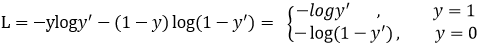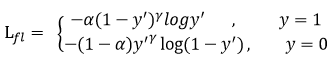- [硬间隔] 所有数据线性可分,所有数据均满足分类条件,即存在超平面完全正确分类正负样本
- [软间隔] 部分数据线性不可分。
- [核函数]
python中的list与c++的list不同,c++中的list是双向链表,而python list更像c++中的vector。<br>
python中Cpython list定义如下结构体
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;(指向列表元素的指针)
Py_ssize_t allocated;(分配内存的大小)
} PyListObject;<br>
这里的分配内存是成倍增加的0,4,8,16,25,35,46,58,72,88……当列表长度小于总内存的一半时,会自动的删除1/2内存<br>
(https://zhuanlan.zhihu.com/p/30584550)
(https://www.jianshu.com/p/cd75475168ae)
append的复杂度O(1) insert O(n) Pop O(1)

CNN卷积前向

训练阶段:对mini-batch中的每一个实例卷积后的对应位置的同一通道中的所有元素求均值以及方差
测试阶段:记录训练mini-batch过程中的每一个均值以及方差,并对所有的均值-方差求无偏估计作为inferere的均值与方差。

LR本质是分类,一般回归用MSE,分类用交叉熵。因为分类,经过MSE,为非凸函数,难以收敛;当接近某一类时,另外一类的数值很小,容易造成梯度消失。
前向随机以概率p失活某神经元。
函数间隔是几何间隔没有除以||w||的表达,几何间隔是函数间隔归一化的结果
一定会收敛。
- ROC曲线: 接收者操作特征(receiver operating characteristic))
纵坐标 真正类率(True Postive Rate)TPR: 在正类中被预测为正类占所有正类的比例 横坐标 负正类率(False Postive Rate)FPR: 在负类中被预测为正类占所有负类的比例

浅copy没有单独申请内存,2个变量为同一个id,改了一个变量另外一个变量也会改变; 深copy单独申请内存
朴素贝叶斯的假设为所有的特征相互独立,贝叶斯网络源于贝叶斯定理(即条件概率)。当特征个数肥肠多时,整个贝叶斯网络里的参数是庞大的,源于不同特征间的联和分布。因此将其简化,可得到最简单的朴素贝叶斯。
K-means,
id类特征除了onehot编码还有哪些?遇到高维特征呢?怎么才算高纬?
RGB,HSV,YBR
L1,L2损失。L1-smooth; 交叉熵损失; triplet损失;
anchor free算法? Yolo,SSD, centernet,cornernet
one-stage比two-stage精度低的原因主要是正负样本比例不均衡。 one-stage会产生大量的候选区域,而这些候选区域只有很少的一部分属于正样本。 而two-stage经过RPN网络,初选出那些概率比较大的候选区域,令正负样本的比例在1:3.
在二分类的交叉熵损失函数中,y'是于猜测输出数值,正样本预测概率值越大,其损失越小;负样本预测概率越小,损失越大。这样使得越简单的正样本占的损失使得困难样本的损失起的作用很小。因此引出如下focal Loss
引入Gamma因子。Gamma>0使得减少易分类样本的损失,使得模型更关注于困难的、错分的样本。
最后再引入数据平衡因子 Alpha,用来平衡正负样本本身的数量比例不均(即类别不均衡)