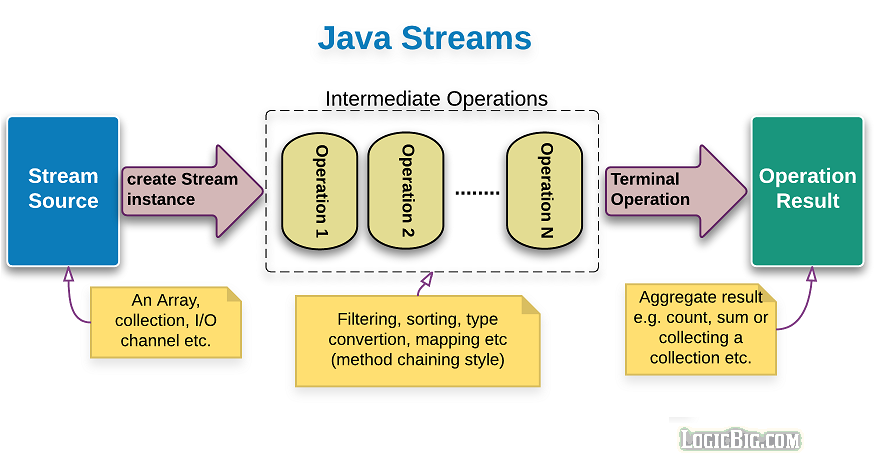
- 데이터 원소의 유한 혹은 무한 시퀀스이다.
- 이 원소들로 수행하는 연산단계를 표현하는 개념을 스트림 파이프라인이라고 한다.
- 스트림안의 데이터는 객체 참조 혹은 기본 타입 값이다.
- 스트림은 생성되고, 중간 연산을 거쳐, 종단 연산으로 끝난다.
- 종단 연산이 실행되기 전까지 그 전의 중간 연산은 지연처리 된다. 따라서 종단 연산은 필수이다.
애너그램이란 단어를 이루는 글자의 순서를 뒤바꾸어 다른 단어로 만드는 것을 의미한다. 아래 예시는 사전에서 많은 애너그램을 가지고 있는 단어를 출력하는 예시이다.
소스코드 자체보다 각 사례별로 코드의 복잡도에 집중하자.
public class Anagrams {
public static void main(String[] args) {
Path dictionary = Paths.get(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
Map<String, Set<String>> groups = new HashMap<>();
try (Scanner scanner = new Scanner(dictionary)) {
while (scanner.hasNext()) {
String word = scanner.next();
groups.computeIfAbsent(alphabetize(word), (unused) -> new TreeSet<>()).add(word);
}
}
for (Set<String> group : groups.values()) {
if (group.size() >= minGroupSize) {
System.out.println(group.size() + ": " + group);
}
}
}
private static String alphabetize(String word) {
char[] a = word.toCharArray();
Arrays.sort(a);
return new String(a);
}
}public class Anagrams {
public static void main(String[] args) throws IOException {
Path dictionary = Paths.get(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
try (Stream<String> words = Files.lines(dictionary)) {
words.collect(groupingBy(word -> word.chars().sorted()
.collect(StringBuilder::new, (sb, c) -> sb.append((char) c), StringBuilder::append).toString()))
.values().stream()
.filter(group -> group.size() >= minGroupSize)
.map(group -> group.size() + ": " + group)
.forEach(System.out::println);
}
}
// 사용되지 않음
// private static String alphabetize(String word) {
// char[] a = word.toCharArray();
// Arrays.sort(a);
// return new String(a);
// }
}위 코드는 당연히 이해하기 어려운 코드이다. 스트림을 과용하면 프로그램이 읽거나 유지보수하기 어려워진다.
public class Anagrams {
public static void main(String[] args) throws IOException {
Path dictionary = Paths.get(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
try (Stream<String> words = Files.lines(dictionary)) {
words.collect(groupingBy(word -> alphabetize(word)))
.values().stream()
.filter(group -> group.size() >= minGroupSize)
.forEach(g -> System.out.println(g.size() + ": " + g));
} catch (IOException e) {
e.printStackTrace();
}
}
private static String alphabetize(String word) {
char[] a = word.toCharArray();
Arrays.sort(a);
return new String(a);
}
}스트림을 처음 쓰기 시작하면 모든 반복문을 스트림으로 바꾸고 싶은 유혹을 느끼겠지만, 서두르지 않는 것이 좋다. 코드를 스트림으로 바꾸는게 가능할지라도 읽기 좋고, 유지보수하기 좋은 코드로 바뀐다는 보장은 없기 때문.
- 지역변수를 읽고 수정하기. 람다에서는 final 이거나 사실상 final 인 변수만 읽을 수 있고, 지역변수를 수정하는 것은 불가능.
- return, break, continue를 사용해 반복문을 종료하거나, 반복을 건너뛰기. 람다에서는 이것이 불가능.
- 원소들을 일관되게 변환한다.
- 원소들을 필터링 한다.
- 원소들을 하나의 연산을 사용해 결합한다. (더하기, 연결하기, 최솟값 등)
- 원소들을 컬렉션에 모은다.
- 원소들 중 특정 조건을 만족하는 원소를 찾는다.
아래 코드는 카드의 숫자와 카드의 모양의 모든 가능한 조합 (데카르트 곱) 을 계산하는 코드이다.
private static List<Card> newDeck() {
List<Card> result = new ArrayList<>();
for (Suit suit : Suit.values()) {
for (Rank rank : Rank.values()) {
result.add(new Card(suit, rank));
}
}
return result;
}전통 for 문을 사용한다면, 2중 for 문을 사용해야할 것 이다.
private static List<Card> newDeck() {
return Stream.of(Suit.values())
.flatMap(suit -> Stream.of(Rank.values())
.map(rank -> new Card(suit, rank)))
.collect(toList());
}어떤 newDeck 메소드가 좋아 보이는지는 개인 취향의 문제이다. 처음 코드가 편한 개발자가 있을 것이고, 반대로 두번째 코드가 편한 개발자가 있을 것이다.
- 스트림을 사용해야 멋지게 처리할 수 있는 일이 있는 반면, 반복 방식이 더 알맞은 일도 있다.
- 많은 작업들은 스트림, 반복 둘 중 하나만 사용하는 것이 아닌, 둘을 적절히 조합하였을 때 멋지게 해결 가능하다.
- 어느쪽을 선택하는 명확한 규칙은 없다. 스트림, 반복 둘다 써보고 더 나은 코드를 선택하는 것이 방법이다.