Batch Normalization protocol does not match code implementation. #22
Comments
|
@llCurious I've added responses in order for your questions below:
|
|
Thank you for you responses. BTW, you seem to miss my question about the BN protocol. You mention that |
|
Yes, that is correct. Either all the exponents have to be the same or the protocol doesn't really guarantee any correctness. About your BN question, like I said, end-to-end training in MPC was not studied (still many open challenges for that) so it is hard to make a comment empirically on the use of BN for training. However, the use of BN is known from ML literature (plaintext) and the idea is that the benefits of BN (improving convergence/stability) will translate into secure computation too. Does this answer your question? If you're asking if BN will help train a network in the current code base then I'll say no, though it is an issue, it is not the only issue that is preventing training. |
|
OK,i got it. Sry for the late reply~
Really thanks for your patient answers!!!! |
|
Hey, snwagh.
I have been reading your paper of Falcon and found this repo. And I am interested in how you perform the computation of Batch Normalization.
I have the following two questions:
the implementation of BN seems to be just a single division
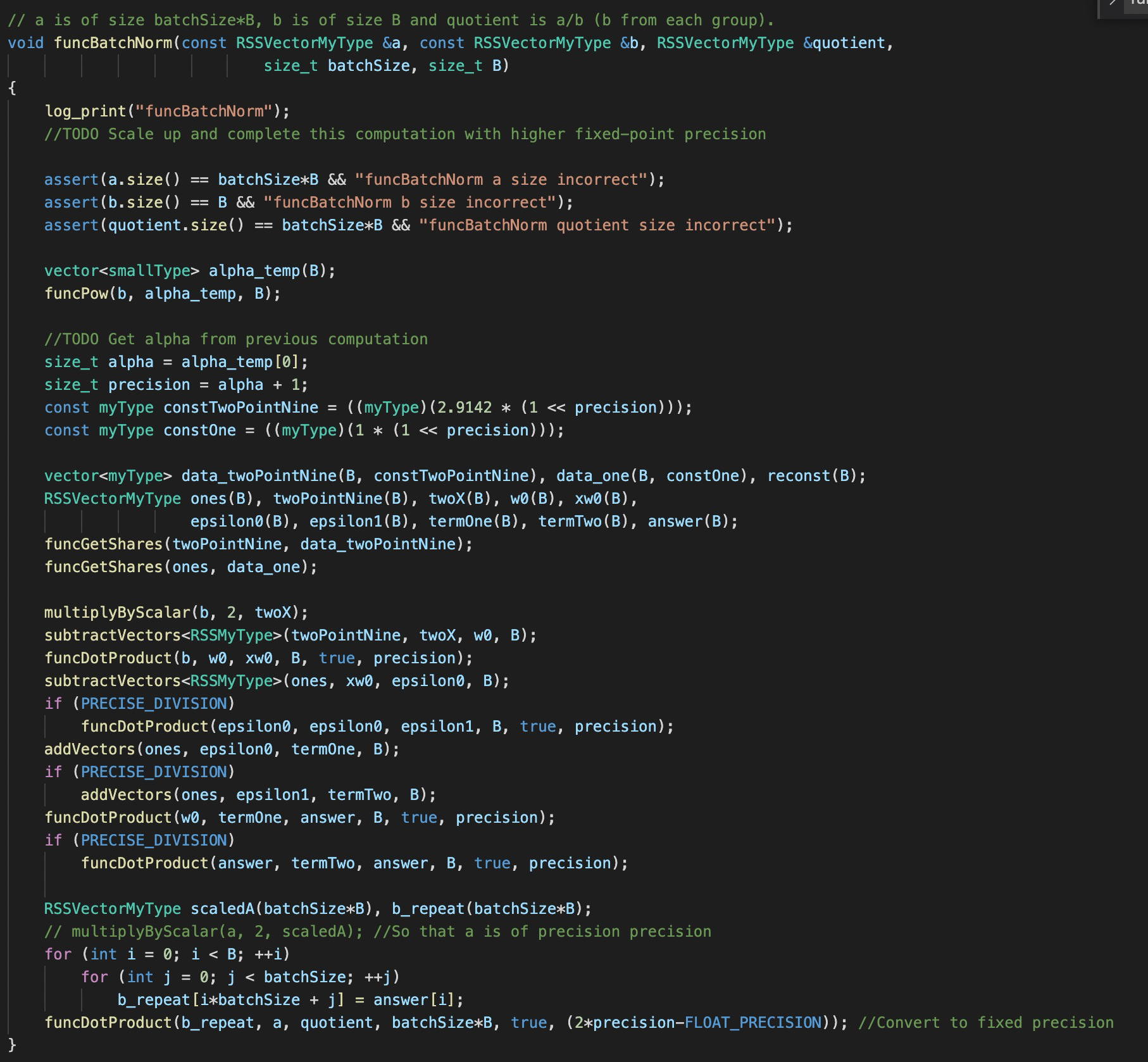
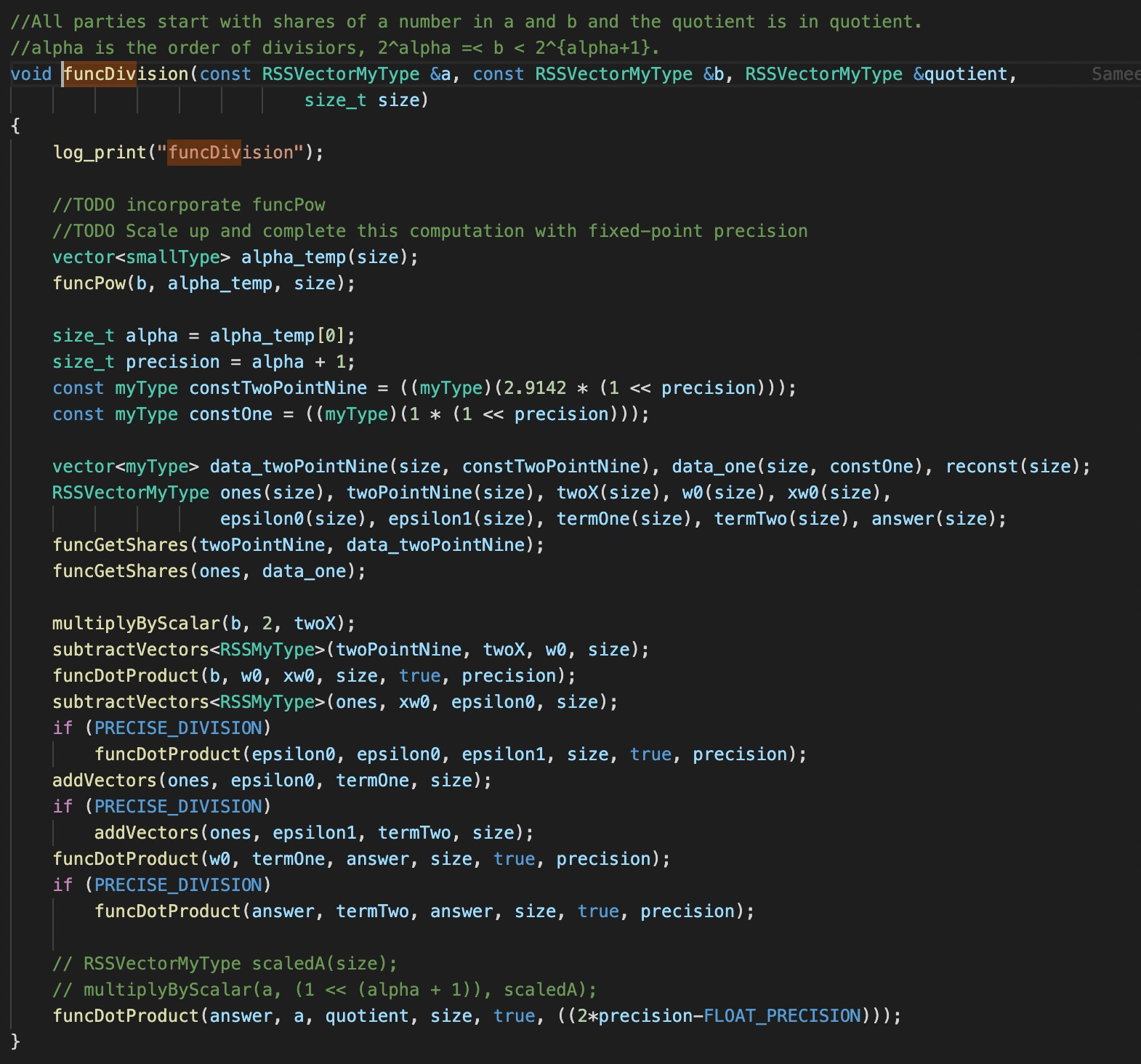
the protocol of
Powseems to reveal the information of the exponent, i.e., \alphathe BIT_SIZE in your paper is 32, which seems to be too small. How you guarantee the accuracy or say precision? IS the BN actually essential to your ML training and inference?
The text was updated successfully, but these errors were encountered: