diff --git a/.github/workflows/codeql.yml b/.github/workflows/codeql.yml
new file mode 100644
index 0000000..07302ab
--- /dev/null
+++ b/.github/workflows/codeql.yml
@@ -0,0 +1,93 @@
+# For most projects, this workflow file will not need changing; you simply need
+# to commit it to your repository.
+#
+# You may wish to alter this file to override the set of languages analyzed,
+# or to provide custom queries or build logic.
+#
+# ******** NOTE ********
+# We have attempted to detect the languages in your repository. Please check
+# the `language` matrix defined below to confirm you have the correct set of
+# supported CodeQL languages.
+#
+name: "CodeQL"
+
+on:
+ push:
+ branches: [ "main" ]
+ pull_request:
+ branches: [ "main" ]
+ schedule:
+ - cron: '23 2 * * 6'
+
+jobs:
+ analyze:
+ name: Analyze (${{ matrix.language }})
+ # Runner size impacts CodeQL analysis time. To learn more, please see:
+ # - https://gh.io/recommended-hardware-resources-for-running-codeql
+ # - https://gh.io/supported-runners-and-hardware-resources
+ # - https://gh.io/using-larger-runners (GitHub.com only)
+ # Consider using larger runners or machines with greater resources for possible analysis time improvements.
+ runs-on: ${{ (matrix.language == 'swift' && 'macos-latest') || 'ubuntu-latest' }}
+ timeout-minutes: ${{ (matrix.language == 'swift' && 120) || 360 }}
+ permissions:
+ # required for all workflows
+ security-events: write
+
+ # required to fetch internal or private CodeQL packs
+ packages: read
+
+ # only required for workflows in private repositories
+ actions: read
+ contents: read
+
+ strategy:
+ fail-fast: false
+ matrix:
+ include:
+ - language: python
+ build-mode: none
+ # CodeQL supports the following values keywords for 'language': 'c-cpp', 'csharp', 'go', 'java-kotlin', 'javascript-typescript', 'python', 'ruby', 'swift'
+ # Use `c-cpp` to analyze code written in C, C++ or both
+ # Use 'java-kotlin' to analyze code written in Java, Kotlin or both
+ # Use 'javascript-typescript' to analyze code written in JavaScript, TypeScript or both
+ # To learn more about changing the languages that are analyzed or customizing the build mode for your analysis,
+ # see https://docs.github.com/en/code-security/code-scanning/creating-an-advanced-setup-for-code-scanning/customizing-your-advanced-setup-for-code-scanning.
+ # If you are analyzing a compiled language, you can modify the 'build-mode' for that language to customize how
+ # your codebase is analyzed, see https://docs.github.com/en/code-security/code-scanning/creating-an-advanced-setup-for-code-scanning/codeql-code-scanning-for-compiled-languages
+ steps:
+ - name: Checkout repository
+ uses: actions/checkout@v4
+
+ # Initializes the CodeQL tools for scanning.
+ - name: Initialize CodeQL
+ uses: github/codeql-action/init@v3
+ with:
+ languages: ${{ matrix.language }}
+ build-mode: ${{ matrix.build-mode }}
+ # If you wish to specify custom queries, you can do so here or in a config file.
+ # By default, queries listed here will override any specified in a config file.
+ # Prefix the list here with "+" to use these queries and those in the config file.
+
+ # For more details on CodeQL's query packs, refer to: https://docs.github.com/en/code-security/code-scanning/automatically-scanning-your-code-for-vulnerabilities-and-errors/configuring-code-scanning#using-queries-in-ql-packs
+ # queries: security-extended,security-and-quality
+
+ # If the analyze step fails for one of the languages you are analyzing with
+ # "We were unable to automatically build your code", modify the matrix above
+ # to set the build mode to "manual" for that language. Then modify this step
+ # to build your code.
+ # ℹ️ Command-line programs to run using the OS shell.
+ # 📚 See https://docs.github.com/en/actions/using-workflows/workflow-syntax-for-github-actions#jobsjob_idstepsrun
+ - if: matrix.build-mode == 'manual'
+ shell: bash
+ run: |
+ echo 'If you are using a "manual" build mode for one or more of the' \
+ 'languages you are analyzing, replace this with the commands to build' \
+ 'your code, for example:'
+ echo ' make bootstrap'
+ echo ' make release'
+ exit 1
+
+ - name: Perform CodeQL Analysis
+ uses: github/codeql-action/analyze@v3
+ with:
+ category: "/language:${{matrix.language}}"
diff --git a/.github/workflows/just_deploy.yml b/.github/workflows/just_deploy.yml
new file mode 100644
index 0000000..7854fb3
--- /dev/null
+++ b/.github/workflows/just_deploy.yml
@@ -0,0 +1,48 @@
+# This workflows will upload a Python Package using Twine when a release is created
+# For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
+
+name: tests
+
+on:
+ push:
+ branches:
+ - main
+ - npe2
+ tags:
+ - "v*" # Push events to matching v*, i.e. v1.0, v20.15.10
+ pull_request:
+ branches:
+ - main
+ - npe2
+ workflow_dispatch:
+
+env:
+ OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
+
+jobs:
+
+ deploy:
+ # this will run when you have tagged a commit, starting with "v*"
+ # and requires that you have put your twine API key in your
+ # github secrets (see readme for details)
+ needs: [ test ]
+ runs-on: ubuntu-latest
+ if: contains(github.ref, 'tags')
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python
+ uses: actions/setup-python@v4
+ with:
+ python-version: "3.x"
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ pip install -U setuptools setuptools_scm wheel twine build
+ - name: Build and publish
+ env:
+ TWINE_USERNAME: __token__
+ TWINE_PASSWORD: ${{ secrets.TWINE_API_KEY }}
+ run: |
+ git tag
+ python -m build .
+ twine upload dist/*
diff --git a/README.md b/README.md
index ec049b3..a573386 100644
--- a/README.md
+++ b/README.md
@@ -3,10 +3,14 @@
[](https://github.com/royerlab/napari-chatgpt/raw/main/LICENSE)
[](https://pypi.org/project/napari-chatgpt)
[](https://python.org)
-[](https://github.com/royerlab/napari-chatgpt/actions)
+[](https://github.com/royerlab/napari-chatgpt/actions/workflows/test_and_deploy.yml)
[](https://codecov.io/gh/royerlab/napari-chatgpt)
+[](https://pepy.tech/project/napari-chatgpt)
+[](https://pepy.tech/project/napari-chatgpt)
[](https://napari-hub.org/plugins/napari-chatgpt)
[](https://doi.org/10.5281/zenodo.10828225)
+[](https://github.com/royerlab/napari-chatgpt/)
+[](https://git:hub.com/royerlab/napari-chatgpt/)

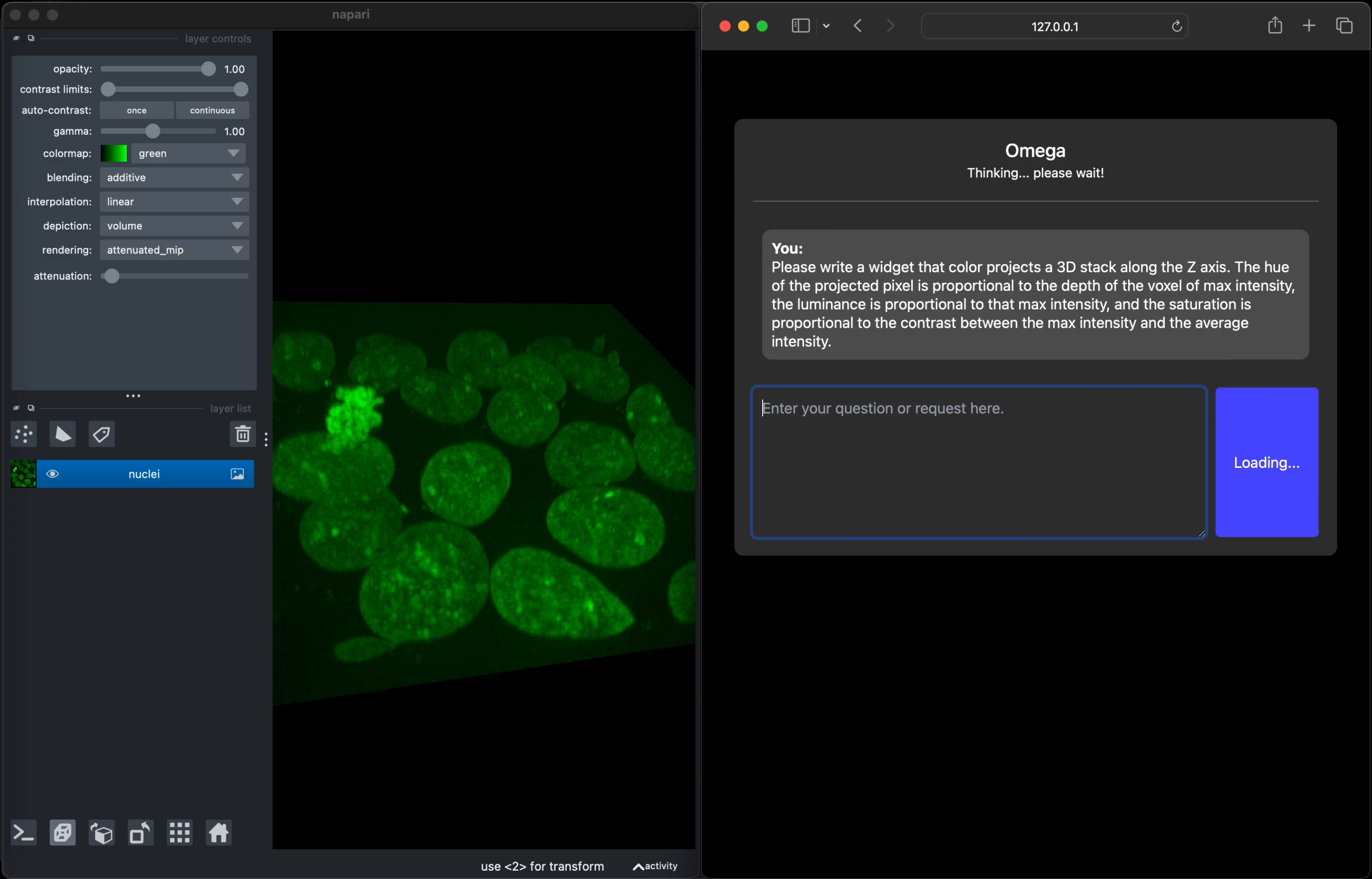 @@ -20,7 +24,7 @@ in a conversational manner.
This repository started as a 'week-end project'
by [Loic A. Royer](https://twitter.com/loicaroyer)
who leads a [research group](https://royerlab.org) at
-the [Chan Zuckerberg Biohub](https://czbiohub.org/sf/). It
+the [Chan Zuckerberg Biohub](https://royerlab.org). It
leverages [OpenAI](https://openai.com)'s ChatGPT API via
the [LangChain](https://python.langchain.com/en/latest/index.html) Python
library, as well as [napari](https://napari.org), a fast, interactive,
@@ -146,6 +150,7 @@ your request.
Omega is generally safe as long as you do not make dangerous requests. To be 100% safe, and
if your experiments with Omega could be potentially problematic, I recommend using this
software from within a sandboxed virtual machine.
+API keys are only as safe as the overall machine is, see the section below on API key hygiene.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
@@ -154,6 +159,15 @@ BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CON
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR
THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+## API key hygiene:
+
+Best Practices for Managing Your API Keys:
+- **Host Computer Hygiene:** Ensure that the machine you’re installing napari-chagot/Onega on is secure, free of malware and viruses, and otherwise not compromised. Make sure to install antivirus software on Windows.
+- **Security:** Treat your API key like a password. Do not share it with others or expose it in public repositories or forums.
+- **Cost Control:** Set spending limits on your OpenAI account (see [here](https://platform.openai.com/account/limits)).
+- **Regenerate Keys:** If you believe your API key has been compromised, cancel and regenerate it from the OpenAI API dashboard immediately.
+- **Key Storage:** Omega has a built-in 'API Key Vault' that encrypts keys using a password, this is the preferred approach. You can also store the key in an environment variable, but that is not encrypted and could compromise the key.
+
## Contributing
Contributions are extremely welcome. Tests can be run with [tox], please ensure
diff --git a/manuscript/SuppTable3_Prompt_Table.pdf b/manuscript/prompt_table.pdf
similarity index 82%
rename from manuscript/SuppTable3_Prompt_Table.pdf
rename to manuscript/prompt_table.pdf
index b28deca..e2aca2e 100644
Binary files a/manuscript/SuppTable3_Prompt_Table.pdf and b/manuscript/prompt_table.pdf differ
diff --git a/manuscript/SuppTable2_ReproducibilityAnalysis.pdf b/manuscript/reproducibility_analysis.pdf
similarity index 100%
rename from manuscript/SuppTable2_ReproducibilityAnalysis.pdf
rename to manuscript/reproducibility_analysis.pdf
diff --git a/manuscript/SuppTable1_Example_widgets.pdf b/manuscript/widget_table.pdf
similarity index 100%
rename from manuscript/SuppTable1_Example_widgets.pdf
rename to manuscript/widget_table.pdf
diff --git a/setup.cfg b/setup.cfg
index 98d1409..723cf4f 100644
--- a/setup.cfg
+++ b/setup.cfg
@@ -1,11 +1,11 @@
[metadata]
name = napari-chatgpt
-version = v2024.3.13.3
+version = v2024.5.15
description = A napari plugin to process and analyse images with chatGPT.
long_description = file: README.md
long_description_content_type = text/markdown
url = https://github.com/royerlab/napari-chatgpt
-author = Loic A. Royer
+author = Loic A. Royer and contributors
author_email = royerloic@gmail.com
license = BSD-3-Clause
license_files = LICENSE
@@ -36,9 +36,11 @@ install_requires =
scikit-image
qtpy
QtAwesome
- langchain==0.1.11
- langchain-openai==0.0.8
- openai==1.13.3
+ langchain==0.2.0rc2
+ langchain-community==0.2.0rc1
+ langchain-openai==0.1.6
+ langchain-anthropic==0.1.11
+ openai==1.29.0
anthropic
fastapi
uvicorn
@@ -52,7 +54,7 @@ install_requires =
xarray
arbol
playwright
- duckduckgo_search
+ duckduckgo_search==5.3.0b4
ome-zarr
transformers
cryptography
@@ -64,6 +66,9 @@ install_requires =
jedi
black
+ # needed because lxml has spun out this code out of its main repo:
+ lxml_html_clean
+
python_requires = >=3.9
include_package_data = True
@@ -90,6 +95,5 @@ testing =
napari
pyqt5
-
[options.package_data]
* = *.yaml
diff --git a/src/microplugin/code_editor/clickable_icon.py b/src/microplugin/code_editor/clickable_icon.py
index 78123ac..d4e49c9 100644
--- a/src/microplugin/code_editor/clickable_icon.py
+++ b/src/microplugin/code_editor/clickable_icon.py
@@ -1,5 +1,8 @@
from typing import Union
+from qtpy.QtCore import QSize
+from qtpy.QtCore import QRect, QPoint
+from qtpy.QtGui import QPainter
from qtpy.QtCore import Qt, Signal
from qtpy.QtGui import QIcon, QPixmap, QColor, QImage
from qtpy.QtWidgets import QLabel
@@ -58,10 +61,36 @@ def __init__(
# Change cursor to hand pointer when hovering over the label:
self.setCursor(Qt.PointingHandCursor)
+ # Highlight color when hovering over the label:
+ self.highlight_color = QColor(200, 200, 200,
+ 50) # Semi-transparent gray color
+
+ # Flag to indicate if the mouse is hovering over the label:
+ self.is_hovered = False
+
+
def mousePressEvent(self, event):
if event.button() == Qt.LeftButton:
self.clicked.emit()
+ def enterEvent(self, event):
+ self.is_hovered = True
+ self.update()
+
+ def leaveEvent(self, event):
+ self.is_hovered = False
+ self.update()
+
+ def paintEvent(self, event):
+ super().paintEvent(event)
+
+ if self.is_hovered:
+ painter = QPainter(self)
+ painter.setCompositionMode(QPainter.CompositionMode_SourceAtop)
+ painter.fillRect(self.rect(),
+ self.highlight_color)
+ painter.end()
+
@staticmethod
def _modify_pixmap_for_dark_ui(pixmap):
# Convert QPixmap to QImage
diff --git a/src/napari_chatgpt/_widget.py b/src/napari_chatgpt/_widget.py
index edeb3da..7f42d2d 100644
--- a/src/napari_chatgpt/_widget.py
+++ b/src/napari_chatgpt/_widget.py
@@ -126,8 +126,8 @@ def _model_selection(self):
model_list.append('claude-2.1')
model_list.append('claude-2.0')
model_list.append('claude-instant-1.2')
- #model_list.append('claude-3-sonnet-20240229')
- #model_list.append('claude-3-opus-20240229')
+ model_list.append('claude-3-sonnet-20240229')
+ model_list.append('claude-3-opus-20240229')
if is_ollama_running():
@@ -159,7 +159,7 @@ def _model_selection(self):
model_list = best_models + [m for m in model_list if m not in best_models]
# Ensure that the very best models are at the top of the list:
- very_best_models = [m for m in model_list if ('gpt-4-0125' in m) ]
+ very_best_models = [m for m in model_list if ('gpt-4-turbo-2024-04-09' in m) ]
model_list = very_best_models + [m for m in model_list if m not in very_best_models]
# normalise list:
@@ -450,14 +450,14 @@ def _start_omega(self):
main_llm_model_name = self.model_combo_box.currentText()
# Warn users with a modal window that the selected model might be sub-optimal:
- if 'gpt-4' not in main_llm_model_name:
+ if 'gpt-4' not in main_llm_model_name and 'claude-3-opus' not in main_llm_model_name:
aprint("Warning: you did not select a gpt-4 level model. Omega's cognitive and coding abilities will be degraded.")
show_warning_dialog(f"You have selected this model: '{main_llm_model_name}'. "
- f"This is not a GPT4-level model. "
+ f"This is not a GPT4 or Claude-3-opus level model. "
f"Omega's cognitive and coding abilities will be degraded. "
f"It might even completely fail or be too slow. "
f"Please visit our wiki "
- f"for information on how to gain access to GPT4.")
+ f"for information on how to gain access to GPT4 (or Claude-3).")
# Set tool LLM model name via configuration file.
tool_llm_model_name = self.config.get('tool_llm_model_name', 'same')
diff --git a/src/napari_chatgpt/chat_server/chat_server.py b/src/napari_chatgpt/chat_server/chat_server.py
index 9e6840c..4fb7d7d 100644
--- a/src/napari_chatgpt/chat_server/chat_server.py
+++ b/src/napari_chatgpt/chat_server/chat_server.py
@@ -300,7 +300,8 @@ def start_chat_server(viewer: napari.Viewer = None,
bridge = NapariBridge(viewer=viewer)
# Register snapshot function:
- notebook.register_snapshot_function(bridge.take_snapshot)
+ if notebook:
+ notebook.register_snapshot_function(bridge.take_snapshot)
# Instantiates server:
chat_server = NapariChatServer(notebook=notebook,
diff --git a/src/napari_chatgpt/llm/llms.py b/src/napari_chatgpt/llm/llms.py
index fae7e99..aaad6d9 100644
--- a/src/napari_chatgpt/llm/llms.py
+++ b/src/napari_chatgpt/llm/llms.py
@@ -63,9 +63,16 @@ def _instantiate_single_llm(llm_model_name: str,
elif 'claude' in llm_model_name:
# Import Claude LLM:
- from langchain.chat_models import ChatAnthropic
+ from langchain_anthropic import ChatAnthropic
- max_token_limit = 8000
+ llm_model_name_lc = llm_model_name.lower()
+
+ if 'opus' in llm_model_name_lc or 'sonnet' in llm_model_name_lc or 'hiaku' in llm_model_name_lc or '2.1':
+ max_tokens_to_sample = 4096
+ max_token_limit = 200000
+ else:
+ max_tokens_to_sample = 4096
+ max_token_limit = 8000
# Instantiates Main LLM:
llm = ChatAnthropic(
@@ -73,7 +80,7 @@ def _instantiate_single_llm(llm_model_name: str,
verbose=verbose,
streaming=streaming,
temperature=temperature,
- max_tokens_to_sample=max_token_limit,
+ max_tokens_to_sample=max_tokens_to_sample,
callbacks=[callback_handler])
return llm, max_token_limit
@@ -103,7 +110,7 @@ def _instantiate_single_llm(llm_model_name: str,
# Wait a bit:
sleep(3)
- # Make ure that Ollama is running
+ # Make sure that Ollama is running
if not is_ollama_running(ollama_host, ollama_port):
aprint(f"Ollama server is not running on '{ollama_host}'. Please start the Ollama server on this machine and make sure the port '{ollama_port}' is open. ")
raise Exception("Ollama server is not running!")
diff --git a/src/napari_chatgpt/omega/tools/napari/cell_nuclei_segmentation_tool.py b/src/napari_chatgpt/omega/tools/napari/cell_nuclei_segmentation_tool.py
index b8822ad..f2996c9 100644
--- a/src/napari_chatgpt/omega/tools/napari/cell_nuclei_segmentation_tool.py
+++ b/src/napari_chatgpt/omega/tools/napari/cell_nuclei_segmentation_tool.py
@@ -235,19 +235,32 @@ def _run_code(self, request: str, code: str, viewer: Viewer) -> str:
loaded_module = dynamic_import(code)
# get the function:
- segment = getattr(loaded_module, 'segment')
+ segment_function = getattr(loaded_module, 'segment')
# Run segmentation:
with asection(f"Running segmentation..."):
- segmented_image = segment(viewer)
+ segmented_image = segment_function(viewer)
+
+ # Add to viewer:
+ viewer.add_labels(segmented_image, name='segmented')
+
+ # Add call to segment function:
+ code += f"\n\nsegmented_image = segment(viewer)"
+ code += f"\nviewer.add_labels(segmented_image, name='segmented')"
# At this point we assume the code ran successfully and we add it to the notebook:
if self.notebook:
self.notebook.add_code_cell(code)
+ # Come up with a filename:
+ filename = f"generated_code_{self.__class__.__name__}.py"
+
+ # Add the snippet to the code snippet editor:
+ from microplugin.microplugin_window import MicroPluginMainWindow
+ MicroPluginMainWindow.add_snippet(filename=filename,
+ code=code)
+
- # Add to viewer:
- viewer.add_labels(segmented_image, name='segmented')
# Message:
message = f"Success: image segmented and added to the viewer as a labels layer named 'segmented'."
diff --git a/src/napari_chatgpt/omega/tools/napari/image_denoising_tool.py b/src/napari_chatgpt/omega/tools/napari/image_denoising_tool.py
index 7d5d265..af39ddf 100644
--- a/src/napari_chatgpt/omega/tools/napari/image_denoising_tool.py
+++ b/src/napari_chatgpt/omega/tools/napari/image_denoising_tool.py
@@ -148,19 +148,31 @@ def _run_code(self, request: str, code: str, viewer: Viewer) -> str:
loaded_module = dynamic_import(code)
# get the function:
- denoise = getattr(loaded_module, 'denoise')
-
- # At this point we assume the code ran successfully and we add it to the notebook:
- if self.notebook:
- self.notebook.add_code_cell(code)
+ denoise_function = getattr(loaded_module, 'denoise')
# Run denoising:
with asection(f"Running image denoising..."):
- denoised_image = denoise(viewer)
+ denoised_image = denoise_function(viewer)
# Add to viewer:
viewer.add_image(denoised_image, name='denoised')
+ # Add call to denoise function & add to napari viewer:
+ code += f"\n\ndenoised_image = denoise(viewer)"
+ code += f"\nviewer.add_image(denoised_image, name='denoised')"
+
+ # At this point we assume the code ran successfully and we add it to the notebook:
+ if self.notebook:
+ self.notebook.add_code_cell(code)
+
+ # Come up with a filename:
+ filename = f"generated_code_{self.__class__.__name__}.py"
+
+ # Add the snippet to the code snippet editor:
+ from microplugin.microplugin_window import MicroPluginMainWindow
+ MicroPluginMainWindow.add_snippet(filename=filename,
+ code=code)
+
# Message:
message = f"Success: image denoised and added to the viewer as layer 'denoised'. "
diff --git a/src/napari_chatgpt/omega/tools/napari/viewer_query_tool.py b/src/napari_chatgpt/omega/tools/napari/viewer_query_tool.py
index 8b80894..a96f1d9 100644
--- a/src/napari_chatgpt/omega/tools/napari/viewer_query_tool.py
+++ b/src/napari_chatgpt/omega/tools/napari/viewer_query_tool.py
@@ -98,10 +98,23 @@ def _run_code(self, query: str, code: str, viewer: Viewer) -> str:
# Run query code:
response = query_function(viewer)
+ # Add call to query function and print response:
+ code += f"\n\nresponse = query(viewer)"
+ code += f"\n\nprint(response)"
+
# Add successfully run code to notebook:
if self.notebook:
self.notebook.add_code_cell(code+'\n\nquery(viewer)')
+ # Come up with a filename:
+ filename = f"generated_code_{self.__class__.__name__}.py"
+
+ # Add the snippet to the code snippet editor:
+ from microplugin.microplugin_window import \
+ MicroPluginMainWindow
+ MicroPluginMainWindow.add_snippet(filename=filename,
+ code=code)
+
# Get captured stdout:
captured_output = f.getvalue()
diff --git a/src/napari_chatgpt/utils/ollama/ollama.py b/src/napari_chatgpt/utils/ollama/ollama.py
index 29f2956..a396be4 100644
--- a/src/napari_chatgpt/utils/ollama/ollama.py
+++ b/src/napari_chatgpt/utils/ollama/ollama.py
@@ -5,7 +5,7 @@
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.schema import LLMResult
-from langchain_community.llms import Ollama
+from langchain_community.llms.ollama import Ollama
_aysync_ollama_thread_pool = ThreadPoolExecutor()
diff --git a/src/napari_chatgpt/utils/openai/default_model.py b/src/napari_chatgpt/utils/openai/default_model.py
index e3f683e..4d6d892 100644
--- a/src/napari_chatgpt/utils/openai/default_model.py
+++ b/src/napari_chatgpt/utils/openai/default_model.py
@@ -23,6 +23,10 @@ def model_key(model):
parts = model.split('-')
# Get the main version (e.g., '3.5' or '4' from 'gpt-3.5' or 'gpt-4')
main_version = parts[1]
+
+ if 'o' in main_version:
+ main_version = main_version.replace('o', '.25')
+
# Use the length of the model name as a secondary sorting criterion
length = len(model)
# Sort by main version (descending), then by length (ascending)
diff --git a/src/napari_chatgpt/utils/openai/test/gpt_vision_test.py b/src/napari_chatgpt/utils/openai/test/gpt_vision_test.py
index 245fb0d..f46003f 100644
--- a/src/napari_chatgpt/utils/openai/test/gpt_vision_test.py
+++ b/src/napari_chatgpt/utils/openai/test/gpt_vision_test.py
@@ -29,7 +29,7 @@ def test_gpt_vision():
print(description_2)
- assert 'futuristic' in description_2 and ('sunset' in description_2 or 'sunrise' in description_2 or 'landscape' in description_2)
+ assert ('futuristic' in description_2 or 'science fiction' in description_2 or 'robots' in description_2) and ('sunset' in description_2 or 'sunrise' in description_2 or 'landscape' in description_2)
def _get_image_path(image_name: str):
diff --git a/src/napari_chatgpt/utils/python/conda_utils.py b/src/napari_chatgpt/utils/python/conda_utils.py
index 995efd3..9f0b516 100644
--- a/src/napari_chatgpt/utils/python/conda_utils.py
+++ b/src/napari_chatgpt/utils/python/conda_utils.py
@@ -7,6 +7,10 @@
def conda_install(list_of_packages: List[str], channel:str = None) -> bool:
+
+ # Ensure it is a list and remove duplicates:
+ list_of_packages = list(set(list_of_packages))
+
base_command = "conda install -y"
if channel:
diff --git a/src/napari_chatgpt/utils/python/missing_packages.py b/src/napari_chatgpt/utils/python/missing_packages.py
index c0fef24..c5f25f6 100644
--- a/src/napari_chatgpt/utils/python/missing_packages.py
+++ b/src/napari_chatgpt/utils/python/missing_packages.py
@@ -89,6 +89,9 @@ def required_packages(code: str,
# Parse the list:
list_of_packages = list_of_packages_str.split()
+ # Remove duplicates:
+ list_of_packages = list(set(list_of_packages))
+
# Strip each package name of white spaces:
list_of_packages = [p.strip() for p in list_of_packages]
diff --git a/src/napari_chatgpt/utils/python/pip_utils.py b/src/napari_chatgpt/utils/python/pip_utils.py
index 450f5ad..6921c0c 100644
--- a/src/napari_chatgpt/utils/python/pip_utils.py
+++ b/src/napari_chatgpt/utils/python/pip_utils.py
@@ -34,8 +34,8 @@ def pip_install(packages: List[str],
aprint(f'Packages left: {packages}')
message += f"Removing 'included' packages that should be already installed with Omega: {', '.join(included_packages)}\n"
- # Ensure it is a list:
- packages = list(packages)
+ # Ensure it is a list and remove duplicates:
+ packages = list(set(packages))
if special_rules:
all_packages_str = ', '.join(packages)
@@ -163,6 +163,9 @@ def pip_uninstall(list_of_packages: List[str]) -> bool:
error_occurred = False
+ # Ensure it is a list and remove duplicates:
+ list_of_packages = list(set(list_of_packages))
+
with asection(f"Installing up to {len(list_of_packages)} packages with pip:"):
for package in list_of_packages:
diff --git a/src/napari_chatgpt/utils/python/test/add_comments_test.py b/src/napari_chatgpt/utils/python/test/add_comments_test.py
index bbc1def..8fa462e 100644
--- a/src/napari_chatgpt/utils/python/test/add_comments_test.py
+++ b/src/napari_chatgpt/utils/python/test/add_comments_test.py
@@ -35,5 +35,8 @@ def test_add_comments():
assert len(commented_code) >= len(___generated_python_code)
# Count the number of comments:
- assert commented_code.count('#') >= 4
+ assert commented_code.count('#') >= 2
+
+ # Count the number of docstrings:
+ assert commented_code.count('"""') >= 2
diff --git a/src/napari_chatgpt/utils/python/test/modify_code_test.py b/src/napari_chatgpt/utils/python/test/modify_code_test.py
index ca5b5c1..c60de62 100644
--- a/src/napari_chatgpt/utils/python/test/modify_code_test.py
+++ b/src/napari_chatgpt/utils/python/test/modify_code_test.py
@@ -25,7 +25,7 @@ def test_modify_code():
assert len(modified_code) >= len(___generated_python_code)
- assert 'multichannel' in modified_code
+ assert 'multichannel' in modified_code or 'multi-channel' in modified_code or 'channel' in modified_code
diff --git a/src/napari_chatgpt/utils/web/test/duckduckgo_test.py b/src/napari_chatgpt/utils/web/test/duckduckgo_test.py
index bcbaa07..bbf7d0d 100644
--- a/src/napari_chatgpt/utils/web/test/duckduckgo_test.py
+++ b/src/napari_chatgpt/utils/web/test/duckduckgo_test.py
@@ -12,6 +12,7 @@ def test_duckduckgo_search_overview_summary():
text = summary_ddg(query, do_summarize=True)
aprint(text)
assert 'Mickey' in text
+ assert 'Web search failed' not in text
def test_duckduckgo_search_overview():
@@ -19,3 +20,4 @@ def test_duckduckgo_search_overview():
text = summary_ddg(query, do_summarize=False)
aprint(text)
assert 'Mickey' in text
+ assert 'Web search failed' not in text
diff --git a/src/napari_chatgpt/utils/web/test/metasearch_test.py b/src/napari_chatgpt/utils/web/test/metasearch_test.py
index 5e08af9..5fb3799 100644
--- a/src/napari_chatgpt/utils/web/test/metasearch_test.py
+++ b/src/napari_chatgpt/utils/web/test/metasearch_test.py
@@ -12,6 +12,7 @@ def test_metasearch_summary():
text = metasearch(query, do_summarize=True)
aprint(text)
assert 'Mickey' in text
+ assert 'Web search failed' not in text
def test_metasearch():
@@ -19,3 +20,4 @@ def test_metasearch():
text = metasearch(query, do_summarize=False)
aprint(text)
assert 'Mickey' in text
+ assert 'Web search failed' not in text
diff --git a/src/napari_chatgpt/utils/web/wikipedia.py b/src/napari_chatgpt/utils/web/wikipedia.py
index 87d4155..f8c0407 100644
--- a/src/napari_chatgpt/utils/web/wikipedia.py
+++ b/src/napari_chatgpt/utils/web/wikipedia.py
@@ -7,12 +7,14 @@
def search_wikipedia(query: str,
num_results: int = 3,
+ lang: str = "en",
max_text_length: int = 4000,
do_summarize: bool = False,
llm: BaseLLM = None) -> str:
# Run a google search specifically on wikipedia:
results = search_ddg(query=f"{query} site:wikipedia.org",
- num_results=max(10, num_results))
+ num_results=min(10, num_results),
+ lang=lang)
# keep the top k results:
results = results[0: num_results]
@@ -20,7 +24,7 @@ in a conversational manner.
This repository started as a 'week-end project'
by [Loic A. Royer](https://twitter.com/loicaroyer)
who leads a [research group](https://royerlab.org) at
-the [Chan Zuckerberg Biohub](https://czbiohub.org/sf/). It
+the [Chan Zuckerberg Biohub](https://royerlab.org). It
leverages [OpenAI](https://openai.com)'s ChatGPT API via
the [LangChain](https://python.langchain.com/en/latest/index.html) Python
library, as well as [napari](https://napari.org), a fast, interactive,
@@ -146,6 +150,7 @@ your request.
Omega is generally safe as long as you do not make dangerous requests. To be 100% safe, and
if your experiments with Omega could be potentially problematic, I recommend using this
software from within a sandboxed virtual machine.
+API keys are only as safe as the overall machine is, see the section below on API key hygiene.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
@@ -154,6 +159,15 @@ BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CON
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR
THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+## API key hygiene:
+
+Best Practices for Managing Your API Keys:
+- **Host Computer Hygiene:** Ensure that the machine you’re installing napari-chagot/Onega on is secure, free of malware and viruses, and otherwise not compromised. Make sure to install antivirus software on Windows.
+- **Security:** Treat your API key like a password. Do not share it with others or expose it in public repositories or forums.
+- **Cost Control:** Set spending limits on your OpenAI account (see [here](https://platform.openai.com/account/limits)).
+- **Regenerate Keys:** If you believe your API key has been compromised, cancel and regenerate it from the OpenAI API dashboard immediately.
+- **Key Storage:** Omega has a built-in 'API Key Vault' that encrypts keys using a password, this is the preferred approach. You can also store the key in an environment variable, but that is not encrypted and could compromise the key.
+
## Contributing
Contributions are extremely welcome. Tests can be run with [tox], please ensure
diff --git a/manuscript/SuppTable3_Prompt_Table.pdf b/manuscript/prompt_table.pdf
similarity index 82%
rename from manuscript/SuppTable3_Prompt_Table.pdf
rename to manuscript/prompt_table.pdf
index b28deca..e2aca2e 100644
Binary files a/manuscript/SuppTable3_Prompt_Table.pdf and b/manuscript/prompt_table.pdf differ
diff --git a/manuscript/SuppTable2_ReproducibilityAnalysis.pdf b/manuscript/reproducibility_analysis.pdf
similarity index 100%
rename from manuscript/SuppTable2_ReproducibilityAnalysis.pdf
rename to manuscript/reproducibility_analysis.pdf
diff --git a/manuscript/SuppTable1_Example_widgets.pdf b/manuscript/widget_table.pdf
similarity index 100%
rename from manuscript/SuppTable1_Example_widgets.pdf
rename to manuscript/widget_table.pdf
diff --git a/setup.cfg b/setup.cfg
index 98d1409..723cf4f 100644
--- a/setup.cfg
+++ b/setup.cfg
@@ -1,11 +1,11 @@
[metadata]
name = napari-chatgpt
-version = v2024.3.13.3
+version = v2024.5.15
description = A napari plugin to process and analyse images with chatGPT.
long_description = file: README.md
long_description_content_type = text/markdown
url = https://github.com/royerlab/napari-chatgpt
-author = Loic A. Royer
+author = Loic A. Royer and contributors
author_email = royerloic@gmail.com
license = BSD-3-Clause
license_files = LICENSE
@@ -36,9 +36,11 @@ install_requires =
scikit-image
qtpy
QtAwesome
- langchain==0.1.11
- langchain-openai==0.0.8
- openai==1.13.3
+ langchain==0.2.0rc2
+ langchain-community==0.2.0rc1
+ langchain-openai==0.1.6
+ langchain-anthropic==0.1.11
+ openai==1.29.0
anthropic
fastapi
uvicorn
@@ -52,7 +54,7 @@ install_requires =
xarray
arbol
playwright
- duckduckgo_search
+ duckduckgo_search==5.3.0b4
ome-zarr
transformers
cryptography
@@ -64,6 +66,9 @@ install_requires =
jedi
black
+ # needed because lxml has spun out this code out of its main repo:
+ lxml_html_clean
+
python_requires = >=3.9
include_package_data = True
@@ -90,6 +95,5 @@ testing =
napari
pyqt5
-
[options.package_data]
* = *.yaml
diff --git a/src/microplugin/code_editor/clickable_icon.py b/src/microplugin/code_editor/clickable_icon.py
index 78123ac..d4e49c9 100644
--- a/src/microplugin/code_editor/clickable_icon.py
+++ b/src/microplugin/code_editor/clickable_icon.py
@@ -1,5 +1,8 @@
from typing import Union
+from qtpy.QtCore import QSize
+from qtpy.QtCore import QRect, QPoint
+from qtpy.QtGui import QPainter
from qtpy.QtCore import Qt, Signal
from qtpy.QtGui import QIcon, QPixmap, QColor, QImage
from qtpy.QtWidgets import QLabel
@@ -58,10 +61,36 @@ def __init__(
# Change cursor to hand pointer when hovering over the label:
self.setCursor(Qt.PointingHandCursor)
+ # Highlight color when hovering over the label:
+ self.highlight_color = QColor(200, 200, 200,
+ 50) # Semi-transparent gray color
+
+ # Flag to indicate if the mouse is hovering over the label:
+ self.is_hovered = False
+
+
def mousePressEvent(self, event):
if event.button() == Qt.LeftButton:
self.clicked.emit()
+ def enterEvent(self, event):
+ self.is_hovered = True
+ self.update()
+
+ def leaveEvent(self, event):
+ self.is_hovered = False
+ self.update()
+
+ def paintEvent(self, event):
+ super().paintEvent(event)
+
+ if self.is_hovered:
+ painter = QPainter(self)
+ painter.setCompositionMode(QPainter.CompositionMode_SourceAtop)
+ painter.fillRect(self.rect(),
+ self.highlight_color)
+ painter.end()
+
@staticmethod
def _modify_pixmap_for_dark_ui(pixmap):
# Convert QPixmap to QImage
diff --git a/src/napari_chatgpt/_widget.py b/src/napari_chatgpt/_widget.py
index edeb3da..7f42d2d 100644
--- a/src/napari_chatgpt/_widget.py
+++ b/src/napari_chatgpt/_widget.py
@@ -126,8 +126,8 @@ def _model_selection(self):
model_list.append('claude-2.1')
model_list.append('claude-2.0')
model_list.append('claude-instant-1.2')
- #model_list.append('claude-3-sonnet-20240229')
- #model_list.append('claude-3-opus-20240229')
+ model_list.append('claude-3-sonnet-20240229')
+ model_list.append('claude-3-opus-20240229')
if is_ollama_running():
@@ -159,7 +159,7 @@ def _model_selection(self):
model_list = best_models + [m for m in model_list if m not in best_models]
# Ensure that the very best models are at the top of the list:
- very_best_models = [m for m in model_list if ('gpt-4-0125' in m) ]
+ very_best_models = [m for m in model_list if ('gpt-4-turbo-2024-04-09' in m) ]
model_list = very_best_models + [m for m in model_list if m not in very_best_models]
# normalise list:
@@ -450,14 +450,14 @@ def _start_omega(self):
main_llm_model_name = self.model_combo_box.currentText()
# Warn users with a modal window that the selected model might be sub-optimal:
- if 'gpt-4' not in main_llm_model_name:
+ if 'gpt-4' not in main_llm_model_name and 'claude-3-opus' not in main_llm_model_name:
aprint("Warning: you did not select a gpt-4 level model. Omega's cognitive and coding abilities will be degraded.")
show_warning_dialog(f"You have selected this model: '{main_llm_model_name}'. "
- f"This is not a GPT4-level model. "
+ f"This is not a GPT4 or Claude-3-opus level model. "
f"Omega's cognitive and coding abilities will be degraded. "
f"It might even completely fail or be too slow. "
f"Please visit our wiki "
- f"for information on how to gain access to GPT4.")
+ f"for information on how to gain access to GPT4 (or Claude-3).")
# Set tool LLM model name via configuration file.
tool_llm_model_name = self.config.get('tool_llm_model_name', 'same')
diff --git a/src/napari_chatgpt/chat_server/chat_server.py b/src/napari_chatgpt/chat_server/chat_server.py
index 9e6840c..4fb7d7d 100644
--- a/src/napari_chatgpt/chat_server/chat_server.py
+++ b/src/napari_chatgpt/chat_server/chat_server.py
@@ -300,7 +300,8 @@ def start_chat_server(viewer: napari.Viewer = None,
bridge = NapariBridge(viewer=viewer)
# Register snapshot function:
- notebook.register_snapshot_function(bridge.take_snapshot)
+ if notebook:
+ notebook.register_snapshot_function(bridge.take_snapshot)
# Instantiates server:
chat_server = NapariChatServer(notebook=notebook,
diff --git a/src/napari_chatgpt/llm/llms.py b/src/napari_chatgpt/llm/llms.py
index fae7e99..aaad6d9 100644
--- a/src/napari_chatgpt/llm/llms.py
+++ b/src/napari_chatgpt/llm/llms.py
@@ -63,9 +63,16 @@ def _instantiate_single_llm(llm_model_name: str,
elif 'claude' in llm_model_name:
# Import Claude LLM:
- from langchain.chat_models import ChatAnthropic
+ from langchain_anthropic import ChatAnthropic
- max_token_limit = 8000
+ llm_model_name_lc = llm_model_name.lower()
+
+ if 'opus' in llm_model_name_lc or 'sonnet' in llm_model_name_lc or 'hiaku' in llm_model_name_lc or '2.1':
+ max_tokens_to_sample = 4096
+ max_token_limit = 200000
+ else:
+ max_tokens_to_sample = 4096
+ max_token_limit = 8000
# Instantiates Main LLM:
llm = ChatAnthropic(
@@ -73,7 +80,7 @@ def _instantiate_single_llm(llm_model_name: str,
verbose=verbose,
streaming=streaming,
temperature=temperature,
- max_tokens_to_sample=max_token_limit,
+ max_tokens_to_sample=max_tokens_to_sample,
callbacks=[callback_handler])
return llm, max_token_limit
@@ -103,7 +110,7 @@ def _instantiate_single_llm(llm_model_name: str,
# Wait a bit:
sleep(3)
- # Make ure that Ollama is running
+ # Make sure that Ollama is running
if not is_ollama_running(ollama_host, ollama_port):
aprint(f"Ollama server is not running on '{ollama_host}'. Please start the Ollama server on this machine and make sure the port '{ollama_port}' is open. ")
raise Exception("Ollama server is not running!")
diff --git a/src/napari_chatgpt/omega/tools/napari/cell_nuclei_segmentation_tool.py b/src/napari_chatgpt/omega/tools/napari/cell_nuclei_segmentation_tool.py
index b8822ad..f2996c9 100644
--- a/src/napari_chatgpt/omega/tools/napari/cell_nuclei_segmentation_tool.py
+++ b/src/napari_chatgpt/omega/tools/napari/cell_nuclei_segmentation_tool.py
@@ -235,19 +235,32 @@ def _run_code(self, request: str, code: str, viewer: Viewer) -> str:
loaded_module = dynamic_import(code)
# get the function:
- segment = getattr(loaded_module, 'segment')
+ segment_function = getattr(loaded_module, 'segment')
# Run segmentation:
with asection(f"Running segmentation..."):
- segmented_image = segment(viewer)
+ segmented_image = segment_function(viewer)
+
+ # Add to viewer:
+ viewer.add_labels(segmented_image, name='segmented')
+
+ # Add call to segment function:
+ code += f"\n\nsegmented_image = segment(viewer)"
+ code += f"\nviewer.add_labels(segmented_image, name='segmented')"
# At this point we assume the code ran successfully and we add it to the notebook:
if self.notebook:
self.notebook.add_code_cell(code)
+ # Come up with a filename:
+ filename = f"generated_code_{self.__class__.__name__}.py"
+
+ # Add the snippet to the code snippet editor:
+ from microplugin.microplugin_window import MicroPluginMainWindow
+ MicroPluginMainWindow.add_snippet(filename=filename,
+ code=code)
+
- # Add to viewer:
- viewer.add_labels(segmented_image, name='segmented')
# Message:
message = f"Success: image segmented and added to the viewer as a labels layer named 'segmented'."
diff --git a/src/napari_chatgpt/omega/tools/napari/image_denoising_tool.py b/src/napari_chatgpt/omega/tools/napari/image_denoising_tool.py
index 7d5d265..af39ddf 100644
--- a/src/napari_chatgpt/omega/tools/napari/image_denoising_tool.py
+++ b/src/napari_chatgpt/omega/tools/napari/image_denoising_tool.py
@@ -148,19 +148,31 @@ def _run_code(self, request: str, code: str, viewer: Viewer) -> str:
loaded_module = dynamic_import(code)
# get the function:
- denoise = getattr(loaded_module, 'denoise')
-
- # At this point we assume the code ran successfully and we add it to the notebook:
- if self.notebook:
- self.notebook.add_code_cell(code)
+ denoise_function = getattr(loaded_module, 'denoise')
# Run denoising:
with asection(f"Running image denoising..."):
- denoised_image = denoise(viewer)
+ denoised_image = denoise_function(viewer)
# Add to viewer:
viewer.add_image(denoised_image, name='denoised')
+ # Add call to denoise function & add to napari viewer:
+ code += f"\n\ndenoised_image = denoise(viewer)"
+ code += f"\nviewer.add_image(denoised_image, name='denoised')"
+
+ # At this point we assume the code ran successfully and we add it to the notebook:
+ if self.notebook:
+ self.notebook.add_code_cell(code)
+
+ # Come up with a filename:
+ filename = f"generated_code_{self.__class__.__name__}.py"
+
+ # Add the snippet to the code snippet editor:
+ from microplugin.microplugin_window import MicroPluginMainWindow
+ MicroPluginMainWindow.add_snippet(filename=filename,
+ code=code)
+
# Message:
message = f"Success: image denoised and added to the viewer as layer 'denoised'. "
diff --git a/src/napari_chatgpt/omega/tools/napari/viewer_query_tool.py b/src/napari_chatgpt/omega/tools/napari/viewer_query_tool.py
index 8b80894..a96f1d9 100644
--- a/src/napari_chatgpt/omega/tools/napari/viewer_query_tool.py
+++ b/src/napari_chatgpt/omega/tools/napari/viewer_query_tool.py
@@ -98,10 +98,23 @@ def _run_code(self, query: str, code: str, viewer: Viewer) -> str:
# Run query code:
response = query_function(viewer)
+ # Add call to query function and print response:
+ code += f"\n\nresponse = query(viewer)"
+ code += f"\n\nprint(response)"
+
# Add successfully run code to notebook:
if self.notebook:
self.notebook.add_code_cell(code+'\n\nquery(viewer)')
+ # Come up with a filename:
+ filename = f"generated_code_{self.__class__.__name__}.py"
+
+ # Add the snippet to the code snippet editor:
+ from microplugin.microplugin_window import \
+ MicroPluginMainWindow
+ MicroPluginMainWindow.add_snippet(filename=filename,
+ code=code)
+
# Get captured stdout:
captured_output = f.getvalue()
diff --git a/src/napari_chatgpt/utils/ollama/ollama.py b/src/napari_chatgpt/utils/ollama/ollama.py
index 29f2956..a396be4 100644
--- a/src/napari_chatgpt/utils/ollama/ollama.py
+++ b/src/napari_chatgpt/utils/ollama/ollama.py
@@ -5,7 +5,7 @@
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.schema import LLMResult
-from langchain_community.llms import Ollama
+from langchain_community.llms.ollama import Ollama
_aysync_ollama_thread_pool = ThreadPoolExecutor()
diff --git a/src/napari_chatgpt/utils/openai/default_model.py b/src/napari_chatgpt/utils/openai/default_model.py
index e3f683e..4d6d892 100644
--- a/src/napari_chatgpt/utils/openai/default_model.py
+++ b/src/napari_chatgpt/utils/openai/default_model.py
@@ -23,6 +23,10 @@ def model_key(model):
parts = model.split('-')
# Get the main version (e.g., '3.5' or '4' from 'gpt-3.5' or 'gpt-4')
main_version = parts[1]
+
+ if 'o' in main_version:
+ main_version = main_version.replace('o', '.25')
+
# Use the length of the model name as a secondary sorting criterion
length = len(model)
# Sort by main version (descending), then by length (ascending)
diff --git a/src/napari_chatgpt/utils/openai/test/gpt_vision_test.py b/src/napari_chatgpt/utils/openai/test/gpt_vision_test.py
index 245fb0d..f46003f 100644
--- a/src/napari_chatgpt/utils/openai/test/gpt_vision_test.py
+++ b/src/napari_chatgpt/utils/openai/test/gpt_vision_test.py
@@ -29,7 +29,7 @@ def test_gpt_vision():
print(description_2)
- assert 'futuristic' in description_2 and ('sunset' in description_2 or 'sunrise' in description_2 or 'landscape' in description_2)
+ assert ('futuristic' in description_2 or 'science fiction' in description_2 or 'robots' in description_2) and ('sunset' in description_2 or 'sunrise' in description_2 or 'landscape' in description_2)
def _get_image_path(image_name: str):
diff --git a/src/napari_chatgpt/utils/python/conda_utils.py b/src/napari_chatgpt/utils/python/conda_utils.py
index 995efd3..9f0b516 100644
--- a/src/napari_chatgpt/utils/python/conda_utils.py
+++ b/src/napari_chatgpt/utils/python/conda_utils.py
@@ -7,6 +7,10 @@
def conda_install(list_of_packages: List[str], channel:str = None) -> bool:
+
+ # Ensure it is a list and remove duplicates:
+ list_of_packages = list(set(list_of_packages))
+
base_command = "conda install -y"
if channel:
diff --git a/src/napari_chatgpt/utils/python/missing_packages.py b/src/napari_chatgpt/utils/python/missing_packages.py
index c0fef24..c5f25f6 100644
--- a/src/napari_chatgpt/utils/python/missing_packages.py
+++ b/src/napari_chatgpt/utils/python/missing_packages.py
@@ -89,6 +89,9 @@ def required_packages(code: str,
# Parse the list:
list_of_packages = list_of_packages_str.split()
+ # Remove duplicates:
+ list_of_packages = list(set(list_of_packages))
+
# Strip each package name of white spaces:
list_of_packages = [p.strip() for p in list_of_packages]
diff --git a/src/napari_chatgpt/utils/python/pip_utils.py b/src/napari_chatgpt/utils/python/pip_utils.py
index 450f5ad..6921c0c 100644
--- a/src/napari_chatgpt/utils/python/pip_utils.py
+++ b/src/napari_chatgpt/utils/python/pip_utils.py
@@ -34,8 +34,8 @@ def pip_install(packages: List[str],
aprint(f'Packages left: {packages}')
message += f"Removing 'included' packages that should be already installed with Omega: {', '.join(included_packages)}\n"
- # Ensure it is a list:
- packages = list(packages)
+ # Ensure it is a list and remove duplicates:
+ packages = list(set(packages))
if special_rules:
all_packages_str = ', '.join(packages)
@@ -163,6 +163,9 @@ def pip_uninstall(list_of_packages: List[str]) -> bool:
error_occurred = False
+ # Ensure it is a list and remove duplicates:
+ list_of_packages = list(set(list_of_packages))
+
with asection(f"Installing up to {len(list_of_packages)} packages with pip:"):
for package in list_of_packages:
diff --git a/src/napari_chatgpt/utils/python/test/add_comments_test.py b/src/napari_chatgpt/utils/python/test/add_comments_test.py
index bbc1def..8fa462e 100644
--- a/src/napari_chatgpt/utils/python/test/add_comments_test.py
+++ b/src/napari_chatgpt/utils/python/test/add_comments_test.py
@@ -35,5 +35,8 @@ def test_add_comments():
assert len(commented_code) >= len(___generated_python_code)
# Count the number of comments:
- assert commented_code.count('#') >= 4
+ assert commented_code.count('#') >= 2
+
+ # Count the number of docstrings:
+ assert commented_code.count('"""') >= 2
diff --git a/src/napari_chatgpt/utils/python/test/modify_code_test.py b/src/napari_chatgpt/utils/python/test/modify_code_test.py
index ca5b5c1..c60de62 100644
--- a/src/napari_chatgpt/utils/python/test/modify_code_test.py
+++ b/src/napari_chatgpt/utils/python/test/modify_code_test.py
@@ -25,7 +25,7 @@ def test_modify_code():
assert len(modified_code) >= len(___generated_python_code)
- assert 'multichannel' in modified_code
+ assert 'multichannel' in modified_code or 'multi-channel' in modified_code or 'channel' in modified_code
diff --git a/src/napari_chatgpt/utils/web/test/duckduckgo_test.py b/src/napari_chatgpt/utils/web/test/duckduckgo_test.py
index bcbaa07..bbf7d0d 100644
--- a/src/napari_chatgpt/utils/web/test/duckduckgo_test.py
+++ b/src/napari_chatgpt/utils/web/test/duckduckgo_test.py
@@ -12,6 +12,7 @@ def test_duckduckgo_search_overview_summary():
text = summary_ddg(query, do_summarize=True)
aprint(text)
assert 'Mickey' in text
+ assert 'Web search failed' not in text
def test_duckduckgo_search_overview():
@@ -19,3 +20,4 @@ def test_duckduckgo_search_overview():
text = summary_ddg(query, do_summarize=False)
aprint(text)
assert 'Mickey' in text
+ assert 'Web search failed' not in text
diff --git a/src/napari_chatgpt/utils/web/test/metasearch_test.py b/src/napari_chatgpt/utils/web/test/metasearch_test.py
index 5e08af9..5fb3799 100644
--- a/src/napari_chatgpt/utils/web/test/metasearch_test.py
+++ b/src/napari_chatgpt/utils/web/test/metasearch_test.py
@@ -12,6 +12,7 @@ def test_metasearch_summary():
text = metasearch(query, do_summarize=True)
aprint(text)
assert 'Mickey' in text
+ assert 'Web search failed' not in text
def test_metasearch():
@@ -19,3 +20,4 @@ def test_metasearch():
text = metasearch(query, do_summarize=False)
aprint(text)
assert 'Mickey' in text
+ assert 'Web search failed' not in text
diff --git a/src/napari_chatgpt/utils/web/wikipedia.py b/src/napari_chatgpt/utils/web/wikipedia.py
index 87d4155..f8c0407 100644
--- a/src/napari_chatgpt/utils/web/wikipedia.py
+++ b/src/napari_chatgpt/utils/web/wikipedia.py
@@ -7,12 +7,14 @@
def search_wikipedia(query: str,
num_results: int = 3,
+ lang: str = "en",
max_text_length: int = 4000,
do_summarize: bool = False,
llm: BaseLLM = None) -> str:
# Run a google search specifically on wikipedia:
results = search_ddg(query=f"{query} site:wikipedia.org",
- num_results=max(10, num_results))
+ num_results=min(10, num_results),
+ lang=lang)
# keep the top k results:
results = results[0: num_results]