{kind=link}
{kind=link}
{kind=link}
GPU Accelerated Ray Tracer using CUDA and C++

1024 triangles, accelerated ray tracing on GPU with cuda. ~28 FPS (runs faster than what is shown, screen capture slows it down)
I used cuda with a NVIDIA GTX 960 graphics card and a laptop with a RTX 2060 graphics card to implement and test a GPU accelerated Ray Tracer. This README describes the parts of the Ray Tracer that I accelerated. This was just taking my CPU implementation, which can be found on my profile, and adding cuda to it, with some small changes to the design.
This code still uses a bvh tree. Except we cudaMallocManage all of the nodes so that they are in global memory so we have access to them on the GPU.
Calculating the initial rays to cast into the scene is the first step of the ray tracer. I was able to accelerate this on the GPU by creating a large array in global memory of size width*height of the frame and passing a pointer of it to my cuda kernel. By indexing into this array we can figure out what pixel corresponds to that index.
But first need to figure out what index a given thread block and individual thread maps to. This picture from Nvidia's website describes this well.
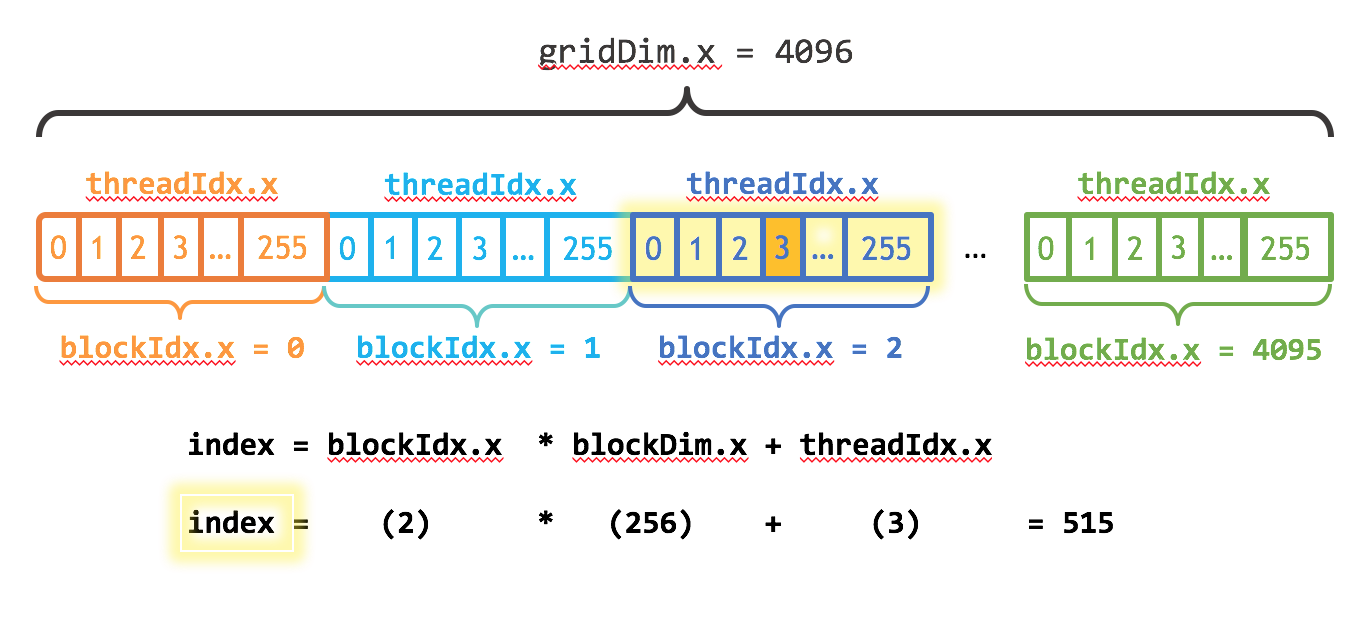
A thread block is made up of some number of threads. In this example a thread block is made up of 256 threads. So to index into an array we can just take what block number the thread belongs to, how many threads per block, and the number of the thread in that block.
So our index equation would be int index = blockNumber * threadsPerBlock + threadInBlockNumber
Now to figure out what Pixel this index corresponds to.
If our frame is 720X360. This can simply be done by saying row = index/720 col = index%720
Now we just do the math to determine the ray we are casting into the scene and put it at that index to be used later.
This is done exactly like Primary Ray Generation where we index into that global array. When we index into that array we get a ray that we can determine the intersection point of. Now, unlike a CPU implementation, we can have thousands of threads working on different rays at the same time, instead of just a few threads. The Ray Intersection function uses a bvh tree traversal function that is located on the GPU. When we find an intersection, we make an intersection point with relevant information and put it in an array at that same index.
From our Ray Intersection function we get a bunch of intersections we can calculating the shading value of. We just use phong shading with the light information. When testing shadow rays, we call the same bvh traversal device(GPU) function as we did with Ray Intersection.

In order to animate the ray tracer, we need to refit the BVH anytime any geometry in the scene moves. We refit the BVH tree from the bottom of the tree up every frame, resulting in all of the geometry staying in the same leafs but the bounding boxes move. Now potentially overlapping more. This constant refitting degrades the quality of the BVH tree, resulting in worse performance if we never rebuild.
In order to fix the BVH tree after so many frames. We completely free the original tree and rebuild from scratch. I picked to rebuild the tree every 20 frames.
I wanted to animate the ray tracer. To do this I simply write all of the RGB values to a OpenGl texture and then render it as a texture onto 2 triangles in an OpenGl Context.

~38 FPS (runs faster than what is shown, screen capture slows it down)
Initial results show significant improvement over my CPU multi-threaded implementation. On a simple scene, it showed 3-4X improvement on the runtime. On the teapot scene it showed 5-10X speed up depending on the reflection options. More testing would need to be done to see how performance scales as more rays and more objects increases.

Teapot (1024 triangles) with no reflection rays, rendered in 17 frames/second on GTX 960 GPU vs. 40 frames/second on RTX 2060 vs. 1.6 frames/second on CPU.
Ray Sorting- GPU caches are small, so ray sorting would possibly increase cache hits by processing rays sequentially that might access the same parts of the bvh tree. So possibly the scene objects would already be in the cache.
Find something for the CPU to do- right now all of the work is being done on the GPU. This results on the CPU just waiting there until the GPU finishes. I tried doing Ray sorting on the CPU while the GPU is doing phong shading, but the GPU returned faster than the CPU could finish sorting, resulting is slower overall execution.
Re-implement Area Lights- I implemented soft shadows using area lights on the CPU, but haven't extended it to my GPU implementation yet.