-
要把
Core Data作为一个对象图管理系统来使用,而不是关系型数据库 -
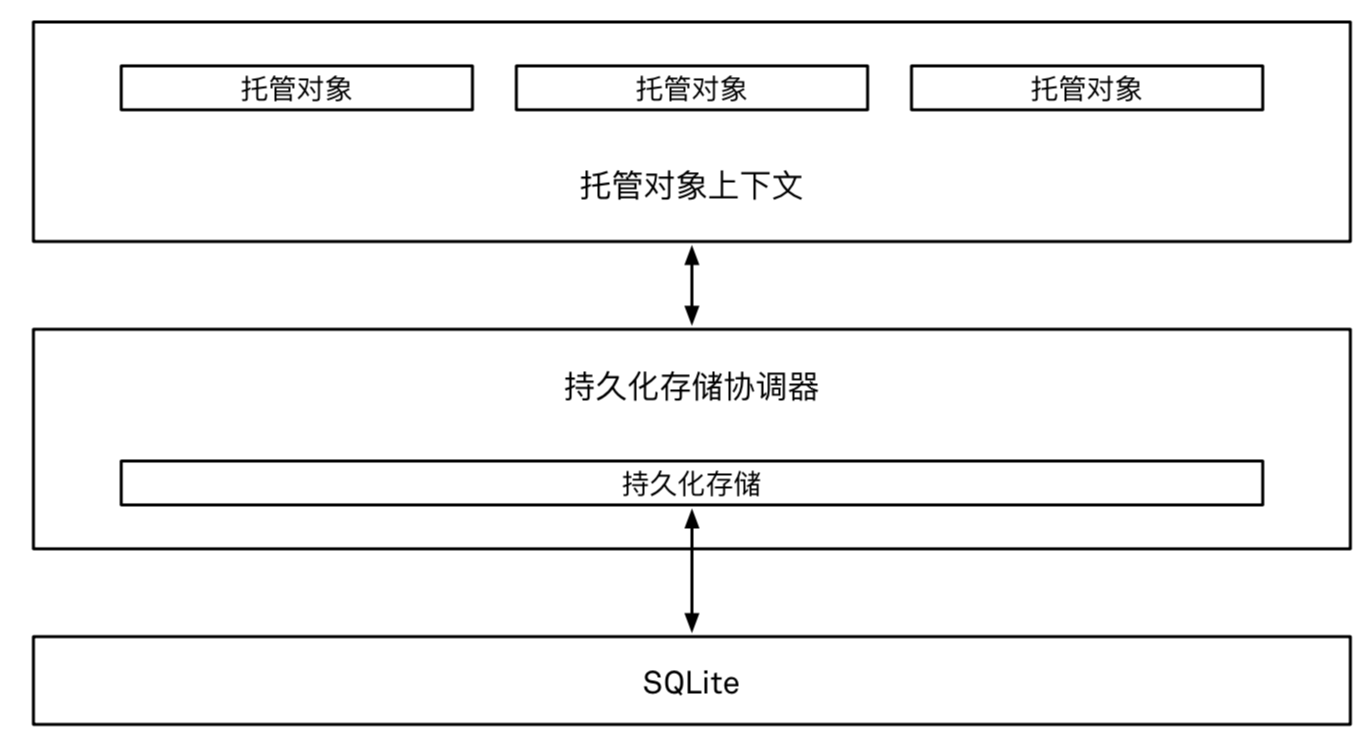
Core Data的架构图:- 托管对象:我们创建的数据模型。
- 托管对象上下文:托管对象上下文记录了它管理的对象,以及对这些对象的 CRUD,每个被托管的对象都知道自己属于哪个上下文。
Core Data支持多个上下文。- 数据底层实际上会被存储在
SQLite数据库里。
-
Core Data存储结构化的数据。所以为了使用Core Data需要先创建一个数据模型来描述我们的数据结构。 -
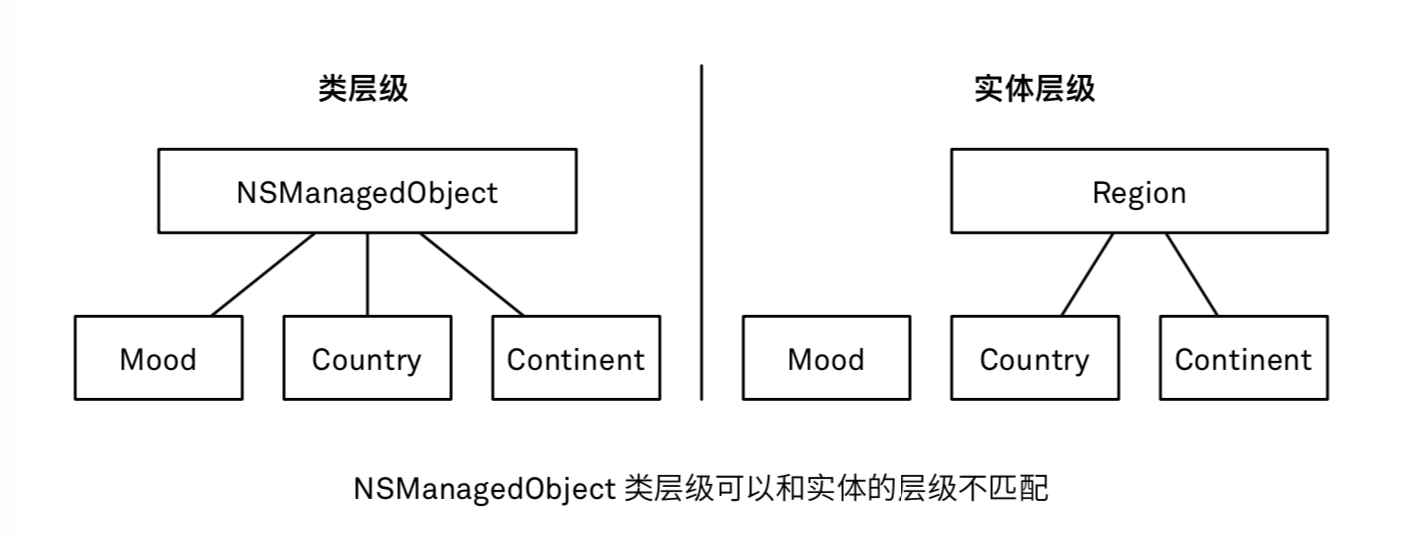
实体:一个实体应该代表你的应用程序里有意义的一个部分数据。实体名称以大写字母开头。
-
属性:属性名称应该以小写字母开头。因为
Array已经遵循里NSCoding协议,所以可以直接把这样的数组直接存入一个可转换类型的属性Transformable里。 -
属性选项:必选属性
non-optional必须要赋给它们恰当的值,才能保存这些数据。把属性标记为可索引时indexed,Core Data会在底层SQLite数据库表里创建一个索引,可以加速这个属性的搜索和排序,但代价是插入数据时的性能下降和额外的存储空间。 -
托管对象子类:实体只是面熟了那些数据属于某个对象,为了能够在代码中使用这个数据,还需要一个具有和实体里定义的属性们相对应的属性的类。
- 实体和类都叫同一个名字。
- 不建议使用
Xcode的代码生成工程工具,而是直接手写。 - 代码通常会如下所示:
final class Mood: NSManagedObject { @NSManaged leprivate(set) var date: Date @NSManaged leprivate(set) var colors: [UIColor]
}
```
- @NSManaged 标签告诉编译器这些属性由 `Core Data` 来实现。
- 在模型编辑器中选中这个实体,然后在 `data model inspector` 里输入它的类名完成实体和类的关联。
-
设置
Core Data栈 -
获取请求 每次执行一个获取请求,都会直达文件系统,是一个相对昂贵的操作,可能是一个潜在的性能瓶颈。
-
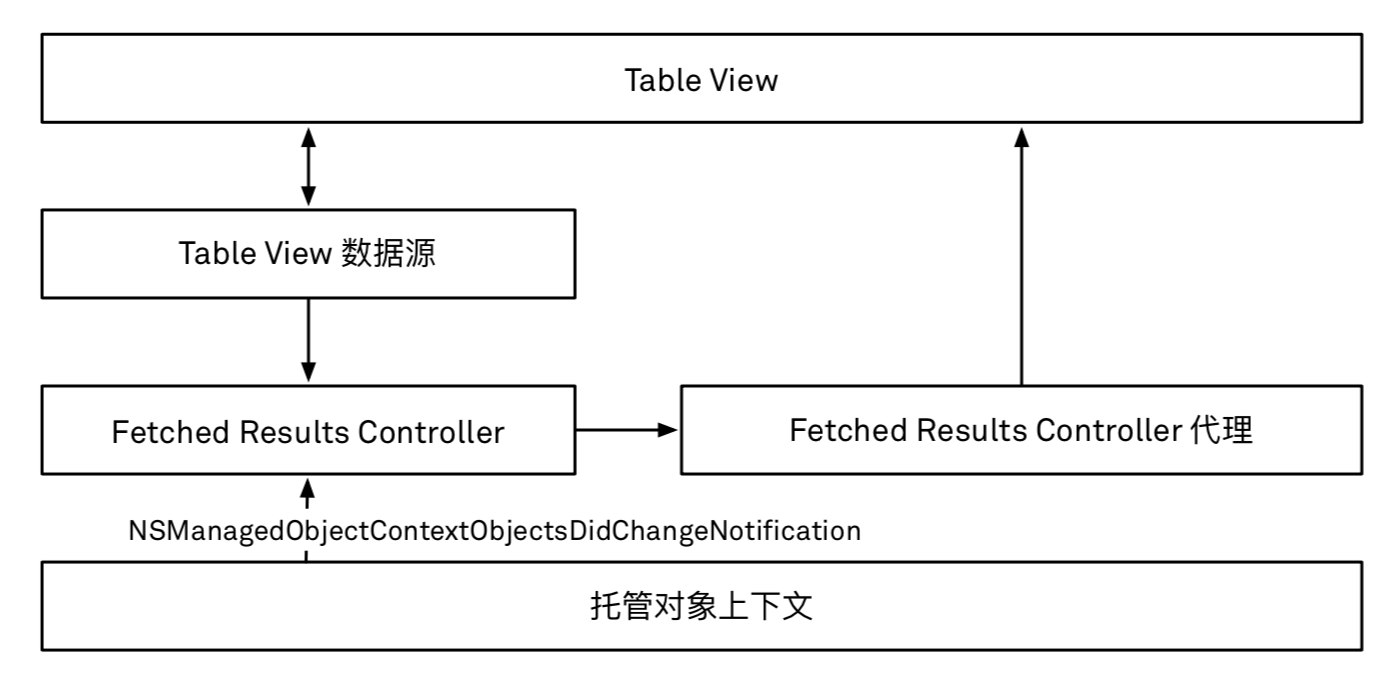
Fetched Results Controller
- 与
tableView的交互:
- 与
-
始终把
Core Data对象交互的代码封装进类似的一个block里。 -
子实体
-
在
Core Data的模型编辑器中设置好关系 -
在代码中写入实体关系代码不是必须的,只要在「模型编辑器」中设置好了对应的关系,实际上就可以开始工作了,但为了在代码里直接使用它们,可以定义一下。
-
自定义删除规则。
- 使用
prepareForDeletion方法,该方法会在对象被删除之前被调用。
- 使用
-
CoreData 推荐在大数据集合时,分批处理,最佳的测试结果显示,单批次 1000 个左右比较好
let request = NSFetchRequest<Mood>(entityName: "Mood")
let moods = try! context.fetch(request)-
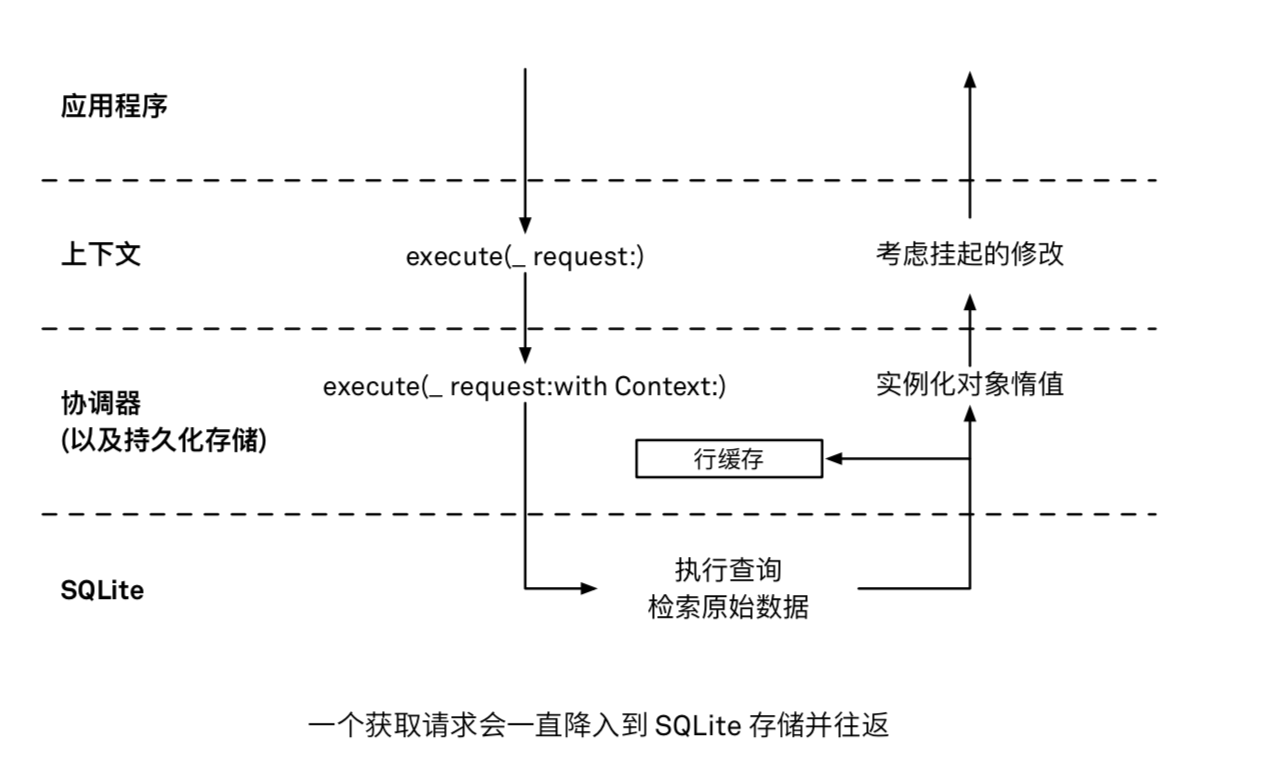
context通过调用execute(_request:withcontext:)方法把请求转交给它的持久化存储协调器。 -
持久化存储协调器通过调用每个存储的
execute(_request:withcontext:)方法把获取到的请求转发给所有的持久化存储。此时的context被传递给了持久化存储。 -
持久化存储把获取请求转换成一个
SQL语句,并把这个SQL语句发送给SQLite。 -
SQLite在存储数据库文件里执行该语句,并将所有匹配查询条件的所有行(row)返回给存储。row里包括了对象的ID和其它属性数据(includesPropertyValues = true)。返回的原始数据是由数字、字符串和二进制大对象 (BLOB, Binary Large Objects) 这样 的简单的数据类型组成的。它被存储在持久化存储的行缓存 (row cache) 里,一起存储 的还有对象 ID 和缓存条目最后更新的时间戳。只要在上下文里存在某个特定对象 ID 的
托管对象,含有这个对象 ID 的行缓存条目就会一直存在,无论这个对象是不是惰值 (fault)。
-
持久化存储把它从
SQLite存储接收到的对象 ID 实例化为托管对象,并把这些对象返回给协调器。这些对象默认是惰性的。在相同的托管对象上下文里,表示相同数据 -
持久化存储协调器把它从持久化存储拿到的托管对象数组返回给上下文。
-
最后,一个匹配该获取请求的托管对象数组被返回给调用者。
需要注意的是,以上这一切的操作都是同步的,而且直到获取请求完成为止,托管对象上下文都会被阻塞。
let request = Mood.sortedFetchRequest(with: moodSource.predicate) request.returnsObjectsAsFaults = false
request.fetchBatchSize = 20这个查询结果只是一个对象 ID 的列表,而不是与它们相关联的所有数据。持久化存储协调器创建一个特殊的,由这些 ID 组成的数组,并将这个数组返回给上下文,并且这个数组没有被任何数据填充,它只在必要的时候才会去获取数据。
一旦我们访问数组里的数据,Core Data 才会去「按页加载」真正的数据,处理流程如下:
- 这个分批处理的数组注意到它缺少你正尝试访问的元素的数据,它会要求上下文加载你 请求的索引附近数量为 fetchBatchSize 的一批对象。
- 像往常一样,这个请求被持久化存储协调器转发到持久化存储,在那里执行适当的SQL 语句来从 SQLite 加载这批数据。原始数据被存储在行缓存里,托管对象则被返回给协 调器。
- 因为我们已经设置了returnsObjectsAsFaults为false,协调器会要求存储提供全部数 据,然后用这些数据来填充对象,并将这些对象返回给上下文。
- 这一批次的数组将返回你所请求的对象,并持有本批次里的其他对象,这样接下来如果 你需要使用其中某个对象的话,就不必再次获取了。
当我们在遍历数组去加载数据时,Core Data 会以 LRU 的原则来控制数据集合,也就是以最近使用作为原则来保持少量批次,而较早的批次将会被释放。
let fetchRequest = NSFetchRequest<Mood>(entityName: "Mood") let asyncRequest = NSAsynchronousFetchRequest(
fetchRequest: fetchRequest) { result in
if let result = result.nalResult { // 获取到结果了
} }
try! context.execute(asyncRequest)为了减小内存消耗和回应内存警告的处理,可以使用 context 的 refreshAllObject() 方法来将不包含待保存改变的对象惰值化。
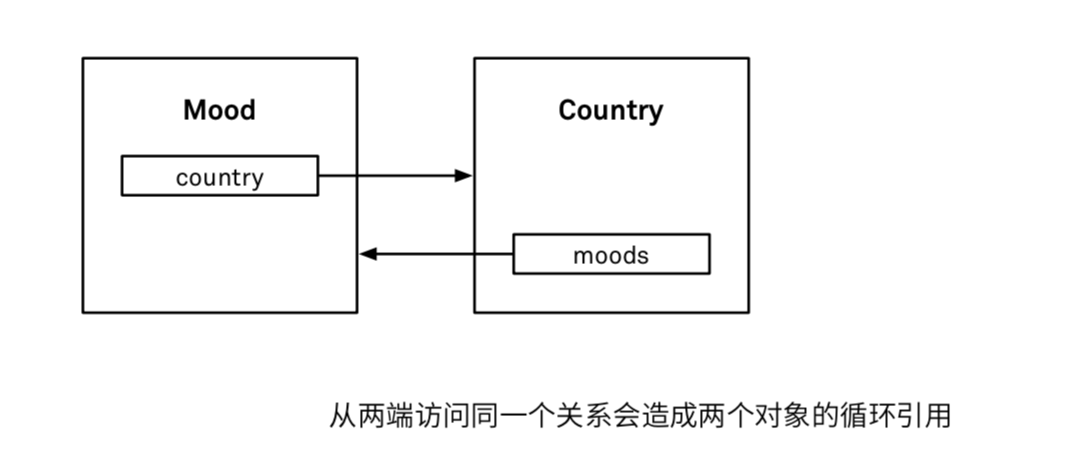
解决以上问题,需要至少刷新一个对象。通过调用上下文的 refresh(_ object:mergeChanges:) 方法
获取请求会遍历整个 Core Data 栈。一个获取请求,按照它的 API 约定,就算是从托管对象上下文中发起的,也会查询到文件系统的 SQLite 存储。
是否添加索引,取决于,在你的应用程序中,获取数据与修改数据频繁程度的比例。如果更新或者插入非常频繁,最好不要添加索引。如果更新或插入不频繁,而查询和搜索非常频繁,那么添加索引会是个好主意。
有一个因素是数据集的大小:如果实体的数目相对较小,添加索引并不能给我们带来多少帮助,因为数据库扫描所有数据也很快。但是如果数量巨大,添加索引就可能可以显著改善性能。
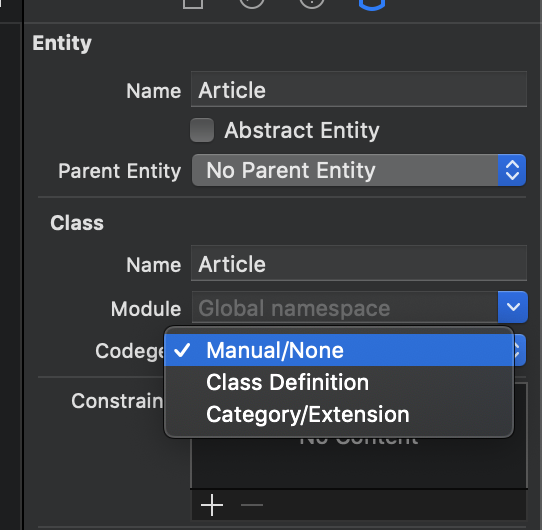
Core Data 默认创建出来的实体是自动生成代码,如果我们想要手动管理实体代码,需要按照如下图进行修改 codegen:
-
第一次初始化时,可以通过
try! fetchedResultsController.performFetch()来获取数据,正常执行完方法后即可拿到数据。NSFetchedResultsController既是 fetch request 的包装,也是一个获取数据用的 container,我们可以从中获取到数据。 -
后续再执行增删时,通过代理响应数据变化。