
-
Construir um sistema (backend -API-only) que permite ler um arquivo CSV através da linha de comando (terminal), validar os dados e inserir no banco de dados.
-
Como sugestão, pode-se implementar a funcionalidade de ler os dados de horas trabalhadas pelos colaboradores da organização. O arquivo pode seguir o formato abaixo para ler esses dados e injetar no banco. Os dados precisam ser validados, como por exemplo, verificar se a data/hora final é maior que a data hora inicial, verificar se para aquele usuário, já não foi reportado um período anterior que conflite com o período sendo reportado atualmente, se o usuário realmente existe no banco de dados, se os dados respeitam a ordem de colunas do arquivo no formato definido (ou se vão inferir a leitura do cabeçalho e ajustar os dados adequadamente), entre outras possíveis validações.
-
Formato sugerida: ld do usuário | data Inicio | hora início | data fim | hora fim .
-
Os dados acima foram apenas uma sugestão mínima, mas pode-se pensar em definir outros dados que façam sentido no contexto explicado, como talvez tipo de operação realizada pelo colaborador naquele período.
-
Opção: definir se a transação poderá ser desfeita (rollback dos dados) caso alguma validação falhe durante o processamento ou se as operações que não falharem serão salvas no banco e os que falharam serão reportados para posterior processamento
-
Comentários : Se houver tempo hábil, ainda pode-se explorar outras funcionalidades, como fornecer uma API para ser consumida por outros serviços dentro da organização. fazer uma Ul para visualização desses dados, também provendo uma forma de passar o arquivo via upload pela Ul e Enviar e-mail com relatório do processamento para usuários administradores do sistema.






-
Indentificando a implementação de processamento em lotes de arquivos csv com a dependência springbatch.
-
Definindo um diagrama de classe de um sistema api, que receba dados de arquivos em lotes de um paciente, contendo informações do tipo( id,nome,cpf,idade,fone e e-mail).
O Spring Batch oferece inúmeros recursos e funções essenciais não apenas para o processamento de grandes volumes de dados, mas, também, acompanhamento e registro de toda esta execução. A biblioteca prevê suporte para o gerenciamento de transações, análise estatística, reinicialização e cancelamento de tarefas, rastreamento e registro dos ciclos de execução de lotes, dentre outros recursos. O mais interessante em tudo isso é que grande parte do esforço que o desenvolvedor terá usando este framework estará relacionado à configuração dos componentes já existentes, acelerando significativamente e garantindo, ao mesmo tempo, alta qualidade no processo de criação de software.
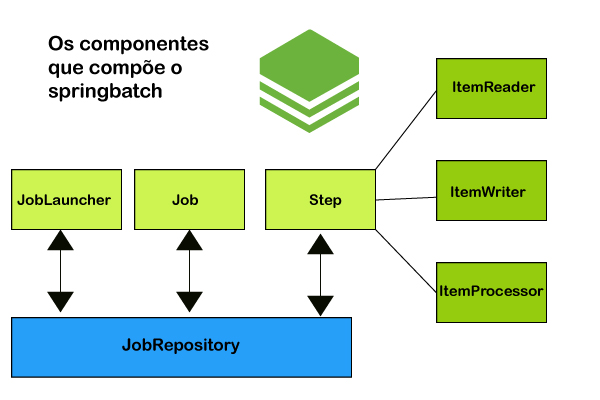
- Job Repository: Mantém o estado do job (duração da execução, status da execução, erros, escritas, leituras, …), que é compartilhado com os outros componentes da solução.
- Job Launcher: Executa o job de fato, considerando fatores como a forma de execução (única thread, distribuído), validação de parâmetros, restart, e outras propriedades da execução.
- Job: Este é o conceito mais genérico e mais importante dentro do Spring Batch. O próprio nome já sugere o seu significado dentro do framework: um trabalho! Em outras palavras, é o que será efetivamente executado pelo sistema.
- Step: Representa uma etapa ou passo na qual uma lógica é executada. Steps são encadeados para obterem o produto final do processamento. Se o step for baseado em chunk (pedaços), ele terá etapas de leitura (ItemReader), processamento (ItemProcessor) e escrita de dados (ItemWriter).


<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.1.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.teste.batch</groupId>
<artifactId>batchTesteApp</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>batchTesteApp</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.8</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
package com.teste.batch.batchTesteApp.springbatch;
import jakarta.persistence.Id;
import lombok.AllArgsConstructor;
import lombok.Data;
//import lombok.ToString;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Paciente {
@Id
private Long id;
private String nome;
private String cpf;
private int idade;
private String fone;
private String email;- Normalmente, seu cliente ou analista de negócios fornece uma planilha. Para este exemplo simples, vamos utilizar dados inventados em https://extendsclass.com/csv-generator.html contendo 1000 registros.
src/main/resources/Paciente.csv:
id,nome,cpf,idade,fone,email
103,Ulrike,Kial,821,Suzette,Karolina
104,Fidelia,Flory,669,Orsola,Alyda
105,Orelia,Dyann,888,Merrie,Ulrike
106,Loree,Starla,487,Kaia,Bernie
107,Betta,Rhoda,887,Kalina,Elena
108,Caritta,Meg,928,Anica,Emilia
109,Anthia,Carly,682,Babita,Anestassia
110,Bertine,Bobinette,188,Feliza,Ardenia
- Script SQL para criar uma tabela para armazenar os dados. Você pode encontrar esse script em src/main/resources/schema-all.sql:
DROP TABLE Paciente IF EXISTS;
CREATE TABLE Paciente (
id long IDENTITY NOT NULL PRIMARY KEY,
nome VARCHAR(50),
cpf VARCHAR(20),
idade int(10),
telefone VARCHAR(20),
email VARCHAR(50)
);
- Um paradigma comum no processamento em lote é ingerir dados, transformá-los e, em seguida, canalizá-los para outro lugar.
- PacienteItemProcessor, implementa a interface do Spring Batch ItemProcessor. Isso facilita a conexão do código em uma tarefa em lote. De acordo com a interface, você recebe um Pacienteobjeto de entrada e depois o transforma em um arquivo Paciente.
package com.teste.batch.batchTesteApp.springbatch;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.lang.NonNull;
public class PacienteItemProcessor implements ItemProcessor<Paciente, Paciente> {
private static final Logger log = LoggerFactory.getLogger(PacienteItemProcessor.class);
@Override
public Paciente process(final @NonNull Paciente paciente) throws Exception {
final Long id = paciente.getId();
final String nome = paciente.getNome().toUpperCase();
final String cpf = paciente.getCpf();
final int idade=paciente.getIdade();
final String fone=paciente.getFone();
final String email=paciente.getEmail();
final Paciente novoPaciente = new Paciente(id, nome, cpf, idade, fone, email);
log.info( "Converting (" + novoPaciente+")into("+ novoPaciente + ")");
return novoPaciente;
}
}-
Spring Batch fornece muitas classes utilitárias que reduzem a necessidade de escrever código personalizado.
-
Configurando a classe trabalho, com a anotação
@Configurationemsrc\main\java\com\teste\batch\batchTesteApp\springbatch\BatchConfig.java.Adicionando os seguintes beans à minha BatchConfigurationclasse para definir um leitor, um processador e um gravador: -
O primeiro pedaço de código define a entrada, o processador e a saída.reader()cria um ItemReader. Ele procura um arquivo chamado Paciente.csv e analisa cada item de linha com informações suficientes para transformá-lo em um arquivo Paciente.
-
processor()cria uma instância do PersonItemProcessor que foi definido anteriormente, destinada a converter os dados .
-
writer(DataSource)cria um ItemWriter. Este é direcionado a um destino JDBC e obtém automaticamente uma cópia do dataSource criado por
@EnableBatchProcessing. Inclui a instrução SQL necessária para inserir um único Paciente, orientado pelas propriedades do Java@bean. -
O primeiro método define o trabalho e o segundo define uma única etapa. Os trabalhos são construídos a partir de etapas, onde cada etapa pode envolver um leitor, um processador e um gravador.
-
Nesta definição de tarefa, foi incrementado, porque as tarefas usam um banco de dados para manter o estado de execução. Em seguida, lista cada etapa (embora este trabalho tenha apenas uma etapa). A tarefa termina e a API Java produz uma tarefa perfeitamente configurada.
-
Na definição da etapa, foi definido quantos dados serão gravados por vez. Neste caso, grava até dez registros por vez.
chunk ( 10 ) é prefixado <Paciente,Paciente>porque é um método genérico. Isso representa os tipos de entrada e saída de cada “pedaço” de processamento e se alinha com ItemReader<Paciente>e ItemWriter<Paciente>.
package com.teste.batch.batchTesteApp.springbatch;
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
public class BatchConfig {
@Bean
public FlatFileItemReader<Paciente> reader() {
FlatFileItemReader<Paciente> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("Paciente.csv")); // Substitua pelo caminho correto do seu arquivo CSV
reader.setLinesToSkip(1); // Pule a primeira linha (cabeçalho)
DefaultLineMapper<Paciente> lineMapper = new DefaultLineMapper<>();
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames("id", "nome", "cpf", "idade", "fone", "email");
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(new BeanWrapperFieldSetMapper<Paciente>() {{
setTargetType(Paciente.class);
}});
reader.setLineMapper(lineMapper);
return reader;
}
@Bean
public PacienteItemProcessor processor() {
return new PacienteItemProcessor();
}
@Bean
public JdbcBatchItemWriter<Paciente> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Paciente>()
.itemSqlParameterSourceProvider( new BeanPropertyItemSqlParameterSourceProvider<>() )
.sql( "INSERT INTO paciente (id, nome, cpf, idade, fone, email) VALUES (:id, :nome, :cpf, :idade, :fone, :email)" )
.dataSource( dataSource )
.build();
}
@Bean
public Job importPacienteJob(JobRepository jobRepository,JobCompletionNotificationListener listener, Step step1) {
return new JobBuilder( "importPacienteJob", jobRepository)
.incrementer( new RunIdIncrementer() )
.listener( listener )
.flow( step1 )
.end()
.build();
}
@Bean
public Step step1(JobRepository jobRepository,
PlatformTransactionManager transactionManager, JdbcBatchItemWriter<Paciente> writer) {
return new StepBuilder( "step1", jobRepository)
.<Paciente, Paciente> chunk( 10 , transactionManager )
.reader( reader() )
.processor( processor() )
.writer( writer )
.transactionManager( transactionManager )
.build();
}
} A última parte da configuração em lote é uma forma de ser notificado quando o trabalho for concluído.
- O JobCompletionNotificationListener escuta quando um trabalho é realizado BatchStatus.COMPLETED e depois usa JdbcTemplate para inspecionar os resultados.
package com.teste.batch.batchTesteApp.springbatch;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
//import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Component;
@Component
public class JobCompletionNotificationListener implements JobExecutionListener {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
//@Autowired
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus()== BatchStatus.COMPLETED){
log.info("!!! JOB FINISHED! Time to verify the results");
jdbcTemplate.query("SELECT * FROM paciente", (rs, row) -> new Paciente(
rs.getLong("id"),
rs.getString("nome"),
rs.getString("cpf"),
rs.getInt("idade"),
rs.getString("fone"),
rs.getString("email"))).forEach(paciente ->log.info("Found <{{}}> in the database.",paciente)); {
}
}
}
}#####Execução do Aplicativo
package com.teste.batch.batchTesteApp;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class BatchTesteAppApplication {
public static void main(String[] args) {
SpringApplication.run(BatchTesteAppApplication.class, args);
}
}-
@SpringBootApplicationé uma anotação de conveniência que adiciona todos os itens a seguir: -
@Configuration: marca a classe como uma fonte de definições de bean para o contexto do aplicativo. -
@EnableAutoConfiguration: Diz ao Spring Boot para começar a adicionar beans com base nas configurações do classpath, outros beans e várias configurações de propriedades. Por exemplo, sespring-webmvcestiver no caminho de classe, essa anotação sinaliza o aplicativo como um aplicativo Web e ativa comportamentos importantes, como configurar um arquivoDispatcherServlet. -
@ComponentScan: Diz ao Spring para procurar outros componentes, configurações e serviços no
com/teste/batch, permitindo que ele encontre os controladores.
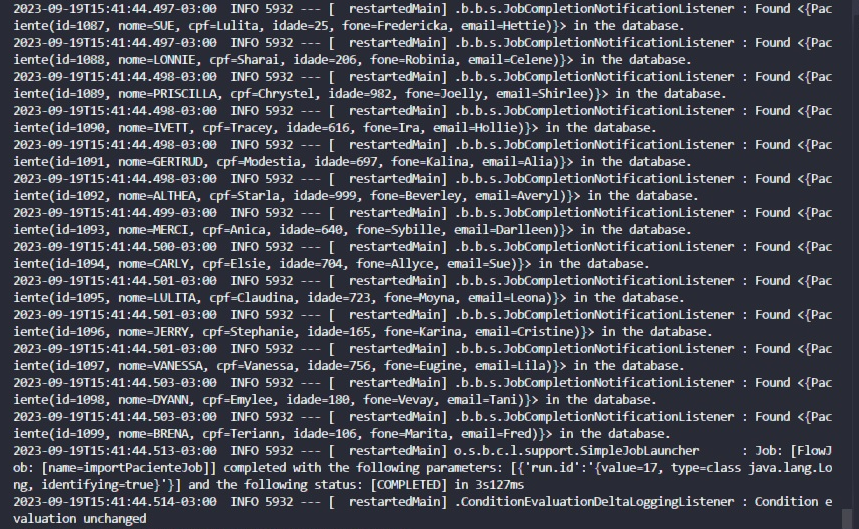
- 1000 Registros foram incluidos em apenas 3s, com o batch.
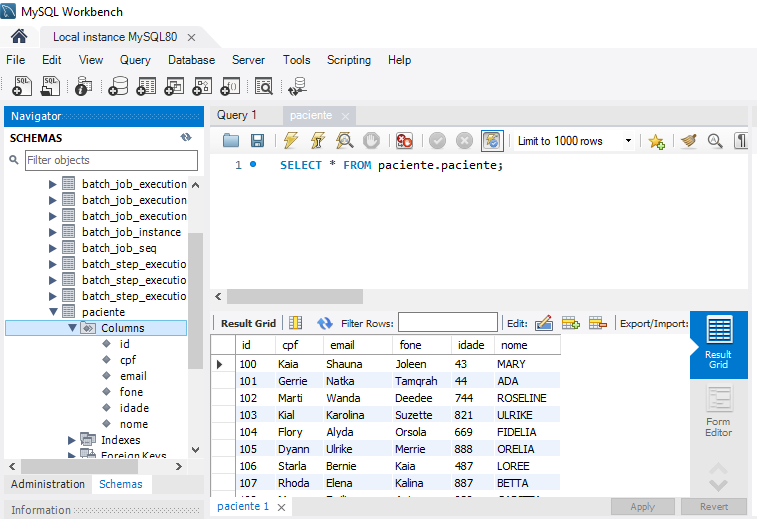
- **1000 Registros foram incluidos na tabela paciente no Mysql com sucesso !
