diff --git a/.github/workflows/release.yml b/.github/workflows/release.yml
index 46e80c986f..13f2f44a30 100644
--- a/.github/workflows/release.yml
+++ b/.github/workflows/release.yml
@@ -33,6 +33,9 @@ jobs:
run: |
PYTHONPATH="$PYTHONPATH:." python scripts/mapping_accuracy_estimate.py
PYTHONPATH="$PYTHONPATH:." python scripts/accuracy_version_plot.py -v ${{ github.ref }}
+ - name: Update Readme
+ run: |
+ PYTHONPATH="$PYTHONPATH:." python scripts/stats-dashboard/generate-markdown.py -v ${{ github.ref }}
- name: Build and publish module
env: # authentication
PYPI_TOKEN: ${{ secrets.PYPI_TOKEN }}
@@ -49,6 +52,10 @@ jobs:
git add input/accuracy/difference.csv
git add input/accuracy/version_plot.png
git commit -m "docs: generate a new accuracy plot"
+ git add README.md
+ git add scripts/stats-dashboard/descr_stats_version.csv
+ git add scripts/stats-dashboard/
+ git commit -m "docs: update README"
git add dist
git add pyproject.toml
git commit -m "chore: build module"
diff --git a/README.md b/README.md
index 2ee9a69abb..30510adfe9 100644
--- a/README.md
+++ b/README.md
@@ -1,37 +1,113 @@
-[](https://github.com/welfare-state-analytics/riksdagen-corpus/actions/workflows/check_unchanged.yml)
[](https://github.com/welfare-state-analytics/riksdagen-corpus/actions/workflows/push.yml)
[](https://github.com/welfare-state-analytics/riksdagen-corpus/actions/workflows/validate.yml)
-# Swedish parliamentary proceedings - Riksdagens protokoll 1867-today
-_Westac Project, 2020-2023_
+# Swedish parliamentary proceedings --- 1867--today --- v0.10.0
+
+_Westac Project_, 2020--2024 |
+_Swerik Project_, 2023--2025
+
+
+## The data set
The full data set consists of multiple parts:
-- Riksdagens protokoll between from 1867 until today in the [Parla-clarin](https://github.com/clarin-eric/parla-clarin) format
-- Comprehensive list of MPs and cabinet members during this period
-- [Documentation](https://github.com/welfare-state-analytics/riksdagen-corpus/wiki/) of the corpus and the curation process
+- Parliamentary records (riksdagens protokoll) from 1867 until today in the [Parla-clarin](https://github.com/clarin-eric/parla-clarin) format
+- Comprehensive list of members of parliament, ministers and governments during this period + associated metadata (mandate periods, party info, etc)
+- [In progress] An annotated catalog of motions submitted to the parliament with linked metadata
+- [Documentation](https://github.com/welfare-state-analytics/riksdagen-corpus/tree/main/docs/) of the corpus and the curation process
- [A Google Colab notebook](https://colab.research.google.com/drive/1C3e2gwi9z83ikXbYXNPfB6RF7spTgzxA?usp=sharing) that demonstrates how the dataset can be used with Python
## Basic use
A full dataset is available under [this download link](https://github.com/welfare-state-analytics/riksdagen-corpus/releases/latest/download/corpus.zip). It has the following structure
-- Annual protocol files in the ```corpus/protocols/``` folder
-- Structured metadata on MPs, speakers, ministers, and governments in the ```corpus/metadata/``` folder
+- Annual Parliamentary record (protocol) files in the ```corpus/protocols/``` directory
+- Structured metadata on members of parliament, ministers, and governments in the ```corpus/metadata/``` directory
The workflow to use the data is demonstrated in [this Google Colab notebook](https://colab.research.google.com/drive/1C3e2gwi9z83ikXbYXNPfB6RF7spTgzxA?usp=sharing).
## Design choices of the project
-The Riksdagen corpus is released as an iterative process, where the corpus is curated and expanded. Semantic versioning is used for the whole corpus, following the established major-minor-patch practices as they apply to data. For each major and minor release, a statistical sample is drawn, annotated and quantitatively evaluated. Errors are fixed as they are detected in order of priority. Moreover, the edit history is kept as a traceable git repository.
+The Riksdagen corpus is released as an iterative process, where the corpus is continuously curated and expanded. Semantic versioning is used for the whole corpus, following the established major-minor-patch practices as they apply to data. For each major and minor release, a battery of unit tests are run and a statistical sample is drawn, annotated and quantitatively evaluated to ensure integrety and quality of updated data. Errors are fixed as they are detected in order of priority. Moreover, the edit history is kept as a traceable git repository.
+
+While the contents of the corpus will change due to curation and expansion, we aim to keep the deliverable API, the `corpus/` folder, as stable as possible. This means we avoid relocating files or folders, changing formats, changing columns in metadata files, or any other changes that might break downstream scripts. Conversely, files outside the `corpus/` folder are internal to the project. End users may find utility in them but we make no effort to keep them consistent.
+
+The data in the corpus is delivered as TEI XML files to follow established practices. The metadata is delivered as CSV files, following a [normal form](https://en.wikipedia.org/wiki/Database_normalization) database structure while allowing for a legible git history. A more detailed description of the data and metadata structure and formats can be found in the README files in the `corpus/` folder.
+
+## Descriptive statistics at a glance
+
+Currently, we have an extensive set of Parliamentary Records (Riksdagens Protokoll) from 1867 until now. We are in the process of preparing Motions for inclusion in the corpus and other document types will follow.
+
+| | v0.10.0 |
+|--------------------------------------|------------|
+| Corpus size (GB) | 5.58 |
+| Number of parliamentary records | 17642 |
+| Total parliamentary record pages* | 1041807 |
+| Total parliamentary record speeches | 1127027 |
+| Total parliamentary record words | 441525242 |
+| Number of Motions | 0 |
+| Total motion pages | 0 |
+| Total motion words | 0 |
+| Number of people with MP role | 5975 |
+| Number of people with minister role | 535 |
+
+\* Digital original parliamentary records for some years in the 1990s are not paginated and thus do not contribute to the page count.See also §_Number of Pages in Parliamentary Records_.
+
+### Parliamentary Records over time
+
+#### Number of Parliamentary Records
+
+
+
+#### Number of Pages in Parliamentary Records
+
+
+
+#### Number of Speeches in Parliamentary Records
+
+
+
+Note: We are aware of an issue whereby speeches are over counted in the data's current form in the years after 2014 -- we're working on a fix. Until then, the following static graph is a better representation of the actual speeches in the Parliamentary Records for those years.
+
+
+
+#### Number of Words in Parliamentary Records
+
+
+
+### Members of Parliament over time
+
+
+
+## Quality assessment
+
+### Speech-to-speaker mapping
+
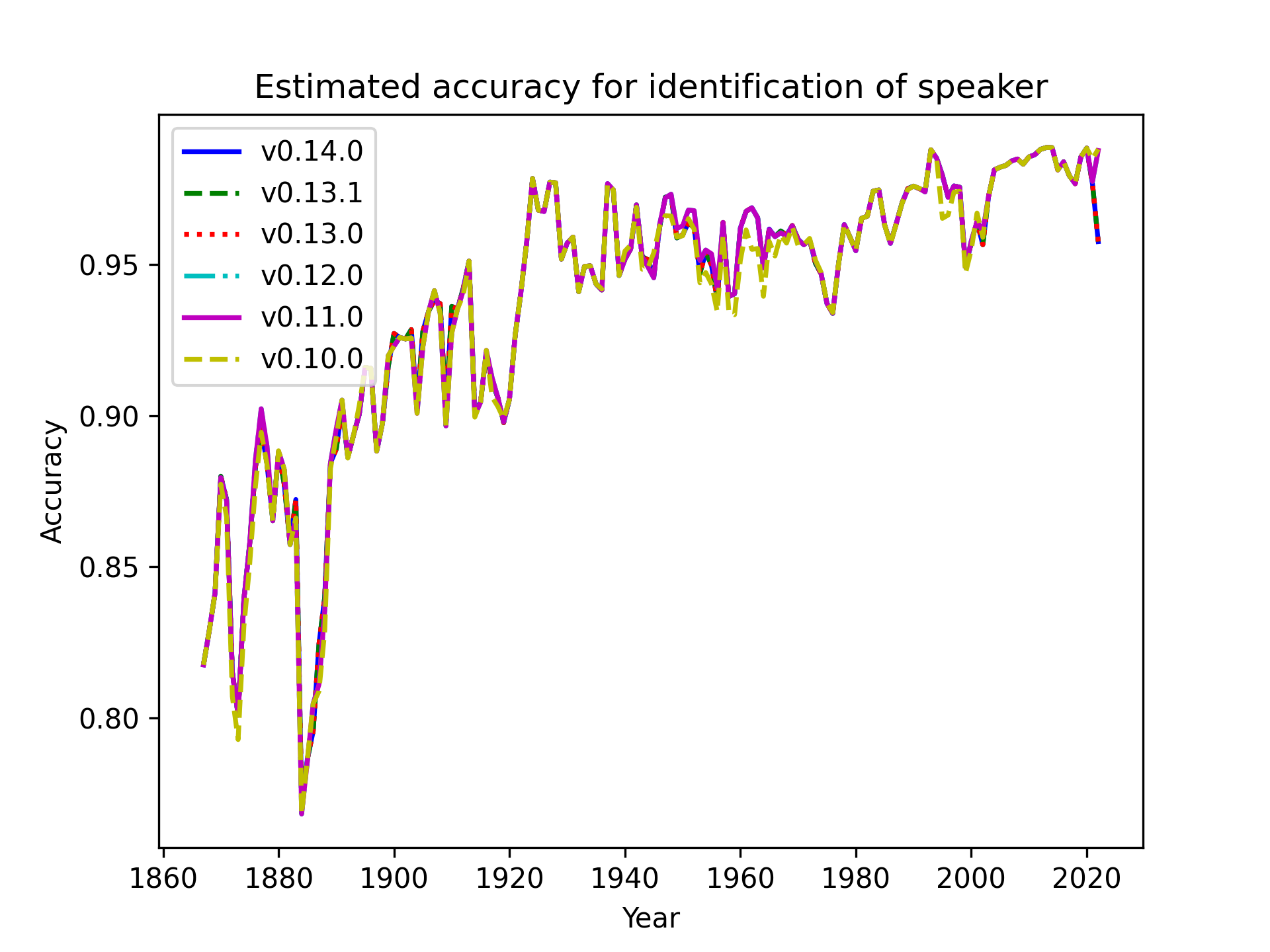
+We check how many speakers in the parliamentary records our algorithms idenify in each release.
-While the contents of the corpus will change due to curation and expansion, we aim to keep the deliverable API, the corpus/ folder, as stable as possible. This means we avoid relocating files or folders, changing formats, changing columns in metadata files, or any other changes that might break downstream scripts. Conversely, files outside the corpus/ folder are internal to the project. End users may find utility in them but we make no effort to keep them consistent.
+### Correct number of MPs over time
+
+
+
+
-The data in the corpus is delivered as TEI XML files to follow established practices. The metadata is delivered as CSV files, following a normal form database structure while allowing for a legible git history. A more detailed description of the data and metadata structure and formats can be found in the README files in the corpus/ folder.
## Participate in the curation process
If you find any errors, it is possible to submit corrections to them. This is documented in the [project wiki](https://github.com/welfare-state-analytics/riksdagen-corpus/wiki/Submit-corrections).
+
+
+## Acknowledgement of support
+
+- Westac funding: Vetenskapsrådet 2018-0606
+
+- Swerik funding: Riksbankens Jubileumsfond IN22-0003
+
+ +
+ +
+---
+Last update: 2023-11-21, 12:27:58
diff --git a/corpus/quality_assessment/baseline_mp_frequencies_per_year/number_mp_in_parliament.csv b/corpus/quality_assessment/baseline_mp_frequencies_per_year/number_mp_in_parliament.csv
index 5a7cdf0c69..e0e0ccff53 100644
--- a/corpus/quality_assessment/baseline_mp_frequencies_per_year/number_mp_in_parliament.csv
+++ b/corpus/quality_assessment/baseline_mp_frequencies_per_year/number_mp_in_parliament.csv
@@ -2,7 +2,7 @@ year,chamber,protocol_spec,n_mps,source
1867,ak,,190,stjernquist1996:107
1867,fk,,125,stjernquist1996:107
1868,ak,,191,stjernquist1996:107
-1868,fk,,,
+1868,fk,,125,inferred
1869,ak,,191,stjernquist1996:107
1869,fk,,127,stjernquist1996:107
1870,ak,,191,stjernquist1996:107
@@ -63,229 +63,229 @@ year,chamber,protocol_spec,n_mps,source
1894,fk,,148,stjernquist1996:107
1895,ak,,230,stjernquist1996:107
1895,fk,,150,stjernquist1996:107
-1896,ak,,,
-1896,fk,,,
-1897,ak,,,
-1897,fk,,,
-1898,ak,,,
-1898,fk,,,
-1899,ak,,,
-1899,fk,,,
+1896,ak,,230,inferred
+1896,fk,,150,inferred
+1897,ak,,230,inferred
+1897,fk,,150,inferred
+1898,ak,,230,inferred
+1898,fk,,150,inferred
+1899,ak,,230,inferred
+1899,fk,,150,inferred
1900,ak,,230,stjernquist1996:122
1900,fk,,150,stjernquist1996:122
-1901,ak,,,
-1901,fk,,,
-1902,ak,,,
-1902,fk,,,
+1901,ak,,230,inferred
+1901,fk,,150,inferred
+1902,ak,,230,inferred
+1902,fk,,150,inferred
1903,ak,,230,stjernquist1996:122
1903,fk,,150,stjernquist1996:122
-1904,ak,,,
-1904,fk,,,
-1905,ak,,,
-1905,fk,,,
-1905,ak,urtima,,
-1905,fk,urtima,,
-1905,ak,urtima2,,
-1905,fk,urtima2,,
+1904,ak,,230,inferred
+1904,fk,,150,inferred
+1905,ak,,230,inferred
+1905,fk,,150,inferred
+1905,ak,urtima,230,inferred
+1905,fk,urtima,150,inferred
+1905,ak,urtima2,230,inferred
+1905,fk,urtima2,150,inferred
1906,ak,,230,stjernquist1996:122
1906,fk,,150,stjernquist1996:122
-1907,ak,,,
-1907,fk,,,
-1908,ak,,,
-1908,fk,,,
-1909,,,,
+1907,ak,,230,inferred
+1907,fk,,150,inferred
+1908,ak,,230,inferred
+1908,fk,,150,inferred
+1909,,,230,inferred
1909,ak,,230,stjernquist1996:122
1909,fk,,150,stjernquist1996:122
-1910,ak,,,
-1910,fk,,,
-1911,ak,,,
-1911,fk,,,
+1910,ak,,230,inferred
+1910,fk,,150,inferred
+1911,ak,,230,inferred
+1911,fk,,150,inferred
1912,ak,,230,stjernquist1996:123
1912,fk,,150,stjernquist1996:123
-1913,ak,,,
-1913,fk,,,
-1914,ak,a,,
-1914,fk,a,,
+1913,ak,,230,inferred
+1913,fk,,150,inferred
+1914,ak,a,230,inferred
+1914,fk,a,150,inferred
1914,ak,b,230,stjernquist1996:123
1914,fk,b,150,stjernquist1996:123
1915,ak,,230,stjernquist1996:123
1915,fk,,150,stjernquist1996:123
-1916,ak,,,
-1916,fk,,,
-1917,ak,,,
-1917,fk,,,
+1916,ak,,230,inferred
+1916,fk,,150,inferred
+1917,ak,,230,inferred
+1917,fk,,150,inferred
1918,ak,,230,stjernquist1996:123
1918,fk,,150,stjernquist1996:123
-1918,ak,urtima,,
-1918,fk,urtima,,
-1919,ak,,,
-1919,fk,,,
-1919,ak,urtima,,
-1919,fk,urtima,,
-1920,ak,,,
-1920,fk,,,
+1918,ak,urtima,230,inferred
+1918,fk,urtima,150,inferred
+1919,ak,,230,inferred
+1919,fk,,150,inferred
+1919,ak,urtima,230,inferred
+1919,fk,urtima,150,inferred
+1920,ak,,230,inferred
+1920,fk,,150,inferred
1921,ak,,230,stjernquist1996:123
1921,fk,,150,stjernquist1996:123
1922,ak,,230,stjernquist1996:123
1922,fk,,150,stjernquist1996:123
-1923,ak,,,
-1923,fk,,,
-1924,ak,,,
-1924,fk,,,
+1923,ak,,230,inferred
+1923,fk,,150,inferred
+1924,ak,,230,inferred
+1924,fk,,150,inferred
1925,ak,,230,stjernquist1996:123
1925,fk,,150,stjernquist1996:123
-1926,ak,,,
-1926,fk,,,
-1927,ak,,,
-1927,fk,,,
-1928,ak,,,
-1928,fk,,,
+1926,ak,,230,inferred
+1926,fk,,150,inferred
+1927,ak,,230,inferred
+1927,fk,,150,inferred
+1928,ak,,230,inferred
+1928,fk,,150,inferred
1929,ak,,230,stjernquist1996:123
1929,fk,,150,stjernquist1996:123
-1930,ak,,,
-1930,fk,,,
-1931,ak,,,
-1931,fk,,,
-1932,ak,,,
-1932,fk,,,
+1930,ak,,230,inferred
+1930,fk,,150,inferred
+1931,ak,,230,inferred
+1931,fk,,150,inferred
+1932,ak,,230,inferred
+1932,fk,,150,inferred
1933,ak,,230,stjernquist1996:123
1933,fk,,150,stjernquist1996:123
-1934,ak,,,
-1934,fk,,,
-1935,ak,,,
-1935,fk,,,
-1936,ak,,,
-1936,fk,,,
+1934,ak,,230,inferred
+1934,fk,,150,inferred
+1935,ak,,230,inferred
+1935,fk,,150,inferred
+1936,ak,,230,inferred
+1936,fk,,150,inferred
1937,ak,,230,stjernquist1996:123
1937,fk,,150,stjernquist1996:123
-1938,ak,,,
-1938,fk,,,
-1939,ak,,,
-1939,fk,,,
-1939,ak,urtima,,
-1939,fk,urtima,,
-1940,ak,,,
-1940,fk,,,
-1940,ak,urtima,,
-1940,fk,urtima,,
+1938,ak,,230,inferred
+1938,fk,,150,inferred
+1939,ak,,230,inferred
+1939,fk,,150,inferred
+1939,ak,urtima,230,inferred
+1939,fk,urtima,150,inferred
+1940,ak,,230,inferred
+1940,fk,,150,inferred
+1940,ak,urtima,230,inferred
+1940,fk,urtima,150,inferred
1941,ak,,230,stjernquist1996:123
1941,fk,,150,stjernquist1996:123
-1941,ak,höst,,
-1941,fk,höst,,
-1942,ak,,,
-1942,fk,,,
-1942,ak,höst,,
-1942,fk,höst,,
-1943,ak,,,
-1943,fk,,,
-1943,ak,höst,,
-1943,fk,höst,,
-1944,ak,,,
-1944,fk,,,
-1944,ak,höst,,
-1944,fk,höst,,
+1941,ak,höst,230,inferred
+1941,fk,höst,150,inferred
+1942,ak,,230,inferred
+1942,fk,,150,inferred
+1942,ak,höst,230,inferred
+1942,fk,höst,150,inferred
+1943,ak,,230,inferred
+1943,fk,,150,inferred
+1943,ak,höst,230,inferred
+1943,fk,höst,150,inferred
+1944,ak,,230,inferred
+1944,fk,,150,inferred
+1944,ak,höst,230,inferred
+1944,fk,höst,150,inferred
1945,ak,,230,stjernquist1996:123
1945,fk,,150,stjernquist1996:123
-1945,ak,höst,,
-1945,fk,höst,,
-1946,ak,,,
-1946,fk,,,
-1946,ak,höst,,
-1946,fk,höst,,
-1947,ak,,,
-1947,fk,,,
-1948,ak,,,
-1948,fk,,,
-1948,ak,höst,,
-1948,fk,höst,,
+1945,ak,höst,230,inferred
+1945,fk,höst,150,inferred
+1946,ak,,230,inferred
+1946,fk,,150,inferred
+1946,ak,höst,230,inferred
+1946,fk,höst,150,inferred
+1947,ak,,230,inferred
+1947,fk,,150,inferred
+1948,ak,,230,inferred
+1948,fk,,150,inferred
+1948,ak,höst,230,inferred
+1948,fk,höst,150,inferred
1949,ak,,230,stjernquist1996:123
1949,fk,,150,stjernquist1996:123
-1949,ak,höst,,
-1949,fk,höst,,
-1950,ak,,,
-1950,fk,,,
-1950,ak,höst,,
-1950,fk,höst,,
-1951,ak,,,
-1951,fk,,,
-1951,ak,extrahöst,,
-1951,fk,extrahöst,,
-1952,ak,,,
-1952,fk,,,
-1952,ak,höst,,
-1952,fk,höst,,
+1949,ak,höst,230,inferred
+1949,fk,höst,150,inferred
+1950,ak,,230,inferred
+1950,fk,,150,inferred
+1950,ak,höst,230,inferred
+1950,fk,höst,150,inferred
+1951,ak,,230,inferred
+1951,fk,,150,inferred
+1951,ak,extrahöst,230,inferred
+1951,fk,extrahöst,150,inferred
+1952,ak,,230,inferred
+1952,fk,,150,inferred
+1952,ak,höst,230,inferred
+1952,fk,höst,150,inferred
1953,ak,,230,stjernquist1996:123
1953,fk,,150,stjernquist1996:123
-1953,ak,höst,,
-1953,fk,höst,,
-1954,ak,,,
-1954,fk,,,
-1954,ak,höst,,
-1954,fk,höst,,
-1955,ak,,,
-1955,fk,,,
-1955,ak,höst,,
-1955,fk,höst,,
-1956,ak,,,
-1956,fk,,,
-1956,ak,höst,,
-1956,fk,höst,,
+1953,ak,höst,230,inferred
+1953,fk,höst,150,inferred
+1954,ak,,230,inferred
+1954,fk,,150,inferred
+1954,ak,höst,230,inferred
+1954,fk,höst,150,inferred
+1955,ak,,230,inferred
+1955,fk,,150,inferred
+1955,ak,höst,230,inferred
+1955,fk,höst,150,inferred
+1956,ak,,230,inferred
+1956,fk,,150,inferred
+1956,ak,höst,230,inferred
+1956,fk,höst,150,inferred
1957,ak,,231,stjernquist1996:123
1957,fk,,150,stjernquist1996:123
-1957,ak,höst,,
-1957,fk,höst,,
-1958,ak,a,,
-1958,fk,a,,
+1957,ak,höst,231,inferred
+1957,fk,höst,150,inferred
+1958,ak,a,231,inferred
+1958,fk,a,150,inferred
1958,ak,b,231,stjernquist1996:123
1958,fk,b,151,stjernquist1996:123
-1959,ak,,,
-1959,fk,,,
-1959,ak,höst,,
-1959,fk,höst,,
-1960,ak,,,
-1960,fk,,,
-1960,ak,höst,,
-1960,fk,höst,,
+1959,ak,,231,inferred
+1959,fk,,150,inferred
+1959,ak,höst,231,inferred
+1959,fk,höst,150,inferred
+1960,ak,,231,inferred
+1960,fk,,150,inferred
+1960,ak,höst,231,inferred
+1960,fk,höst,150,inferred
1961,ak,,232,stjernquist1996:123
1961,fk,,151,stjernquist1996:123
-1961,ak,höst,,
-1961,fk,höst,,
-1962,ak,,,
-1962,fk,,,
-1962,ak,höst,,
-1962,fk,höst,,
-1963,ak,,,
-1963,fk,,,
-1963,ak,höst,,
-1963,fk,höst,,
-1964,ak,,,
-1964,fk,,,
-1964,ak,höst,,
-1964,fk,höst,,
+1961,ak,höst,232,inferred
+1961,fk,höst,151,inferred
+1962,ak,,232,inferred
+1962,fk,,151,inferred
+1962,ak,höst,232,inferred
+1962,fk,höst,151,inferred
+1963,ak,,232,inferred
+1963,fk,,151,inferred
+1963,ak,höst,232,inferred
+1963,fk,höst,151,inferred
+1964,ak,,232,inferred
+1964,fk,,151,inferred
+1964,ak,höst,232,inferred
+1964,fk,höst,151,inferred
1965,ak,,233,stjernquist1996:123
1965,fk,,151,stjernquist1996:123
-1965,ak,höst,,
-1965,fk,höst,,
-1966,ak,,,
-1966,fk,,,
-1966,ak,höst,,
-1966,fk,höst,,
-1967,ak,,,
-1967,fk,,,
-1967,ak,höst,,
-1967,fk,höst,,
-1968,ak,,,
-1968,fk,,,
-1968,ak,höst,,
-1968,fk,höst,,
+1965,ak,höst,233,inferred
+1965,fk,höst,151,inferred
+1966,ak,,233,inferred
+1966,fk,,151,inferred
+1966,ak,höst,233,inferred
+1966,fk,höst,151,inferred
+1967,ak,,233,inferred
+1967,fk,,151,inferred
+1967,ak,höst,233,inferred
+1967,fk,höst,151,inferred
+1968,ak,,233,inferred
+1968,fk,,151,inferred
+1968,ak,höst,233,inferred
+1968,fk,höst,151,inferred
1969,ak,,233,stjernquist1996:123
1969,fk,,151,stjernquist1996:123
-1969,ak,höst,,
-1969,fk,höst,,
-1970,ak,,,
-1970,fk,,,
-1970,ak,höst,,
-1970,fk,höst,,
+1969,ak,höst,233,inferred
+1969,fk,höst,151,inferred
+1970,ak,,233,inferred
+1970,fk,,151,inferred
+1970,ak,höst,233,inferred
+1970,fk,höst,151,inferred
1971,ek,,350,stjernquist1992:276
1972,ek,,350,stjernquist1992:276
1973,ek,,350,stjernquist1992:276
diff --git a/scripts/stats-dashboard/descr_stats_version.csv b/scripts/stats-dashboard/descr_stats_version.csv
new file mode 100644
index 0000000000..fe01307b46
--- /dev/null
+++ b/scripts/stats-dashboard/descr_stats_version.csv
@@ -0,0 +1,2 @@
+version,corpus_size,N_prot,N_prot_pages,N_prot_speeches,N_prot_words,N_mot,N_mot_pages,N_mot_words,N_MP,N_MIN
+v0.10.0,5.58,17642,1041807,1127027,441525242,0,0,0,5975,535
diff --git a/scripts/stats-dashboard/figures/logos/rj.png b/scripts/stats-dashboard/figures/logos/rj.png
new file mode 100644
index 0000000000..15f13592e7
Binary files /dev/null and b/scripts/stats-dashboard/figures/logos/rj.png differ
diff --git a/scripts/stats-dashboard/figures/logos/vr.png b/scripts/stats-dashboard/figures/logos/vr.png
new file mode 100644
index 0000000000..7f5ed8adeb
Binary files /dev/null and b/scripts/stats-dashboard/figures/logos/vr.png differ
diff --git a/scripts/stats-dashboard/figures/mp-coverage/mp-coverage-ratio.png b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage-ratio.png
new file mode 100644
index 0000000000..692bb28369
Binary files /dev/null and b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage-ratio.png differ
diff --git a/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.csv b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.csv
new file mode 100644
index 0000000000..e177ca3625
--- /dev/null
+++ b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.csv
@@ -0,0 +1,157 @@
+year,v0.10.0
+1867,1.0092764542936283
+1868,1.002579222926426
+1869,0.9916618188869498
+1870,1.0184555365825738
+1871,1.0414319558412433
+1872,1.00839672033982
+1873,0.9991341817010309
+1874,1.0191204016675117
+1875,1.0033112013210403
+1876,0.9981960985563023
+1877,1.0043177523683504
+1878,1.018034446984295
+1879,1.0093485481624342
+1880,1.0154621848739496
+1881,1.0133998855016457
+1882,1.0009769225097693
+1883,1.0132178489287251
+1884,1.0070709146968138
+1885,1.0150900870052215
+1886,1.0222699048466737
+1887,1.1866438152130312
+1888,1.0130208333333333
+1889,1.0182457163385694
+1890,1.0175356758078695
+1891,1.0045830869308103
+1892,1.0829600219369284
+1893,1.0031014621178556
+1894,1.0045637743006166
+1895,0.9944082125603867
+1896,0.9952569169960477
+1897,1.0045217391304346
+1898,1.0068460245015611
+1899,1.0031999999999996
+1900,1.0021291448516578
+1901,1.0052759197324415
+1902,0.9977287475665152
+1903,1.011713554987212
+1904,1.0119267734553774
+1905,1.0556920013275801
+1906,1.0065144596651447
+1907,1.0165064102564103
+1908,1.0038830584707648
+1909,1.0144544708777687
+1910,1.0072514619883042
+1911,1.0047554347826089
+1912,1.0054901120868136
+1913,1.0184476650563608
+1914,1.1364444444444446
+1915,1.0142486651411131
+1916,1.0241841004184105
+1917,1.0040808269700279
+1918,1.0243478260869563
+1919,1.2704569479965901
+1920,1.0114333800841517
+1921,0.960986974866997
+1922,1.0034594391116132
+1923,0.9982665809952167
+1924,1.0096078431372546
+1925,1.0077272727272724
+1926,1.0034447600320442
+1927,1.0011879552451752
+1928,1.0120798239623645
+1929,1.010537084398977
+1930,1.0025928329367657
+1931,1.0081159420289854
+1932,1.0025008983111754
+1933,1.0086714975845406
+1934,1.0076461769115441
+1935,1.00551828847481
+1936,1.010185185185185
+1937,1.0120923913043478
+1938,1.0109281875915972
+1939,1.0255583972719522
+1940,1.0184829431438125
+1941,1.0074021882339461
+1942,1.0220653859116955
+1943,1.02516008155618
+1944,1.0098550724637676
+1945,1.00256543370106
+1946,1.0168
+1947,1.0080434782608696
+1948,1.0122918891431478
+1949,1.015755233494364
+1950,1.0146255557480224
+1951,1.004273504273504
+1952,1.002087215320911
+1953,1.0010832832431709
+1954,1.0172288295314225
+1955,1.0018834250996773
+1956,1.0028961748633878
+1957,1.012068808384598
+1958,1.0679751900760304
+1959,1.0047166821273963
+1960,1.005221238938053
+1961,0.99124299984706
+1962,1.0010798100872558
+1963,0.9831705847477343
+1964,1.0058243643079119
+1965,0.9907461423034897
+1966,0.9946100001808723
+1967,0.9855259393481964
+1968,0.9998874333725183
+1969,0.9901307230983496
+1970,0.993537565980958
+1971,1.0007892659826363
+1972,1.0045158488927486
+1973,1.002826254826255
+1974,0.988044733044733
+1975,1.005127445168939
+1976,1.005948673227856
+1977,1.0008808610163313
+1978,1.0079934085123652
+1979,1.009468045346954
+1980,1.0077001759858704
+1981,1.012532418457724
+1982,1.0076274264498166
+1983,1.006
+1984,1.01048351661953
+1985,1.0099535791594199
+1986,1.008907437398779
+1987,1.006929027401154
+1988,1.0037317914314638
+1989,1.0048836748301526
+1990,1.0060416250194353
+1991,1.0018049319766262
+1992,1.0005590886854427
+1993,0.9994040114613181
+1994,0.999365869697966
+1995,0.9993771022798057
+1996,0.9998314512051238
+1997,0.9999295410775518
+1998,0.9997441670077772
+1999,0.9999328438395416
+2000,0.9997518218532139
+2001,0.9997707736389685
+2002,1.001150829066654
+2003,1.0007484069623231
+2004,0.9997015281757403
+2005,0.9997035866021146
+2006,0.9992204618236978
+2007,0.9997982162314862
+2008,0.9998577495986507
+2009,0.9998245716624761
+2010,0.9994179799426934
+2011,0.9995292672943102
+2012,0.9996207652115288
+2013,0.9996364880468714
+2014,0.9994875020383441
+2015,0.9997795900374696
+2016,0.9995723388786725
+2017,0.9995964324629728
+2018,0.9993348342202211
+2019,0.9998451173236274
+2020,0.9997279750462442
+2021,1.2331611445175348
+2022,
diff --git a/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.png b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.png
new file mode 100644
index 0000000000..92833fd638
Binary files /dev/null and b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.png differ
diff --git a/scripts/stats-dashboard/figures/n-prot/n-prot.csv b/scripts/stats-dashboard/figures/n-prot/n-prot.csv
new file mode 100644
index 0000000000..c76e60116b
--- /dev/null
+++ b/scripts/stats-dashboard/figures/n-prot/n-prot.csv
@@ -0,0 +1,157 @@
+year,v0.10.0
+1867,149.0
+1868,130.0
+1869,123.0
+1870,129.0
+1871,160.0
+1872,123.0
+1873,148.0
+1874,152.0
+1875,103.0
+1876,95.0
+1877,107.0
+1878,112.0
+1879,103.0
+1880,104.0
+1881,85.0
+1882,113.0
+1883,118.0
+1884,94.0
+1885,109.0
+1886,103.0
+1887,86.0
+1888,94.0
+1889,94.0
+1890,85.0
+1891,88.0
+1892,102.0
+1893,79.0
+1894,92.0
+1895,81.0
+1896,79.0
+1897,78.0
+1898,77.0
+1899,69.0
+1900,96.0
+1901,81.0
+1902,93.0
+1903,129.0
+1904,126.0
+1905,136.0
+1906,120.0
+1907,126.0
+1908,139.0
+1909,122.0
+1910,103.0
+1911,93.0
+1912,97.0
+1913,97.0
+1914,277.0
+1915,183.0
+1916,202.0
+1917,148.0
+1918,176.0
+1919,149.0
+1920,153.0
+1921,110.0
+1922,93.0
+1923,91.0
+1924,87.0
+1925,88.0
+1926,88.0
+1927,84.0
+1928,84.0
+1929,82.0
+1930,94.0
+1931,92.0
+1932,112.0
+1933,101.0
+1934,95.0
+1935,86.0
+1936,98.0
+1937,88.0
+1938,87.0
+1939,142.0
+1940,128.0
+1941,102.0
+1942,60.0
+1943,72.0
+1944,70.0
+1945,84.0
+1946,86.0
+1947,74.0
+1948,80.0
+1949,64.0
+1950,68.0
+1951,69.0
+1952,64.0
+1953,64.0
+1954,66.0
+1955,64.0
+1956,66.0
+1957,60.0
+1958,66.0
+1959,64.0
+1960,59.0
+1961,72.0
+1962,73.0
+1963,74.0
+1964,84.0
+1965,84.0
+1966,78.0
+1967,106.0
+1968,90.0
+1969,86.0
+1970,92.0
+1971,152.0
+1972,148.0
+1973,161.0
+1974,146.0
+1975,200.0
+1976,88.0
+1977,127.0
+1978,176.0
+1979,172.0
+1980,174.0
+1981,178.0
+1982,167.0
+1983,170.0
+1984,169.0
+1985,167.0
+1986,139.0
+1987,140.0
+1988,133.0
+1989,142.0
+1990,129.0
+1991,127.0
+1992,123.0
+1993,125.0
+1994,122.0
+1995,115.0
+1996,119.0
+1997,122.0
+1998,112.0
+1999,128.0
+2000,127.0
+2001,125.0
+2002,122.0
+2003,134.0
+2004,144.0
+2005,145.0
+2006,136.0
+2007,142.0
+2008,141.0
+2009,147.0
+2010,128.0
+2011,140.0
+2012,136.0
+2013,134.0
+2014,123.0
+2015,130.0
+2016,134.0
+2017,142.0
+2018,112.0
+2019,148.0
+2020,158.0
+2021,142.0
+2022,
diff --git a/scripts/stats-dashboard/figures/n-prot/n-prot.png b/scripts/stats-dashboard/figures/n-prot/n-prot.png
new file mode 100644
index 0000000000..5767691682
Binary files /dev/null and b/scripts/stats-dashboard/figures/n-prot/n-prot.png differ
diff --git a/scripts/stats-dashboard/figures/prot-pages/prot-pages.csv b/scripts/stats-dashboard/figures/prot-pages/prot-pages.csv
new file mode 100644
index 0000000000..9a4e0952ce
--- /dev/null
+++ b/scripts/stats-dashboard/figures/prot-pages/prot-pages.csv
@@ -0,0 +1,157 @@
+year,v0.10.0
+1867,4660.0
+1868,4591.0
+1869,4525.0
+1870,4157.0
+1871,5194.0
+1872,4353.0
+1873,5100.0
+1874,4283.0
+1875,4655.0
+1876,4343.0
+1877,4494.0
+1878,4551.0
+1879,3827.0
+1880,3812.0
+1881,2867.0
+1882,4048.0
+1883,3778.0
+1884,2894.0
+1885,3816.0
+1886,3840.0
+1887,3101.0
+1888,3770.0
+1889,4094.0
+1890,3563.0
+1891,3484.0
+1892,4279.0
+1893,3211.0
+1894,3901.0
+1895,3562.0
+1896,3786.0
+1897,3773.0
+1898,3829.0
+1899,3067.0
+1900,3447.0
+1901,3438.0
+1902,3881.0
+1903,4130.0
+1904,4604.0
+1905,4624.0
+1906,4524.0
+1907,5192.0
+1908,5674.0
+1909,5892.0
+1910,6088.0
+1911,6163.0
+1912,6307.0
+1913,6562.0
+1914,5789.0
+1915,5094.0
+1916,5117.0
+1917,6925.0
+1918,8148.0
+1919,7803.0
+1920,8071.0
+1921,8722.0
+1922,6818.0
+1923,5843.0
+1924,5029.0
+1925,4918.0
+1926,5683.0
+1927,5593.0
+1928,5847.0
+1929,5847.0
+1930,6349.0
+1931,5543.0
+1932,7295.0
+1933,5842.0
+1934,5742.0
+1935,4641.0
+1936,5757.0
+1937,4793.0
+1938,4492.0
+1939,5555.0
+1940,4632.0
+1941,4401.0
+1942,5003.0
+1943,5161.0
+1944,4906.0
+1945,6669.0
+1946,6384.0
+1947,5023.0
+1948,6723.0
+1949,5417.0
+1950,5831.0
+1951,6306.0
+1952,5886.0
+1953,5643.0
+1954,6259.0
+1955,5976.0
+1956,6553.0
+1957,5880.0
+1958,6504.0
+1959,6661.0
+1960,6761.0
+1961,6268.0
+1962,7028.0
+1963,7231.0
+1964,8230.0
+1965,7912.0
+1966,8285.0
+1967,9909.0
+1968,9042.0
+1969,9304.0
+1970,9882.0
+1971,9790.0
+1972,10703.0
+1973,10732.0
+1974,9502.0
+1975,14658.0
+1976,5050.0
+1977,8963.0
+1978,12278.0
+1979,11316.0
+1980,10097.0
+1981,11092.0
+1982,10165.0
+1983,10743.0
+1984,10767.0
+1985,9558.0
+1986,9867.0
+1987,10343.0
+1988,10049.0
+1989,10905.0
+1990,0.0
+1991,0.0
+1992,0.0
+1993,0.0
+1994,8491.0
+1995,7778.0
+1996,9495.0
+1997,9845.0
+1998,7975.0
+1999,9779.0
+2000,10389.0
+2001,10524.0
+2002,9275.0
+2003,10047.0
+2004,11747.0
+2005,10858.0
+2006,10730.0
+2007,12489.0
+2008,11254.0
+2009,10338.0
+2010,9249.0
+2011,9711.0
+2012,10337.0
+2013,11567.0
+2014,10435.0
+2015,10784.0
+2016,10041.0
+2017,10539.0
+2018,7384.0
+2019,8538.0
+2020,12981.0
+2021,7989.0
+2022,
diff --git a/scripts/stats-dashboard/figures/prot-pages/prot-pages.png b/scripts/stats-dashboard/figures/prot-pages/prot-pages.png
new file mode 100644
index 0000000000..bf06efbcb8
Binary files /dev/null and b/scripts/stats-dashboard/figures/prot-pages/prot-pages.png differ
diff --git a/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.csv b/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.csv
new file mode 100644
index 0000000000..426f137791
--- /dev/null
+++ b/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.csv
@@ -0,0 +1,157 @@
+year,v0.10.0
+1867,6889.0
+1868,4766.0
+1869,5142.0
+1870,4046.0
+1871,4831.0
+1872,3891.0
+1873,4535.0
+1874,4078.0
+1875,3944.0
+1876,3372.0
+1877,3608.0
+1878,3336.0
+1879,3067.0
+1880,3042.0
+1881,2045.0
+1882,2778.0
+1883,2677.0
+1884,2190.0
+1885,2750.0
+1886,2784.0
+1887,2109.0
+1888,2862.0
+1889,2732.0
+1890,2716.0
+1891,2608.0
+1892,3050.0
+1893,2377.0
+1894,2641.0
+1895,2570.0
+1896,2549.0
+1897,2494.0
+1898,2215.0
+1899,1929.0
+1900,2034.0
+1901,1960.0
+1902,2361.0
+1903,2321.0
+1904,2365.0
+1905,2519.0
+1906,2174.0
+1907,2600.0
+1908,3030.0
+1909,2786.0
+1910,3428.0
+1911,3092.0
+1912,3230.0
+1913,3476.0
+1914,2978.0
+1915,2726.0
+1916,2694.0
+1917,3653.0
+1918,3858.0
+1919,4278.0
+1920,4765.0
+1921,5015.0
+1922,3862.0
+1923,3514.0
+1924,3743.0
+1925,3661.0
+1926,4109.0
+1927,4089.0
+1928,4360.0
+1929,4217.0
+1930,4891.0
+1931,4021.0
+1932,4968.0
+1933,4474.0
+1934,4302.0
+1935,3510.0
+1936,4435.0
+1937,3571.0
+1938,3278.0
+1939,4394.0
+1940,3496.0
+1941,3186.0
+1942,3485.0
+1943,3599.0
+1944,3601.0
+1945,4845.0
+1946,4626.0
+1947,3493.0
+1948,4986.0
+1949,3935.0
+1950,4358.0
+1951,4970.0
+1952,4745.0
+1953,4455.0
+1954,5223.0
+1955,5017.0
+1956,5581.0
+1957,5112.0
+1958,5494.0
+1959,5568.0
+1960,6023.0
+1961,5206.0
+1962,5632.0
+1963,6013.0
+1964,7366.0
+1965,7116.0
+1966,7619.0
+1967,9099.0
+1968,8477.0
+1969,8853.0
+1970,8751.0
+1971,7555.0
+1972,8069.0
+1973,7657.0
+1974,6927.0
+1975,10987.0
+1976,4358.0
+1977,7597.0
+1978,10335.0
+1979,10131.0
+1980,9165.0
+1981,10155.0
+1982,10013.0
+1983,10924.0
+1984,10712.0
+1985,10469.0
+1986,10716.0
+1987,10798.0
+1988,11669.0
+1989,12930.0
+1990,13692.0
+1991,15012.0
+1992,16232.0
+1993,14845.0
+1994,13000.0
+1995,12357.0
+1996,13094.0
+1997,13495.0
+1998,13571.0
+1999,15173.0
+2000,15965.0
+2001,15368.0
+2002,14213.0
+2003,13631.0
+2004,15999.0
+2005,13957.0
+2006,14161.0
+2007,16042.0
+2008,13944.0
+2009,12070.0
+2010,11506.0
+2011,11600.0
+2012,12167.0
+2013,14189.0
+2014,26039.0
+2015,27562.0
+2016,25444.0
+2017,24953.0
+2018,18786.0
+2019,20918.0
+2020,30418.0
+2021,19162.0
+2022,
diff --git a/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.png b/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.png
new file mode 100644
index 0000000000..172e56e433
Binary files /dev/null and b/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.png differ
diff --git a/scripts/stats-dashboard/figures/prot-speeches/tomas.png b/scripts/stats-dashboard/figures/prot-speeches/tomas.png
new file mode 100644
index 0000000000..65c71a48b7
Binary files /dev/null and b/scripts/stats-dashboard/figures/prot-speeches/tomas.png differ
diff --git a/scripts/stats-dashboard/figures/prot-words/prot-words.csv b/scripts/stats-dashboard/figures/prot-words/prot-words.csv
new file mode 100644
index 0000000000..732163a942
--- /dev/null
+++ b/scripts/stats-dashboard/figures/prot-words/prot-words.csv
@@ -0,0 +1,157 @@
+year,v0.10.0
+1867,1591238.0
+1868,1592931.0
+1869,1580857.0
+1870,1435350.0
+1871,1895649.0
+1872,1532646.0
+1873,1824376.0
+1874,1455329.0
+1875,1564345.0
+1876,1480530.0
+1877,1514412.0
+1878,1602362.0
+1879,1302538.0
+1880,1316188.0
+1881,1003666.0
+1882,1443849.0
+1883,1328002.0
+1884,937789.0
+1885,1335744.0
+1886,1333906.0
+1887,1021747.0
+1888,1304866.0
+1889,1461603.0
+1890,1185833.0
+1891,1156740.0
+1892,1378249.0
+1893,1054098.0
+1894,1282653.0
+1895,1184232.0
+1896,1262177.0
+1897,1253249.0
+1898,1292059.0
+1899,992187.0
+1900,1155933.0
+1901,1130132.0
+1902,1269410.0
+1903,1362308.0
+1904,1495605.0
+1905,1420572.0
+1906,1484967.0
+1907,1588914.0
+1908,1791118.0
+1909,1752418.0
+1910,2086481.0
+1911,2128578.0
+1912,2204961.0
+1913,2391449.0
+1914,1955109.0
+1915,1834711.0
+1916,1791033.0
+1917,2561289.0
+1918,2999756.0
+1919,2832141.0
+1920,3092845.0
+1921,3436475.0
+1922,2727106.0
+1923,2282936.0
+1924,2453334.0
+1925,2239336.0
+1926,2707307.0
+1927,2648870.0
+1928,2810465.0
+1929,2908736.0
+1930,3094375.0
+1931,2699010.0
+1932,3660696.0
+1933,2692625.0
+1934,2667217.0
+1935,2115118.0
+1936,2643704.0
+1937,2185436.0
+1938,2047723.0
+1939,2477679.0
+1940,2052009.0
+1941,1998795.0
+1942,2353748.0
+1943,2384781.0
+1944,2275671.0
+1945,3191777.0
+1946,3070821.0
+1947,2336597.0
+1948,3209625.0
+1949,2574526.0
+1950,2741600.0
+1951,2988766.0
+1952,2715558.0
+1953,2634942.0
+1954,2910489.0
+1955,2732445.0
+1956,2988982.0
+1957,2617813.0
+1958,2939689.0
+1959,2948781.0
+1960,2912716.0
+1961,2692147.0
+1962,3057543.0
+1963,3190936.0
+1964,3529092.0
+1965,3422241.0
+1966,3610675.0
+1967,4393404.0
+1968,3931411.0
+1969,4060869.0
+1970,4214297.0
+1971,3774910.0
+1972,4023408.0
+1973,3916190.0
+1974,3318375.0
+1975,4954960.0
+1976,1760447.0
+1977,3200518.0
+1978,4116040.0
+1979,3885636.0
+1980,3800097.0
+1981,4096858.0
+1982,3714561.0
+1983,3948083.0
+1984,4008008.0
+1985,3604574.0
+1986,3872952.0
+1987,4102224.0
+1988,3924182.0
+1989,4486791.0
+1990,4453341.0
+1991,3864813.0
+1992,4270996.0
+1993,4141749.0
+1994,3575551.0
+1995,3144410.0
+1996,4163526.0
+1997,4390406.0
+1998,3567720.0
+1999,4331630.0
+2000,4613972.0
+2001,4559244.0
+2002,4124491.0
+2003,4538801.0
+2004,5362698.0
+2005,4933864.0
+2006,4857982.0
+2007,5711144.0
+2008,5170145.0
+2009,4702052.0
+2010,4233437.0
+2011,4381618.0
+2012,4689117.0
+2013,5284958.0
+2014,4430259.0
+2015,4658512.0
+2016,4265050.0
+2017,4524876.0
+2018,3069920.0
+2019,3544674.0
+2020,5579663.0
+2021,3463785.0
+2022,
diff --git a/scripts/stats-dashboard/figures/prot-words/prot-words.png b/scripts/stats-dashboard/figures/prot-words/prot-words.png
new file mode 100644
index 0000000000..a2a865a2b0
Binary files /dev/null and b/scripts/stats-dashboard/figures/prot-words/prot-words.png differ
diff --git a/scripts/stats-dashboard/generate-markdown.py b/scripts/stats-dashboard/generate-markdown.py
new file mode 100644
index 0000000000..ac7364bd51
--- /dev/null
+++ b/scripts/stats-dashboard/generate-markdown.py
@@ -0,0 +1,340 @@
+#!/usr/bin/env python3
+"""
+Generates a dynamic markdown file for the repo's main README.
+ - generate variable dict
+ - reads in readme-template.txt
+ - substitutess variables
+ - writes README.md
+"""
+from datetime import datetime
+from pyriksdagen.utils import (
+ protocol_iterators,
+ elem_iter,
+ )
+from lxml import etree
+from py_markdown_table.markdown_table import markdown_table
+from tqdm import tqdm
+import argparse
+import matplotlib.pyplot as plt
+import matplotlib.ticker as ticker
+import os
+import pandas as pd
+import re, subprocess
+
+
+
+
+here = os.path.dirname(__file__)
+now = datetime.now()
+
+corpus_paths = {
+ "protocols_path": "corpus/protocols",
+ "metadata_path": "corpus/metadata/"
+}
+
+md_row_names = {
+ "-": "",
+ "corpus_size": "Corpus size (GB)",
+ "N_prot": "Number of parliamentary records",
+ "N_prot_pages": "Total parliamentary record pages*",
+ "N_prot_speeches": "Total parliamentary record speeches",
+ "N_prot_words": "Total parliamentary record words",
+ "N_mot": "Number of Motions",
+ "N_mot_pages": "Total motion pages",
+ "N_mot_words": "Total motion words",
+ "N_MP": "Number of people with MP role",
+ "N_MIN": "Number of people with minister role"
+}
+
+
+
+
+def render_markdown(renderd):
+ with open(f"{here}/readme-template.md", 'r') as inf:
+ template = inf.read()
+ readme = template.format(**renderd)
+ with open(f"README.md", 'w+') as out:
+ out.write(readme)
+ return True
+
+
+
+
+def mk_table_data(df):
+ table_data = []
+ D = {}
+ version = sorted(list(set(df['version'])), key=lambda s: list(map(int, s[1:].split('.'))), reverse=True)
+ cols = [c for c in df.columns if c != "version"]
+ for v in version[:3]:
+ dfv = df.loc[df["version"]==v].copy()
+ dfv.reset_index(inplace=True, drop=True)
+ for col in cols:
+ if col not in D:
+ D[col] = {}
+ D[col][v] = dfv.at[0, col]
+ for k, v in D.items():
+ n = {'': md_row_names[k]}
+ n.update(v)
+ table_data.append(n)
+ return table_data
+
+
+
+
+def calculate_corpus_size():
+ """
+ Calculate the corpus size in GB
+ """
+ print("Calculating corpus size...")
+ corpus_size = 0
+ for k, v in corpus_paths.items():
+ for dirpath, dirnames, filenames in os.walk(v):
+ for f in filenames:
+ fp = os.path.join(dirpath, f)
+ if not os.path.islink(fp):
+ corpus_size += os.path.getsize(fp)
+ fsize = "%.2f" % (corpus_size / (1024 * 1024 * 1024)) # converts size to gigabytes
+ print(f"...{fsize} GB")
+ return fsize
+
+
+
+
+def count_pages_speeches_words(protocol):
+ """
+ Count pages (\ elems) in protocols and words.
+ """
+ pages, speeches, words = 0,0,0
+ tei_ns = ".//{http://www.tei-c.org/ns/1.0}"
+ xml_ns = "{http://www.w3.org/XML/1998/namespace}"
+ parser = etree.XMLParser(remove_blank_text=True)
+ root = etree.parse(protocol, parser).getroot()
+ tei = root.find(f"{tei_ns}TEI")
+ for tag, elem in elem_iter(root):
+ if tag == "u":
+ for segelem in elem:
+ words += len([_.strip() for _ in segelem.text.split(' ') if len(_) > 0 and _ != '\n'])
+ elif tag in ["note"]:
+ if 'type' in elem.attrib:
+ if elem.attrib['type'] == 'speaker':
+ speeches += 1
+ pages = len(tei.findall(f"{tei_ns}pb"))
+ return pages, speeches, words
+
+def infer_year(protocol):
+ return int(protocol.split('/')[-1].split('-')[1][:4])
+
+
+
+
+def calculate_prot_stats():
+ """
+ Counts protocol docs, number of pages, and words
+ """
+ print("Calculating protocol summary statistics...")
+ D = {"protocols":{}, "pages":{}, "speeches": {}, "words":{}}
+ N_prot,N_prot_pages,N_prot_speeches, N_prot_words = 0,0,0,0
+ protocols = sorted(list(protocol_iterators("corpus/protocols/", start=1867, end=2023)))
+ for protocol in tqdm(protocols, total=len(protocols)):
+ prot_year = infer_year(protocol)
+ if prot_year not in D["protocols"]:
+ D["protocols"][prot_year] = 0
+ D["pages"][prot_year] = 0
+ D["speeches"][prot_year] = 0
+ D["words"][prot_year] = 0
+ N_prot += 1
+ D["protocols"][prot_year] += 1
+ pp, sp, pw = count_pages_speeches_words(protocol)
+ N_prot_pages += pp
+ D["pages"][prot_year] += pp
+ N_prot_speeches += sp
+ D["speeches"][prot_year] += sp
+ N_prot_words += pw
+ D["words"][prot_year] += pw
+
+ print(f"...{N_prot} protocols, {N_prot_pages} protocol pages, {N_prot_words} protocol words")
+ return N_prot, N_prot_pages, N_prot_speeches, N_prot_words, D
+
+
+
+
+def calculate_mot_stats():
+ """
+ Calculate N motions, N motion pages and N motion words
+ """
+ print("Calculating motion summary statistics...")
+ print("...this function hasn't been written yet, return 0,0,0")
+ N_mot, N_mot_pages, N_mot_words = 0,0,0
+ return N_mot, N_mot_pages, N_mot_words
+
+
+
+
+def count_MP():
+ """
+ Counts N unique MEPs (unique wiki id's) in the MP database
+ """
+ print("Counting MPs (unique people w/ role)...")
+ N_MP = 0
+ df = pd.read_csv("corpus/metadata/member_of_parliament.csv")
+ N_MP = len(df["wiki_id"].unique())
+ print(f"... {N_MP} individuals have a 'member of parliament' role")
+ return N_MP
+
+
+
+
+def count_MIN():
+ """
+ Counts ministers in the metadata
+ """
+ print("Counting ministers (unique people with role)...")
+ N_MIN = 0
+ df = pd.read_csv("corpus/metadata/minister.csv")
+ N_MIN = len(df["wiki_id"].unique())
+ print(f"... {N_MIN} individuals have a 'minister' role")
+ return N_MIN
+
+
+
+
+def gen_prot_plot(df, path, title_string, ylab):
+ scales = {
+ "Words":1e6,
+ "Pages":1e3,
+ "Speeches":1e3,
+ "Records":1
+ }
+ labels = {
+ "Words":"M",
+ "Pages":"k",
+ "Speeches":"k",
+ "Records":""
+ }
+ path_dir = os.path.dirname(path)
+ fig_name = os.path.basename(path).split('.')[0]
+ versions = df.columns
+ versions = sorted(set(versions), key=lambda v: list(map(int, v[1:].split('.'))), reverse=True)
+ versions = versions[:4]
+ df = df[versions]
+ p, a = plt.subplots()
+ a.plot(df)
+ plt.title(title_string)
+ plt.legend(versions, loc ="upper left")
+ a.set_xlabel('Year')
+ a.set_ylabel(ylab)
+ ticks_y = ticker.FuncFormatter(lambda x, pos: '{0:g}{1}'.format(x/scales[ylab], labels[ylab]))
+ a.yaxis.set_major_formatter(ticks_y)
+ plt.savefig(f"{path_dir}/{fig_name}.png")
+
+
+
+
+def main(args):
+ print(f"CALUCLATING SUMSTATS FOR {args.version}")
+ print("---------------------------------")
+ new_version_row = [args.version]
+ new_version_row.append(calculate_corpus_size())
+ prot_stats = calculate_prot_stats()
+ prot_d = prot_stats[4]
+ [new_version_row.append(_) for _ in prot_stats[:4]]
+ [new_version_row.append(_) for _ in calculate_mot_stats()]
+ new_version_row.append(count_MP())
+ new_version_row.append(count_MIN())
+
+ # Update running stats
+ running_stats = pd.read_csv(f"{here}/descr_stats_version.csv")
+ running_stats.drop(running_stats[running_stats.version == args.version].index, inplace=True)
+ running_stats.reset_index(inplace=True, drop=True)
+ running_stats.loc[len(running_stats)] = new_version_row
+ running_stats.to_csv(f"{here}/descr_stats_version.csv", index=False)
+
+ # generate table data
+ table_data = mk_table_data(running_stats)
+ # generate table
+ table = markdown_table(
+ table_data
+ ).set_params(
+ quote=False,
+ padding_width=3,
+ row_sep="markdown"
+ ).get_markdown()
+
+ print("Sumstats, last 3 versions:\n")
+ print(table)
+ print("\n\n")
+
+
+ print("GENERATING SUMSTAT PLOTS:")
+ n_prot_path = "scripts/stats-dashboard/figures/n-prot/n-prot.csv"
+ prot_pages_path = "scripts/stats-dashboard/figures/prot-pages/prot-pages.csv"
+ prot_speeches_path = "scripts/stats-dashboard/figures/prot-speeches/prot-speeches.csv"
+ prot_words_path = "scripts/stats-dashboard/figures/prot-words/prot-words.csv"
+
+ n_prot_df = pd.read_csv(n_prot_path)
+ prot_pages_df = pd.read_csv(prot_pages_path)
+ prot_speeches_df = pd.read_csv(prot_speeches_path)
+ prot_words_df = pd.read_csv(prot_words_path)
+
+ n_prot_df.set_index('year', inplace=True)
+ prot_pages_df.set_index('year', inplace=True)
+ prot_speeches_df.set_index('year', inplace=True)
+ prot_words_df.set_index('year', inplace=True)
+
+ n_prot_df[args.version] = prot_d["protocols"]
+ prot_pages_df[args.version] = prot_d["pages"]
+ prot_speeches_df[args.version] = prot_d["speeches"]
+ prot_words_df[args.version] = prot_d["words"]
+
+ n_prot_df.to_csv(n_prot_path)
+ prot_pages_df.to_csv(prot_pages_path)
+ prot_speeches_df.to_csv(prot_speeches_path)
+ prot_words_df.to_csv(prot_words_path)
+
+ gen_prot_plot(n_prot_df, n_prot_path, f"Number of Parliamentary Records over time ({args.version})", "Records")
+ gen_prot_plot(prot_pages_df, prot_pages_path, f"Number of Pages in Parliamentary Records over time ({args.version})", "Pages")
+ gen_prot_plot(prot_speeches_df, prot_speeches_path, f"Number of Speeches in Parliamentary Records over time ({args.version})", "Speeches")
+ gen_prot_plot(prot_words_df, prot_words_path, f"Number of Words in Parliamentary Records over time ({args.version})", "Words")
+ print("...done")
+
+ print("GENERATING PLOTS OF MP COVERAGE:")
+ #mp_coverage = subprocess.run(
+ # ['python', 'scripts/stats-dashboard/mp-coverage.py'],
+ # capture_output=True, text=True
+ #)
+ #assert mp_coverage.returncode == 0
+ mp_plot = subprocess.run(
+ ['python', 'scripts/stats-dashboard/plot-mp-coverage.py', "-v", args.version],
+ capture_output=True, text=True
+ )
+ assert mp_plot.returncode == 0
+ mp_plot_ratio = subprocess.run(
+ ['python', 'scripts/stats-dashboard/plot-mp-coverage-ratio.py', "-v", args.version],
+ capture_output=True, text=True
+ )
+ assert mp_plot_ratio.returncode == 0
+ print("...done")
+
+ print("RENDERING NEW README FILE:")
+ to_render = {
+ "Updated": now.strftime("%Y-%m-%d, %H:%M:%S"),
+ "Version": args.version,
+ "sumstats_table": table,
+ }
+ if render_markdown(to_render):
+ print("New README generated successfully.")
+
+
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description=__doc__)
+ parser.add_argument("-v", "--version", type=str)
+ args = parser.parse_args()
+ exp = re.compile(r"v([0-9]+)([.])([0-9]+)([.])([0-9]+)(b|rc)?([0-9]+)?")
+ if exp.search(args.version) is None:
+ print(f"{args.version} is not a valid version number. Exiting")
+ exit()
+ else:
+ args.version = exp.search(args.version).group(0)
+ main(args)
diff --git a/scripts/stats-dashboard/mp-coverage.py b/scripts/stats-dashboard/mp-coverage.py
new file mode 100644
index 0000000000..ec98ce481c
--- /dev/null
+++ b/scripts/stats-dashboard/mp-coverage.py
@@ -0,0 +1,263 @@
+#!/usr/bin/env python3
+"""
+Calculates MP coverage and generates plots
+Should be run by `./generate-markdown.py`
+"""
+from tqdm import tqdm
+import argparse
+import datetime as dt
+import os
+import pandas as pd
+
+
+
+
+here = os.path.dirname(__file__)
+
+ledamot_map = {
+ "fk": "förstakammarledamot",
+ "ak": "andrakammarledamot",
+ "ek": "ledamot"
+}
+
+skip = [
+ 'corpus/protocols/1909/prot-1909----reg-01.xml',
+ 'corpus/protocols/1909/prot-1909----reg-02.xml',
+ 'corpus/protocols/197677/prot-197677--.xml',
+ 'corpus/protocols/197677/prot-197778--.xml',
+]
+
+
+
+
+def is_within_tolerance(nmp, baseline):
+ ratio = nmp/baseline
+ #print(f" ---> R: {ratio}")
+ if ratio > 1.1:
+ return False, ratio
+ elif ratio > 0.9:
+ return True, ratio
+ else:
+ return False, ratio
+
+
+
+
+def get_spec(protocol_path):
+ spec = None
+ spl = protocol_path.split('/')[3].split('-')
+ if len(spl) == 4:
+ return spec
+ else:
+ if len(spl[2]) > 0:
+ spec = spl[2]
+ return spec
+
+
+
+
+def mk_py(row):
+ if pd.isna(row['spec']):
+ return row['year']
+ else:
+ return str(row['year']) + row['spec']
+
+
+
+
+def get_ch(protocol_path):
+ chamber = None
+ spl = protocol_path.split('/')[3].split('-')
+ if len(spl) == 4:
+ chamber = "ek"
+ else:
+ chamber = spl[3]
+ return chamber
+
+
+
+
+def get_baseline(row, baseline_df):
+ #print(row)
+ #print(row['year'], row['chamber'], type(row['year']), type(row['chamber']))
+ y = row['year']
+ c = row['chamber']
+ fdf = baseline_df.loc[(baseline_df['year'] == y) & (baseline_df['chamber'] == c)].copy()
+ fdf.reset_index(inplace=True)
+ #print(fdf.at[0, "n_mps"])
+ return fdf.at[0, "n_mps"]
+
+
+
+
+def main():
+ print("checking MP coverage...")
+ baseline_df = pd.read_csv("corpus/quality_assessment/baseline_mp_frequencies_per_year/number_mp_in_parliament.csv")
+ baseline_df['year'] = baseline_df['year'].apply(lambda x: str(x)[:4])
+ #print(baseline_df)
+ dates = pd.read_csv("corpus/quality_assessment/session-dates/session-dates.csv", sep=";")
+ dates = dates[~dates['protocol'].isin(skip)]
+ #print(dates)
+ if "N_MP" not in dates.columns:
+ dates["N_MP"] = None
+ if "passes_test" not in dates.columns:
+ dates["passes_test"] = None
+ if "almost_passes_test" not in dates.columns:
+ dates['almost_passes_test'] = None
+ if "ratio" not in dates.columns:
+ dates["ratio"] = None
+ if "year" not in dates.columns:
+ dates["year"] = None
+ if "spec" not in dates.columns:
+ dates["spec"] = None
+ if "parliament_year" not in dates.columns:
+ dates["parliament_year"] = None
+ if "chamber" not in dates.columns:
+ dates["chamber"] = None
+ if "baseline_N" not in dates.columns:
+ dates["baseline_N"] = None
+ if "MEPs" not in dates.columns:
+ dates["MEPs"] = None
+
+ dates["year"] = dates["protocol"].apply(lambda x: str(x.split('/')[2][:4]))
+ dates["spec"] = dates["protocol"].apply(lambda x: get_spec(x))
+ dates["parliament_year"] = dates.apply(mk_py, axis=1)
+ dates['chamber'] = dates['protocol'].apply(lambda x: get_ch(x))
+ dates['baseline_N'] = dates.apply(get_baseline, args=(baseline_df,), axis=1)
+
+ mp_meta = pd.read_csv("corpus/metadata/member_of_parliament.csv")
+ #convert full dates dates of mp_meta to datetime ('start', 'end') -- leave year as str
+ mp_meta['start'] = mp_meta['start'].apply(lambda x: pd.to_datetime(x, format='%Y-%m-%d', errors='ignore'))
+ mp_meta['end'] = mp_meta['end'].apply(lambda x: pd.to_datetime(x, format='%Y-%m-%d', errors='ignore'))
+ mp_meta = mp_meta[mp_meta.start.notnull()]
+
+ baselines = {
+ "ak_baseline": 0,
+ "fk_baseline": 0,
+ "ek_baseline": 0
+ }
+
+ filtered_DFs = {}
+ for k, v in ledamot_map.items():
+ filtered_DFs[k] = mp_meta.loc[mp_meta['role'] == v]
+
+ shouldnt_happen = 0
+ with tqdm(total=len(dates)) as prgbr:
+ for i, r in dates.iterrows():
+ N_MP = 0
+ chamber = r['chamber']
+ MEPs = []
+ if not pd.isna(chamber):
+ parliament_day = r['date']
+ baseline = r['baseline_N']
+ prgbr.set_postfix_str(f"{chamber} / {r['parliament_year']} / {shouldnt_happen}")
+ #if not pd.isna(baseline):
+ # baselines[f'{chamber}_baseline'] = baseline
+ #else:
+ # baseline = baselines[f'{chamber}_baseline']
+ # dates.at[i, 'baseline_N'] = baseline
+
+ if len(parliament_day) == 10:
+ #print(r['date'], type(r['date']))
+ day = dt.datetime.strptime(r['date'], '%Y-%m-%d')
+ #print(day, type(day))
+ fdf = filtered_DFs[chamber]
+ for idx, row in fdf.iterrows():
+
+ start = None
+ end = None
+ pdts = pd._libs.tslibs.timestamps.Timestamp
+
+ #print(' -> first', start, end, row['start'], row['end'], type(row['start']), type(row['end']))
+ msg = f" -> first, {start}, {end}, {row['start']}, {row['end']}, {type(row['start'])}, {type(row['end'])}"
+ inform = False
+ if type(row['start']) == pdts:
+ start = row['start']
+ elif type(row['start']) == str:
+ start = row['start']
+ else:
+ print('start', row['start'], type(row['start']))
+ shouldnt_happen += 1
+
+ if type(row['end']) == pdts:
+ end = row['end']
+ elif type(row['end']) == str:
+ end = row['end']
+ else:
+ #print(msg)
+ #inform = True
+ #print(f"NO END: {row['end']} | {type(row['end'])}")
+ if type(start) == pdts:
+ end = int(start.year)
+ else:
+ end = start
+
+ if inform:
+ print(' --> second', start, end, type(start), type(end))
+
+ if type(start) == pdts and type(end) == pdts:
+ if start <= day < end:
+ if row["wiki_id"] not in MEPs:
+ MEPs.append(row["wiki_id"])
+ N_MP += 1
+ else:
+ if pd.notnull(start):
+ year = int(day.year)
+
+ if type(start) == pdts:
+ start = int(start.year)
+ else:
+ start = int(start[:4]) # a few (n==4) date strings are in yyyy-mm format
+
+ if type(end) == pdts:
+ end = int(end.year)
+ elif type(end) == str:
+ end = int(end[:4])
+ elif type(end) == int:
+ pass
+ else:
+ print('~~~~~~~~~/////NO!!!!!!!!!~~~~~~~', 'start', start, type(start), 'end', end, type(end))
+ shouldnt_happen += 1
+
+ #print('\\\\\\', start, year, end)
+
+ if start <= year <= end:
+ if row["wiki_id"] not in MEPs:
+ MEPs.append(row["wiki_id"])
+ N_MP += 1
+ else:
+ print("no start")
+
+ dates.at[i, 'N_MP'] = N_MP
+
+ if N_MP != 0:
+ if N_MP == r['baseline_N']:
+ dates.at[i, 'passes_test'] = True
+ dates.at[i, 'almost_passes_test'], dates.at[i, "ratio"] = is_within_tolerance(N_MP, baseline)
+ else:
+ dates.at[i, 'passes_test'] = False
+ dates.at[i, 'almost_passes_test'], dates.at[i, "ratio"] = is_within_tolerance(N_MP, baseline)
+ else:
+ dates.at[i, 'passes_test'] = False
+ dates.at[i, 'almost_passes_test'] = False
+ dates.at[i, "ratio"] = 0
+ else:
+ dates.at[i, 'passes_test'] = "None"
+ dates.at[i, 'almost_passes_test'] = "None"
+ dates.at[i, "ratio"] = "None"
+ dates.at[i, "MEPs"] = MEPs
+ prgbr.update()
+ dates.to_csv(f"{here}/figures/mp-coverage/_test-result.csv", index=False, sep=";")
+
+
+ total_passed = len(dates.loc[dates['passes_test'] == True])
+ total_almost = len(dates.loc[dates['almost_passes_test'] == True])
+ no_passdf = dates.loc[dates['almost_passes_test'] == False]
+ total = len(dates)
+ print(f"Of {total} parliament days, {total_passed} have correct N MPs in metadata: {total_passed/total}.")
+ print(f" {total_almost} pass or almost passed within the margin of error, i.e. +- 10%: {total_almost/total}.")
+
+
+
+if __name__ == '__main__':
+ main()
diff --git a/scripts/stats-dashboard/plot-mp-coverage-ratio.py b/scripts/stats-dashboard/plot-mp-coverage-ratio.py
new file mode 100644
index 0000000000..24a19c34a7
--- /dev/null
+++ b/scripts/stats-dashboard/plot-mp-coverage-ratio.py
@@ -0,0 +1,85 @@
+#!/usr/bin/env python3
+import argparse
+import matplotlib.pyplot as plt
+import os, re
+import pandas as pd
+import pandas.api.types as pdtypes
+
+
+
+
+here = os.path.dirname(__file__)
+
+
+def plot(df):
+ versions = df.columns
+ versions = sorted(set(versions), key=lambda v: list(map(int, v[1:].split('.'))), reverse=True)
+ versions = versions[:4]
+ df = df[versions]
+ p, a = plt.subplots()
+ a.plot(df)
+ a.axhline(y=1, color='green', linestyle='--', linewidth=1, label='_nolegend_')
+ a.set_title("Ratio: members of parliament to seats")
+ a.legend(versions, loc ="upper left")
+ p.savefig(f"{here}/figures/mp-coverage/mp-coverage-ratio.png")
+
+
+
+
+def main(args):
+
+ skip = [
+ 'prot-1909----reg-01.xml',
+ 'prot-1909----reg-02.xml',
+ 'prot-197677--.xml',
+ 'prot-197778--.xml',
+ ] # these were "test" protocols & break code :|
+ print("plotting quality of MP coverage")
+ df = pd.read_csv(f"{here}/figures/mp-coverage/_test-result.csv", sep=';') # output of MP frequency pre-unittest
+ mp_coverage_df = pd.read_csv(f"{here}/figures/mp-coverage/mp-coverage.csv")
+ mp_coverage_df.set_index('year', inplace=True)
+
+ for s in skip:
+ df.drop(df[df['protocol']==s].index, inplace=True)
+
+ df['parliament_year'] = df['parliament_year'].apply(lambda x: int(x[:4]))
+ pyears = df['parliament_year'].unique()
+
+ D = {}
+
+ for py in pyears:
+ D[py] = df.loc[df['parliament_year']==py, "ratio"].mean()
+
+ mp_coverage_df[args.version] = D
+
+ mp_coverage_df.to_csv(f"{here}/figures/mp-coverage/mp-coverage.csv")
+
+
+ plot(mp_coverage_df)
+
+
+ """
+ p, a = plt.subplots()
+ plt.rcParams.update({'font.size': 14})
+ a.plot(newdf['Avg_ratio'])
+ a.spines['top'].set_visible(False)
+ a.spines['right'].set_visible(False)
+ a.title("Ratio: members of parliament to seats")
+ p.axhline(y=1, color='green', linestyle='--', linewidth=1, label='_nolegend_')
+ p.savefig(f"{here}/_MP_db_coverage-vs-baseline.pdf", format='pdf', dpi=300)
+ #plt.show()
+ """
+
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description=__doc__)
+ parser.add_argument("-v", "--version", type=str)
+ args = parser.parse_args()
+ exp = re.compile(r"v([0-9]+)([.])([0-9]+)([.])([0-9]+)(b|rc)?([0-9]+)?")
+ if exp.search(args.version) is None:
+ print(f"{args.version} is not a valid version number. Exiting")
+ exit()
+ else:
+ args.version = exp.search(args.version).group(0)
+ main(args)
diff --git a/scripts/stats-dashboard/plot-mp-coverage.py b/scripts/stats-dashboard/plot-mp-coverage.py
new file mode 100644
index 0000000000..d829efdb97
--- /dev/null
+++ b/scripts/stats-dashboard/plot-mp-coverage.py
@@ -0,0 +1,91 @@
+#!/usr/bin/env python3
+"""
+Plots MP coverage per year/chamber/session
+"""
+import argparse, os, re
+import pandas as pd
+import matplotlib.pyplot as plt
+
+
+
+here = os.path.dirname(__file__)
+
+
+
+def main(args):
+ print("plotting MP coverage")
+ df = pd.read_csv(f"{here}/figures/mp-coverage/_test-result.csv", sep=";")
+
+ year = df['parliament_year'].unique()
+ #print(year)
+ plt.figure(figsize=(38.20, 10.80))
+
+ fk = df.loc[df["chamber"] == "fk"]
+ plt.plot(fk['parliament_year'], fk['baseline_N'], label = "First Chamber baseline")
+ for ix, y in enumerate(fk['parliament_year'].unique()):
+ col = "blue"
+ plt.boxplot(fk.loc[fk['parliament_year'] == y, "N_MP"].tolist(), positions=[ix],
+ manage_ticks=False,
+ boxprops=dict(color=col),
+ flierprops=dict(markeredgecolor=col, marker=".", markersize=3),
+ whiskerprops=dict(color=col),
+ capprops=dict(color=col),
+ medianprops=dict(color="red")
+ )
+
+
+
+ ak = df.loc[df["chamber"] == "ak"]
+ plt.plot(ak['parliament_year'], ak['baseline_N'], label = "Second Chamber baseline")
+ c = 0
+ for ix, y in enumerate(ak['parliament_year'].unique()):
+ c += 1
+ col = "orange"
+ plt.boxplot(ak.loc[ak['parliament_year'] == y, "N_MP"].tolist(), positions=[ix],
+ manage_ticks=False,
+ boxprops=dict(color=col),
+ flierprops=dict(markeredgecolor=col, marker=".", markersize=3),
+ whiskerprops=dict(color=col),
+ capprops=dict(color=col),
+ medianprops=dict(color="red")
+ )
+
+
+ ek = df.loc[df["chamber"] == "ek"]
+ plt.plot(ek['parliament_year'], ek['baseline_N'], label = "Unicameral baseline")
+ for ix, y in enumerate(ek['parliament_year'].unique(), start = c):
+ col = "green"
+ plt.boxplot(ek.loc[ek['parliament_year'] == y, "N_MP"].tolist(), positions=[ix],
+ manage_ticks=False,
+ boxprops=dict(color=col),
+ flierprops=dict(markeredgecolor=col, marker=".", markersize=3),
+ whiskerprops=dict(color=col),
+ capprops=dict(color=col),
+ medianprops=dict(color="red")
+ )
+
+ plt.title(f"MEP Coverage, relativee to baseline values ({args.version})", fontsize="40")
+ plt.legend(fontsize="35")
+ plt.xticks(range(0, len(year), 5), year[::5], rotation = 90, fontsize=25)
+ plt.yticks(fontsize=20)
+ #plt.xticks(rotation=90)
+ plt.savefig(f"{here}/figures/mp-coverage/mp-coverage.png",
+ dpi=100,
+ bbox_inches='tight',
+ pad_inches = 0.2
+ )
+
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description=__doc__)
+ parser.add_argument("-v", "--version", type=str)
+ args = parser.parse_args()
+ exp = re.compile(r"v([0-9]+)([.])([0-9]+)([.])([0-9]+)(b|rc)?([0-9]+)?")
+ if exp.search(args.version) is None:
+ print(f"{args.version} is not a valid version number. Exiting")
+ exit()
+ else:
+ args.version = exp.search(args.version).group(0)
+ main(args)
+
diff --git a/scripts/stats-dashboard/readme-template.md b/scripts/stats-dashboard/readme-template.md
new file mode 100644
index 0000000000..11bae0c041
--- /dev/null
+++ b/scripts/stats-dashboard/readme-template.md
@@ -0,0 +1,102 @@
+[](https://github.com/welfare-state-analytics/riksdagen-corpus/actions/workflows/push.yml)
+[](https://github.com/welfare-state-analytics/riksdagen-corpus/actions/workflows/validate.yml)
+
+
+# Swedish parliamentary proceedings --- 1867--today --- {Version}
+
+_Westac Project_, 2020--2024 |
+_Swerik Project_, 2023--2025
+
+
+## The data set
+
+The full data set consists of multiple parts:
+
+- Parliamentary records (riksdagens protokoll) from 1867 until today in the [Parla-clarin](https://github.com/clarin-eric/parla-clarin) format
+- Comprehensive list of members of parliament, ministers and governments during this period + associated metadata (mandate periods, party info, etc)
+- [In progress] An annotated catalog of motions submitted to the parliament with linked metadata
+- [Documentation](https://github.com/welfare-state-analytics/riksdagen-corpus/tree/main/docs/) of the corpus and the curation process
+- [A Google Colab notebook](https://colab.research.google.com/drive/1C3e2gwi9z83ikXbYXNPfB6RF7spTgzxA?usp=sharing) that demonstrates how the dataset can be used with Python
+
+## Basic use
+
+A full dataset is available under [this download link](https://github.com/welfare-state-analytics/riksdagen-corpus/releases/latest/download/corpus.zip). It has the following structure
+
+- Annual Parliamentary record (protocol) files in the ```corpus/protocols/``` directory
+- Structured metadata on members of parliament, ministers, and governments in the ```corpus/metadata/``` directory
+
+The workflow to use the data is demonstrated in [this Google Colab notebook](https://colab.research.google.com/drive/1C3e2gwi9z83ikXbYXNPfB6RF7spTgzxA?usp=sharing).
+
+## Design choices of the project
+
+The Riksdagen corpus is released as an iterative process, where the corpus is continuously curated and expanded. Semantic versioning is used for the whole corpus, following the established major-minor-patch practices as they apply to data. For each major and minor release, a battery of unit tests are run and a statistical sample is drawn, annotated and quantitatively evaluated to ensure integrety and quality of updated data. Errors are fixed as they are detected in order of priority. Moreover, the edit history is kept as a traceable git repository.
+
+While the contents of the corpus will change due to curation and expansion, we aim to keep the deliverable API, the `corpus/` folder, as stable as possible. This means we avoid relocating files or folders, changing formats, changing columns in metadata files, or any other changes that might break downstream scripts. Conversely, files outside the `corpus/` folder are internal to the project. End users may find utility in them but we make no effort to keep them consistent.
+
+The data in the corpus is delivered as TEI XML files to follow established practices. The metadata is delivered as CSV files, following a [normal form](https://en.wikipedia.org/wiki/Database_normalization) database structure while allowing for a legible git history. A more detailed description of the data and metadata structure and formats can be found in the README files in the `corpus/` folder.
+
+## Descriptive statistics at a glance
+
+Currently, we have an extensive set of Parliamentary Records (Riksdagens Protokoll) from 1867 until now. We are in the process of preparing Motions for inclusion in the corpus and other document types will follow.
+
+{sumstats_table}
+
+\* Digital original parliamentary records for some years in the 1990s are not paginated and thus do not contribute to the page count.See also §_Number of Pages in Parliamentary Records_.
+
+### Parliamentary Records over time
+
+#### Number of Parliamentary Records
+
+
+
+#### Number of Pages in Parliamentary Records
+
+
+
+#### Number of Speeches in Parliamentary Records
+
+
+
+Note: We are aware of an issue whereby speeches are over counted in the data's current form in the years after 2014 -- we're working on a fix. Until then, the following static graph is a better representation of the actual speeches in the Parliamentary Records for those years.
+
+
+
+#### Number of Words in Parliamentary Records
+
+
+
+### Members of Parliament over time
+
+
+
+## Quality assessment
+
+### Speech-to-speaker mapping
+
+We check how many speakers in the parliamentary records our algorithms idenify in each release.
+
+
+
+### Correct number of MPs over time
+
+
+
+
+
+
+## Participate in the curation process
+
+If you find any errors, it is possible to submit corrections to them. This is documented in the [project wiki](https://github.com/welfare-state-analytics/riksdagen-corpus/wiki/Submit-corrections).
+
+
+## Acknowledgement of support
+
+- Westac funding: Vetenskapsrådet 2018-0606
+
+- Swerik funding:Riksbankens Jubileumsfond IN22-0003
+
+
+
+
+---
+Last update: {Updated}
+
+---
+Last update: 2023-11-21, 12:27:58
diff --git a/corpus/quality_assessment/baseline_mp_frequencies_per_year/number_mp_in_parliament.csv b/corpus/quality_assessment/baseline_mp_frequencies_per_year/number_mp_in_parliament.csv
index 5a7cdf0c69..e0e0ccff53 100644
--- a/corpus/quality_assessment/baseline_mp_frequencies_per_year/number_mp_in_parliament.csv
+++ b/corpus/quality_assessment/baseline_mp_frequencies_per_year/number_mp_in_parliament.csv
@@ -2,7 +2,7 @@ year,chamber,protocol_spec,n_mps,source
1867,ak,,190,stjernquist1996:107
1867,fk,,125,stjernquist1996:107
1868,ak,,191,stjernquist1996:107
-1868,fk,,,
+1868,fk,,125,inferred
1869,ak,,191,stjernquist1996:107
1869,fk,,127,stjernquist1996:107
1870,ak,,191,stjernquist1996:107
@@ -63,229 +63,229 @@ year,chamber,protocol_spec,n_mps,source
1894,fk,,148,stjernquist1996:107
1895,ak,,230,stjernquist1996:107
1895,fk,,150,stjernquist1996:107
-1896,ak,,,
-1896,fk,,,
-1897,ak,,,
-1897,fk,,,
-1898,ak,,,
-1898,fk,,,
-1899,ak,,,
-1899,fk,,,
+1896,ak,,230,inferred
+1896,fk,,150,inferred
+1897,ak,,230,inferred
+1897,fk,,150,inferred
+1898,ak,,230,inferred
+1898,fk,,150,inferred
+1899,ak,,230,inferred
+1899,fk,,150,inferred
1900,ak,,230,stjernquist1996:122
1900,fk,,150,stjernquist1996:122
-1901,ak,,,
-1901,fk,,,
-1902,ak,,,
-1902,fk,,,
+1901,ak,,230,inferred
+1901,fk,,150,inferred
+1902,ak,,230,inferred
+1902,fk,,150,inferred
1903,ak,,230,stjernquist1996:122
1903,fk,,150,stjernquist1996:122
-1904,ak,,,
-1904,fk,,,
-1905,ak,,,
-1905,fk,,,
-1905,ak,urtima,,
-1905,fk,urtima,,
-1905,ak,urtima2,,
-1905,fk,urtima2,,
+1904,ak,,230,inferred
+1904,fk,,150,inferred
+1905,ak,,230,inferred
+1905,fk,,150,inferred
+1905,ak,urtima,230,inferred
+1905,fk,urtima,150,inferred
+1905,ak,urtima2,230,inferred
+1905,fk,urtima2,150,inferred
1906,ak,,230,stjernquist1996:122
1906,fk,,150,stjernquist1996:122
-1907,ak,,,
-1907,fk,,,
-1908,ak,,,
-1908,fk,,,
-1909,,,,
+1907,ak,,230,inferred
+1907,fk,,150,inferred
+1908,ak,,230,inferred
+1908,fk,,150,inferred
+1909,,,230,inferred
1909,ak,,230,stjernquist1996:122
1909,fk,,150,stjernquist1996:122
-1910,ak,,,
-1910,fk,,,
-1911,ak,,,
-1911,fk,,,
+1910,ak,,230,inferred
+1910,fk,,150,inferred
+1911,ak,,230,inferred
+1911,fk,,150,inferred
1912,ak,,230,stjernquist1996:123
1912,fk,,150,stjernquist1996:123
-1913,ak,,,
-1913,fk,,,
-1914,ak,a,,
-1914,fk,a,,
+1913,ak,,230,inferred
+1913,fk,,150,inferred
+1914,ak,a,230,inferred
+1914,fk,a,150,inferred
1914,ak,b,230,stjernquist1996:123
1914,fk,b,150,stjernquist1996:123
1915,ak,,230,stjernquist1996:123
1915,fk,,150,stjernquist1996:123
-1916,ak,,,
-1916,fk,,,
-1917,ak,,,
-1917,fk,,,
+1916,ak,,230,inferred
+1916,fk,,150,inferred
+1917,ak,,230,inferred
+1917,fk,,150,inferred
1918,ak,,230,stjernquist1996:123
1918,fk,,150,stjernquist1996:123
-1918,ak,urtima,,
-1918,fk,urtima,,
-1919,ak,,,
-1919,fk,,,
-1919,ak,urtima,,
-1919,fk,urtima,,
-1920,ak,,,
-1920,fk,,,
+1918,ak,urtima,230,inferred
+1918,fk,urtima,150,inferred
+1919,ak,,230,inferred
+1919,fk,,150,inferred
+1919,ak,urtima,230,inferred
+1919,fk,urtima,150,inferred
+1920,ak,,230,inferred
+1920,fk,,150,inferred
1921,ak,,230,stjernquist1996:123
1921,fk,,150,stjernquist1996:123
1922,ak,,230,stjernquist1996:123
1922,fk,,150,stjernquist1996:123
-1923,ak,,,
-1923,fk,,,
-1924,ak,,,
-1924,fk,,,
+1923,ak,,230,inferred
+1923,fk,,150,inferred
+1924,ak,,230,inferred
+1924,fk,,150,inferred
1925,ak,,230,stjernquist1996:123
1925,fk,,150,stjernquist1996:123
-1926,ak,,,
-1926,fk,,,
-1927,ak,,,
-1927,fk,,,
-1928,ak,,,
-1928,fk,,,
+1926,ak,,230,inferred
+1926,fk,,150,inferred
+1927,ak,,230,inferred
+1927,fk,,150,inferred
+1928,ak,,230,inferred
+1928,fk,,150,inferred
1929,ak,,230,stjernquist1996:123
1929,fk,,150,stjernquist1996:123
-1930,ak,,,
-1930,fk,,,
-1931,ak,,,
-1931,fk,,,
-1932,ak,,,
-1932,fk,,,
+1930,ak,,230,inferred
+1930,fk,,150,inferred
+1931,ak,,230,inferred
+1931,fk,,150,inferred
+1932,ak,,230,inferred
+1932,fk,,150,inferred
1933,ak,,230,stjernquist1996:123
1933,fk,,150,stjernquist1996:123
-1934,ak,,,
-1934,fk,,,
-1935,ak,,,
-1935,fk,,,
-1936,ak,,,
-1936,fk,,,
+1934,ak,,230,inferred
+1934,fk,,150,inferred
+1935,ak,,230,inferred
+1935,fk,,150,inferred
+1936,ak,,230,inferred
+1936,fk,,150,inferred
1937,ak,,230,stjernquist1996:123
1937,fk,,150,stjernquist1996:123
-1938,ak,,,
-1938,fk,,,
-1939,ak,,,
-1939,fk,,,
-1939,ak,urtima,,
-1939,fk,urtima,,
-1940,ak,,,
-1940,fk,,,
-1940,ak,urtima,,
-1940,fk,urtima,,
+1938,ak,,230,inferred
+1938,fk,,150,inferred
+1939,ak,,230,inferred
+1939,fk,,150,inferred
+1939,ak,urtima,230,inferred
+1939,fk,urtima,150,inferred
+1940,ak,,230,inferred
+1940,fk,,150,inferred
+1940,ak,urtima,230,inferred
+1940,fk,urtima,150,inferred
1941,ak,,230,stjernquist1996:123
1941,fk,,150,stjernquist1996:123
-1941,ak,höst,,
-1941,fk,höst,,
-1942,ak,,,
-1942,fk,,,
-1942,ak,höst,,
-1942,fk,höst,,
-1943,ak,,,
-1943,fk,,,
-1943,ak,höst,,
-1943,fk,höst,,
-1944,ak,,,
-1944,fk,,,
-1944,ak,höst,,
-1944,fk,höst,,
+1941,ak,höst,230,inferred
+1941,fk,höst,150,inferred
+1942,ak,,230,inferred
+1942,fk,,150,inferred
+1942,ak,höst,230,inferred
+1942,fk,höst,150,inferred
+1943,ak,,230,inferred
+1943,fk,,150,inferred
+1943,ak,höst,230,inferred
+1943,fk,höst,150,inferred
+1944,ak,,230,inferred
+1944,fk,,150,inferred
+1944,ak,höst,230,inferred
+1944,fk,höst,150,inferred
1945,ak,,230,stjernquist1996:123
1945,fk,,150,stjernquist1996:123
-1945,ak,höst,,
-1945,fk,höst,,
-1946,ak,,,
-1946,fk,,,
-1946,ak,höst,,
-1946,fk,höst,,
-1947,ak,,,
-1947,fk,,,
-1948,ak,,,
-1948,fk,,,
-1948,ak,höst,,
-1948,fk,höst,,
+1945,ak,höst,230,inferred
+1945,fk,höst,150,inferred
+1946,ak,,230,inferred
+1946,fk,,150,inferred
+1946,ak,höst,230,inferred
+1946,fk,höst,150,inferred
+1947,ak,,230,inferred
+1947,fk,,150,inferred
+1948,ak,,230,inferred
+1948,fk,,150,inferred
+1948,ak,höst,230,inferred
+1948,fk,höst,150,inferred
1949,ak,,230,stjernquist1996:123
1949,fk,,150,stjernquist1996:123
-1949,ak,höst,,
-1949,fk,höst,,
-1950,ak,,,
-1950,fk,,,
-1950,ak,höst,,
-1950,fk,höst,,
-1951,ak,,,
-1951,fk,,,
-1951,ak,extrahöst,,
-1951,fk,extrahöst,,
-1952,ak,,,
-1952,fk,,,
-1952,ak,höst,,
-1952,fk,höst,,
+1949,ak,höst,230,inferred
+1949,fk,höst,150,inferred
+1950,ak,,230,inferred
+1950,fk,,150,inferred
+1950,ak,höst,230,inferred
+1950,fk,höst,150,inferred
+1951,ak,,230,inferred
+1951,fk,,150,inferred
+1951,ak,extrahöst,230,inferred
+1951,fk,extrahöst,150,inferred
+1952,ak,,230,inferred
+1952,fk,,150,inferred
+1952,ak,höst,230,inferred
+1952,fk,höst,150,inferred
1953,ak,,230,stjernquist1996:123
1953,fk,,150,stjernquist1996:123
-1953,ak,höst,,
-1953,fk,höst,,
-1954,ak,,,
-1954,fk,,,
-1954,ak,höst,,
-1954,fk,höst,,
-1955,ak,,,
-1955,fk,,,
-1955,ak,höst,,
-1955,fk,höst,,
-1956,ak,,,
-1956,fk,,,
-1956,ak,höst,,
-1956,fk,höst,,
+1953,ak,höst,230,inferred
+1953,fk,höst,150,inferred
+1954,ak,,230,inferred
+1954,fk,,150,inferred
+1954,ak,höst,230,inferred
+1954,fk,höst,150,inferred
+1955,ak,,230,inferred
+1955,fk,,150,inferred
+1955,ak,höst,230,inferred
+1955,fk,höst,150,inferred
+1956,ak,,230,inferred
+1956,fk,,150,inferred
+1956,ak,höst,230,inferred
+1956,fk,höst,150,inferred
1957,ak,,231,stjernquist1996:123
1957,fk,,150,stjernquist1996:123
-1957,ak,höst,,
-1957,fk,höst,,
-1958,ak,a,,
-1958,fk,a,,
+1957,ak,höst,231,inferred
+1957,fk,höst,150,inferred
+1958,ak,a,231,inferred
+1958,fk,a,150,inferred
1958,ak,b,231,stjernquist1996:123
1958,fk,b,151,stjernquist1996:123
-1959,ak,,,
-1959,fk,,,
-1959,ak,höst,,
-1959,fk,höst,,
-1960,ak,,,
-1960,fk,,,
-1960,ak,höst,,
-1960,fk,höst,,
+1959,ak,,231,inferred
+1959,fk,,150,inferred
+1959,ak,höst,231,inferred
+1959,fk,höst,150,inferred
+1960,ak,,231,inferred
+1960,fk,,150,inferred
+1960,ak,höst,231,inferred
+1960,fk,höst,150,inferred
1961,ak,,232,stjernquist1996:123
1961,fk,,151,stjernquist1996:123
-1961,ak,höst,,
-1961,fk,höst,,
-1962,ak,,,
-1962,fk,,,
-1962,ak,höst,,
-1962,fk,höst,,
-1963,ak,,,
-1963,fk,,,
-1963,ak,höst,,
-1963,fk,höst,,
-1964,ak,,,
-1964,fk,,,
-1964,ak,höst,,
-1964,fk,höst,,
+1961,ak,höst,232,inferred
+1961,fk,höst,151,inferred
+1962,ak,,232,inferred
+1962,fk,,151,inferred
+1962,ak,höst,232,inferred
+1962,fk,höst,151,inferred
+1963,ak,,232,inferred
+1963,fk,,151,inferred
+1963,ak,höst,232,inferred
+1963,fk,höst,151,inferred
+1964,ak,,232,inferred
+1964,fk,,151,inferred
+1964,ak,höst,232,inferred
+1964,fk,höst,151,inferred
1965,ak,,233,stjernquist1996:123
1965,fk,,151,stjernquist1996:123
-1965,ak,höst,,
-1965,fk,höst,,
-1966,ak,,,
-1966,fk,,,
-1966,ak,höst,,
-1966,fk,höst,,
-1967,ak,,,
-1967,fk,,,
-1967,ak,höst,,
-1967,fk,höst,,
-1968,ak,,,
-1968,fk,,,
-1968,ak,höst,,
-1968,fk,höst,,
+1965,ak,höst,233,inferred
+1965,fk,höst,151,inferred
+1966,ak,,233,inferred
+1966,fk,,151,inferred
+1966,ak,höst,233,inferred
+1966,fk,höst,151,inferred
+1967,ak,,233,inferred
+1967,fk,,151,inferred
+1967,ak,höst,233,inferred
+1967,fk,höst,151,inferred
+1968,ak,,233,inferred
+1968,fk,,151,inferred
+1968,ak,höst,233,inferred
+1968,fk,höst,151,inferred
1969,ak,,233,stjernquist1996:123
1969,fk,,151,stjernquist1996:123
-1969,ak,höst,,
-1969,fk,höst,,
-1970,ak,,,
-1970,fk,,,
-1970,ak,höst,,
-1970,fk,höst,,
+1969,ak,höst,233,inferred
+1969,fk,höst,151,inferred
+1970,ak,,233,inferred
+1970,fk,,151,inferred
+1970,ak,höst,233,inferred
+1970,fk,höst,151,inferred
1971,ek,,350,stjernquist1992:276
1972,ek,,350,stjernquist1992:276
1973,ek,,350,stjernquist1992:276
diff --git a/scripts/stats-dashboard/descr_stats_version.csv b/scripts/stats-dashboard/descr_stats_version.csv
new file mode 100644
index 0000000000..fe01307b46
--- /dev/null
+++ b/scripts/stats-dashboard/descr_stats_version.csv
@@ -0,0 +1,2 @@
+version,corpus_size,N_prot,N_prot_pages,N_prot_speeches,N_prot_words,N_mot,N_mot_pages,N_mot_words,N_MP,N_MIN
+v0.10.0,5.58,17642,1041807,1127027,441525242,0,0,0,5975,535
diff --git a/scripts/stats-dashboard/figures/logos/rj.png b/scripts/stats-dashboard/figures/logos/rj.png
new file mode 100644
index 0000000000..15f13592e7
Binary files /dev/null and b/scripts/stats-dashboard/figures/logos/rj.png differ
diff --git a/scripts/stats-dashboard/figures/logos/vr.png b/scripts/stats-dashboard/figures/logos/vr.png
new file mode 100644
index 0000000000..7f5ed8adeb
Binary files /dev/null and b/scripts/stats-dashboard/figures/logos/vr.png differ
diff --git a/scripts/stats-dashboard/figures/mp-coverage/mp-coverage-ratio.png b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage-ratio.png
new file mode 100644
index 0000000000..692bb28369
Binary files /dev/null and b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage-ratio.png differ
diff --git a/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.csv b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.csv
new file mode 100644
index 0000000000..e177ca3625
--- /dev/null
+++ b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.csv
@@ -0,0 +1,157 @@
+year,v0.10.0
+1867,1.0092764542936283
+1868,1.002579222926426
+1869,0.9916618188869498
+1870,1.0184555365825738
+1871,1.0414319558412433
+1872,1.00839672033982
+1873,0.9991341817010309
+1874,1.0191204016675117
+1875,1.0033112013210403
+1876,0.9981960985563023
+1877,1.0043177523683504
+1878,1.018034446984295
+1879,1.0093485481624342
+1880,1.0154621848739496
+1881,1.0133998855016457
+1882,1.0009769225097693
+1883,1.0132178489287251
+1884,1.0070709146968138
+1885,1.0150900870052215
+1886,1.0222699048466737
+1887,1.1866438152130312
+1888,1.0130208333333333
+1889,1.0182457163385694
+1890,1.0175356758078695
+1891,1.0045830869308103
+1892,1.0829600219369284
+1893,1.0031014621178556
+1894,1.0045637743006166
+1895,0.9944082125603867
+1896,0.9952569169960477
+1897,1.0045217391304346
+1898,1.0068460245015611
+1899,1.0031999999999996
+1900,1.0021291448516578
+1901,1.0052759197324415
+1902,0.9977287475665152
+1903,1.011713554987212
+1904,1.0119267734553774
+1905,1.0556920013275801
+1906,1.0065144596651447
+1907,1.0165064102564103
+1908,1.0038830584707648
+1909,1.0144544708777687
+1910,1.0072514619883042
+1911,1.0047554347826089
+1912,1.0054901120868136
+1913,1.0184476650563608
+1914,1.1364444444444446
+1915,1.0142486651411131
+1916,1.0241841004184105
+1917,1.0040808269700279
+1918,1.0243478260869563
+1919,1.2704569479965901
+1920,1.0114333800841517
+1921,0.960986974866997
+1922,1.0034594391116132
+1923,0.9982665809952167
+1924,1.0096078431372546
+1925,1.0077272727272724
+1926,1.0034447600320442
+1927,1.0011879552451752
+1928,1.0120798239623645
+1929,1.010537084398977
+1930,1.0025928329367657
+1931,1.0081159420289854
+1932,1.0025008983111754
+1933,1.0086714975845406
+1934,1.0076461769115441
+1935,1.00551828847481
+1936,1.010185185185185
+1937,1.0120923913043478
+1938,1.0109281875915972
+1939,1.0255583972719522
+1940,1.0184829431438125
+1941,1.0074021882339461
+1942,1.0220653859116955
+1943,1.02516008155618
+1944,1.0098550724637676
+1945,1.00256543370106
+1946,1.0168
+1947,1.0080434782608696
+1948,1.0122918891431478
+1949,1.015755233494364
+1950,1.0146255557480224
+1951,1.004273504273504
+1952,1.002087215320911
+1953,1.0010832832431709
+1954,1.0172288295314225
+1955,1.0018834250996773
+1956,1.0028961748633878
+1957,1.012068808384598
+1958,1.0679751900760304
+1959,1.0047166821273963
+1960,1.005221238938053
+1961,0.99124299984706
+1962,1.0010798100872558
+1963,0.9831705847477343
+1964,1.0058243643079119
+1965,0.9907461423034897
+1966,0.9946100001808723
+1967,0.9855259393481964
+1968,0.9998874333725183
+1969,0.9901307230983496
+1970,0.993537565980958
+1971,1.0007892659826363
+1972,1.0045158488927486
+1973,1.002826254826255
+1974,0.988044733044733
+1975,1.005127445168939
+1976,1.005948673227856
+1977,1.0008808610163313
+1978,1.0079934085123652
+1979,1.009468045346954
+1980,1.0077001759858704
+1981,1.012532418457724
+1982,1.0076274264498166
+1983,1.006
+1984,1.01048351661953
+1985,1.0099535791594199
+1986,1.008907437398779
+1987,1.006929027401154
+1988,1.0037317914314638
+1989,1.0048836748301526
+1990,1.0060416250194353
+1991,1.0018049319766262
+1992,1.0005590886854427
+1993,0.9994040114613181
+1994,0.999365869697966
+1995,0.9993771022798057
+1996,0.9998314512051238
+1997,0.9999295410775518
+1998,0.9997441670077772
+1999,0.9999328438395416
+2000,0.9997518218532139
+2001,0.9997707736389685
+2002,1.001150829066654
+2003,1.0007484069623231
+2004,0.9997015281757403
+2005,0.9997035866021146
+2006,0.9992204618236978
+2007,0.9997982162314862
+2008,0.9998577495986507
+2009,0.9998245716624761
+2010,0.9994179799426934
+2011,0.9995292672943102
+2012,0.9996207652115288
+2013,0.9996364880468714
+2014,0.9994875020383441
+2015,0.9997795900374696
+2016,0.9995723388786725
+2017,0.9995964324629728
+2018,0.9993348342202211
+2019,0.9998451173236274
+2020,0.9997279750462442
+2021,1.2331611445175348
+2022,
diff --git a/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.png b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.png
new file mode 100644
index 0000000000..92833fd638
Binary files /dev/null and b/scripts/stats-dashboard/figures/mp-coverage/mp-coverage.png differ
diff --git a/scripts/stats-dashboard/figures/n-prot/n-prot.csv b/scripts/stats-dashboard/figures/n-prot/n-prot.csv
new file mode 100644
index 0000000000..c76e60116b
--- /dev/null
+++ b/scripts/stats-dashboard/figures/n-prot/n-prot.csv
@@ -0,0 +1,157 @@
+year,v0.10.0
+1867,149.0
+1868,130.0
+1869,123.0
+1870,129.0
+1871,160.0
+1872,123.0
+1873,148.0
+1874,152.0
+1875,103.0
+1876,95.0
+1877,107.0
+1878,112.0
+1879,103.0
+1880,104.0
+1881,85.0
+1882,113.0
+1883,118.0
+1884,94.0
+1885,109.0
+1886,103.0
+1887,86.0
+1888,94.0
+1889,94.0
+1890,85.0
+1891,88.0
+1892,102.0
+1893,79.0
+1894,92.0
+1895,81.0
+1896,79.0
+1897,78.0
+1898,77.0
+1899,69.0
+1900,96.0
+1901,81.0
+1902,93.0
+1903,129.0
+1904,126.0
+1905,136.0
+1906,120.0
+1907,126.0
+1908,139.0
+1909,122.0
+1910,103.0
+1911,93.0
+1912,97.0
+1913,97.0
+1914,277.0
+1915,183.0
+1916,202.0
+1917,148.0
+1918,176.0
+1919,149.0
+1920,153.0
+1921,110.0
+1922,93.0
+1923,91.0
+1924,87.0
+1925,88.0
+1926,88.0
+1927,84.0
+1928,84.0
+1929,82.0
+1930,94.0
+1931,92.0
+1932,112.0
+1933,101.0
+1934,95.0
+1935,86.0
+1936,98.0
+1937,88.0
+1938,87.0
+1939,142.0
+1940,128.0
+1941,102.0
+1942,60.0
+1943,72.0
+1944,70.0
+1945,84.0
+1946,86.0
+1947,74.0
+1948,80.0
+1949,64.0
+1950,68.0
+1951,69.0
+1952,64.0
+1953,64.0
+1954,66.0
+1955,64.0
+1956,66.0
+1957,60.0
+1958,66.0
+1959,64.0
+1960,59.0
+1961,72.0
+1962,73.0
+1963,74.0
+1964,84.0
+1965,84.0
+1966,78.0
+1967,106.0
+1968,90.0
+1969,86.0
+1970,92.0
+1971,152.0
+1972,148.0
+1973,161.0
+1974,146.0
+1975,200.0
+1976,88.0
+1977,127.0
+1978,176.0
+1979,172.0
+1980,174.0
+1981,178.0
+1982,167.0
+1983,170.0
+1984,169.0
+1985,167.0
+1986,139.0
+1987,140.0
+1988,133.0
+1989,142.0
+1990,129.0
+1991,127.0
+1992,123.0
+1993,125.0
+1994,122.0
+1995,115.0
+1996,119.0
+1997,122.0
+1998,112.0
+1999,128.0
+2000,127.0
+2001,125.0
+2002,122.0
+2003,134.0
+2004,144.0
+2005,145.0
+2006,136.0
+2007,142.0
+2008,141.0
+2009,147.0
+2010,128.0
+2011,140.0
+2012,136.0
+2013,134.0
+2014,123.0
+2015,130.0
+2016,134.0
+2017,142.0
+2018,112.0
+2019,148.0
+2020,158.0
+2021,142.0
+2022,
diff --git a/scripts/stats-dashboard/figures/n-prot/n-prot.png b/scripts/stats-dashboard/figures/n-prot/n-prot.png
new file mode 100644
index 0000000000..5767691682
Binary files /dev/null and b/scripts/stats-dashboard/figures/n-prot/n-prot.png differ
diff --git a/scripts/stats-dashboard/figures/prot-pages/prot-pages.csv b/scripts/stats-dashboard/figures/prot-pages/prot-pages.csv
new file mode 100644
index 0000000000..9a4e0952ce
--- /dev/null
+++ b/scripts/stats-dashboard/figures/prot-pages/prot-pages.csv
@@ -0,0 +1,157 @@
+year,v0.10.0
+1867,4660.0
+1868,4591.0
+1869,4525.0
+1870,4157.0
+1871,5194.0
+1872,4353.0
+1873,5100.0
+1874,4283.0
+1875,4655.0
+1876,4343.0
+1877,4494.0
+1878,4551.0
+1879,3827.0
+1880,3812.0
+1881,2867.0
+1882,4048.0
+1883,3778.0
+1884,2894.0
+1885,3816.0
+1886,3840.0
+1887,3101.0
+1888,3770.0
+1889,4094.0
+1890,3563.0
+1891,3484.0
+1892,4279.0
+1893,3211.0
+1894,3901.0
+1895,3562.0
+1896,3786.0
+1897,3773.0
+1898,3829.0
+1899,3067.0
+1900,3447.0
+1901,3438.0
+1902,3881.0
+1903,4130.0
+1904,4604.0
+1905,4624.0
+1906,4524.0
+1907,5192.0
+1908,5674.0
+1909,5892.0
+1910,6088.0
+1911,6163.0
+1912,6307.0
+1913,6562.0
+1914,5789.0
+1915,5094.0
+1916,5117.0
+1917,6925.0
+1918,8148.0
+1919,7803.0
+1920,8071.0
+1921,8722.0
+1922,6818.0
+1923,5843.0
+1924,5029.0
+1925,4918.0
+1926,5683.0
+1927,5593.0
+1928,5847.0
+1929,5847.0
+1930,6349.0
+1931,5543.0
+1932,7295.0
+1933,5842.0
+1934,5742.0
+1935,4641.0
+1936,5757.0
+1937,4793.0
+1938,4492.0
+1939,5555.0
+1940,4632.0
+1941,4401.0
+1942,5003.0
+1943,5161.0
+1944,4906.0
+1945,6669.0
+1946,6384.0
+1947,5023.0
+1948,6723.0
+1949,5417.0
+1950,5831.0
+1951,6306.0
+1952,5886.0
+1953,5643.0
+1954,6259.0
+1955,5976.0
+1956,6553.0
+1957,5880.0
+1958,6504.0
+1959,6661.0
+1960,6761.0
+1961,6268.0
+1962,7028.0
+1963,7231.0
+1964,8230.0
+1965,7912.0
+1966,8285.0
+1967,9909.0
+1968,9042.0
+1969,9304.0
+1970,9882.0
+1971,9790.0
+1972,10703.0
+1973,10732.0
+1974,9502.0
+1975,14658.0
+1976,5050.0
+1977,8963.0
+1978,12278.0
+1979,11316.0
+1980,10097.0
+1981,11092.0
+1982,10165.0
+1983,10743.0
+1984,10767.0
+1985,9558.0
+1986,9867.0
+1987,10343.0
+1988,10049.0
+1989,10905.0
+1990,0.0
+1991,0.0
+1992,0.0
+1993,0.0
+1994,8491.0
+1995,7778.0
+1996,9495.0
+1997,9845.0
+1998,7975.0
+1999,9779.0
+2000,10389.0
+2001,10524.0
+2002,9275.0
+2003,10047.0
+2004,11747.0
+2005,10858.0
+2006,10730.0
+2007,12489.0
+2008,11254.0
+2009,10338.0
+2010,9249.0
+2011,9711.0
+2012,10337.0
+2013,11567.0
+2014,10435.0
+2015,10784.0
+2016,10041.0
+2017,10539.0
+2018,7384.0
+2019,8538.0
+2020,12981.0
+2021,7989.0
+2022,
diff --git a/scripts/stats-dashboard/figures/prot-pages/prot-pages.png b/scripts/stats-dashboard/figures/prot-pages/prot-pages.png
new file mode 100644
index 0000000000..bf06efbcb8
Binary files /dev/null and b/scripts/stats-dashboard/figures/prot-pages/prot-pages.png differ
diff --git a/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.csv b/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.csv
new file mode 100644
index 0000000000..426f137791
--- /dev/null
+++ b/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.csv
@@ -0,0 +1,157 @@
+year,v0.10.0
+1867,6889.0
+1868,4766.0
+1869,5142.0
+1870,4046.0
+1871,4831.0
+1872,3891.0
+1873,4535.0
+1874,4078.0
+1875,3944.0
+1876,3372.0
+1877,3608.0
+1878,3336.0
+1879,3067.0
+1880,3042.0
+1881,2045.0
+1882,2778.0
+1883,2677.0
+1884,2190.0
+1885,2750.0
+1886,2784.0
+1887,2109.0
+1888,2862.0
+1889,2732.0
+1890,2716.0
+1891,2608.0
+1892,3050.0
+1893,2377.0
+1894,2641.0
+1895,2570.0
+1896,2549.0
+1897,2494.0
+1898,2215.0
+1899,1929.0
+1900,2034.0
+1901,1960.0
+1902,2361.0
+1903,2321.0
+1904,2365.0
+1905,2519.0
+1906,2174.0
+1907,2600.0
+1908,3030.0
+1909,2786.0
+1910,3428.0
+1911,3092.0
+1912,3230.0
+1913,3476.0
+1914,2978.0
+1915,2726.0
+1916,2694.0
+1917,3653.0
+1918,3858.0
+1919,4278.0
+1920,4765.0
+1921,5015.0
+1922,3862.0
+1923,3514.0
+1924,3743.0
+1925,3661.0
+1926,4109.0
+1927,4089.0
+1928,4360.0
+1929,4217.0
+1930,4891.0
+1931,4021.0
+1932,4968.0
+1933,4474.0
+1934,4302.0
+1935,3510.0
+1936,4435.0
+1937,3571.0
+1938,3278.0
+1939,4394.0
+1940,3496.0
+1941,3186.0
+1942,3485.0
+1943,3599.0
+1944,3601.0
+1945,4845.0
+1946,4626.0
+1947,3493.0
+1948,4986.0
+1949,3935.0
+1950,4358.0
+1951,4970.0
+1952,4745.0
+1953,4455.0
+1954,5223.0
+1955,5017.0
+1956,5581.0
+1957,5112.0
+1958,5494.0
+1959,5568.0
+1960,6023.0
+1961,5206.0
+1962,5632.0
+1963,6013.0
+1964,7366.0
+1965,7116.0
+1966,7619.0
+1967,9099.0
+1968,8477.0
+1969,8853.0
+1970,8751.0
+1971,7555.0
+1972,8069.0
+1973,7657.0
+1974,6927.0
+1975,10987.0
+1976,4358.0
+1977,7597.0
+1978,10335.0
+1979,10131.0
+1980,9165.0
+1981,10155.0
+1982,10013.0
+1983,10924.0
+1984,10712.0
+1985,10469.0
+1986,10716.0
+1987,10798.0
+1988,11669.0
+1989,12930.0
+1990,13692.0
+1991,15012.0
+1992,16232.0
+1993,14845.0
+1994,13000.0
+1995,12357.0
+1996,13094.0
+1997,13495.0
+1998,13571.0
+1999,15173.0
+2000,15965.0
+2001,15368.0
+2002,14213.0
+2003,13631.0
+2004,15999.0
+2005,13957.0
+2006,14161.0
+2007,16042.0
+2008,13944.0
+2009,12070.0
+2010,11506.0
+2011,11600.0
+2012,12167.0
+2013,14189.0
+2014,26039.0
+2015,27562.0
+2016,25444.0
+2017,24953.0
+2018,18786.0
+2019,20918.0
+2020,30418.0
+2021,19162.0
+2022,
diff --git a/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.png b/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.png
new file mode 100644
index 0000000000..172e56e433
Binary files /dev/null and b/scripts/stats-dashboard/figures/prot-speeches/prot-speeches.png differ
diff --git a/scripts/stats-dashboard/figures/prot-speeches/tomas.png b/scripts/stats-dashboard/figures/prot-speeches/tomas.png
new file mode 100644
index 0000000000..65c71a48b7
Binary files /dev/null and b/scripts/stats-dashboard/figures/prot-speeches/tomas.png differ
diff --git a/scripts/stats-dashboard/figures/prot-words/prot-words.csv b/scripts/stats-dashboard/figures/prot-words/prot-words.csv
new file mode 100644
index 0000000000..732163a942
--- /dev/null
+++ b/scripts/stats-dashboard/figures/prot-words/prot-words.csv
@@ -0,0 +1,157 @@
+year,v0.10.0
+1867,1591238.0
+1868,1592931.0
+1869,1580857.0
+1870,1435350.0
+1871,1895649.0
+1872,1532646.0
+1873,1824376.0
+1874,1455329.0
+1875,1564345.0
+1876,1480530.0
+1877,1514412.0
+1878,1602362.0
+1879,1302538.0
+1880,1316188.0
+1881,1003666.0
+1882,1443849.0
+1883,1328002.0
+1884,937789.0
+1885,1335744.0
+1886,1333906.0
+1887,1021747.0
+1888,1304866.0
+1889,1461603.0
+1890,1185833.0
+1891,1156740.0
+1892,1378249.0
+1893,1054098.0
+1894,1282653.0
+1895,1184232.0
+1896,1262177.0
+1897,1253249.0
+1898,1292059.0
+1899,992187.0
+1900,1155933.0
+1901,1130132.0
+1902,1269410.0
+1903,1362308.0
+1904,1495605.0
+1905,1420572.0
+1906,1484967.0
+1907,1588914.0
+1908,1791118.0
+1909,1752418.0
+1910,2086481.0
+1911,2128578.0
+1912,2204961.0
+1913,2391449.0
+1914,1955109.0
+1915,1834711.0
+1916,1791033.0
+1917,2561289.0
+1918,2999756.0
+1919,2832141.0
+1920,3092845.0
+1921,3436475.0
+1922,2727106.0
+1923,2282936.0
+1924,2453334.0
+1925,2239336.0
+1926,2707307.0
+1927,2648870.0
+1928,2810465.0
+1929,2908736.0
+1930,3094375.0
+1931,2699010.0
+1932,3660696.0
+1933,2692625.0
+1934,2667217.0
+1935,2115118.0
+1936,2643704.0
+1937,2185436.0
+1938,2047723.0
+1939,2477679.0
+1940,2052009.0
+1941,1998795.0
+1942,2353748.0
+1943,2384781.0
+1944,2275671.0
+1945,3191777.0
+1946,3070821.0
+1947,2336597.0
+1948,3209625.0
+1949,2574526.0
+1950,2741600.0
+1951,2988766.0
+1952,2715558.0
+1953,2634942.0
+1954,2910489.0
+1955,2732445.0
+1956,2988982.0
+1957,2617813.0
+1958,2939689.0
+1959,2948781.0
+1960,2912716.0
+1961,2692147.0
+1962,3057543.0
+1963,3190936.0
+1964,3529092.0
+1965,3422241.0
+1966,3610675.0
+1967,4393404.0
+1968,3931411.0
+1969,4060869.0
+1970,4214297.0
+1971,3774910.0
+1972,4023408.0
+1973,3916190.0
+1974,3318375.0
+1975,4954960.0
+1976,1760447.0
+1977,3200518.0
+1978,4116040.0
+1979,3885636.0
+1980,3800097.0
+1981,4096858.0
+1982,3714561.0
+1983,3948083.0
+1984,4008008.0
+1985,3604574.0
+1986,3872952.0
+1987,4102224.0
+1988,3924182.0
+1989,4486791.0
+1990,4453341.0
+1991,3864813.0
+1992,4270996.0
+1993,4141749.0
+1994,3575551.0
+1995,3144410.0
+1996,4163526.0
+1997,4390406.0
+1998,3567720.0
+1999,4331630.0
+2000,4613972.0
+2001,4559244.0
+2002,4124491.0
+2003,4538801.0
+2004,5362698.0
+2005,4933864.0
+2006,4857982.0
+2007,5711144.0
+2008,5170145.0
+2009,4702052.0
+2010,4233437.0
+2011,4381618.0
+2012,4689117.0
+2013,5284958.0
+2014,4430259.0
+2015,4658512.0
+2016,4265050.0
+2017,4524876.0
+2018,3069920.0
+2019,3544674.0
+2020,5579663.0
+2021,3463785.0
+2022,
diff --git a/scripts/stats-dashboard/figures/prot-words/prot-words.png b/scripts/stats-dashboard/figures/prot-words/prot-words.png
new file mode 100644
index 0000000000..a2a865a2b0
Binary files /dev/null and b/scripts/stats-dashboard/figures/prot-words/prot-words.png differ
diff --git a/scripts/stats-dashboard/generate-markdown.py b/scripts/stats-dashboard/generate-markdown.py
new file mode 100644
index 0000000000..ac7364bd51
--- /dev/null
+++ b/scripts/stats-dashboard/generate-markdown.py
@@ -0,0 +1,340 @@
+#!/usr/bin/env python3
+"""
+Generates a dynamic markdown file for the repo's main README.
+ - generate variable dict
+ - reads in readme-template.txt
+ - substitutess variables
+ - writes README.md
+"""
+from datetime import datetime
+from pyriksdagen.utils import (
+ protocol_iterators,
+ elem_iter,
+ )
+from lxml import etree
+from py_markdown_table.markdown_table import markdown_table
+from tqdm import tqdm
+import argparse
+import matplotlib.pyplot as plt
+import matplotlib.ticker as ticker
+import os
+import pandas as pd
+import re, subprocess
+
+
+
+
+here = os.path.dirname(__file__)
+now = datetime.now()
+
+corpus_paths = {
+ "protocols_path": "corpus/protocols",
+ "metadata_path": "corpus/metadata/"
+}
+
+md_row_names = {
+ "-": "",
+ "corpus_size": "Corpus size (GB)",
+ "N_prot": "Number of parliamentary records",
+ "N_prot_pages": "Total parliamentary record pages*",
+ "N_prot_speeches": "Total parliamentary record speeches",
+ "N_prot_words": "Total parliamentary record words",
+ "N_mot": "Number of Motions",
+ "N_mot_pages": "Total motion pages",
+ "N_mot_words": "Total motion words",
+ "N_MP": "Number of people with MP role",
+ "N_MIN": "Number of people with minister role"
+}
+
+
+
+
+def render_markdown(renderd):
+ with open(f"{here}/readme-template.md", 'r') as inf:
+ template = inf.read()
+ readme = template.format(**renderd)
+ with open(f"README.md", 'w+') as out:
+ out.write(readme)
+ return True
+
+
+
+
+def mk_table_data(df):
+ table_data = []
+ D = {}
+ version = sorted(list(set(df['version'])), key=lambda s: list(map(int, s[1:].split('.'))), reverse=True)
+ cols = [c for c in df.columns if c != "version"]
+ for v in version[:3]:
+ dfv = df.loc[df["version"]==v].copy()
+ dfv.reset_index(inplace=True, drop=True)
+ for col in cols:
+ if col not in D:
+ D[col] = {}
+ D[col][v] = dfv.at[0, col]
+ for k, v in D.items():
+ n = {'': md_row_names[k]}
+ n.update(v)
+ table_data.append(n)
+ return table_data
+
+
+
+
+def calculate_corpus_size():
+ """
+ Calculate the corpus size in GB
+ """
+ print("Calculating corpus size...")
+ corpus_size = 0
+ for k, v in corpus_paths.items():
+ for dirpath, dirnames, filenames in os.walk(v):
+ for f in filenames:
+ fp = os.path.join(dirpath, f)
+ if not os.path.islink(fp):
+ corpus_size += os.path.getsize(fp)
+ fsize = "%.2f" % (corpus_size / (1024 * 1024 * 1024)) # converts size to gigabytes
+ print(f"...{fsize} GB")
+ return fsize
+
+
+
+
+def count_pages_speeches_words(protocol):
+ """
+ Count pages (\ elems) in protocols and words.
+ """
+ pages, speeches, words = 0,0,0
+ tei_ns = ".//{http://www.tei-c.org/ns/1.0}"
+ xml_ns = "{http://www.w3.org/XML/1998/namespace}"
+ parser = etree.XMLParser(remove_blank_text=True)
+ root = etree.parse(protocol, parser).getroot()
+ tei = root.find(f"{tei_ns}TEI")
+ for tag, elem in elem_iter(root):
+ if tag == "u":
+ for segelem in elem:
+ words += len([_.strip() for _ in segelem.text.split(' ') if len(_) > 0 and _ != '\n'])
+ elif tag in ["note"]:
+ if 'type' in elem.attrib:
+ if elem.attrib['type'] == 'speaker':
+ speeches += 1
+ pages = len(tei.findall(f"{tei_ns}pb"))
+ return pages, speeches, words
+
+def infer_year(protocol):
+ return int(protocol.split('/')[-1].split('-')[1][:4])
+
+
+
+
+def calculate_prot_stats():
+ """
+ Counts protocol docs, number of pages, and words
+ """
+ print("Calculating protocol summary statistics...")
+ D = {"protocols":{}, "pages":{}, "speeches": {}, "words":{}}
+ N_prot,N_prot_pages,N_prot_speeches, N_prot_words = 0,0,0,0
+ protocols = sorted(list(protocol_iterators("corpus/protocols/", start=1867, end=2023)))
+ for protocol in tqdm(protocols, total=len(protocols)):
+ prot_year = infer_year(protocol)
+ if prot_year not in D["protocols"]:
+ D["protocols"][prot_year] = 0
+ D["pages"][prot_year] = 0
+ D["speeches"][prot_year] = 0
+ D["words"][prot_year] = 0
+ N_prot += 1
+ D["protocols"][prot_year] += 1
+ pp, sp, pw = count_pages_speeches_words(protocol)
+ N_prot_pages += pp
+ D["pages"][prot_year] += pp
+ N_prot_speeches += sp
+ D["speeches"][prot_year] += sp
+ N_prot_words += pw
+ D["words"][prot_year] += pw
+
+ print(f"...{N_prot} protocols, {N_prot_pages} protocol pages, {N_prot_words} protocol words")
+ return N_prot, N_prot_pages, N_prot_speeches, N_prot_words, D
+
+
+
+
+def calculate_mot_stats():
+ """
+ Calculate N motions, N motion pages and N motion words
+ """
+ print("Calculating motion summary statistics...")
+ print("...this function hasn't been written yet, return 0,0,0")
+ N_mot, N_mot_pages, N_mot_words = 0,0,0
+ return N_mot, N_mot_pages, N_mot_words
+
+
+
+
+def count_MP():
+ """
+ Counts N unique MEPs (unique wiki id's) in the MP database
+ """
+ print("Counting MPs (unique people w/ role)...")
+ N_MP = 0
+ df = pd.read_csv("corpus/metadata/member_of_parliament.csv")
+ N_MP = len(df["wiki_id"].unique())
+ print(f"... {N_MP} individuals have a 'member of parliament' role")
+ return N_MP
+
+
+
+
+def count_MIN():
+ """
+ Counts ministers in the metadata
+ """
+ print("Counting ministers (unique people with role)...")
+ N_MIN = 0
+ df = pd.read_csv("corpus/metadata/minister.csv")
+ N_MIN = len(df["wiki_id"].unique())
+ print(f"... {N_MIN} individuals have a 'minister' role")
+ return N_MIN
+
+
+
+
+def gen_prot_plot(df, path, title_string, ylab):
+ scales = {
+ "Words":1e6,
+ "Pages":1e3,
+ "Speeches":1e3,
+ "Records":1
+ }
+ labels = {
+ "Words":"M",
+ "Pages":"k",
+ "Speeches":"k",
+ "Records":""
+ }
+ path_dir = os.path.dirname(path)
+ fig_name = os.path.basename(path).split('.')[0]
+ versions = df.columns
+ versions = sorted(set(versions), key=lambda v: list(map(int, v[1:].split('.'))), reverse=True)
+ versions = versions[:4]
+ df = df[versions]
+ p, a = plt.subplots()
+ a.plot(df)
+ plt.title(title_string)
+ plt.legend(versions, loc ="upper left")
+ a.set_xlabel('Year')
+ a.set_ylabel(ylab)
+ ticks_y = ticker.FuncFormatter(lambda x, pos: '{0:g}{1}'.format(x/scales[ylab], labels[ylab]))
+ a.yaxis.set_major_formatter(ticks_y)
+ plt.savefig(f"{path_dir}/{fig_name}.png")
+
+
+
+
+def main(args):
+ print(f"CALUCLATING SUMSTATS FOR {args.version}")
+ print("---------------------------------")
+ new_version_row = [args.version]
+ new_version_row.append(calculate_corpus_size())
+ prot_stats = calculate_prot_stats()
+ prot_d = prot_stats[4]
+ [new_version_row.append(_) for _ in prot_stats[:4]]
+ [new_version_row.append(_) for _ in calculate_mot_stats()]
+ new_version_row.append(count_MP())
+ new_version_row.append(count_MIN())
+
+ # Update running stats
+ running_stats = pd.read_csv(f"{here}/descr_stats_version.csv")
+ running_stats.drop(running_stats[running_stats.version == args.version].index, inplace=True)
+ running_stats.reset_index(inplace=True, drop=True)
+ running_stats.loc[len(running_stats)] = new_version_row
+ running_stats.to_csv(f"{here}/descr_stats_version.csv", index=False)
+
+ # generate table data
+ table_data = mk_table_data(running_stats)
+ # generate table
+ table = markdown_table(
+ table_data
+ ).set_params(
+ quote=False,
+ padding_width=3,
+ row_sep="markdown"
+ ).get_markdown()
+
+ print("Sumstats, last 3 versions:\n")
+ print(table)
+ print("\n\n")
+
+
+ print("GENERATING SUMSTAT PLOTS:")
+ n_prot_path = "scripts/stats-dashboard/figures/n-prot/n-prot.csv"
+ prot_pages_path = "scripts/stats-dashboard/figures/prot-pages/prot-pages.csv"
+ prot_speeches_path = "scripts/stats-dashboard/figures/prot-speeches/prot-speeches.csv"
+ prot_words_path = "scripts/stats-dashboard/figures/prot-words/prot-words.csv"
+
+ n_prot_df = pd.read_csv(n_prot_path)
+ prot_pages_df = pd.read_csv(prot_pages_path)
+ prot_speeches_df = pd.read_csv(prot_speeches_path)
+ prot_words_df = pd.read_csv(prot_words_path)
+
+ n_prot_df.set_index('year', inplace=True)
+ prot_pages_df.set_index('year', inplace=True)
+ prot_speeches_df.set_index('year', inplace=True)
+ prot_words_df.set_index('year', inplace=True)
+
+ n_prot_df[args.version] = prot_d["protocols"]
+ prot_pages_df[args.version] = prot_d["pages"]
+ prot_speeches_df[args.version] = prot_d["speeches"]
+ prot_words_df[args.version] = prot_d["words"]
+
+ n_prot_df.to_csv(n_prot_path)
+ prot_pages_df.to_csv(prot_pages_path)
+ prot_speeches_df.to_csv(prot_speeches_path)
+ prot_words_df.to_csv(prot_words_path)
+
+ gen_prot_plot(n_prot_df, n_prot_path, f"Number of Parliamentary Records over time ({args.version})", "Records")
+ gen_prot_plot(prot_pages_df, prot_pages_path, f"Number of Pages in Parliamentary Records over time ({args.version})", "Pages")
+ gen_prot_plot(prot_speeches_df, prot_speeches_path, f"Number of Speeches in Parliamentary Records over time ({args.version})", "Speeches")
+ gen_prot_plot(prot_words_df, prot_words_path, f"Number of Words in Parliamentary Records over time ({args.version})", "Words")
+ print("...done")
+
+ print("GENERATING PLOTS OF MP COVERAGE:")
+ #mp_coverage = subprocess.run(
+ # ['python', 'scripts/stats-dashboard/mp-coverage.py'],
+ # capture_output=True, text=True
+ #)
+ #assert mp_coverage.returncode == 0
+ mp_plot = subprocess.run(
+ ['python', 'scripts/stats-dashboard/plot-mp-coverage.py', "-v", args.version],
+ capture_output=True, text=True
+ )
+ assert mp_plot.returncode == 0
+ mp_plot_ratio = subprocess.run(
+ ['python', 'scripts/stats-dashboard/plot-mp-coverage-ratio.py', "-v", args.version],
+ capture_output=True, text=True
+ )
+ assert mp_plot_ratio.returncode == 0
+ print("...done")
+
+ print("RENDERING NEW README FILE:")
+ to_render = {
+ "Updated": now.strftime("%Y-%m-%d, %H:%M:%S"),
+ "Version": args.version,
+ "sumstats_table": table,
+ }
+ if render_markdown(to_render):
+ print("New README generated successfully.")
+
+
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description=__doc__)
+ parser.add_argument("-v", "--version", type=str)
+ args = parser.parse_args()
+ exp = re.compile(r"v([0-9]+)([.])([0-9]+)([.])([0-9]+)(b|rc)?([0-9]+)?")
+ if exp.search(args.version) is None:
+ print(f"{args.version} is not a valid version number. Exiting")
+ exit()
+ else:
+ args.version = exp.search(args.version).group(0)
+ main(args)
diff --git a/scripts/stats-dashboard/mp-coverage.py b/scripts/stats-dashboard/mp-coverage.py
new file mode 100644
index 0000000000..ec98ce481c
--- /dev/null
+++ b/scripts/stats-dashboard/mp-coverage.py
@@ -0,0 +1,263 @@
+#!/usr/bin/env python3
+"""
+Calculates MP coverage and generates plots
+Should be run by `./generate-markdown.py`
+"""
+from tqdm import tqdm
+import argparse
+import datetime as dt
+import os
+import pandas as pd
+
+
+
+
+here = os.path.dirname(__file__)
+
+ledamot_map = {
+ "fk": "förstakammarledamot",
+ "ak": "andrakammarledamot",
+ "ek": "ledamot"
+}
+
+skip = [
+ 'corpus/protocols/1909/prot-1909----reg-01.xml',
+ 'corpus/protocols/1909/prot-1909----reg-02.xml',
+ 'corpus/protocols/197677/prot-197677--.xml',
+ 'corpus/protocols/197677/prot-197778--.xml',
+]
+
+
+
+
+def is_within_tolerance(nmp, baseline):
+ ratio = nmp/baseline
+ #print(f" ---> R: {ratio}")
+ if ratio > 1.1:
+ return False, ratio
+ elif ratio > 0.9:
+ return True, ratio
+ else:
+ return False, ratio
+
+
+
+
+def get_spec(protocol_path):
+ spec = None
+ spl = protocol_path.split('/')[3].split('-')
+ if len(spl) == 4:
+ return spec
+ else:
+ if len(spl[2]) > 0:
+ spec = spl[2]
+ return spec
+
+
+
+
+def mk_py(row):
+ if pd.isna(row['spec']):
+ return row['year']
+ else:
+ return str(row['year']) + row['spec']
+
+
+
+
+def get_ch(protocol_path):
+ chamber = None
+ spl = protocol_path.split('/')[3].split('-')
+ if len(spl) == 4:
+ chamber = "ek"
+ else:
+ chamber = spl[3]
+ return chamber
+
+
+
+
+def get_baseline(row, baseline_df):
+ #print(row)
+ #print(row['year'], row['chamber'], type(row['year']), type(row['chamber']))
+ y = row['year']
+ c = row['chamber']
+ fdf = baseline_df.loc[(baseline_df['year'] == y) & (baseline_df['chamber'] == c)].copy()
+ fdf.reset_index(inplace=True)
+ #print(fdf.at[0, "n_mps"])
+ return fdf.at[0, "n_mps"]
+
+
+
+
+def main():
+ print("checking MP coverage...")
+ baseline_df = pd.read_csv("corpus/quality_assessment/baseline_mp_frequencies_per_year/number_mp_in_parliament.csv")
+ baseline_df['year'] = baseline_df['year'].apply(lambda x: str(x)[:4])
+ #print(baseline_df)
+ dates = pd.read_csv("corpus/quality_assessment/session-dates/session-dates.csv", sep=";")
+ dates = dates[~dates['protocol'].isin(skip)]
+ #print(dates)
+ if "N_MP" not in dates.columns:
+ dates["N_MP"] = None
+ if "passes_test" not in dates.columns:
+ dates["passes_test"] = None
+ if "almost_passes_test" not in dates.columns:
+ dates['almost_passes_test'] = None
+ if "ratio" not in dates.columns:
+ dates["ratio"] = None
+ if "year" not in dates.columns:
+ dates["year"] = None
+ if "spec" not in dates.columns:
+ dates["spec"] = None
+ if "parliament_year" not in dates.columns:
+ dates["parliament_year"] = None
+ if "chamber" not in dates.columns:
+ dates["chamber"] = None
+ if "baseline_N" not in dates.columns:
+ dates["baseline_N"] = None
+ if "MEPs" not in dates.columns:
+ dates["MEPs"] = None
+
+ dates["year"] = dates["protocol"].apply(lambda x: str(x.split('/')[2][:4]))
+ dates["spec"] = dates["protocol"].apply(lambda x: get_spec(x))
+ dates["parliament_year"] = dates.apply(mk_py, axis=1)
+ dates['chamber'] = dates['protocol'].apply(lambda x: get_ch(x))
+ dates['baseline_N'] = dates.apply(get_baseline, args=(baseline_df,), axis=1)
+
+ mp_meta = pd.read_csv("corpus/metadata/member_of_parliament.csv")
+ #convert full dates dates of mp_meta to datetime ('start', 'end') -- leave year as str
+ mp_meta['start'] = mp_meta['start'].apply(lambda x: pd.to_datetime(x, format='%Y-%m-%d', errors='ignore'))
+ mp_meta['end'] = mp_meta['end'].apply(lambda x: pd.to_datetime(x, format='%Y-%m-%d', errors='ignore'))
+ mp_meta = mp_meta[mp_meta.start.notnull()]
+
+ baselines = {
+ "ak_baseline": 0,
+ "fk_baseline": 0,
+ "ek_baseline": 0
+ }
+
+ filtered_DFs = {}
+ for k, v in ledamot_map.items():
+ filtered_DFs[k] = mp_meta.loc[mp_meta['role'] == v]
+
+ shouldnt_happen = 0
+ with tqdm(total=len(dates)) as prgbr:
+ for i, r in dates.iterrows():
+ N_MP = 0
+ chamber = r['chamber']
+ MEPs = []
+ if not pd.isna(chamber):
+ parliament_day = r['date']
+ baseline = r['baseline_N']
+ prgbr.set_postfix_str(f"{chamber} / {r['parliament_year']} / {shouldnt_happen}")
+ #if not pd.isna(baseline):
+ # baselines[f'{chamber}_baseline'] = baseline
+ #else:
+ # baseline = baselines[f'{chamber}_baseline']
+ # dates.at[i, 'baseline_N'] = baseline
+
+ if len(parliament_day) == 10:
+ #print(r['date'], type(r['date']))
+ day = dt.datetime.strptime(r['date'], '%Y-%m-%d')
+ #print(day, type(day))
+ fdf = filtered_DFs[chamber]
+ for idx, row in fdf.iterrows():
+
+ start = None
+ end = None
+ pdts = pd._libs.tslibs.timestamps.Timestamp
+
+ #print(' -> first', start, end, row['start'], row['end'], type(row['start']), type(row['end']))
+ msg = f" -> first, {start}, {end}, {row['start']}, {row['end']}, {type(row['start'])}, {type(row['end'])}"
+ inform = False
+ if type(row['start']) == pdts:
+ start = row['start']
+ elif type(row['start']) == str:
+ start = row['start']
+ else:
+ print('start', row['start'], type(row['start']))
+ shouldnt_happen += 1
+
+ if type(row['end']) == pdts:
+ end = row['end']
+ elif type(row['end']) == str:
+ end = row['end']
+ else:
+ #print(msg)
+ #inform = True
+ #print(f"NO END: {row['end']} | {type(row['end'])}")
+ if type(start) == pdts:
+ end = int(start.year)
+ else:
+ end = start
+
+ if inform:
+ print(' --> second', start, end, type(start), type(end))
+
+ if type(start) == pdts and type(end) == pdts:
+ if start <= day < end:
+ if row["wiki_id"] not in MEPs:
+ MEPs.append(row["wiki_id"])
+ N_MP += 1
+ else:
+ if pd.notnull(start):
+ year = int(day.year)
+
+ if type(start) == pdts:
+ start = int(start.year)
+ else:
+ start = int(start[:4]) # a few (n==4) date strings are in yyyy-mm format
+
+ if type(end) == pdts:
+ end = int(end.year)
+ elif type(end) == str:
+ end = int(end[:4])
+ elif type(end) == int:
+ pass
+ else:
+ print('~~~~~~~~~/////NO!!!!!!!!!~~~~~~~', 'start', start, type(start), 'end', end, type(end))
+ shouldnt_happen += 1
+
+ #print('\\\\\\', start, year, end)
+
+ if start <= year <= end:
+ if row["wiki_id"] not in MEPs:
+ MEPs.append(row["wiki_id"])
+ N_MP += 1
+ else:
+ print("no start")
+
+ dates.at[i, 'N_MP'] = N_MP
+
+ if N_MP != 0:
+ if N_MP == r['baseline_N']:
+ dates.at[i, 'passes_test'] = True
+ dates.at[i, 'almost_passes_test'], dates.at[i, "ratio"] = is_within_tolerance(N_MP, baseline)
+ else:
+ dates.at[i, 'passes_test'] = False
+ dates.at[i, 'almost_passes_test'], dates.at[i, "ratio"] = is_within_tolerance(N_MP, baseline)
+ else:
+ dates.at[i, 'passes_test'] = False
+ dates.at[i, 'almost_passes_test'] = False
+ dates.at[i, "ratio"] = 0
+ else:
+ dates.at[i, 'passes_test'] = "None"
+ dates.at[i, 'almost_passes_test'] = "None"
+ dates.at[i, "ratio"] = "None"
+ dates.at[i, "MEPs"] = MEPs
+ prgbr.update()
+ dates.to_csv(f"{here}/figures/mp-coverage/_test-result.csv", index=False, sep=";")
+
+
+ total_passed = len(dates.loc[dates['passes_test'] == True])
+ total_almost = len(dates.loc[dates['almost_passes_test'] == True])
+ no_passdf = dates.loc[dates['almost_passes_test'] == False]
+ total = len(dates)
+ print(f"Of {total} parliament days, {total_passed} have correct N MPs in metadata: {total_passed/total}.")
+ print(f" {total_almost} pass or almost passed within the margin of error, i.e. +- 10%: {total_almost/total}.")
+
+
+
+if __name__ == '__main__':
+ main()
diff --git a/scripts/stats-dashboard/plot-mp-coverage-ratio.py b/scripts/stats-dashboard/plot-mp-coverage-ratio.py
new file mode 100644
index 0000000000..24a19c34a7
--- /dev/null
+++ b/scripts/stats-dashboard/plot-mp-coverage-ratio.py
@@ -0,0 +1,85 @@
+#!/usr/bin/env python3
+import argparse
+import matplotlib.pyplot as plt
+import os, re
+import pandas as pd
+import pandas.api.types as pdtypes
+
+
+
+
+here = os.path.dirname(__file__)
+
+
+def plot(df):
+ versions = df.columns
+ versions = sorted(set(versions), key=lambda v: list(map(int, v[1:].split('.'))), reverse=True)
+ versions = versions[:4]
+ df = df[versions]
+ p, a = plt.subplots()
+ a.plot(df)
+ a.axhline(y=1, color='green', linestyle='--', linewidth=1, label='_nolegend_')
+ a.set_title("Ratio: members of parliament to seats")
+ a.legend(versions, loc ="upper left")
+ p.savefig(f"{here}/figures/mp-coverage/mp-coverage-ratio.png")
+
+
+
+
+def main(args):
+
+ skip = [
+ 'prot-1909----reg-01.xml',
+ 'prot-1909----reg-02.xml',
+ 'prot-197677--.xml',
+ 'prot-197778--.xml',
+ ] # these were "test" protocols & break code :|
+ print("plotting quality of MP coverage")
+ df = pd.read_csv(f"{here}/figures/mp-coverage/_test-result.csv", sep=';') # output of MP frequency pre-unittest
+ mp_coverage_df = pd.read_csv(f"{here}/figures/mp-coverage/mp-coverage.csv")
+ mp_coverage_df.set_index('year', inplace=True)
+
+ for s in skip:
+ df.drop(df[df['protocol']==s].index, inplace=True)
+
+ df['parliament_year'] = df['parliament_year'].apply(lambda x: int(x[:4]))
+ pyears = df['parliament_year'].unique()
+
+ D = {}
+
+ for py in pyears:
+ D[py] = df.loc[df['parliament_year']==py, "ratio"].mean()
+
+ mp_coverage_df[args.version] = D
+
+ mp_coverage_df.to_csv(f"{here}/figures/mp-coverage/mp-coverage.csv")
+
+
+ plot(mp_coverage_df)
+
+
+ """
+ p, a = plt.subplots()
+ plt.rcParams.update({'font.size': 14})
+ a.plot(newdf['Avg_ratio'])
+ a.spines['top'].set_visible(False)
+ a.spines['right'].set_visible(False)
+ a.title("Ratio: members of parliament to seats")
+ p.axhline(y=1, color='green', linestyle='--', linewidth=1, label='_nolegend_')
+ p.savefig(f"{here}/_MP_db_coverage-vs-baseline.pdf", format='pdf', dpi=300)
+ #plt.show()
+ """
+
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description=__doc__)
+ parser.add_argument("-v", "--version", type=str)
+ args = parser.parse_args()
+ exp = re.compile(r"v([0-9]+)([.])([0-9]+)([.])([0-9]+)(b|rc)?([0-9]+)?")
+ if exp.search(args.version) is None:
+ print(f"{args.version} is not a valid version number. Exiting")
+ exit()
+ else:
+ args.version = exp.search(args.version).group(0)
+ main(args)
diff --git a/scripts/stats-dashboard/plot-mp-coverage.py b/scripts/stats-dashboard/plot-mp-coverage.py
new file mode 100644
index 0000000000..d829efdb97
--- /dev/null
+++ b/scripts/stats-dashboard/plot-mp-coverage.py
@@ -0,0 +1,91 @@
+#!/usr/bin/env python3
+"""
+Plots MP coverage per year/chamber/session
+"""
+import argparse, os, re
+import pandas as pd
+import matplotlib.pyplot as plt
+
+
+
+here = os.path.dirname(__file__)
+
+
+
+def main(args):
+ print("plotting MP coverage")
+ df = pd.read_csv(f"{here}/figures/mp-coverage/_test-result.csv", sep=";")
+
+ year = df['parliament_year'].unique()
+ #print(year)
+ plt.figure(figsize=(38.20, 10.80))
+
+ fk = df.loc[df["chamber"] == "fk"]
+ plt.plot(fk['parliament_year'], fk['baseline_N'], label = "First Chamber baseline")
+ for ix, y in enumerate(fk['parliament_year'].unique()):
+ col = "blue"
+ plt.boxplot(fk.loc[fk['parliament_year'] == y, "N_MP"].tolist(), positions=[ix],
+ manage_ticks=False,
+ boxprops=dict(color=col),
+ flierprops=dict(markeredgecolor=col, marker=".", markersize=3),
+ whiskerprops=dict(color=col),
+ capprops=dict(color=col),
+ medianprops=dict(color="red")
+ )
+
+
+
+ ak = df.loc[df["chamber"] == "ak"]
+ plt.plot(ak['parliament_year'], ak['baseline_N'], label = "Second Chamber baseline")
+ c = 0
+ for ix, y in enumerate(ak['parliament_year'].unique()):
+ c += 1
+ col = "orange"
+ plt.boxplot(ak.loc[ak['parliament_year'] == y, "N_MP"].tolist(), positions=[ix],
+ manage_ticks=False,
+ boxprops=dict(color=col),
+ flierprops=dict(markeredgecolor=col, marker=".", markersize=3),
+ whiskerprops=dict(color=col),
+ capprops=dict(color=col),
+ medianprops=dict(color="red")
+ )
+
+
+ ek = df.loc[df["chamber"] == "ek"]
+ plt.plot(ek['parliament_year'], ek['baseline_N'], label = "Unicameral baseline")
+ for ix, y in enumerate(ek['parliament_year'].unique(), start = c):
+ col = "green"
+ plt.boxplot(ek.loc[ek['parliament_year'] == y, "N_MP"].tolist(), positions=[ix],
+ manage_ticks=False,
+ boxprops=dict(color=col),
+ flierprops=dict(markeredgecolor=col, marker=".", markersize=3),
+ whiskerprops=dict(color=col),
+ capprops=dict(color=col),
+ medianprops=dict(color="red")
+ )
+
+ plt.title(f"MEP Coverage, relativee to baseline values ({args.version})", fontsize="40")
+ plt.legend(fontsize="35")
+ plt.xticks(range(0, len(year), 5), year[::5], rotation = 90, fontsize=25)
+ plt.yticks(fontsize=20)
+ #plt.xticks(rotation=90)
+ plt.savefig(f"{here}/figures/mp-coverage/mp-coverage.png",
+ dpi=100,
+ bbox_inches='tight',
+ pad_inches = 0.2
+ )
+
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description=__doc__)
+ parser.add_argument("-v", "--version", type=str)
+ args = parser.parse_args()
+ exp = re.compile(r"v([0-9]+)([.])([0-9]+)([.])([0-9]+)(b|rc)?([0-9]+)?")
+ if exp.search(args.version) is None:
+ print(f"{args.version} is not a valid version number. Exiting")
+ exit()
+ else:
+ args.version = exp.search(args.version).group(0)
+ main(args)
+
diff --git a/scripts/stats-dashboard/readme-template.md b/scripts/stats-dashboard/readme-template.md
new file mode 100644
index 0000000000..11bae0c041
--- /dev/null
+++ b/scripts/stats-dashboard/readme-template.md
@@ -0,0 +1,102 @@
+[](https://github.com/welfare-state-analytics/riksdagen-corpus/actions/workflows/push.yml)
+[](https://github.com/welfare-state-analytics/riksdagen-corpus/actions/workflows/validate.yml)
+
+
+# Swedish parliamentary proceedings --- 1867--today --- {Version}
+
+_Westac Project_, 2020--2024 |
+_Swerik Project_, 2023--2025
+
+
+## The data set
+
+The full data set consists of multiple parts:
+
+- Parliamentary records (riksdagens protokoll) from 1867 until today in the [Parla-clarin](https://github.com/clarin-eric/parla-clarin) format
+- Comprehensive list of members of parliament, ministers and governments during this period + associated metadata (mandate periods, party info, etc)
+- [In progress] An annotated catalog of motions submitted to the parliament with linked metadata
+- [Documentation](https://github.com/welfare-state-analytics/riksdagen-corpus/tree/main/docs/) of the corpus and the curation process
+- [A Google Colab notebook](https://colab.research.google.com/drive/1C3e2gwi9z83ikXbYXNPfB6RF7spTgzxA?usp=sharing) that demonstrates how the dataset can be used with Python
+
+## Basic use
+
+A full dataset is available under [this download link](https://github.com/welfare-state-analytics/riksdagen-corpus/releases/latest/download/corpus.zip). It has the following structure
+
+- Annual Parliamentary record (protocol) files in the ```corpus/protocols/``` directory
+- Structured metadata on members of parliament, ministers, and governments in the ```corpus/metadata/``` directory
+
+The workflow to use the data is demonstrated in [this Google Colab notebook](https://colab.research.google.com/drive/1C3e2gwi9z83ikXbYXNPfB6RF7spTgzxA?usp=sharing).
+
+## Design choices of the project
+
+The Riksdagen corpus is released as an iterative process, where the corpus is continuously curated and expanded. Semantic versioning is used for the whole corpus, following the established major-minor-patch practices as they apply to data. For each major and minor release, a battery of unit tests are run and a statistical sample is drawn, annotated and quantitatively evaluated to ensure integrety and quality of updated data. Errors are fixed as they are detected in order of priority. Moreover, the edit history is kept as a traceable git repository.
+
+While the contents of the corpus will change due to curation and expansion, we aim to keep the deliverable API, the `corpus/` folder, as stable as possible. This means we avoid relocating files or folders, changing formats, changing columns in metadata files, or any other changes that might break downstream scripts. Conversely, files outside the `corpus/` folder are internal to the project. End users may find utility in them but we make no effort to keep them consistent.
+
+The data in the corpus is delivered as TEI XML files to follow established practices. The metadata is delivered as CSV files, following a [normal form](https://en.wikipedia.org/wiki/Database_normalization) database structure while allowing for a legible git history. A more detailed description of the data and metadata structure and formats can be found in the README files in the `corpus/` folder.
+
+## Descriptive statistics at a glance
+
+Currently, we have an extensive set of Parliamentary Records (Riksdagens Protokoll) from 1867 until now. We are in the process of preparing Motions for inclusion in the corpus and other document types will follow.
+
+{sumstats_table}
+
+\* Digital original parliamentary records for some years in the 1990s are not paginated and thus do not contribute to the page count.See also §_Number of Pages in Parliamentary Records_.
+
+### Parliamentary Records over time
+
+#### Number of Parliamentary Records
+
+
+
+#### Number of Pages in Parliamentary Records
+
+
+
+#### Number of Speeches in Parliamentary Records
+
+
+
+Note: We are aware of an issue whereby speeches are over counted in the data's current form in the years after 2014 -- we're working on a fix. Until then, the following static graph is a better representation of the actual speeches in the Parliamentary Records for those years.
+
+
+
+#### Number of Words in Parliamentary Records
+
+
+
+### Members of Parliament over time
+
+
+
+## Quality assessment
+
+### Speech-to-speaker mapping
+
+We check how many speakers in the parliamentary records our algorithms idenify in each release.
+
+
+
+### Correct number of MPs over time
+
+
+
+
+
+
+## Participate in the curation process
+
+If you find any errors, it is possible to submit corrections to them. This is documented in the [project wiki](https://github.com/welfare-state-analytics/riksdagen-corpus/wiki/Submit-corrections).
+
+
+## Acknowledgement of support
+
+- Westac funding: Vetenskapsrådet 2018-0606
+
+- Swerik funding:Riksbankens Jubileumsfond IN22-0003
+
+
+
+
+---
+Last update: {Updated}