GPT Code Clippy: The Open Source version of GitHub Copilot
![]()
Courtesy of the awesome Aimee Trevett!
GPT-Code-Clippy (GPT-CC) is a community effort to create an open-source version of GitHub Copilot, an AI pair programmer based on GPT-3, called GPT-Codex. GPT-CC is fine-tuned on publicly available code from GitHub. It was created to allow researchers to easily study large deep learning models that are trained on code to better understand their abilities and limitations. It uses the GPT-Neo model as the base language model, which has been trained on the Pile dataset, and uses the Causal Language Modelling Objective to train the model.
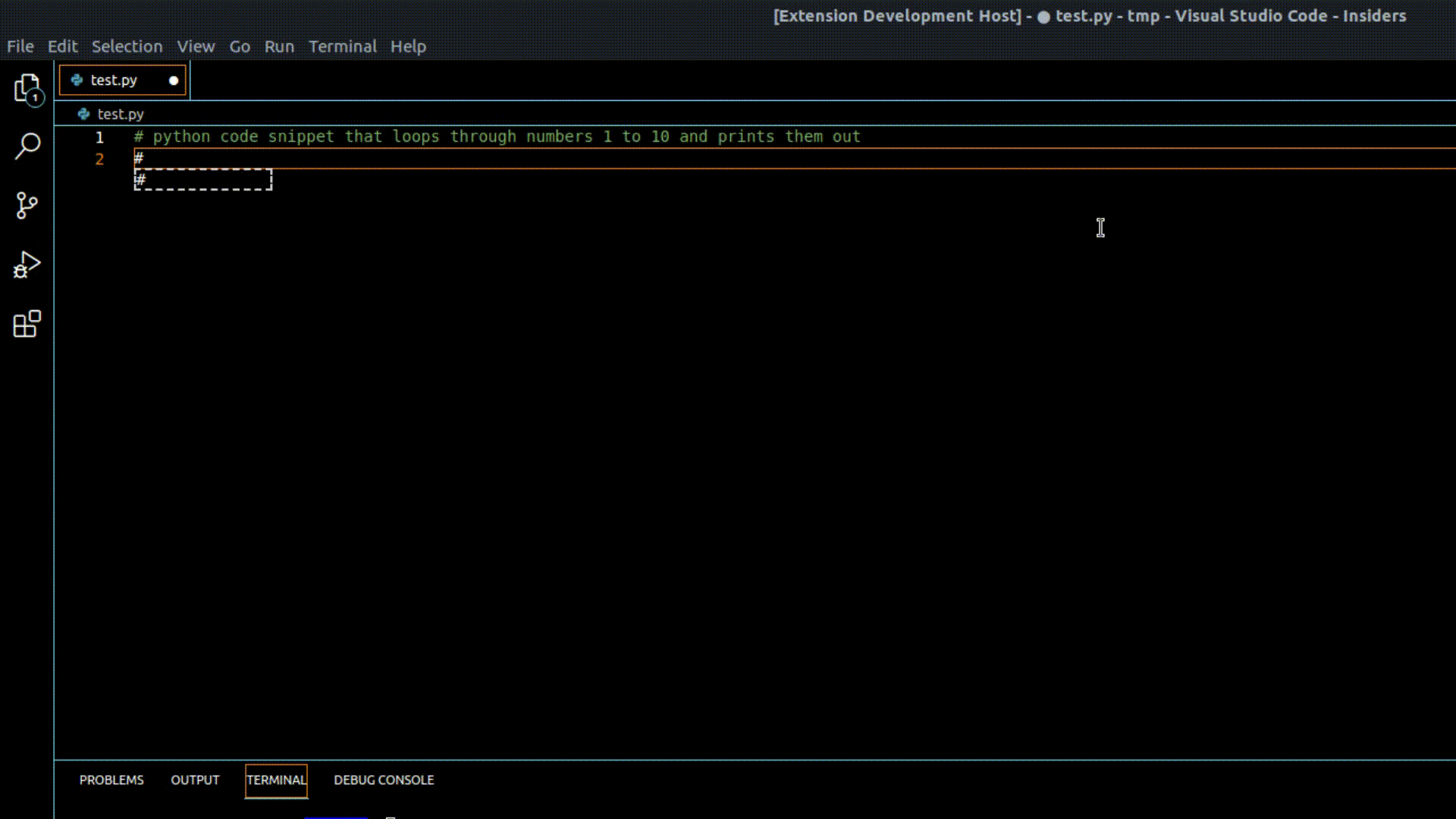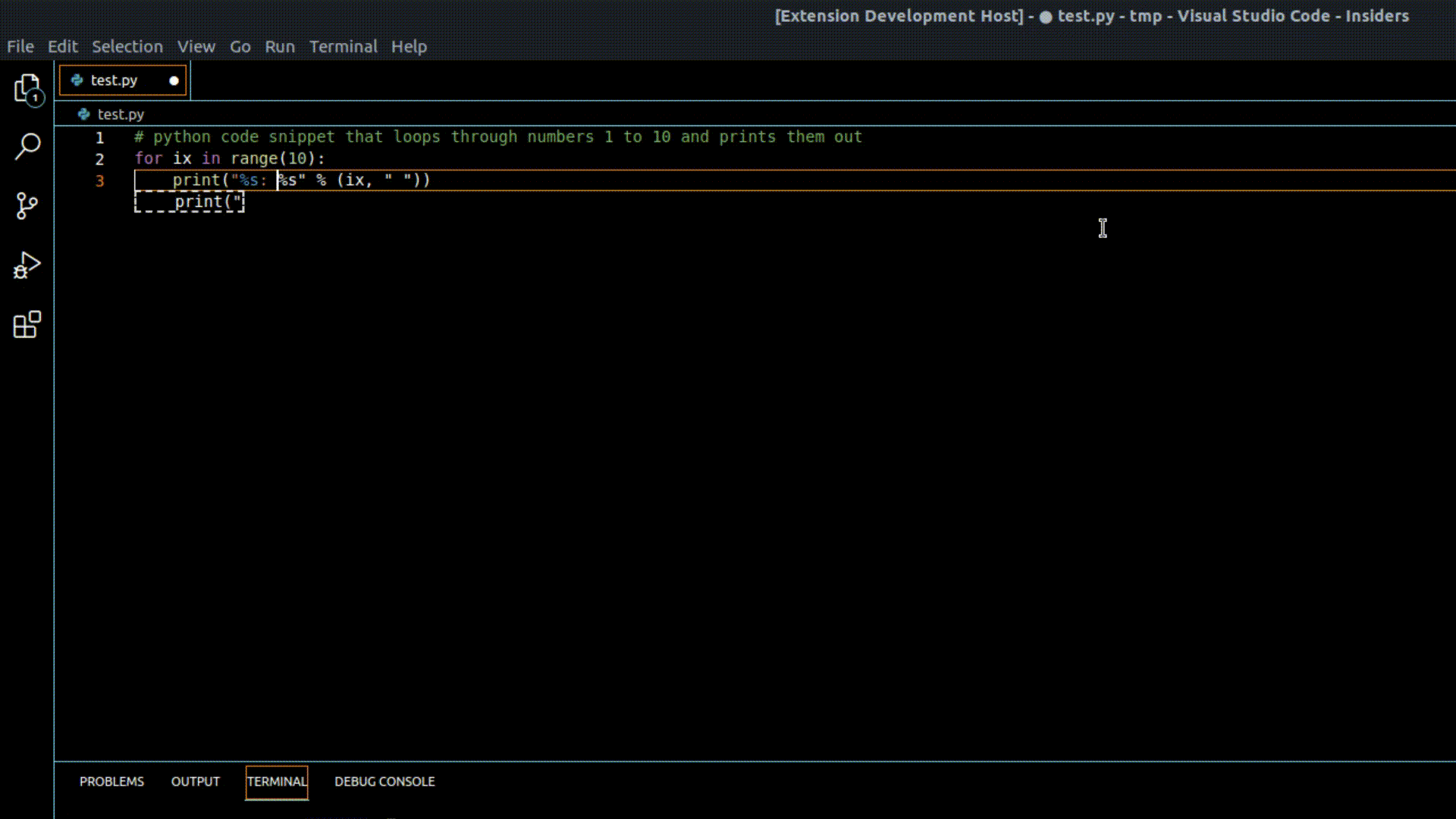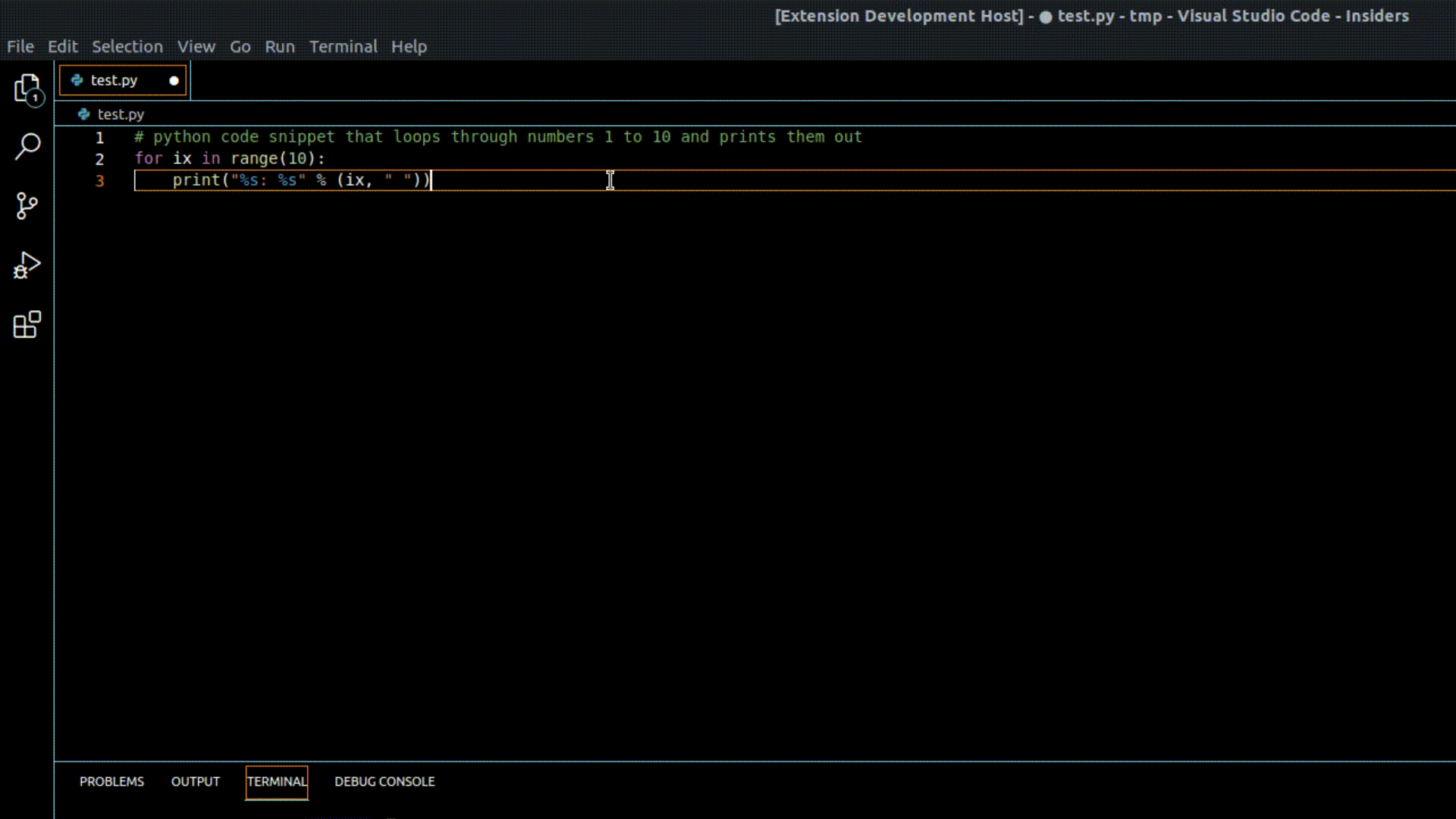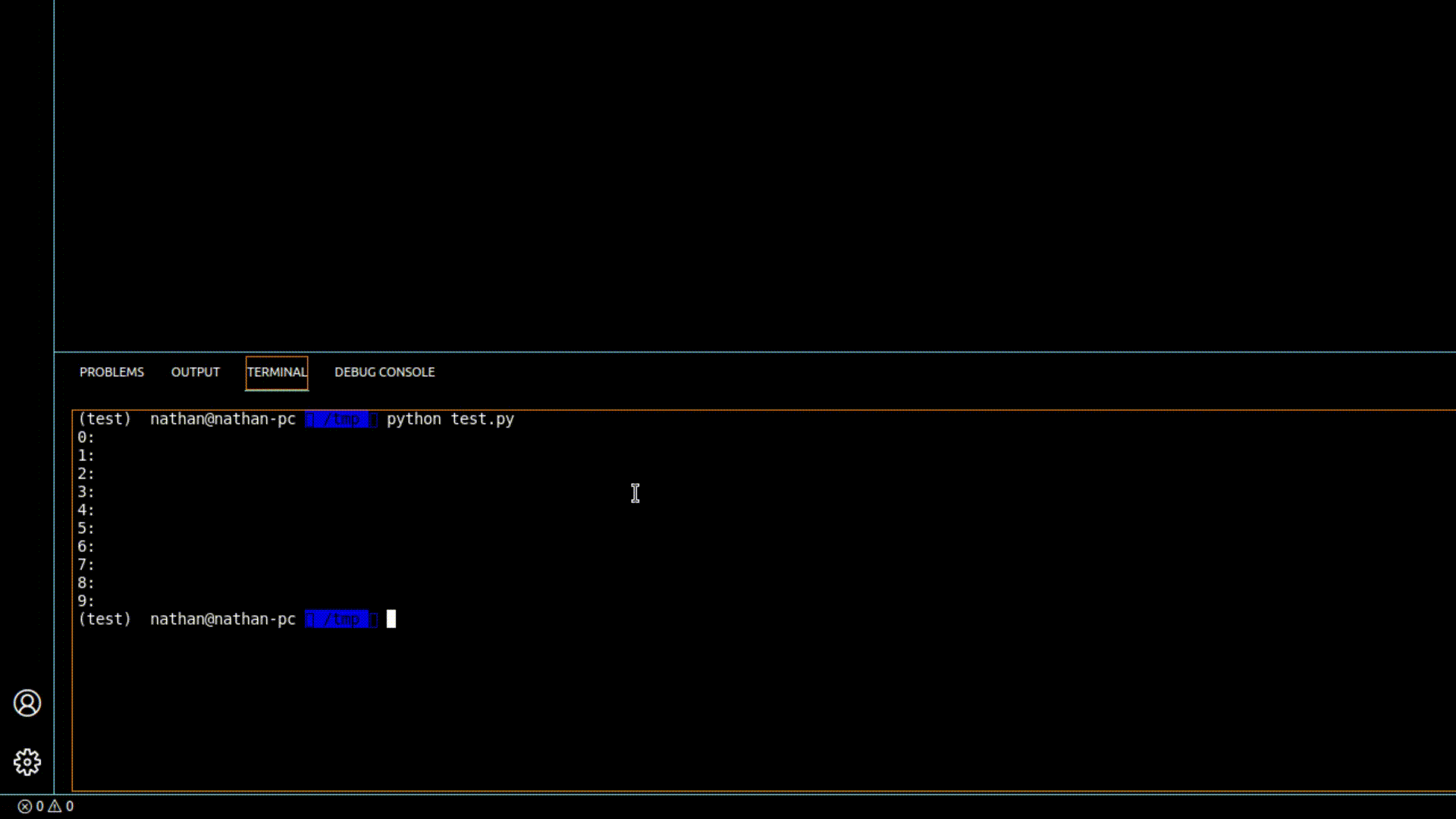
Demo of our VSCode extension in action using one of our GPT-Code Clippy models
- Our self-curated open-source(d) dataset:
Code Clippy Data - Open sourced codebase:
GPT Code Clippy - Our code-generation model base on HuggingFace:
-
VSCode extensionand HuggingFace Space app for immediate use
To train our model, we used Huggingface's Transformers library and specifically their Flax API to fine-tune our model on various code datasets including one of our own, which we scraped from GitHub. Please visit our datasets page for more information regarding them. We used the hyperparameters discussed in the GPT-3 small configuration from EleutherAI's GPT-Neo model. Modifying the batch size and learning rate as suggested by people in EleutherAI's discord server when fine-tuning the model. We decided to fine-tune rather than train from scratch since in OpenAI's GPT-Codex paper, they report that training from scratch and fine-tuning the model are both equally in performance. However, fine-tuning allowed the model to converge faster than training from scratch. Therefore, all of the versions of our models are fine-tuned.
Our training scripts are based on the Flax Causal Language Modelling script from here. However, we heavily modified this script to support the GPT3 learning rate scheduler, weights and biases report monitoring, and gradient accumulation since we only had access to TPUv3-8s for training and so large batch sizes (1024-2048) would not fit in memory.
Please visit our models page to see the models we trained and the results of our fine-tuning.
Eleuther AI has kindly agreed to provide us with the necessary computing resources to continue developing our project. Our ultimate aim is to not only develop an open-source version of Github's Code Copilot but one which is of comparable performance and ease of use. To that end, we are continually expanding our dataset and developing better models. The following are few action items we aim to tick off in the near future:
- Pretrain the model from scratch with the dataset we have curated from GitHub: This would be quite a straightforward process with the computing resources from Eleuther AI
- Experiment with the use of GPT-J in code generation as recommended by Evaluating Large Language Models Trained on Code
- Expand the capabilities of GPT Code Clippy to other languages especially underrepresented ones