这是我另外一个项目其中一个组件——品种选择器,因为今天是周六,磨磨唧唧的造出了它。一眼看过去跟现有的通讯录样式和操作方式基本一致,但大家也知道我的尿性,从最开始能用三方组件就用三方到现在能自己写就自己写。
因为前后端都是我自己一个人在做(创业狗就是惨 = =)所以在今天萌生了很多好玩的想法,刚把这个组建弄出来后觉得有必要跟大家分享一些好玩的事情。
先来看看 UI 样式,
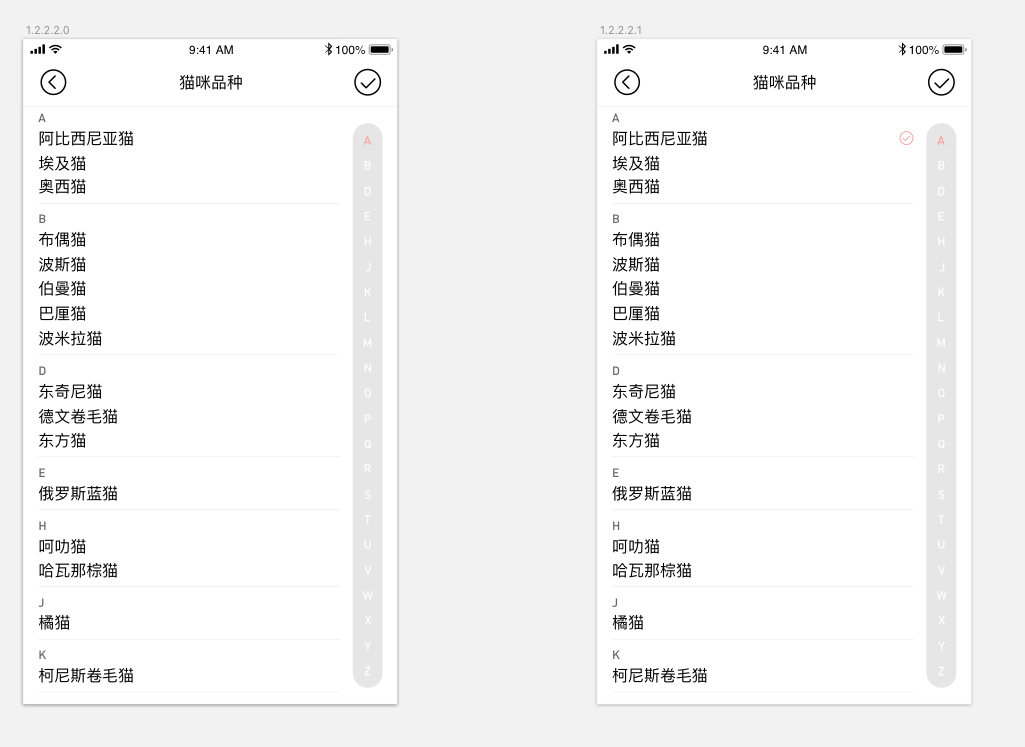
最开始看到设计图时,并不认为这是一个有多少搞头的东西,一直拖到今天。这是最终实现的成果,
给到我的文案是个 .docx 格式的文档,如下所示:

之前沟通过了一次,给我按照字母表顺序排好就行了。最开始我的设计非常简单,因为后端是用 python 写的,直接从文件中读出数据,split 一下丢入库里就好了,接口直接返回 id 和 zh_name 即可,遂开干。
# 初始化:尽量通过 python shell 调用该方法
def init_dog_breed():
f = open(settings.DOG_BREED_DIR, 'r')
f_str = f.read()
f_str_arr = f_str.split()
for dog_name in f_str_arr:
dog_breed(zh_name=dog_name).save()
f.close()从本地路径读取转化成 .txt 文件(本人对直接读 .docx 没把握)后简单的操作下入库完事,这个方法并未暴露在接口中,而且只是第一次初始化数据时需要调用该方法。为了方便后续产品迭代添加宠物品种信息,做了另外一个简单的方法:
# 新增狗品种
def add_dog_breed(breed_name):
dog_breed(zh_name=breed_name).save()当然,也会有猫的,因为基本上差不多就不展开了。接口上这么写:
@decorator.request_methon('GET')
@decorator.request_check_args(['pet_type'])
def get_breeds(request):
pet_type = request.GET.get('pet_type', '')
functions = {
'dog': dog(),
'cat': cat()
}
if pet_type in functions.keys():
json = {
'breeds': functions[pet_type]
}
return utils.SuccessResponse(json, request)
else:
return utils.ErrorResponse('2333', '不支持该物种', request)
# 获取所有狗品种
def dog():
dog_breeds = dog_breed.objects.all()
breeds = []
for breed in dog_breeds:
json = {
'id': breed.pk,
'zh_name': breed.zh_name,
}
breeds.append(json)
return breeds猜测后续产品可能还会引入其它宠物,毕竟现代人对宠物的需求是越来越奇葩了,没有直接 if-else ,想用 switch ,但发现 python 中并没有 switch 语句,查阅一番资料后,发现居然可以用 key-value 完成,虽然有些稍许麻烦,但第一次见还可以把键值对玩成这样!
访问对应接口后拿到的 JSON 格式数据如下:
{
"msgCode": 666,
"msg": {
"breeds": [
{
"id": 89,
"zh_name": "拉布拉多寻回犬"
},
{·
"id": 90,
"zh_name": "拉萨犬"
},
{
"id": 91,
"zh_name": "腊肠犬"
},
{
"id": 92,
"zh_name": "兰波格犬"
},
{
"id": 93,
"zh_name": "猎水獭犬"
},
]
}
}一切顺利,看起来不错,开始造客户端 UI。客户端上的实现同样也是比较轻松,一个 tableView 的正常渲染流程即可。
数据渲染出来后,脑子已经在快速运转,站起来活动活动,发现肚子有些饿,纠结了一会是食堂呢还是饿了么,最后因为贫穷而选择了食堂。
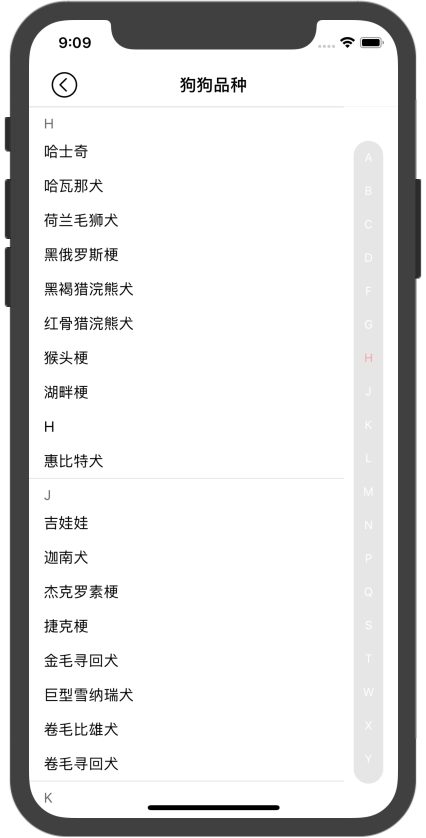
午饭结束后,继续干活。开始做数据分组,思考并发现了问题所在,如果按照上午接口所返回的数据格式去做,那么就需要端上做数据分组,把宠物品种按照 A~Z 的顺序放到一个个的 section 中,这样不但 iOS 需要做一遍,以后 Android 也要再做一遍,而且极其有可能还是我写,本来我就十分厌烦 Android,多花费一分钟甚至一秒钟都是极其不乐意的。
所有,重新思考接口返回的数据格式。可以确保的是,数据都已经按照字母序排好了,我们只需要对数据做分组,把第一个字的拼音的第一个字母相同的品种归类为一组,最后把所有组都放到一个大的列表中,序列化为 JSON 返回即可完事。
遂又开干!
首先给品种模型新增了一个字段 group 用于标记所属组别,中途考虑到了不想多增迁移文件,居然脑残的把之前生成的表给删了,导致后边生成迁移文件时对不上,最后又删库重来,真是多此一举 = =。
重新把基本操作都弄完后,改造初始化数据的方法,用到了一个中文转拼音的库 pinyin:
# 初始化:尽量通过 python shell 调用该方法
def init_dog_breed():
f = open(settings.DOG_BREED_DIR, 'r')
f_str = f.read()
f_str_arr = f_str.split()
# 删除 array 中的第一个 'A'
del f_str_arr[0]
group = 'A'
for dog_name in f_str_arr:
first_cat_name = pinyin.get(dog_name, format='strip')[0:1].upper()
if first_cat_name != group:
group = first_cat_name
# 切换 group 时跳过
continue
dog_breed(zh_name=dog_name, group=group).save()
f.close()这样清洗过数据后,数据就十分清晰漂亮了:
+-----+-------+--------------------------------+
| id | group | zh_name |
+-----+-------+--------------------------------+
| 1 | A | 阿富汗猎犬 |
| 2 | A | 阿拉斯加雪橇犬 |
| 3 | A | 爱尔兰梗 |
| 4 | A | 爱尔兰红白雪达犬 |
| 5 | A | 爱尔兰猎狼犬 |
| 6 | A | 爱尔兰软毛梗 |
| 7 | A | 爱尔兰水猎犬 |
| 8 | A | 爱尔兰峡谷梗 |
+-----+-------+--------------------------------+而接口,只需要进行拼接同类数据即可,
# 获取所有狗品种
def dog():
dog_breeds = dog_breed.objects.all()
# 所有种类
breeds = []
# 当前种类名
breed_groups = []
group = "A"
for breed in dog_breeds:
if breed.group != group:
breed_group = {
'group': group,
'breeds': breed_groups,
}
breeds.append(breed_group)
group = breed.group
breed_groups = []
b_group = {
'id': breed.pk,
'zh_name': breed.zh_name,
}
breed_groups.append(b_group)
return breeds这样,客户端就能够拿到已经分组好的数据:
{
"msgCode": 666,
"msg": {
"breeds": [
{
"group": "A",
"breeds": [
{
"group": "T",
"breeds": [
{
"id": 137,
"zh_name": "田野小猎犬"
}
]
},
]
},
{
"group": "W",
"breeds": [
{
"id": 138,
"zh_name": "玩具猎狐梗"
},
{
"id": 139,
"zh_name": "玩具曼彻斯特犬"
},
]
}
]
}
}那客户端接下来要做的事情稍微冗余一些,但不复杂。首先先确定 tableView.sections 的值,然后返回 sectionHeaderView,接着编写 cellForRow 渲染 cell 的方法,依然是正常的 tableView 渲染流程。
剩下的就是一些其它 UI 和交互细节上的修修补补了。
这次做的这个组件前后端花费的时间比例大约在 7:3,主要时间都花在客户端上,因为是第一次做类似于这种通讯录组件的开发,再加上是周六,让自己的大脑和心情都放松了下来,没有把时间抓得特别紧。
给我最大的收获是最开始只考虑了后端处理数据的便利,而忘了前端处理数据的复杂,到后边转换了思维,用前端的思维对接口格式进行了修改,这一来一回让自己更加明白了前后端配合是才能够把一个东西做好,做到极致。