex 0.07826337
+5 meal.cal sex 0.18389545
+6 pat.karno sex 0.04132443
+7 ph.ecog sex 0.02564987
+8 ph.karno sex 0.01702471
+9 wt.loss sex 0.13431983sex doesn’t correlate strongly with any other feature, so we can compute the PDP:
# create two datasets: one with males and one with females
+# all other features remain the same (use train data, 205 patients)
+d = task$data(rows = part$train) # `rows = part$test` to use the test set
+
+d$sex = 1
+task_males = as_task_surv(d, time = 'time', event = 'status', id = 'lung-males')
+d$sex = 0
+task_females = as_task_surv(d, time = 'time', event = 'status', id = 'lung-females')
+
+# make predictions
+p_males = learner$predict(task_males)
+p_females = learner$predict(task_females)
+
+# take the median posterior survival probability
+surv_males = p_males$distr$survival(months) # patients x times
+surv_females = p_females$distr$survival(months) # patients x times
+
+# tidy up data: average and quantiles across patients
+data_males =
+ apply(surv_males, 1, function(row) {
+ tibble(
+ low = quantile(row, probs = 0.025),
+ avg = mean(row),
+ high = quantile(row, probs = 0.975)
+ )
+ }) %>%
+ bind_rows() %>%
+ add_column(sex = 'male', month = months, .before = 1)
+
+data_females =
+ apply(surv_females, 1, function(row) {
+ tibble(
+ low = quantile(row, probs = 0.025),
+ avg = mean(row),
+ high = quantile(row, probs = 0.975)
+ )
+ }) %>%
+ bind_rows() %>%
+ add_column(sex = 'female', month = months, .before = 1)
+
+pdp_tbl = bind_rows(data_males, data_females)
+pdp_tbl# A tibble: 72 × 5
+ sex month low avg high
+ <chr> <int> <dbl> <dbl> <dbl>
+ 1 male 1 0.836 0.942 0.981
+ 2 male 2 0.704 0.889 0.963
+ 3 male 3 0.587 0.839 0.943
+ 4 male 4 0.488 0.788 0.924
+ 5 male 5 0.392 0.732 0.897
+ 6 male 6 0.304 0.663 0.860
+ 7 male 7 0.234 0.601 0.829
+ 8 male 8 0.172 0.550 0.799
+ 9 male 9 0.130 0.503 0.766
+10 male 10 0.0945 0.455 0.733
+# ℹ 62 more rowsmy_colors = c("#E41A1C", "#4DAF4A")
+names(my_colors) = c('male', 'female')
+
+pdp_tbl %>%
+ ggplot(aes(x = month, y = avg)) +
+ geom_step(aes(color = sex), linewidth = 1) +
+ xlab('Time (Months)') +
+ ylab('Survival Probability') +
+ geom_ribbon(aes(ymin = low, ymax = high, fill = sex), alpha = 0.2, show.legend = F) +
+ theme_bw(base_size = 14) +
+ scale_color_manual(values = my_colors) +
+ scale_fill_manual(values = my_colors)
Compare the runtime performance of tidymodels and mlr3.
+
+ In the realm of data science, machine learning frameworks play an important role in streamlining and accelerating the development of analytical workflows. Among these, tidymodels and mlr3 stand out as prominent tools within the R community. They provide a unified interface for data preprocessing, model training, resampling and tuning. The streamlined and accelerated development process, while efficient, typically results in a trade-off concerning runtime performance. This article undertakes a detailed comparison of the runtime efficiency of tidymodels and mlr3, focusing on their performance in training, resampling, and tuning machine learning models. Specifically, we assess the time efficiency of these frameworks in running the rpart::rpart() and ranger::ranger() models, using the Sonar dataset as a test case. Additionally, the study delves into analyzing the runtime overhead of these frameworks by comparing their performance against training the models without a framework. Through this comparative analysis, the article aims to provide valuable insights into the operational trade-offs of using these advanced machine learning frameworks in practical data science applications.
We employ the microbenchmark package to measure the time required for training, resampling, and tuning models. This benchmarking process is applied to the Sonar dataset using the rpart and ranger algorithms.
library("mlr3verse")
+library("tidymodels")
+library("microbenchmark")
+
+task = tsk("sonar")
+data = task$data()
+formula = Class ~ .To ensure the robustness of our results, each function call within the benchmark is executed 100 times in a randomized sequence. The microbenchmark package then provides us with detailed insights, including the median, lower quartile, and upper quartile of the runtimes. To further enhance the reliability of our findings, we execute the benchmark on a cluster. Each run of microbenchmark is repeated 100 times, with different seeds applied for each iteration. Resulting in a total of 10,000 function calls of each command. The computing environment for each worker in the cluster consists of 3 cores and 12 GB of RAM. For transparency and reproducibility, the examples of the code used for this experiment are provided as snippets in the article. The complete code, along with all details of the experiment, is available in our public repository, mlr-org/mlr-benchmark.
It’s important to note that our cluster setup is not specifically optimized for single-core performance. Consequently, executing the same benchmark on a local machine with might yield faster results.
+Our benchmark starts with the fundamental task of model training. To facilitate a direct comparison, we have structured our presentation into two distinct segments. On the left, we demonstrate the initialization of the rpart model, employing both mlr3 and tidymodels frameworks. The rpart model is a decision tree classifier, which is a simple and fast-fitting algorithm for classification tasks. Simultaneously, on the right, we turn our attention to the initialization of the ranger model, known for its efficient implementation of the random forest algorithm. Our aim is to mirror the configuration as closely as possible across both frameworks, maintaining consistency in parameters and settings.
# tidymodels
+tm_mod = decision_tree() %>%
+ set_engine("rpart",
+ xval = 0L) %>%
+ set_mode("classification")
+
+# mlr3
+learner = lrn("classif.rpart",
+ xval = 0L)
+# tidymodels
+tm_mod = rand_forest(trees = 1000L) %>%
+ set_engine("ranger",
+ num.threads = 1L,
+ seed = 1) %>%
+ set_mode("classification")
+
+# mlr3
+learner = lrn("classif.ranger",
+ num.trees = 1000L,
+ num.threads = 1L,
+ seed = 1,
+ verbose = FALSE,
+ predict_type = "prob")We measure the runtime for the train functions within each framework. The result of the train function is a trained model in both frameworks. In addition, we invoke the rpart() and ranger() functions to establish a baseline for the minimum achievable runtime. This allows us to not only assess the efficiency of the train functions in each framework but also to understand how they perform relative to the base packages.
# tidymodels train
+fit(tm_mod, formula, data = data)
+
+# mlr3 train
+learner$train(task)When training an rpart model, tidymodels demonstrates superior speed, outperforming mlr3 (Table 1). Notably, the mlr3 package requires approximately twice the time compared to the baseline.
A key observation from our results is the significant relative overhead when using a framework for rpart model training. Given that rpart inherently requires a shorter training time, the additional processing time introduced by the frameworks becomes more pronounced. This aspect highlights the trade-off between the convenience offered by these frameworks and their impact on runtime for quicker tasks.
Conversely, when we shift our focus to training a ranger model, the scenario changes (Table 2). Here, the runtime performance of ranger is strikingly similar across both tidymodels and mlr3. This equality in execution time can be attributed to the inherently longer training duration required by ranger models. As a result, the relative overhead introduced by either framework becomes minimal, effectively diminishing in the face of the more time-intensive training process. This pattern suggests that for more complex or time-consuming tasks, the choice of framework may have a less significant impact on overall runtime performance.
rpart depending on the framework.
+| Framework | +LQ | +Median | +UQ | +
|---|---|---|---|
| base | +11 | +11 | +12 | +
| mlr3 | +23 | +23 | +24 | +
| tidymodels | +18 | +18 | +19 | +
ranger depending on the framework.
+| Framework | +LQ | +Median | +UQ | +
|---|---|---|---|
| base | +286 | +322 | +347 | +
| mlr3 | +301 | +335 | +357 | +
| tidymodels | +310 | +342 | +362 | +
We proceed to evaluate the runtime performance of the resampling functions within both frameworks, specifically under conditions without parallelization. This step involves the generation of resampling splits, including 3-fold, 6-fold, and 9-fold cross-validation. Additionally, we run a 100 times repeated 3-fold cross-validation.
+We generate the same resampling splits for both frameworks. This consistency is key to ensuring that any observed differences in runtime are attributable to the frameworks themselves, rather than variations in the resampling process.
+In our pursuit of a fair and balanced comparison, we address certain inherent differences between the two frameworks. Notably, tidymodels inherently includes scoring of the resampling results as part of its process. To align the comparison, we replicate this scoring step in mlr3, thus maintaining a level field for evaluation. Furthermore, mlr3 inherently saves predictions during the resampling process. To match this, we activate the saving of the predictions in tidymodels.
# tidymodels resample
+control = control_grid(save_pred = TRUE)
+metrics = metric_set(accuracy)
+
+tm_wf =
+ workflow() %>%
+ add_model(tm_mod) %>%
+ add_formula(formula)
+
+fit_resamples(tm_wf, folds, metrics = metrics, control = control)
+
+# mlr3 resample
+measure = msr("classif.acc")
+
+rr = resample(task, learner, resampling)
+rr$score(measure)When resampling the fast-fitting rpart model, mlr3 demonstrates a notable edge in speed, as detailed in Table 3. In contrast, when it comes to resampling the more computationally intensive ranger models, the performance of tidymodels and mlr3 converges closely (Table 4). This parity in performance is particularly noteworthy, considering the differing internal mechanisms and optimizations of tidymodels and mlr3. A consistent trend observed across both frameworks is a linear increase in runtime proportional to the number of folds in cross-validation (Figure 1).
rpart depending on the framework and resampling strategy.
+| Framework | +Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|---|
| mlr3 | +cv3 | +188 | +196 | +210 | +
| tidymodels | +cv3 | +233 | +242 | +257 | +
| mlr3 | +cv6 | +343 | +357 | +379 | +
| tidymodels | +cv6 | +401 | +415 | +436 | +
| mlr3 | +cv9 | +500 | +520 | +548 | +
| tidymodels | +cv9 | +568 | +588 | +616 | +
| mlr3 | +rcv100 | +15526 | +16023 | +16777 | +
| tidymodels | +rcv100 | +16409 | +16876 | +17527 | +
ranger depending on the framework and resampling strategy.
+| Framework | +Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|---|
| mlr3 | +cv3 | +923 | +1004 | +1062 | +
| tidymodels | +cv3 | +916 | +981 | +1023 | +
| mlr3 | +cv6 | +1990 | +2159 | +2272 | +
| tidymodels | +cv6 | +2089 | +2176 | +2239 | +
| mlr3 | +cv9 | +3074 | +3279 | +3441 | +
| tidymodels | +cv9 | +3260 | +3373 | +3453 | +
| mlr3 | +rcv100 | +85909 | +88642 | +91381 | +
| tidymodels | +rcv100 | +87828 | +88822 | +89843 | +
 +
+rpart (displayed on the left) and ranger (on the right). The comparison encompasses variations across different frameworks and the number of folds in the cross-validation.
+We conducted a second set of resampling function tests, this time incorporating parallelization to explore its impact on runtime efficiency. In this phase, we utilized doFuture and doParallel as the primary parallelization packages for tidymodels, recognizing their robust support and compatibility. Meanwhile, for mlr3, the future package was employed to facilitate parallel processing.
Our findings, as presented in the respective tables (Table 5 and Table 6), reveal interesting dynamics about parallelization within the frameworks. When the number of folds in the resampling process is doubled, we observe only a marginal increase in the average runtime. This pattern suggests a significant overhead associated with initializing the parallel workers, a factor that becomes particularly influential in the overall efficiency of the parallelization process.
+In the case of the rpart model, the parallelization overhead appears to outweigh the potential speedup benefits, as illustrated in the left section of Figure 2. This result indicates that for less complex models like rpart, where individual training times are relatively short, the initialization cost of parallel workers may not be sufficiently offset by the reduced processing time per fold.
Conversely, for the ranger model, the utilization of parallelization demonstrates a clear advantage over the sequential version, as evidenced in the right section of Figure 2. This finding underscores that for more computationally intensive models like ranger, which have longer individual training times, the benefits of parallel processing significantly overcome the initial overhead of worker setup. This differentiation highlights the importance of considering the complexity and inherent processing time of models when deciding to implement parallelization strategies in these frameworks.
mlr3 with future and rpart depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +625 | +655 | +703 | +
| cv6 | +738 | +771 | +817 | +
| cv9 | +831 | +875 | +923 | +
| rcv100 | +8620 | +9043 | +9532 | +
mlr3 with future and ranger depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +836 | +884 | +943 | +
| cv6 | +1200 | +1249 | +1314 | +
| cv9 | +1577 | +1634 | +1706 | +
| rcv100 | +32047 | +32483 | +33022 | +
When paired with doFuture, tidymodels exhibits significantly slower runtime compared to the mlr3 package utilizing future (Table 7 and Table 8). We observed that tidymodels exports more data to the parallel workers, which notably exceeds that of mlr3. This substantial difference in data export could plausibly account for the observed slower runtime when using tidymodels on small tasks.
tidymodels with doFuture and rpart depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +2778 | +2817 | +3019 | +
| cv6 | +2808 | +2856 | +3033 | +
| cv9 | +2935 | +2975 | +3170 | +
| rcv100 | +9154 | +9302 | +9489 | +
tidymodels with doFuture and ranger depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +2982 | +3046 | +3234 | +
| cv6 | +3282 | +3366 | +3543 | +
| cv9 | +3568 | +3695 | +3869 | +
| rcv100 | +27546 | +27843 | +28166 | +
The utilization of the doParallel package demonstrates a notable improvement in handling smaller resampling tasks. In these scenarios, the resampling process consistently outperforms the mlr3 framework in terms of speed. However, it’s important to note that even with this enhanced performance, the doParallel package does not always surpass the efficiency of the sequential version, especially when working with the rpart model. This specific observation is illustrated in the left section of Figure 2.
tidymodels with doParallel and rpart depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +557 | +649 | +863 | +
| cv6 | +602 | +714 | +910 | +
| cv9 | +661 | +772 | +968 | +
| rcv100 | +10609 | +10820 | +11071 | +
tidymodels with doParallel and ranger depending on the resampling strategy.
+| Resampling | +LQ | +Median | +UQ | +
|---|---|---|---|
| cv3 | +684 | +756 | +948 | +
| cv6 | +1007 | +1099 | +1272 | +
| cv9 | +1360 | +1461 | +1625 | +
| rcv100 | +31205 | +31486 | +31793 | +
 +
+rpart (displayed on the left) and ranger (on the right). The comparison encompasses variations across different frameworks, the number of folds in the cross-validation, and the implementation of parallelization.
+In the context of repeated cross-validation, our findings underscore the efficacy of parallelization (Figure 3). Across all frameworks tested, the adoption of parallel processing techniques yields a significant increase in speed. This enhancement is particularly noticeable in larger resampling tasks, where the demands on computational resources are more substantial.
+Interestingly, within these more extensive resampling scenarios, the doFuture package emerges as a more efficient option compared to doParallel. This distinction is important, as it highlights the relative strengths of different parallelization packages under varying workload conditions. While doParallel shows proficiency in smaller tasks, doFuture demonstrates its capability to handle larger, more complex resampling processes with greater speed and efficiency.
 +
+rpart (displayed on the left) and ranger (on the right). The comparison encompasses variations across different frameworks and the implementation of parallelization.
+We then shift our focus to assessing the runtime performance of the tuning functions. In this phase, the tidymodels package is utilized to evaluate a predefined grid, comprising a specific set of hyperparameter configurations. To ensure a balanced and comparable analysis, we employ the "design_points" tuner from the mlr3tuning package. This approach allows us to evaluate the same grid within the mlr3 framework, maintaining consistency across both platforms. The grid used for this comparison contains 200 hyperparameter configurations each, for both the rpart and ranger models. This approach helps us to understand how each framework handles the optimization of model hyperparameters, a key aspect of building effective and efficient machine learning models.
# tidymodels
+tm_mod = decision_tree(
+ cost_complexity = tune()) %>%
+ set_engine("rpart",
+ xval = 0) %>%
+ set_mode("classification")
+
+tm_design = data.table(
+ cost_complexity = seq(0.1, 0.2, length.out = 200))
+
+# mlr3
+learner = lrn("classif.rpart",
+ xval = 0,
+ cp = to_tune())
+
+mlr3_design = data.table(
+ cp = seq(0.1, 0.2, length.out = 200))
+# tidymodels
+tm_mod = rand_forest(
+ trees = tune()) %>%
+ set_engine("ranger",
+ num.threads = 1L,
+ seed = 1) %>%
+ set_mode("classification")
+
+tm_design = data.table(
+ trees = seq(1000, 1199))
+
+# mlr3
+learner = lrn("classif.ranger",
+ num.trees = to_tune(1, 10000),
+ num.threads = 1L,
+ seed = 1,
+ verbose = FALSE,
+ predict_type = "prob")
+
+mlr3_design = data.table(
+ num.trees = seq(1000, 1199))We measure the runtime of the tune functions within each framework. Both the tidymodels and mlr3 frameworks are tasked with identifying the optimal hyperparameter configuration.
# tidymodels tune
+tune::tune_grid(
+ tm_wf,
+ resamples = resamples,
+ grid = design,
+ metrics = metrics)
+
+# mlr3 tune
+tuner = tnr("design_points", design = design, batch_size = nrow(design))
+mlr3tuning::tune(
+ tuner = tuner,
+ task = task,
+ learner = learner,
+ resampling = resampling,
+ measures = measure,
+ store_benchmark_result = FALSE)In our sequential tuning tests, mlr3 demonstrates a notable advantage in terms of speed. This finding is clearly evidenced in our results, as shown in Table Table 11 for the rpart model and Table Table 12 for the ranger model. The faster performance of mlr3 in these sequential runs highlights its efficiency in handling the tuning process without parallelization.
rpart depending on the framework.
+| Framework | +LQ | +Median | +UQ | +
|---|---|---|---|
| mlr3 | +27 | +27 | +28 | +
| tidymodels | +37 | +37 | +39 | +
ranger depending on the framework.
+| Framework | +LQ | +Median | +UQ | +
|---|---|---|---|
| mlr3 | +167 | +171 | +175 | +
| tidymodels | +194 | +195 | +196 | +
Concluding our analysis, we proceed to evaluate the runtime performance of the tune functions, this time implementing parallelization to enhance efficiency. For these runs, parallelization is executed on 3 cores.
+In the case of mlr3, we opt for the largest possible chunk size. This strategic choice means that all points within the tuning grid are sent to the workers in a single batch, effectively minimizing the overhead typically associated with parallelization. This approach is crucial in reducing the time spent in distributing tasks across multiple cores, thereby streamlining the tuning process. On the other hand, the tidymodels package also operates with the same chunk size, but this setting is determined and managed internally within the framework.
By conducting these parallelization tests, we aim to provide a deeper understanding of how each framework handles the distribution and management of computational tasks during the tuning process, particularly in a parallel computing environment. This final set of measurements is important in painting a complete picture of the runtime performance of the tune functions across both tidymodels and mlr3 under different operational settings.
options("mlr3.exec_chunk_size" = 200)Our analysis of the parallelized tuning functions reveals that the runtimes for mlr3 and tidymodels are remarkably similar. However, subtle differences emerge upon closer inspection. For instance, the mlr3 package exhibits a slightly faster performance when tuning the rpart model, as indicated in Table 13. In contrast, it falls marginally behind tidymodels in tuning the ranger model, as shown in Table 14.
Interestingly, when considering the specific context of a 3-fold cross-validation, the doParallel package outperforms doFuture in terms of speed, as demonstrated in Figure 4. This outcome suggests that the choice of parallelization package can have a significant impact on tuning efficiency, particularly in scenarios with a smaller number of folds.
A key takeaway from our study is the clear benefit of enabling parallelization, regardless of the chosen framework-backend combination. Activating parallelization consistently enhances performance, making it a highly recommended strategy for tuning machine learning models, especially in tasks involving extensive hyperparameter exploration or larger datasets. This conclusion underscores the value of parallel processing in modern machine learning workflows, offering a practical solution for accelerating model tuning across various computational settings.
+rpart depending on the framework.
+| Framework | +Backend | +LQ | +Median | +UQ | +
|---|---|---|---|---|
| mlr3 | +future | +11 | +12 | +12 | +
| tidymodels | +doFuture | +17 | +17 | +17 | +
| tidymodels | +doParallel | +13 | +13 | +13 | +
ranger depending on the framework.
+| Framework | +Backend | +LQ | +Median | +UQ | +
|---|---|---|---|---|
| mlr3 | +future | +54 | +55 | +55 | +
| tidymodels | +doFuture | +58 | +58 | +59 | +
| tidymodels | +doParallel | +54 | +54 | +55 | +
 +
+rpart (displayed on the left) and ranger (on the right). The comparison encompasses variations across different frameworks and the implementation of parallelization.
+Our analysis reveals that both tidymodels and mlr3 exhibit comparable runtimes across key processes such as training, resampling, and tuning, each displaying its own set of strengths and efficiencies.
A notable observation is the relative overhead associated with using either framework, particularly when working with fast-fitting models like rpart. In these cases, the additional processing time introduced by the frameworks is more pronounced due to the inherently short training time of rpart models. This results in a higher relative overhead, reflecting the trade-offs between the convenience of a comprehensive framework and the directness of more basic approaches.
Conversely, when dealing with slower-fitting models such as ranger, the scenario shifts. For these more time-intensive models, the relative overhead introduced by the frameworks diminishes significantly. In such instances, the extended training times of the models absorb much of the frameworks’ inherent overhead, rendering it relatively negligible.
In summary, while there is no outright winner in terms of overall performance, the decision to use tidymodels or mlr3 should be informed by the specific requirements of the task at hand.
Set time limits for learners, tuning and nested resampling.
+
+ The mlr3 ecosystem is the framework for machine learning in R.
+An open-source collection of R packages providing a unified interface for machine learning in the R language. Successor of mlr.
+There are many packages in the mlr3 ecosystem that you may want to use. You can install the full mlr3 universe at once with:
+install.packages("mlr3verse")You can also use our Docker images.
+
Our book “Applied Machine Learning Using mlr3 in R” is the central entry point to mlr3 ecosystem. This essential guide covers key aspects of machine learning, from building and evaluating predictive models to advanced techniques like hyperparameter tuning for peak performance. It delves into constructing comprehensive machine learning pipelines, encompassing data pre-processing, modeling, and prediction aggregation.
+The book is primarily aimed at researchers, practitioners, and graduate students who use machine learning or who are interested in using it. It can be used as a textbook for an introductory or advanced machine learning class that uses R, as a reference for people who work with machine learning methods, and in industry for exploratory experiments in machine learning.
+In addition to the book, there are many other resources to learn more about mlr3. The gallery contains a collection of case studies that demonstrate the functionality of mlr3. The cheatsheets provide a quick overview of the most important functions. The resources section contains links to talks, courses, and other material.
+Get to know the basic building blocks of machine learning in mlr3. Train your first learner and estimate its performance with resampling. Compare the performance of learners with benchmarking.
+ + + +Optimize the hyperparameters of a classification tree on the Palmer Penguins data set. Become familiar with search spaces and transformations. Fit a final model with optimized hyperparameters for predicting new data.
+ + + +Build a preprocessing pipeline for missing data in the German Credit data set. Optimize the parameters of the pipeline and stack multiple learners into an ensemble model. Learn about techniques to tackle challenging data sets.
+ + + +Start a feature selection on the Titanic data set. Learn about different optimization algorithms and fit a final model. Estimate the performance of the optimized feature set with nested resampling.
+ + + +To keep the dependencies on other packages reasonable, the base package mlr3 only ships with with regression and classification trees from the rpart package and some learners for debugging. A subjective selection of implementations for essential ML algorithms can be found in mlr3learners package. Survival learners are provided by mlr3proba, cluster learners via mlr3cluster. Additional learners, including some learners which are not yet to be considered stable or which are not available on CRAN, are connected via the mlr3extralearners package. For neural networks, see the mlr3torch extension.
+Fit a classification tree on the Wisconsin Breast Cancer Data Set and predict on left-out observations.
library("mlr3verse")
+
+# retrieve the task
+task = tsk("breast_cancer")
+
+# split into two partitions
+split = partition(task)
+
+# retrieve a learner
+learner = lrn("classif.rpart", keep_model = TRUE, predict_type = "prob")
+
+# fit decision tree
+learner$train(task, split$train)
+
+# access learned model
+learner$modeln= 458
+
+node), split, n, loss, yval, (yprob)
+ * denotes terminal node
+
+ 1) root 458 163 benign (0.35589520 0.64410480)
+ 2) cell_shape=4,5,6,7,8,9,10 156 12 malignant (0.92307692 0.07692308) *
+ 3) cell_shape=1,2,3 302 19 benign (0.06291391 0.93708609)
+ 6) bl_cromatin=5,6,7,8,9,10 21 6 malignant (0.71428571 0.28571429)
+ 12) cl_thickness=4,5,6,7,8,9,10 13 0 malignant (1.00000000 0.00000000) *
+ 13) cl_thickness=1,2,3 8 2 benign (0.25000000 0.75000000) *
+ 7) bl_cromatin=1,2,3,4 281 4 benign (0.01423488 0.98576512) *# predict on data frame with new data
+predictions = learner$predict_newdata(task$data(split$test))
+
+# predict on subset of the task
+predictions = learner$predict(task, split$test)
+
+# inspect predictions
+predictions<PredictionClassif> for 225 observations:
+ row_ids truth response prob.malignant prob.benign
+ 6 malignant malignant 0.92307692 0.07692308
+ 10 benign benign 0.01423488 0.98576512
+ 11 benign benign 0.01423488 0.98576512
+---
+ 672 benign benign 0.01423488 0.98576512
+ 677 benign benign 0.01423488 0.98576512
+ 683 malignant malignant 0.92307692 0.07692308predictions$score(msr("classif.auc"))classif.auc
+ 0.9259096 autoplot(predictions, type = "roc")
${w.content.map(p).join("")}
`:""}return f.map(p).join("")}function LRt(i,a){a&&i.attr("style",a)}function MRt(i,a,f,p){const w=i.append("foreignObject"),y=w.append("xhtml:div"),b=a.label,E=a.isNode?"nodeLabel":"edgeLabel";y.html(`"+b+""),LRt(y,a.labelStyle),y.style("display","table-cell"),y.style("white-space","nowrap"),y.style("max-width",f+"px"),y.attr("xmlns","http://www.w3.org/1999/xhtml");let S=y.node().getBoundingClientRect();return S.width===f&&(y.style("display","table"),y.style("white-space","break-spaces"),y.style("width",f+"px"),S=y.node().getBoundingClientRect()),w.style("width",S.width),w.style("height",S.height),w.node()}function IBe(i,a,f){return i.append("tspan").attr("class","text-outer-tspan").attr("x",0).attr("y",a*f-.1+"em").attr("dy",f+"em")}function DRt(i,a,f,p=!1){const y=a.append("g");let b=y.insert("rect").attr("class","background");const E=y.append("text").attr("y","-10.1");let S=-1;if(f.forEach(N=>{S++;let B=IBe(E,S,1.1),R=[...N].reverse(),j,$=[];for(;R.length;)j=R.pop(),$.push(j),OBe(B,$),B.node().getComputedTextLength()>i&&($.pop(),R.push(j),OBe(B,$),$=[],S++,B=IBe(E,S,1.1))}),p){const N=E.node().getBBox(),B=2;return b.attr("x",-B).attr("y",-B).attr("width",N.width+2*B).attr("height",N.height+2*B),y.node()}else return E.node()}function OBe(i,a){i.text(""),a.forEach((f,p)=>{const w=i.append("tspan").attr("font-style",f.type==="em"?"italic":"normal").attr("class","text-inner-tspan").attr("font-weight",f.type==="strong"?"bold":"normal");p===0?w.text(f.content):w.text(" "+f.content)})}const dK=(i,a="",{style:f="",isTitle:p=!1,classes:w="",useHtmlLabels:y=!0,isNode:b=!0,width:E,addSvgBackground:S=!1}={})=>{if(Fe.info("createText",a,f,p,w,y,b,S),y){const N=ARt(a),B={isNode:b,label:XN(N).replace(/fa[blrs]?:fa-[\w-]+/g,j=>``),labelStyle:f.replace("fill:","color:")};return MRt(i,B,E,w)}else{const N=SRt(a),B=['"',"'",".",",",":",";","!","?","(",")","[","]","{","}"];let R;return N.forEach($=>{$.forEach(V=>{B.includes(V.content)&&R&&(R.content+=V.content,V.content=""),R=V})}),DRt(E,i,N,S)}},jd=async(i,a,f,p)=>{let w;const y=a.useHtmlLabels||d1(Tt().flowchart.htmlLabels);f?w=f:w="node default";const b=i.insert("g").attr("class",w).attr("id",a.domId||a.id),E=b.insert("g").attr("class","label").attr("style",a.labelStyle);let S;a.labelText===void 0?S="":S=typeof a.labelText=="string"?a.labelText:a.labelText[0];const N=E.node();let B;a.labelType==="markdown"?B=dK(E,ep(XN(S),Tt()),{useHtmlLabels:y,width:a.width||Tt().flowchart.wrappingWidth,classes:"markdown-node-label"}):B=N.appendChild(sp(ep(XN(S),Tt()),a.labelStyle,!1,p));let R=B.getBBox();const j=a.padding/2;if(d1(Tt().flowchart.htmlLabels)){const $=B.children[0],V=Cr(B),Q=$.getElementsByTagName("img");if(Q){const oe=S.replace(/