
This implementation can be used to both 1) to perform field-guide like question-answering ZSL and reproduce the results from the paper(for example).
See requirements.txt for installation. It is recommended to use python3.9 as the code has been tested in python3.9.
The direct download link for the data can be found here [data.zip]. The data directory should be extracted in the home directory of the project.
So if path/to/Field-Guide-ZSL is the project directory data directory should be path/to/Field-Guide-ZSL/data.
The data directory is organized in the following format:
data/
CUB/
CUB_r101.pkl
CUB_parent.npy
CUB_nns.npy
SUN/
...
AWA2/
...
{Dataset}_r101.pkl contains information semantic and image information for the dataset. The .pkl file contains the information provided by the datasets from [1].
{Dataset}_parent.npy contains the taxonomy information about the dataset. Classes with same parents are considered siblings in our framework.
{Dataset}_nns.npy contains the user annotated nearest base class information for the novel classes.
[1] Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly, Xian et. al., CVPR 2017
The scripts directory provides useful commands for training and reproducing the results from the paper. To train all the models for reproduction of the results use:
bash train_models.sh {Dataset} # {Dataset} = CUB, SUN, AWA2
This will train all the models (and also 6 different random runs for each on 2 GPUs). The trained models can be used to then run the experiments.
Note that in the train_models.sh file and infer_*.sh, CUDA_VISIBLE_DEVICES is used to parallelize the experiments on 2 GPUs. Change the variable accounting for the number of GPUs and GPU memory.
train_models.sh uses train_vae.py for training the CADA-VAE on base classes.
Once the model are trained on a particular dataset, different infer_*.sh can be used to look at the performance accuracies.
The bash files in script are also arranged according to experiments in the paper.
For example, to collect data for experiment from section 4.2 in the paper use exp4.2_cadavae.sh.
So run:
bash exp4.2_cadavae.sh {Dataset} # {Dataset} = CUB, SUN, AWA2
This will generate all the baselines and our method for that experiment.
We also recommend to look at the comments and commands of scripts/run_single_experiment_cub.sh for better understanding of which testing mode corresponds to which policy in the paper.
The plots directory can be used to create and look at the plots from the paper one the experimental data is collected.
To evaluate a certain experiment say 4.3, go to plots directory and run 4.3.sh bash file.
cd plots
bash 4.3.sh
This will create a directory with available experimental data and different ZSL datasets.
For example, experiment 4.2 for CUB produced the following plots.
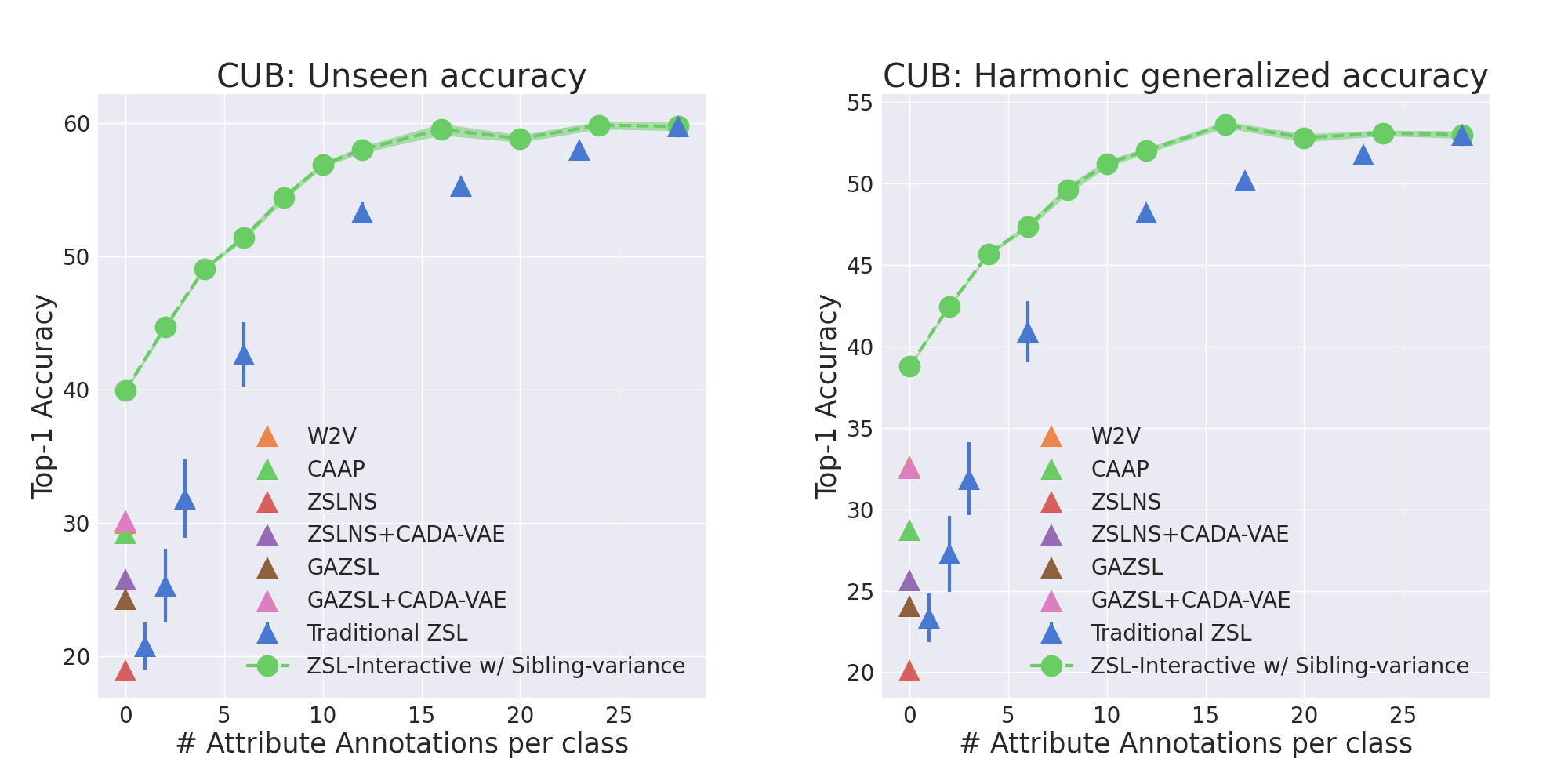
The evaluation experiments with experts and expert annotations are coming soon.
The base model of this code is based on the CADA-VAE implementation.